
基于非对称卷积的大规模天线信道状态信息反馈算法
2022-07-18 09:10:44李婷婷辛雨桐
无线电通信技术 2022年4期
李婷婷,辛雨桐,冉 鹏,曹 彪,杨 阳
(北京邮电大学 人工智能学院,北京 100876)
0 引言
大规模天线技术是未来无线通信系统中的关键技术之一,具有高频谱效率以及大容量链路等优势[1]。获得这些优势的前提是具有向基站(BS)反馈较高的信道状态信息(CSI)质量。然而,大规模天线系统中由于天线数量很多,形成了庞大的CSI矩阵,导致无法在信道容量受限的条件下完整反馈CSI。
为了突破CSI反馈中的这一技术瓶颈,近年来基于深度学习的自编码器获得了广泛关注[2-12]。东南大学金石教授团队[2]最先提出CsiNet,验证了其与传统压缩感知(Compress Sensing,CS)方案之间的巨大优势。以此为基础,该团队又提出了CsiNet+并加入了信道传输量化的考量[3]。基于CsiNet[2],大多数基于深度学习的后续方法利用更强大的深度学习块构建,以牺牲计算开销来获得更好的性能。CsiNet-LSTM[4]和Attention-CSI[5]引入了LSTM[6],显著增加了计算开销;DS-NLCsiNet[7]采用非本地阻塞提高其捕获长程相关性的效率;CsiNet+[3]和DS-NLCsiNet[7]的计算开销约比CsiNet[2]分别高6和2.5倍。近年来,一些降低复杂度的方法开始出现,如JCNet[8]和BcsiNet[9],但它们的性能也有所下降。文献[10]利用深度循环网络来开发通道相关性。之后,CRNet[11]在网络中使用了多分辨率架构,并强调了训练方案的重要性。此外,文献[12]提出了ConvCsiNet,其中网络基于卷积,同时也提出了ShuffleCsiNet,以使编码器部分轻量化。然而,上述模型的性能还可以进一步提高,尤其是在户外场景中。此外,在实际部署中,还需要考虑模型的参数量和泛化能力。
本文设计了一个名为Asy-CSINet的自编码器网络,深入研究了解码器的部分,并使用非对称卷积块[13]来进一步提高网络性能。此外,使用深度可分离卷积来减轻编码器端,从而保留网络的基本结构。在实际部署中,不同的压缩比和不同的场景对应不同的神经网络。还探索了多模型综合集成的可能性,以进一步减少需要存储在用户设备中的参数数量。
本文的主要贡献包括三方面:首先,提出了自编码器框架Asy-CSINet。由于更深的解码器端和非对称卷积模块的使用,户外场景的性能得到了极大的提升。其次,在Asy-CSINet的基础上,引入了一个算法裁剪模型Asy-CSINet-l,其性能虽然略有下降,但更适合用户端。第三,讨论了多速率融合方案和多场景融合方案,大大提高了网络的泛化能力。
1 大规模天线CSI反馈架构
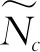
(1)

(2)

(3)
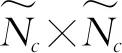
通过上述方法,虽然矩阵H的规模大大减小,但其传输开销仍然很大,可以进一步压缩。传统的基于CS的方法在H是稀疏的假设下压缩H。然而,该假设仅在发射天线数Nt→∞时成立,这在实际系统中是不可实现的。假设与实际系统之间的差距导致了性能问题。如果没有这样的假设,基于深度学习的框架可以更好地工作。
本文忽略了CSI估计的过程,假设可以得到完美的CSI矩阵。一旦在用户估计CSI矩阵H编码器将H压缩为长度为M的码字,然后压缩比可以表示为:
2 自编码器网络
本节提出了一个名为Asy-CSINet的自动编码器框架。此外,还提出了一种简单的算法剪裁解决方案。最后介绍了多速率多模型集成策略。
2.1 基于非对称卷积的CSI反馈网络(Asy-CSINet)
深度学习在计算机视觉任务中显示出巨大潜力。幸运的是,CSI矩阵可以看作是具有实部和虚部的两通道图像。基于此,提出的Asy-CSINet如图1所示。所有方形卷积核的大小为3×3。在每个卷积层之后使用LeakyRelu和批量归一化。与现有的基于深度学习的网络相比,Asy-CSINet有两个主要特点,如下所述。
2.1.1 非对称卷积模块的使用
Asy-CSINet的基本结构由编码器端和解码器端的多个卷积层组成,同时避免使用全连接层。最直观的想法是,如果可以加强卷积层的性能,整个网络的性能就会得到相应的提升。因此,提出了编码非对称卷积模块(Encoding Asymmetric Convolution Block,EACB)和解码非对称卷积模块(Decoding Asymmetric Convolution Block ,DACB)。每个EACB由一个非对称卷积模块和随后的平均池化层组成,而每个DACB由一个上采样层和一个随后的非对称卷积模块组成。非对称卷积模块的主要思想是通过添加两个条纹卷积来增强方形卷积核。如图1所示,非对称卷积模块层的输出是3个路径的总和。在功能上,非对称卷积模块中的条带卷积是为了加强整体网络框架,一些实验已经验证了其在计算机视觉任务中的优越性[13],此处在无线通信领域使用EACB。
非对称卷积模块的另一个优点是它只增加了训练阶段的参数数量,在部署阶段,它可以等效地转换为标准的卷积结构,这意味着可以使用非对称卷积模块而不需要额外的开销。从非对称卷积模块到标准卷积的转换依赖于卷积的可加性。对于以I∈RU×V×C作为输入和O∈RR×T×D作为输出的卷积运算,需要D个卷积核F∈RH×W×C。那么O的第j个通道是:
(4)
(5)
式中,X表示对应位置的滑动窗口。式(5)说明了卷积的一个重要性质:如果多个卷积核共享同一个滑动窗口X,当它们以相同的步幅应用于相同的输入以生成具有相同分辨率的输出时,它们的输出之和等于单个卷积算子使用内核的总和,即便使用的内核大小不同,如等式所示:
I*F(1)+I*F(2)=I*[F(1)⊕F(2)]。
(6)
非对称卷积模块中的3个并行卷积核共享同一个滑动窗口,这意味着它可以通过式(6)进行转换。更多的转换细节可以在文献[13]中找到。
2.1.2 加深的网络编码器结构
在室内场景中,CSI矩阵的非零点很少,而在室外场景中,由于非零点变得分散和模糊,CSI矩阵更加复杂。一般来说,更多的特征总是需要更大的网络来丰富计算机视觉领域的表达能力。但是在编码器端,参数太多是不可接受的,难以部署;解码端存储在具有足够计算能力的基站中。迁移计算机视觉领域的经验,增加了ConvCsiNet解码端的深度。本文使用了5个DACB,输出通道分别为512、512、256、128、8。值得注意的是,DACB中包含的上采样操作会使特征图的大小增大一倍,因此在第4个DACB之后运行了一个额外的平均池化层。此外,还将Refine-Block中卷积层的输出通道更改为8、16、16、8,以便将更多有用的信息传递给后续层。
2.2 Asy-CSINet的算法裁剪
虽然本文提出的Asy-CSINet可以处理CSI压缩和解压缩问题,但实际部署必须考虑参数的量。在无线通信系统中,移动通信得到了广泛的应用,这意味着编码器不能包含太多的参数。本文采用了一种简洁的算法裁剪方法Asy-CSINet-l,受 MobileNet[14]的启发,使用深度可分离卷积来使编码器更加轻量化。通过将EACB的非对称卷积模块替换为深度可分离卷积,编码器端的参数数量显著减少,同时保留了原始结构。
本文也尝试直接使用MobileNet来裁剪ACCsiNet的编码器结构,即形成MobileNet-en。Asy-CSINet-l使用平均池化层来减小特征图的大小,而对于MobileNet-en,使用步长为2的深度可分离卷积来达到相同的效果。
2.3 多速率集成和多场景集成
在实际的通信系统中,压缩率可能会随着环境的变化而变化。实验中使用的压缩率是16、32、64,这意味着用户端需要为3个不同的压缩率存储3个不同的编码器网络,导致实际中难以实现。为了处理这样的问题,本文提出了一个名为Asy-CSINet-mr的多速率网络。Asy-CSINet-l仅包含卷积层,前一个卷积将特征提取到高维通道,而最后一个卷积层根据压缩率减少输出维度。所以本文让不同压缩率的编码器网络共享前面卷积层的参数,只有最后一个卷积层是分开的。该模型如图2所示,3个并行输出卷积层对应3个压缩率(16,32,64)。经过网络的公共部分后,进行压缩率选择,选择某个输出层。在基站端,由于其存储空间大,不同的压缩率对应不同的解码器网络,因此基站中可以存储3个解码器。

图2 多速率集成模型架构
在许多计算机视觉的任务中,一个深度神经网络可以同时处理多个数据。同样,CSI矩阵在实际应用中会随着环境不断变化,因此需要不断切换压缩和重构模型,进一步地,探索了多场景集成的可能性。
3 实验结果及分析
3.1 实验设置
为了公平地比较实验结果,本文使用与CsiNet相同的数据集。所有通道矩阵均由COST 2100[15]生成。考虑2种典型场景,包括5.3 GHz的室内场景和300 MHz的室外场景。在基站端,采用了Nt=32和Nc=1 024的均匀线性阵列模型。转换为角延迟域后,仅保留前Nc=32行。实验中使用的压缩率为16、32和64。总共150 000个生成的CSI矩阵被分为训练、验证和测试数据集,分别由100 000、30 000和20 000个样本组成。
在训练阶段,使用自适应矩阵估计优化器来更新可训练参数。均方误差(Mean Squared Error,MSE)被计算为损失函数。总训练轮次和每次的批次大小分别设置为500和200。受CRNet[5]启发,使用余弦退火学习率(Learning Rate,LR)和预热来加速参数收敛。不同的是每批次而不是每个时期都改变LR,那么LR可以表示为:
(7)
其中,ηmax,ηmin分别代表初始的LR和最终的LR;i、Nw和Ns分别是当前步数、预热步数和总步数。在预热阶段,根据余弦退火函数,LR线性增加到ηmax,然后LR非线性减小到ηmin。在训练阶段之后,学习到的超参数可以集成到方核卷积中,从而消除非对称卷积模块带来的开销。
对于评估指标,使用归一化均方误差(Normalized Mean Squared Error,NMSE)和余弦相似度ρ来表示重建误差。

(8)
为了与之前的模型进行比较,还计算了余弦相似度ρ:
(9)
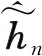
3.2 Asy-CSINet性能评估
将Asy-CSINet与一些基于深度学习的方法进行比较,例如CsiNet[2]等。为了探索影响模型性能的因素,将Asy-CSINet中的非对称卷积模块替换为卷积层,其NMSE性能对比结果显示如图3和图4。
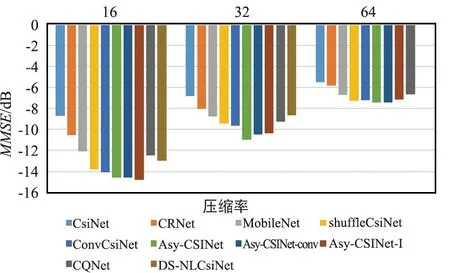
图3 不同压缩率下NMSE性能对比(室内)
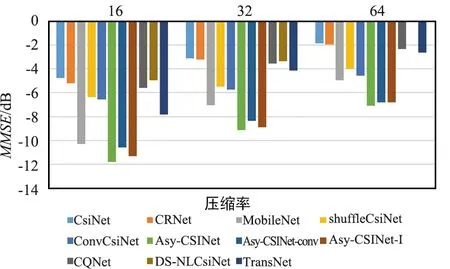
图4 不同压缩率下NMSE性能对比(室外)
对于户外场景,与之前的研究相比,性能提升相当可观。Asy-CSINet-conv和ConvCsiNet的区别在于解码器端的更深层。室内场景的CSI矩阵比较简单,因此较大的模型并不能大大提高性能。对于室外CSI矩阵,特征点更加复杂和分散,使用更深的网络可以丰富表达能力,从而获得更高的性能。此外,还使用了带有不同滤波器的DACB层,添加更多滤波器时性能会提高,但解码器端的参数数量也会大大增加。在实验中,选择添加一个具有512层输出的额外DACB,以平衡性能和参数数量。
使用非对称卷积模块后的结果显示在“Asy-CSINet”中,这表明使用非对称卷积模块可以进一步提高性能。非对称卷积模块通过添加2个带状卷积更好地关注水平和垂直特征。正如文献[13]所解释的,卷积核的骨架是核心部分,2个额外的带状卷积显著增强了骨架,从而在训练阶段丰富了特征空间。值得注意的是,Asy-CSINet对Asy-CSINet-conv的性能提升在室内场景下较小。实验现象表明,改进还取决于CSI矩阵的复杂性。室内性能主要受压缩率限制,而室外性能可以通过使用更强大的工作模块来提高。
此外,Asy-CSINet的余弦相似度对比结果如图5所示,可以看出,同图3和图4类似,模型在户外场景中的性能提升比较大。值得注意的是,在传统的CRNet中,一般通过使用不同的核大小来提供多分辨率的能力,而在Asy-CSINet-conv中,为了发现各种尺度的特征,特征图的大小逐渐改变并使用固定大小的核进行提取。可以看出,渐进式特征提取使Asy-CSINet-conv的性能优于CRNet。

图5 不同模型的余弦相似度对比
3.3 Asy-CSINet-l性能评估
ShuffleCsiNet[6]使用Shuffle Network (SN)来减少ConvCsiNet的参数,本文使用一种更简洁的方法来裁剪编码器网络。为了保留原始神经网络的优越性,利用深度可分离卷积来替换EACB中的非对称卷积模块,即Asy-CSINet-l。结果如图6和图7所示。
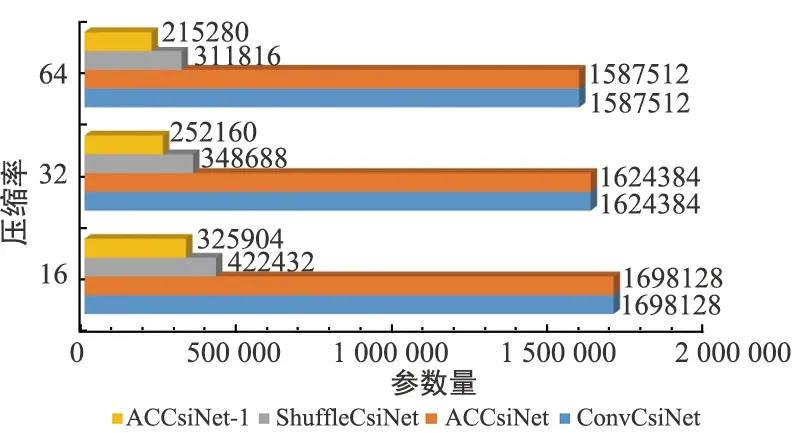
图6 不同编码器的参数量对比

图7 不同编码器的浮点数对比
由于保留了原始网络结构,Asy-CSINet-l 的性能在室内和室外场景中都只略有下降。但是,部署阶段的参数和浮点运算(FLOPs)的数量大幅减少,这对UE的存储非常有利。MobileNet-en的实验结果也如图3所示,这表明用深度可分离卷积替换非对称卷积模块优于用MobileNet替换整个编码器,原因是深度可分离卷积更适合替代固定网络结构中的标准卷积层。
3.4多模型综合集成的性能评估
为了提高泛化能力,本文在Asy-CSINet-l的基础上提出了Asy-CSINet-mr,其编码器的最后一个卷积层是独立的,前面的所有层都是通用的,从而大大减少了多速率下的参数数量。在训练阶段,编码器的输出是3个压缩率的组合,解码器端的3个唯一网络对应3个压缩率。以端到端的方式训练网络,总损失是3个压缩率的总和。很明显,高压缩率的网络损失更大,为了平衡影响,在每个损失前面乘以一个加权项,可以表示为:
LT(θ)=c16L16(θ16)+c32L32(θ32)+c64L64(θ64),
(10)
其中,LN和θN是压缩率为N的均方误差损失和网络参数,cN是乘法权重。在实验中,设置c16=5.5、c32=2和c64=1。归一化均方误差性能结果如表1所示。

表1 不同模型的性能对比
此外,通过融合不同室内外场景的模型,Asy-CSINet-ms被提出。可以看到Asy-CSINet-ms 仍然与Asy-CSINet保持接近最优,而存储在编码器和解码器端的参数量显著下降到原始的一半。在压缩率较低的室内场景中,Asy-CSINet-ms的性能损失更为明显。但是,整体性能损失并不是很大。
进一步将Asy-CSINet-mr和Asy-CSINet-ms集成到一个模型中,即Asy-CSINet-mrs。Asy-CSINet-mrs的结果与Asy-CSINet-ms的结果非常接近。可以得出结论,影响Asy-CSINet-mrs性能的主要原因是多个场景的集成。
考虑3个压缩率不同的室内外场景,用户端需要存储的参数总数如图8所示。通过使用深度可分离卷积,Asy-CSINet-l的参数数量比ACCsiNet减少了83%。对于 Asy-CSINet和Asy-CSINet-l,总共需要集成6个编码器模型。对于 Asy-CSINet-mr,集成了多速率模型,因此只需要2个编码器模型即可处理2种场景,因此与Asy-CSINet-l和Asy-CSINet相比,参数数量分别减少了约45%和90%。最后,Asy-CSINet-mrs集成了多场景模型,使用Asy-CSINet-mrs时只需要一个模型。

图8 各模型参数量对比
该实验为实际部署提供了指导,多速率集成方案可以大大减少参数,同时几乎没有性能损失。如果存储空间需要进一步压缩,可以考虑多场景集成方案。
4 结论
本文提出了使用Asy-CSINet来处理 CSI 反馈问题,通过使用非对称卷积模块和深度可分离卷积,不仅增强了网络的特征提取能力,而且大大减轻了编码器端的重量。然后,进一步提出多模型综合集成方案,以增强网络的泛化能力。实验结果表明,所提出的Asy-CSINet极大地提高了归一化均方误差和ρ性能,特别是对于户外场景。最后,结果验证了算法剪裁和多模型综合集成方案都可以达到所提出Asy-CSINet的最优性能,同时减少了83%和90%以上的参数量。
猜你喜欢
数学年刊A辑(中文版)(2018年2期)2019-01-08 01:59:50
科学与财富(2018年26期)2018-10-24 15:31:44
科技信息·中旬刊(2018年4期)2018-10-21 03:34:14
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
电子设计工程(2017年20期)2017-02-10 03:39:29
滁州学院学报(2016年5期)2016-12-16 07:41:46
科教导刊·电子版(2016年23期)2016-10-31 21:27:33
数学理论与应用(2016年4期)2016-05-17 04:50:23
电子器件(2015年5期)2015-12-29 08:42:24
电测与仪表(2015年4期)2015-04-12 00:43:04
