
无监督单目图像深度和位姿估计算法优化*
2022-07-15 13:11罗志斌项志宇
传感器与微系统 2022年7期
罗志斌, 项志宇, 刘 磊
(浙江大学 信息与电子工程学院,浙江 杭州 310007)
0 引 言
从图像估计场景深度和相机位姿信息在自主导航、3D重建、增强和虚拟现实等中具有广泛的应用。传统方法主要是基于图像匹配原理,利用匹配的特征点来计算场景深度和相机位姿。该类传统方法对相机参数较为敏感,在部分场景如弱纹理、运动模糊以及光照变化的情况下鲁棒性较低。
近年来,随着深度学习在计算机视觉领域的巨大成功,使用深度学习的方法来实现单目图像深度与位姿估计问题也逐步受到关注,主要出现了有监督和无监督两类方法。有监督的方法直接利用深度和位姿真值拟合回归模型,训练需要大量深度和位姿真值,往往是难以获得的。无监督方法将深度和位姿估计问题转化为视图重建问题,训练不需要深度和位姿真值,克服了训练真值难以获得的问题。2018年,Babuv M等人[1]提出的UnDEMoN模型是无监督方法的典型代表,并且取得了该类方法当时最好的效果。
本文在UnDEMoN模型的基础上,保持其基本网络模型不变,提出了三种优化改进措施:一是低尺度视差上采样重建;二是增加前后帧深度一致性约束;三是引入多种掩模。实验效果显示,通过这些优化改进措施,模型预测的精度得到了有效提升。
1 基本框架
1.1 网络结构框架
优化模型以UnDEMoN为基本框架,框架如图1,包含深度预测网络DispNet(图2 上)和位姿预测网络PoseNet(图2)两个子网络。深度预测子网络输入左视图,输出左右视图相对视差图,进而可以分别重构出左右视图。位姿预测子网络输入左视图序列,输出相邻视图之间的相对位姿,结合深度预测网络预测的视差图,可以实现前后视图间的重构。框架同时利用左右和前后的视图重构误差作为约束训练网络。模型训练时两个网络耦合训练,但预测时可以单独使用。模型使用立体图像对序列进行训练,训练好的模型预测的深度和位姿是具有尺度的。

图1 UnDEMoN框架
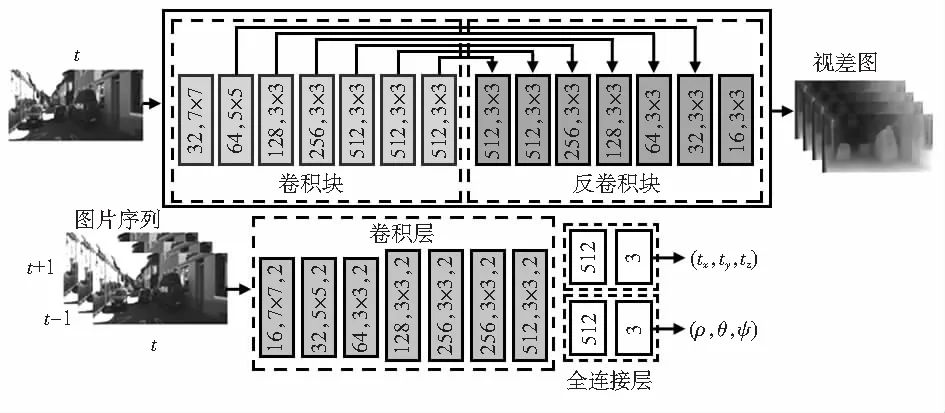
图2 网络结构[1]
1.2 损失函数
UnDEMoN的损失函数主要包括视图重建损失、视差图平滑损失和左右视差一致性损失三部分,三分部损失按一定权重相加。
1)视图重建损失定义为结构相似性和光度误差的加权组合形式
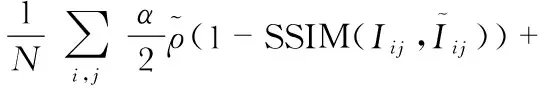
(1)
式中Iij,ij分别为原视图和重构的视图,SSIM为结构相似性函数,是一种度量图像之间相似度的方法。是Babuv M等人[1]引入的一个Charbonnier penalty目标函数,是绝对值范数的一个可微变体,这个目标函数对异常值和噪声具有较强的鲁棒性。总的视图重建损失同时包括左右图像重建损失和前后图像重建损失,按一定权重相加。
2)具有边缘感知的视差图平滑损失
(2)
式中Iij为原视图,dij为相应视差图,i,j为视图的某一像素坐标,N为像素总数。
3)左右视差一致性损失
(3)

1.3 视图重建方法
以视图重建损失作为约束训练网络是无监督训练的核心思想,视图重建主要分为像素坐标投影和双线性图片采样两个步骤完成。
1)基于视差的左右帧像素坐标投影的投影关系为
(4)

2)基于深度和位姿的前后帧像素坐标投影关系为
(5)


(6)


图3 双线性插值图像采样
2 基于UnDEMoN模型的优化改进
2.1 视差上采样重建
由于双线性图片采样具有梯度局部性,为了防止训练目标陷入局部极小点,UnDEMoN模型采用多尺度视差预测和图像重建,在计算重建误差时将各个尺度上的重建误差相加求平均值。这样低尺度的视图重建在场景有大面积平滑区域时容易造成视差图“孔洞”问题。为此,借鉴Godard等人[2]的方法将低尺度的视差上采样到原始图片大小,然后进行原始尺寸的视图重建和计算损失。
2.2 深度一致性约束
由于UnDEMoN模型主要依靠重建光度损失约束训练网络,要求场景具有光度不变性。在光照变化的情况下,鲁棒性变差。为此,受文献[3]的启发,通过约束前后帧之间深度的一致性来增加几何空间一致性约束。如图4所示。

图4 深度一致性约束和掩模[3]

(7)
2.3 掩模优化
在计算重建误差时,一些像素的重建误差可能不利于模型的训练,如投影越界,场景不符合静态假设等像素。通过掩模优化来屏蔽或减小这些像素对模型训练的影响。
2.3.1 投影有效性掩模
由于相机自运动,相邻帧之间进行投影重建时,有些像素投影的坐标可能超过了视图的坐标范围。采用一个投影有效性掩模Mp来标记每一个像素坐标。当某像素投影坐标在视图范围内时,标记Mp的值为1,否则为0。利用这个投影掩模Mp,在计算重建误差时,可以屏蔽掉投影越界的像素的重建误差。
2.3.2 静态像素掩模
自监督训练的前提假设是相机运动和场景静态。当这一假设被打破时,例如相机静态或场景中有动态物体,模型效果会受到很大影响。观察发现,相邻帧之间同一位置像素值保持不变的情况,通常可能有三种情况造成:1)相机本身静止;2)物体与相机保持相对静止运动;3)像素处于弱纹理区域。这三种情况都不利于网络的训练。为此,设计了一个掩模Ms将前后帧中像素值没有明显变化的像素在计算重建误差时屏蔽掉。主要的做法是如果前后帧经过重投影的光度误差小于前后帧直接计算的光度误差,则该像素的Ms的值为1,反之为0。Ms的元素取值μ定义如下
在华山医院的努力和支持下,上海市脑卒中临床救治网络的建设有效地推进了脑卒中救治工作,也进一步推动了全市脑卒中救治能力的整体攀升。
μ=[pe(It,It′→t) (8) 式中 []为艾佛森括号,如果方括号内的条件满足则为1,不满足则为0。 2.3.3 深度一致掩模 增加深度一致性约束后,通过实验发现Ddiff值比较大往往出现在三种情况下:1)场景中有动态物体;2)场景中存在遮挡;3)困难区域的错误预测,这三种情况都不利于网络的训练。为此,基于Ddiff设计了一个深度不一致掩模Mdiff。定义Mdiff=1-Ddiff,Mdiff每一个元素的取值范围在[0,1]之间。当Ddiff很大时,Mdiff权重则很小,从而减少上述三种不利情况对重建误差的影响。 本文模型基于Tensorflow框架进行实现,总共有大约3 500万个参数,使用一块GeForce GTX显卡,训练3万张图片,经过20万次训练迭代,大约35 h达到基本收敛。使用Adam优化器进行训练,设置参数β1=0.9,β2=0.99。初始化学习速率为0.000 1,经过3/5的迭代后,学习速率降低了50 %并且在下一个4/5的迭代之后进一步减少50 %。 本文采用KITTI原始数据集进行训练,数据集采用Eigen等人[4]的方法进行分割。训练集包括21 055张图片,验证集包括2 123张图片。在训练集图像上应用不同类型的数据增强,随机概率为0.5,提高训练集图像的多样性。数据增强主要包括图像翻转和色彩增强。颜色增强包括在[0.5,2.0]范围内应用随机亮度采样,在[0.8,1.2]范围内应用随机伽马和改变颜色。 本文采用文献[4]中所提的指标对深度预测进行评估。为了验证各项优化措施的有效性,进行了剥离实验,在基本框架UnDEMoN的基础上,逐步加入各项优化改进措施,实验结果见表1。从表中可以看出各项优化改进措施对模型都有一定的提升。 表1 剥离实验误差比较 表2是与当前主要方法比较的结果,其中,单/双表示训练过程中用了单目还是双目图像。从表2可以看出,优化模型精度大幅超越当前主要方法的精度。 表2 深度评估性能 为了直观地显示深度网络的效果,将网络预测的视差进行可视化,如图5,从视差图的显示效果来看,本文的方法显示的视差图细节表现更好,预测的物体边缘更锋锐。 图5 视差图可视化 本文模型是在KITTI数据集Eigen分割[4]上进行深度估计训练的,发现具有真值的4个视觉里程计序列没有包含在训练集中,因此可以用来测试位姿估计性能。位姿估计采用绝对轨迹误差(ATE)来量化姿态估计的性能。表3为本文模型、UnDEMoN[1]、SfMLearner[5]和一种传统的位姿估计方法VISO[6]的性能比较。由于SfMLearner是基于单目视频数据训练的模型,网络预测的结果是缺少尺度的,需要经过后处理恢复尺度。在表3中,SfMLearner_PP是经过尺度后处理的结果,SfMLearner_noPP是没有经过尺度后处理的结果。VISO_S是双目版本的结果,VISO_M是单目版本的结果。表格显示的结果表现超过了UnDEMoN,SfMLearner_noPP和VISO_M,并且可以和SfMLearner_PP和VISO_S 使用立体图像进行位姿估计的方法相媲美。由于KITTI训练数据集具有旋转变化的场景非常少,深度网络不能很好地学习旋转变量,导致长距离积累较大的位姿误差,如图6所示。 表3 位姿性能 图6 位姿预测轨迹 本文对无监督单目图像的深度和位姿估计问题进行了深入研究。在模型UnDEMoN的基础上,通过优化损失函数,增加约束条件,引入多种掩模等手段,进行集成优化,有效提高了模型预测效果。虽然引入掩模在一定程度上缓解了场景不满足静态假设的问题,但要完全解决场景中动态物体对模型的影响,还需要进一步做深入的研究。此外,由于KITTI数据集旋转变化并不多,本文模型在姿态的估计方面效果还并不是很好。分析是通过对具有更多旋转变化的数据集进行训练,可以进一步提高网络的姿态估计性能。下一步考虑利用单目图像和有噪声的IMU数据来训练深度网络,以消除网络目前需要的立体图像对的需要,这些问题将指导今后的研究方向。3 实验与评估
3.1 实验设置
3.2 KITTI原始数据集
3.3 在KITTI数据集上的深度评估



3.4 在KITTI数据集上的位姿评估


4 结束语
猜你喜欢
计算机应用与软件(2022年1期)2022-01-28
小型微型计算机系统(2022年1期)2022-01-21
中国科技纵横(2020年13期)2020-12-11
现代信息科技(2020年22期)2020-06-24
山东工业技术(2019年16期)2019-07-19
现代兵器(2017年4期)2017-06-02
现代兵器(2017年4期)2017-06-02
试题与研究·中考数学(2016年4期)2017-03-28
科技视界(2016年6期)2016-07-12
电脑知识与技术(2016年13期)2016-06-29
