
基于TF-IDF与用户聚类的推荐算法
2022-07-20 02:34:28林振荣黄虹霞舒伟红刘承启
计算机仿真 2022年6期
林振荣,黄虹霞,舒伟红,刘承启
(南昌大学信息工程学院,江西 南昌 330031)
1 引言
在一些协同过滤算法中,物品或其他用户之间的相似度系数计算常是影响推荐效果的重要因素。通常在数学研究中,余弦相似度和皮尔森系数是较为常用到的计算公式。但是由于用户-物品矩阵存在数据稀疏等问题,使得上述相似度计算方法存在着相似度失真的现象,进而导致推荐结果不准确,很大程度上影响了用户体验。
为了提升用户对推荐物品的体验感,近年来,随之提出对相似度计算改进的理论逐步增多。张俐提出的一种自适应局部和全局融合的协同过滤算法理论,通过增加自适应加权系数来提高用户之间相似性度量的准确性。柯翔敏和陈江提出一种改进的基于兴趣相似度的推荐算法,提出了逆流行度和共同兴趣2个定义,通过对用户兴趣权重采用事物流行度进行分配,并将用户共同偏好的事物数量运用到相似度计算中,建立一种新的推荐模型。程小林和熊焰将基于物品与基于用户的两种推荐方法进行融合,通过利用预测置信度进行加权得出结果,该模型的优点是使得推荐的准确度提高了,但同时也带了时间等资源消耗的问题,在实际生活中难以运用。
综上可以看出,很多推荐算法的研究都试图从各个方面对相似度计算进行改进,但是对物品特征的考虑不足,即物品具有的特征对相似的程度是有影响的,不能够单纯只考虑用户对物品的评价信息。例如在日常生活中,人们对于同一类商品中,不同品种的商品喜欢某一类是具有一定偏好的,比如在购物时,用户对某一色彩更加喜爱,在选择时往往偏向于购买该色彩的商品。基于上述的思考,本文将充分的利用物品的特征信息,建立相关模型。
本文在先介绍熟知的基于用户的推荐算法之后,接着介绍提出的基于TF-IDF(term frequency-inverse document frequency,Inverse Document Frequency词频-逆文本频率指数)与用户聚类的推荐算法:通过介绍TF-IDF算法,用该算法计算得到用户-物品-特征TF值矩阵,使用该矩阵与用户身份属性信息合并后进行聚类,产生较小的用户数据集,紧接着计算物品特征的TF-IDF值,利用该值通过加权的方式修改评分数据用来改进相似度计算公式;最后,为用户生成推荐列表。然后,进行相关的实验去验证所提出的算法模型。最后总结了本文的工作和研究展望。
2 基于用户的协同过滤推荐算法
基于用户的协同过滤算法的思路是通过收集目标用户以往对物品进行过评价的数据,分析出目标用户感兴趣的项,并将此信息与其他用户的此类信息进行比较,找出与目标用户兴趣相似的用户,互相之间可以进行物品推荐。其算法步骤主要有2个:
1) 比较目标用户与其他用户兴趣的相似程度,得到与目标用户相似的用户集合
2) 在相似用户集合中,通过一定的比较方法,将相似用户偏好的物品推荐给目标用户。
2.1 数据集描述
为了更好的说明用户之间的相似程度,将用户对物品的感兴趣程度具体转化为评分指标。假设用户-物品之间的关系R
*如下表所示,表中m
是用户个数,m
={x
,x
,x
…x
},n
是物品数,n
={i
,i
,i
…i
}。用户-物品评分矩阵的数据表示用户对物品的打分值,取值为区间[1,5]的整数值,值越高,意味着用户对该项更加喜爱;0值则表示该用户未进行评分,见表1。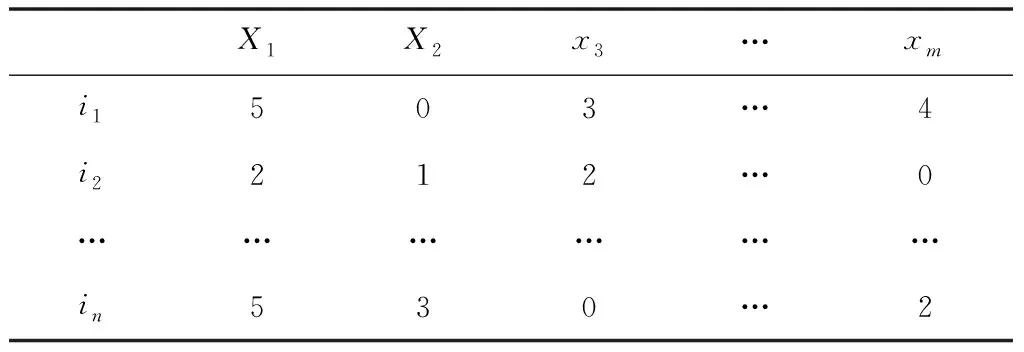
表1 用户-物品评分矩阵
2.2 相似度计算
在上文介绍到的算法中,找到兴趣相似的用户集合至关重要,普遍研究中,使用到的是余弦相似度计算。其计算公式使用下列式(1)所示。该公式需要筛选出需要进行比较的用户x,y共同评分过的物品集合n,i表示物品集合中具体的某个物品,r,r分别表示两者对物品i的评分值。

(1)
由于上式计算结果大小意味着两用户之间的相似程度高低,因此,对用户集合通过相似度公式计算后得到的多个结果进行降序排序,并选取一定数量的用户,便可以组成相似用户集合m。
2.3 预测评分得出推荐物品给目标用户
在得出相似用户集合m后,定义Δ
n为目标用户需要预测评分的物品集合,Δ
n={i,i,i……},使用下列式(2)将Δ
n中的物品依次进行评分值预测。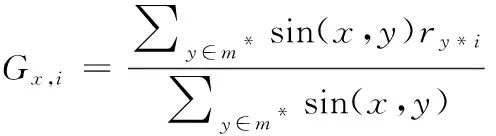
(2)
式(2)中sin
(x,y)为目标用户x与用户集m中用户y之间的利用式(1)计算得到的值,r是相似用户y对集合Δ
n中物品i的实际评分值,结果值G是目标用户预测值。目标用户利用式(2)在对集合Δ
n中所有项预测之后,预测评分值越高意味着目标更容易感兴趣,将该值降序排序,其相对应的物品取排序较前的N个即TOP-N项进行推荐。3 基于TF-IDF与用户聚类的推荐算法
上文中在利用余弦相似度计算得出了相似用户集时,该方法只考虑用户对同一物品进行打分,而忽略了用户之间身份属性信息的相似度;并且在推荐某个物品时,没有充分考虑到该物品特征的重要性,基于上述的问题,本文将提出相应的方法予以解决。
3.1 相关数据集
首先为建立用户-物品-特征数据集,需要收集物品所拥有的全部特征及某用户所评分过的物品所具有的特征。
假设收集到的全部物品所拥有的特征个数为F,用户评分过n个物品;当该用户评分过的物品不具有该特征时,值为0;值为1则表示物品具有该特征。
因此,某用户所具有的用户-物品-特征数据集可以用一个向量表来统计,其值如表2所示。

表2 用户-物品-特征数据集
3.2 TF-IDF算法
TF-IDF是一种统计方法。TF是词频,表示在一份文章中统计某一个词出现的频率。求解某个关键词w的TF值需要两个重要参数:一是规定的关键词w出现的次数;二是该文档的总词数。将这两个参数相除便可以得到结果。其公式如下式(3)所示。

(3)
为了更好的将文档之间类别进行区分,如果包含关键字w的文档较少,则意味着关键字w具有良好的类别区分能力。用IDF(逆文本频率指数)概念来解释,该值的计算方法是假设在一个文档库中,统计包含关键字w的文章数目,并且也统计该文档库中文章总数,按照下列式(4)进行计算:

(4)
对于关键字w,如果其预测主题的能力越强,其权重也随之增强,反之,一个较弱的关键词所具有的权重就越低。由此计算一个词的TF-IDF的式(5)如下所示
(TF
-IDF
)=TF
*IDF
(5)
根据上述TF-IDF的定义,在本文中为了充分利用用户所评分过的物品所具有的特征,设S为某一物品所拥有的全部特征个数,对于某用户评分过的所有物品中某一特征w的TF式(6)如下:

(6)
式中num
(w
)表示在用户评分过的物品中,物品特征w
出现的次数,∑num
(s
)表示物品全部的S
个特征出现的次数之和。TF
为物品特征w
在所有评分过的物品中出现的次数除以用户评分过的物品全部的S
个特征出现的总次数,该值可用来表示目标用户对于某一特征的偏好。TF
值大小与用户感兴趣程度呈正相关。运用该式(6),结合上文所说的用户-物品-特征数据集,由此便可以获得用户-物品-特征TF
值矩阵。同样对于目标用户所评分过的所有物品中某一特征w
的IDF
定义式(7)如下:
(7)
该公式能得到物品的代表特征,更好地将物品之间做区分。计算方法是先统计某一用户评分过的物品总数,在其中统计包含特征w
的物品数,根据上述公式计算后便可以得到该特征的IDF
的值。根据式(6)(7),对于某用户来说,其所评分过的物品含有的特征的TF
-IDF
值式(8)如下P
=TF
*IDF
(8)
式中P
为特征w
的TF值与IDF值乘积,根据以上公式,用户评分过的物品特征都可以计算出该特征的TF
-IDF
值P
。3.3 融合物品特征TF值的用户聚类
本文对用户采用融合物品特征TF值的聚类方法去为目标用户缩小需要比对用户集合数目,做法如下:将用户身份属性信息及上文提到的用户-物品-特征TF值矩阵合并,采用K-means算法进行聚类分析。
该算法的流程图如图1所示。

图1 算法流程图
3.4 改进相似度的算法
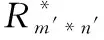
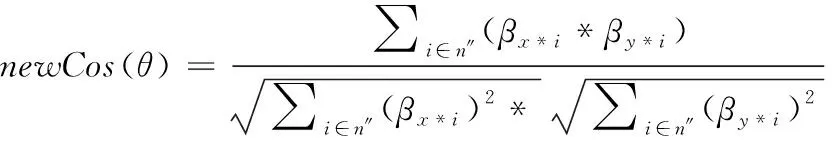
(9)
其中β
*=∑∈P
*r
*在上式中,类似地,在n
′中找到共同评分过的物品集合,该集合设为n
″,n
″={i
,i
,i
…},F
则表示集合n
″中每个物品i
所含有的特征个数,F
={f
,f
,f
…},P
表示该物品每一个特征TF
-IDF
值。β
*等于该物品所具有的每一个特征的P
值求和,再乘上用户的原始评分r
*。同理可得用户y
的改进后β
*。最后,在计算得出相似度值后,需要修改评分预测公式,将P
值添加进上文的式(2),推出新的式(10)如下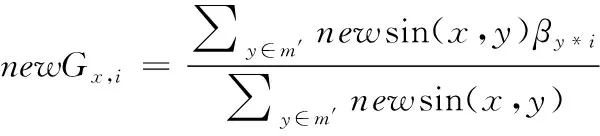
(10)
new
sin(x
,y
)为上文式(9)所求得到的相似度值。同样,选取N
个排序较前的物品形成了TOP-N项,将TOP-N项进行推荐。4 实验分析与结果
4.1 实验环境与数据集
本文的实验环境如下:ASUA笔记本,8G内存,8核处理器,win10 64位系统旗舰版。
本文实验采用的是Grouplens网站上发布的MovieLens-1M数据集,该数据集包括了users,movies,ratings.dat三个数据文件。在文件movie.dat文件中对电影的类型已经做好了类别区分,该分类有效的区分了各种电影,所以,可以将所有特征的IDF值都设为固定值。
4.2 实验评价指标
1) 精确度(Precision)
精确度是指在TOP-N项中,将用户所感兴趣的物品个数与推荐物品个数N的相除计算得到。精确度值可以用来衡量推荐性能的高低,并且二者呈正相关。
精确度计算式(11)如下
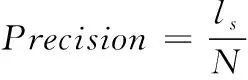
(11)
式中,l
由用户感兴趣的物品与TOP-N中取交集后产生的个数。2) 召回率(Recall)
召回率是指在TOP-N项中,将用户感兴趣的物品数量与TOP-N项中用户感兴趣物品数量相除计算得到。并且召回率与推荐性能呈正相关。召回率计算式(12)如下:
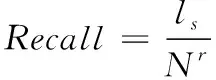
(12)
式中,N
表示在TOP-N项中,用户感兴趣的物品数。3) F-Measure
在使用评价指标精确度和召回率时往往会出现相矛盾的情况,通常会分析F-Measure曲线来综合考虑它们之间的关系。可用F-Measure来衡量推荐的性能高低,并且该值越大,说明推荐的性能越优。F-Measure的计算式(13)如下
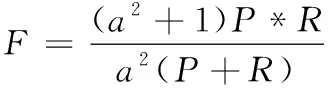
(13)
通常使用的F1就是当参数a取值为1时,其式(14)如下
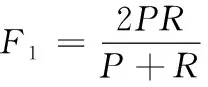
(14)
4.3 实验分析
本文中实验采用TOP-N方法进行推荐。实验分为训练集的60%和测试集的40%。
实验过程主要分为二大类:
1) 参数对推荐模型的影响
利用K-means算法得到不同簇的情况下,相邻用户一定时K=35(这里K指与目标用户相邻的用户个数),推荐列表的长度变化的影响。

图2 簇为5的TOP-N折线图
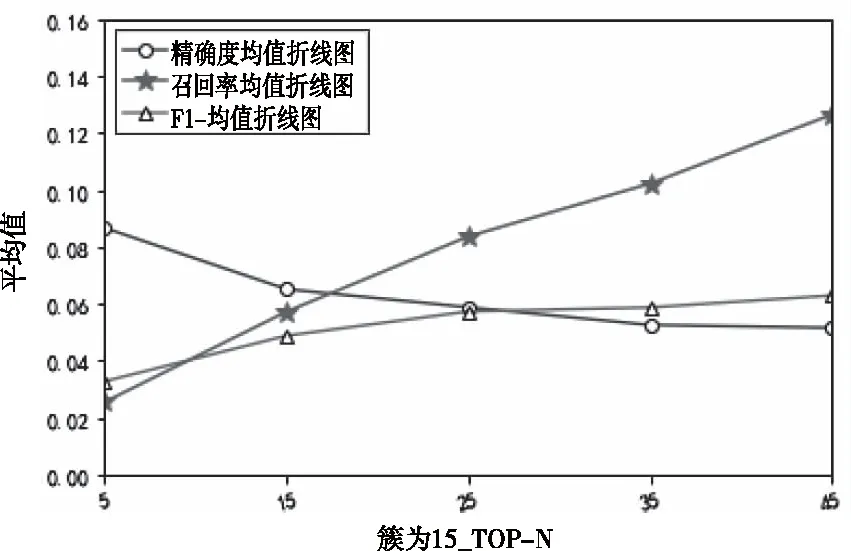
图3 簇为15的TOP-N折线图

图4 簇为45的TOP-N折线图
由图2,图3,图4可知,在聚类所分簇数一定的情况下,随着TOP-N的数目增加,精确度在不断的下降,之所以产生这种现象,是因为随着推荐数目的增多,系统将会把排序越后的物品也进行推荐,但该物品极有可能是目标用户不喜欢的物品。但是,召回率在不断上升。因此,采用观察在所分簇数不同的情况下各图F1值,由图2,图3,图4可知均呈上升趋势。由此可以推出,各簇的推荐准确度不断上升。
如图图5是簇为5、簇为15和簇为45的情况下,各F1值比较图线。由图5可以推出,随着聚类所分的簇数越多,所产生的F1值在推荐数目大于15个之后,逐渐上升,推荐效果越好。因此,可以得出通过用户身份属性及用户-物品-特征的TF值矩阵所产生的聚类生成簇数越多的情况下,形成的比对用户集中需要比对的数目越小,更能够为目标用户找到相似的用户,再利用改进后的融合物品特征的相似度计算公式,其最终产生的推荐效果更优。
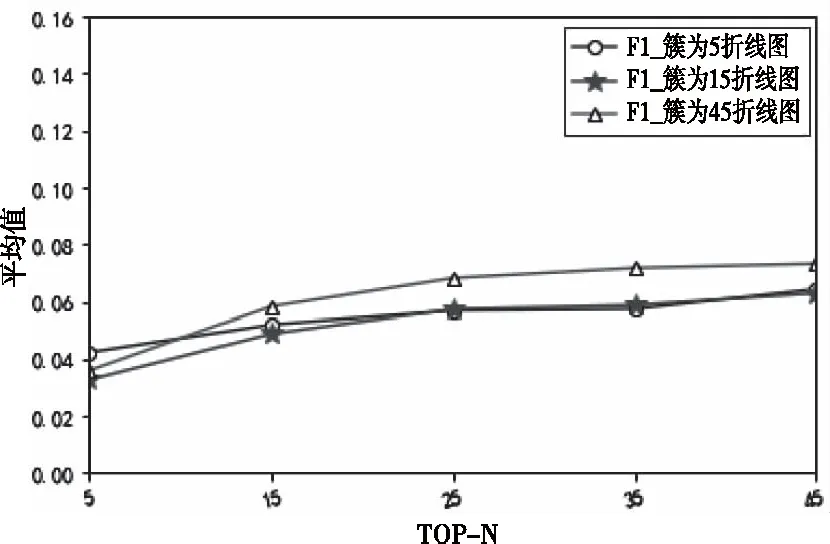
图5 不同簇的F1折线图
2) 与传统协同过滤方法的比较
将比较本文提出的方法在不同簇的情况下与传统的余弦相似度的方法进行F1值的比较。图6中是聚类所分簇为5、簇为15和簇为45的F1值随推荐数目不同的曲线与该情况下余弦相似度F1值得到的F1-cos 曲线。根据图6可以得出,在TOP-N取值逐步上升时,本文所分簇类F1值均高于传统的余弦相似度的计算。
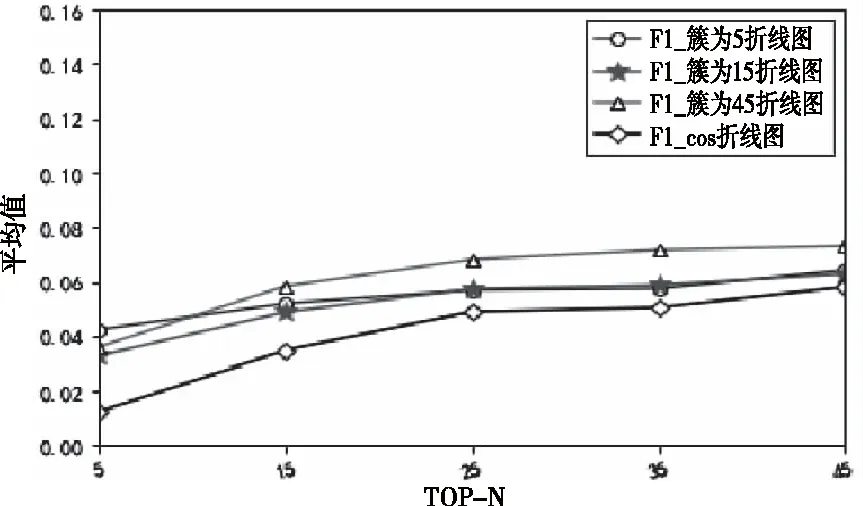
图6 不同簇的F1值与传统协同过滤方法的比较折线图
5 结束
通过实验可以得出:本文提出的一种基于TF-IDF与用户聚类的推荐算法,在相似度计算和使用聚类算法时充分利用物品的特征信息,能够有效提高推荐的精确度。但在研究中,对于用户不同时期的特征偏好,以及外部原因的影响,如社交媒体的宣传,时尚流行度等,使得用户对某一特征偏好的改变不能够进行及时修正,下一步将进行完善研究。
猜你喜欢
小学生学习指导(低年级)(2022年5期)2022-05-31 08:33:14
疯狂英语·初中天地(2021年11期)2021-02-16 00:38:58
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
少年漫画(艺术创想)(2019年2期)2019-06-06 07:47:02
当代陕西(2019年10期)2019-06-03 10:12:04
电子测试(2017年15期)2017-12-18 07:19:27
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
智能系统学报(2015年4期)2015-12-27 09:38:39
小天使·一年级语数英综合(2015年8期)2015-07-06 06:23:32
电子设计工程(2015年6期)2015-02-27 12:04:53
