
一种基于视频的篮球运动员能力评估方法
2022-07-26 09:30黎明
微型电脑应用 2022年6期
黎明
(四川文理学院,体育学院, 四川,达州 635000)
0 引言
衡量球员的标准往往是依据他的数据,例如每场比赛的得分和篮板[1-2],然而这些指标并不能反映出教练可能想要用来评估他在未来球队中的潜在影响的每一个方面。教练和球探们渴望通过观看一个篮球运动员的大量篮球视频来捕捉他能力的每一个细微差别,因此在青训中,寻找最佳球员的任务变得更具挑战性,成本更高,劳动强度也更大。更重要的是,这些衡量标准都是基于个人的主观评价。更主要的是,目前用于自动评估运动员在特定运动中表现的计算模型方面进展有限[3-5]。所以,为了解决以上问题,本文提出了一种基于第一人称的篮球运动员评估方法(BPA),该方法首先使用卷积LSTM[6]从第一人称视频中检测元篮球事件。这些元事件通过高斯混合产生一个高度非线性的视觉时空篮球评估特征。最后,通过最小化一个铰链损失函数,从标记的第一人称篮球视频中学习篮球评估模型,从而实现对球员的评估。
1 BPA的原理
在这里使用第一人称视频定义球员评估指标,具体如式(1):
(1)


图1 评估预测的框架
1.1 视觉时空评价
这里的第一个目标是使用第一人称篮球视频来建立一个强大的特征表示,可以用于有效的球员的表现评估。从第一人称篮球视频中识别出3个与构建这种表现形式相关的关键挑战:①提出的系统需要处理严佩戴摄像头的人的头部运动;②需要根据其原子事件来解释篮球表现;③这里的特征表示对于球员的性能预测任务必须具有高度的区分性。
为了解决这些问题,建议将分段视频的视觉特征Vt表示如式(2):
Ø(Vt,x)=fgm(fevent(fcrop(Vt),x))
(2)
其中,fcrop是一个函数,它通过放大重要区域生成裁剪的视频来处理严重的摄像机佩戴者的头部运动,fevent是一个计算元篮球事件概率的函数,fgm是一个高斯混合函数,它计算视频的高度非线性视觉特征。
1.1.1 缩放
fcrop的一个关键特性是能够缩放到相关像素,这使得学习一个有效的视觉表现来进行篮球成绩评估。使用这种区域性的裁剪,将第一人称视频的不稳定的影响降到最低,这会导致视觉数据的更大变化。在实验部分,证明在提出的模型中使用fcrop可以大大提高预测性能。因此,最初处理第一人称视频以生成裁剪视频:
(3)

通过使用完全卷积网络学习wcrop来预测裁剪窗口的中心[5]。为了做到这一点,通过训练网络来预测球的位置,这通常是大多数球员看到的地方。对于视频中的每一帧,计算XY位置坐标的加权平均值,然后在该加权平均位置周围裁剪一个固定大小的面片。
1.1.2 元篮球事件检测
为了建立元篮球事件的可解释性表征,分别预测了身体投篮、持球者持球、投篮命中的篮球事件。注意,裁剪后的视频聚焦于篮球及其视觉环境,这样可以更有效地学习每个元事件的视觉语义。为此,使用一个多路径卷积LSTM网络,其中每个路径预测其各自的元篮球事件。可以注意到,这样的多路径架构是有益的,因为它允许每个路径专注于学习单个元篮球概念。相比之下,可以观察到用单一路径训练一个类似的网络并不能对所有三个元事件产生准确的预测。给定一个裁剪过的视频,提出的多径网络被联合训练,从而最小化交叉熵损失,如式(4):
(4)

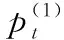
将4个篮球事件预测在时间维度上分成两半,并对8个区块中的每一个进行时间最大池化。然后将所有合并值串联成一个矢量bt,如式(5):
(5)
1.1.3 高斯混合
为了建立一个有区别但可以概括的表示,构造了一个高度非线性的特征,它可以很好地与线性分类器一起工作。为了实现这些目标,使用高斯混合,将元篮球事件特征转化为复杂的篮球评估特征。形式上,给定Ts上的向量bt,计算给定视频片段的视觉时空评估特征如式(6):
(6)

1.2 篮球评估预测
在后面章节,将根据前职业篮球运动员对运动员的比较评估,得出式(1)中的线性权重w。尽量减少以下铰链损耗,如式(7):
(7)


图2 学习框架说明
1.3 实施细节
对于所有涉及CNNs的实验,在这里使用了Caffe库。这两个网络都基于DeepLab[7]的架构,经过4 000次迭代训练,学习率为10-8,动量为0.9,权重衰减为5×10-5,每批30个样本。元篮球事件网络内部的LSTM层在视频输入中跨越了10个连续帧。元篮球事件网络中的每个路径由2个1 024维的核,大小为1×1的卷积层和1个1 024维的LSTM层组成。网络使用标准数据扩充进行训练。为了学习权重w,使用了0.001的学习率,并进行了100次迭代的梯度下降优化。
2 第一人称篮球数据集
数据集由48.3小时的篮球运动员组成,每段视频约13分钟长,由GoPro Hero 3黑色版安装头条拍摄。它的记录速度为1 280×960,每秒100帧。在这两天里,录制了48段视频,每天都有不同的人在播放。使用前24个视频作为训练和后24个视频作为测试。这里以每秒5帧的速度提取视频帧,得到98 452帧用于训练,87 393帧用于测试。
在这请一位篮球球员根据一些第一人称视频来标注哪个球员表现更好。总共使用500对,250对用于训练,250对用于测试。注意,在训练和测试之间没有球员重叠。
将3个简单的篮球项目列为:①有人投篮;②持球者持球,③投篮命中。这些是推动篮球比赛的关键元事件,分别为这三个事件获得了3 734、4 502和2 175个注释。
此外,为了训练一个球探测器,在5 073张图像上标记一个球的位置,只需点击一次这个位置。在这些位置周围放置一个固定大小的高斯函数,并将其用作基本真实性标签。在这里通过手动检查与最大篮球评估模型权重w相关的高斯混合体对篮球活动进行可视化。
图3中每行描述一个单独的事件,每列说明事件的时间推移(从左到右),从图中可知,2个最正的高斯混合分别对应于一个球员的2分球和3分球(前两排),而最负权重的混合体捕捉了一个球员错过2分球(最后一行)的事件。

图3 多个篮球活动的检测
3 实验结果
3.1 定量结果
3.1.1 元篮球事件检测
在表1中,首先说明元篮球事件检测任务的结果。根据最大F分数(MF)度量,对预测的元事件概率进行小间隔阈值化,然后计算精度和召回曲线。首先,将模型的预测与最近的几个第一人称活动识别baseline[9-11]以及成功的视频活动识别baseline C3D[8]进行比较。得出结果:对于每个元事件,提出的模型都优于所有这些baseline。

表1 数据集上定量检测的结果
此外,为了证明提出的模型的设计选择,在表1中还包括了几个实验,研究了多路径体系结构、LSTM层和放大方案的效果。实验表明,这些组件中的每一个都是实现元事件识别精度的关键,也就是说,当这三个组件都包含在模型中时,系统达到了最佳的性能。
3.1.2 篮球评估结果
在表2中,展示了对测试数据集中的24名篮球运动员的评估结果。为了检验方法的准确性,对250对有标签的球员进行了评估,其中篮球专家提供的标签表明球员中哪一个更好。对于每个球员,本文的方法产生一个评估指标,指出哪个球员更好(越高越好)。为了获得准确度,计算了所有250对中正确预测的分数。
由于目前还没有相关研究,因此对于这项任务,没有现成的基准。因此,将以下baseline列表作为比较。
首先,包括2个篮球活动baseline:2分球和3分球。实验中标记数据集中发生这些活动的所有实例,并发现大约100个这样的实例。请注意,如此少的实例并不是数据集的缺陷,而是本文任务的固有特性。这类篮球活动属于长尾数据分布,很少发生,因此很难训练有监督的分类器进行这类此外,为了证明在模型中提出的每个组成部分的合理性,在表2中还包括几个ablation baselines。首先,研究了高斯混合(GM)和权值的学习过程对能力评估准确性的影响,在这里用本文预测的和真实的元事件来做这件事。实验表明,在这两种情况下提出的每一个组成部分都是有益的。此外还观察到提出的方法对元事件识别错误具有很强的鲁棒性,当使用基本真实元事件时,其准确度仅比原始模型提高2.8%。

表2 BPA评估结果
活动识别。然后,将LRCN[12]模型训练为2分投篮探测器,3分投篮探测器。由于训练数据量很少,在所有情况下,网络都严重过度拟合训练数据,没有学习到任何有意义的模式.
当从系统中移除四个元事件中的一个时,实验也给出了性能评估结果。实验表明,当使用所有四个元事件时,提出的方法执行得最好,这表明每个元事件都是有用的。最后,作为两个额外的baseline,在这里手动选择2个权重最大的高斯混合体,并独立使用它们的每一个预测(在表2中表示为单个GM-top1,2)。因此可以证明,本文的完整模型优于所有其他基线,因此提出的模型中的每一个组成部分对于准确地评估球员表现至关重要。
3.2 定性结果
3.2.1 BPA实际评估结果
此外,在图4中,还包含了评估模型如何随时间变化的更动态可视化。为了做到这一点,随机选择4对篮球运动员,提出的模型随着时间的推移评估每个球员。每对中的红色图表示更好的选手,而蓝色的图则表示较差的选手。图中的y轴说明了对球员第一人称视频中特定时间发生的事件的预测性能度量。
此外,在图5中,还包括了一些短序列的例子,说明了一个球员的行为对他/她的能力评估贡献最大与对他/她的能力评估贡献最大的行为。通过选择第一人称视频序列来选择这些动作序列,第一人称视频序列在式(1)的总和中具有最大的正负值(这也对应于图4中的正负峰)。这些术语描述了每个视频片段对整个篮球技能评估指标的贡献。在图5(b)中,负面事件定义为投篮不进。

图5 BPA模型检测的结果
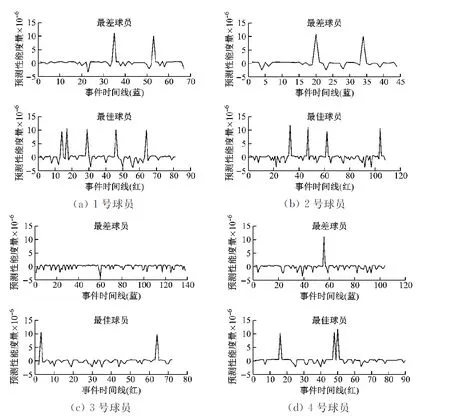
图4 随机4名球员的评估结果
需要指出的是,将这些结果包含在图像格式中是相当困难的,因为图像是静态的,它们无法捕获视频的全部内容且与原始的480×640视频相比,论文中的图像以非常低的分辨率出现,这使得更难理解什么是事件在这些图像中描绘的。
3.2.2 对特征表示的理解
高斯混合会产生高度非线性的特征表示,为了更好地了解它所代表的内容,分析学习到的权重w,然后手动检查与w中最大量级权重相关联的高斯混合。这样做后,发现当佩戴相机的人分别拍摄2分和3分时,具有最大正权重的2个混合体学习捕捉篮球活动。相反,具有两个最负权重的混合体表示相机错过2分镜头的活动,以及相机佩戴者的防守者分别进行拍摄的活动。在图3中,包含了与这些发现的活动相对应的几个序列。
4 总结
本文介绍了一个篮球评估模型,从一个球员的第一人称篮球视频中评估他/她的表现。研究表明,可以从第一人称视频中学习到强大的视觉时空评估特征,然后利用这些特征从弱标记的第一人称篮球视频中学习提出的技能评估模型。结果证明,尽管不知道他人的评估标准,但提出的模型能够准确地评估球员。此外,使用提出的模型可以发现相机佩戴者对其能力评估有积极或消极影响的活动。
猜你喜欢
小天使·二年级语数英综合(2019年4期)2019-10-06
小学生学习指导(低年级)(2019年6期)2019-07-22
学苑创造·A版(2019年2期)2019-02-19
NBA特刊(2018年14期)2018-08-13
中国收藏(2017年4期)2017-05-13
文艺论坛(2016年23期)2016-02-28
电影故事(2015年16期)2015-07-14
