
基于Light-BotNet 的激光点云分类研究*
2022-07-22 06:32:48雷根华张志勇
电子技术应用 2022年6期
雷根华 ,王 蕾 ,2,张志勇
(1.东华理工大学 信息工程学院,江西 南昌 330013;2.江西省核地学数据科学与系统工程技术研究中心,江西 南昌 330013)
0 引言
大多的深度学习点云分类方法都是采用卷积层与池化层交替实现的,卷积层中的神经元仅与上一层的部分区域相连接,学习局部特征,在点云数据特征提取时容易丢失部分特征,从而导致分类精度下降等问题。而Transform 的提出则带来了一种新的思路,主要利用自我注意机制提取内在特征[1-3]。Transform 最初应用在自然语言处理(NLP)领域,并且取得了重大的成功,受到NLP中Transformer 功能的启发,研究人员开始将Transformer应用在计算机视觉(CV)任务。研究发现CNN 曾是视觉应用的基本组件[4-5],但Transformer 正在显示其作为CNN替代品的能力。Chen 等人[6]训练序列变换器,以自回归预测像素,并在图像分类任务上与CNN 取得竞争性结果。卷积操作擅长提取细节,但是在大数据量的大场景三维点云数据分类任务中,要掌握三维点云的全局信息往往需要堆叠很多个卷积层,而Transform 中的注意力善于把握整体信息,但又需要大量的数据进行训练。
BotNet[7]网络是伯克利与谷歌的研究人员在Convolution+Transformer 组合方面一个探索,它采用混合方式同时利用了CNN 的特征提取能力、Transformer 的内容自注意力与位置自注意力机制,取得了优于纯CNN 或者自注意力的性能,在ImageNet 中取得了84.7%的精度。将CNN与Transform 结合起来,达到取长补短的效果。BoTNet 与ResNet[8]网络框架的不同之处在于:ResNet[8]框架在最后3 个bottleneck blocks 中使用的是3×3 的空间卷积,而BotNet 框架则是采用全局自我注意替代空间卷积。带自注意力模块的Bottleneck 模块可以视作Transformer 模块。
本文通过改进方法[7],使用一种基于点的特征图像生成方法,将框架应用到三维点云任务中。对于特征提取方法中点云中的每个点,本文利用其相邻点的局部特征组成点云特征图像,然后使用点云特征图像输入到基于CNN 的Transform 的高效神经网络Light-BotNet 网络模型并使用该模型做最后的激光点云分类任务。
1 框架
1.1 BotNet 网络框架
BotNet 网络框架是一种基于Transformer 的架构,同时使用卷积和自我注意的混合模型,利用CNN+Transformer 的方式提出一种Bottleneck Transformer 来代替ResNet Bottleneck,即仅在ResNet 框架的最后3 个bottleneck blocks 中使用全局多头自注意力 (Multi-Head Self-Attention,MHSA)替换3×3 空间卷积。该方法思想简单但是功能强大。由于引入Self-Attention 会导致计算量大与内存占用过多,BotNet 在ResNet 框架的最后3 个bottleneck blocks 添加自注意力模块。每个bottleneck 包含一个3×3 卷积,采用MHSA 替换该卷积,第一个Bottleneck 中的3×3 卷积stride=2,而MHSA 模块并不支持stride 操作,故而BoTNet 采用2×2 均值池化进行下采样。传统的Transformer 方法通常使用位置编码,考虑了不同位置特征之间的相对距离,从而能够有效地将对象之间的信息与位置感知关联起来,更适合视觉任务[9-11]。BotNet 采用了文献[9]、[12]中的2D 相对位置自我注意机制。类似于transformer block[3]或None Local block[13]方法。
1.2 基于Light-BotNet 的大场景点云分类框架
为了有效地从三维点云中挖掘有用的信息,采用了CNN 和Transform 结合的BotNet 框架,首先,分别从三维点云中提取这些特征,将得到的特征计算成点云的特征图像[14];然后将它们输入Light-BotNet 网络框架,Light-BotNet 网络框架从点云特征图像中选择有用的信息来对三维点云进行分类。
整体的大场景点云分类网络框架如图1 所示。首先是在三维和二维两个不同的层面上进行点云的特征提取,得到大小[N,32,32,1]的点云特征图像,输入Light-BotNet 网络框架,可以看出总共有4 个网络层块(block),每一个block 的大小为[1,3,1,1],在block_1 中Conv 参数为3×3 的卷积核和Channel 大小为64 的卷积层,block_2 的Conv 参数为3×3 和Channel 为64 的卷积层,block_3 中Conv 的参数为3×3 的卷积核和Channel 为64的卷积层,block_4 的Conv 参数为3×3 和Channel 为128的卷积层,通过这些卷积层可以提取点云特征图像的特征信息,得到一个[128,K]的一维向量,得出分数进而输出分类结果。

图1 基于Light-BotNet 的大场景点云分类框架
本文采用了ResNet50 和BotNet50 网络框架来与Light-BotNet 进行对比,如表1 所示。
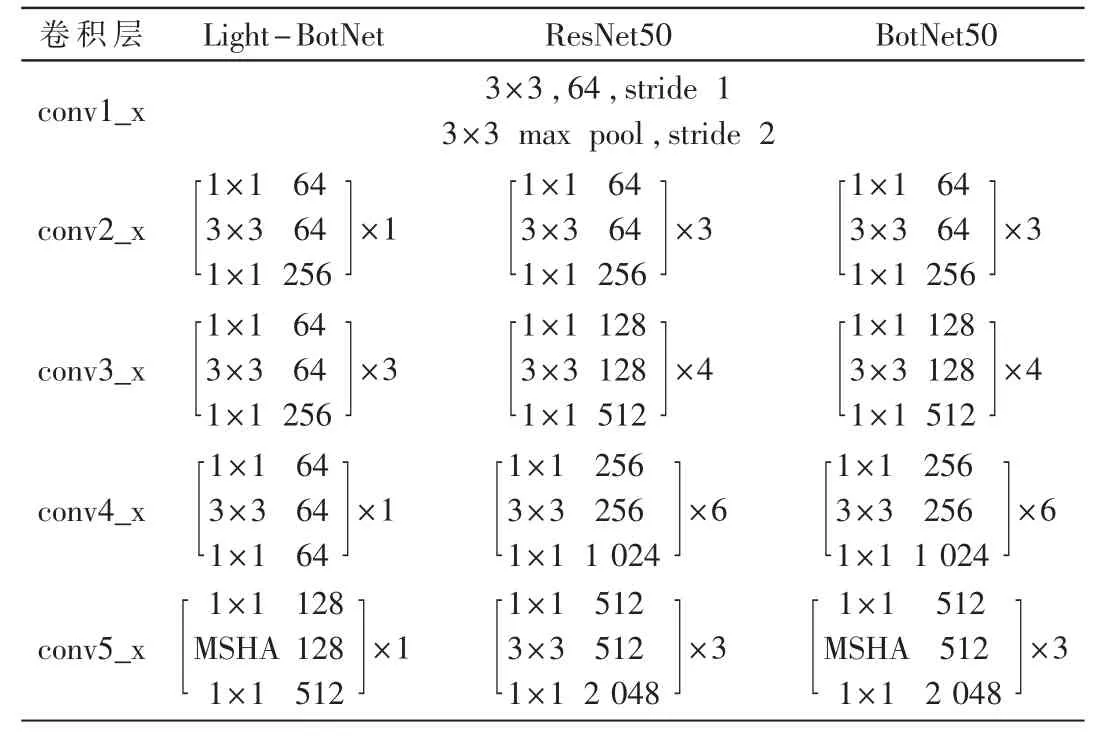
表1 几种不同神经网络框架设计表
2 实验结果分析
本文在Oakland 3D 大场景三维点云数据集上进行实验,以验证基于Light-BotNet 大场景点云分类方法的有效性和鲁棒性,对Oakland 3D 数据集中的实验分类结果进行分析。
在Oakland 3D 三维大场景点云数据集上测试所提出的算法框架,该数据集来源于奥克兰卡耐基梅隆大学的校园周边场景,是使用最广泛的地面移动激光扫描(MLS)所获取的数据集。该数据集主要是城市大场景环境。该数据集包括电线(Wire)、杆(Pole)、建筑立面(Facade)、地面(Ground)和植物(Vegetation)这5 个语义类别,其中每个类别的样本数量如表2 所示。
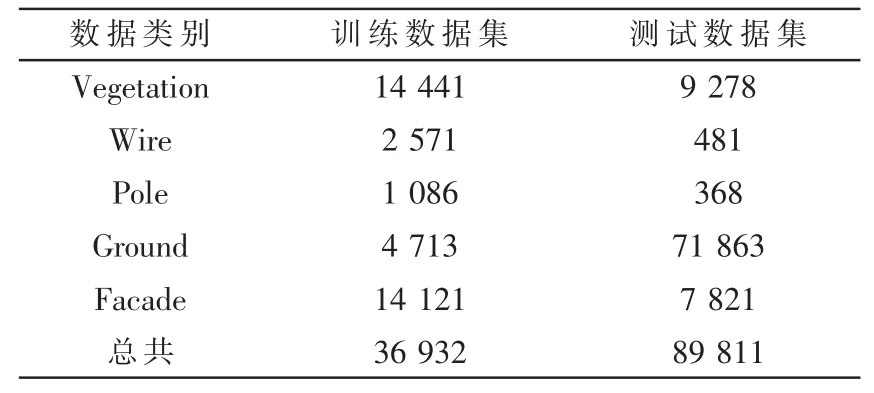
表2 Oakland 数据集
实验运行环境:Intel i7-4790、NVIDIA RTX 2070、8 GB 内存,在Windows10 和Python3.7 下搭建CUDA 10.0、CUDNN7.6.4、PyTorch 0.6 的深度学习环境,初始学习率为1×10-3。
本文在Oakland 大场景三维点云数据集上分类任务的测试精度实验对比如表3 所示,其中OA 表示总体分类精度,在总体分类精度(OA)明显要好于其他文献的方法。实验结果表明,所提出的Light-BotNet 方法在Oakland 数据集上的总体分类精度达到了98.1%,与文献[15]-[19]相比较,如图2 所示的Oakland 3D 大场景三维点云分类结果可视化对比,其中图2(a)是测试集的Ground Truth,图2(b)是算法分类结果的可视化效果。
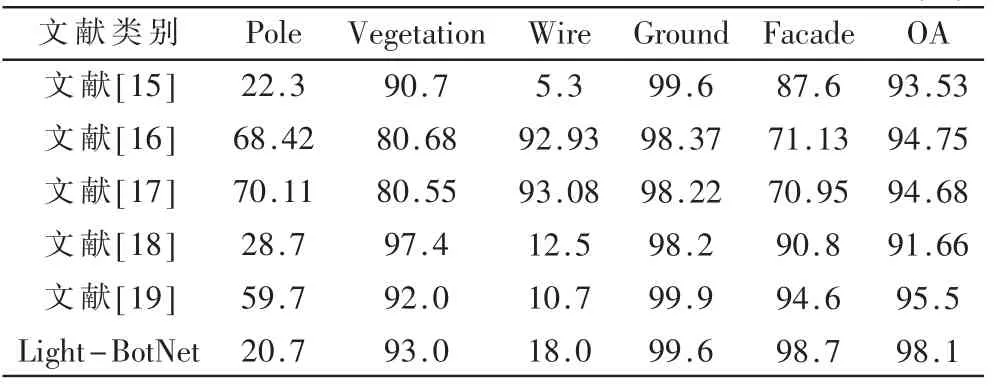
表3 Oakland 数据集对比精度 (%)

图2 可视化效果图
图2 中1 表示地面,2 表示电线,3 表示电线杆,4表示墙面,5 表示植物。
可看到Oakland 测试集上分类后可视化效果与测试集真实标签可视化效果对比。从表3 对比数据以及图2展示的效果来看,电线杆类(Pole)和线(Wire)这两类别的分类精度分别为20.7%和18.0%,与其他的文献相比较差。因为这些类别的点本来就是数据量少,当对这些类别的点进行在x、y、z 方向投影时,这一投影势必会造成部分不同类别的点的重合覆盖,从而影响计算该类点的二维特征精度的计算。但是对于类别的点比较有优势,类别多的覆盖了类别少的点,所以在最终的结果呈现出类别多的点准确率高,类别少的点准确率低。
由于对比方法中涉及Oakland 大场景三维点云数据相关文献[15-19],为了证明本文所提基于通道注意力机制的深度卷积神经网络在时间和效率上的优良性,针对在大场景三维点云的海量数据在训练过程中如何更好地平衡分类精度和实现效率问题,通过对比Light-BotNet与ResNet50 和BotNet50 网络框架在大场景三维点云数据集Oakland 和测试分类的性能与时间复杂度作为评价指标来证明所提算法轻量级框架的优良性,图3 展示的是Light-BotNet 与ResNet50 和BotNet50 网络框架在大场景三维点云Oakland 数据集上随着轮数(epoch)增加对点云分类精度(accuary)的变化。
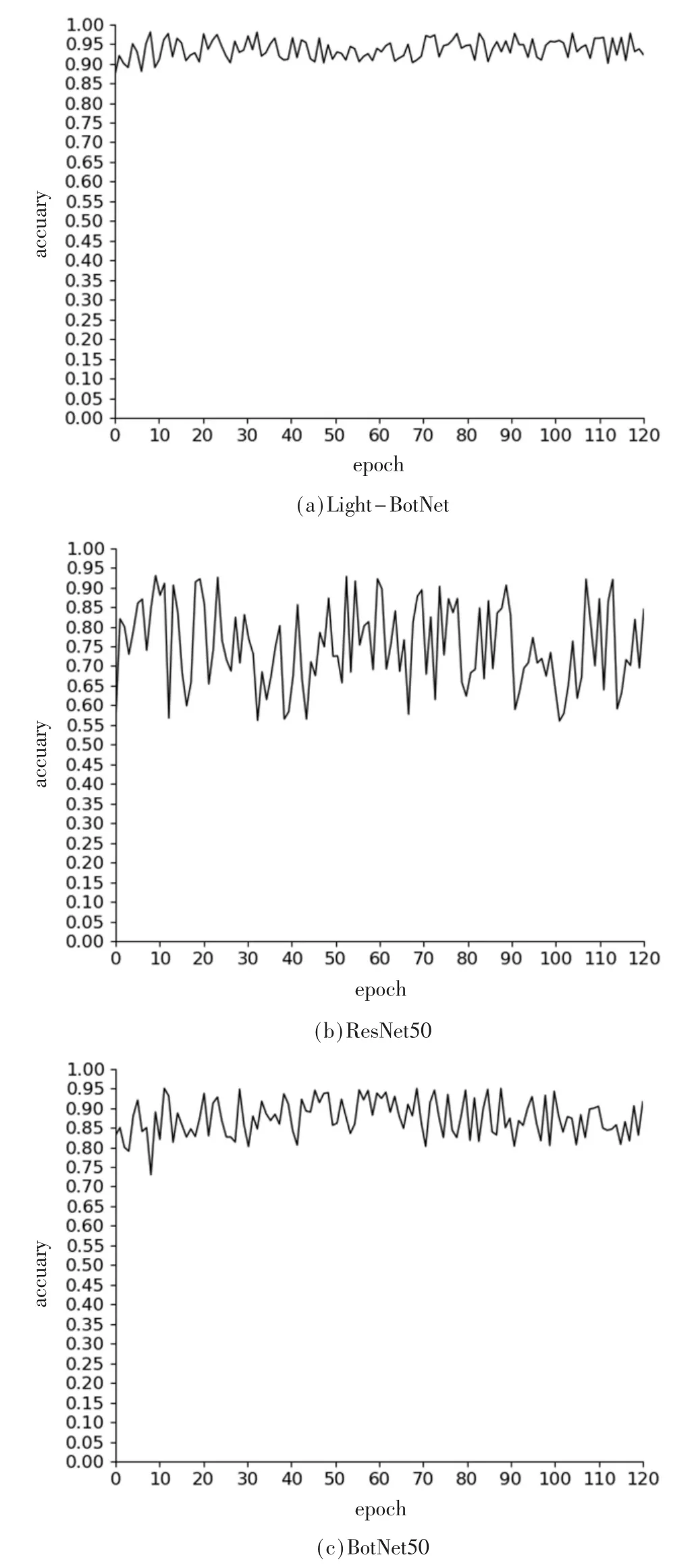
图3 Light-BotNet 与Method_1 和Method_2 分类精度可视化
通过图3 展示的效果可以看出,Backbone 分别为ResNet50 和BotNet50 的网络模型,在分类精度上对比Light-BotNet 比较低,这在很大程度上是因为本文已经对激光点云已经进行了一遍处理,所以在后面使用的网络层模型应该偏向于轻量级的网络模型。本文也同在SVM 和Random Forest 方法上进行验证分类结果,发现在分类结果上能够达到90%左右的效果,在Backbone 为轻量级的网络框架的效果[17]中,也能够取得比较好的效果,虽然ResNet 网络层模型可以适用于在一些比较深的网络模型提取有效的特征,但是可能并不适用于本方法中。从结果可以看出,整体的实验分类结果具有很大的波动性,虽然达到了一个比较好的效果,但是可能存在是研究结果出现过拟合的可能。BotNet50 Backbone 同理可证,在Light-BotNet 网络框架设计上如表1 所示,在整体的网络框架上,相比于ResNet50 和BotNet50 网络框架,在网络层上进行了50%的删减,形成一个相对轻量级的基于CNN 的Transform 网络框架模型、在实验结果上,相比于ResNet50 和BotNet50,整体的分类结果比较稳定,分类精度也高。
对比在Oakland 3D 数据集下Light-BotNet 与Bot-Net50、ResNet50 3 种不同网络框架的分类精度,结果如表4 所示。
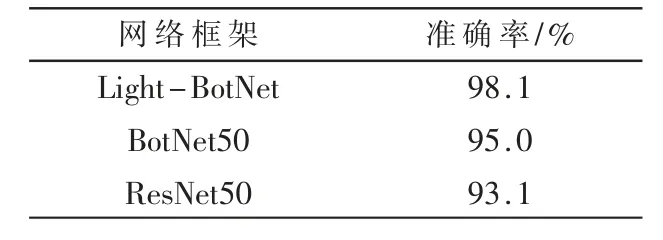
表4 网络框架实验结果对比
对比不同网络的参数,表5 展示了使用的不同网络框架运行点云分类的Flops 和Params 对比。从中可以看出,Backbone BotNet50 与ResNet50 在Flops 和Params 对比上差距不是很大,但是结合表4 来看,牺牲一部分的内存和效率,可以换取到准确率的提升。对比Light-BotNet,Light-BotNet 在Flops 和Params 上都降低近50%的消耗,准确率也是达到了一个很好的效果,通过在同样硬件环境配置下在不同的Backbone 的分类网络框架中进行实验,Light-BotNet 的Flops 消耗与Params 与其他相比都处于最低的效果。
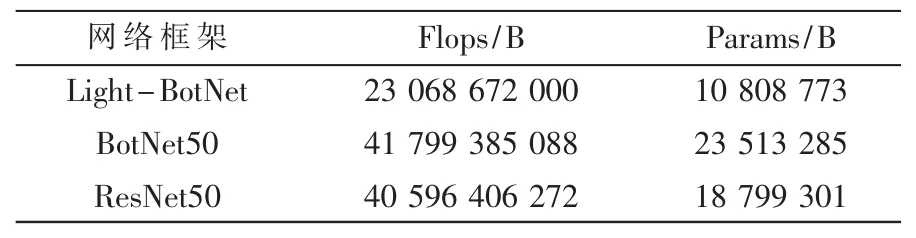
表5 不同网络框架的Flops 和Params 对比
由于对比方法中涉及Oakland 大场景三维点云数据相关文献[15-19],为了证明本文所提出基于Light-BotNet的激光点云分类方法,针对在大场景激光点云的海量数据在训练过程中Light-BotNet 对本框架的影响,本文对比了在本框架和去除掉MSHA 框架的实验结果,如图4 所示,实验证明MHSA 有利于点云分类精度的提高。
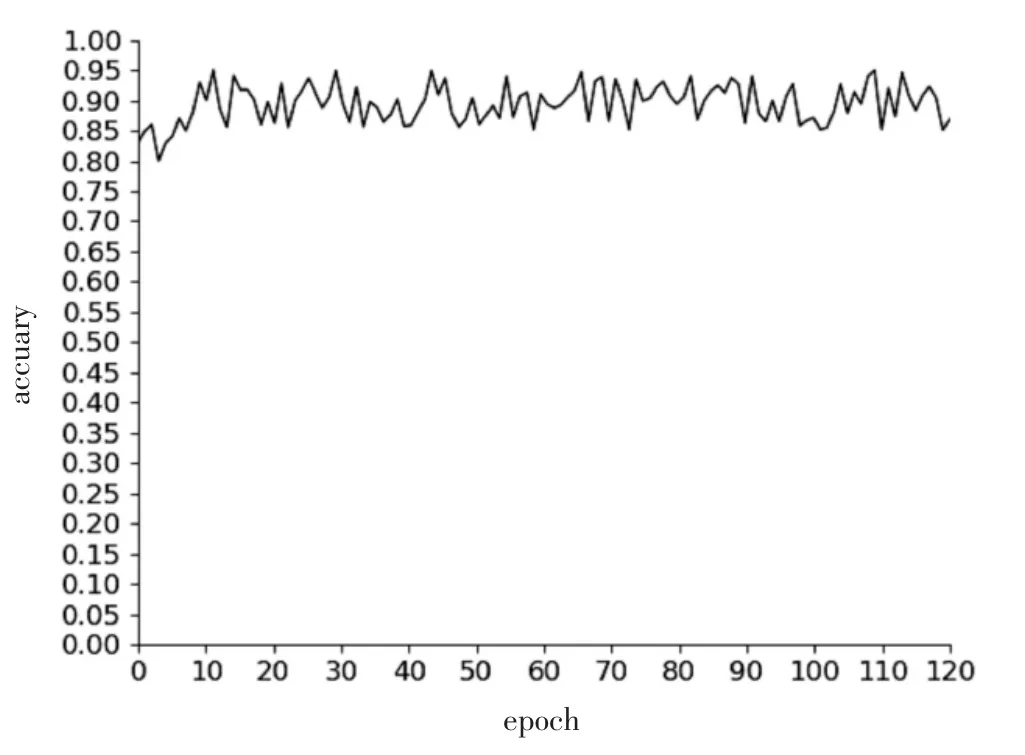
图4 无MSHA 的准确率变化曲线
3 结论
针对大场景三维点云本身数据量巨大,存在计算量大、训练时间长的挑战,设计更为适合三维点云数据处理的轻量级卷积神经网络,在保证分类精度的同时尽可能减少了参数的数量和训练测试时间,使得网络进一步快速收敛以及减少计算量。本文提出一种基于Light-BotNet 低复杂度、轻量级框架,在取到较好的分类精度的基础上减少了训练和测试时间,提升了整个网络框架的性能。但是从每个类别的分类精度来看,对于Oakland 3D 数据集,本方法存在着一些不足之处,对一些数量占比少类别不友好,而对于一些数量多的类别来说,可以达到一个非常好的效果,这是本文存在的一个缺点,需要在以后工作中进行改进。这种问题的出现在很大程度上是因为本文在提取点云特征图像上存在着一些缺点,或许不应该在xoy、yoz、xoz 3 个直平面进行投影,或许应该从一个有利于类别数量少的点的角度进行投影,例如旋转到某一个角度,能够让类别数量少的点受到其他类别少的点的影响尽可能少,这将是未来将继续的工作。在未来工作内容中,也会继续探讨在三维大场景点云数据同等数据容量下,对数据特性分析与提升深度学习框架本身的计算性能。
猜你喜欢
小资CHIC!ELEGANCE(2022年1期)2022-01-11 00:49:59
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
数学物理学报(2020年3期)2020-07-27 01:19:46
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
法大研究生(2017年1期)2017-04-10 08:55:06
新校长(2016年8期)2016-01-10 06:43:59
华东理工大学学报(自然科学版)(2015年2期)2015-11-07 09:16:21
商事法论集(2014年1期)2014-06-27 01:20:42
电视技术(2014年19期)2014-03-11 15:38:20
