
基于弱监督的生物医学文献细粒度索引研究
2022-07-12 04:53王勇
微型电脑应用 2022年5期
王勇
(山东搜搜中医信息科技有限公司, 山东,济南 250014)
0 引言
引文的检索对于寻找特定信息的生物医学研究人员而言是极其重要的,通过精准的检索能够很大程度上提升研究效率。目前,在生物医学引文的语义索引领域应用较广泛的是医学主题词表(Medical Subject Headings, MeSH)。MeSH词库由大量相互关联主题词组成,包括主题描述符、主题限定词(也称为子标题)和补充概念记录。每个MeSH描述符都包含一组术语[1],这些术语在语义索引和搜索中被认为是等效的,但不一定是严格意义上的同义词。这些术语被组织为MeSH概念,这些概念是一组同义词。
尽管MeSH具有近29 000个描述符,但它经常将一些紧密相关但截然不同的概念归为同一描述符,而无法实现对生物医学领域相关文献的精准检索。研究特定生物医学领域专家检索的文献通常需要深入到MeSH描述符不支持的粒度级别,将相关文献分为细粒度的子集可以揭示特定患者亚型的差异,并为精准医学应用提供信息,这在MeSH的疾病类别中尤其重要。
由于目前没有这种细粒度索引的相关研究,因此本文的工作旨在实现生物医学文献的细粒度索引,将文章摘要中概念术语用作弱监督(weakly supervised, WS)。本文以阿尔茨海默病(AD)相关文章为例,利用现有的MeSH注释参考已经用MeSH描述符注释的引用文献,而不是考虑所有摘要。此外,本文还利用每个描述符的概念结构,重点关注较狭窄的概念。
1 概述
1.1 生物医学文献的语义索引
生物医学文献的语义索引研究主要集中在为每个生物医学文章匹配合适的MeSH条目方面。在这类研究中索引者使用适当的MeSH条目对PubMed / MEDLINE引用进行手动注释。这类资源已用于开发机器学习系统,该系统能够自动将MeSH条目(尤其是描述符)分配给生物医学文章,从而开发出高度精确的解决方案。有些研究者强调了细粒度语义索引对于精确信息检索的重要性[2],对于稀有和慢性疾病的实验,这些研究者认为在摘要或标题中确实包含MeSH概念某些术语的文章是唯一应使用该概念进行索引的文章。这些研究者得出的结论是在MeSH概念级别进行索引对于更精确地检索信息而言效果很好。
1.2 弱监督分类
由于缺少用于细粒度语义索引的数据集,研究者研究了多种弱监督方法,即不准确、不完全和不确切的监督[3]。在不准确的监督下,训练集中的某些可用标签是错误的,应将其视为噪音[4],本文研究的问题就属于此类。在不完全监督下,通常仅标记数据集的一小部分。在这种情况下,通过半监督学习方法来利用未标记数据,以弥补训练数据的不足[5]。半监督学习(Semi-Supervised Learning,SSL)是模式识别和机器学习领域研究的重点问题,是监督学习与无监督学习相结合的一种学习方法。半监督学习使用大量的未标记数据,同时使用标记数据进行模式识别工作。在不确切的监督下,每个带有标签的示例(也称为包)均由多个实例组成。
目前,研究者已经提出了不同的方法来处理标签噪声在分类中的影响。部分研究者在训练数据集之前依靠过滤器来识别数据集中潜在的错误标记示例。在这种情况下,过滤器可以基于相似实例的标签[6]对数据的不同部分进行训练。一些机器学习算法已被明确设计为对特定类型的噪声进行建模,从而降低了噪声对其性能的影响[7-8]。然而,即使实际上没有针对某种噪声的学习算法也可以在实践中对某些级别的噪声具有鲁棒性,特别是在针对低方差的配置中可以避免过度拟合。
2 基于弱监督的生物医学文献细粒度索引
由于缺乏基本的真实数据,本文提出了一种弱监督方法用于开发模型,以利用现有的MeSH注释以及MeSH描述符和MeSH概念之间的已知关系来预测文献中的细粒度主题注释。需要强调的是,本文将细粒度的语义索引问题公式化为单实例多标签分类问题,在学习阶段和预测过程中都带有噪声标签。从描述符的概念结构来看,每个模型的可用标签集是预先已知的。基于文献中的概念出现,本文通过WS方法为词汇分配标签以进行模型训练。
图1对本文所提出的方法进行了简要描述。首先,所有与MeSH描述符t相关的文章从PubMed / MEDLINE中被检索出来。在这项工作中,本文仅考虑描述符,其中首选概念cpref是MeSH描述符t对应的概念集里较为宽泛的描述符。其次,根据相关概念的出现情况,将噪声细粒度标签分配给选定的文献,以开发弱监督训练数据集。需要强调的是,每篇文献都标有来自集合Ct且在文献中出现的概念ci。概念ci在文献中出现不能保证文献实际内容与该概念相关,即使该文章与描述符t相关。但是,可以明确的是概念ci在文献中的出现与概念ci高度相关,这可用于文献噪声的细粒度标签。
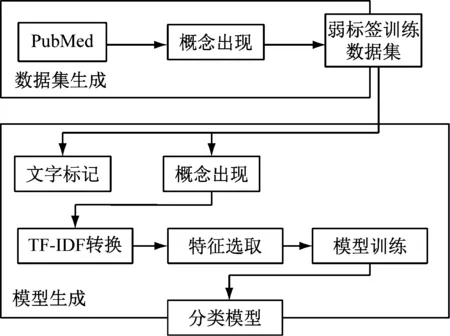
图1 基于弱监督的生物医学文章细粒度语义索引的方案
文献中生物医学概念出现的标识是一项信息提取任务,涉及生物医学命名实体的识别及其在规范化语义系统中对特定概念的映射。这项任务的特殊挑战包括识别具有多个单词的术语或出现在文献中的术语的概念以及消除属于多个同构概念术语的歧义。本文使用的MetaMap[9]是当下最流行和最全面的方法之一,可用于识别包含了MeSH概念的统一医学语言系统(Unified Medical Language System,UMLS)中的概念。MetaMap是一个把生物医学文本与UMLS超级词表中的概念匹配起来的程序,该程序可以设置很多参数,这些参数用于控制MetaMap的输出以及内部运行(如单词变形的程度、是否忽略超级词表中含有常见词的字串,是否考虑字母的顺序等等)。
由于本文中用于细粒度索引的每篇文章均已使用t进行索引,所以本文假设集合Ct中至少存在一个ci与相应文章有关。如果没有一个较窄的概念可以识别,则该文章至少与较宽泛的概念cpref有关。但是,这种“默认”类别cpref的识别标记无效,因此不被视为要预测的标签之一。出现cpref的文章包含在数据集中,但相应模型的开发和验证将忽略cpref注释。
弱标签数据集中每篇文章的摘要和标题都用来为文章生成2种类型的特征。尽管在PubMed Central中也可以找到某些文章的全文,但本文目前将分析重点放在标题和摘要上,这些结论可用于更多文章。此外,由于摘要中的概念预计与文章的主题相关,可以与文献主体中的概念形成鲜明对比。此外,使用MetaMap提取的文本中的概念为文献提供了附加的语义特征。不论其提取的资源词汇表或语义类型如何,所有提取的UMLS概念都被视为特征,而不仅仅是与MeSH描述符相对应的概念。与词汇特征不同,概念特征是二进制的。在词汇和语义特征方面,基于数据集的稀缺性,使用TF-IDF转换对特征进行加权。TF-IDF是术语频率-逆文档频率的缩写,是一种数字统计,旨在反映单词对集合或语料库中的文档的重要程度。MA是Manually Assigned的缩写,即手动分配。
此外,对于语义特征使用布尔术语频率。
由于某些特征的信息量较少或可能引入噪声,因此本文根据特征在训练数据中区分目标类别的能力,使用特征来选择其中最有用的信息。每篇文章的最终矢量表示仅基于这些选定的特征而产生,并用于分类模型的开发。
由于细粒度语义索引的任务是多标签的,因此本文采用一对多法,对与集合Ct中除cpref外每个概念对应的每个标签训练不同的二进制分类器。弱标签数据集中带有cpref注释的文章数据保留在数据集中,但它们的cpref注释将被忽略。在预测阶段,每个特定类别的模型对文献与相应的细粒度标签的相关性进行预测,并且对预测进行集成以生成每篇文献预测的所有细粒度主题标签的最终集合。
3 仿真与数据分析
3.1 仿真设置
本文提出的方法使用SciKitLearn库在Python中实现,并应用于AD的MeSH描述符。ScikitLearn提供了一系列监督与非监督学习算法的Python接口,它使用了简单又友好的BSD license,鼓励学术使用或商用。在这种情况下,集合Ct由同义概念cpref以及6个较窄的概念,分别是早发性AD(Early-onset AD, EOAD)、晚发性AD(Late-onset AD, LOAD)、局灶性AD(Focal-onset AD, FOAD)、家族性AD(Familial AD, FAD)、早期痴呆(Presenile Dementia, PD)和急性混淆性老年性痴呆(Acute Confusional Senile Dementia, ACSD)组成。需要强调的是,本文从PubMed中为AD描述符检索了68 542篇文章,其标题和摘要作为初始数据集。弱标签已分配给其中的51 450个,余下17 092个未进行标注的文献。
表1中总结了WS标签在初始数据集中的分布。需要强调的是,FOAD和ACSD在任何文章中都未被明确,因此这两个极其少见的概念被排除在模型训练和验证之外。实验的最初目标是将带有AD描述符的文章归类为与任何较窄的疾病类型相关的文章,而忽略cpref的标签。这些较窄的类别是4种疾病类型:PD、FAD、EOAD和LOAD。
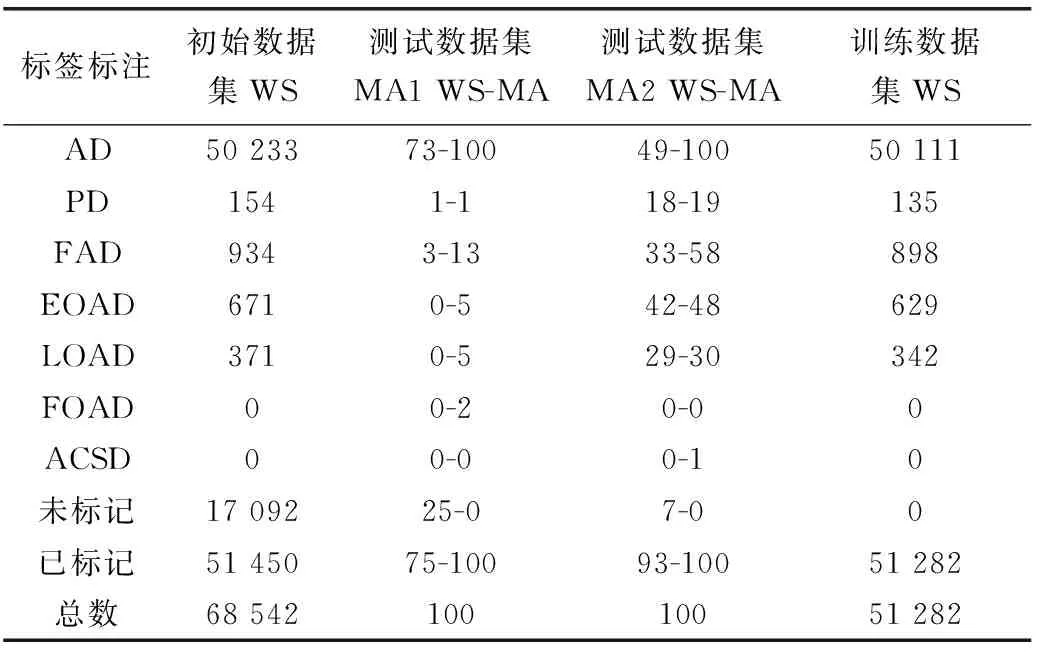
表1 AD数据集中每个标签的文章数
为了衡量分类性能,需要一些基本实况注释。为此,本文从初始数据集中保留了100个文章(MA1)的随机子集进行手动注释。但是,初始数据集是弱标签数据集,这表明类别的分布严重偏斜,大部分文章都标有cpref。为了提高随机子集中低流行类别的预期实验效果,本文基于弱标签选择了100个文章(MA2)的平衡子集。MA2数据集是使用基于标签组合的迭代过程构建的,标签组合是所有可用标签集的子集。在此过程中,在MA2中添加1篇用每个标签组合注释的文献,直到选择了100篇文献或选择了用该标签组合注释的文献的一半。
随后,本文2次手动对MA1和MA2中200篇文章的摘要和标题进行了审查,并分别对MA细粒度标签,使用了4种类别的宏观平均Kappa统计量。通过对2次注释结果的综合考量,共识注释被用作MA1和MA2中的最终依据。表1还展示了WS和共识MA标签在MA1和MA2测试数据集上的分布。
初始数据集中剩余的51 282篇文章用作WS训练数据集,开发多标签分类模型,以预测与t相关的文章的概念级标签。需要强调的是,考虑到具有和不具有特征选择的替代配置,本文在训练数据集上对不同的分类模型进行了训练。关于特征选择,根据卡方(Chi2)或ANOVA F统计量选择前k个特征,k范围为5至1 000。表2中列出了基于ANOVA F的前20个特征。对于特征类型,仅考虑词法特征或同时考虑词法和语义特征都是适用的。对于每个替代配置,本文训练了逻辑回归分类器(Logistic regression classifier, LRC)、线性支持向量分类器(Linear Support Vector Classifier, LSVC)、决策树分类器(Decision Tree Classifier, DTC)和随机森林分类器(Random Forest Classifier, RFC)。
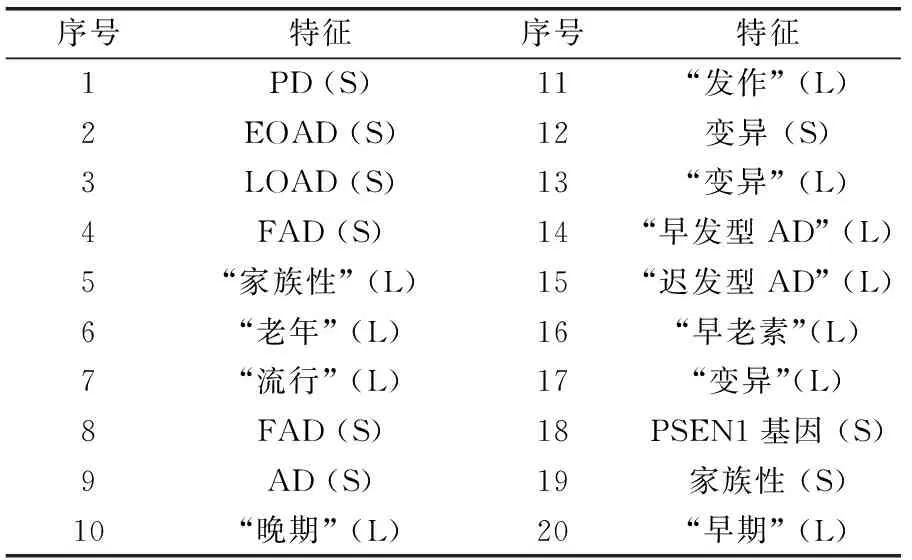
表2 F ANOVA的TOP 20词汇(L)和语义(S)特征
本文框架的重点是针对所有考虑的类别进行细分类,而无论其流行程度如何。因此,为了对方案进行整体评估,本文采用了基于标签的宏平均F1度量,该度量平均加权所有类别。除了训练性能较好的模型,本文还通过简单的基线方案进行比较。一个简单的对比方案就是使用所有可用标签(all available labels, AIIAII)标记所有文章;另一种更有效的方法是信任初始的弱标签(weak supervision labels, WSLabels);第三种方法,本文通过将所有可用标签(weak supervision all rest available labels, WSRestAll)分配给未贴标签的文献来扩展后者。
3.2 数据分析
图2、图3分别给出了上述每个分类器最佳模型在MA1和MA2数据集中的F1分数。对这些结果的第一个结论是,WSLabels基线方案在MA2中表现良好,MA2包含4个较小类别的许多文章,而在MA1中则表现较差。在MA1中,针对4个关注标签的WS注释较少。这表明,对于可用的细粒度语义索引,概念的出现确实是一种很好的WS方法,但对于较窄的概念或很少见的情况而言,这可能是不够的。
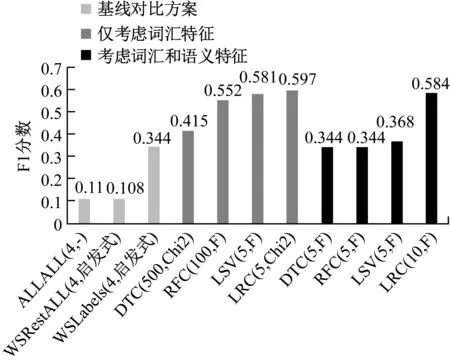
图2 不同方案最佳模型在MA1数据集中的F1分数
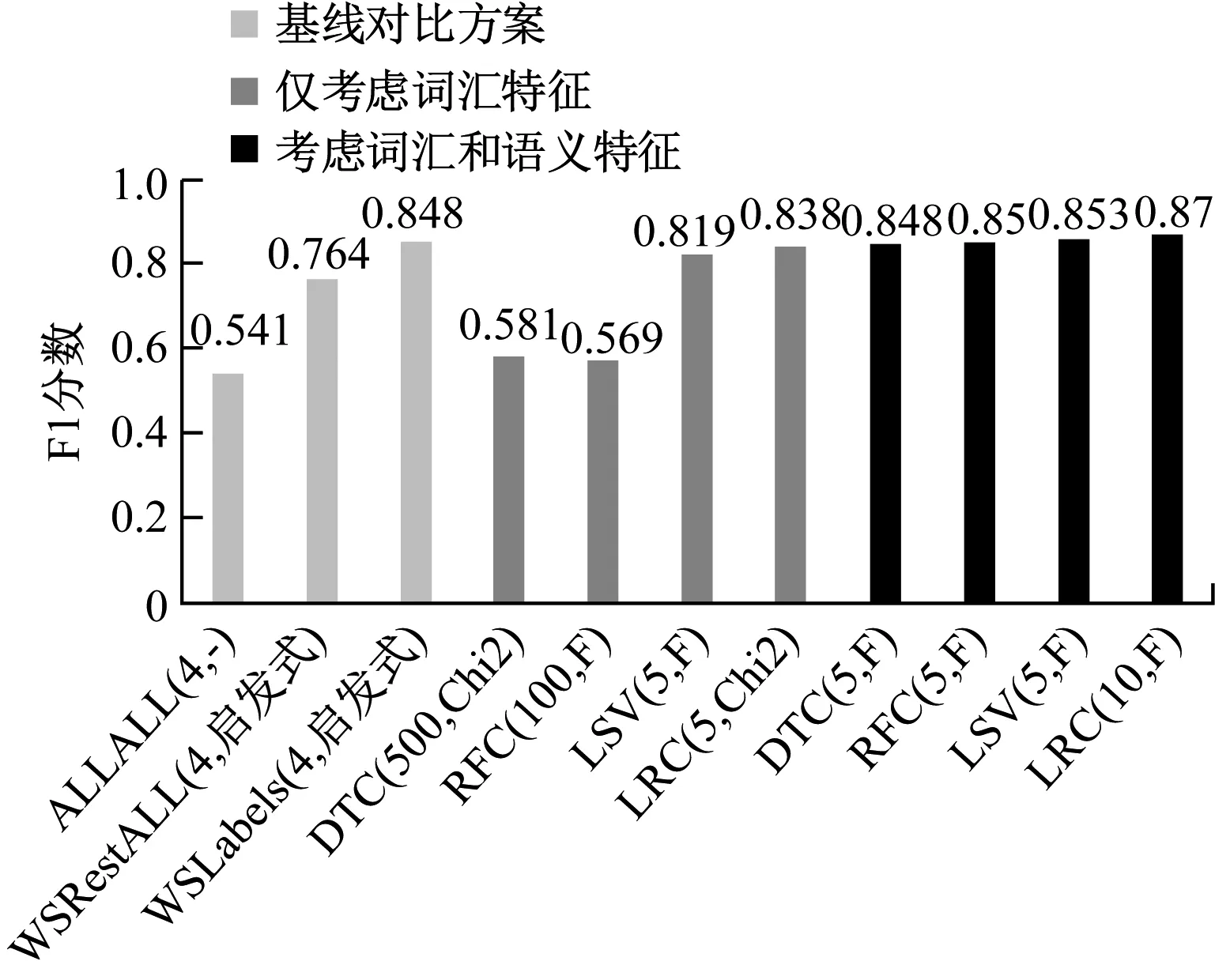
图3 不同方案最佳模型在MA2数据集中的F1分数
不论学习算法如何设置,所有仅通过词汇特征训练的性能最好的模型都优于超过MA1数据集中的基线方案,其中一些仅具有5个词汇特征。这个事实表明,在WS训练数据集上训练的模型可以改善用于弱标记的WS方法。在MA2数据集中,只有基于LSVC和LRC的最佳模型才能接近基线方案WSLabels的性能。该观察结果表明,概念出现在某些情况下可能是有用的,为基线方案提供了优势。
通过添加语义功能,基于DTC和RFC的最佳模型的性能几乎与基线方案WSLabel性能相同。这表明这些模型学会了信任语义特征ci,这与他们必须学习的WS标签完全相关。另一方面,2个数据集上表现最佳的模型都是基于LRC的模型。该模型使用语义和词汇功能,尤其是在MA1数据集上性能更佳。
4 总结
本文的贡献集中,将细粒度语义索引问题表述为多标签分类任务,提出了一种自动为该任务生成弱监督分类器的方法,并证明了在实际用例中应用此方法的可行性。此外,本文还提出了能够胜过性能优异对比方案的模型,这表明基于概念出现的弱标签训练可以产生预测模型,该模型确实可以比概念出现本身更好地泛化并产生注释。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
软件导刊(2018年2期)2018-03-10
现代电子技术(2018年1期)2018-01-20
电脑知识与技术(2017年26期)2017-11-20
科技资讯(2017年7期)2017-05-06
长江学术(2016年4期)2016-03-11
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
