
泛网智能变电站时钟系统的质量监管模块设计与实现
2022-07-12 04:53付强董成马文浩
微型电脑应用 2022年5期
付强, 董成, 马文浩
(1. 国网固原供电公司, 宁夏, 固原 756000; 2. 武汉国电武仪电气股份有限公司, 湖北, 武汉 430074)
0 引言
为了满足人们用电需要、提高供电服务质量,泛网智能变电站正在逐渐取代传统的变电站进行供电。智能变电站最大的特点是远程控制,通过光纤以太网实现智能变电站内各智能设备间的通信,因此一旦光纤以太网链路出现问题,智能变电站的运行可靠性就会大大降低,甚至消失[1]。为此,提前感知光纤链路健康程度对于保证光纤链路正常运行具有重要的现实意义。为解决上述问题,泛网智能变电站时钟系统被设计出来了,该系统工作原理是利用变电站运行大数据和设备台账信息,智能分析出虚回路所在光纤通道健康情况,然后智能感知运维数据并自动生成安全措施票工作票,并指导二次运维人员更高效地处理泛网智能变电站光纤回路的相关缺陷[2]。
在泛网智能变电站时钟系统当中,质量监管模块是其中最关键的部分,它是利用一种智能算法判断光纤链路是否存在异常情况。关于光纤链路异常监测中智能算法的选择有很多,如王红霞等过一种小波分析和改进支持向量机的算法进行光纤链路异常检测;牛咏梅通过构建正交基神经网络模型实现光纤网络异常检测;许鹏等将光纤网络异常数据检测的问题转换成求取最优解的问题,采用改进遗传算法实现了对光纤网络异常检测。
基于前人研究,本文进行泛网智能变电站时钟系统质量。本研究中以变电站运行大数据和设备台账信息为基础,通过数据挖掘算法实现对光纤链路的质量监管,以期为变电站运维提供技术支撑,并为智能电网其他系统提供服务和大数据支持。
1 泛网智能变电站时钟系统质量监管模块设计
泛网智能变电站站内光缆光纤智能设备光口和对时装置的可靠性是变电站网络正常运行的基础。由于站内众多的光跳线使用,基于站内光缆的基本特性,在变电站内环境变化和人员施工的情况下,可能对光纤造成弯曲、挤压;另外鼠类啃咬等伤害也不容忽视,因此监测光缆和尾纤的运行情况和智能设备光口稳定性是当前一个十分必要和迫切的问题[3]。为此,泛网智能变电站时钟系统质量监管模块的重要任务之一就是对光纤链路及其相关设备的健康状况进行识别和判断。
光纤链路中存在2个时钟系统,即发送时钟和接收时钟,这些时钟中包含了变电站运行大数据和设备台账信息,一旦光纤链路存在异常,这些数据和信息也会出现异常变化,因此可以通过这些数据来判断光纤链路是否存在异常问题,具体过程如图1所示[4]。

图1 泛网智能变电站时钟系统质量监管模块设计流程
1.1 历史数据信息处理
历史数据信息采集与分析是进行泛网智能变电站站内光缆质量分析的基础。在本文中,历史数据信息主要包括变电站运行大数据和设备台账信息2种,前者主要为变电站运行时产生的相关数据,后者主要为变电站中光纤衰减和光功率数据[5]。以上这些历史数据需要经过进一步处理才能满足后续分析需要,包括数据标准化、数据降维、数据离散化。下面进行具体分析。
(1) 数据标准化
采集到历史数据量纲不同,在后续无法进行比较分析,因此需要消除数据的不同量纲,进行数据标准化。目前,标准化方法主要有3种,即Min-Max标准化、正规化方法和log函数转换法,如表1所示[6]。
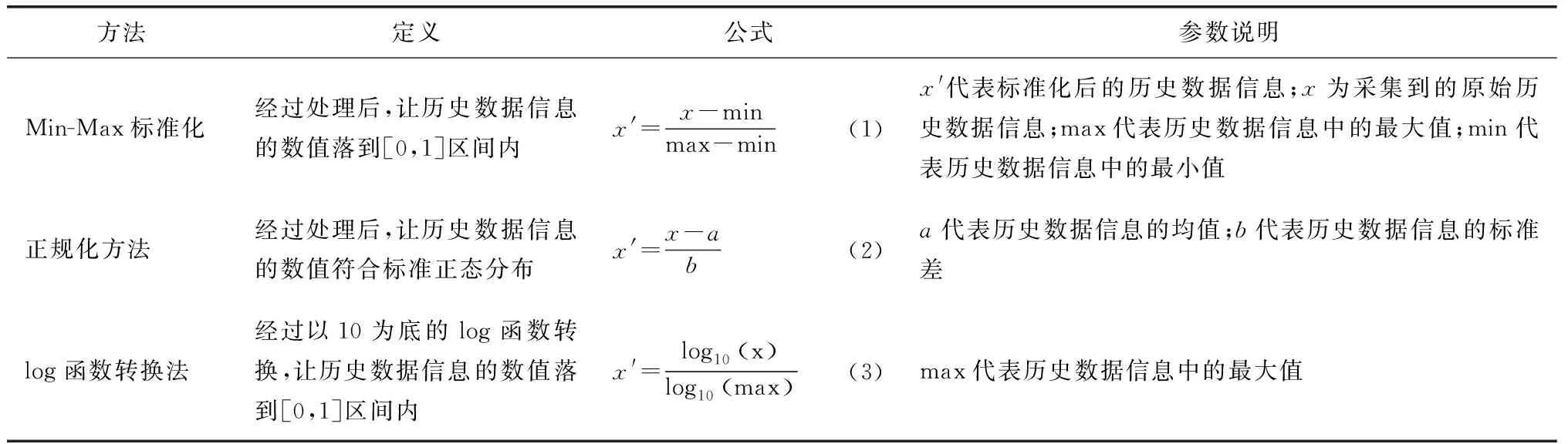
表1 数据标准化方法对比表
(2) 数据降维
采集到的历史数据来自不同的数据库,因此存在多个特征变量。多个特征变量虽然会提供丰富信息,但是也会增加计算量和计算难度,因此需要进行降维,在减少特征变量同时,尽量保证信息完整性[7]。数据降维方法主要有线性映射和非线性映射方法两大类。在这里采用主成分分析方法进行降维。
步骤1:假设待降维数据是一个包含m个样本的n维数据集。
步骤2:将数据集按照m行n列重新排列,组成矩阵。
步骤3:按列对数据集进行标准化处理,组成标准化矩阵。
步骤4:计算标准化矩阵中每列数据的协方差,组成协方差矩阵。
步骤5:用雅克比方法解协方差矩阵的特征方程,得到特征值和特征向量。
步骤6:将特征值从大到小排列,选取前k个特征值对应的特征向量,并组成特征向量P。
步骤7:计算特征向量的累计贡献率,选择超过85%贡献率的特征向量作为主成分。
步骤8:主成分就是降维后历史数据[8]。
(3) 数据离散化
在异常分析中很少将连续值作为识别模型的特征输入,而是将连续特征离散化为一系列01特征,然后输入到异常识别模型当中。以上这一过程就是数据离散化过程[9]。在这里引入信息熵理论,进行数据离散。具体过程如下。
步骤1:假设待离散数据是一个包含m个连续属性s个类别的数据集。
步骤2:计算数据集的一致性水平Y1。
步骤3:按照从小到大的顺序排列属性值。其中需要注意的是,相同的属性值,视为一个区间。
步骤4:计算所有属性相邻区间的合并标准值IMC,该值就被视为一个断点。
步骤5:合并最小IMC值的两个区间,即两个断点构成一个区间。
步骤6:再次计算当前数据的一致性水平Y2。
步骤7:判断Y1和Y2之间的差值是否小于数据可容忍的信息丢失率。若大于,则结束离散化操作;若小于,则回到步骤5。迭代地合并相邻区间,在最小化信息丢失的情况下,将连续属性值域转换成小数目有限的区间,直至满足上述迭代终止条件[10]。
1.2 历史数据特征提取
历史数据特征提取是建立关联规则库的关键。数据特征是进行后续匹配识别的基础。历史数据特征提取思路是从样本数据中提取出潜在的异常行为模式,产生相应的关联规则,并转换成符合Snort规则语法的入侵检测规则,添加到规则库中[11]。在该模块中,采用遗传算法进行数据特征提取,具体过程如下。
步骤1:输入样本数据库,随机从中选择一个特征,并计算其信息熵。
步骤2:判断信息熵值是否大于等于设定的阈值。若超过阈值,则选择该特征,记为第一个有效特征x,否则回到步骤1重新进行一个特征,直到信息熵值大于等于设定的阈值s1[12]。
步骤3:再次从样本数据库随机选择第二个特征记为y,并计算x与y之间的互信息值。
步骤4:判断x与y之间的互信息值是否大于等于预定阈值s2。若大于等于预定阈值s2,则选择y作为第二个有效特征,否则回到步骤3重新进行选择,直到选出第二个有效特征为止。
步骤5:组合x与y构成一个类别C,并计算其中每个特征与样本之间的相关性,去除其中的不相关特征和冗余特征,构成有效特征集L。
步骤6:对特征集L进行偏F检验,得出L1。
步骤7:以L1构建初始群体,并进行染色体编码。
步骤8:计算每个个体的适用度值并排序,选择适用度值前k个个体组成新的群体G。
步骤9:根据适用度值,进行选择、交叉和变异操作。
步骤10:判断当前个体适用度值是否达到最大进化代数,若满足上述迭代终止条件,则输出最优解;否则回到步骤9,继续遗传操作[13]。
步骤11:根据输出的最优解选出编码为“1”的特征构成特征集。
1.3 基于数据挖掘的光纤链路健康状况判断
数据挖掘的作用是从大数据集中发现目标信息。目前数据挖掘主要分为五大类,即分类分析、关联规则分析、序列模式分析、离群点分析和聚类分析。其中,聚类分析是最常用的,典型算法包括密度聚类算法、分层聚类算法、网格聚类算法、k-means算法、模糊聚类算法等。在本章节选择k-means算法进行光纤链路健康状况判断,其基本思路是计算测试样本与各类特征之间的相似度来判断,具体过程如图2所示。
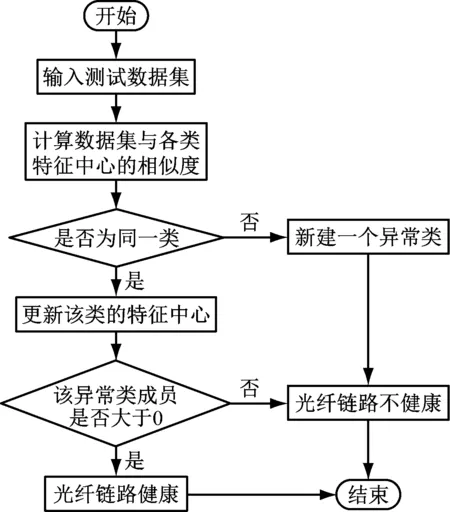
图2 基于k-means算法的光纤链路健康状况判断流程
计算测试样本X=(x1,x2,…,xn)与各类特征集Y=(y1,y2,…,yn)之间的相似度是k-means算法的关键。目前计算公式主要有以下几种。
(1) 欧几里得距离:
(4)
(2) 曼哈顿距离:
(5)
(3) 明可夫斯基距离:
(6)
式中,p≥1是一个变量值。
2 仿真测试分析
为测试所研究的泛网智能变电站时钟系统质量监管模块设计的有效性,以引言中前人研究的3种方法作为对比项,即基于小波分析和改进支持向量机的检测方法、正交基神经网络模型检测方法和改进遗传算法的检测方法,在CPU 为 Intel pentium G630 2.7 GHz,内存为 2 GB,操作系统为 Windows XP 的计算机中进行仿真测试。选择型号为T5100-S型号的智能时钟同步系统,结合泛网智能变电站数据和卫星信号,由光纤秒脉冲方式进行时钟同步,设置同步精度要求在1 μs/h,ANNONCE报文每2 s发送一次,SYNC报文每500 ms发送一次。
2.1 光纤链路数据分布情况
光纤链路数据分布情况如表2所示。
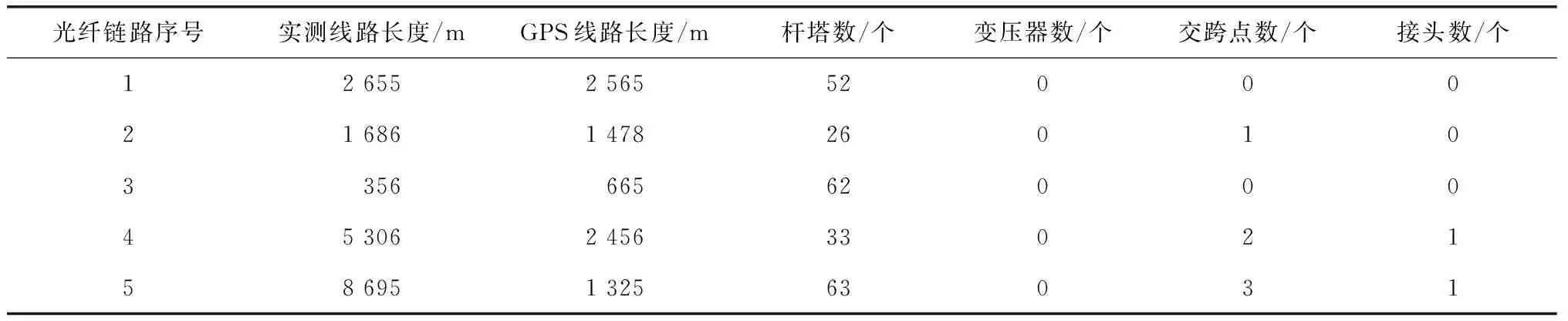
表2 光纤链路数据分布情况
2.2 关则数据库
按照表2,提取数据特征,生成关联规则库,具体如表3所示。
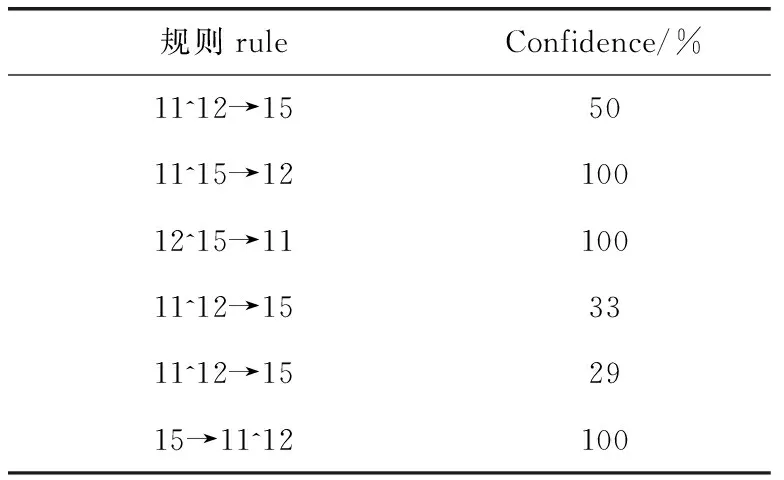
表3 关联规则库(部分)
2.3 测试环境搭建
为获取测试样本需要搭建测试环境。该测试环境搭建需要光纤线缆、内部总线控制卡、内部总线底板、测控板卡和运动控制卡等几部分,如图3所示。

图3 仿真实验测试环境
图3仿真实验测试环境的参数设置情况如表4所示。
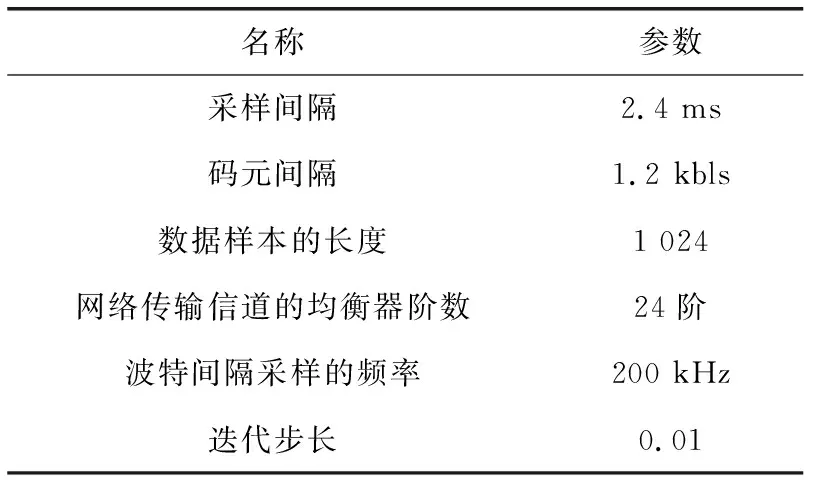
表4 仿真参数设置
2.4 测试数据采集
运行图3仿真实验测试环境,采集到的测试数据分布情况如表5所示。
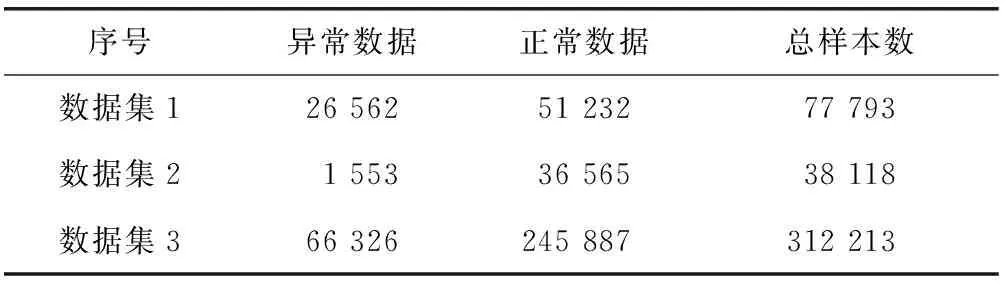
表5 样本分布情况 单位:bit
2.5 结果显示
将数据输入计算机,运行所研究的光纤链路健康状况判断方法,然后输出结果。结果显示界面如图4所示。
图4 光纤链路健康状况判断结果显示界面
2.6 光纤链路质量监管质量判断结果统计与分析
相同仿真条件下,对比3种已有的方法进行光纤链路质量判断,然后统计所有判断结果的漏报率和误报率结果如表6所示。
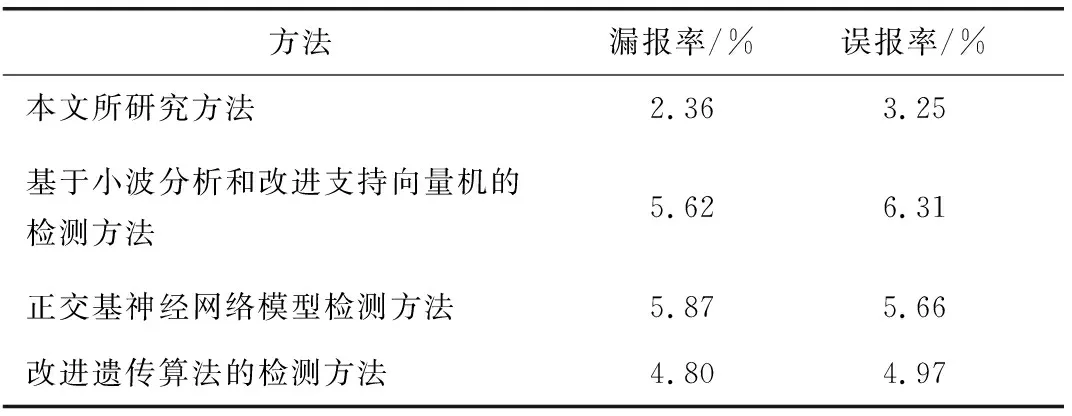
表6 光纤链路质量监管质量判断结果
从表6中可以看出,与3种前人研究的方法相比较,本文所研究方法应用下漏报率和误报率都较低,说明所设计的质量监管模块是有效的。
3 总结
泛网智能变电站时钟系统质量监控管理模块的设计旨在基于电力物联网技术、对象组件技术及相关国家标准等,以全面统一规划的技术架构,实现智能变电站中信息空间和物理空间的无缝连接,提高电网运行效率和可靠性,提高效率和经济效益。为此,针对该模块的关键,即光纤链路健康状况判断进行研究。经测试,证明了本文所研究内容的有效性,为泛网智能变电站时钟系统中质量监控管理模块的完善提供了参考和借鉴。
猜你喜欢
火力与指挥控制(2022年8期)2022-09-16
网络安全与数据管理(2022年6期)2022-07-13
移动通信(2021年5期)2021-10-25
小学生学习指导(低年级)(2020年10期)2020-11-09
家庭影院技术(2020年1期)2020-06-24
家庭影院技术(2019年4期)2019-04-17
汽车实用技术(2019年6期)2019-04-11
数学大王·低年级(2018年9期)2018-10-24
中学物理·初中(2017年8期)2018-03-06
科技创新导报(2016年27期)2017-03-14
