
基于1D-CNN-Densenet的恶意代码检测方法
2022-07-20 02:29:08刘晓晨芦天亮杨锦璈
中国人民公安大学学报(自然科学版) 2022年1期
刘晓晨, 芦天亮, 杨锦璈, 杨 明
(1.中国人民公安大学信息网络安全学院, 北京 100038; 2.中国人民公安大学公共安全行为科学实验室, 北京 100038)
0 引言
网络技术的日益发展带来越来越多的网络安全问题,恶意软件如病毒、蠕虫、后门、僵尸网络和特洛伊木马等成为当今影响世界网络安全的一大威胁,其多种多样的攻击手段给人们的生活带来了极为不利的影响。恶意代码对互联网的健康发展产生了严重的影响,甚至对重点行业的关键基础设施造成威胁。McAfee发布报告称,2020年第二季度新发现恶意软件样本数量增长了11.5%,平均每分钟会出现419个新威胁[1]。
随着深度学习模型的发展,API调用序列作为特征处理恶意代码检测不再局限于数据挖掘和传统的机器学习算法[2-3],基于深度学习的恶意代码检测模型中循环神经网络占多数,这些模型比数据挖掘和传统的机器学习方法具有更高的准确性。本文设计了一种1D-CNN-Densenet模型对恶意代码进行检测,主要工作如下:
(1)通过Cuckoo Sandbox动态提取API序列,对获取到的API原始序列转化、去重,对每个API进行十进制编码向量化表示。
(2)统计所有API个数和每一个恶意程序的API个数,通过剪裁和补齐,构建输入到检测模型的矩阵。
(3)设计基于一维卷积和稠密网络结构的1D-CNN-Densenet,提取和学习更深层次的恶意代码特征,进一步提高恶意代码检测模型的准确率。
1 相关工作
1.1 恶意代码分析技术
静态分析和动态分析是恶意代码分析技术的两种常见方法。静态分析不对恶意样本进行执行操作,直接从二进制文件中提取特征,方法简单,效率高,占用资源较少,从特征码、文件完整性、反汇编等方面了解恶意软件的代码、逻辑结构等。廖国辉等[4]从Windows可执行PE文件中提取静态特征分析恶意代码;Natarajf等[5]将恶意代码的二进制文件转化为灰度图像,利用神经网络分类恶意代码;杨频等[6]提取操作码特征构建检测模型;Raff等[7]将恶意代码原生字节序列作为输入,将可执行文件结构通过神经网络学习软件中具有判别力的特征信息;Zhao等[8]基于函数的调用图对恶意代码的变形进行分类检测。静态分析具有局限性,攻击技术的加强,受混淆、压缩、加壳等影响,静态分析的泛化能力变弱,易出现漏报和误报。
动态分析是在隔离环境如沙箱中执行恶意样本,提取样本的动态特征,对新型恶意代码识别率较高。其中分析API调用序列最具代表性,Dahl等[9]根据置信度分析恶意代码的动态API序列进行恶意代码分类;Hyunjoo等[10]使用API调用序列和序列比对算法实现了恶意软件的检测和分类;Abdurrahman等[11]提取恶意代码注册表活动以及API序列等动态特征,构建特征向量,对恶意软件进行分类检测。
此外还有通过静态分析技术提取恶意代码特征,利用动态检测方法识别恶意代码的混合分析技术。Zhao等[12]结合动态和静态特征基于机器学习算法对恶意代码进行检测;Kang[13]等基于word2vec以较少维度分析操作码和API序列,使用分类器分类恶意软件。
综上,无论是静态分析还是动态分析都是通过分析样本的内容以及样本间的关系提取恶意代码的特征并对其进行分类。
1.2 基于API调用序列的恶意代码检测技术
传统的基于特征码的检测受限于混淆、多态的代码。许多研究使用机器学习算法进行恶意代码分析如LR、DT、NNs等。Kolter等[14]使用字节序列N- Gram通过机器学习(如NB、SVM、DT等)构建分类模型对恶意代码进行检测。Saxe等[15]使用神经网络算法对恶意代码进行分类检测。深度学习的卷积神经网络和循环神经网络及其改进的算法在恶意代码检测领域中也有所应用。Kolosnjaji等[16]将提取的特征通过N- Gram和CNN模型将其转换为LSTM模型的输入进行分类。Tobiyama等[17]将API序列和API返回值输入RNN模型中进行恶意代码分类。
API调用序列可以反映恶意代码的运行,可以作为恶意代码检测的特征进行分析。Chen等[18]从PE文件中提取API调用序列;Ravi等[19]将API调用序列用用数据挖掘算法进行恶意代码检测;Hansen等[20]利用RF根据API调用序列和API调用频率对恶意软件进行分类;Ding等[21]标记API序列,提取调用关系,挖掘行为依赖图用于恶意代码检测。芦效峰[22]基于序列数据的长短期记忆深度学习模型对API调用统计特征组合提出恶意样本检测框架。
上述列举的基于API调用序列的模型大多依赖于循环结构,循环结构按顺序处理长数据,处理较长的输入序列性能较低,需要消耗较长的时间和资源,影响恶意代码检测的性能。在这种情况下,本文设计了基于一维卷积和稠密结构的1D-CNN-Densenet模型。
2 模型设计与实现
如图1所示,本文设计了一种1D-CNN-Densenet针对恶意代码进行检测,在Cuckoo sandbox中运行程序动态提取正常软件和恶意代码的行为报告,经过API序列数据预处理[23],将十进制编码映射API序列对其进行补齐和裁剪,向量化输入到1D-CNN-Densenet模型,通过稠密网络式结构,挖掘和学习更深层次的特征,训练和测试模型,从而判断程序是良性还是恶意。
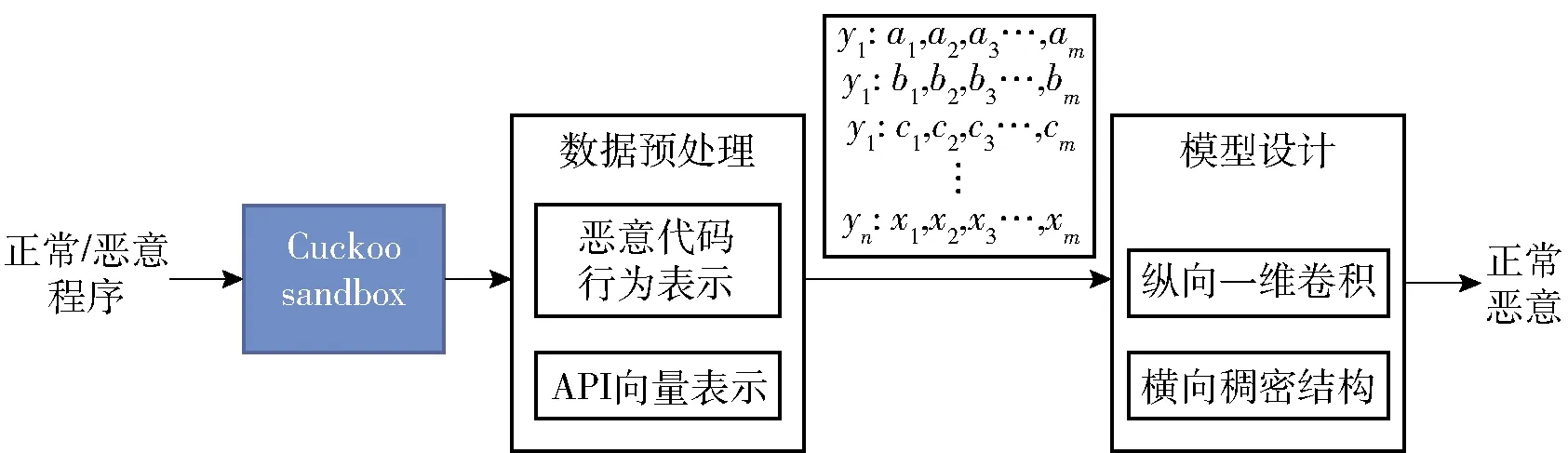
图1 实验流程
2.1 数据预处理
2.1.1 恶意代码行为表示
每一个可执行文件运行程序的行为都可以使用API调用序列来表示,API调用序列的提取可以通过沙箱动态执行程序获得。本文基于Cuckoo sandbox[24]搭建恶意代码分析环境,使用隔离环境自动执行不可信的恶意软件,分析样本提取出进程、网络、文件等动态行为。主机通过Cuckoo sandbox分发恶意样本至客户机并执行恶意代码,Cuckoo sandbox生成多种形式的结果,由于Json格式的报告在跨平台适用性方面较好,且格式规范统一,便于下一步对恶意代码样本行为进行批量处理,因此采用Json格式的报告提取API调用序列并转化为txt文档进行下一步数据处理。
经转化,每一个txt文档代表着一个程序所有的API调用,即一个程序的所有动态行为,其中一行由API类型和API名称两部分组成,表示一个API调用序列。
2.1.2 向量化表示
程序会连续执行类似的操作,因此在分析API调用序列时发现无论正常还是恶意程序,同一个API函数通常被连续多次调用,为减少送入模型的序列的长度,对重复调用的API序列进行去重,删除重复的API调用序列可以避免信息冗余。
将txt文件去重后将每一串字符用十进制编码成[n,m]的矩阵。n为每个程序中API的取值个数,m为每个API的平均长度,本文3.4的预实验中得出结论n的取值为平均个数时效率最高,因此n为每个程序的平均API个数。对每个API长度不足平均长度的补0,大于平均长度的裁剪,将所有API个数不足平均个数的补[1,m]的0矩阵至n,超过n的进行裁剪以保证每一个txt里面的矩阵为[n,m]。
本次实验最终网络输出为(N, 50,22),其中N代表输入数据的批次,是一个由20行20列组成的矩阵;50代表经过裁剪和补齐的行数,即每一个txt里有50个API。22代表API编码化后的平均列数,即每一个API编码化后的向量长度为22。
2.2 1D-CNN-Densenet模型
2.2.1 模型设计
本文设计了一种融合一维卷积和稠密结构的模型:1D-CNN-Densenet模型,此模型包含了两部分:一维卷积和稠密结构,横向进行一维卷积计算,纵向构建稠密结构网络,每一层的输入都是前面所有层输出的相加。本文采用的基于深度学习的恶意代码检测程序能够自主学习恶意代码的深度特征,对测试集的恶意代码样本进行分类。
(1)一维卷积网络
一维卷积在单方向上滑动窗口并相乘求和,常用于序列模型、自然语言处理领域,对本文恶意代码序列预处理后的数据处理效果较好。将处理过的恶意代码API序列向量表示为矩阵,输入到模型中,如图2对矩阵横向做一维卷积,一个n×m的矩阵经一维卷积计算为n×1的矩阵,恶意代码特征数据在卷积层进行学习和训练,同时数据经转置为(N,1,n)。
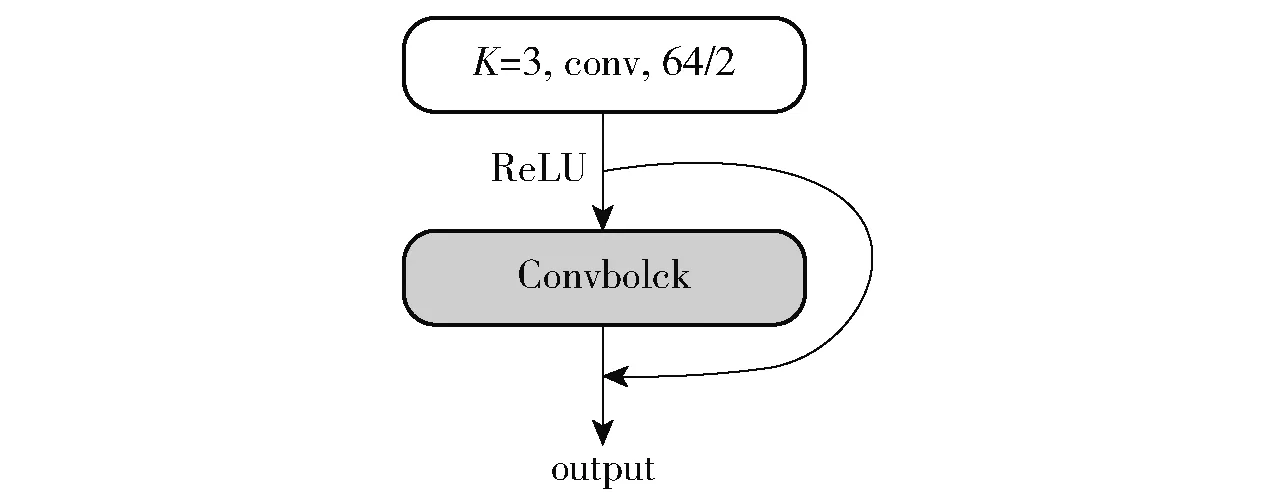
图2 一维卷积网络
(2)稠密结构
卷积层的加深可以提高分类模型准确性,但随着卷积层增多、计算量增加,梯度消失等问题随之而来,准确率反而会受到影响,因此引入跳跃连接嵌套稠密卷积网络的稠密结构,稠密网络[25]的结构每个层都会接受其前面所有层作为其额外的输入,能很好地学习恶意代码更深层次的特征如式(1),通过加深网络层数提高分类准确性的同时,跳跃连接[26]即式(2)对于解决梯度消失、改善梯度反向传播、加快训练过程效果较好。
xl=Hl([x0,x1,…,xl-1])
(1)
y=H(x,WH)+X
(2)
以上的优点融合有效地提高了分类检测的准确性。一维稠密网络的输入(1,n),特征通过包含17层卷积层和1层全连接层的18层稠密结构网络,稠密结构的稠密块使用跳跃连接使得网络层数加深也不会出现梯度消失问题,卷积层能够向更深发展,提取和学习更深层次的特征,提高恶意代码检测的准确性,1D-CNN-Densenet的稠密结构及其内部的卷积块如图3所示。
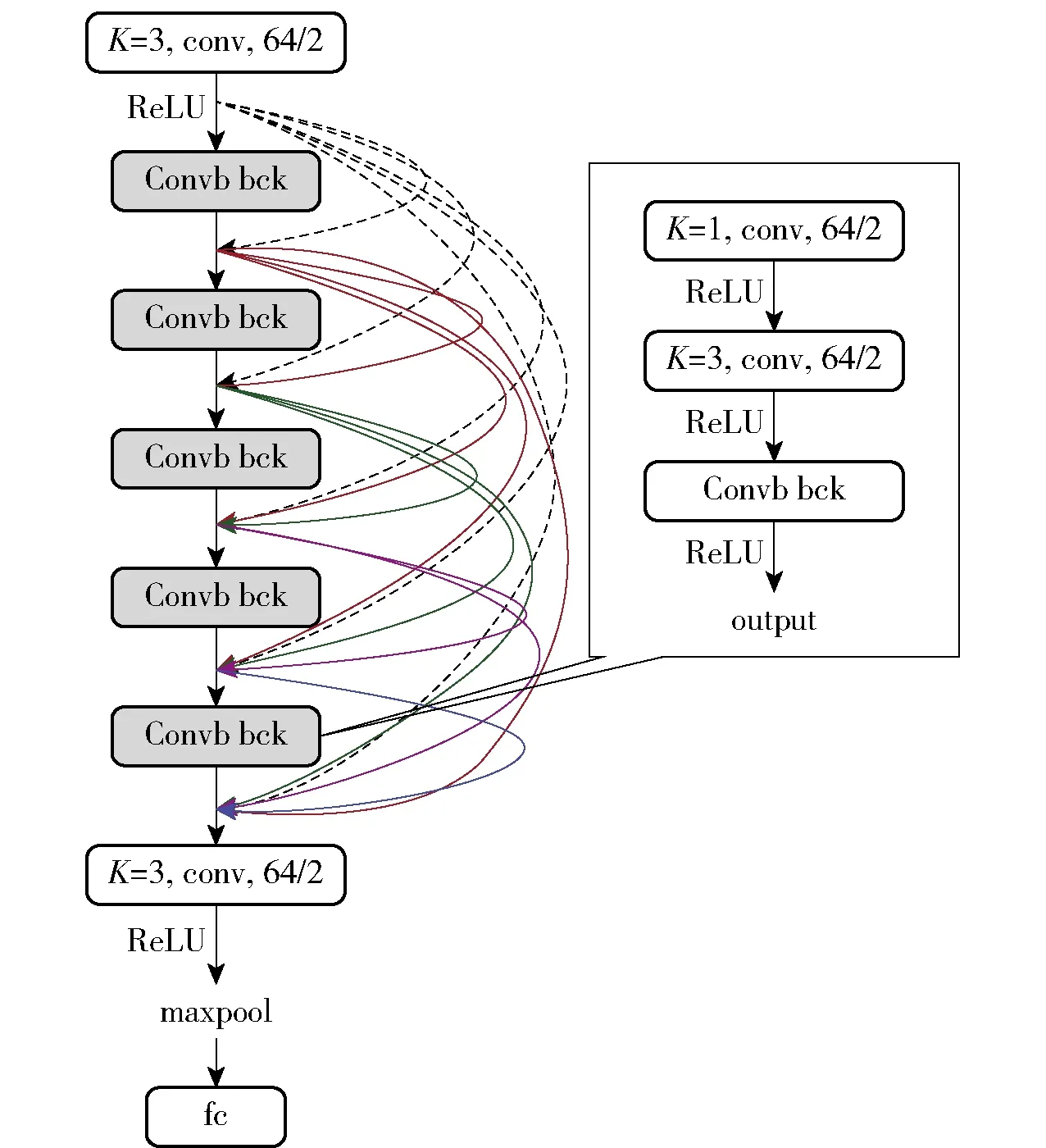
图3 稠密结构
2.2.2 模型优化及训练
本文设计的1D-CNN-Densenet模型在选取激活函数时考虑到ReLU函数可以增加神经网络模型的非线性,提升分类的准确性。且该激活函数计算简便,没有复杂运算,消耗资源少,收敛速度快,提高检测效率,于是选取此函数作为激活函数。ReLU函数契合神经网络激活机制,贴近深度学习模型,能更好地挖掘恶意代码特征,拟合训练数据,取得更好的效果,公式如(3)。
ReLU(x)=max(0,x)
(3)
神经网络模型参数的优化需要优化器来调整,模型学习和训练参数在优化器的优化下得到更新,这充分地挖掘模型的潜力,使分类检测取得更好的效果。本文为了提升模型的准确性,通过对超参数进行对比实验选择Adam优化器[27]优化模型参数。该优化器可对学习率的动态调整且实现简单,计算效率却很高。Adam优化器每次迭代的学习率都有确定范围,因此参数比较平稳,不需要调整,对大批量数据的优化优势明显。
根据训练模型的经验,本文采用的稠密结构包含了17个卷积层和1个全连接层。每个卷积层的各单元之间共享训练参数。使用dropout避免过拟合问题[28],dropout设置为0.7,为了更好地估计模型在新数据集上的错误率,采用十折交叉法验证线性核函数的分类准确率,每次留一份数据作为测试集,其余数据用于训练模型。模型的参数对于大批量的恶意代码检测能发挥其优越性。
3 实验结果与分析
3.1 数据集
实验数据中Windows平台恶意代码样本的收集使用网站http:∥virusshare.com[29]以及http:∥www.malware-traffic-analysis.net[30],正常样本的收集是Windows操作系统中的正常应用程序,且经VirusTotal[31]检测扫描确认无恶意。将分类错误的恶意样本和正确样本剔除,以保证样本的纯净。实验数据通过在虚拟环境Cuckoo Sandbox中模拟运行正常和恶意的样本,获取分析报告,提取其API调用序列。为保证正负样本比例近似为1∶1,恶意样本取5 000,正常样本取4 975,其中70%的样本用于模型训练,30%的样本用于测试,筛选后的数据集样本分布如表1所示。
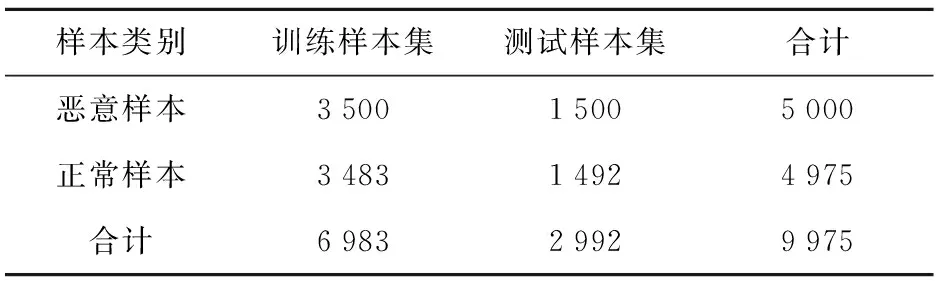
表1 数据集样本分布
3.2 实验环境
本实验环境为Ubuntu 16.04 LTS,依托编程语言Python实现,运行环境为PyCharm,算法的实现由TensorFlow深度学习框架完成。其中Cuckoo Sandbox提取API序列运行环境为Ubuntu 16.10,虚拟机环境为Windows 7。
3.3 评价指标
为分析该模型的恶意代码检测效果,本实验使用以下评价指标来评价模型的效果:准确率(accuracy)、精确率(precision)、召回率(recall)。
本实验解决样本基于深度学习模型的二分类问题,因此实验结果会出现以下4种情况:
TP:正常样本被算法分类为正常样本;
TN:恶意样本被算法分类为恶意样本;
FP:恶意样本被算法分类为正常样本;
FN:正常样本被算法分类为恶意样本。
其混淆矩阵如表2:

表2 混淆矩阵
准确率是指输入到所设计的分类模型中所有数据中分类正确的数据个数:
(4)
精确率是指输入到所设计的分类模型中分类为正常样本的数据个数中分类正确的数据个数:
(5)
召回率是指输入到所设计的分类模型中真实为正常样本的数据个数中分类正确的数据个数:
(6)
3.4 实验结果与分析
为评估设计的模型对恶意代码检测任务的有效性以及所提出的设计和设置的影响,包括API序列预处理方法、超参数设置以及评估所提出模型的性能。
首先,为在数据预处理阶段选取更好的网络输入矩阵进行预实验,以此决定编码后的每个程序中API的个数,以评估所提出的数据预处理的效果。经统计,每个程序API个数的平均值为50,去重后的API个数最大为156。预实验阶段,取不同的API数据长度进行实验,分别取30、50、70、90、120、150,通过准确性评估训练后的模型。结果如图4。
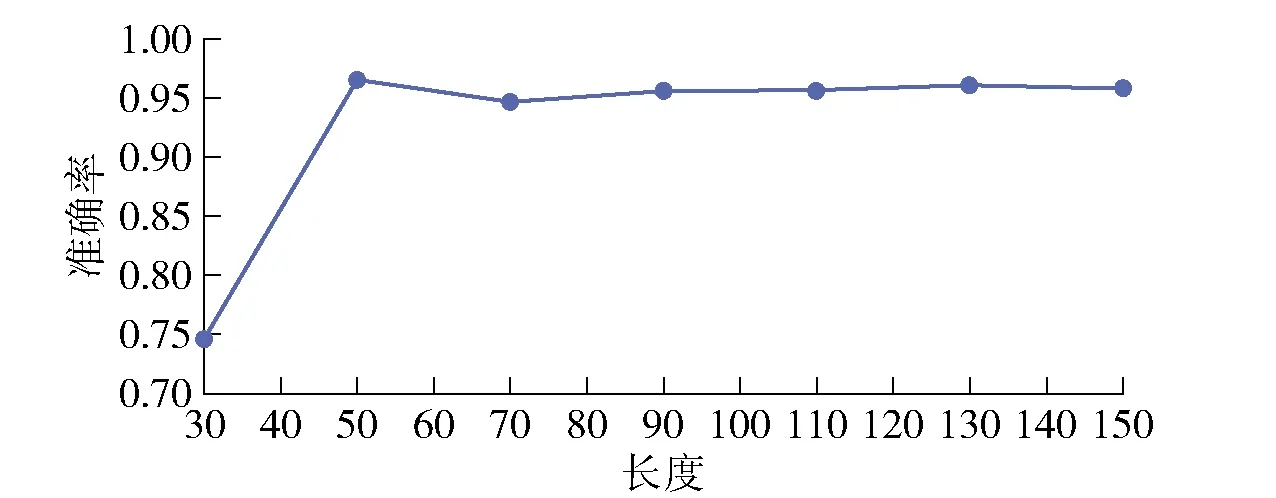
图4 API个数取值对准确率的影响
由图4可知,当API的个数取到50及以上实验结果趋于平缓,且API个数为50时预实验效果最好,这表明当每一个程序里的API个数取到50时,模型能学习到更多的特征,可以有效地提高此模型的性能,同时保证了模型效率。因此,在以下所有实验选取50个API个数作为模型输入。
进行实验以选择模型的超参数值,控制其他变量,通过准确率、每个epoch的用时来评估不同的设置,其中对于重要性较低的超参数不做讨论,结果如表3所示。
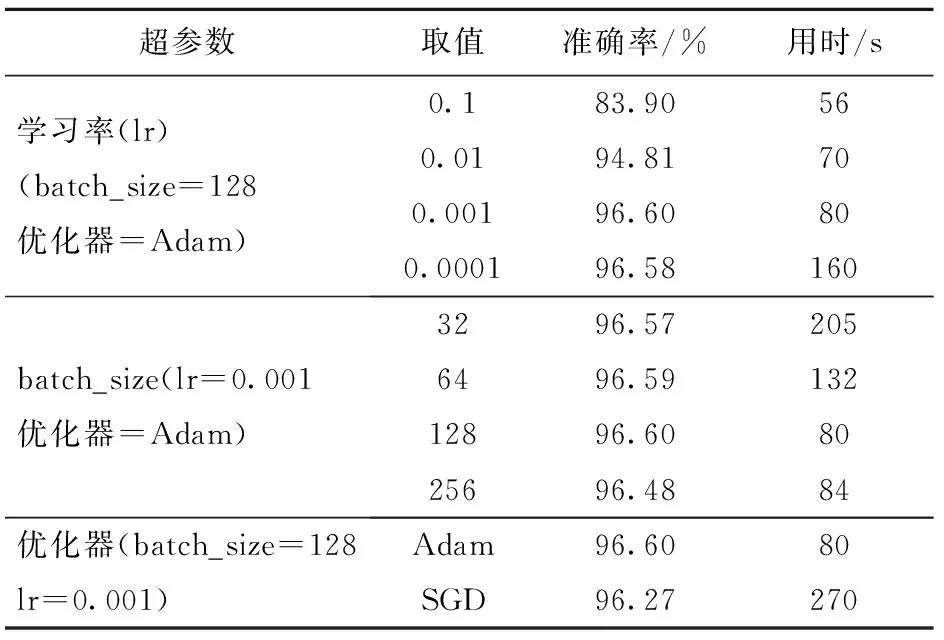
表3 不同超参数的影响
作为深度学习模型中的重要超参数之一,学习率(lr)对目标函数收敛到最小值起决定作用。合适时间收敛到局部最小值是选取学习率的标准。如表3所示,当lr取0.001时模型收敛到局部最小值的时间和准确率最佳。batch_size表示模型模块能够接受作为输入的长度,序列越长,分裂越少,但训练成本却会增加。如表3所示,尺寸增大至128效果最好。在优化器的选择上Adam的效果和效率均比SGD要高。
为验证本文所提1D-CNN-Densenet模型对于恶意代码检测的有效性,本文还进行了不同模型的对比实验,选取SVM、DT、RF 3种传统的基于机器学习的恶意代码检测方法,CNN、LSTM、LSTM- ATT、Ghostnet 4种深度学习算法的恶意代码检测方法在不改变运行环境的基础上,使用同样的数据集对它们进行控制变量的对比试验,实验所得的结果如表4所示。
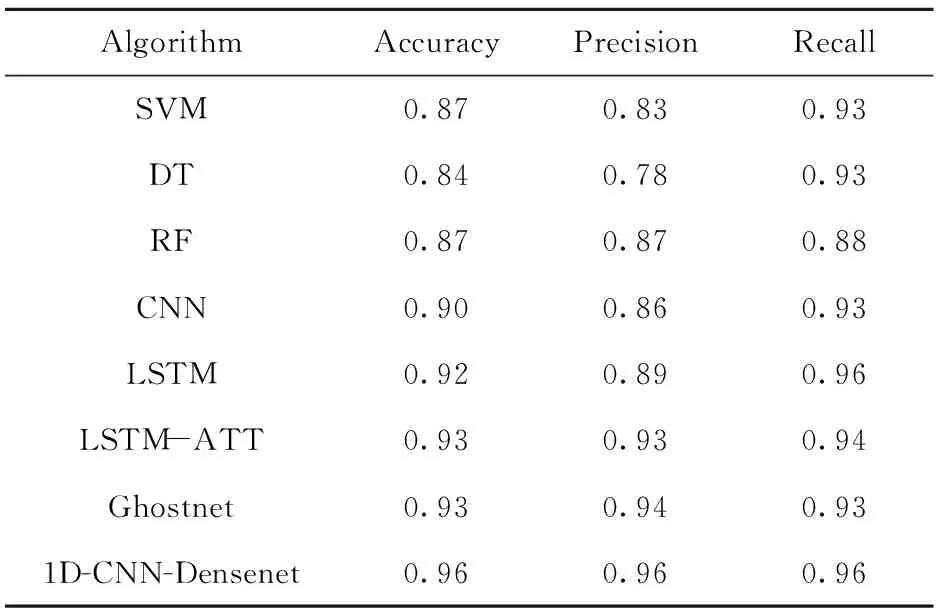
表4 不同模型对模型的评价
上表列出上述模型的检测准确率、精确率和召回率。模型1~3是基于传统机器学习算法对文本特征进行分类,模型4~7是基于现有热门的深度学习算法对文本输入进行分类的,通过两组模型对比可以得出结论,在机器学习算法中随机森林在3种评价指标中的结果较稳定,但召回率较低,在现有的热门深度学习算法中添加注意力机制的LSTM模型和Ghostnet模型在3种评价指标中的结果较稳定,但同样召回率较低,同时可知当使用API调用序列作为文本特征输入时,深度学习模型的性能优于传统的机器学习模型。模型8结果与模型4~7的对比表明了本文设计的模型带来了可观的性能改进。从以上结果可以得出结论,1D-CNN-Densenet模型具有最高的准确率、精确率、召回率,因此其性能优于表中的其他模型。
4 结语
本文针对依赖于循环神经网络的基于API调用序列进行恶意代码检测存在按序处理长数据性能低、消耗时间长,影响检测效果等问题,提出了一种基于API序列和卷积神经网络的恶意代码检测方法,设计了基于1D-CNN-Densenet的网络模型,通过沙箱动态提取的恶意代码特征,编码处理动态API调用序列,输入到基于1D-CNN-Densenet的网络模型,学习恶意代码更深层次的特征,从而进行模型的训练和测试。从实验结果可知,对比传统的神经网络、循环神经网络和图像分类网络等,在相同恶意代码数据集情况下,1D-CNN-Densenet模型在恶意代码检测方面有更高的准确率和效率,性能更好。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
小学生学习指导(低年级)(2021年9期)2021-10-14 07:57:00
商品与质量(2019年34期)2019-11-29 03:25:51
中学生数理化·七年级数学人教版(2019年10期)2019-11-25 07:34:00
小学生学习指导(低年级)(2019年9期)2019-09-25 07:43:28
电子制作(2019年11期)2019-07-04 00:34:38
测控技术(2018年5期)2018-12-09 09:04:46
小学生学习指导(低年级)(2018年9期)2018-09-26 05:59:46
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
信息安全研究(2016年4期)2016-12-01 06:07:05
