
基于人工智能的旅游大数据分析模型创建
2022-07-11 07:46邓伟陈婕
电子技术与软件工程 2022年10期
邓伟 陈婕
(宁德师范学院 福建省宁德市 352100)
进入21 世纪,国民经济飞速发展,人们的物质生活水平得到了进一步提升,旅游业如雨后春笋得到了蓬勃发展,其作为人们休闲放松的重要途径,一方面丰富了人们的生活,另一方面促进了国民经济增长。从旅游业发展现状看,其在旅游人数、旅游效益方面迅猛增长,但由于发展时间短、配套设施不完善,尚缺乏科学的预测机制,旅游经济增收受到了一定的限制。人工智能时代的到来,使得旅游业发展进入一个新的阶段,行业需求呈现出精细化的特征,利用大数据、信息化手段,能够为游客衣食住行提供极大的便利。现有的旅游大数据平台成熟度低,缺乏有效的监管,距离智慧旅游发展还存在一定的距离。构建基于人工智能的旅游大数据分析模型是满足游客个性化旅游需求的有效举措,也是促进智慧旅游发展的必然选择。
1 基于人工智能的旅游大数据分析技术
人工智能时代,旅游业的发展离不开高新技术的支持。在大数据、人工智能等技术支持下,能够实现旅游行业信息与游客行为信息的动态收集,对用户个性化需求予以全面整合与分析,进而设计多元化旅游方案,满足游客的个性需求。旅游数据收集、分析处理涉及到数据整合、处理及深度学习等多个方面,其中关键技术包括大数据与人工技能技术。
1.1 大数据与Hadoop
所谓大数据,主要指的是数据规模超出传统数据管理工具范畴的集合,在数据获取、存储及分析方面均有着更高的要求,包括结构化与非结构化两种数据类型。大数据拥有海量的信息数据,能够为企业目标制定及利益群体运营策略提供可靠的参考,海量的数据经过专业化处理分析,能够获得有价值的信息。数据存储是大数据的基本问题,目前大数据存储常用工具为Hadoop 工具,其隶属于HDFS 分布式文件系统,能够存储成千上百台机器的数据。海量数据的处理是大数据的核心问题,基于该问题引入了mapReduce 框架,通过Shuffle 将Map 与Reduce 进行串联。在Map 支持下,多台机器能够对所需的海量数据文件进行读取,并根据设定的方法对结果进行处理。然后进入Reduce 数据处理环节,严格按照各个步骤,汇总所得到的结果。针对Hive 数据处理慢的问题,引入Spark 框架,其具有较快的处理速度。HDFS 将每次处理结果均保存在计算机硬盘。而Spark则将运行结果放入内存,在其中完成迭代运算,速度优于mapReduce。
1.2 人工智能与Python
人工智能主要是对人思维、意识的研究,并通过数学工具对人的行为进行分析、模拟的过程。机器学习与深度学习是人工智能的关键模块。Python 包含Numpy、Matplotlib、Keras 等多个库,其中应用于数据处理与分析的库包括Matplotlib、Sklearn,同时还能够完成数据建模,总之在Python 中能够找到与机器学习相对应的库,完成数据分析处理。此次研究在旅游大数据分析模型构建中,获取数据不仅来源于企业,而且还可以通过Python 爬虫技术爬取,其中需要运用到Sclenium、Scrapy 及BeautifulSoup 等库。爬取后能够进入机器学习与深度学习阶段。Python 为基础的语言是人工智能领域相关模型的主要语言。
2 基于人工智能的旅游平台模块设计
利用信息技术的不断进步,通过让景区智慧化,把人工智能、传感技术、大数据分析等高科技技术植入到景区,实现趣味、安全、有序的旅游体验,将大幅度提升景区的综合服务能力及服务质量。研究在大数据技术支持下,对旅游平台进行设计,依据旅游产业信息生成、传输及处理特点,可以划分为硬件资源、数据处理、大数据分析等层面,能够提升旅游产业发展的智慧化,满足游客多样化需求。
硬件资源层。主要功能为为旅游大数据平台提供硬件保障,主要包括信息采集功能,建立Hadoop 集群,完成数据分析。
(1)数据处理层。数据处理的关键环节为数据爬取、数据清洗以及数据预处理,利用Python 爬虫技术能够爬取到游客的旅游信息、需求等,并对论坛中相关信息数据进行汇总,通过数据清洗能够实现去粗取精,按照深度学习模型要求,完后数据预处理。
(2)大数据分析层。其是针对获得数据的预处理,在Python 技术支持下,利用Numpy、Matplotlib 库能够帮助挖掘数据的特征,了解其分布情况,并对基础信息实施汇总分析。
(3)人工智能层。针对不同的旅游景点,其构建的大数据模型也呈现出一定的差异性,通过构建测试集与训练集,然后优化模型中对应的参数。
(4)应用服务层。完成深度学习后,需要针对对应的数据,设计动态的应用服务程序,其主要为用户需求及个性化旅游资源推荐提供服务,主要服务对象包括旅行社、景区、酒店等。
3 基于人工智能的旅游大数据分析模型
3.1 数据模型
用户与旅游景点是数据模型的实体部分,分别用U、O表示,旅游景点涉及内涵丰富,包括名胜古迹、特定遗址、博物馆陈列的图片与雕塑等,另外历史建筑也属于旅游景点范畴,将旅游景点与PoI 建立连接,其能够对旅游景点的地理坐标位置予以表示。
假设旅游景点O属于O,用元组进行标注,ai 表示的是本体属性,bi 表示的是元数据。旅游景点的相关数据包括文本资料、图像资料等多媒体数据,均能够与旅游景点建立关联。在用户方面,需要对静态信息、动态信息进行处理,其中前者主要在用户配置文件中保存,后者在用户数据日志中记录。

将上述模型组间为知识数据库,在这个数据库中能够帮助推断特定用户的信息,如可能产生兴趣的景点等。用(V,E)表示知识库,节点集合、边的集合分别用V、E 表示,节点包括旅游景点、标注及用户,边能够对节点的关系予以反映。
3.2 旅游信息挖掘
旅游信息的挖掘主要分为两个步骤完成,第一阶段为频繁项集的生成,在大数据分析技术支持下能够掌握其基本信息及基本属性情况,见表1。

表1: 旅游基本信息与属性
通过对多项旅游平台基本信息的整理,可以获得局部频繁项集,对数据库Q 进行划分,使其成为不具相关性的数据块,并向m 个节点发送,其可以采用如下公式计算:

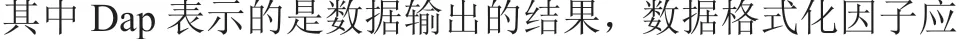
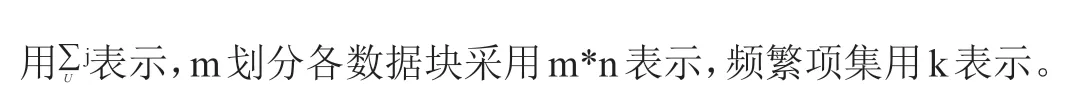
经过上述处理获得候选频繁项集,具有全局特征,然后应用大数据分析技术,掌握分析的目的,在这个过程中需要对旅游信息进行提炼,获得低密度信息价值。

3.3 旅游平台构建
旅游平台的构建是在旅游信息挖掘基础上实现的,其能够对旅游中不确定问题予以有效的解决。在大数据分析技术支持下能够掌握用户的历史浏览记录,了解其评价情况及搜索记录等,进而对旅游信息趋势指数作出相应的预测。该平台能够对景点进行自动化搜索,挖掘其中的隐含特征,并与用户兴趣及景点建立联系,结合游客的喜好,向用户进行景点路线的推荐,其实现流程如图1 所示。

图1: 旅游路线推荐过程流程图



完成旅游信息挖掘后,将获得的结果与路径规划结果相结合,在大数据技术支持下,在数据库中将各类数据存储其中,能够完成对旅游资源的配置,旅游数据能够为决策提供可靠的依据。另外数据库的周期数据需要进行深加工,并实现信息交换。数据库自E-R 实体联系,与数据库模型建立关联,景区旅游平台所涉及的数据表均在数据库中存储,配合相应的字段涉及,其信息输入情况如表2 所示。

表2: 数据库表主要信息分析
在大数据分析技术下,构建一个涵盖旅游指标、时间、游客访问信息等在内的旅游平台,其中涉及到旅游关键数据信息,能够完成数据的抽取、加载与转换,一方面能够为游客个性化旅游服务提供参考,另一方面便于人员信息查询,实现信息数据资源共享。
3.4 推荐策略
旅游景区推荐策略旨在为用户旅游计划提供PoI 参考,其主要包括三个阶段,第一个阶段为数据的预过滤,该阶段用户的信息输入到系统中,能够通过分析获得位置信息,掌握兴趣,为用户旅游景点选择提供更多满意的、感兴趣的方案。第二阶段为排序,该阶段呈现出动态化特征,其针对预过滤阶段筛选的旅游景点进行三个维度权重分配,分别为兴趣、情绪及流行度。第三个阶段为后过滤,该阶段需要掌握用户位置信息,并结合景点的文化吸引力、本体概率时空进行推断。
3.4.1 预过滤阶段
预过滤阶段能够帮助明确用户感兴趣的旅游景点,用子集O O 表示,主要依据的是位置信息、流行度,结合用户兴趣特点等。用户位置可以参照经纬度作出准确的判断,将与用户比较近的景点集合为一个集,即A;对用户数据日志作出全面的分析,获得旅游景点子集B,其中能够看出访问量最大的景点。最后需要借助机器学习技术对对应的旅游景点进行选择,根据配置文件获得子集C。

3.4.2 排序阶段
排序主要是针对预过滤阶段获得的景点信息予以排列,其主要参照以下三个方面:
(1)流行度,景点拍摄频率、次数最高,表明其受欢迎程度越高。
(2)情感。采用情感分析算法获得情感加权总和,对景点进行排序,在具体计算中主要依据的是社会网络获得标题、旅游景点类型等。
(3)兴趣。计算核心内容为用户数据日志,算法为页面排名算法,原理为访问统一项目的用户过多,往往意味着该旅游景点是有趣的。
3.4.3 后过滤阶段
该环节主要目的是过滤掉推荐列表中与游客位置较远的且用户不感兴趣的旅游景点,其主要包括如下两个子阶段:
(1)依据推荐集实施排序,对加权总和进行排序,获得一个完整、有序的列表。
(2)依据旅游景点位置与用户需求排序,对比的是被检查的旅游景点与其之后的景点,列表还显示了旅游景点距离。
若在给定阈值下,第一距离较第二距离小,表示为经过更新的列表。另外研究引入本体论方法,以满足用户需求。假设游客在中午顺文化路线前进,那么在该算法下会向用户推荐距离最近的餐厅,同时还使得文化景点本体得到了丰富。
4 旅游大数据分析模型结构与实现
研究构建了大数据技术下的多层体系结构,并从数据获取、知识库及数据处理层面对推荐策略进行区分。数据层包括源子层、数据存储子层两个部分,前者主要功能为获取异构数据源的数据,能够从多个视角为游客提供景点信息。该计算过程中,需要对用户访问情况及具体操作信息进行收集,并作为用户的数据日志,其实了解用户喜好的主要依据。在浏览CH 固有本体是采用RESP 法,与给定文化项目相连接。数据存储子层在存储数据时主要依据的是数据的类型与源,NoSQL 列式数据库主要用于文化项目、地理定位信息及用户数据日志信息的存储,其能够对海量数据信息进行处理。NoSQL 文档数据库主要用于对用户照片、评分及心情等数据的存储,其主要来源于社交网络,是一个动态的信息知识库。
作为一个事物数据库,KB 层数据库具有一致性、持久性及隔离性等特征,其应用Ne04j 数据库,在Java 作用下,对原生图形的存储、处理进行编写。数据处理层则能够对CH 应用程序予以支持,其主要技术支持为数据挖掘技术、大数据分析技术,利用Spark 框架能够对数据库中相关数据查询,与数据挖掘本体数据结合处理。应用程序层主要利用的是API 开发的应用程度,其主要功能为数据档案查询、数据分析任务的执行等。
另外API 程序还能够针对游客所在的地理位置、环境等,分析游客偏好,并推荐文化项目列表。经过过滤模块处理后,能够在对应设备尤其是具有边缘计算功能设备上的正常运行。
5 实验评估与测试
为验证旅游大数据分析模型的可靠性与应用价值,研究选择某旅游机构80 名游客作为研究对象,利用随机数字表法分为观察组与对照组,首先在试验前调查了游客的旅游需求情况,结果显示其对信息查询、天气、线路、酒店及预定信息、景点信息等需求均为1,提示两组研究对象对享受服务的需求基本一致。然后采用基于人工智能的旅游大数据分析模型了解观察组旅游信息,采用传统旅游平台了解对照组的景点信息,评估两组游客对景点信息的了解程度,结果如表3 所示,可以发现观察组对信息查询、天气信息、线路信息等了解程度均显著高于对照组,差异有统计学意义(P<0.05)。这是因为在大数据分析技术支持下,旅游平台能够对游客的历史信息进行收集与分析,结合用户的喜好提供个性化服务,为游客提供丰富多样的信息。经上述试验证实,该研究设计的旅游大数据分析模型涵盖信息量丰富,游客需求可以得到满足,应用推广价值高。

表3: 观察组与对照组对旅游信息了解程度比较
6 结束语
综上所述,在人工智能技术支持下,构建旅游大数据分析模型,引入机器学习技术推荐算法,能够了解游客需求,推荐个性化旅游景点相关信息,提供智能、便捷、有效的服务,满足用户个性化需求。实验证实该方法性能高,可为游客提供丰富信息,为将该模型推广到真实的应用场景中,提高旅游服务的智能化、精细化。
猜你喜欢
商界(2019年12期)2019-01-03
IT经理世界(2018年20期)2018-10-24
意林·全彩Color(2018年7期)2018-08-13
小康(2017年16期)2017-06-07
海外星云(2016年7期)2016-12-01
Coco薇(2015年11期)2015-11-09
首都外语论坛(2014年1期)2014-03-20
