
用于目标跟踪的特征融合孪生网络算法研究
2022-07-15 08:15范东嘉林名强戴厚德仲训杲
厦门大学学报(自然科学版) 2022年4期
范东嘉,林名强,戴厚德,仲训杲*,赵 晶
(1.厦门理工学院电气工程与自动化学院,福建 厦门 361024;2.中国科学院福建物质结构研究所泉州装备制造研究所,福建 晋江 362216)
目标跟踪技术在计算机视觉领域得到广泛应用与长足发展.然而目标运动变化、背景杂乱、运动模糊等动态不确定性的问题,对现有目标跟踪方法提出了新的挑战.因此,改进目标跟踪方法提升算法性能已成为当前研究的热点.
目标跟踪方法通常可分为两大类,一类是传统相关滤波跟踪法,另一类是基于机器学习的跟踪法.前者是以目标相似度为跟踪衡量指标,如Bolme等[1]提出的MOSSE(minimum output sum of squared error filter)方法将相关滤波首次应用于目标跟踪任务,其基本思想是通过提取目标特征训练相关滤波器,并利用快速傅里叶变换加速计算效率.Henriques等[2]提出的KCF(kernelized correlation filters)方法针对CSK[3](circulant structure kernel)算法使用灰度特征的不足,通过引入多通道特征,利用目标周围区域循环矩阵获取正负样本,有效提高算法的鲁棒性.成悦等[4]提出加权特征融合与置信度模型及尺度更新机制相结合的方法,加强算法的鲁棒性.然而上述相关滤波方法存在固有缺点,当目标与背景非常相似时,算法无法实现相似度评价,从而导致目标跟踪失败.
当前,作为机器学习应用最广泛的深度学习方法,在目标跟踪领域表现优异,特别是孪生网络利用深层网络结合多样本,其特征丰富程度远超传统学习方法,因此,孪生网络已成为目标跟踪问题的主流研究方法.Berinetto等[5]提出SiamFC(fully-convolutional siamese networks)算法,奠定了孪生网络算法的基本思想,该算法使用两个完全相同的网络结构分别对模板和搜索图像进行特征提取,进而对特征图进行互相关性操作,得到目标在搜索图中的跟踪位置.然而SiamFC跟踪算法使用浅层AlexNet[6]网络,目标特征提取不充分,同时也难以应对目标尺度变化情况.因此Li等[7]将RPN(region proposal network)网络加入到孪生网络框架中,在多个检测区域设置多个锚框,并对这些锚框进行分类和回归,使回归锚框更接近真实框,有效解决目标尺度变化跟踪问题.为了充分提取目标特征,SiamRPN++[8]算法采用深层ResNet-50作为特征提取主干网络,但是随着网络的加深会带来空间和通道信息冗余的问题.为了更好拟合目标真实框,Wang等[9]提出SiamMask算法,将网络训练得到的掩膜外接矩形作为目标跟踪框.Siam R-CNN[10]方法结合分割网络,对目标进行二次分割处理实现目标跟踪.SiamBan[11]方法使用无锚框策略克服跟踪锚框的限制,使跟踪框拥有更大的自由度.
考虑到,一方面深度学习方法提取目标特征信息时会产生多维特征空间和通道,仅少部分信息对目标跟踪任务起正向作用,大部分是冗余信息,不可避免增加方法的运算负担;另一方面,孪生网络通过主干网络末端输出层提取目标特征,再进行相似度计算,由于深层特征只包含稀疏语义信息,分辨率较低,不利于目标精确定位.为此,针对目标特征相似度计算跟踪问题,本文将浅层特征和深层特征相融合,提升网络对目标特征的辨识能力,同时引入注意力机制,降低冗余信息,加强网络对正样本的聚焦,提高目标跟踪的鲁棒特性.
1 SiamMask 三分支目标跟踪网络结构
SiamMask网络框架如图1所示,该跟踪方法主干网fθ采用深层ResNet-50网络,结合膨胀卷积进行特征提取.SiamMask框架对模板图片和搜索图片使用两个结构相同的网络构成孪生网架构,并使用深度互相关操作计算模板图片和搜索图片的相似度,图中用d表示,网络末端包含3个网络参数相互独立的分支结构,分别为分割掩码(mask)分支、边框回归(box)分支、前景/背景分类(score)分支,各分支卷积操作分别为hφ、bσ和Sφ.该方法在边框回归和前景/背景分支中使用锚框机制,前景/背景分支输出特征图的每一个图像包含2K个数值,其中每两个数值为一组,表示该图像的K个候选框属于前景和背景的概率;而边框回归分支输出特征图每个位置对应4K个数值,其中每4个数值为一组,表示该位置K个候选框的偏移量.分割掩码分支生成17×17×(63×63)形状特征图,其中每个位置包括一个63×63维度向量,最后将目标所在位置映射为二值分割掩码图,实现目标和背景的像素级分类.SiamMask算法在目标跟踪任务中表现优异,但其网络结构依然存在不足:1) 使用加深的特征提取网络虽然能获得更加丰富的信息,但所提取特征过于稀疏抽象,不利于目标精确定位;2) 大量的空间和通道信息只有部分对跟踪任务起正向作用,其余冗余信息不免带来负面影响.
2 方法提出
针对SiamMask网络存在的上述问题,本文提出如图2所示的网络框架.使用改进的ResNet-50作为特征提取网络,为防止特征过于抽象去掉res3之后的残差块,然后使用卷积将通道数下采样至256得到模板和搜索分支的深层特征Fht和Fhs;同时将res1输出的模板和搜索分支浅层特征经过卷积得到和深层特征相同维度的特征Flt和Fls,然后对各分支特征进行相加融合,使模型充分利用浅层特征信息.除此之外,在浅层特征提取和深层特征融合后分别结合CSAM(channel and spatial attention models)注意力机制,从空间和通道维度对目标信息进行加强,抑制特征提取过程中冗余信息的干扰.最后将所提取的搜索图特征和模板图特征经过深度互相关处理,再由3分支任务学习实现目标的鲁棒跟踪.
3 双重注意力模型设计
特征提取普遍采用不同卷积核提取不同通道和空间信息,此过程产生大量冗余信息,对网络学习具有负影响,进而影响跟踪结果.为了筛选有用跟踪信息,同时降低冗余信息的干扰,本文设计双重注意力模型CSAM,在网络学习中融入注意力算法,使特征提取过程聚焦目标跟踪的有用信息.
借鉴ECANet[12]和CBAM[13]思路,本文设计的CSAM模型如图3所示.具体地,对于输入特征图F∈RW×H×C,其中W,H,C分别表示特征图宽、高和通道数,首先经过通道注意力网络,对特征图各通道进行全局平均池化得到各通道目标响应值,如下:

图3 CSAM注意力模型Fig.3 CSAM attentional model
(1)
其中:Fc(i,j)为第c个通道第(i,j)个像素点的特征值(c=1,2,…,C);bc为每个通道的全局平均池化值.
经过全局平均池化输出1×1×C的特征图B=(bc),进一步将每个通道与其k个近邻通道进行交互学习捕捉通道间的依赖关系,并通过sigmoid激活函数将通道特征值转化为通道间的权重:
(2)

F′c=b′cFc,
(3)
其中,Fc为输入特征图第c个通道,F′=(F′c)∈RW×H×C为输出通道注意力特征图.因为计算通道权重时引入了sigmiod激活函数,对表征目标的通道信息赋予较大权重进行加强,对背景信息赋予较小权重进行抑制,所以F′能更关注目标信息.
同上,使用空间注意力模型作用于特征图,加强目标的空间信息.首先,对输入大小为W×H×C的通道注意力特征图做基于通道的全局最大池化和全局平均池化;其次,将全局最大池化值和全局平均池化值拼接并使用卷积学习得到W×H×1特征图;最后,通过sigmoid激活函数获得空间位置权重并赋予输入特征图,得到空间注意力特征图F″∈RW×H×C为:
F″=(σ(f7×7([AvgPool(F′);
MaxPool(F′)])))F′,
(4)
其中,σ为sigmoid激活函数,f7×7表示卷积核大小为7×7的卷积操作.
4 特征融合网
卷积神经网络通过前向传播对目标特征进行逐层提取,使特征信息变得高级抽象,同时目标的纹理、轮廓和颜色等浅层结构化特征信息被丢失.SiamMask算法因只使用高级抽象特征,导致目标特征表达不全,不能对目标进行精确定位.为此,本文将浅层结构化特征与高级抽象特征进行融合以表征目标,如图2所示,对res3输出的1 024通道深层特征通过下采样缩减至256以减少信息复杂度,同时对res1输出的256通道浅层特征使用卷积运算,使其和下采样输出特征具有相同维度,并经过注意力模型对其通道和空间信息进行筛选,输出表征目标轮廓、纹理等的浅层特征.将具有相同大小的浅层特征Flow和深层特征Fhigh进行相加融合,使融合特征Ffusion同时具有目标的深层语义和浅层结构表征,提高目标在运动模糊,形变等场景下的特征表达,特征融合计算过程为:
Flow=CSAM(conv(res1(p))),
(5)
Fhigh=(conv(res3(p))),
(6)
Ffusion=(Flow⊕Fhigh),
(7)
其中,p表示输入网络的图片;conv表示卷积;CSAM表示注意力网络;res1和res3表示特征提取网络res1层和res3层,⊕表示特征图相加融合.
5 损失函数
本文损失函数为3个任务损失函数之和,其中分割掩码分支损失函数为:
(8)
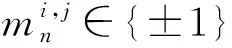
边框回归分支损失函数Lreg使用交叉熵损失,前景/背景分支使用光滑L1函数计算损失Lcls,网络损失函数为三分支损失加权和:
Ltotal=α1Lmask+α2Lcls+α3Lreg,
(9)
式中,α1、α2、α3分别是mask分支、box分支和score分支损失函数的权重,本文中分别设为32,1,1.
6 实验结果与分析
实验平台采用Ubuntu16.04和pytorch深度学习框架,选用NVIDIA GeForce RTX 2080显卡和CUDA11.0对数据集进行训练,训练过程设定15个epoch,其中前5个epoch是预训练阶段,学习率从1×10-3增加到5×10-3,后10个epoch学习率逐渐降低.每批次训练图片数量(batch size)为16张图像对,训练时使用随机梯度下降法对参数进行优化.为了更好地应对目标尺度变化,锚框设置了5种尺度.
本文使用COCO[14]、ImageNet-DET 2015[15]、ImageNet-VID 2015[15]和YouTube-VOS[16]4个数据集对网络进行训练,使用VOT2016[17]、VOT2018[18]数据集作为测试集,每个测试数据集各有60个视频序列,包含多个目标跟踪的挑战因素,如相机运动、运动模糊、运动变化等.
VOT数据集使用跟踪准确率A、鲁棒性R和期望平均覆盖率EAO作为评价指标.
跟踪准确率由真实框与预测框的IOU来定义,第t帧的准确率定义为:
(10)

(11)
其中,Φt为第t帧的准确率,Nvalid为有效视频帧数.
R是衡量跟踪器目标跟踪的稳定性的量,定义为:
R=(F/NF)×100%,
(12)
其中,F为跟丢帧数,NF为数据集中的总帧数.
EAO用于同时评估跟踪器的准确性和鲁棒性,首先计算第s段长度为Ns的视频序列的平均准确率:
(13)
式中,Φs,t为第s个长度为Ns的视频序列第t帧的准确率.最后在长度范围[Nlo,Nhi]上对所有长度序列的准确率进行平均,得到期望平均覆盖率:
(14)
为了充分验证本文方法的性能,对比本文算法和DaSiamRPN[19],ECO[20],SRDCF[21],MDNet[22],Staple[23],DSST[24],ASMS[25],CCOT[26],DAT[27]等算法在VOT2016数据集上的测试结果(表1).由表1可知,本文算法跟踪准确率为63.2%,在所列算法中最高;而鲁棒性能和期望平均覆盖率分别为29.4%和37.8%,与所列算法具有可比性.具体分析:1) 与基准SiamMask算法比较,本文算法准确率略有提升,鲁棒性优化了1.8个百分点,期望平均覆盖率提高了1.4个百分点.2) 与SiamFC相比,本文算法使用锚框机制,能够更好拟合目标位置,在3个指标上都得到较好改进.3) 与KCF、ECO等传统相关滤波算法相比,本文方法使用深度学习结合注意力机制,有效提升动态目标运动变化、背景杂乱等场景的跟踪能力.
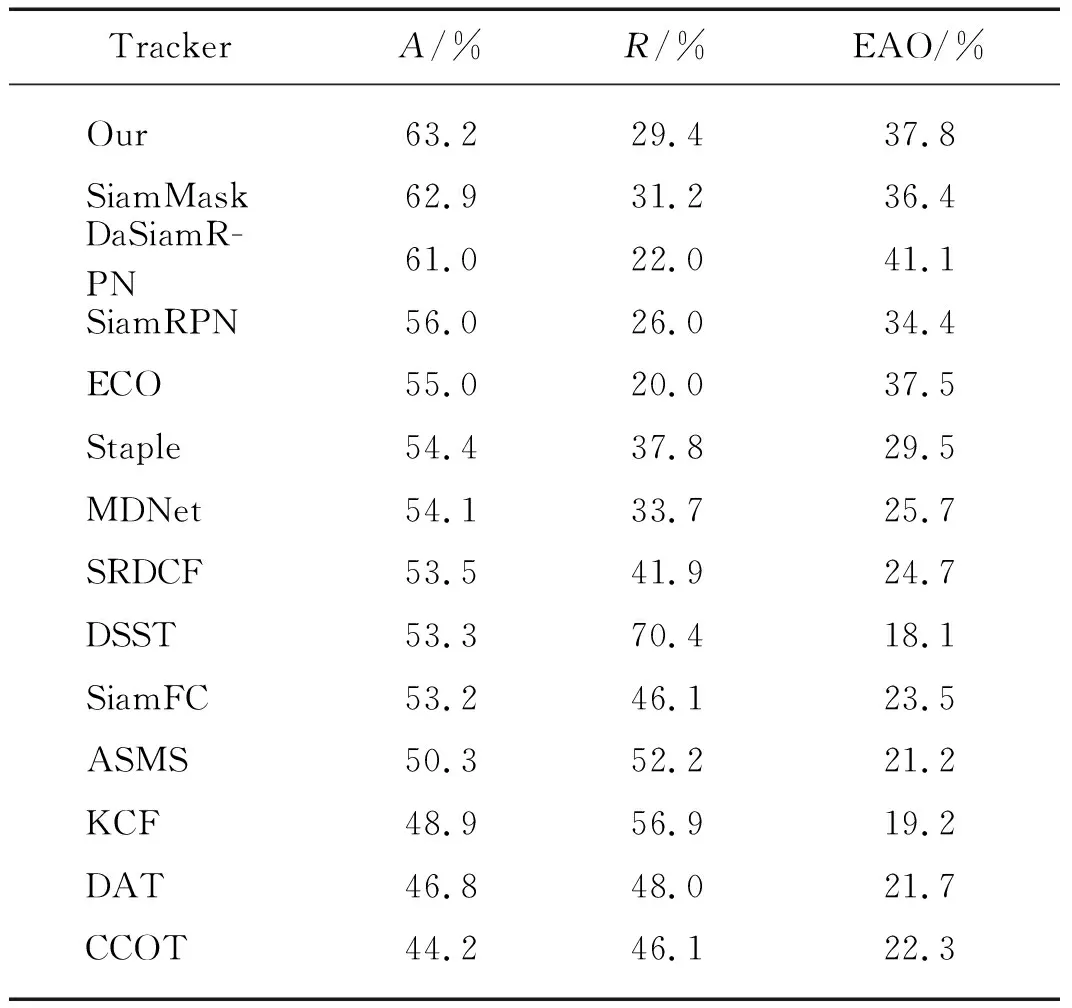
表1 VOT2016数据集上不同方法跟踪结果
图4为各算法在VOT2016数据集上相机运动、光照变化、运动变化、无标注场景、尺度变化场景的A-R图(此处的R是根据VOT数据集官方定义的鲁棒性,与上文的R并不一样,文中仅图5与此处R的定义一致),其中,S表示预期可连续跟踪的视频帧.可以看出:本文算法由于使用通道和空间注意力机制,并充分考虑融合浅层特征,在相机运动、目标运动变化场景下的A-R图中相较于基准算法明显更靠近坐标系的右上角,表示性能更好;在其他场景下,本文算法在准确率上也具有一定优势,与其他算法各场景下的对比结果也具有一定可比性.

图4 不同算法在VOT2016数据集不同场景下的A-R图(S=30)Fig.4 The A-R graphs of different algorithms in different scenarios of VOT2016 dataset(S=30)
本文算法在VOT2018数据集上与UPDT[28],SA_Siam_R[29],DensSiam[30]等11种算法的对比结果如表2所示,其中本文算法准确率为60.1%,较基准算法SiamMask提升了1.2个百分点,在所有比较算法中结果最优;鲁棒性为37.5%,较基准算法优化了3.7个百分点;平均期望覆盖率为31.0%,较基准算法提升了1.4个百分点,在所有对比算法中具有可比性,可看出本文提出的特征融合与注意力机制有利于应对目标跟踪存在的动态不确定性因素.图5为不同算法在VOT2018数据集不同场景下的A-R图,可看出在面对相机运动、运动变化和无标注场景时本文算法相较于基准算法得到较好改善.本文算法从通道和空间维度加强对目标和背景的辨别能力,另外结合轮廓、纹理等浅层特征进一步提升目标跟踪性能,因此与其他跟踪算法相比,本文算法在图5挑战场景下也具有一定可比性.

表2 VOT2018数据集上不同方法跟踪结果
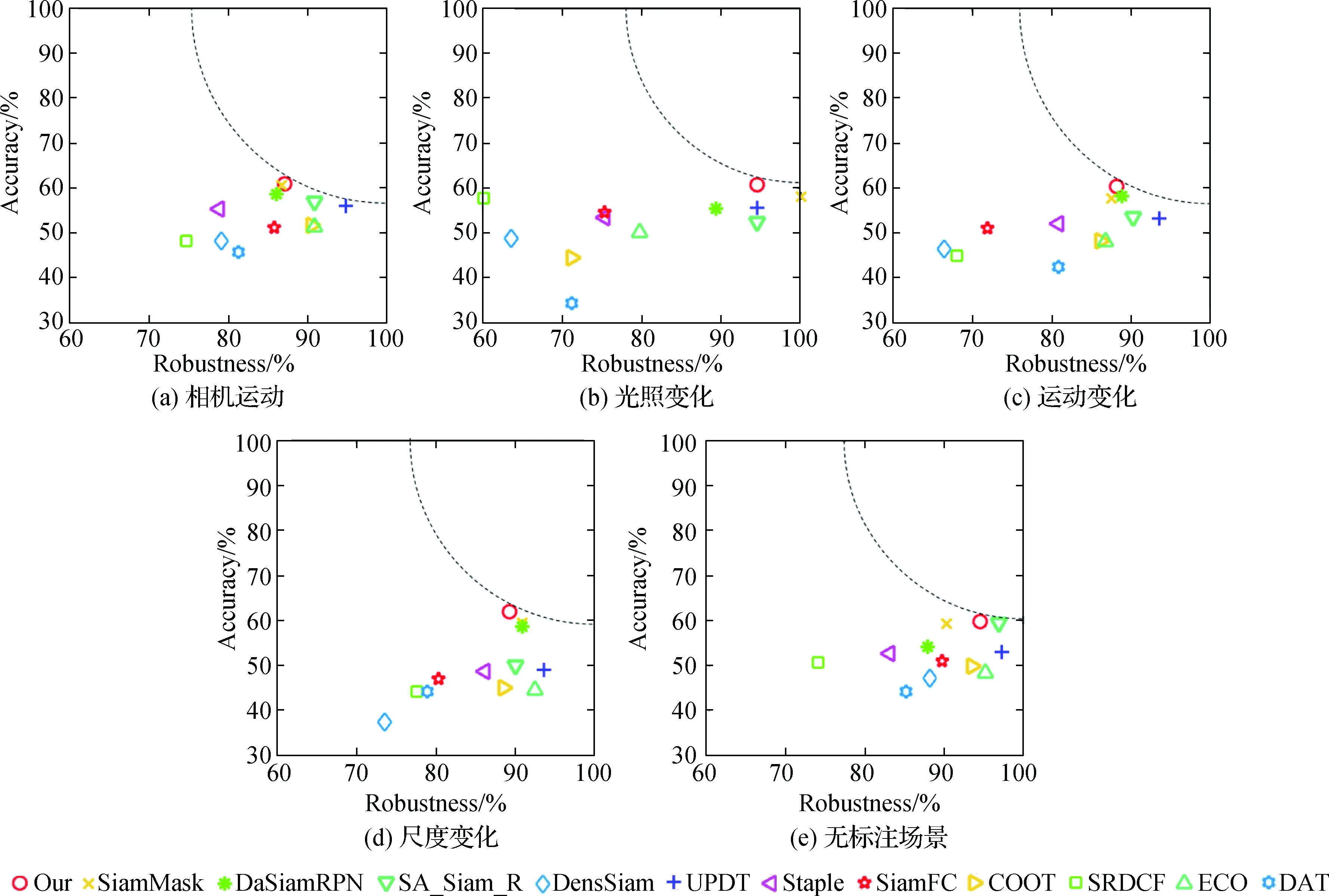
图5 不同算法在VOT2018数据集不同场景下的A-R图(S=30)Fig.5 The A-R graphs of different algorithms in different scenarios of VOT2018 dataset(S=30)
为了更清晰对比本文和其他算法,图6可视化了跟踪器在VOT2016数据集上的跟踪结果,分析如下:
1) 图6(a)视频序列第26帧,目标与周围环境差异明显,3种算法均能很好跟踪目标;当后续视频序列出现相似目标时,如第77帧,基准算法跟踪框漂移到相似物上,本文算法由于添加空间注意力机制,通过全局信息辨别相似目标的干扰,实现正确定位;而第67帧和第78帧,SiamFC算法对目标框的拟合不如本文算法和基准算法.
2) 图6(b)视频序列中,目标在人手中被不断旋转,并且背景杂乱,第18帧本文算法最接近真实框;第79帧SiamFC算法由于目标发生较大变化,同时背景出现相似物体导致目标框发生漂移,跟踪失败;第116帧由于目标旋转和尺度变化导致基准算法产生漂移,而本文算法可以较好的跟踪目标.
3) 在图6(c)视频序列中,SiamFC算法的预测目标框包含较多背景信息,不能很好的拟合真实框;在第54帧和第88帧目标发生形变,由于本文算法有效结合浅层纹理信息,相比基准算法能更好的跟踪目标.

图6 VOT2016数据集不同场景下不同跟踪算法结果Fig.6 The results of different tracking algorithms under different scenarios in VOT2016 dataset
4) 图6(d)视频序列第2帧中,3种算法均能很好实现目标跟踪;由于目标运动产生模糊并且背景杂乱,基准和SiamFC算法在第75帧均发生漂移,而本文算法通过加入注意力机制并结合浅层特征,对目标有着更充分的学习能力,可以更好的对背景和目标进行区分.
5) 在图6(e)视频序列中,由于相机不断运动,同时伴随目标运动变化、尺度变化和背景光照变化,基准算法和SiamFC算法只识别出目标的一部分,而本文算法能够结合全局信息和多层次特征,实现目标的鲁棒识别.
为了进一步验证注意力机制对目标的辨别能力和对背景信息的抑制作用,图7使用热度图可视化了注意力机制对目标信息提取的作用.在图7(a)和(b)中,面对相似物体干扰和运动变化,注意力机制能对相似背景信息进行有效抑制,聚焦于兴趣目标.在图7(c)序列中,面对目标运动变化、运动模糊、背景杂乱的挑战因素,非注意力对背景区域产生大量响应,而采用注意力机制后模型响应更收敛于兴趣目标区域.
7 结 论
基于SiamMask算法,本文提出一种融合注意力机制的孪生网络目标跟踪方法,通过改进ResNet-50作为主干网络,有效结合纹理、轮廓等浅层信息,弥补网络结构加深导致深层特征过于稀疏抽象的缺陷,实现了目标特征的充分表达.为了降低冗余特征影响,融合通道和空间双重注意力机制,提高网络对兴趣目标的辨别能力,使算法有效应对目标运动变化、背景杂乱等挑战性问题.通过在VOT数据集上实验测试,本文算法比SiamFC算法表现更优异,同时相较于基准算法,本文算法性能在VOT评价指标上均得到提升.本文算法只使用初始帧作为模板,同时受锚框数量的限制,因此后续在模板更新和无锚框方面将进一步研究.
猜你喜欢
导航定位学报(2022年5期)2022-10-13
水土保持学报(2022年5期)2022-10-10
黑龙江大学自然科学学报(2022年1期)2022-03-29
计算机系统应用(2021年10期)2022-01-06
建材发展导向(2021年24期)2021-02-12
上海师范大学学报·自然科学版(2018年3期)2018-05-14
电机与控制学报(2018年9期)2018-05-14
计算机应用(2016年10期)2017-05-12
吉林农业(2016年4期)2016-05-14
疯狂英语·口语版(2013年1期)2013-01-31
