
基于R语言的作物分类研究
2022-07-28 12:59:54刁雨晴冉谷林查元源
节水灌溉 2022年7期
刁雨晴,冉谷林,查元源
(武汉大学水资源与水电工程科学国家重点实验室,武汉 430072)
0 引 言
灌区的农业生产规划情况影响着全国的粮食生产,对粮食生产具有关键的意义。作物的空间分布影响着农业生产管理方法以及农业政策的制定,快速、精准地提取灌区的作物种植信息对推进灌区生产的合理规划及农业现代化具有重要意义。
遥感是一门高效、便捷的监测技术,其检测范围广,信息多元。精准农业是农业发展的趋势,信息采集是发展精准农业的基础,将农业信息监测与遥感技术相结合,可以快速、准确的提取到所需的农业信息,目前,遥感技术已广泛地应用于农业信息的监测[1,2]。
作物分类方法根据数据源的差异又可分为基于单一遥感数据的分类和基于多源数据融合的分类。单一的遥感数据源往往受时间分辨率或空间分辨率的限制,导致其不能准确表达作物的光谱特征,从而导致分类结果较差。基于多源数据融合的分类就是把各种遥感及非遥感数据融合为一个整体的数据集,这种方法可以有效地减少由于单一遥感数据分辨率引起的“同物异谱”及“同谱异物”的现象,从而提高分类的精度。根据宋茜[3]等统计,目前农作物遥感识别的研究中基于单一数据源的分类仍占主导,但基于多源遥感数据的分类越来越多地得到应用,单一数据源在单一农作物的识别和提取方面应用较为普遍,而多源数据在农作物分类方面的应用更多。
目前,国内外已有大量基于遥感的作物分类研究。使用遥感数据进行作物分类的方法主要分为统计分析的图像分类、人工神经网络分类。基于统计分析的遥感图像分类方法又分为监督分类和非监督分类。张健康[4]等使用TM/ETM+影像数据和MODIS EVI 影像数据,采用监督分类与决策树分类相结合的人机交互解译方法,建立决策树识别模型,对黑龙港地区的主要作物进行了遥感解译;王冬利[5]等使用GF-1 多光谱数据,以归一化植被指数作为冬小麦信息提取的判别指标,运用非监督分类结合多尺度技术提取了辛集市冬小麦种植信息。张东彦[6]等基于Sentinel-2 数据,分析内蒙古自治区兴安盟扎赉特旗现代农业示范园区作物的典型植被指数时序变化特征,采用随机森林等机器学习算法对研究区主要作物进行识别。
在应用遥感数据进行作物分类的过程中,分析处理遥感数据的工具至关重要。目前的研究多使用arcGIS、ENVI 等软件,这些软件具有成熟的数据分析功能,但对于遥感数据的下载以及批量处理等方面有所欠缺。R语言是近些年来较为流行的一款开源性编程语言,其操作界面简单,可视化功能完善,语法灵活[7-9]。此外,R 语言中的包具有众多功能,用户可根据需要在R 语言中直接下载安装包,这些包涵盖了遥感数据的下载、预处理及计算分析等各个方面。由于遥感数据的下载、格式等差异,使用集成化软件处理遥感数据需要跨越多个平台操作,步骤繁琐,效率低下,而R 语言中只需安装对应功能的包并输入相应函数,即可批量完成遥感数据的处理过程,这种流程化的处理方式避免了跨平台操作,极大地提高了遥感数据的处理效率。
因此,本研究基于R 语言,采用多源遥感数据融合技术,提出了基于机器学习的作物分类方法,为实现多源遥感数据融合,提高遥感数据处理效率,提升作物分类精度提供了新思路。
1 研究区及数据
1.1 研究区概况
研究区漳河灌区位于湖北省中部,江汉平原西部,地理坐标为111°54′~112°42′E,30°23′~31°34′N,总灌区面积约5 543 km2,地势西北部高,东南部低,地形主要为平原与丘陵。灌区属长江中游亚热带季风气候区,日照充足,降水充沛,年平均气温15.6~16.3 ℃,年平均降水量804~1 067 mm。农作物以水稻、棉花、冬小麦、油菜为主,部分地区有早稻-晚稻连作、水稻-油菜轮作及小麦-棉花轮作的种植模式。漳河灌区是湖北省最重要的商品粮食基地之一,具有南方灌区的特点,以该区域作为研究区进行作物分类具有一定的代表性,见图1。

图1 漳河灌区区位图Fig.1 Zhanghe irrigation area location map
1.2 数据及预处理
本研究采用2017年12月至2018年12月的GF-1、Landsat 8 OLI 和Sentinel-2 数据。GF-1 卫星是我国于2013年4月26日发射的一颗高分辨率对地观测卫星,其波段1-4分别对应可见光波段及近红外波段,空间分辨率16 m;Landsat 8 卫星于2013年2月11日由美国航天航空局成功发射,卫星共有11 个波段,其中波段2-5为可见光波段及近红外波段,其空间分辨率均为30 m[10];Sentinel-2 卫星于2016年6月23日成功发射,其共包含12个波段,波段2-4对应可见光波段,波段8对应近红外波段,可见光及近红外波段的空间分辨率均为10 m。在研究区内根据云量小于10%筛选,GF-1全年可用数据共3期,Landsat 8 覆盖研究区需2 景影像,全年可用数据共计5 期,Sentinel-2 数据覆盖研究区需4-6 景影像,全年可用数据共4期。影像数据见表1。

表1 影像列表Tab.1 Image list
对于研究所选取的遥感数据的下载及预处理,R语言中有大量的处理遥感数据的包,这些包涵盖了遥感数据的下载、预处理及使用、输出等各个方面。getSpatialData包是一个用于下载遥感数据的包,研究所选的Landsat 8 数据及Sentinel-2 数据均可以通过该包进行下载,除此之外,getlandsat 包[11]和sen2r 包[12]也可以分别用于下载Landsat 数据和Sentinel 数据。除了下载,sen2r包还集成了针对Sentinel数据的校正、裁剪等各种构建完整的Sentinel-2 处理链所需的所有步骤,无须任何外部工具。GF-1 数据需要在中国资源卫星应用中心进行下载,但其处理可以在R 语言中完成。对于除Sentinel-2 数据外的遥感数据处理,RSToolbox 包[13]是一个专门处理遥感数据的包,可以对遥感数据进行导入、预处理、数据分析等多种处理;raster 包[14]是针对栅格对象处理的包,可以用于遥感图像的拼接、裁剪、分析计算及保存等多个功能。使用上述R 包,对研究所选取的数据进行校正、拼接,将影像数据根据研究区范围进行裁剪,导出蓝、绿、红、近红外波段,并分别按日期保存得到研究所需的遥感数据。本研究使用的R 包及其功能汇总见表2。

表2 研究中使用的R包及其主要功能介绍Tab.2 The R package used in the study and its main functions
通过查阅相关文献,访问农业信息网,并结合Google Earth 高清历史影像,可以基本掌握各种作物的种植区域、纹理和色相等特点。油菜广泛分布于漳河灌区各个区域,其花期在10月下旬,影像上呈亮黄绿色;棉花主要产于马良镇附近区域,其花期在7月下旬,花期时棉花在影像中呈黄白色;除了油菜与棉花,各种作物都有比较独特的特征,可以在影像中较好的分辨各种作物。在Google Earth 上根据目视解译选取作物样本点共3 092 个,按70%作为训练样本,30%作为测试样本,见表3。
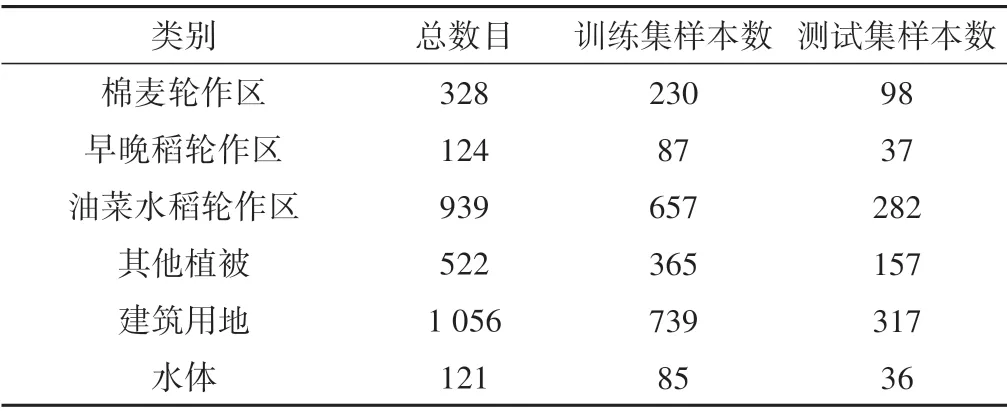
表3 地物样本数量Tab.3 Number of sample points
2 研究方法
以遥感数据为基础,分别计算各日期的归一化差值植被指数(Normalized Difference Vegetation Index,NDVI)、增强型植被指数(Enhanced Vegetation Index,EVI)及比值植被指数(Ratio Vegetation Index,RVI),并分别构造3种植被指数的时间序列数据。根据作物样本点分别提取各作物的时间序列曲线,以此作为分类依据,分别使用CART 决策树、随机森林(Random Forest,RF)、朴素贝叶斯(Naive Bayes,NB)、支持向量机(Support Vector Machines,SVM)及K 近邻(K Nearest Neighbor,KNN)算法进行作物分类,并对比分类效果。
2.1 特征选择
在遥感技术发展初期,研究人员为了探索植被与遥感光谱波段之间的关系,将各波段以不同方式组合,分别探究各种组合与植被之间的相关关系,在此过程中发现了植被在红光波段具有强吸收、在近红外波段具有高反射的特点,提出了植被指数这一概念。随着遥感技术的进一步发展,各种形式的植被指数被提出,植被指数逐步被应用在环境、生态、农业等领域[15]。在作物分类方面,因为各作物的生育期不同,光谱特征随作物生育期发生变化,植被指数也会随之变化,不同作物的植被指数变化趋势不同,因此,可以以植被指数的时间序列为分类依据来对作物进行分类。
NDVI是在作物分类中应用最广泛的植被指数,它是近红外波段与红光波段反射率之差与二者之和的比值。根据NDVI值,可以将植被从水体和土地中分类出来,NDVI值越大代表植被覆盖度越高。但以NDVI时间序列作为作物分类依据有两个缺陷:一是NDVI缺乏对大气及土壤背景干扰的处理;二是NDVI在覆盖度较好的地区饱和问题比较严重[16]。EVI和RVI可以改进NDVI的这两个缺陷。针对大气及土壤背景的干扰问题,EVI引入了蓝光波段,减少了气溶胶及土壤背景对植被指数的影响;在高植被覆盖区,RVI具有比NDVI更高的灵敏度,且RVI可以趋于无穷大,不存在饱和问题。
基于以上分析,研究选用NDVI、EVI、RVI3 种植被指数为分类指标,各指标介绍如表4所示。
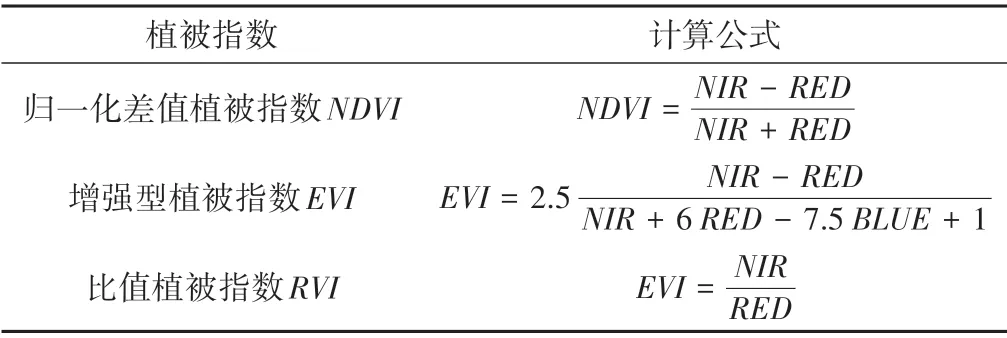
表4 植被指数介绍Tab.4 Calculation formula of vegetation index
2.2 分类方法
作物分类就是将各种作物的特征信息作为样本集,通过分类器从样本集中寻找到各类作物的共性,从而形成一种统一的分类规则。将测试样本代入该分类规则中即可获得分类的精度,将新数据代入该规则中即可得到预测分类结果。研究使用决策树、随机森林、朴素贝叶斯、支持向量机及K 近邻算法5种分类方法进行分类。
决策树是一种树形的分类模型,它在树枝节点处依据特征值对数据类别进行判断,把数据集划分为两个分支,在分支的节点处再进行类别判断,如此重复下去,将训练的数据集按级依次分割,最终将具有类似特征条件的数据划分在同一个集合内,完成对数据集的分类。本文选用决策树中最基础的CART决策树进行分类。
随机森林算法是一种基于决策树算法而改进的集成学习方法,它组合了多棵决策树,随机选择样本并对样本数据集进行重复预测,每棵决策树都会有不同的分类结果,使用多数投票法对不同分类结果进行投票整合,最终得到对数据集分类的结果。
朴素贝叶斯分类方法是以贝叶斯定理为基础理论的分类方法,是贝叶斯分类器中应用最为广泛的模型之一。它计算给定样本在各类别上的后验概率,通过概率推理的方法,将样本判定为最大后验概率所对应的类别,从而完成分类[17,18]。
支持向量机算法是一种基于统计学习理论的学习方法[19,20],该算法采用结构风险最小化的原则,求解一个能够划分训练数据类别且能使各类别之间的几何间隔最大的分类面,通过该分类面实现数据的分类。
K近邻算法是一种非参数的分类技术,它通过在分类样本集中选取与待分类样本点最相近的K 个已知类别的样本,从而将该待分类样本点划分为该类别,达到分类的效果。该算法简单且易于实现,但计算量庞大,分类速度比较慢[21]。
2.3 精度评价
研究使用总体分类精度和Kappa系数评价研究区地物分类效果。总体分类精度为正确分类的像元数占分类总像元数的比例,即混淆矩阵的对角线之和与混淆矩阵之和的比值;Kappa系数是通过把所有地表真实分类中的像元总数乘以混淆矩阵对角线的和,再减去某一类地表真实像元总数与该类中被分类像元总数之积对所有类别求和的结果,再除以总像元数的平方减去某一类地表真实像元总数与该类中被分类像元总数之积对所有类别求和的结果所得到的[22]。
使用用户精度(User’s Accuracy,UA)、生产者精度(Producer’s Accuracy,PA)评价各类地物分类效果。用户精度表示某一类地物正确分类的像元数与该类别地物实际总像元数的比值;生产者精度表示某一类地物正确分类的像元数与整个分类过程中分类到该类别的像元数的比值[23]。
3 结果与分析
3.1 光谱时序特征分析
分别计算漳河灌区的NDVI、EVI、RVI,提取各作物样本点的植被指数特征值,剔除异常值点,并按类别求取均值,得到漳河灌区主要地物的NDVI、EVI、RVI时间序列曲线见图2~图4。
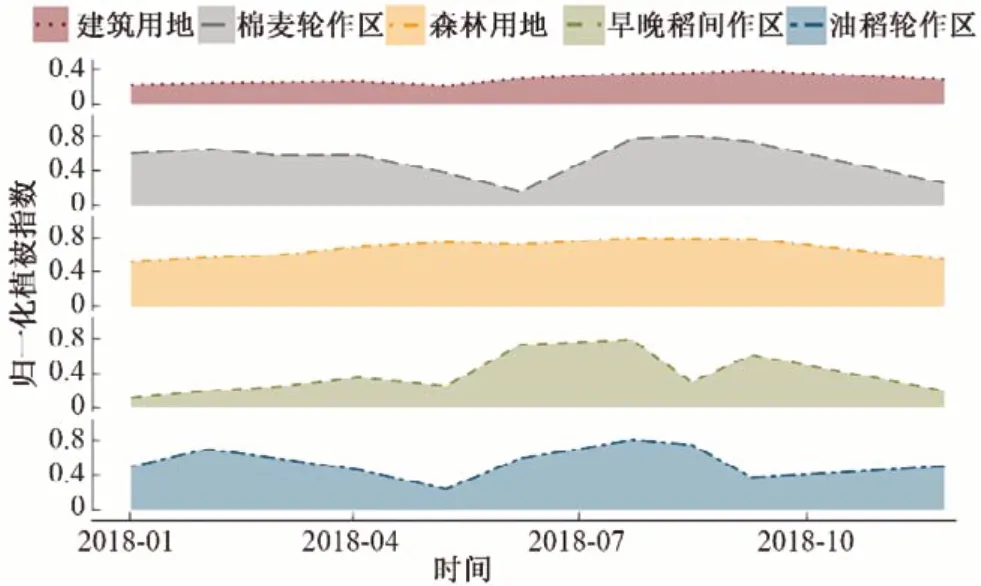
图2 各作物NDVI时序变化曲线Fig.2 Temporal changes of NDVI of all crops
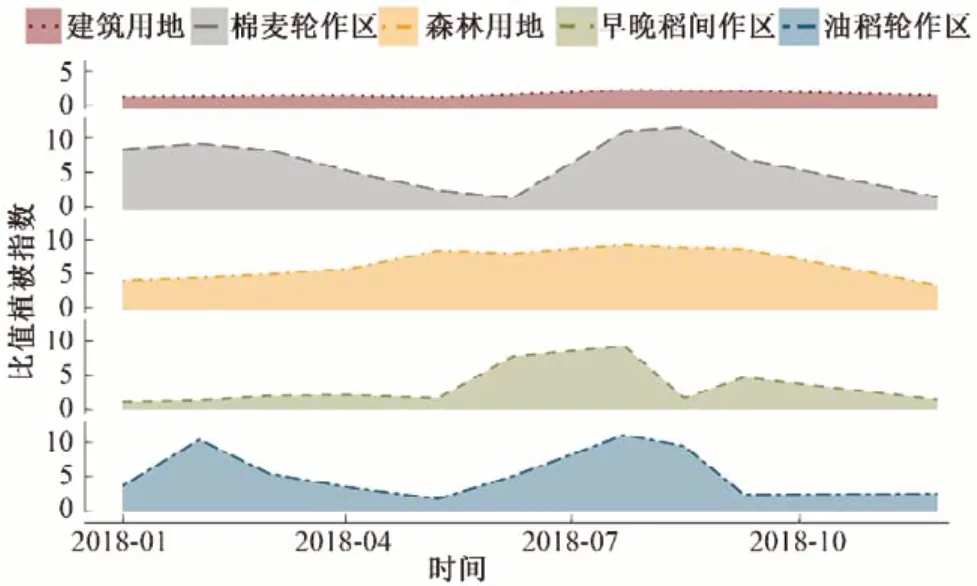
图3 各作物RVI时序变化曲线Fig.3 Temporal changes of RVI of all crops

图4 各作物EVI时序变化Fig.4 Temporal changes of EVI of all crops
由图2~图4可以看出,建筑用地的NDVI、EVI、RVI值在全年都处于很低的水平,波动不大。森林的年内变化不大,其NDVI值全年都处于较高水平,均大于0.5,而RVI在高覆盖区具有比NDVI更高的灵敏度,因此在夏季茂密的森林地区,RVI值呈上升趋势,并在8月达到峰值。
棉花-小麦轮作区、早稻-晚稻间作区、水稻-油菜轮作区的植被指数时序曲线均具有明显的双峰特征,符合轮作区的植被指数变化规律。其中,棉花-小麦轮作区的NDVI曲线的第一个峰值在3月,对应的是小麦的返青及拔节,第一个谷值在6月,对应的是小麦的收获,第二个峰值在6月,对应的是棉花开花;早稻-晚稻间作区的NDVI曲线自3月下旬早稻播种后缓慢降低,5月中旬早稻分蘖期NDVI值达到第一个谷值,然后NDVI值开始增加,在6月下旬早稻抽穗期达到第一个峰值,7月下旬早稻收获,在8月中旬晚稻分蘖期时NDVI曲线达到第二个谷值,在9月中旬晚稻抽穗期达到第二个峰值。水稻-油菜轮作区的NDVI曲线第一个峰值是在3月油菜开花期,第二个峰值在7月中稻抽穗期。各轮作区的EVI、RVI时序曲线的趋势均与NDVI时序曲线的趋势基本相同,但RVI的变化幅度更剧烈。
3.2 分类方案及分类过程
将地物分类过程根据分类数据分成4 个方案,方案1、2、3分别以NDVI、RVI、EVI时间序列为分类数据,方案4采用按顺序合成的3种植被指数时间序列为分类数据。每种方案均使用CART 决策树、朴素贝叶斯、支持向量机、K 近邻、随机森林五种不同的算法为分类方法,对漳河灌区地物进行分类预测。
R 语言中有可以完成作物分类及验证的包。例如,caret包[24]可以训练决策树、朴素贝叶斯分类模型,randomForest 包可以训练随机森林算法分类模型,e1071 包可以训练支持向量机算法分类模型,class包[25]可以训练K近邻算法分类模型。对于训练好的模型,将测试集数据去除类别信息,使用predict函数进行预测,并调用confusionMatrix 函数计算分类的混淆矩阵、总体精度值、Kappa值、用户精度值及生产者精度值等指标。将整理好的植被指数时序图像作为预测数据,使用predict函数,即可得到研究区域的作物分类图见图5。
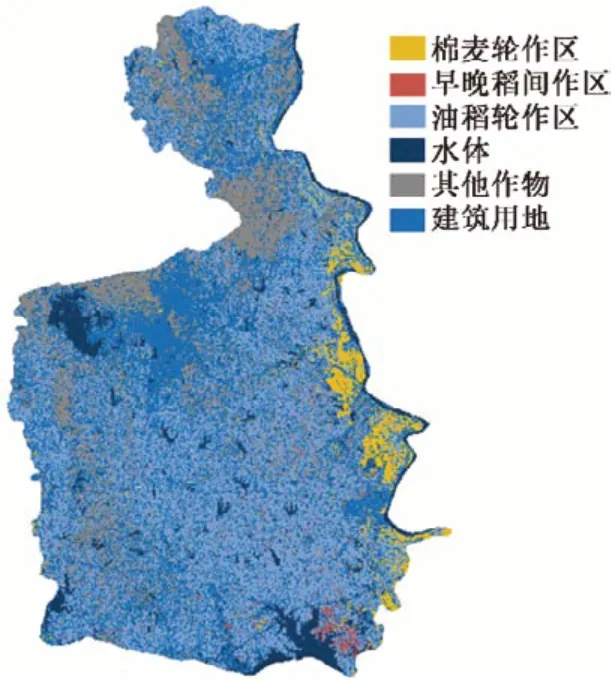
图5 漳河灌区地物分类预测图Fig.5 Classification forecast map of Zhanghe Irrigation area
3.3 分类结果与精度评价
图5为使用随机森林算法对NDVI、RVI、EVI3 种植被指数混合数据进行分类得到的漳河灌区地物分类预测图。从图5可以看出,漳河灌区主要种植作物有水稻、油菜、棉花、小麦。其中水稻-油菜轮作的种植方式在漳河灌区最为普遍,分布较广;而棉花-小麦轮作的种植方式主要集中在灌区东部临近汉江的地带;早稻-晚稻间作的种植模式在灌区分布较少,主要集中在灌区东南部靠近长湖的地带。
使用训练好的模型对测试数据进行分类预测,并调用confusionMatrix 函数,整理运行后的结果,得到分类总体精度值、Kappa 系数值见表5,各地物的用户精度及生产者精度见图6~图7。

表5 分类精度统计Tab.5 Classification accuracy statistics
根据表5,对方案4 采用随机森林算法对灌区进行地物分类的分类效果最好,总精度达96.96%,Kappa 系数为0.948;对方案3 采用CART 决策树对灌区进行分类的分类效果最差,总精度仅为81.52%,Kappa 系数仅为0.662。对比同一方案中不同分类器的分类效果,随机森林算法的分类效果最好,K近邻算法、支持向量机算法及朴素贝叶斯算法次之,CART 决策树分类器的效果最差,其中,随机森林算法的分类平均总精度达95.6%,K 近邻、支持向量机及朴素贝叶斯算法的分类平均总精度值在93.2%~94.5%之间,CART 决策树分类的平均总精度仅有83.2%。对比同一分类器下不同方案的分类效果,方案4 效果最好,方案1 及方案2 的平均总精度值及Kappa 系数略低于方案4,但差别不大,方案3 的分类效果最差,平均总精度值比其他方案低2%左右。
根据图6~图7对比各方案中地物的用户精度值及生产者精度值,水体在各种分类方案下的用户精度值均为100.0%,生产者精度均大于97.0%,其分类结果最可靠,分类效果最好;油菜-水稻轮作区、棉花-小麦轮作区、其他植被区及建筑用地的分类可靠性及效果比水体略差;早稻-晚稻间作区的分类结果最不可靠,分类效果最差。结合图2~图4,水体、建筑及其他植被区的植被指数曲线具有明显特征,易于从其他地物中区分出来;油稻轮作区及棉麦轮作区的植被指数时序曲线虽有相同的双峰趋势,但达到峰值的时间不同,因此也利于区分;而早晚稻间作区由于面积较小,样本点数目少,且植被指数曲线在夏季达到峰值的时间与油稻轮作区基本相同,容易错分进油稻轮作区,因此分类效果不好。
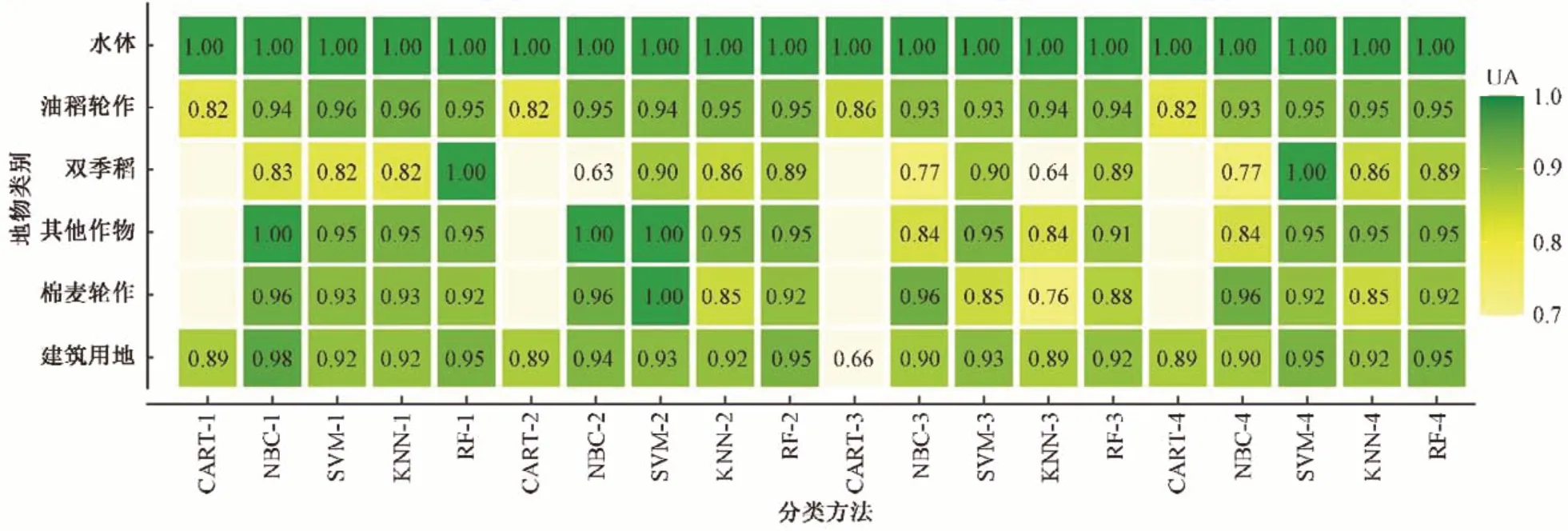
图6 各地物分类用户精度Fig.6 User accuracy of local object classification

图7 各地物分类生产者精度Fig.7 Producer accuracy of local object classification
综上所述,对于分类器,使用随机森林分类器的分类效果最好,使用CART 决策树的分类效果最差;对于分类数据,方案4 的数据分类效果最好,方案3 的数据分类效果最差,但综合考虑工作量与精度提升之间的关系,使用方案1的数据进行分类与方案4差别不大;对于地物分类结果,水体的分类结果最可靠,双季稻区域的分类结果最差。
4 结 论
本研究以R 语言为工具,分别基于GF-1数据、Sentinel-2数据及Landsat 8 数据构建的湖北省漳河灌区NDVI、EVI、RVI时间序列,采用决策树、支持向量机、K近邻算法、朴素贝叶斯算法及随机森林5种分类器对研究区地物进行分类,主要得到以下结论:
(1)以R 语言为工具,实现了遥感数据的下载、预处理、分析及可视化过程,避免了跨平台数据处理,简化了遥感数据的处理过程,验证了R 语言在遥感数据处理过程中的适用性与优越性。
(2)采用CART 决策树、朴素贝叶斯、支持向量机、K 近邻算法及随机森林模型对研究区地物分类。结果表明,随机森林算法分类效果最好,平均总精度达到95.60%;CART决策树算法分类效果最差,平均总精度仅83.15%。
(3)分别使用NDVI、RVI、EVI及三者组合的时间序列作为分类数据,对比4种方案的分类效果,结果表明,使用组合数据分类的效果最好,单独使用EVI时间序列的分类效果最差,单独使用NDVI作为分类数据进行分类与使用组合数据分类的精度差别不大。综合考虑工作量与精度提升之间的关系,使用NDVI时间序列为分类数据进行分类最佳。
(4)使用用户精度、生产者精度对各地物分类效果进行评价,结果表明,水体分类效果最好,双季稻分类效果最差。
本研究的主要优势在于使用R 语言简化了遥感数据的处理及分析过程,为提高遥感数据处理效率提供了新思路。同时,对湖北省漳河灌区的作物进行分类,为当地农业布局提供了数据支撑。但研究还存在一些不足之处需要改进,目前研究表明,同时考虑地物的光谱特征和纹理特征可以极大提高分类的精度,后续研究应在本研究的基础上考虑使用面向对象的分类方法对本研究进行改进。
猜你喜欢
今日农业(2020年20期)2020-12-15 15:53:19
今日农业(2020年17期)2020-12-15 12:34:28
世界农药(2019年4期)2019-12-30 06:25:10
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
水土保持研究(2018年5期)2018-10-12 05:29:52
电子制作(2018年16期)2018-09-26 03:27:06
中国农业信息(2018年2期)2018-07-28 08:02:10
上海农业学报(2016年2期)2016-10-27 00:49:58
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
西藏科技(2015年1期)2015-09-26 12:09:29
