
一种融合引导滤波的密集人群计数方法研究
2022-07-11 01:12左安康陈锦秋谢小芳
电子技术与软件工程 2022年7期
左安康 陈锦秋 谢小芳
(1.遵义医科大学医学信息工程学院 贵州省遵义市 563000 2.遵义医科大学图书馆 贵州省遵义市 563000)
1 引言
人群计数是计算特定场景中人群目标的数量。随着城市人口的迅速增加,在公共场合不可避免会出现大量的人群,当人群过于密集时,会带来一定的不稳定因素。对公共场合的密集人群及时进行数量统计,在人群密度超过一定预先设定的阈值时发出预警,能有效避免因人群大量聚集而引发的踩踏等事故。同时人群计数在交通客流量预测,智能视频监控,动态分配城市资源等方面都有着广泛的应用。
随着计算机视觉技术的发展,监控视频设备越来越多,基于计算机视觉的人群计数方法因为其高效性和精准性而渐渐成为目前主流的方法。
在密集场景下的人群计数研究中,复杂背景通常会对计数结果的精度造成一定的干扰,针对该问题,有研究者试图采用图像分割的方法将前景与背景进行分割,在分割之后的前景上进行人群计数。不正确的分割会对计数精度造成不可逆的影响,因此对这类算法的鲁棒性要求非常高。
针对人群目标在图像中存在的尺度变化问题,文献采用多列网络提取3 中不同大小尺度的特征,但多列网络的运算量不可避免会比单列网络大许多。
针对以上情况,本文提出一种融合引导滤波的密集人群计数方法。
2 密集人群计数方法整体结构
本文方法的网络结构可分为前端和后端两部分,前端采用去掉全连接层的VGG16网络提取特征,后端采用改进的空洞卷积融合特征,最后输出人群密度图及人群数量。整体网络结构如图1 所示,具体可分为引导滤波去噪模块,特征提取主干网络模块以及感受野扩大模块,下面分别介绍这三部分。

图1:整体网络结构图
2.1 引导滤波去噪
滤波操作能够使得特定频率的图像信号通过,抑制其他频率的信号。引导滤波在保持边缘轮廓清晰的前提下,能够有效减少无效信息的干扰,避免过拟合。对于给定引导图像I,输入图像p,输出图像q,引导滤波的定义如下:

其中i 和j 是像素位置,滤波器权重W是关于引导图像I 的函数,引导滤波器相对于输入图像p 是线性的,在一个像素i 处的滤波输出用一个加权平均值来表示。引导滤波的关键假设是引导图像I 和输出图像q 之间存在局部线性相关,即假设q 是一个以像素k 为中心的窗口ω内的引导图像I 的线性变换,计算公式为:


2.2 特征提取主干网络
考虑到VGG 网络强大的特征提取能力,本文采用VGG对数据集进行特征提取,但是VGG 网络过多的池化层会使得输出特征图的分辨率太小,不利于小目标的人群计数。人群计数任务只有一个输出类别,而原始网络全连接层有1000 个类别,因此,本文最终选取了VGG-16 的前10 层提取特征,并去掉了全连接层,主干网络如表1 所示。
表1 中卷积层的参数表示为“Conv(卷积核x 卷积核)-(卷积核数量)”,每个卷积层后接一个ReLU 激活函数,为了保持和前一层相同的尺寸,卷积层采用了0 填充操作,池化窗口的大小为2x2,步长为2。
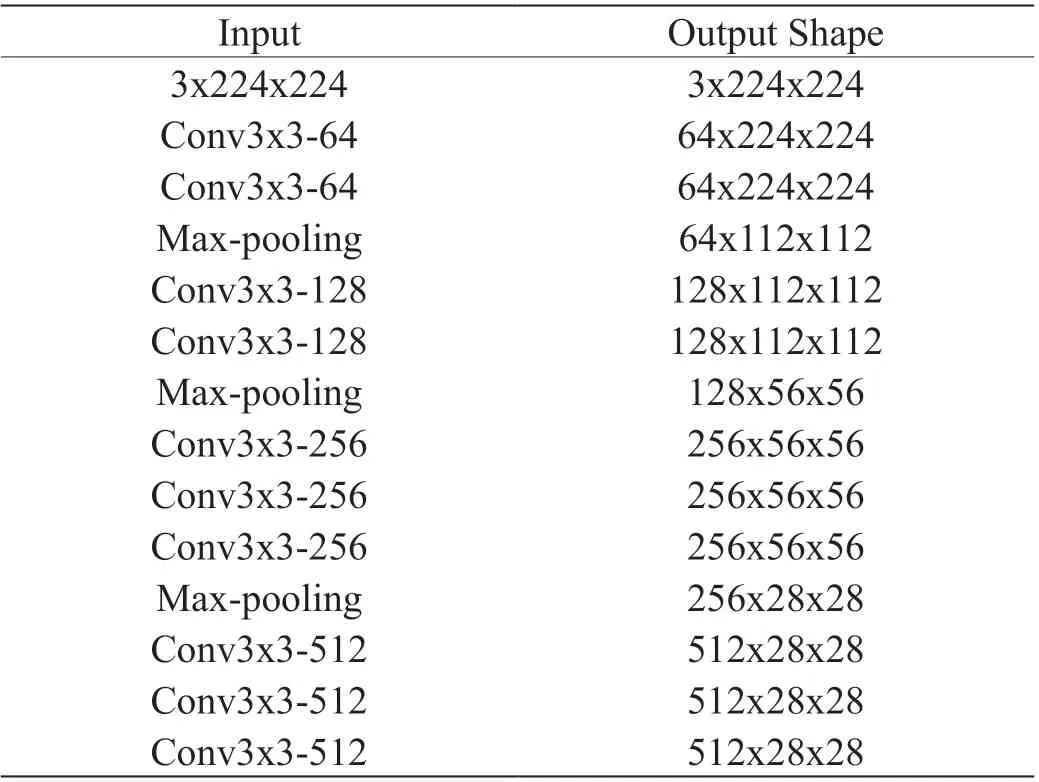
表1:特征提取主干网络
2.3 感受野扩大模块
空洞卷积最先是在图像分割任务中被提出的,通过在正常卷积中间填充零,其目的是在卷积核尺寸不增加的前提下扩大神经元的感受野。
如图2 所示,在正常卷积中间填充0 即为空洞卷积,空洞卷积可以在不增加参数的前提下扩大感受野,缺点是特征图会丢失一部分信息。

图2:空洞卷积示意图
为了弥补单列网络处理多尺度人群信息的不足,本文基于空洞卷积设计了感受野扩大模块,使得网络后端能获取到不同尺度大小的特征信息,同时,通过叠加合适的空洞率,有效避免了特征图信息丢失问题。
表2 中的感受野扩大模块主要由7 个带空洞的卷积层构成,参数表示为“Conv(卷积核x 卷积核)-(卷积核数量)-(空洞率)”,除最后一层外,每个卷积层后都接一个ReLU 激活函数。

表2:感受野扩大模块
3 实验结果与分析
为了验证本文提出方法的有效性,本文在两个密集人群数据集上进行了相关实验。
3.1 评价指标
本文采用MAE 和MSE 来衡量算法性能。本文采用平均绝对误差(Mean absolute error, MAE)和均方根误差(mean squared error, MSE)来评价算法的性能,它们的定义分别如下:

3.2 数据集
ShanghaiTech 数据集,包含PartA 和PartB 两部分,训练集和测试集共1198 张图像、共包含了330165 个人头标注,场景变化多样。其中,PartA 数据集十分密集,主要为一些大型集会、运动会等人群集中的场景,包含300 张训练图像和182 张测试图像,单张图像的人群数量范围为33 人至3139 人,人群十分密集;PartB 数据集为上海市区某街道实拍图,包含400 张训练图像和316 张测试图像,单张图像的人群数量范围为9 人至578 人,人群密度总体不及PartA。
BeijingBRT 数据集为北京某个快速公交车站的候车人群,一共包含720 张训练图像和560 张测试图像,每张图像分辨率大小固定为640x360。数据集采集了多个日期、从早到晚不同时刻的图像,包含场景丰富:有白天强烈的太阳光线、有阴天、有雾天、也有夜晚昏暗的场景。单张图像人群范围从1 人至64 人。
3.3 密度图生成
对数据集采用的是点标注的有监督学习方法,点标注的文件过于稀疏不能直接用于网络训练,需要对其进行预处理,转换成可以用于网络训练的数据。其转换过程如下:首先构造一个二维矩阵,矩阵尺寸和原图相同,矩阵中的值初始化置0,接下来将矩阵在图像对应标注文件中有人的位置置1,再使用高斯核函数对稀疏的二维矩阵进行卷积,使得每个孤立的点变成服从高斯分布的小块连通区域。
根据数据集密集程度的不同,采用不同的高斯核函数对数据进行预处理。在普通密集数据集下使用固定高斯核,在高度密集场景下则使用自适应高斯核进行转换,生成用于训练的真实密度图,自适应高斯核定义如下:

3.4 参数设置
由于ShanghaiTech PartA 数据集密集度高,因此使用自适应高斯核,ShanghaiTech PartB 和Beijing BRT 数据集则采用kernel=15 的固定高斯核。经过多次实验对比,确定了如表3 所示的训练参数。

表3:训练参数设置
3.5 实验结果分析
为了获取不同尺度下的人头信息,在感受野扩大模块中设置了不同的空洞率。
表4 为本文提出的方法和目前的主流方法在ShanghaiTech 数据集上的实验对比。可以看出,在PartA 数据集上本文提出方法的MAE 和MSE 分别为67.7 和105.4,在PartB 数据集上MAE 和MSE 分别为9.7 和16.2,均超过了其他方法,证明了本文方法的有效性。

表4:ShanghaiTech 数据集实验对比
从表4 可以看出,在数据集PartA 上的误差比PartB 大,原因在于PartA 数据集过于密集,人群被遮挡得比较严重,并且远处的人群目标太小,因此,最后人群识别的MAE 及MSE 均不如PartB。
图3 展示了在ShanghaiTech 数据集上的部分实验结果,可以看出,第一张图真实人群是402人,估计的数量是444人,第二张图像真实值是109 人,估计的数量是112,误差较小,且人群空间分布较能反应真实的分布情况。

图3:ShanghaiTech 部分实验示例
表5 对比了本文方法和当前主流方法在Beijing BRT 数据集上的性能表现,可以看出,提出的方法MAE 为1.44,MSE 为2.06,超过了大部分方法,表现出了较好的性能。但是本文方法略微次于DR-ResNet,原因是该论文使用了一种深度递归网络的方法,反复学习图像特征,学习到了更深层次的特征。

表5:Bejing BRT 数据集实验对比
图4 展示了在BeijingBRT 数据集上的部分实验结果,真实人群是63 人,估计的人群数量是65 人,误差较小,且人群空间分布较能反应真实的分布情况。

图4:BeijingBRT 部分实验示例
为了验证引导滤波预对网络性能的影响,分别在上述两个数据集上进行了验证实验,实验结果如表6 所示。

表6:引导滤波对比实验
从表6 可以看出,增加引导滤波后,在三个数据集上MAE 均有所下降。鲁棒性方面,在PartA 数据集上,加入引导滤波去噪模块后模型的MSE 下降了近10 个点,说明模型的泛化能力得到了明显提升。在PartB 和BeijingBRT 两个数据集上MSE 变化不明显。
4 结论与展望
在人群计数研究中,针对密集场景下的复杂背景问题,本文提出了一种融合引导滤波的密集人群计数方法,通过引导滤波去掉了复杂背景信息的学习,同时保留人头边缘信息,有效减少了复杂背景信息对人群目标的干扰。针对尺度变化问题,本文提出一种扩散的空洞卷积,通过设置合理的空洞率,有效避免了网格效应造成的特征图信息丢失,在两个数据集上对比了本文方法和最近一些方法,本文方法在精度和鲁棒性方面都有较大的提升,当然,本文方法也有一些缺点,例如主干网络采用的是VGG,参数量及运算量还是较大,下一步考虑采用更为轻量化的网络,以方便部署在移动边缘端设备上。
猜你喜欢
数学小灵通(1-2年级)(2021年11期)2021-12-02
中等数学(2020年8期)2020-11-26
数学年刊A辑(中文版)(2020年2期)2020-07-25
小学生学习指导(低年级)(2020年4期)2020-06-02
数学物理学报(2019年6期)2020-01-13
数学小灵通·3-4年级(2017年11期)2017-11-29
数学物理学报(2017年5期)2017-11-23
故事作文·高年级(2017年2期)2017-03-01
新闻传播(2015年20期)2015-07-18
新课程学习·中(2013年3期)2013-06-14
