
气象要素缺失条件下不同机器学习模型计算参考作物蒸散量比较
2022-07-28 13:00:00郝林如郭向红郑利剑马娟娟孙西欢苏媛媛胡飞鹏
节水灌溉 2022年7期
郝林如,郭向红,2,雷 涛,郑利剑,马娟娟,孙西欢,苏媛媛,胡飞鹏
(1.太原理工大学水利科学与工程学院,太原 030024;2.中国水利水电科学研究院流域水循环模拟与调控国家重点实验室,北京 100038)
0 引 言
参考作物蒸散量(ET0)是指导农业灌溉的重要参数,它被定义为具有特定特征的假设作物参考表面的蒸散量,将ET0与不同作物系数相乘可得不同作物需水量[1]。因此ET0的准确计算对灌溉规划和农业用水管理具有重大意义[2]。
Penman-Monteith(PM)公式是联合国粮农组织推荐计算ET0的标准方法[3],所需气象要素包括最高气温、最低气温、相对湿度、2 m 高风速和日照时数[4]。但是在很多地区,由于降雨、仪器故障、人为误操作等原因会导致气象要素缺失,无法使用PM 公式计算[5]。因此,很多学者提出了基于较少气象要素的简化模型,例如Hargreaves-Samani 模型、Priestly-Taylor 模型和Irmak-Allen 模型等,但是这些模型的模拟精度不高[6]。随着计算机技术和机器学习算法的发展,越来越多的机器学习算法应用于气象要素缺失条件下ET0的预测,该方法简便高效,易于推广。WEN等[7]在气象要素缺失条件下,使用支持向量机、人工神经网络和经验法Priestley-Taylor、Hargreaves-Samani 对蒸散量进行预测,得出支持向量机在蒸散量的估计方面比人工神经网络和经验法更准确的结果。程才华[8]在26个气象要素缺失条件下,使用支持向量机对蒸散量进行模拟,得出模拟精度最高的气象要素组合为气温、风速、日照时数、相对湿度。张薇等[9]在4 个气象要素缺失组合下,使用3种基于树型算法,包括梯度提升决策树(GBDT)、随机森林(RF)和回归树(CART)模型预测蒸散量,结果表明GBDT 和RF有较高模拟精度。
然而尽管国内外在气象要素缺失条件下使用支持向量机、随机森林、人工神经网络等机器学习模型预测ET0已经有了大量的研究,但是在不同气象要素缺失组合下系统比较不同机器学习模型的研究还较少,因此本文以山西省果树研究所Adcon-Ws 无线自动气象站为例,把PM 公式的计算值作为标准值,用决策树(CART)、随机森林(RF)、梯度提升决策树(GBDT)、极端梯度提升树(XGBoost)、支持向量机(SVR)、BP 神经网络(BPNN)和深度学习(DL)7 种机器学习模型模拟不同气象要素缺失条件下的ET0,为气象要素缺乏的地区预测蒸散量提供理论依据。
1 材料与方法
1.1 研究区概况
研究站点位于山西省晋中市太谷县的农科院果树研究所(东经112°32’,北纬37°23’,海拔约800 m),所在区域为典型的大陆性半干旱气候,多年平均气温为9.8 ℃,年平均降雨量约460 mm,无霜期175 d。受季风季影响,年内降雨严重不均[10]。
1.2 数据来源
本文所用基础气象数据来自山西省果树研究所Adcon-Ws无线自动气象监测站,包括最高气温(Tmax)、最低气温(Tmin)、2 m高风速(u2)、相对湿度(RH)、日照时数(n)。
1.3 研究方法
(1)Penman Monteith 模型。PM 公式综合考虑各种气象要素,具有较强的普适性,其计算结果可作为模拟ET0的标准值[3]。公式如下:
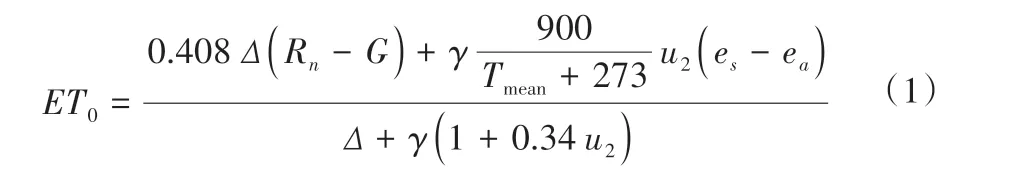
式中:ET0为参考作物蒸散量,mm/d;Rn为净辐射,MJ/(m2·d);G为土壤热通量,MJ/(m2·d);Tmean为2 m 高处日平均气温,℃;u2为2 m高处的风速,m/s;es为饱和水汽压,kPa;ea为实际水汽压,kPa;Δ为饱和水汽压曲线的斜率;γ为湿度计常数,kPa/℃。
(2)决策树(CART)。CART 是一种广泛应用的决策树学习方法,用于回归时称为CART回归树。它包含特征选择、树的生成与剪枝。该模型计算复杂度不高,解释性强,对中间缺失值不敏感,但方差高,容易过拟合[9]。
(3)随机森林算法(RF)。随机森林是一种基于Bagging的集成学习算法。首先用bootstrap方法有放回的从数据集中重复取样来选取训练样本,在得到训练集后分别独立训练决策树,然后将其组合,由决策树预测结果的均值作为最终结果[11]。RF 算法数据采样以及特征采样随机,并且它训练速度快,容易做成并行化方法,实现比较简单,能通过减小模型方差提高性能,被广泛用来解决分类与回归问题[11]。
(4)梯度提升决策树(GBDT)算法。GBDT 是一种基于Boosting 的集成学习算法,它的基本思想是用当前模型损失函数的负梯度信息来训练新加入的弱分类器,然后将训练好的弱分类器以累加的形式结合到现有的模型中,弱分类器一般选择CART 模型[12]。GBDT 的性能在RF 的基础上又有一步提升,它能灵活的处理各种类型的数据,在相对较少的调参时间下,预测的准确度较高,并且对数据缺失不敏感,能通过减小模型偏差提高性能。但由于它是Boosting,基学习器存在串行关系,难以并行训练数据[9]。
(5)极端梯度提升(XGBoost)算法。XGBoost 是一种高效的GBDT 算法。在算法的损失函数上,XGBoost 加上了正则化部分。在算法的优化方式上,GBDT 的损失函数只对误差部分做负梯度(一阶泰勒)展开,而XGBoost的损失函数对误差部分做二阶泰勒展开,使得结果更加准确[13]。同时XGBoost 具有模块结构可以支持并行计算[14]。
(6)支持向量机(SVR)。支持向量机算法用于回归时称为支持向量回归(SVR),它比较好的实现了结构风险最小化思想,得到的是全局最优解[5]。为解决非线性回归问题,模型通常用转换函数φ将变量x映射到高维特征空间,再对其进行计算,并引入核函数可以将原来线性算法非线性化[15]。SVR能较好解决小样本以及非线性问题。本研究核函数类型选择为径向基函数(RBF)。
(7)BP 神经网络(BPNN)。BP 神经网络的学习过程由信号的正向传播和误差的反向传播组成,要素信息由输入层输入,经隐含层处理后,传向输出层,若输出层的实际输出和期望输出不符,就进入误差的反向传播阶段,此过程不断重复直至达到要求[16]。Kolmogorov 定理表明,具有一个隐含层的3 层BPNN 已经有足够的逼近能力[17]。因此本文采用3 层网络结构,分别由输入层、隐含层和输出层组成,每层的激活函数均设为Relu函数,学习率为0.01。
(8)深度学习(DL)。深度学习是在传统人工神经网络的基础上添加更多的隐含层,以建立更加复杂的网络结构[5]。本文采用增加BP 神经网络隐含层数量的深度学习算法,把隐含层设为3 层,它的具体训练过程与BP 神经网络相同。每层激活函数设为Relu 函数,优化方法采用Adam 算法,学习率为0.01。为了防止过拟合,正则化系数L1、L2设为0.01。
(9)经验法。选取4种经验法与机器学习模型进行对比分析,具体计算公式见表1[18]。

表1 经验法及计算公式Tab.1 Empirical method and calculation formula
1.4 气象要素缺失条件下不同机器学习预测模型构建
首先,选取与PM 公式计算所需的气象要素最高气温(Tmax)、最低气温(Tmin)、相对湿度(RH)、2 m 高风速(u2)和日照时数(n)一致的数据构成组合1。为了构建气象要素缺失条件下机器学习模型,在组合1的基础上分别缺失相对湿度(RH)、日照时数(n)、2 m 高风速(u2)、最高最低气温(Tmax、Tmin)构成组合2~5。将气象要素缺失最多,仅包含Tmax、Tmin数据组合构成组合9。再在组合9 的基础上分别增加了RH、n、u2构成组合6~8。气象要素缺失组合见表2。将9组气象要素组合分别作为7 种机器学习模型的输入,ET0作为模型的输出,构建CART1~CART9,RF1~RF9,GBDT1~GBDT9,XGBoost1~XGBoost9,SVR1~SVR9,BPNN1~BPNN9,DL1~DL9共63个机器学习模型。
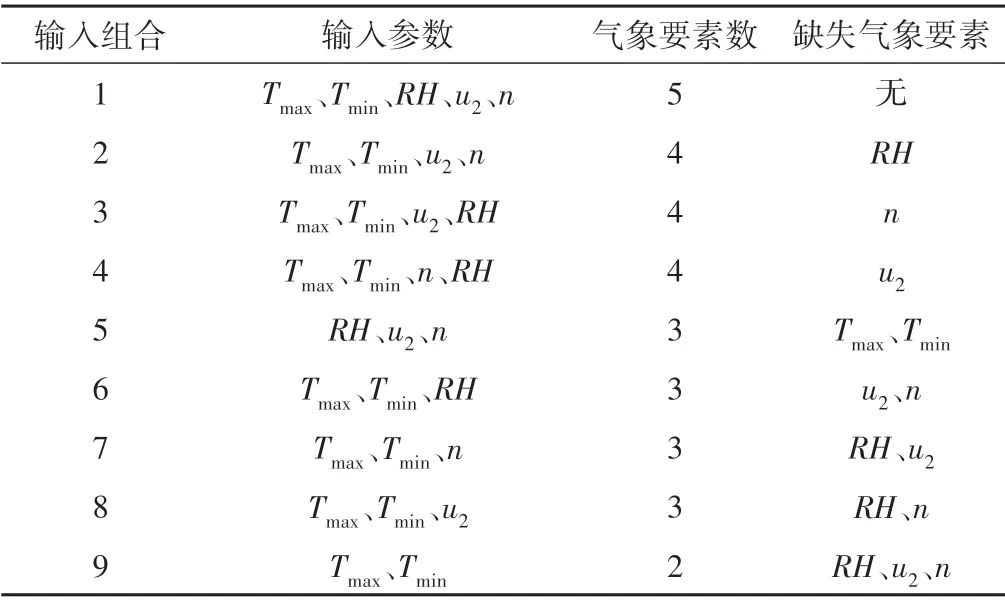
表2 不同气象要素缺失组合Tab.2 Combinations of different input meteorological factors
CART、RF、GBDT、XGBoost、SVR 算法是基于Python 语言的Skicit-Learn 模块建立的模型,BPNN 和DL 是基于Python语言Keras 模块建立的模型。在选取的687 组样本数据中,随机选取其中515组(约占总样本的3/4)作为训练样本,172组(约占总样本的1/4)作为测试样本。使用StandardScaler 对数据集进行标准化和归一化处理。CART、RF、GBDT、XGBoost、SVR 5 种模型使用网格搜索和5 折交叉验证相结合的方法选择最优参数组合。网格搜索其本质就是将参数空间划分成若干网格,通过遍历网格交叉点处所有的参数组合来优化需要训练的模型[19];5 折交叉验证是将初始数据集分成5份,每次将其中一份保留,其他4 份用于训练,以最终5 折交叉验证所得的平均误差指标作为模型最终结果[20]。BPNN和DL模型的参数有隐含层节点数和最大迭代次数,本研究在根据经验确定出隐含层节点数的范围的基础上,将其放大,通过不断调整节点数和迭代次数,使得训练目标方差达到要求,最终确定最优参数组合。
1.5 模型评价指标
选用平均绝对误差(MAE)、均方根误差(RMSE)、平均绝对百分比误差(MAPE)和决定系数(R2)作为模型评价指标,公式如下[21]:
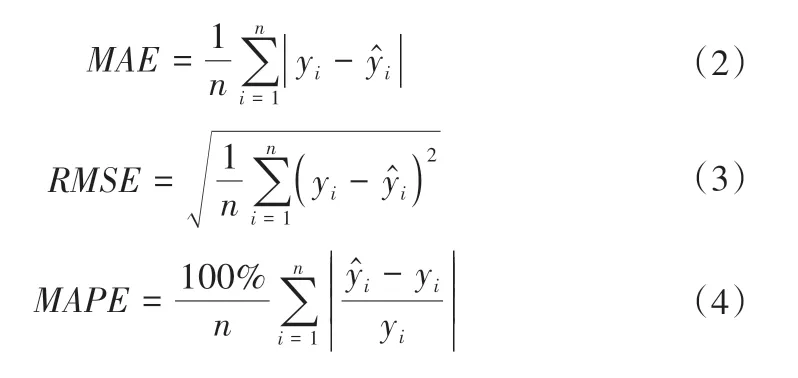
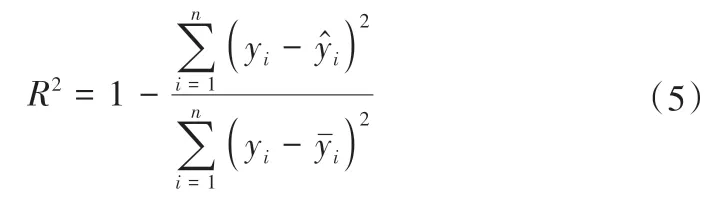
若计算精度越高,MAE、RMSE和MAPE越接近0,R2越接近于1。
2 结果与分析
2.1 气象要素缺失条件下不同机器学习模型模拟精度对比
为了对比气象要素缺失条件下不同机器学习模型模拟精度,本文选用训练误差和预测误差对比来说明模型的泛化能力,同时选用预测误差结果来说明模型的模拟精度。各模型在不同气象要素缺失组合下的ET0计算的精度对比见表3。
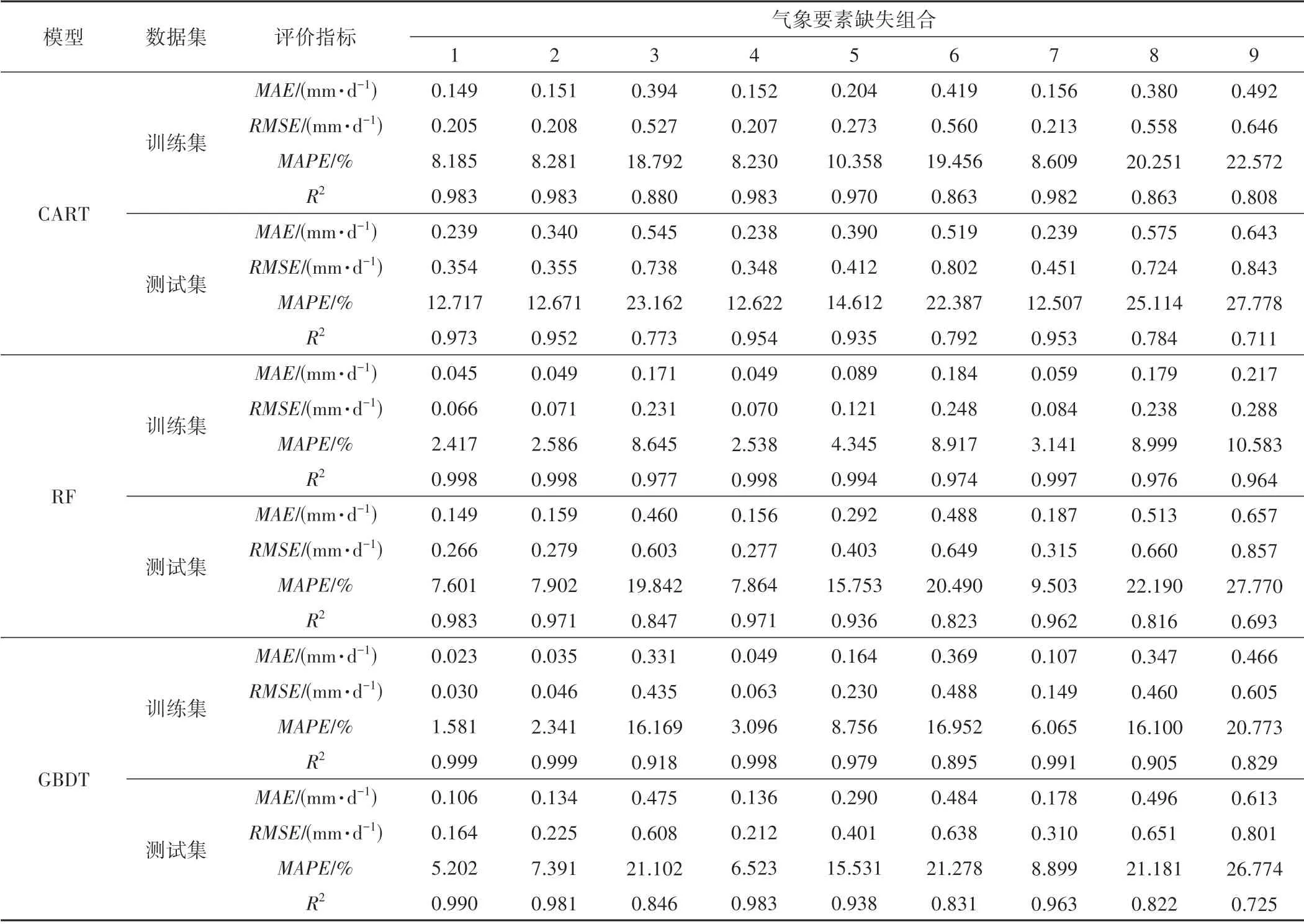
表3 7种模型在不同气象要素缺失组合下的训练误差和测试误差Tab.3 Training and testing errors of seven models under different combinations of meteorological elements
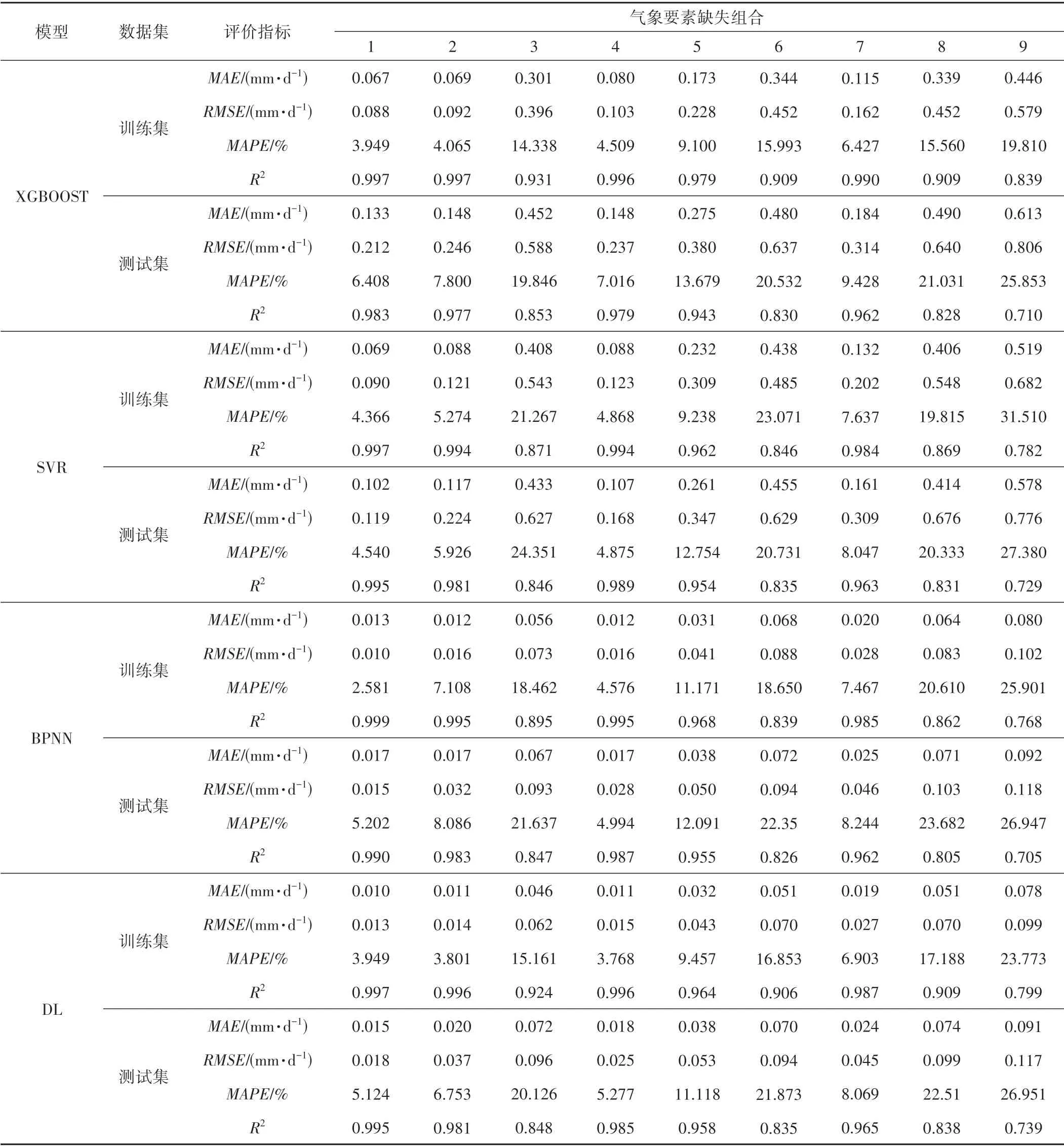
续表
当输入全部5个气象要素时,所有模型的测试集R2达到最高,MAE、RMSE和MAPE达到最低。7 种机器学习模型中DL的模拟精度最高,R2达到0.995,MAE、RMSE和MAPE分别为0.015 mm/d、0.018 mm/d 和5.124%,其他6 种模型按模拟精度由高到低依次为BPNN、SVR、GBDT、XGBoost、RF 和CART。同时DL 的训练误差与预测误差相差较小,R2差值为0.002,MAE和RMSE的相差范围均不超过0.005 mm/d,MAPE的差异值在1.5%以内,泛化能力较好,其他6 种模型按泛化能力由高到低依次为BPNN、SVR、XGBoost、GBDT、CART和RF。
当缺乏一个气象要素时(组合2~4),机器学习模型模拟精度相比组合1有所降低,在缺失相同气象要素条件下,不同机器学习模型模拟精度也有所差异。组合2~4中,DL和BPNN模拟精度较高,排名为第1 或第2,其他5 种模型模拟精度在组合2、4 中排名相同,由高到低依次为SVR、GBDT、XGBoost、RF、CART,组合3 中排名依次为XGBoost、RF、GBDT、SVR、CART。在这3 个组合中,BPNN 训练误差与预测误差相差均较小,泛化能力较好,其他6种模型泛化能力排名在组合2 中由高到低依次为DL、SVR、XGBoost、GBDT、RF、CART,组合3 中依次为DL、SVR、GBDT、XGBoost、CART、RF,组合4 中依次为DL、SVR、XGBoost、GBDT、CART、RF。
当缺乏2 个气象要素(组合5~8)时,机器学习模型模拟精度都进一步降低。在组合5~8 中,DL 的预测误差均最小,模拟精度排名第1。其他6种模型模拟精度在组合5~6,8中排名相同,由高到低依次为BPNN、SVR、XGBoost、GBDT、RF、CART,组合7 中排名依次为BPNN、SVR、GBDT、XGBoost、RF、CART。在这4 个组合中,BPNN 训练误差与预测误差相差均较小,泛化能力排名第1。其他6 种模型泛化能力在组合5、7 中排名相同,由高到低依次为DL、SVR、XGBoost、GBDT、CART、RF,在组合6、8 中排名相同,由高到低依次为DL、SVR、GBDT、XGBoost、CART、RF。
当输入2个气象要素(组合9),所有机器学习模型模拟精度达到最低,即模型测试集的R2均小于0.8,MAE、RMSE除BPNN 和DL 外均大于0.5 mm/d,MAPE均大于25%。7 种机器学习模型中DL 的模拟精度最高,其他6 种模型按模拟精度由高到低依次为BPNN、SVR、XGBoost、GBDT、CART、RF。同时BPNN 的训练误差与预测误差相差较小,泛化能力较好,其他6 种模型按泛化能力由高到低依次为DL、SVR、CART、GBDT、XGBoost、RF。
综上,在所有组合中DL 模拟精度普遍较高,BPNN 泛化能力普遍较好,表明DL、BPNN 相比其他模型可以有效避免参数的随机性选择,具有高度自学习自适应能力,能够快速有效地反映多因素之间高度非线性的复杂关系[22],提高了模拟精度和泛化能力。同时DL 相比BPNN 建立了更复杂的网络结构使得模拟结果更加准确,但可能因为训练样本数量或噪声的影响导致训练过程出现过拟合现象,从而泛化能力稍逊于BPNN。刘堃等[5]在干旱半干旱区生态系统缺失蒸散量插补研究中得出DL和BPNN 相比SVR、CART等模型预测效果更好的结论,与本研究结论一致。XGBoost、GBDT、RF 是以决策树为基学习器的集成模型,模拟精度和泛化能力相比CART都有了一定的提高。但这3种模型与SVR相比训练误差较小或相差不多,而预测误差却大于SVR,这可能是因为训练的样本数量不足或数据有噪声,导致XGBoost、GBDT、RF 在训练过程中容易出现过拟合现象,从而降低了预测精度。本研究中除组合3 以外其他组合XGBoost 和GBDT 模拟精度和泛化能力均大于RF,说明XGBoost、GBDT 在预测蒸散量时相比RF 更有优势,这与牛曼丽等[23]、张薇等[9]的研究结果基本一致。本文不同组合中XGBoost、GBDT 模型的模拟精度和泛化能力排名不同,但整体上XGBoost 效果更好,这与理论上XGBoost 是一种高效的GBDT算法一致。
2.2 不同气象要素对机器学习模型模拟的影响
为了分析不同气象要素对机器学习模型模拟的影响,以随机森林(RF)为例将气象要素缺失条件下的模型模拟结果进行对比,其他6种模型情况与之相同。
组合2~5 分别缺失气象要素相对湿度(RH)、日照时数(n)、2 m 高风速(u2)和最高最低气温(Tmax、Tmin),这4 种组合下随机森林模型(RF2~RF5)的模拟精度由图1可得,RF3、RF5 的模拟精度稍逊于RF2、RF4,说明最高最低气温(Tmax、Tmin)和日照时数(n)对于模型模拟蒸散量的影响比其他气象要素更显著,同时RF2的模拟精度低于RF4,RF3的模拟精度低于RF5,说明日照时数(n)对模型的影响最大,然后是最高最低气温(Tmax、Tmin)、相对湿度(RH),最后是2 m高风速(u2)。
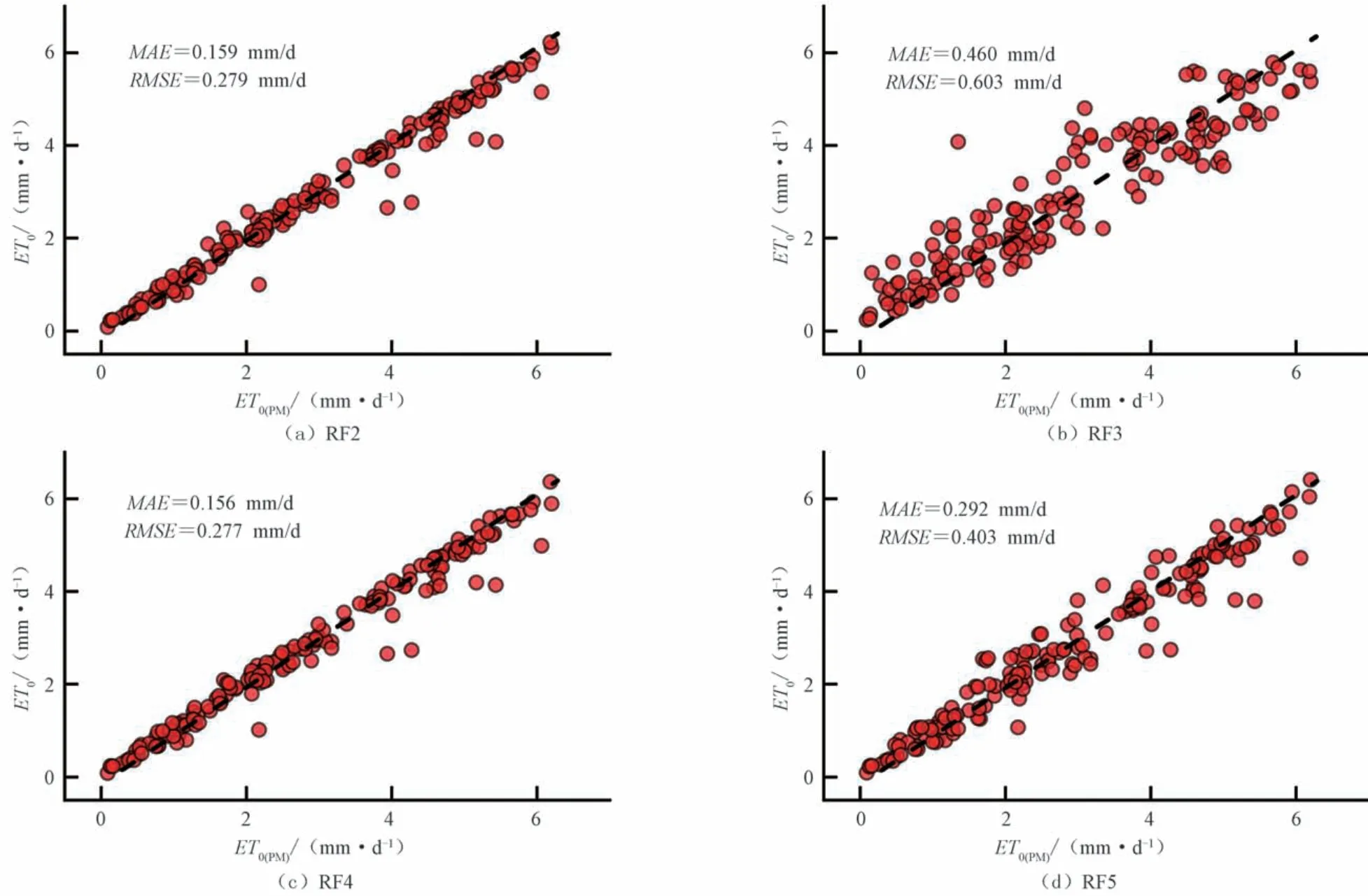
图1 RF2~RF5与PM模型计算结果对比Fig.1 Comparison of calculation results between RF2~RF5 and PM model
组合6~8 是在组合9(Tmax、Tmin)的基础上分别增加了RH、n、u2,这3 种组合下随机森林模型(RF6~RF8)的模拟精度见图2,RF7 的MAE和RMSE较小,模拟精度较高,其次是RF6,最后是RF8,因此RH、n、u2对模型预测ET0的影响程度为n>RH>u2。
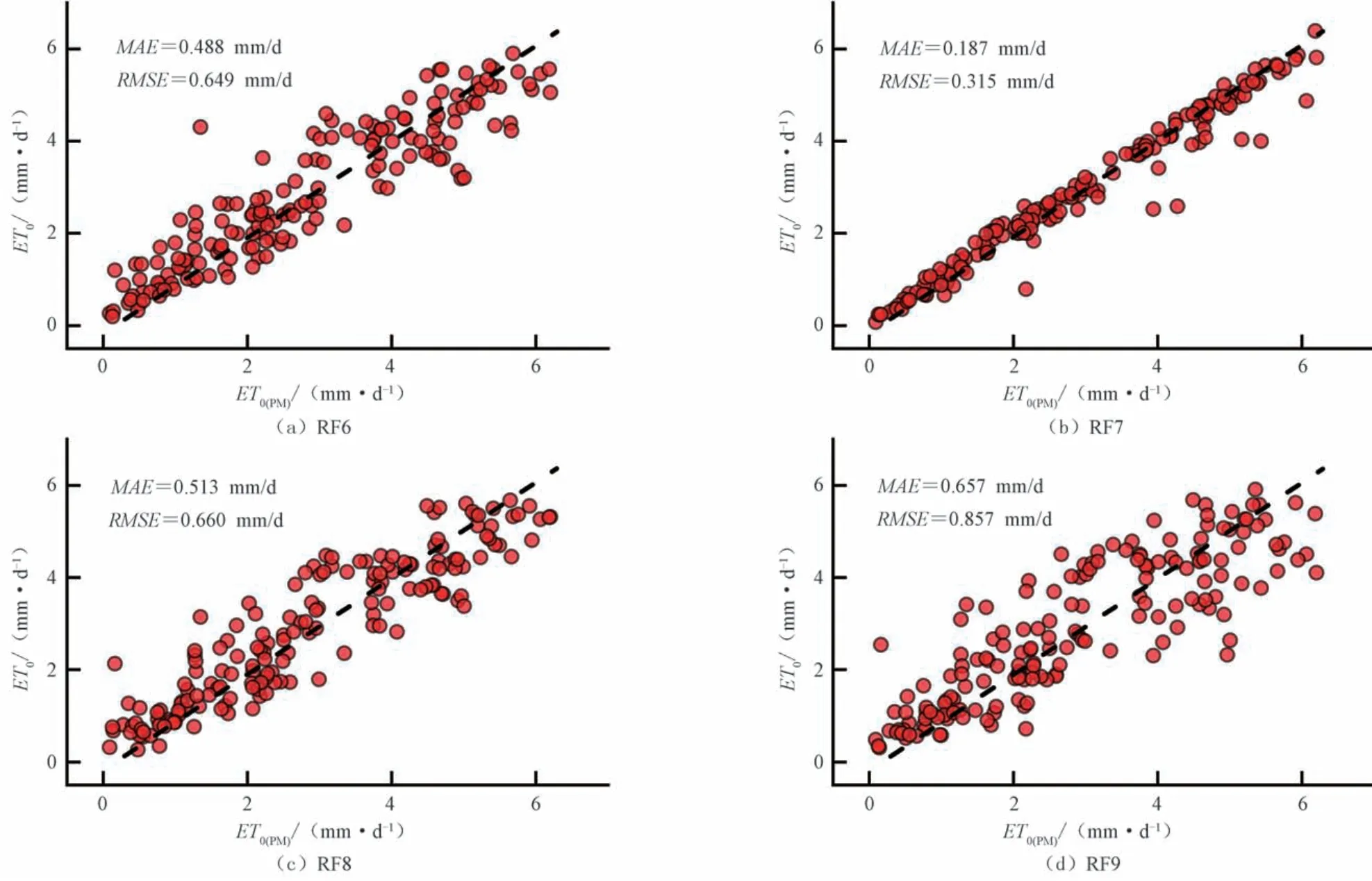
图2 RF6~RF9与PM模型计算结果对比Fig.2 Comparison of calculation results between RF6~RF9 and PM model
综上,气象要素对机器学习模型模拟参考作物蒸散量(ET0)的影响程度由大到小依次为n、Tmax、Tmin、RH、u2。
2.3 机器学习模型与经验法比较
为了比较机器学习模型和经验法的模拟精度,选取机器学习模型中模拟精度较差的决策树模型与H-S、I-A、Makkink、P-T 经验法进行对比。组合9 与H-S 的输入参数相同,组合7 与I-A、Makkink、P-T 的输入参数相同,故将这2种组合下决策树算法(CART7、CART9)与对应经验法的MAE、RMSE进行比较,见图3。
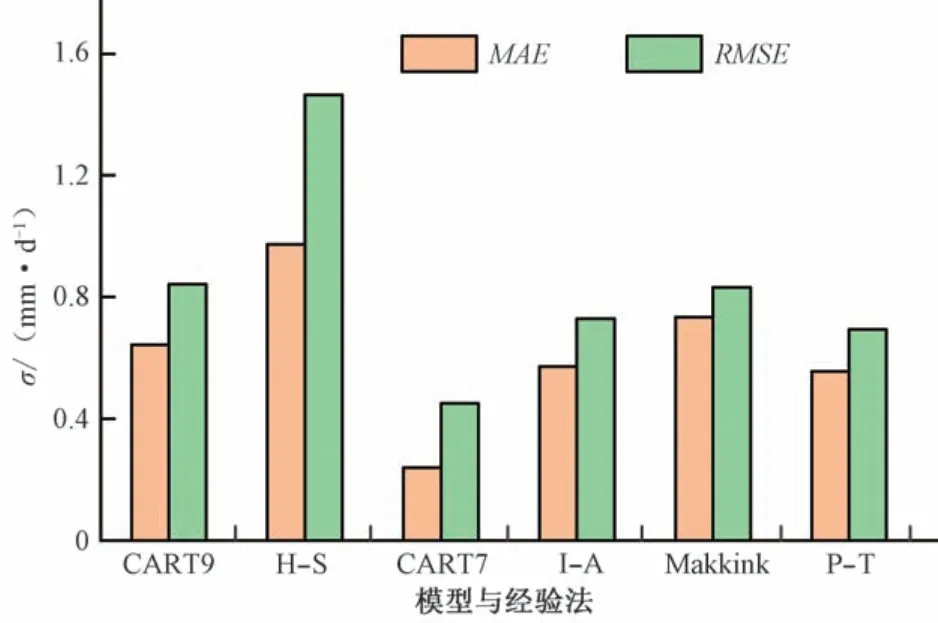
图3 决策树模型与经验法精度比较Fig.3 Comparison of accuracy between decision tree model and empirical method
当Tmax、Tmin(组合9)作为输入参数,H-S 经验法的MAE和RMSE大于CART9;当Tmax、Tmin、n(组合7)作为输入参数,P-T 经验法的精度高于I-A、Makkink 但MAE和RMSE仍大于CART7。因此在输入气象要素相同的条件下,决策树模型的模拟精度均大于经验法,由此说明机器学习模型模拟精度更高,故建议在气象要素缺失条件下优先考虑使用机器学习模型。
3 结 论
本文构建了9 种气象要素缺失组合下的7 种机器学习ET0计算模型进行模拟精度和泛化能力的对比分析,并与经验法比较,结果表明:
(1)在9 种气象要素缺失组合下,深度学习(DL)和BP神经网络(BPNN)的模拟精度均较高且有较好的泛化能力,其他模型在不同气象要素缺失组合中模拟精度和泛化能力有不同的排名,但整体效果较好的是支持向量机(SVR)。
(2)在气象要素缺失条件下,各气象要素对模型模拟参考作物蒸散量(ET0)的影响程度不同,由大到小排序依次为日照时数、最高最低气温、相对湿度、2 m 高风速(n、Tmax、Tmin、RH、u2)。
(3)与H-S、I-A、Makkink、P-T 经验法相比,机器学习模型的模拟精度均大于输入相同组合的经验法,在气象要素缺失条件下可优先考虑使用机器学习模型。
猜你喜欢
环球时报(2022-07-13)2022-07-13 17:18:39
环球时报(2022-03-14)2022-03-14 18:19:44
成都信息工程大学学报(2021年3期)2021-11-22 07:17:52
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
水利技术监督(2018年5期)2018-10-20 02:07:42
电子制作(2018年16期)2018-09-26 03:27:06
电影(2018年8期)2018-09-21 08:00:06
环境保护与循环经济(2017年1期)2017-09-26 11:44:31
现代农业科技(2016年21期)2017-03-06 04:15:09
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
