
基于时空耦合的时空网格快速伴随研究
2022-07-13 01:00:02黄晓雄
中国电子科学研究院学报 2022年2期
黄晓雄,赖 伟,史 超
(广州汇智通信技术有限公司,广东 广州 510630)
0 引 言
随着移动通信、智能手机和卫星导航定位技术的发展,人们在使用这些技术及产品的过程中产生了大量的位置数据,包括全球定位系统(Global Positioning System,GPS)定位数据、移动终端设备和通信基站之间的通信数据以及人们在购物旅游过程中的位置等数据,这些位置数据和时间与数据实体结合就形成了实体对象的时空轨迹数据。在大数据广泛应用的今天,时空轨迹数据具有非常高的应用价值,通过对时空轨迹数据的研究可以挖掘人们的出行习惯以便于制定交通规划方案和市场营销方案,分析人群聚集地和聚集时间以便于制定应急方案,挖掘多个实体对象的伴随关系,以便于进行同伙犯罪分析从而维护社会安全等。
通过时空轨迹数据进行伴随关系挖掘分析是近年来的一个研究热点,大数据技术的发展使得时空数据的搜集、存储和分析变得更为简单,但同时也带来了问题,例如在海量的时空数据中快速而准确的挖掘出具有伴随关系的两个实体对象。
时空轨迹伴随分析是通过计算两条轨迹的相似度来比较两条轨迹的实体对象是否具有伴随关系,常见的轨迹相似度计算方法包括欧式距离[1]、动态时间规划(Dynamic Time Warping,DTW)[2]、最长公共子序列(Longest Common Subsequence,LCSS)[3]、编辑距离(Edit Distance on Real Sequences,EDR)[4]、弗雷歇距离[5]和豪斯多夫距离[6]等。在动态时间规划方面,文献[7]出了一种基于DTW改进的轨迹相似度算法。在最长公共子序列LCSS研究方面,文献[8]使用改进LCSS进行移动用户轨迹相似性查询算法研究,文献[9]进行了基于LCSS的非同步相似轨迹判断研究,文献[10]提出了一种LCSS+算法解决时空轨迹相似度计算中轨迹点比较的时间阈值敏感问题。在基于编辑距离EDR进行轨迹相似研究方面,文献[11]改进了实数代价编辑距离算法,更好地应用于移动轨迹。在弗雷歇距离研究方面,文献[12]将其应用于地图匹配算法研究中,在基于豪斯多夫距离进行轨迹相似性研究方面,文献[13]提出一种基于单位时间平均值的Hausdorff距离的时空轨迹相似性度量方法。除了基于轨迹点距离计算轨迹相似性之外,文献[14]提出了一种基于面积划分的轨迹相似性度量方法很好地提升了轨迹点分布不均匀的轨迹相似度计算准确率,文献[15]进行了基于时空邻域的多粒度轨迹相似性查询研究。
上述这些距离都是通过计算轨迹数据中相对应的轨迹点的距离来计算两条轨迹的相似度,但是在实际数据中,由于受各种环境因素包括天气、地形和建筑物的影响以及终端设备的移动速度等影响,通过基站得到的实体对象的轨迹数据存在漂移、误差甚至错误,特别是终端设备和通信基站之间通信时产生的位置数据不是终端设备的实际位置,因此这些伴随分析算法并不适合于使用基站位置数据的场景。文献[16]提出了一种基于网格索引的时空轨迹伴随模式挖掘算法,该算法将需要挖掘的区域划分为多个小的矩形网格,并引入“8-近邻”网格的概念,通过计算两个实体对象经过的共同网格或“8-近邻”网格的数量来衡量是否具有伴随关系。但该算法具有两个问题,1)使用的网格为自定义网格,不具有通用性,在大数据分析场景中,如果数据预处理时采用多种网格,在数据查询时无法进行高效的查询;2)每个网格内或多或少都存在与目标实体对象不具有伴随关系的其他实体对象,这些实体对象如果不进行有效的排除,不仅对伴随结果造成干扰,也会增加后续的计算量。针对上述两个问题,提出了基于时空网格的快速伴随相似度算法(Spatial-temporal Grid Accompany Similarity, SGAS),采用基于希尔伯特曲线的Google S2空间索引算法[17],生成通用的S2网格,通用的网格相比自定义网格具有以下三个优点。
1)自定义网格需要保存经纬度和网格的映射关系,在空间范围比较大的情况下,映射关系的加载与查询需要占用较多的资源,而通用网格可直接通过经纬度进行计算,无需保存映射关系;
2)自定义网格没有网格级别之分,不同大小的网格之间无法进行转换,而通用网格有多个级别,不同级别的网格可以直接转换;
3)在大数据场景中,存在较多的跨系统调用情况,通用网格更利用系统对接部署。
将网格与时间组合形成时空空格,在借鉴网格“8-近邻”概念的基础上,计算两条轨迹具有相同或相邻时空网格的数量;并在此基础上,深入分析伴随关系特征,提出了时空耦合伴随模式,即在主对象运动轨迹中的每一个轨迹采样点的位置和时刻,时空耦合具有以下两个特征。
1)当主对象的位置已经发生变化时,相同时刻仍在主对象的上一个或多个位置点的其他实体对象和主对象不具有伴随关系;
2)当主对象的位置还未发生变化时,相同时刻已经在主对象下一个或多个位置点的其他实体对象和主对象不具有伴随关系。
基于时空耦合的时空网格快速伴随分析,可以大幅减少主对象伴随结果中的干扰项,适用于大数据场景下的伴随关系挖掘分析,能够有效屏蔽实体对象轨迹数据的误差、偏差甚至错误以及多个实体对象的轨迹数据采样时间不同步问题,其运行效率和准确性也有较大提高,实测结果表明,在亿级时空数据场景下,对一个主对象任意24 h内的运动轨迹进行伴随分析,能够在十秒内返回结果,且相比于不使用时空耦合的快速伴随,能平均减少伴随结果集的对象数量69%,显著提高目标对象在伴随结果集中的排名,减少数据分析过程中的干扰项。
1 轨迹数据降维
时空轨迹数据包括时间和经纬度数据,是由一系列时间和位置组成的轨迹点序列,理论上时间和对象的移动轨迹都是连续的,但是受限于数据源的采样条件,在实际中这些轨迹点都是离散的,因此一条时空轨迹Tr通常可以表示为
Tr={(t1,x1,y1),(t2,x2,y2),……,(ti,xi,yi)}
(1)
式中:轨迹点(ti,xi,yi)表示移动对象在任意ti时刻,都具有一个由经纬度表示的位置(xi,yi)。
传统的时空数据存储通常将实体对象ID、时间和经纬度数据分开存储,以实体对象ID作为索引进行时空数据的存储和查询。但是在时空搜索、时空碰撞和时空伴随等大数据应用场景中,需要在短时间内(一般10 s以内)查询一段时间范围内在某个区域出现的实体对象,如果对时间、经度和纬度分别进行查询后再做过滤,查询效率将受到严重影响。因此,需要针对大数据场景下的时空数据存储及索引进行优化。
在轨迹数据中,采样轨迹点具有离散性和随机性,为了便于存储与检索,我们提出了时空网格索引,将时间、经度和纬度这三个维度的数据利用时间片和空间网格索引算法进行降维处理,将三个维度的数据降低为一个维度的时空网格数据,具体算法流程如下:
1)将时间分为十分钟分片,时间戳t映射为小于等于t的最接近的十分钟时间戳t′为
t′=f(t)=⎣t/600」×600
(2)
式中:⎣t/600」表示对t/600的结果向下取整。
若将时间分为五分钟分片,则最接近的五分钟时间戳t′为
t′=f(t)=⎣t/300」×300
(3)
2)将t′格式化为时间字符串,得到十分钟粒度的时间片;
3)将经纬度(x,y)使用Google S2空间索引算法转换为S2网格,本文采用的是14级S2网格,其网格大小约0.32 km2;
4)将十分钟粒度的时间片作为时空网格的时间域,S2网格作为时空网格的网格域,共同组成了时空网格,其格式为:时间域_网格域。时间域的格式为:yyyyMMddHHmm,网格域的格式为S2网格。
将时间、经度和纬度三个维度的数据降低为一个维度的时空网格数据,并以时空网格数据做索引,可以方便地对轨迹数据进行索引、存储和压缩。使用时空网格索引算法将轨迹中的某一点(ti,xi,yi)转换为一维的时空网格得到TiGi,然后以TiGi作为key,移动对象ID作为value,组成Key-Value对存储于Key-Value数据库中的索引表中;将移动对象ID作为key,(ti,xi,yi)作为value,组成Key-Value对存储于Key-Value数据库中的数据表中,即可实现对任意时间和任意区域出现的移动对象及其轨迹进行搜索的功能。
2 时空网格伴随相似度算法
伴随是指两个或两个以上的移动对象在一段限定的时间内一起移动的过程,移动对象包括人、车或其他运动对象,在这个过程中,以某个移动对象作为主对象,与主对象一起移动的其他对象作为关联对象,则关联对象在任意时刻一定位于主对象的地理位置的周围。例如同乘一辆车的多个乘客、一起步行的多个伙伴等。
定义1:至少N个相关联的移动对象,在一起运动至少T时长,其中N和T是用户自定义的阈值,且N>1,T≥30 min,则这N个移动对象在T时间内形成的轨迹模式就叫做时空轨迹的伴随模式。
基于时空网格的伴随相似度算法指将所有移动对象的时空轨迹数据转换为时空网格后,根据主移动对象的时空轨迹转换后的时空网格,检索数据库中在相同或相邻的时空网格中出现的其他关联移动对象,并统计每个关联移动对象出现的次数,再将每个移动对象出现的次数除以主移动对象的时空网格数就得到了基于时空网格的伴随相似度。
定义2:主移动对象A在T1到Ti时间范围内,其对应的时空网格序列为
TrA={T1G1,T2G2,……,TiGi}
(4)
式中:时空网格TiGi中的Ti代表时间域,Gi代表网格域。对于任意一个时空网格TiGi,它的“8-邻域”计算规则为
1)把时空网格TiGi分隔为时间域Ti和网格域Gi;
2)计算出网格域Gi的八邻域;
3)保持时间域Ti不变,将时间域和网格域Gi的八个邻域网格组成八个时空网格,得到时空“8-邻域”,如图1所示。

图1 时空8-邻域
时空网格集合(TiGi1,TiGi2,TiGi3,TiGi4,TiGi5,TiGi6,TiGi7,TiGi8)为时空网格TiGi的时空八邻域。
按照上述“8-邻域”计算规则,将主移动对象A的时空网格序列进行“8-邻域”扩域后得到新的时空网格序列为
NTrA={(NT1G11,NT1G12,NT1G13,NT1G14,T1G1,
NT1G15,NT1G16,NT1G17,NT1G18),
(NT2G21,NT2G22,NT2G23,NT2G24,T2G2,NT2G25,
NT2G26,NT2G27,NT2G28),
……,
(NTiGi1,NTiGi2,NTiGi3,NTiGi4,TiGi,NTiGi5,
NTiGi6,NTiGi7,NTiGi8)}
(5)
SGAS算法的规则为
1)将主移动对象A的时空网格序列TrA进行“8-邻域”扩域后得到新的时空网格序列NTrA;
2)对于NTrA中的每一个时空网格集合
(NTi1Gi1,NTi2Gi2,NTi3Gi3,NTi4Gi4,TiGi,NTi5Gi5,NTi6Gi6,NTi7Gi7,NTi8Gi8)中的每个元素(即一个时空网格),在数据库中检索其对应的移动对象ID,同一个时空网格集合中出现的移动对象ID仅计算一次;
3)分别统计NTrA的所有时空网格中每个移动对象ID的出现次数
4)主移动对象A和关联移动对象B的时空网格相似度SGAS定义为
(6)
其中,
式中:‖TrA‖表示时空网格序列TrA的元素个数。
3 时空耦合模式
基于时空网格的时空伴随算法,是通过计算每个时空八邻域网格中出现的移动对象ID,然后统计在所有的时空八邻域网格中出现的移动对象ID的次数。在这个过程中,若某个移动对象出现的次数较少,或者仅在某些时空网格中存在,仍然会被统计到,为了减少伴随结果中杂质的干扰,提高伴随结果的命中率,需要对伴随的过滤逻辑进行优化。
根据定义1中伴随模式的特征,具有伴随关系的多个移动对象,其位置随时间的变化规则相同;反之,若移动对象的位置随时间的变化和主移动对象的不同,则该移动对象和主移动对象不具有伴随关系。
因此时空耦合伴随是指多个移动对象在时间和空间上同时发生关联变化的模式,如图2所示。
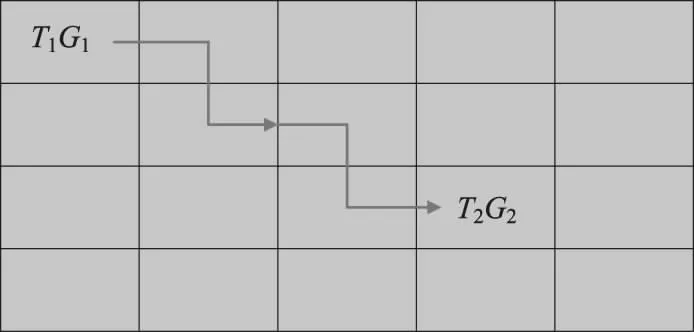
图2 对象移动轨迹
假设采样时刻为T1和T2,主移动对象A由T1G1运动到T2G2,T1≠T2且G1≠G2,在T1时刻,对象A位于时空网格G1,时空网格T1G1的时空八邻域中出现的移动对象可能和对象A具有伴随关系,但是在T2时刻,仍然在网格G1中的,即在时空网格T2G1的时空八邻域中出现的移动对象和对象A则不具有伴随关系,因此在使用时空网格检索数据库时,需要加入排除条件,根据定义2的规则,时空网格T1G1的时空八邻域为
(NT1G11,NT1G12,NT1G13,NT1G14,T1G1,
NT1G15,NT1G16,NT1G17,NT1G18)
排除条件为
(NT2G11,NT2G12,NT2G13,NT2G14,T2G1,
NT2G15,NT2G16,NT2G17,NT2G18)
将两者通过NOT关系连接后即得到时空网格T1G1的检索条件为
(NT1G11,NT1G12,NT1G13,NT1G14,T1G1,
NT1G15,NT1G16,NT1G17,NT1G18)
NOT
(NT2G11,NT2G12,NT2G13,NT2G14,T2G1,
NT2G15,NT2G16,NT2G17,NT2G18)
同理,当对象A在T2时刻运动至网格G2时,时空网格T2G2的时空八邻域为
(NT2G21,NT2G22,NT2G23,NT2G24,T2G2,
NT2G25,NT2G26,NT2G27,NT2G28)
排除条件为
(NT1G21,NT1G22,NT1G23,NT1G24,T1G2,
NT1G25,NT1G26,NT1G27,NT1G28)
将两者通过NOT关系连接后即得到时空网格T2G2的检索条件为
(NT2G21,NT2G22,NT2G23,NT2G24,T2G2,
NT2G25,NT2G26,NT2G27,NT2G28)
NOT
(NT1G21,NT1G22,NT1G23,NT1G24,T1G2,
NT1G25,NT1G26,NT1G27,NT1G28)

需要注意的是,此处对于T1G1这个时空网格仅添加了一个排除的时空网格集合,在实际计算中,若主对象的轨迹中有多个时空网格不等于T1G1,则可以根据每一个时空网格添加一个排除的时空网格集合,排除时空网格集合的数量仅受限于底层数据库所能支持的并发查询能力。
是否符合排除条件,需要同时考虑时间域和空间域,即时间域和空间域均不相等,由于时间的单调递增特性,按照本文前述的时间戳切片规则,不会存在相同的时间域,因此只需要考虑空间域是否相等即可。由于本文采用“8-邻域”作为空间域,因此,判断空间域是否相等只需要对标识空间域的网格集合判断是否相等,而两个网格集合的比较分为三种情况。
1)当两个网格集合完全不重合时,如图3所示,由于时间域已不相等,因此时空网格T1G1的排除条件是时间域T2和网格G1的“8-邻域”组成的时空网格集合,时空网格T2G2的排除条件是时间域T1和网格G2的“8-邻域”组成的时空网格集合。

图3 两个网格集合完全不重合
时空网格T1G1的排除条件是时间域T2和网格G1的“8-邻域”组成的时空网格集合,也可以描述为时间域T2和网格G1的“8-邻域”中除了网格G1的“8-邻域”和网格G2的“8-邻域”的交集之外的网格,可表示为:
时空网格T1G1的排除条件=T2·(CG1-CG1∩G2)
(7)
式中:CG1表示网格G1和它的“8—邻域”网格集合;CG1∩G2表示网格G1和它的“8-邻域”网格集合与网格G2和它的“8-邻域”网格集合的交集。
由于两个网格集合完全不重合,网格G1和它的“8-邻域”与网格G2和它的“8-邻域”的交集为空,因此网格G1的“8-邻域”网格集合减去空集后仍然保持不变。时空网格T2G2的排除条件同理。
2)当两个网格集合部分重合时,如图4所示,时空网格T1G1的排除条件是时间域T2和网格G1的“8-邻域”中除了阴影部分的网格组成的时空网格集合,而时空网格T2G2的排除条件是时间域T1与网格G2的“8-邻域”中除了阴影部分的网格组成的时空网格集合。
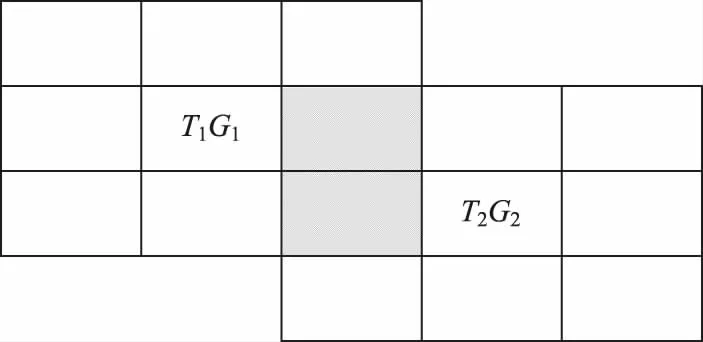
图4 两个网格集合部分重合
根据式(7)计算时空网格T1G1的排除条件,网格G1的“8-邻域”需要减去网格G1和它的“8-邻域”与网格G2和它的“8-邻域”的交集,由于两个网格集合部分重合,式(7)中的CG1∩G2即为图4中的阴影部分,因此排除条件中网格G1的“8-邻域”网格不包括阴影部分的网格。如果未对阴影部分的网格进行特殊处理,直接将阴影部分的网格添加到排除条件中,若目标恰好位于阴影部分的网格中,则会降低目标的伴随次数,进而影响到目标对象在伴随结果中的排名。时空网格T2G2的排除条件同理。
3)当两个网格集合完全重合时,根据式(7)计算时空网格T1G1的排除条件,网格G1的“8-邻域”需要减去网格G1和它的“8-邻域”与网格G2和它的“8-邻域”的交集,由于两个网格集合完全重合,它们的交集仍然等于其中一个网格集合,即式(7)中的CG1=CG1∩G2,则CG1-CG1∩G2=∅,即两个网格集合完全重合时,需要排除的网格集合为空集,也就是说不需要添加排除网格集合。
综上所述,时空网格T1G1排除条件中时空网格集合的计算可以归纳如下:
1)取出时空网格T1G1的网格域G1,计算“8-邻域”,得到网格和邻域集合CG1;
2)取出时空网格T2G2的网格域G2,计算“8-邻域”,得到网格和邻域集合CG2;
3)计算CG1和CG2的交集CG1∩G2;
4)计算排除网格集合为CG1-CG1∩G2;
5)与时间域T2结合得到排除的时空网格集合。
4 实验结果
本文时空网格数据存储在时空库集群系统中,该数据库基于分布式数据库HBase,利用HBase的协处理器框架实现移动对象ID和时空网格数据的相互索引,并结合高效的Bitmap位运算机制实现时空网格的AND、OR和NOT连接关系计算,协处理器与Bitmap相互结合可以支撑亿级时空数据查询秒级响应。在时空库集群中,单个时空网格的查询可达到毫秒级,再利用协处理器的并发特性,多个时空网格的查询与连接关系计算均可在秒级完成,关于时空库集群系统的更多细节问题本文不展开描述,本文中算法实现的效率与计算量方面在时空库集群中不存在性能瓶颈,仅对比算法计算出的结果数据量变化情况。
实验选用某大数据系统,数据存储集群包含5个存储计算服务节点,单节点配置为CPU Intel(R) Xeon(R) Gold 5218 CPU @ 2.3GHz,256GB内存,24×1.2TB SAS硬盘,操作系统为CentOS Linux 7.6,移动对象用户数约两千万,数据存储周期九十天,数据库内的时空网格数据量约三千亿条。伴随分析工具采用Java语言开发,该程序输入参数为主对象ID和时间段,输出数据为在输入的时间段内,和输入的主对象ID具有伴随关系的关联对象ID及其伴随相似度。
从数据集中选取两个具有伴随关系的移动对象,其中一个作为主对象,另一个作为目标伴随对象,测试从一批移动对象中找出和主对象具有伴随关系的目标对象。将轨迹数据按照时空网格数据规则进行预处理后(注:数据预处理采用Flink实时流计算集群,预处理逻辑及实现不在本文描述范围内)写入到时空库集群系统中,然后分别在不同时间分片(五分钟时间片和十分钟时间片)情况下使用不包括耦合条件和包括耦合条件两种检索逻辑从数据库中检索出所有相关联的对象ID,根据每个相关联对象出现的次数,使用SGAS算法计算出伴随相似度,并根据相似度对关联对应进行排序,目标对象在结果集中的排序越靠前,其准确性越高。
下面分别对十分钟时间片的快速伴随与耦合快速伴随和五分钟时间片的快速伴随与耦合快速伴随进行测试,并对比不同时间片情况下伴随结果数据量的变化情况。测试验证数据如表1所示。
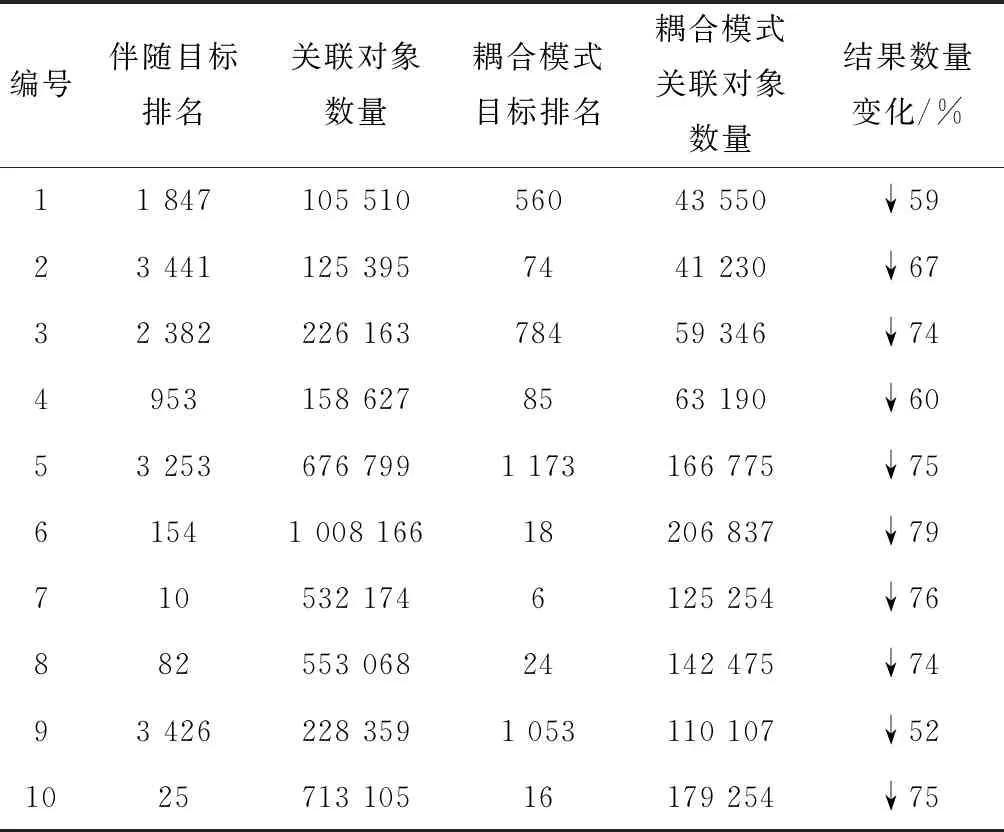
表1 十分钟时间分片的实验结果数据
从表1中的测试验证数据可以看出在十分钟时间片的情况下,使用时空网格耦合伴随增加排除条件后,结果集中关联对象的数量均有大幅度的减少,数量平均下降69%,显著降低了干扰项的数量,提高了目标对象在结果集中的排名。
从表2中的测试验证数据可以看出在五分钟时间片的情况下,使用时空网格耦合伴随增加排除条件后,结果集中关联对象的数量也有较大幅度的减少,数量平均下降73%,略优于十分钟时间分片。

表2 五分钟时间分片的实验结果数据
从表3中的测试验证数据可以看出五分钟时间片的测试结果均优于十分钟时间片的测试结果,主要原因是时间分片越小,目标对象的轨迹形成的时空网格越多,根据耦合得到的排除条件就越多,因此可以排除更多的干扰结果。

表3 不同时间分片的结果数据量变化
5 结 语
本文提出了一种针对大数据场景下,根据移动通信终端与通信基站之间的信令数据快速计算移动对象的伴随对象的方法,该方法首先通过将信令数据中的时间戳转换为时间片作为时间域,使用S2空间索引算法将信令数据中的位置点网格化并作为网格域;然后,将时间域和网格域组合为时空网格,并对时空网格进行索引存入分布式数据库中。在进行伴随计算时,首先,查询出主对象在执行时间段内的时空网格,对时空网格进行“8-邻域”扩域计算,并利用耦合模式添加排除条件;然后,在数据库中检索添加排除条件后的时空网格序列,并统计结果数据中的关联移动出现的次数;最后,计算出时空网格相似度,对结果以相似度排序输出。通过对测试数据进行验证表明,算法能有效减少伴随结果集的对象数量,降低干扰项的数量,显著提高目标对象在伴随结果集中的排名。
虽然本文提出的时空耦合算法有效地降低了伴随结果集中干扰项的数量,但是仅对那些持续运动且运动距离较长的对象伴随有效,当对象的轨迹中有较长时间的停留时,仍然可能存在一些无法排除的干扰项,下一步工作重点是识别对象的运动和停留状态,分别针对不同的状态进行伴随特征研究。
猜你喜欢
四川党的建设(2022年8期)2022-04-28 21:29:35
小学生学习指导(低年级)(2020年11期)2020-12-14 07:28:10
读友·少年文学(清雅版)(2020年4期)2020-08-24 07:36:26
读友·少年文学(清雅版)(2020年3期)2020-07-24 08:57:04
吉林大学学报(理学版)(2020年3期)2020-05-29 06:32:16
作文大王·低年级(2018年10期)2018-12-06 06:22:44
自动化学报(2018年7期)2018-08-20 02:59:04
现代装饰(2018年5期)2018-05-26 09:09:39
中国三峡(2017年2期)2017-06-09 08:15:29
周口师范学院学报(2016年5期)2016-10-17 06:36:47
