黄文专
(肇庆医学高等专科学校, 口腔医学院, 广东, 肇庆 526020)
0 引言
网络音乐信息与用户提供的偏好信息相结合能够在用户查询网络音乐的过程中扩大音乐搜索范围,但现有的系统查询方式较为单一,查询结果的排序也难以满足用户需求[1-3]。为此,本文提出了一种基于深度学习的网络音乐检索系统,在不同机制下进行查询结果的初排序和重排序,通过深度排序学习的方式优化最终的查询结果,在很大程度上提升了用户的使用体验。
1 网络音乐检索系统架构
本文所设计的网络音乐检索系统主要包括初排序与重排序两个模型,系统的结构和工作流程如图1所示。
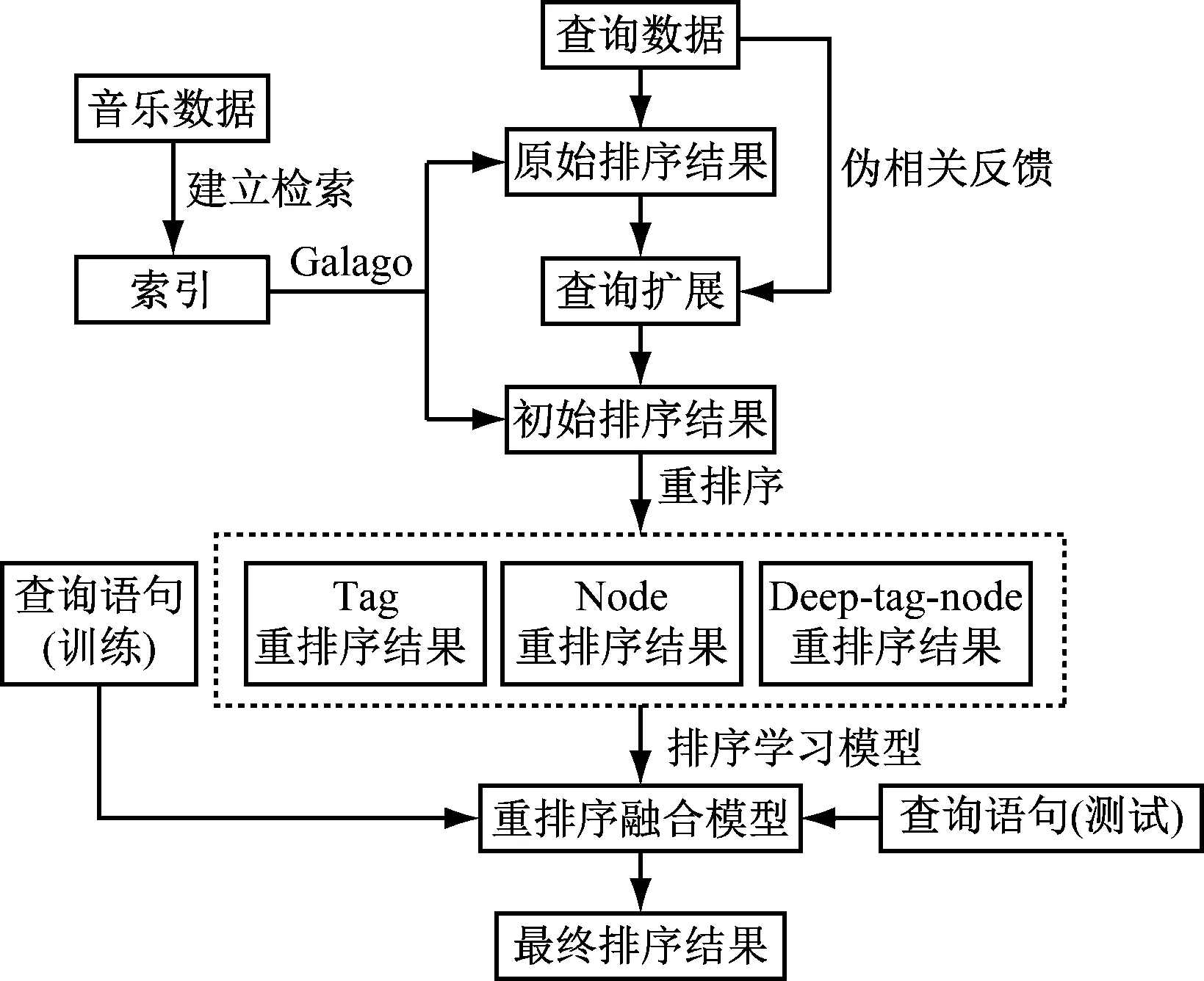
图1 基于深度学习的网络音乐信息检索系统
用户提出查询请求后,系统根据用户输入的原始内容通过Galago搜索引擎进行首次查询,得到网络音乐信息的原始排序结果,接下来利用伪相关反馈技术扩展查询内容并以此为基础进行二次查询,从而得到网络音乐信息的初排序结果;对初排序结果中的社会信息进行特征提取,基于不同的特征或多种特征的不同组合选择重排序机制;通过排序学习方法创建重排序融合模型,在充分融合各种排序结果的条件下输出最优的排序结果。
2 深度学习方法及技术实现
2.1 数据预处理
在用户进行网络音乐信息查询的过程中,系统会根据用户输入的查询内容和网络音乐信息中关键词词频对输出的结果进行排序,在系统启动搜索程序之前,需要同时对查询数据和音乐数据进行预处理,即通过建立信息丰富的索引来提高查询结果的质量[4]。网络中的部分音乐为数字形式,所以需要将其转换为统一的文本信息[5]。本文采用Galago搜索引擎根据文本信息的具体内容分别建立四种索引:整体数据索引、元数据(作者提供的关键词)索引、内容(音乐内容概括)索引、社会信息(用户的评论及为其设定的标签)索引。
2.2 伪相关反馈技术
为了获得更多的查询结果,可以在用户输入的初始查询内容的基础上选择与关键词意义相近的扩展词,同输入内容相结合组建扩充后的查询词句,以此来提高查询内容的丰富性、准确性和完整性[6]。伪相关反馈技术能够有效实现查询扩展,且通过该技术所获得的扩展词是对查询内容最大化扩展的结果[7],在基于用户的原始查询获得首批网络音乐信息后,在排序靠前的信息中提取扩展词来进一步丰富查询内容,可见扩展词的数量与准确性是由这部分网络音乐信息所决定的。
伪相关反馈技术有一个假定的前提,即根据用户原始查询内容所获得的查询结果中排序为1~k的网络音乐信息都确实与用户输入的关键词句相关,以此为基础实现查询结果初排序的流程[8]如下。
步骤1 通过用户输入的原始内容对查询结果进行首次排序,依据内容相关性的强弱选出排序靠前的k个网络音乐信息。
步骤2 从以上k个网络音乐信息中提取内容关键词,将出现次数最多的前w个词作为与用户输入相关的扩展词。
步骤3 根据用户输入关键词与扩展词相结合组建成的新查询词句进行二次查询,获得新的查询结果。
步骤4 利用Galago搜索引擎的查询似然模型对以上结果进行初排序,排序依据即相关性采用下式进行计算[9]:
(1)
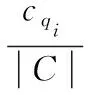
2.3 重排序机制
对于本文所设计的检索系统,为了扩大查询目标的范围,首先假定与用户所偏好的音乐类型相近的音乐也可一并视为用户偏好的音乐,以此为前提的重排序可通过下式进行:
scorer(Q,D)=a×score(Q,D)+(1-a)e(D)
(2)
式中,score(Q,D)代表初排序评分;e(D)代表相似音乐发挥作用的大小,其数值通过相似度加权进行计算,即:
(3)
式中,sim(Di,Dj)代表初排序结果中第i名与第j名音乐的相似程度。Q为音乐的数量集。
若以网络音乐数据中单个域的出现次数作为重排序的依据,那么两首歌曲之间相似度的计算方法为
Sim(Di,Dj)=cos
(4)
式中,vecDi代表排名为i的音乐的特征向量;vecDj代表排名为j的音乐的特征向量。若以组合特征的相似度作为重排序的依据,那么基于初排序结果的相似度计算方法[10]为
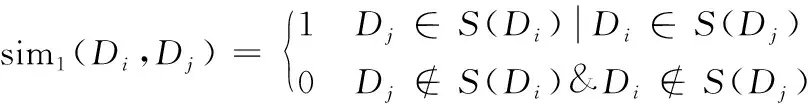
(5)
式中,S(Di)代表与Di类型相似的音乐。对于式(5)的计算结果,若S(Di)中包含初排序结果中的音乐,那么该音乐的标记值为1,反之则为0,由此可通过相似度的对比得到重排序的结果。在此基础上,本文所建立的重排序机制为DTN、ITN、DT、IT、TN、T、N、I、D,其中T、N、I、D分别代表用户标签、浏览节点、相似音乐、相似音乐的相似音乐。
在以上多种重排序机制下所获取的排序结果需要经历一个有机融合的过程来保证排序的准确性,而当前排序融合多采用人工或半人工的方式进行,使得最终的结果极容易产生偏差,因此本文采用基于pointwise的深度排序学习方法来获得最优排序结果。Pointwise主要用于单一文档的处理,它能够将文档以特定的方式转换为特征向量,从而以机器学习模式下回归或分类的方式进行排序。在排序学习的过程中,以音乐的多个不同排序结果为特征向量,以音乐在最优排序结果中的排名为训练目标,获取多个排序结果与最优排名的映射关系,作为选择最佳重排序机制的依据。本文引入随机森林模型实现排序学习在重排序过程中的应用。
3 系统应用测试
3.1 测试参数
本文选取HIFIVE网络平台的音乐查询结果建立实验样本集,平台数据库中保存了280万首音乐的数据,每一条数据都包含丰富的内容信息和用户添加的各种社会信息,这些信息可划分为2种标签域,一是等音乐内容信息,二是<similarproducts><tags>等社会信息。从平台数据库中筛选出2016~2019年期间每年一定数量的查询记录构建系统的训练集和测试集,其各自的数据构成如表1所示。</p><p><img src="https://img.fx361.cc/images/2022/1204/875b884de41bdc8c6f63a1f96cebe7fd07804456.webp"/></p><p>表1 实验数据集</p><h3>3.2 测试结果分析</h3><p>本次测试选用排名前10的查询结果的准确性DB-CF算法平台[5]作为系统性能的评价指标。选取2019年的平台查询记录分别针对系统的初排序、重排序以及特征融合3个模型的不同参数进行实验。</p><p>首先对伪相关反馈的相关参数的不同设定值进行比较,实验结果如表2所示。Initial代表首次排序,PRF代表初排序,由表2中的数据可见在从原始排序结果前20名中提取15个关键词的条件下能够得到最优的初排序结果。</p><p><img src="https://img.fx361.cc/images/2022/1204/eeb6f0b95bcaeef5526c788a8d46d77e70f6bcaa.webp"/></p><p>表2 初排序结果</p><p>接下来对重排序过程中所需设定的社会信息占比a的不同设定值进行比较,在表1数据集中进行初排序和全部特征组合的重排序,实验结果如表3所示。</p><p><img src="https://img.fx361.cc/images/2022/1204/87479a984400e2acbe0dd8670da68347014a49ac.webp"/></p><p>表3 不同a值条件下的重排序结果</p><p>由表3中的数据可见,所有重排序结果的准确性都高于初排序结果,其中以tag为重排序机制的重排序结果相较于初排序结果在训练集与测试集中的准确率分别高出了6.17%和9.30%。</p><p>针对基于排序学习的重排序结果进行实验,以不同重排序机制为训练的输入,以训练集中的现实排序结果为标准,通过改变随机森林模型参数组合方式进行数据集训练,实验结果如表4所示。</p><p><img src="https://img.fx361.cc/images/2022/1204/313d72e28d41cda84567e29e022caf455d38885e.webp"/></p><p>表4 基于排序学习的重排序结果</p><p>由表4中的数据可见,利用排序学习方法将不同重排序结果进行有机融合,能够进一步提高重排序结果的准确性,其中通过排序学习使tag(T)重排序机制的准确率提高了13%,由此可见,本文所设计的系统能够大幅提高网络音乐信息查询的准确性。</p><h2>4 总结</h2><p>为了切实提高网络音乐查询结果的质量,本文提出并设计了一种基于深度学习的网络音乐信息检索系统,利用伪相关反馈技术初步扩大了网络音乐的搜索范围并获得初排序结果,根据用户在查询过程中生成的社会信息建立了重排序机制,最终通过排序学习方法实现了不同重排序结果的融合,由此得到了最优的排序结果。系统测试结果表明,该系统在很大程度上提高了网络音乐信息查询的准确性,为用户提供了良好的使用体验。</p></p>
<!-- <div class="article_pdf"><a href="https://cimg.fx361.com/kkb.apk">查看pdf文档请下载app</a></div>--><div class="article_love">
<div class="title">猜你喜欢</div>
<div class="article_love_keyword"><span><a href="/tags/c/6/dbcffdf31e86d2d8/1.html" target="_blank">排序</a></span><span><a href="/tags/3/6/50e6378559d22817/1.html" target="_blank">准确性</a></span><span><a href="/tags/2/7/bd0db0ad240cc83b/1.html" target="_blank">内容</a></span></div>
<div class="article_love_news"><dd><a class="txt_title" href="/page/2022/0811/10798976.shtml" target="_blank" title="CT及超声在剖宫产瘢痕部位妊娠中的诊治价值及准确性">CT及超声在剖宫产瘢痕部位妊娠中的诊治价值及准确性</a><div class="rsorc"><a href="/bk/xdyqyyl/20222.html" class="ly" title="现代仪器与医疗(2022年2期)">现代仪器与医疗(2022年2期)</a><span class="txt">2022-08-11</span></div></dd><dd><a class="txt_title" href="/page/2022/0621/11646577.shtml" target="_blank" title="内容回顾温故知新">内容回顾温故知新</a><div class="rsorc"><a href="/bk/kexuedz/202211.html" class="ly" title="科学大众(2022年11期)">科学大众(2022年11期)</a><span class="txt">2022-06-21</span></div></dd><dd><a class="txt_title" href="/page/2022/0513/10309510.shtml" target="_blank" title="CT诊断中心型肺癌的准确性及MRI补充诊断的意义">CT诊断中心型肺癌的准确性及MRI补充诊断的意义</a><div class="rsorc"><a href="/bk/zgdxbldq/202212.html" class="ly" title="中国典型病例大全(2022年12期)">中国典型病例大全(2022年12期)</a><span class="txt">2022-05-13</span></div></dd><dd><a class="txt_title" href="/page/2021/0716/10968625.shtml" target="_blank" title="浅谈如何提高建筑安装工程预算的准确性">浅谈如何提高建筑安装工程预算的准确性</a><div class="rsorc"><a href="/bk/jcfzdx/202110.html" class="ly" title="建材发展导向(2021年10期)">建材发展导向(2021年10期)</a><span class="txt">2021-07-16</span></div></dd><dd><a class="txt_title" href="/page/2021/0512/10845714.shtml" target="_blank" title="作者简介">作者简介</a><div class="rsorc"><a href="/bk/mjmz/20214.html" class="ly" title="名家名作(2021年4期)">名家名作(2021年4期)</a><span class="txt">2021-05-12</span></div></dd><dd><a class="txt_title" href="/page/2020/0508/8981522.shtml" target="_blank" title="恐怖排序">恐怖排序</a><div class="rsorc"><a href="/bk/kpthxbrj/20201.html" class="ly" title="科普童话·学霸日记(2020年1期)">科普童话·学霸日记(2020年1期)</a><span class="txt">2020-05-08</span></div></dd><dd><a class="txt_title" href="/page/2019/0110/4655314.shtml" target="_blank" title="节日排序">节日排序</a><div class="rsorc"><a href="/bk/xtsynjysyzh/20192.html" class="ly" title="小天使·一年级语数英综合(2019年2期)">小天使·一年级语数英综合(2019年2期)</a><span class="txt">2019-01-10</span></div></dd><dd><a class="txt_title" href="/page/2016/0916/11648596.shtml" target="_blank" title="主要内容">主要内容</a><div class="rsorc"><a href="/bk/taishen/20162.html" class="ly" title="台声(2016年2期)">台声(2016年2期)</a><span class="txt">2016-09-16</span></div></dd><dd><a class="txt_title" href="/page/2006/0525/5788474.shtml" target="_blank" title="谈书法作品的完整性与用字的准确性">谈书法作品的完整性与用字的准确性</a><div class="rsorc"><a href="/bk/zgxwjysx/20065.html" class="ly" title="中国校外教育(上旬)(2006年5期)">中国校外教育(上旬)(2006年5期)</a><span class="txt">2006-05-25</span></div></dd></div>
</div><div class="other_pel mt80">
<p class="fl"><a href="/bk/wxdnyy/20226.html" target="_blank"><img src="https://img.fx361.cc/images/2022/1204/6c2ebd29e832520a27797f8aaf31f67a24177e62.webp" alt=""></a><span class="p1"><a href="/bk/wxdnyy/" target="_blank">微型电脑应用</a></span><span class="p2"><a href="/bk/wxdnyy/20226.html" target="_blank">2022年6期</a></span></p>
<dl class="fl"><dt>微型电脑应用的其它文章</dt><dd><a href="/page/2022/0726/12302854.shtml" title="水平井井轨迹三维可视化技术研究">水平井井轨迹三维可视化技术研究</a></dd><dd><a href="/page/2022/0726/12303596.shtml" title="基于FPGA的智能行车检测系统">基于FPGA的智能行车检测系统</a></dd><dd><a href="/page/2022/0726/12304149.shtml" title="基于编程的快速移动光标方法研究">基于编程的快速移动光标方法研究</a></dd><dd><a href="/page/2022/0726/12463859.shtml" title="基于生成对抗网络的遥感影像场景分类">基于生成对抗网络的遥感影像场景分类</a></dd><dd><a href="/page/2022/0726/12463958.shtml" title="基于阈值的混合电网开关故障诊断方法">基于阈值的混合电网开关故障诊断方法</a></dd><dd><a href="/page/2022/0726/12464012.shtml" title="基于模糊数学理论的实时分布对象编程方法">基于模糊数学理论的实时分布对象编程方法</a></dd></dl>
</div></div>
</div>
</div>
<div class="sidebarR">
<!-- tab选项卡 -->
<div class="tab01 mb20"><div class="tabArrow"></div><div class="tabItem"><div class="tabTit"><a href="#">杂志排行</a></div>
<div class="tabCont"><ol><li><p class="row01"><span class="topNum">1</span><a href="/bk/hzjjykj/202413.html" class="row01a">《合作经济与科技》</a><span class="row01_fr"><a href="/bk/hzjjykj/202413.html">2024年13期</a></span></p></li><li><p class="row01"><span class="topNum">2</span><a href="/bk/hyyjk/202410.html" class="row01a">《婚育与健康》</a><span class="row01_fr"><a href="/bk/hyyjk/202410.html">2024年10期</a></span></p></li><li><p class="row01"><span class="topNum">3</span><a href="/bk/swyzhsby/20247.html" class="row01a">《思维与智慧·上半月》</a><span class="row01_fr"><a href="/bk/swyzhsby/20247.html">2024年7期</a></span></p></li><li><p class="row01"><span class="topNum">4</span><a href="/bk/tckjyjs/202311.html" class="row01a">《陶瓷科学与艺术》</a><span class="row01_fr"><a href="/bk/tckjyjs/202311.html">2023年11期</a></span></p></li><li><p class="row01"><span class="topNum">5</span><a href="/bk/zgsr/20247.html" class="row01a">《中国商人》</a><span class="row01_fr"><a href="/bk/zgsr/20247.html">2024年7期</a></span></p></li><li><p class="row01"><span class="topNum">6</span><a href="/bk/jsbl/20244.html" class="row01a">《教师博览》</a><span class="row01_fr"><a href="/bk/jsbl/20244.html">2024年4期</a></span></p></li><li><p class="row01"><span class="topNum">7</span><a href="/bk/sdjy/20246.html" class="row01a">《师道·教研》</a><span class="row01_fr"><a href="/bk/sdjy/20246.html">2024年6期</a></span></p></li><li><p class="row01"><span class="topNum">8</span><a href="/bk/zgdwmy/20246.html" class="row01a">《中国对外贸易》</a><span class="row01_fr"><a href="/bk/zgdwmy/20246.html">2024年6期</a></span></p></li><li><p class="row01"><span class="topNum">9</span><a href="/bk/bl/20246.html" class="row01a">《伴侣》</a><span class="row01_fr"><a href="/bk/bl/20246.html">2024年6期</a></span></p></li><li><p class="row01"><span class="topNum">10</span><a href="/bk/jjjsxzxx/20246.html" class="row01a">《经济技术协作信息》</a><span class="row01_fr"><a href="/bk/jjjsxzxx/20246.html">2024年6期</a></span></p></li></ol> </div></div>
</div>
</div>
<div class="clr"></div>
</div>
</div>
<!--div class="advertisement">
</div-->
<div class="footer">
<p><a href="/aboutus/index.html">关于参考网</a></p>
</div>
<script>
if ('serviceWorker' in navigator) {
window.onload = function () {
navigator.serviceWorker.register('/sw.js');
};
}
</script>
<script type="text/javascript" src="https://s1.pstatp.com/cdn/expire-1-M/jquery/3.4.0/jquery.min.js"></script>
<script type="text/javascript" src="https://s1.pstatp.com/cdn/expire-1-M/sticky-kit/1.1.3/sticky-kit.min.js"></script>
<script type="text/javascript" src="https://s1.pstatp.com/cdn/expire-1-M/jquery.lazyload/1.9.1/jquery.lazyload.js"></script>
<script type="text/javascript">
document.write('<script src="https://img.fx361.cc/cdn/w/index_cc.js"><\/script>');
</script>
</body>
</html>
