
基于无监督3D-GAN 网络的快速三维重建技术研究
2022-07-11 07:44马文煜章方圆陈伟斌
电子技术与软件工程 2022年10期
马文煜 章方圆 陈伟斌
(温州大学计算机与人工智能学院 浙江省温州市 325000)
1 引言
在过去的几十年里,研究人员在三维重建方面取得了十足的进展,提供了诸多解决三维重建的方法,如Van等人于2011 和Veltkamp等人于2008 提出的理论。但是,这些方法大多是通过拿“模型库”中的“零件”来合成新的对象。虽然生成的结果逼真,但其三维重建的结果只跟“零件”相像,其重建模型局限性过高,无法做到创新性地生成新的物体。而采用3D-GAN 网络的三维重建技术有着诸多好处:譬如,使用对抗性标准,而不是传统的启发式标准,使生成器能够隐式捕获对象结构并合成高质量的3D 对象;可以在没有精确参考模型的情况下,在无监督的情况下也可以生成3D 对象。
本文改进一种基于3D-GAN 的无监督三维重建算法,借助对抗网络可以生成更加真实样本的优点来重建3D 世界中的物体。该方法融合了3D-GAN和体积卷积网络各自的优点。
(1)我们可以从潜在的概率空间(高斯分布或是均匀分布)随机生成一些噪声,再借助生成器来生成新的3D对象,以达到创新性的生成物体的目的。
(2)由于对抗式生成网络中的判别器、生成器是同步进化的,可以凭借训练完成的判别器判别现实中的三维物体,也可以人为构造噪声输送到生成器来生成指定的物体。
实验表明,我们的方法可以生成高质量的3D 对象,并且我们的无监督学习特征在诸如椅子、汽车、桌子等实际3D 对象识别上取得了与监督学习方法相当的重建结果。
2 网络模型设计
2.1 生成式对抗网络
生成式对抗网络(GAN, Generative Adversarial Networks)是一种非监督式学习的一种方法,在2014 年由Goodfellow提出,其灵感来自于零和博弈。GAN(生成对抗网络)分别由生成网络和判别网络组成。生成网络通过输入随机的采样参数,生成逼近真实样本的案例。判别网络是真实样本的概率输出,用于区分生成网络的生成案例。两个网络相互生成,互相对抗,达到无法区分生成网络生成案例是真实的还是伪造的情况。
3D-GAN 的训练流程如图1 所示。

图1: 3D-GAN 训练流程图
在我们的3D 对抗式生成网络中,生成器接收了从概率潜在空间随机采样的200 维噪声z,生成出32*32*32 的立方体。这个立方体就是3D 体素空间上的G(z)。判别器接收来自真实样本32*32*32 的体素立方体和生成器生成出的立方体,输出其为真为假的概率值D(x)或是D(z),大小介于0 到1 之间。生成器和判别器网络结构参数设置见表1。
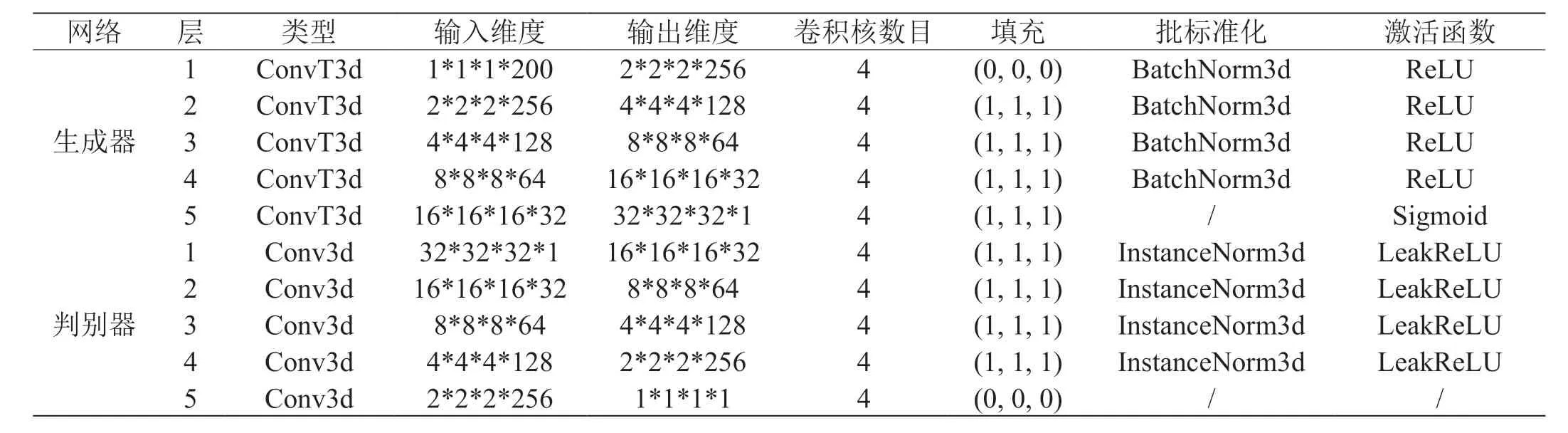
表1: 生成器和判别器网络结构参数
2.1.1 生成器网络结构
我们网络模型为全卷积神经网络,结构如图2 所示。生成器网络主要由复制的5 层块组成。在每一个层块中先是一个3D 转置卷积层ConvTranspose3d,size 为4,stride 为2,padding 为(1, 1, 1)。紧接着是一个批标准化BatchNorm3d,接收上一层3D 转置卷积层的输出。最后一层是ReLU 激活函数。在最后一层块即第5 层块中,删减了批标准化函数并把激活函数换成了Sigmoid 函数。训练生成器时,先将200维的噪声z 展开成层块规定输入的格式out(维度为[200, 1, 1,1])。然后就是把out 依次输入到这5 个层块中。待out 从最后一个层块输出时,out 的维度已经为3 维物体的维度即[32, 32, 32]。

图2: 生成器网络结构
2.1.2 判别器网络结构
判别器网络的结构基本上跟生成器网络类似,因为其接受的是真实3D 模型或是生成器虚假3D 模型的输入,所以在结构顺序上是跟判别器是相反的,如图3 所示。类似的,主要是由5 层块组成。在每一个层块里先是一个3D 卷积函数Conv3d,size 为4,stride 为2,padding 为(1, 1, 1)。 紧接着是一个批标准化函数InstanceNorm3d,接受来自上一层3D 卷积函数的输出。最后一层是受到Mass 等人提出的建议使用了激活函数LeakyRelu,而不是激活函数Relu。因为在反向传播过程中,对于LeakyRelu 输入值小于零的部分,较于Relu 激活函数将其全部变成0,LeakyRelu 激活函数可以计算得到出梯度但是Relu,解决了神经元“死亡”问题。在训练的最后一层,移去了批标准化函数和激活函数。训练判别器时,首先把传入模型的维度变化成[32, 32, 32],以供判别器输入第一层块网络。然后,把这个结果依次传入5 个层块中。最后一层的输出即为这个3D 模型为真为假的概率值,大小介于0 到1 之间。

图3: 判别器网络结构
2.2 目标函数

在训练判别器时,固定生成器。D(G(z))是对噪声生成样本的概率输出。在训练过程中,希望它的值越靠近1 越好,即越大越好。因此1- D(G(z))的值就越小越好。因此是最小化V(D,G)。

在训练判别器时,固定生成器。D(x)是判别器接受真实样本的概率输出。希望它的值越靠近1 越好,即越大越好。D(G(z))则相反,希望其越小越好,体现出分辨假样本的能力。那么,1- D(G(z))就是越大越好。因此需要最大化V(D, G)。
这个原始的目标函数于2014 年提出,随着时间、技术不断增长。这原始目标函数应对现今大型深度学习网络显得有些力不从心,伴随着许多问题。例如,训练过程中不神经网络不易稳定,而且目标函数值(loss)的大小跟以往深度学习的目标函数不同,易于上下波动,无法借此来分别出训练过程的好坏。Bengi等人通过分析GAN 公式解释了GAN 训练过程中不稳定的原因。主要是由于等价优化的距离衡量JS 散度易于趋近零导致的,因此在下文中提出了解决方案。
3 算法改进
3.1 新目标函数
由于传统的目标函数存在着梯度爆炸难以收敛等问题,本文中选中了WGAN-GP 作为目标函数。WGAN-GP 目标函数是WGAN 目标函数的变体,由Ishaan Gulrajani等人于2017 年提出。公式如(4)所示:


WGAN-GP 是由WGAN 进化而来的。WGAN 目标函数利用了Wasserstein 距离来度量真实分布和生成分布间的距离,目的是解决传统目标函数存在问题。另外的,WGAN目标函数中用到了权重剪裁技巧来保证判别器满足Lipschiz连续,使定义域内每点梯度不超过某个常数。当判别器满足了Lipschiz 连续之后,判别器和生成器的训练过程得以稳定训练结果得以收敛完善。
虽然WGAN 目标函数采用了权重剪裁等技术保证了Lipschiz 连续,但是由于其剪裁结果会让大部分权重趋近于两个极端,很容易一不小心就梯度消失或者梯度爆炸。
因为判别器属于多层网络,即使每一层的剪裁阈值稍微缩小,多层叠加后会加速衰减;相反,如果每一层稍微变大,多层叠加后会带来爆炸性增长。所以,如何恰到好处的设置这个阈值,让生成器获得恰到好处的回传梯度,但是在实际中往往难以实现。因此 WGAN-GP,WGAN 的升级版,通过梯度惩罚(GP, gradient penalty)代替权重裁剪,从而保证了Lipschiz 连续。梯度惩罚要求判别器原始输入梯度的L2范数约束在双边约束附近。
3.2 3D-GAN变化
3.2.1 改变了训练时候目标函数Loss 判定方式
对GAN 来说,目标函数至关重要。因为,它不仅决定了生成器G 和判别器D 如何共同“进步”,还决定了这个模型训练时候是否稳定。
之前的目标函数是:

3.2.2 改变了判别器和生成器更新逻辑
对判别器来说:
Critic: maxE[critic(real) ]-E[critic(fake)],即要求最大化判别器对真实图片的评估减去判别器对生成器生成假照片的评估。与此同时,由于WGAN-GP 中GP(gradient penalty,梯度惩罚)的要求。通过在loss_critic 中加入梯度惩罚值gp,改进了weight clipping 造成的梯度爆炸和消失问题。
对生成器来说:
Generator: maxE [critic(gen_fake)],即要求最大化判别器对生成器生成假照片的评估。然后对这个目标进行迭代要求,生成器就会生成出越来越逼真的图像。
4 实验结果及分析
4.1 实验环境
硬件条件为GeForce RTX 3060 显卡和i5-11400H 的intel处理器。软件环境是cuda11.3+pytorch1.10。实验的数据集来自ModelNet40,拥有40 个种类的CAD 模型。
4.2 训练模型
4.2.1 数据预处理及参数设置
训练过程时,总轮数(epoch)设置成50,把每批次训练数据的数量(batch_size)设置成28。梯度惩罚权重(λ)设置为10。参考WGAN-GP 的建议,生成器和判别器均使用Adam 优化器,其超参数设置分别设置为0.0025 和0.00001。根据实验以往分析,判别器只用判别真假而生成器需要输出模型。因为判别器易于生成器训练,在本文中设置每训练5轮生成器再训练1 轮生成器。由于数据集提供的是.mat 文件,因此需要将其转成pytorch 张量。转换具体在创建Dataset 时候完成,这样训练时直接从DataLoader 类中读取模型张量即可。
4.2.2 结果分析
训练过程中,选用tensorboard 观察神经网络的稳定性和训练的程度。训练结果如图4 和图5 所示。纵坐标为目标值,横坐标为训练次数。可以明显看到选用原始目标函数的神经网络中的判别网络和生成网络进行着激烈的对抗。借此训练出的网络效果相当不稳定,这也是原始目标函数不好来判别网络训练成果优劣的原因。反观选用了WGAN-GP 为目标函数的神经网络的,虽然在训练的后段也出现了较大的波动,但是在整体比较上训练的稳定性更好。
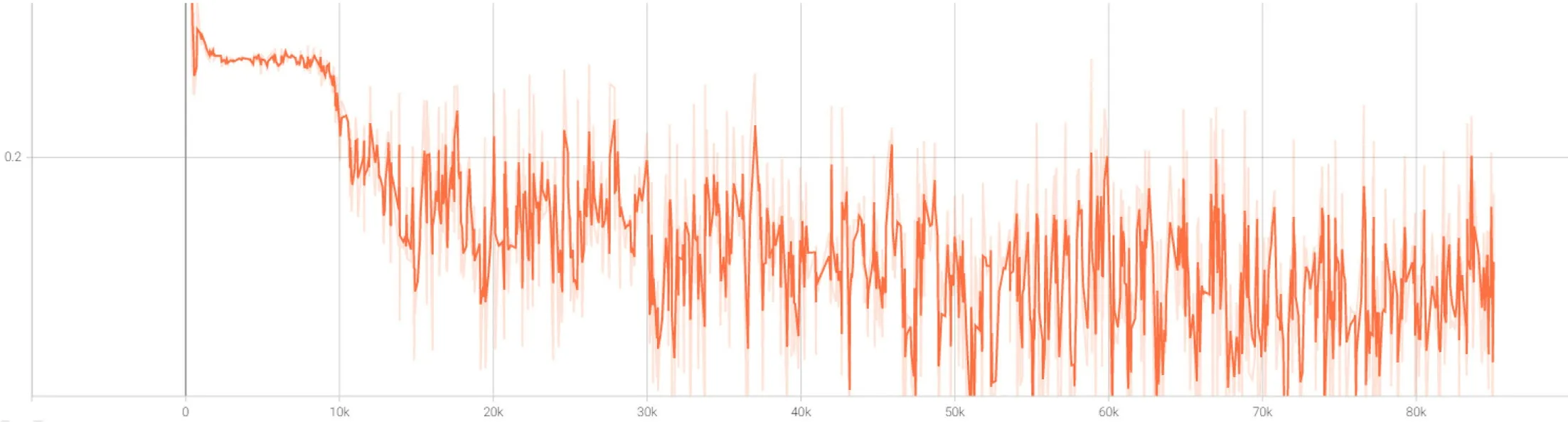
图4: 原始目标函数判别损失(D_loss-Step)

图5: WGAN-GP 目标函数判别损失(D_loss-Step)
在训练成果和训练时间上,选用WGAN-GP 为目标函数的神经网络也要优于选用原始目标函数的神经网络。对比图6、图7 和图8,可以看出选用了选用WGAN-GP 为目标函数的神经网络出来的3d 结构有更多纹理结构和更紧凑的整体性。由表2 表可知,同样是训练30 轮,选用WGANGP 的网络训练时间更短。
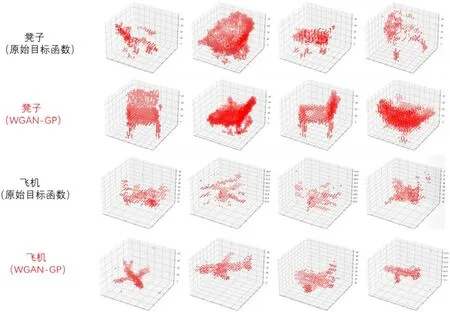
图6: 不同目标函数训练成果比较1

图7: 不同目标函数训练成果比较2
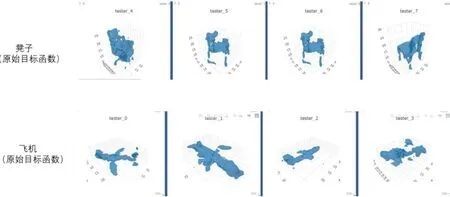
图8: 不同目标函数训练成果比较3

表2: 3D-GAN 训练耗时比较
*训练相同轮数,30 轮。可以看到使用了WGAN-GP 目标函数的3D-GAN 模型效果好,细节更加丰富。上述模型的维度为32*32*32。
*这里采用visdom 显示方法,对比原始目标函数可以更加清楚的看出采用了WAN-GP 目标函数的3D-GAN 模型效果更好。
5 结论
本文研究了快速三维重建生成问题,分析了3D-GAN 网络中的网络结构和其原本目标函数的优缺点。在此基础上,改进了3D-GAN 网络,替换原本目标函数为WGAN-GP 目标函数,从概率空间生成3D 对象。跟之前网络结果做对比,这一改变减少了模型稳定所需的时间并且丰富了3D 模型结果的细节。该算法可以在需要快速生成三维模型的各个领域拓展应用,譬如推广应用至汽车制造、家具生产等行业。
猜你喜欢
数学物理学报(2021年6期)2021-12-21
应用数学(2020年2期)2020-06-24
数学年刊A辑(中文版)(2018年2期)2019-01-08
光学精密工程(2016年6期)2016-11-07
腹腔镜外科杂志(2016年12期)2016-06-01
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
管理现代化(2016年3期)2016-02-06
管理现代化(2016年3期)2016-02-06
智能系统学报(2015年4期)2015-12-27
中国医疗美容(2015年1期)2015-07-12
