
基于差分进化算法的思政多模态语料库智能构建
2022-07-12 05:26:04王晓莉
微型电脑应用 2022年5期
王晓莉
(渭南职业技术学院,马克思主义学院, 陕西,渭南 714026)
0 引言
语料库为通过科学取样和处理后的电子文本库,是一种承载语言知识的基本资源。语料库的研究已经在各类学科教学方面被广泛应用。文献[1]构建的命名性失语的汉语普通话语料库,以命名性失语症举例,搭建语料数据集。文献[2]基于自动回标的地理实体关系语料库构建方法,以地理实体的分类标准和语义关系作为参考标准,根据地理实体关系语言描述习惯构建标注体系。该方法的平均回标成功率较高,且标注速度较快,可将其应用于开放式的关系抽取任务中。文献[3]研究了用Elan软件构建上下文驱动的多模式语料库的方法和过程。通过在不同语境下创造丰富而真实的语言环境,并提供潜在的用户自定义策略,构建多模式英语学习语料库是一种理想的数据驱动学习模式范式。文献[4]利用数据挖掘技术和机器学习智能算法,对Internet上电力行业的信息数据进行获取和分类,构建电力行业语料库。
本文以思政知识作为语料库核心要素,而上述语料库大多数为文本型,在语境的丰富性方面存在一定程度的局限性,不符合当今多媒体时代的思政教学需求[5],因此本文创新使用多模态语料库,为语言学习带来新的生机。
本文提出了一种基于差分进化算法的思政多模态语料库智能构建方案。根据思政教育的内容特征,通过差分进化算法获得应用于语料库的最优内容,对语料库的各个功能模块进行分析,完成多模态语料库构建的全过程。实验表明,本文方法所构建的语料库能够在搜索关键词后给出准确的相关资料,且响应时间较短,具有一定的实际应用价值。
1 差分进化算法下思政多模态语料库构建
1.1 基于差分进化算法的语料筛选
考虑到语料库的针对性、规模性和代表性,根据思政教育的教学内容总结出多模态语料库内容需要兼顾时代性、全面性以及恰当性的特点。
因此,为获得符合要求的最优语料内容,DE(Differential Evolution,差异进化算法)对语料库内容进行智能筛选[6-7]。
(1)
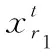
(2)
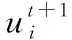
(3)

为了对群体的多样性进行衡量,引入多样性度量准则ρ,定义如下:
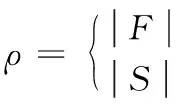
(4)
式中,|F|为每次搜索过程产生的可行解数目,|S|为生成的个体数目。同理,可通过约束违反度函数均值对群体中不同性解反约束强度进行衡量,如下:
(5)
式中,Po为集合内所含元素数量,Pc为种群内所含元素数量,P(y)为反约束强度函数。为减少算法的复杂程度,设可行集合规模为N1,不可行群体规模为N2,最大规模为N3,O为群体规模数量,多样性群体的复杂度可以表示为
(6)
则对差分算法进行一次迭代后的复杂度可以表示为
M=O(N1)+O(N1)+O(N1)+O(N2)+

(7)
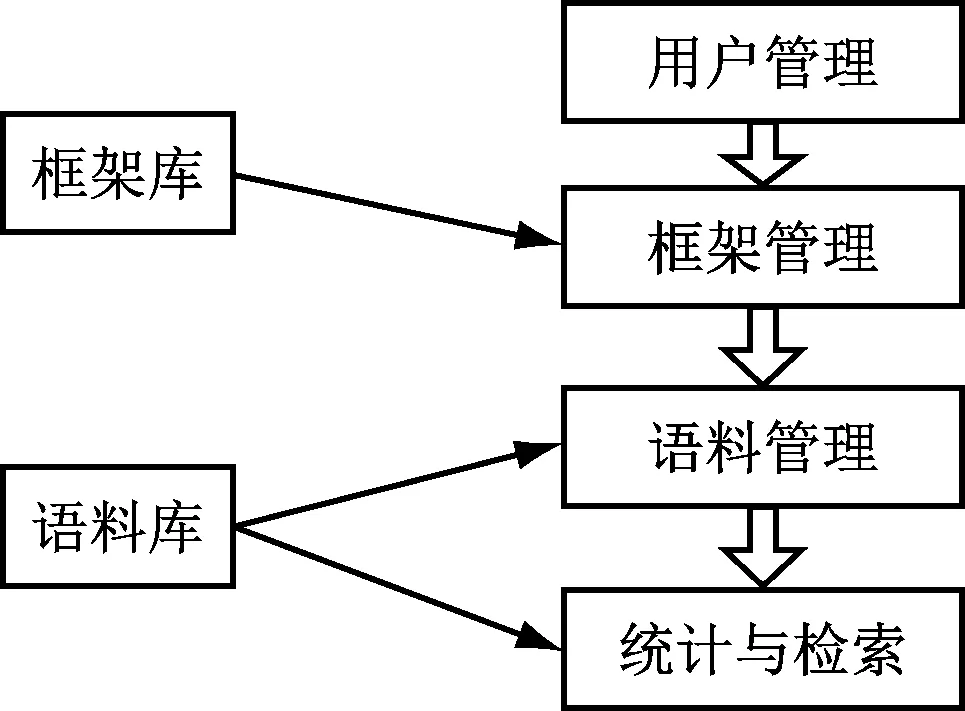
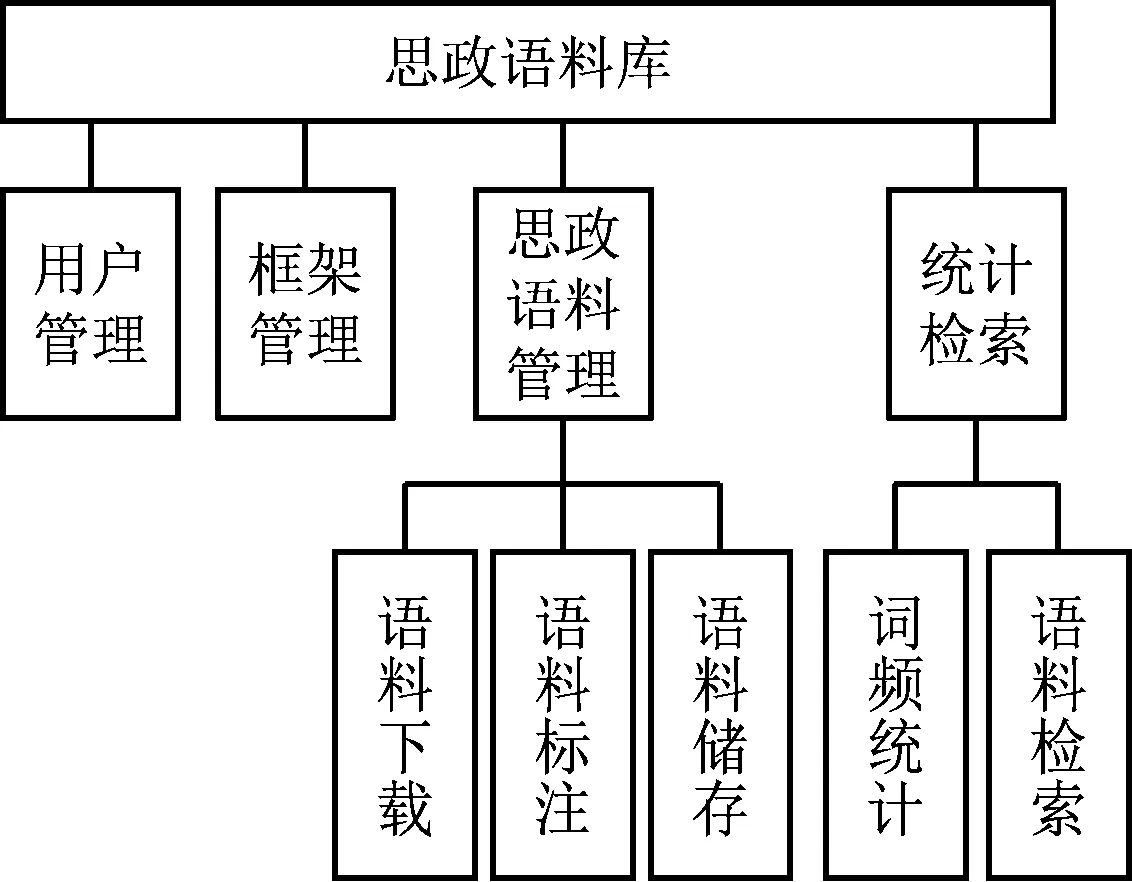
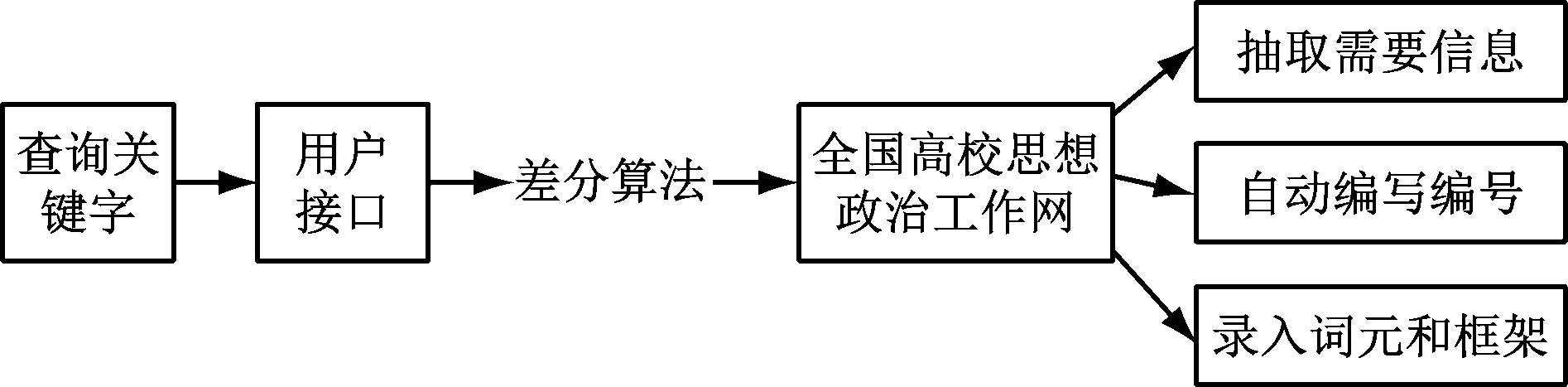
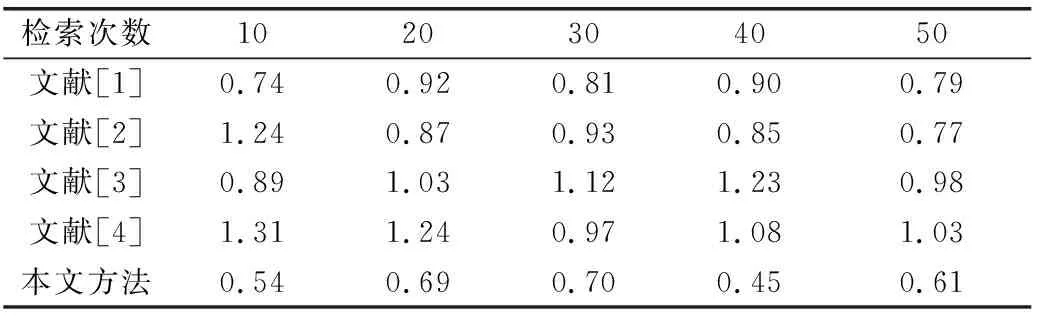
若搜索范围N=N1+N2+N3,则有效降低了处理后的复杂度M 1.2.1 语料库基本框架 语料库的总体框架如图1所示,整个体系主要分为4个模块,分别为用户管理模块、框架管理模块、思政语料管理模块、语料统计检索模块4个部分。 图1 系统基本框架结构 1.2.2 语料库功能结构构建 在图1基础上,给出语料库的功能结构如图2所示。 图2 语料库的功能结构 (1) 用户管理模块功能 在语料库内设置不同级别的用户组,并且赋予不同权限。用户权限服从最小权限原则,用户操作过程中没有明确的允许即视为拒绝,且拒绝权限优先。 (2) 框架管理模块功能 该模块具备查询、修改、删除思政知识等基本功能,且在使用时管理者能够根据实际情况对框架以及词元适当调整。 (3) 语料管理模块功能 该模块能够实现基于思政的网络语料下载。此处以“全国高校思想政治工作网”为数据源。根据关键字或用户请求处理利用所提差分进化算法搜索最优结果,并将搜索获得的视频或文本下载至本地磁盘中。规定下载的语料信息中要包括标题、作者等相关内容。每进行一次下载则自动赋予其编号,方便使用者管理,语料下载过程如图3所示。 图3 语料自动下载过程 该模块还能够实现语料标注功能。现阶段较为常用的语料库标注软件有ANVIL、Elan、DRS、MCA等[9]。由于Elan可以同时对多种行为符号进行研究,还能够以其为基础平台实现语料库的构建。因此本文选择Elan软件完成思政多模态语料库的标注和检索。 Elan软件[10]也支持音频和视频的多层标注,在构建语料库的过程中,可以根据实际授课的检索需要设定各层的标注信息,并通过对标注层属性的设置规定层与层之间的关系。标注者也可以在Elan软件中标注不同类型的语料单元,使语料库可以识别出特定的符号,从而提高了标注的准确性,同时也便于相关人员对语料库信息的管理。 针对语料库的片段显示与播放速度的控制,可以通过Elan软件导出含有视频或音频片段的标注文件,并支持这些文件以表格、文本和字幕等方式显示,在使用者使用时,还可以随时回放显示内容和控制播放速度,使语料库更加智能化。 (4) 统计检索模块功能 本文提供2种语料检索方式,分别为简单检索与高级检索。简单检索主要通过逐词索引的方式给出关键词在语料库中的相关信息,逐词索引能够记录关键词在语料库中出现的位置,也能具备词性选择功能,记录关键词的不同词性出现位置。高级检索以简单检索为基础,进一步提供更多层面的索引,如利用时间、作者、框架元素等进行检索[11-12]。 语料库功能结构实现的部分伪代码如下: Time register level (void * ARG) struct multiboot_ uinfo*mb=(struct multiboot_ Uinfo *) parameter; EDF_ uregister_ ulevel(EDF_ Uenable all); / / level 0: EDF CBS_ uregister_ ulevel(CBS_ Uenable all, 0); / / level 1: CBS RR_ uegister_ ulevel(RRTICK,RR_ .MAIN_ Yes, MB); / / level 2: loop dummy_ uregister_ Ulevel(); / / Level 3: Virtual Register module (); 1 / resource access protocol CABS_ uregister_ umudule(); //Resource access protocol Warning sound; 通过差异进化算法对语料库内容进行智能筛选,以获得符合要求的最优语料内容,并在此基础上,设计用户管理模块、框架管理模块、思政语料管理模块、语料统计检索模块4个模块,完成差分进化算法下思政多模态语料库的智能构建。 为验证本文所建语料库的可行性,对其进行实际应用分析。选用某|检索网站中的数据作为测试数据,以关键词搜索为例,在语料库内输入马克思理论后,语料库弹出的搜索结果如图4所示。 图4 搜索结果页面 从图4中可知,在语料库内搜索关键词后,系统给出的相关内容符合马克思主义检索要求,且未出现重复信息。这是因为本文使用差分进化算法优化了构建过程中语料筛选过程,证明了构建方法可以应用于实际工作中。 随后对语料库的搜索响应时间进行测试,并与文献[1]、文献[2]、文献[3]、文献[4]作对比分析,测试过程中每10次记录1次平均值,50次后3种算法所得结果如表1所示。 表1 不同语料库平均响应时长对比 单位:s 从表1中可以看出,相比文献[1]、文献[2]、文献[3]、文献[4],本文方法的响应时间更短,则可说明差分进化算法对语料库内容进行智能筛选,识别出特定的符号,从而提高标注的准确性。采用2种语料检索方式,寻求最优结果,能够有效地提高工作效率,提升用户的使用感。 为了提高思政教育工作效率,提出一种基于差分进化算法的思政多模态语料库智能构建。该语料库支持多种格式的音频、视频、文件的打开和播放,也能够实现正则表达式的精确检索与多模态语境的播放,用户可以在使用的过程中随时进行播放、暂停、回放等操作,实现智能化操作。 在未来的工作中,需要进一步为语义角色标注提供训练集,并且根据不同的用户需求,不断更新和完善语料库的内容。1.2 多模态语料库设计
2 仿真实验

3 总结
