
基于词向量集成与数据增强的恶意评论分类模型
2022-07-25 02:12:06杨金灵
科学技术创新 2022年22期
杨金灵
(大连外国语大学,辽宁 大连 116044)
如今,随着科技时代的到来,人们在发达的互联网背景下往往倾向于利用方便的电子设备在网络中发表各种各样的言论和表达自身的情感。因此从众多的意见中也产生了海量的数据。但是,其中不乏暗含着具有充满威胁性的甚至报复性质的恶意评论。据调查,网络安全研究员Jeremy Fuchs 在发表的一份报告中写道,CheckPoint 公司旗下的电子邮件协作和安全公司的研究人员在12 月首次观察到了大规模黑客利用谷歌文档的评论功能进行攻击的趋势,并且到目前为止攻击者通过利用谷歌基于云端的文字处理应用程序的功能,已经攻击了30 个用户的500 多个收件箱,来自100 多个不同的Gmail 账户。这类不良现象的频繁发生聚集了越来越多的科学家和研究人员等业内人士的焦点。在处理这一问题的方法上,实则是一个文本分类的工作,因此利用经典的,前沿的技术手段对这些文本进行高效最优地分类成为了科研人员研究的热点问题之一[1]。如在文献[2]中陈等人提出了融合领域知识图谱的方法,将跨境民族文化文本进行归类处理。
本文采用来自维基百科谈话页面编辑的评论数据集设计了恶意评论的文本分类任务,即使研究者们的实验模型已经达到了不错的预测性能,但是在实验配置与数据集等方面仍有待改进之处:
(1)将文本转换成数值向量的词向量中记录了日常常见单词文本的相似度,词向量的选择对于模型的分类性能有着巨大影响。而在某个语料库单独训练的词向量往往会对统计学的捕捉存有偏差,因而降低模型的分类性能。在恶意评论分类模型中只使用了一个在fastText上预训练的300 维词向量,因此在这一问题上增大了模型预测值不准确性的概率。
(2)现有的数据集中约有15 万条评论,由于样本数量有限,因此模型在样本数据集中能会导致恶意分类错误的情况发生,从而危害模型的稳健性(robustness)。因此,从模型所能够学到的内容与稳健性角度来看,现有的模型仍存在不足。
(3)在现有的研究中,集成词向量与数据增强较少被人们使用,研究方法层面也有所欠缺。
所以针对以上问题,本文提出了一种集成词向量与数据增强的恶意文本分类模型(ENSVEC-DA)。
1 实验设置
1.1 实验框架
本实验的总体流程介绍如下:
首先,准备本实验所需的两种训练集,分别为增强的训练集与非增强的训练集。
其次,先后选择训练集中的一种,通过预训练的词向量将里面的评论文本转化为非集成的数值向量和集成的数值向量。
再次,通过是否增强训练集与是否集成词向量两两组合得到四组对比实验,并使用相同的测试集使RNN 网络依次预测四组实验的恶意概率。
最后,计算出每组实验中六组标签所对应的Acc、AUC、Brier Score 评估指标,通过对比评估指标得出结论。实验框架如图1 所示。

图1 实验框架图
1.2 实验数据集
本实验的样本数据集采用来自维基百科谈话页面编辑的评论数据集,来源可靠且相对权威。
此数据集包含训练集与测试集,均含有6 个标签,总评论条数分别为159571 条和153165 条,其中在测试集里除-1 标签标注的无效评论外共有63979 条有效评论,统计的样本数据集如表1、表2 所示。

表1 训练集标签

表2 测试集标签
1.3 评估指标
为了更合理且准确地评估ENSVEC-DA 恶意文本分类模型的预测性能,本文选用了较为常用高效的准确率Acc(Accuracy)、AUC(Area Under Curve)和布里尔分数(Brier Score)三种评估指标。详见表3。

表3 性能评估相关值表
准确率Acc(Accuracy)计算公式:

布里尔分数(Brier Score)计算公式:

布里尔分数是衡量概率校准的一个参数[3],可以被认为是对一组概率预测的“校准”的量度。式(2)中:N 表示总共检测的样本数目,y^t是预测的概率值,yt是真实的概率值。
AUC 是ROC 曲线下方的面积大小[4],是对模型性能评估的一项重要指标。ROC 曲线[5]的横坐标是假正例率(FPR),其计算公式为FPR=FP/(TN+FP),纵坐标是真正例率(TPR),计算公式为TPR=TP/(TP+FN)。
在本实验中以是否集成词向量,是否数据增强为变量,使变量两两组合得到四组对比实验。通过分别计算四组实验的评估指标最终判断模型的预测性能提升与否。
2 实验结果
2.1 词向量集成技术对恶意评论分类性能的影响
为了验证词向量集成技术具有提升模型分类性能的优点,我们基于非数据增强的训练集,对使用词向量集成技术与非使用词向量集成技术进行了对比实验。表4、5、6 为实验评估指标结果。

表4 Acc 评估指标
在指标值层面分析实验的恶意预测概率可以看出,词向量集成技术对模型分类性能的提升有所帮助。虽然在表5 所示的AUC 指标中,六种标签所对应的AUC 数值在非集成词向量方面表现更好,但是综合对比Acc 和Brier Score 指标后我们发现,词向量技术在某些恶意评论分类上有更优效果。根据表4 进一步分析,在toxic、server_toxic、obscene 这三种评论上集成词向量比非集成词向量的评估指标Acc 值分别高出0.0026、0.0024 和0.0004。并且由表6 中的Brier Score 值所示,在集成词向量实验中,server_toxic 的Brier Score 值比非集成词向量实验的值降低了0.0003。因此,结合表4 与表6 的结果,我们发现词向量集成技术可以提升部分种类的恶意评论的分类性能。

表5 AUC 评估指标

表6 Brier Score 评估指标
2.2 数据增强技术对恶意评论分类性能的影响
本组实验使用与上组实验相同的评估指标来分析数据增强技术对恶意评论分类性能的影响。根据实验所得的恶意评论分值计算出的评估指标展示如图7-9。
对比分析表7、8、9 中的数据,我们发现数据增强技术与词向量集成技术所产生效果相似,两者均提高了实验模型对某种恶意评论的分类性能。根据表中数据可得出结果如下:

表7 Acc 评估指标

表8 AUC 评估指标
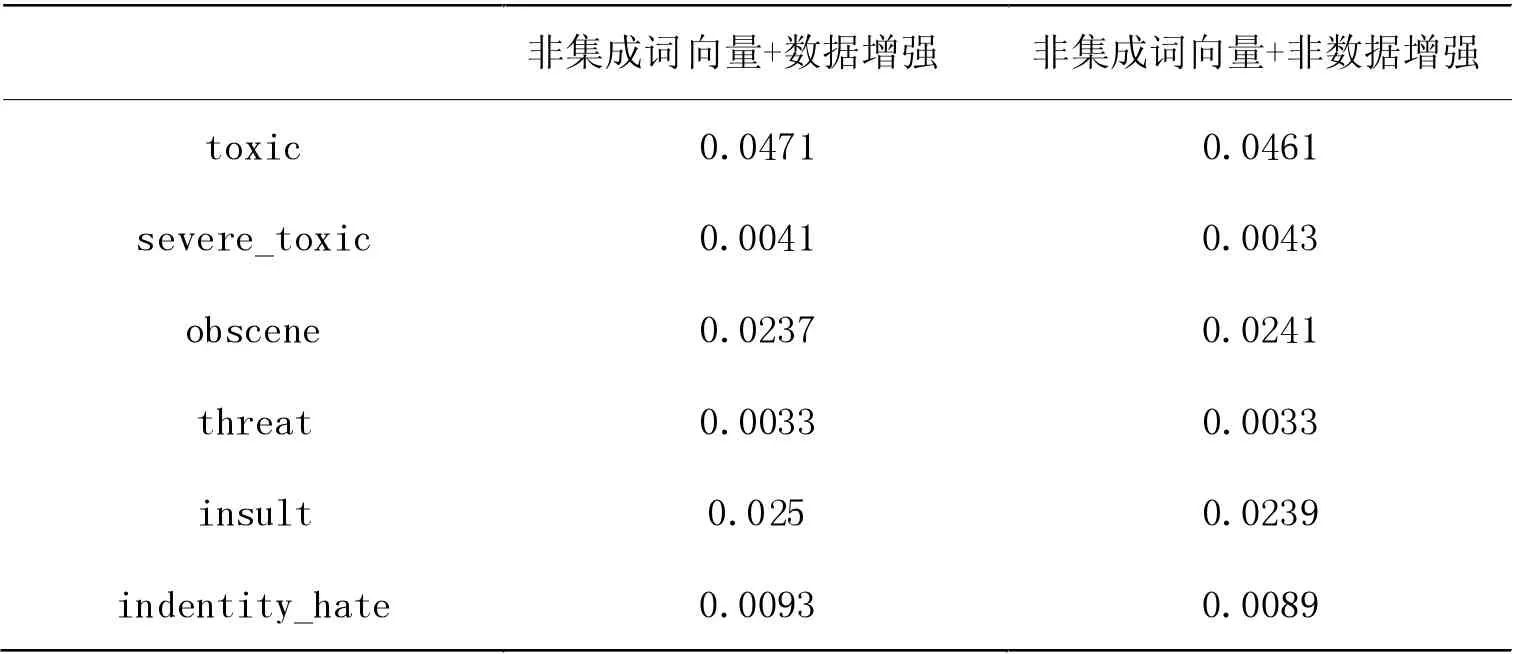
表9 Brier Score 评估指标
(1) 在server_toxic 和obscene种类上,数据增强实验的Acc 值比非数据增强的Acc 值分别高出了0.0003 和0.0027。
(2)在AUC 值上,数据增强的indentity_hate 种类表现更好,且比非数据增强高出0.0022。
(3) 对比非数据增强实验的Brier Score 值,在数据增强的实验里,server_toxic 和obscene 种类所对应的数值分别降低了0.0001 和0.0004。
因此,可以肯定数据集成技术对恶意评论分类性能提升的积极影响。
2.3 ENSVEC-DA 恶意文本分类模型性能评估
为研究词向量集成技术与数据增强技术的结合使用的ENSVEC-DA 恶意文本分类模型是否对分类性能产生有益影响,本文分别从ACC、AUC、Brier Score 三种评估指标分析了本模型在四组实验中对六种恶意评论的预测分值,并通过绘制分组条形图进行对比分析,如图2、3、4 所示。

图2 Acc 评估指标对比

图3 AUC 评估指标对比

图4 Brier Score 评估指标对比
从图2 中我们可以发现,在server_toxic 种类上,Acc 值虽然在集成词向量和数据增强方面略低,但是总体在直方图展示上几乎呈现上升趋势,并且在toxic、obscene、indentity_hate 中,两种技术的结合使用比其他某个组合实验的Acc 值更高。由AUC 评估指标对比图可见,结合词向量集成技术和数据增强技术的AUC 值比集成词向量和非数据增强实验的AUC 值在indentity_hate 种类表现上更好,并且在图4 Brier Score 分组条形图中的server_toxic 种类上,使用两种技术的评估值比非使用两者的评估值高。
由此可见,词向量集成技术和数据增强技术的结合使用使ENSVEC-DA 恶意文本分类模型的预测性能在部分种类的恶意评论上有所提升。
3 结论
通过分析恶意评论分类模型的实验配置与样本数据集,我们发现了原实验中存在的使用词向量单一,数据集信息有限的问题,这会降低分类模型在某种恶意评论的预测性能。因此,本文中提出了ENSVEC-DA 恶意文本分类模型,使用词向量集成技术和数据增强技术来有效解决这一问题,通过控制是否集成词向量和是否数据增强这两个变量在同一测试集上做四组对比实验。最终结果显示,ENSVEC-DA 恶意文本分类模型在某种恶意评论分类性能上表现更好,这有效地改善了现有方法的不足之处。
综上,在未来的研究工作中我们将继续多角度优化并验证ENSVEC-DA 恶意文本分类模型的分类性能,使该模型应用于更多领域中。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
新高考·高二数学(2015年11期)2015-12-23 18:17:44
质量与标准化(2015年9期)2015-07-10 15:12:07
浙江人大(2014年5期)2014-03-20 16:20:25
