
利用空间关联随机森林模型与遥感影像估算裸土期耕地土壤盐分含量的研究
2022-07-23 08:10:42徐夕博吕明荟王海会周忠科彭远新颜学文
河南农业科学 2022年5期
徐夕博,吕明荟,王海会,周忠科,彭远新,颜学文
(1. 北京师范大学 地理科学学部,北京 100875;2. 枣庄学院 旅游与资源环境学院,山东 枣庄 277160;3. 山东省地下水环境保护与修复工程技术研究中心,山东 济南 250014;4. 山东省地质矿产勘查开发局 八〇一水文地质工程地质大队,山东 济南 250014)
土壤盐分含量(Soil salt content,SSC)是土壤的一项重要的理化参数,对于维持绿色植物的细胞物质交换具有重要作用。SSC 过高,会限制光合作用阻碍作物的正常生长,进而降低粮食产量,对地表生态系统和社会经济发展产生负面影响[1-2]。从全球范围来看,约有40%的耕地土壤在盐化作用胁迫下,表现出不同程度的土壤退化,土壤盐化的治理和恢复工作已经成为当务之急。而进行这一工作的关键前提则是,需要对治理区域内的SSC 进行实时准确识别和监测。
近年来,随着现代遥感信息技术的发展,卫星遥感影像因其覆盖范围大、时效性强和获取成本低廉等特点,在资源环境监测领域的应用优势更加明显。卢 霞[3]、LIU 等[4]、WANG 等[5]和SRIVASTAVA等[6]在严格控制的实验室条件下,基于土壤光谱定量分析技术,确定了SSC 在可见光及近红外波长范围内(400~2 500 nm)的响应波段,并将其作为输入自变量构建光谱估算模型,完成了SSC 的估算。冯娟等[7]、贾萍萍等[8]、曹雷等[9]、FAN 等[10]和MULLER等[11]进一步将卫星影像波段反射率和地面实测SSC建立回归联系,完成区域尺度上的SSC估算制图,为SSC在大范围上的空间变异监测提供了理论依据。
但是,土壤盐分的电磁信号在产生、反射和传递过程中受到自然环境诸如大气、水分和地表特征等多因素的影响,这为准确建立SSC 信息与卫星接收到的反射率信号之间的映射关系增加了难度。因此,诸多学者[4,7,12-13]在进行SSC 估算模型构建时多采用以非线性拟合方式为基础的机器学习方法,例如人工神经网络、支持向量机、极限学习机和随机森林等。机器学习模型可以通过增加隐藏层结构、控制参数和决策树数量等方式,实现光谱信号到土壤属性含量的特征转变,能够提供相对较高的精度。但所得估算模型对真实地表环境的模拟过程中,因受到成土母质、人类活动和数据采集过程等因素作用下产生的特异性地理标签数据的影响,会导致机器学习模型出现过拟合和局部极值等问题,限制模型性能的提升。针对这个问题,LIU 等[14]和BAO 等[15]通过随机抽取、光谱特征、土壤类型和含量欧式距离划分等方式选择建模样本集,减弱或避免特异性样本数据的干扰,在保证验证集精度的同时最大程度提升训练集准确性。然而上述对特异样本数据的识别均是基于土壤属性的含量特征进行的,而地理样本数据除具有描述性的含量特征值外,还具有显著的空间位置特征信息[16-17]。地理学第一定律[18]表明,距离越近的地物间空间关联性越强,而特异性数据则展现出显著的非关联性。因此,将空间位置信息引入用于评估数据样本间空间关联度和最佳训练样本集的建立,对于提升SSC 估算模型的计算效率和精度具有极大的潜力。本试验以莱州湾南岸滨海平原地区为研究区,系统采集95 处土壤样点并获取同期Sentinel-2 多光谱影像;进一步利用随机森林变量重要度评估技术选择土壤盐分的响应波段,作为输入自变量,将测得SSC作为因变量;最后建立基于空间关联随机森林算法的遥感估算模型,实现区域尺度上的SSC 遥感定量估算和数字制图,以期为区域的盐碱治理和资源环境优化提供理论依据和技术支持。
1 材料和方法
1.1 研究区概况
研究区位于莱州湾南岸滨海平原地区,介于118°44′22″E~118°53′20″E 和37°6′10″N~37°11′33″N,总面积约为87.3 km2(图1)。研究区的气候类型为典型的季风区温带大陆性气候,受海洋环境影响明显,干湿季分明。多年平均气温和降水量分别为12.7 ℃和608.5 mm,平均高潮位1.75 m。在地质构造上属辽冀台向斜第四系沉积层,地形则以平原为主,平坦开阔。小麦和玉米为主要的种植作物,部分近海区域以种植耐盐抗逆境能力强的棉花为主。近些年来,研究区港口贸易繁荣,工农业发展迅猛。地下水开采量随之增加,引发海咸水倒灌,土壤表现出轻微的盐碱化[19]。

图1 研究区及采样点Fig.1 The study area and sampling sites
1.2 样点数据与测试分析
在综合考虑土地利用、地质地貌和交通可达性等因素的基础之上,利用ArcGIS 10.2软件中的数字底图,初步完成95处土壤样点的预设。在实际采样过程中,在预设点周边50 m 内,选取合适的区域进行土壤采集,采用手持式GPS 确定并记录采样点的真实地理坐标。在采样时,土壤样品的采集采用多点混合法,在样点位置周边10 m 范围内,将土壤混合至1 kg 左右,装入聚乙烯密封袋中进行保存并及时运送至实验室开展分析测试[20]。土壤样品的采集在裸土期(2019 年1 月7—11 日)内完成。在实验室内,首先去除土壤中明显异质体,例如石块、树叶、草根、木棒等;接下来,土壤在实验室内(25 ℃)进行自然风干,研磨后过1 mm 筛,完成测试前的预处理;最后,采用质量法对土壤样品的全盐含量进行测定,即吸取一定量基质水浸出液,蒸干除去有机质后,烘干,称量测得SSC[21]。
1.3 影像获取及预处理
Sentinel-2B(哨兵二号)是欧空局在2017 年发射的一颗地球资源环境观测卫星,在晴朗少云的状态下,哨兵卫星可对全球实现5 d 频次的重复观测[22]。卫星影像按照空间分辨率可分为3 类:10 m(B2、B3、B4 和B8)、20 m(B5、B6、B7、B8a、B11 和B12)和60 m(B1、B9和B10)。在美国地质调查局网站(https://glovis.usgs.gov)免费下载Sentinel-2B 影像一景(生成时间为2019年1月17日),天气状态为晴朗无云。对获取的影像数据进行辐射校正、大气校正和重采样(10 m)3项预处理操作,具体在SNAP软件(已安装Sen2Cor 插件)中计算完成[23]。哨兵二号影像数据的B1、B9和B10设计用于气溶胶和大气特征的检测,不参与SSC的反演计算过程[24]。
1.4 空间关联随机森林模型
空间关联随机森林模型是以随机森林算法[25]为基础,在数据输入侧引入空间权重函数[26-27]对样本数据的空间关联度进行评估(公式1 和公式2),在厘清输入样本数据在局部空间上的关联关系后,赋以权值,依据关联度值大小形成最优聚类,以此为样本输入完成估算模型训练回归的一种技术方法。模型构建及实现流程如图2所示。
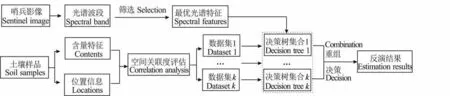
图2 空间关联随机森林模型计算流程Fig.2 The calculation processes for the spatial random forest model

式中,(μi,vi)表示样点i的经纬度坐标,Fi(φ)为样点i位置处的空间权重高斯函数,L和δ分别表示样点i的SSC实测值和随机误差项。t值的大小表示样本数据的空间关联度的强弱,数值越小,样本数据间空间关联度越强,表现出的空间特异程度越低。
空间关联随机森林模型有4 个重要的参数,分别为输入变量的重要度值(Variable importance scores,VIS)、决策树的数量(ntree)、分裂点变量的数量(mtry)和地理信息协同变量(Xj)。VIS值的大小表示输入自变量对因变量影响程度的强弱,数值越大,自变量对SSC 的影响越大,相关性就越强。此外,为提升空间权重函数对样本数据的属性和空间信息的评估能力,Xj设置为典型且易获取的5 种环境要素辅助信息,分别为高程、归一化植被指数、土壤湿度指数、地表温度和距海远近。高程数据免费获取自地理空间数据云网站(http://www.gscloud.cn/),归一化植被指数、土壤湿度指数和地表温度数据的获取与采样时间保持一致,具体求算方法参见文献[28-29]。距海远近为每个采样点距离海洋的最近距离,在确定海洋边界之后在ArcGIS 10.2 软件的欧氏距离模型中完成计算。进一步的,决策树类模型构建的核心思想是通过构建若干棵决策树进行投票汇总最后得出结果,在决策树的各个节点上,从M个特征中选取m个特征集用作预测变量,在节点的分裂过程中,逐次选取最优的m个预测变量,最后进行结果汇总得出预测结果[30]。根据多次试验结果,ntree和mtry在本研究中分别设置为800和3。模型的实现和计算在Python 3.8中编程完成。
1.5 精度评估
获取的95个土壤样本随机划分为建模集(n=75)和验证集(n=20),建模集样本用于训练遥感估算模型,而验证集样本用于估算模型的独立验证和评价。决定系数(Coefficient of determination,R2)和均方根误差(Root mean square error,RMSE)通常作为评价模型精度的重要统计指标。R2用来评价自变量对因变量的信息解释能力,估算得到的SSC 与实测值的差值为RMSE值。所以RMSE值越小,R2值就越大,估算模型的精度和稳定性就越好[31]。
2 结果与分析
2.1 SSC描述性统计特征
从表1 可以看出,样品总集的SSC 在0.50~121.79 g/kg,均值为3.39 g/kg,覆盖范围较大且不均匀。变异系数用来评估数据的波动程度,3 个数据集的变异系数均较大,处于高度变异(>0.36),表明区域内存在较多盐分异常值[32]。建模集和验证集的变异系数也相差较大,但是3个集合的中值均一致,说明特异值的存在并不是普遍现象。此外,样本数据的空间变异会增加地表模拟模型的训练难度,但是一定程度的数据变异性会对模型准确度提升产生积极影响,所以随机抽取到的建模集和验证集样本用于SSC 的遥感建模估算是可靠的[33]。峰度和偏度用于描述数据分布的集中和双尾特性,样本总集的偏度值较大,表现出正偏,表明外部活动已经干扰了成土之初土壤盐分正态分布状态。SSC的描述性统计特征所表现出的变异性一定程度上也反映了土壤盐渍化的趋势和状态。莱州湾南岸滨海平原地区内有大量海咸水赋存在浅层地表,在地下水过度开采、旱季蒸发强烈以及海咸水倒灌等因素影响下,致使表层SSC 在不断增加,土壤肥力下降,随之带来一系列的土地环境退化问题,这也是不同土壤样本集的盐分含量分布存在偏移的潜在驱动因素[34]。
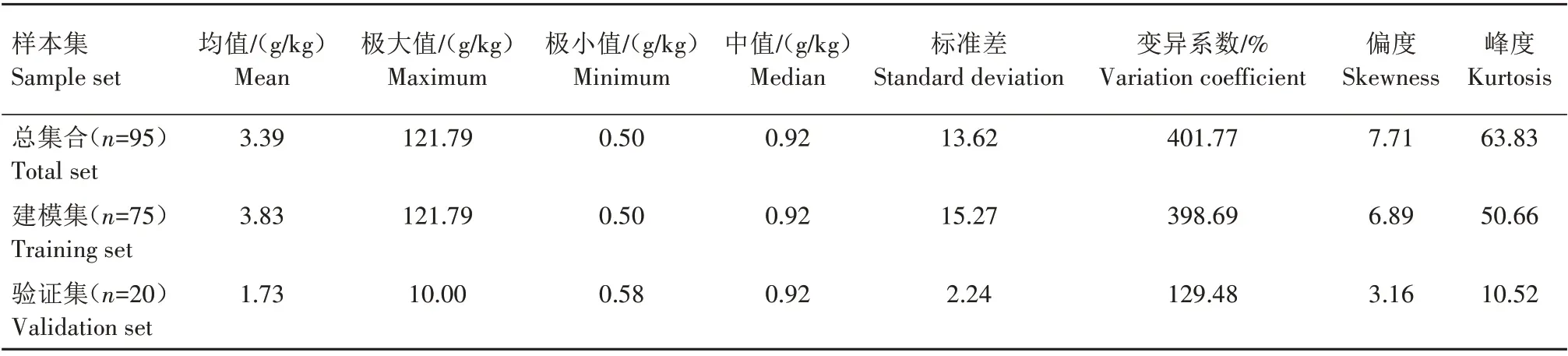
表1 SSC描述性统计特征Tab.1 The descriptive statistical characteristics of soil salt content
2.2 SSC的敏感光谱波段
如图3 所示,B11 的VIS 最高,B12、B2 和B8a 次之(VIS>10%),其余都比较小,因而B11、B12、B2 和B8a被选为敏感波段用作反演模型的输入变量。土壤在盐化过程中会产生NaCl、Na2SO4和CaCO3等化合物,这些化学物质与水在键态结构上的结合引发的振动,会产生特异性的光谱吸收峰特征[35]。例如,WANG等[36]指出波长2 200 nm附近是Na2SO4的光谱吸收峰,这与B12 波段的中心波长位置相一致。此外,KAHAER 等[37]在对新疆艾比湖流域土壤盐分的光谱特征进行分析时发现,SSC 的高度相关性波段均处在近红外波段范围之内,包括800~1 000 nm、1 300~1 400 nm、1 500~1 700 nm、1 800~1 900 nm 和2 000~2 100 nm。同样地,SHRESTHA 等[38]在研究中也得出了卫星影像的近红外范围内波段是表层土壤盐分高度敏感区。此外,在蓝光波段(485 nm附近)的波段反射率与SSC 具有显著的相关性[39],WANG 等[5]在进行SSC 光谱定量分析时也发现,光谱范围在500 nm 附近存在有SSC 的敏感特征波段。上述研究结果较好解释了本研究对SSC的敏感波段VIS 评估结果。因此,将4 个波段(B11、B12、B2 和B8a)作为土壤盐分的敏感光谱参数,用作反演模型构建的输入自变量。
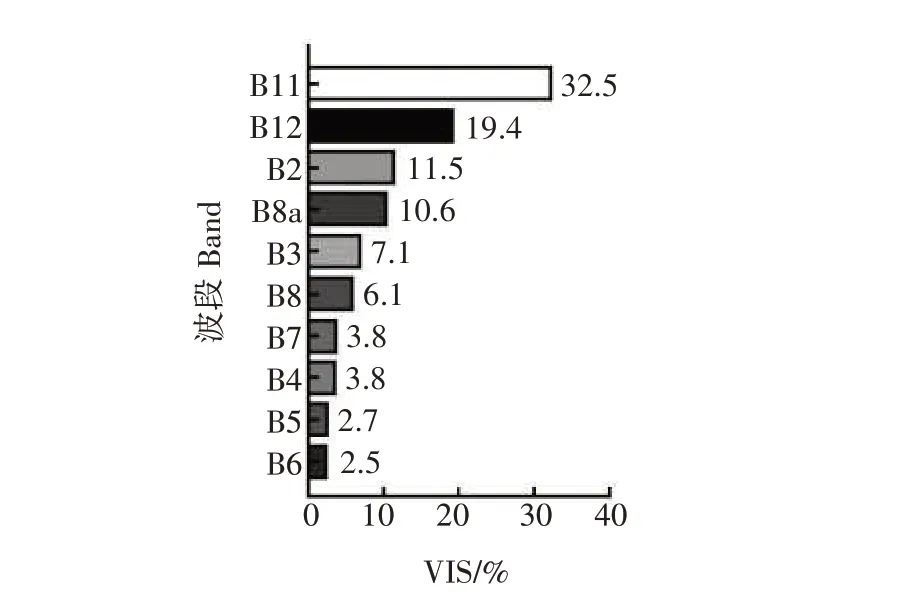
图3 哨兵影像各个波段的重要度值Fig.3 The variable importance scores(VIS)of various multispectral bands
2.3 SSC估算模型构建与精度对比
将优选得到的光谱波段作为输入自变量,实测SSC 值为因变量,分别建立基于随机森林和空间关联随机森林算法的SSC 遥感估算模型,结果如图4所示。可以看出,随机森林模型的精度评价指标R2和RMSE分别为0.74 和0.59(图4a),SSC 估算值和实测值出现较大偏差,偏差点较多,模型不能够进行SSC 的准确估算,需要进一步提升。在图4b 中,基于空间关联随机森林算法构建的SSC遥感估算模型的估算值和实测值数值比较接近,能够基本保持在1∶1线附近,但随着样点实测值不断变大,与估算值的偏差也开始增大。总的来看,利用随机森林算法和多光谱影像波段无法实现对莱州湾滨海平原的SSC 的准确估算,而在采用空间关联随机森林算法构建模型时,则能够较准确地对SSC 值进行遥感估算。

图4 SSC估算值与实测值对比散点图及验证精度Fig.4 The scatter plots of the measured values versus estimated values of soil salt content and the validation accuracy
在不同的空间关联度t值下,建立的空间关联随机森林模型的精度变化如图5 所示。可以看出,随着t值的减小,对数据样本间的空间关联度要求增加,模型的精度逐步提升,当t值为1 时模型的性能最强。其后随着t值的继续降低,样本总数量也进一步减少,模型得不到充分训练,精度开始下降。总体来看,空间关联随机森林模型的建立考虑了地理样本数据的空间信息,提升了对SSC的估算精度,使模型在区域土壤信息制图中的稳健性得到增强。

图5 不同t值下空间关联随机森林模型估算精度(n代表输入样本总数)Fig.5 The accuracy of the spatial random forest model based on different t values(n is the number of the calculation samples)
2.4 SSC空间分布反演结果
为检验基于空间关联随机森林算法构建的遥感估算模型的稳定性与可靠性,将得到的最优估算模型应用至整个研究区进行SSC 的反演及空间制图。反演的SSC 的空间分布如图6 所示,整体来看,SSC 处于0.41~2.00 g/kg,SSC 的高值区(>50 g/kg)主要分布在研究区的西北部和东部部分地区。此外,研究区内也存在大量块状分布的中度土壤盐化区域,呈离散状分布,主要分布于农田之中,SSC 处在2~4 g/kg。参照相关土壤盐化分级标准[40],研究区大部分属于轻微水平的土壤盐化区域(1 g/kg<SSC<2 g/kg),重度的土壤盐化区域(SSC>6 g/kg)存在于西北部和东部部分地区,但区域内存在的离散状分布 的 中 度 盐 化 风 险(2 g/kg≤SSC<4 g/kg)应 引 起重视。

图6 研究区SSC分布Fig.6 The spatial distribution of soil salt content of the study area
SSC分布主要受到微地貌、海水入侵、气候因素的影响。研究区地处莱州湾南岸沿海地区,区域浅层地下海咸水存量丰富,地表蒸发盐分结晶后析出,盐分晶体析出后在土壤表层聚集,造成部分区域SSC 不断升高,在西北部和部分东部区域尤为显著;同时,温带大陆性气候在旱季表现出降水少且蒸发大的特点,在受到微地貌影响后,导致广大田块出现中度土壤盐化的离散斑块。
3 结论与讨论
3.1 模型的机制和特点
本试验结果表明,空间关联随机森林模型在厘清区域地理环境中存在的样本特异性和空间关联性的同时,利用随机森林方法建立起SSC 与影像波段反射率之间的回归联系,估算效果指标R2和RMSE达到0.86 和0.38,能够较准确地完成区域尺度上SSC的遥感估算与数字制图。传统随机森林算法通常假设样本在空间上是独立存在的,通过不断改变决策树的数量和节点数目拟合这种真实的地表环境过程,进而实现标签值到特征值的信息转换[41]。但很明显,这种假设与真实的地理环境是存在一定偏差的,因此,直接将随机森林模型应用至真实的环境会带来一定误差。另外,土壤属性的含量特征与影像波段反射率之间有着确定的映射关系,但因受到大气、水分和地表粗糙度等因素的影响使得这种对应关系异常复杂[42]。并且这种函数关系在不同的地理空间单元还存在显著的差异,这种空间维度上的特殊性进一步增加了土壤属性遥感估算与制图模型的构建难度[1,14]。所以本研究在随机森林算法中引入空间关联函数模块以判断SSC数据样本间的关联度与异质度,聚类形成最优的输入样本集,得到具有相对正态的数据集,使接下来的空间关联随机森林模型在训练过程中可以减少决策树和预测节点的选择,有效提升运算效率和精度,模型的稳健性得到增强。
3.2 模型的适用性
本研究提出的基于空间关联随机森林算法的遥感估算模型,对于土壤环境情况复杂区域的SSC估算具有明显的优势。试验选择的研究区地处海陆交接地带,土壤的盐化过程受到海洋和陆地气候的共同作用,使得土壤盐化的空间变异十分复杂。刘文全等[43]和蒙永辉等[44]通过在莱州湾滨海平原地区实地采集土壤样品,运用传统的地统计学和地理加权回归等方法,研究了SSC 的空间变异性并绘制出土壤盐分的空间分布图,但此种方法的推广应用受到经费和时间的极大限制。张丽霞等[45]和曹文涛等[46]利用光谱定量分析技术和实测土壤高光谱数据,采用多元回归模型技术实现了莱州湾滨海平原地区局地尺度上的SSC的定量估算。但是在此特殊的景观格局下,直接运用局地遥感估算模型进行SSC的区域制图仍有局限。本研究提出的空间关联随机森林模型通过对输入样本集进行优化选择,使由此训练得到的估算模型能够较好地适应环境情况复杂区域SSC 的估算,并取得良好的空间估算精度,研究所得结果可为裸土期耕地SSC 的估算及空间分布监测提供有效的方法支持。
猜你喜欢
ELLE世界时装之苑(2024年5期)2024-05-14 09:45:39
北京航空航天大学学报(2022年8期)2022-08-31 08:58:58
当代陕西(2019年15期)2019-09-02 01:52:00
学苑创造·A版(2018年11期)2018-02-01 06:29:20
读者(2017年5期)2017-02-15 18:04:18
高师理科学刊(2016年8期)2016-06-15 20:27:45
中国光学(2015年5期)2015-12-09 09:00:28
西藏科技(2015年4期)2015-09-26 12:12:58
食品工业科技(2014年23期)2014-03-11 18:18:54
无机化学学报(2014年1期)2014-02-28 17:30:08
