
基于深度主动学习的中文电子病历命名实体识别
2022-07-26 09:04李梦翔尤丽珏
微型电脑应用 2022年6期
李梦翔, 尤丽珏
(1.中国福利会国际和平妇幼保健院, 上海 200030;2.上海交通大学医学院附属瑞金医院, 卢湾分院, 上海 200020)
0 引言
中文电子病历(Electronic Medical Records,EMRs)作为一种内容丰富的数据,对于临床研究的开展有着重要作用。研究表明,EMRs的使用促进了疾病分析、危险因素评估等工作的开展[1]。然而,EMRs通常存储以非结构化的文本,带给EMRs研究使用的巨大障碍[2]。因此,发展EMRs的结构化方法,对于提升该医疗记录的可用性、激发其在临床研究中的价值有着重要作用。
近年来,结合深度神经网络(Deep Neural Networks,DNN)的命名实体识别(Named Entity Recognition,NER)是EMRs结构化研究的里程碑方法。通过递归、卷积等单元的使用,能实现EMRs结构信息抽取的良好表现[2]。然而,DNN是数据驱动方法,高性能模型的建立离不开准确、大量标注的使用,而上述条件的取得伴随着高额成本[3-4]。
主动学习是一种从未标注数据集找出有用样本提升标注的方法[5],在保持模型性能的同时能降低标注数据量,对DNN的成本节约有着巨大作用。对应不同场景,基于池采样的方法通过整个数据集的评估、排名选出最佳查询样本,具有广泛应用。按不同选择策略,基于不确定性采样的方法能将最易混淆、信息量最大的样本用于标注,在主动学习的相关应用中有着良好效果。
该研究结合深度主动学习,给出了一种高资源利用、鲁棒的中文电子病历NER方法。具体以不确定性采样为样本标注策略,经数据选择、专家标注等多次循环操作,确定NER任务的DNN训练样本。该研究以冠心病患者的EMRs为研究对象,结合数据特点,突出深度主动学习在某项疾病EMRs中的应用效果。
1 相关工作
主动学习在文本识别领域获得广泛关注。Shusen等[5]使用受限玻尔兹曼机构建主动学习模型,用于数据集的无监督训练。Chang等[6]提出透明批量主动采样框架,可以使采样过程对标注噪声更加鲁棒。
对于深度主动学习,Yao等[7]研究了基于CNN主动学习的句子分类方法;Shen等[8]研究了基于CNN+LSTM的深度主动学习方法,获得小样本集的较好NER性能。在医疗应用方面,Shardlow等[9]提出了面向神经科学的NER方法,只需很少训练数据即可得到出色医疗信息识别精度。然而,基于Bi-LSTM+CRF的主动学习在冠心病中文EMRs的NER研究还未有广泛报道。
2 方法
2.1 模型框架
模型框架如图1所示,共含两个部分。

图1 中文电子病历命名实体识别的框架
①使用深度主动学习,从大量未标记中文EMRs样本集中选出有用样本用于数据标注;②搭建包含词嵌入输入层和条件随机场(Conditional Random Field,CRF)输出层的双向长短期记忆网络(Bi-LSTM)结构,用于冠心病中文EMRs的结构化信息抽取。
2.2 深度主动学习
深度主动学习旨在结合主动学习降低标注量及深度学习特征提取的能力。图1展示了该方法在中文EMRs中NER任务框架,相应计算如下:①使用小部分标注样本集L0,初始、预训练DNN模型参数θ;②使用DNN对未标注样本池U提取特征;③基于查询策略选择样本,并让专家手动标注;④更新标签训练集L和未标注样本池U;⑤回到步骤2,直到预定条件。
深度主动学习计算,可描述为优化问题。假设n、m样本数量的未标注数据集和已标注数据集为Un={χ,γ}、Lm={X,Y},该方法通过DNN映射f:χ→γ的查询策略Q完成标注样本选择。给定样本示例x∈X、参数θ,该方法通过标记样本损失最小化优化参数:
argminEL[l(f(x;θ),y)]
(1)
其中,f(x;θ)是待选标签分数向量,EL是覆盖已标注数据集的期望,l是损失函数。对于离散随机变量Y,主动学习不确定性可由令牌熵(Token Entropy,TE)表示:
(2)
其中,T是x的长度,z覆盖所有标签,P(yt=z,θ)是位置t处标签的边际概率,表示计算出结果yt=z所需的信息。
2.3 分类模型
分类模型为Bi-LSTM+CRF,如图2所示。Bi-LSTM通过文本向前和向后两个方向的文字训练,使得过去上下文(左)和将来上下文(右)均可访问。该网络LSTM的存储单元由输入门、忘记门和输出门构成,以调节进、出存储器信息。对于以词序列向量组x1,x2,…,xm为输入、h1,h2,…,hm为输出的文本识别,当存储单元t-1时刻的状态为ct-1时,输入门it、忘记门ft和输出门ot的更新公式如下:
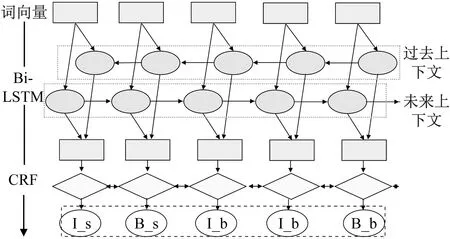
图2 命名实体识别的分类模型
it=σ(Wiht-1+Uixt+bi)
ft=σ(Wfht-1+Ufxt+bf)
(3)
ot=σ(Woht-1+Uoxt+bo)
新的LSTM状态ct和输出ht如下:
ct=fiΘct-1+itΘtanh(Wcht-1+Ucxt+bc)
ht=otΘtanh(ct)
(4)
其中,σ是sigmoid函数;Θ为元素乘积;xt和ht分别表示t时刻输入、输出向量;U、W和b分别是不同门输入向量的权重矩阵、隐藏层的权重矩阵及偏置向量。
Bi-LSTM后接CRF,用于更好捕获文本信息。对于输入文本向量组X=x1,x2,…,xm。当输出序列Y=y1,y2,…,ym时,分数计算如下:
(5)
其中,pi,yi为句中i单词对应标签yi的分数,Ayi,yi+1代表从标签yi到标签yi+1的转换分数。
3 实验
3.1 数据设置
实验数据含700份冠心病患者的中文EMRs,其中的私人信息均已移除。随机选择其中600份为主动学习样本池,其中1/2样本用于后续NER任务的模型训练。每次样本选择比例记为1/c(c=4,2对应后续实验TE1和TE2),随机选择拟训练样本的1/c数据为初始样本L0,其中的1/c数据为每次经DNN特性提取后策略选择的样本。NER任务将样本数据按3∶1设置训练、测试集,标注包括症状、疾病、检查和治疗4个类别,标注参照UMLS语义类型进行人工添加,如表1所示。

表1 实验数据集设置情况
3.2 模型训练
模型训练涉及主动学习的训练样本选择和NER任务。按主动学习训练样本策略选择与否,将实验模型分为TE1、TE2和Random。其中,前2个模型的策略选择使用TE方法,使用LSTM+CRF特征计算后的概率值进行Token熵的计算。基于Random的模型使用随机选择标注样本训练模型及后续的NER任务。词嵌入模型使用SGNS[10]。对于分类模型,该研究的LSTM单元数设为100;学习率为0.01;训练通过Adam优化;批处理为64;Dropout的概率为0.5。
4 结果
实验在冠心病中文EMRs数据上开展。表2显示了在不同标注数据选择下各模型的NER结果。观察发现,使用策略选择方法TE的主动学习结果要优于常规模型。以F-Score为评估指标,使用TE的模型有着1.3%的性能增益。另外,对比TE1、TE2的结果发现,多次数据选择的结果有着1%的提升。
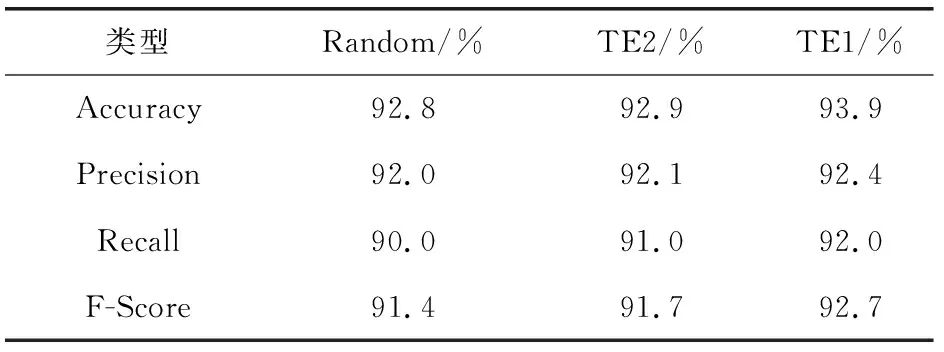
表2 不同模型的命名实体识别结果对比
不同模型NER训练的F-Score、Loss由图3给出。由图3(a)发现,在模型训练趋于平稳(Steps>1 K),进行标注样本选择TE1、TE2的结果优于未标注样本选择Random的结果。由图3(b)发现,使用主动学习的模型在Loss收敛方面表现更好。对应不同TE使用,细分多次标注数据选择的TE1结果有着更好表现。
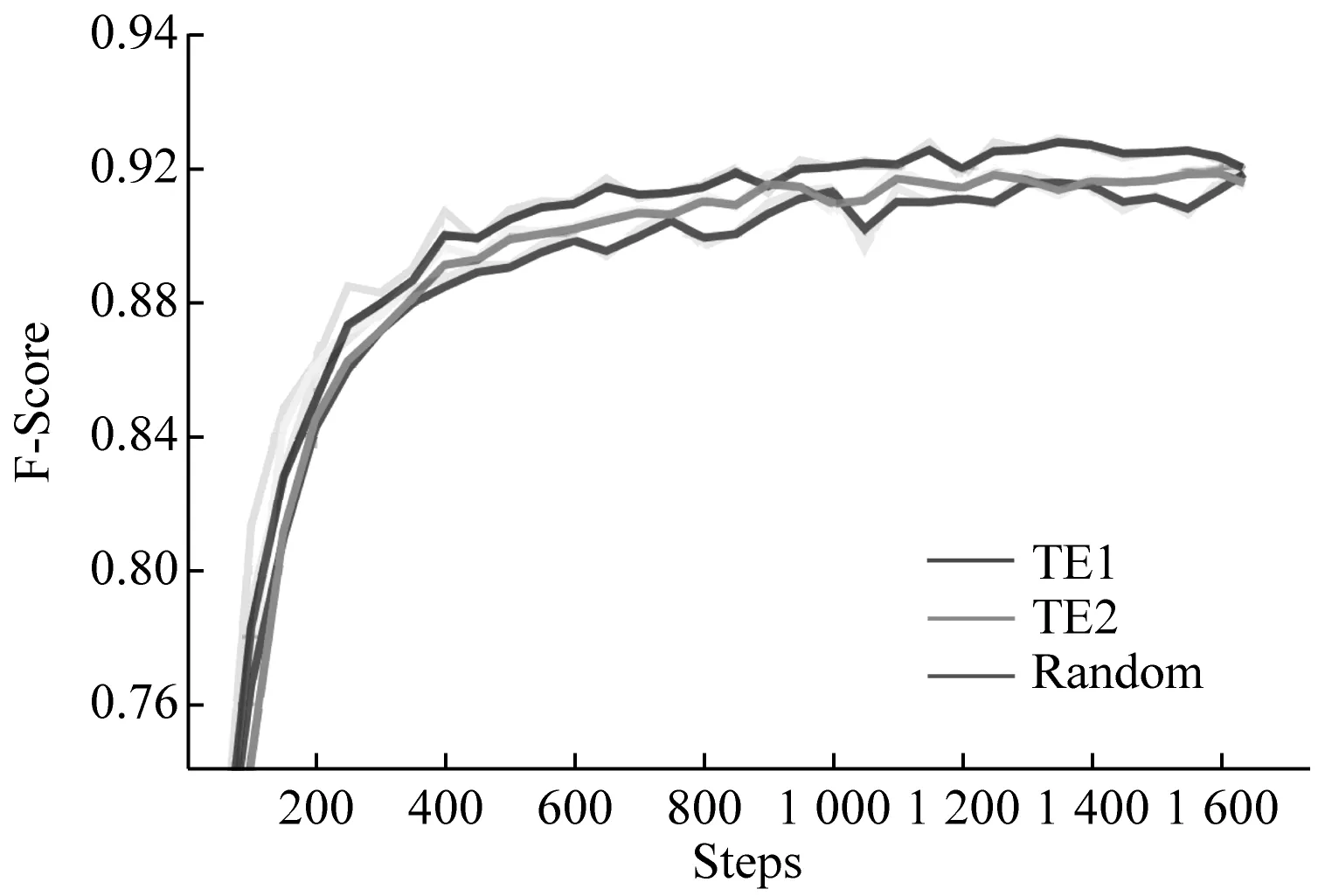
(a) 模型训练过程的各实体识别结果的F-Score(%)
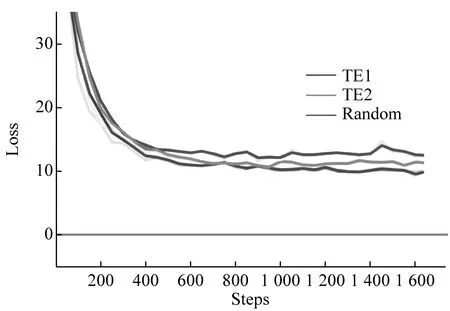
(b) 模型训练过程的Loss变化图3 不同模型在训练过程中的结果对比
5 总结
该研究以冠心病中文EMRs为对象,探究深度主动学习在某一特定疾病下的NER可行性。该研究以TE为策略选择方法,通过LSTM+CRF计算后的概率值进行TE计算并完成待标注样本数据的选择。该研究将每次标注数据选择的样本量进行设置,探究深度主动学习数据选择的意义。
实验表明,使用主动学习策略选择TE的LSTM+CRF结果更好,TE1、TE2的F-Score、Loss变化明显优于非标注数据选择Random的结果。此外,对于深度主动学习,更多次样本数据选择的TE1结果更好。总体而言,经过一系列探究,本文初步论证了深度主动学习在小样本下的可用性。研究模型对于提升数据标注质量、减少标注数据数量、降低人工标注成本,对进而提升医疗记录可用性、激发其在临床疾病研究中的价值有着积极作用。后续,研究组将细化、探索和总结中文EMRs中深度主动学习的研究价值及意义。
猜你喜欢
快乐学习报·教育周刊(2022年16期)2022-05-01
新高考·高三数学(2022年3期)2022-04-28
中学生数理化(高中版.高一使用)(2021年2期)2021-03-19
福建基础教育研究(2019年6期)2019-05-28
领导决策信息(2018年16期)2018-09-27
海峡姐妹(2018年3期)2018-05-09
数学学习与研究(2017年3期)2017-03-09
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
少儿科学周刊·儿童版(2015年2期)2015-07-07
