
基于Tesseract-OCR 文本识别的检票系统研究
2022-07-10 13:45聂霜霜杨轶男卫晶马建钟
现代信息科技 2022年5期
关键词:图像处理
聂霜霜 杨轶男 卫晶 马建钟




摘 要:通过对已有手写字符识别相关技术和应用实例进行研究,发现Tesseract文本识别方法具有经济、可训练、识别准确等优点,设计了基于Tesseract文本识别的特殊手写字符检票系统。此系统结合数字图像处理技术,以谷歌开源OCR引擎Tesseract的字符識别技术为核心,并通过训练字库实现对多种选民手写选票的准确识别。测试结果表明,该系统具有实时性、交互性、高可靠性等特点,为纸质选票的传统人工唱票计票方式提供了智能解决方案。
关键词:手写字符识别;选票识别系统;图像处理;Tesseract-OCR
中图分类号:TP391.1 文献标识码:A文章编号:2096-4706(2022)05-0001-05
Research on Ticket Checking System Based on Tesseract-OCR Text Recognition
NIE Shuangshuang, YANG Yinan, WEI Jing, MA Jianzhong
(School of Information Technology and Engineering Tianjin University of Technology and Education, Tianjin 300222, China)
Abstract: According to the research of related technologies and application examples of existing handwritten character recognition, it is found that Tesseract text recognition method has the advantages of economy, trainable and accurate recognition and so on, and a special handwritten character ticket checking system based on Tesseract text recognition is designed. This system combines digital image processing technology, with the character recognition technology of Google open source OCR engine Tesseract as the core, and realizes the accurate recognition of multiple voters’ handwritten ballots through the training word library. The testing results show that the system has the characteristics of real-time, interaction and high reliability and so on, which provides an intelligent solution for the traditional manual vote counting method of paper ballots.
Keywords: handwritten character recognition; ballot recognition system; image processing; Tesseract-OCR
0 引 言
在信息技术高速发展的今天,传统计票方式已经不能满足社会的普遍需求。面对大型选举中产生的数量庞大的手写选票,传统计票方式已无法准确并且快速地得出选举结果。为解决人工唱票统计方式中存在的诸多问题,多种基于图像识别技术的选票统计方法陆续被提出。此类方法基于计算机自动识别方式统计选票内容,大大提高了选票统计的速度,在一定程度上弥补了传统计票方式存在的缺陷,同时避免了人工唱票时因人为因素导致的不公平问题。然而,基于图像识别技术的选票统计方法在已有技术基础上很难快速适应人们的常规选举习惯,传统选票通常采用手写字符“√,×,○”进行选举,但现有的计算机识别字库中基本无法对手写字符“√,×,○”进行比较准确的识别,所以仍需要进行深入研究以获得适合现实选举场景的自动识别系统[1]。
Tesseract是目前最完备的开源OCR引擎,不仅具备极高的精确度,同时也具有很高的灵活性,可以读取多种格式的图像,并可以将它们转化成多种语言的文本,而且支持使用者不断训练字库来识别出任何需要的字体[2]。目前该技术已被应用于文档扫描、票据识别、古汉语识别等多种场景,并且得到了很好的反响[3]。
根据前期调查结果,针对某些需要手写式投票的场合,初步确立了手写特殊字符“√,×,○”检票识别系统的设计方案:首先使用高拍仪快速获取选票图片,并结合图像处理技术和Tesseract的字符识别技术对手写特殊字符“√,×,○”进行快速准确识别,最后将识别结果进行统计并以表格形式进行可视化,有效地提高对手写特殊字符“√,×,○”识别的效率,解决传统选票识别方法存在的效率低,容易出错等问题。
1 整体框架
1.1 技术路线
本系统运用高拍仪进行选票图像获取,同时以Tesseract的字符识别技术为核心,结合图像处理、字符区域检测、字库训练等技术,实现对特殊手写字符“√,×,○”进行准确识别和快速统计功能。
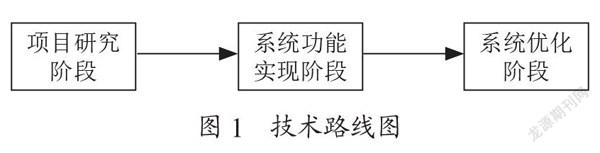
实施阶段主要分为系统功能实现和系统优化两大部分,其中系统功能实现阶段分为:图像获取、图像预处理、字库训练、字符识别、显示统计结果。图像预处理实现字符位置的确定,字符识别实现对特定字符进行识别,字库训练实现生成系统特有的字库,显示统计结果实现对识别结果进行统计并显示在界面上。系统优化阶段包括优化算法,加大字库样本训练。研究技术路线如图1所示。
图1 技术路线图
1.2 系统功能实现
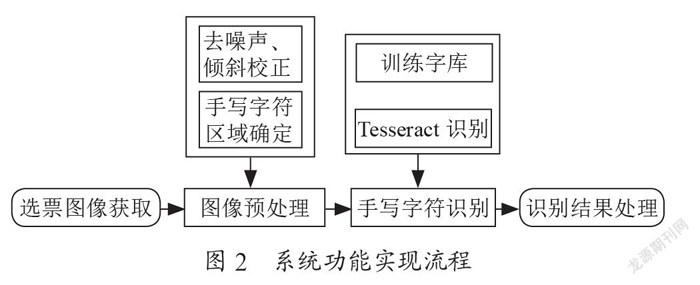
实现系统功能阶段的实施方案主要分为四个部分:(1)选票图像获取。(2)图片预处理,即通过运用数字图像处理技术确定要识别的字符区域。(3)选票字符识别,用jTessBoxEditor对手写字符“√,×,○”进行样本训练,得到本系统专用字库,运用Tesseract对字符进行识别。(4)识别结果处理,统计识别结果并显示。系统功能实现流程如图2所示。
图2 系统功能实现流程
1.3 系统优化
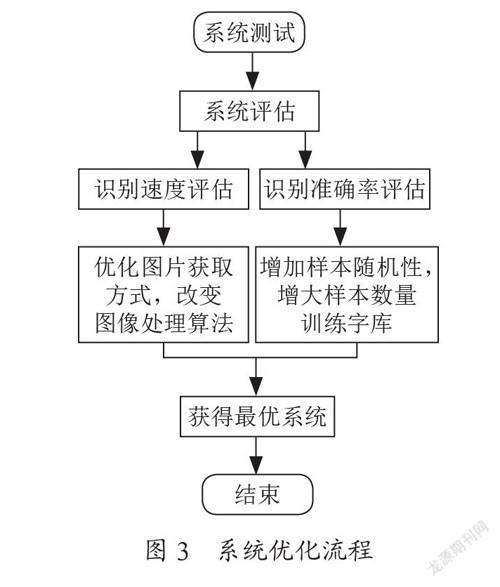
在实现系统功能后,对系统的识别准确率和识别速率等进行多方面测试,根据测试结果对系统进行优化。具体优化内容包括:识别速度优化、识别准确率优化。其中识别速度主要与系统采用的图像处理算法、图片获取方式等因素有关,可以通变改进图像处理算法、改进选票图像获取方式进行系统识别速度优化。识别准确率与图像处理效果、字库质量等有关,可以通过加大字库训练样本数量、增加样本随机性来优化识别准确率。优化流程图如图3所示。
图3 系统优化流程
2 系统软件设计
2.1 系统实现流程
本系统基于OCR引擎Tesseract的字符识别技术,对手写符号“√,×,○”进行自动识别及选票数目统计工作,实现基于视觉检测方法的手写选票特殊字符自动识别统计。系统实现具体流程如图4所示。
图4 系统功能实现流程
首先,用高拍仪获取选票图片,对获取的图片进行图像形态学操作、倾斜矫正、获取字符区域等操作。确定要识别字符的区域,利用jTessBoxEditor对特定字符“√,×,○”进行针对性的训练来获得系统的专门字库。接着基于字库,采用Tesseract进行手写字符“√,×,○”识别,通过定义每张选票图片的左顶角为原点、并以水平向右为X轴正向、竖直向下为Y轴正向,建立一套标准坐标系。计算图片中原点与各文字区域框的距离远近,用sorted函数实现按升序排列。调用Tesseract对按此顺序排列的一系列文本框进行识别,将识别数据按sorted升序排列写入字典中,通过循环检票输出识别结果,并写入result.txt文本文档,最终将识别结果显示在界面上。
2.2 实现步骤及原理
2.2.1 字符区域检测——处理选票图像对选民意向字符区域进行提取
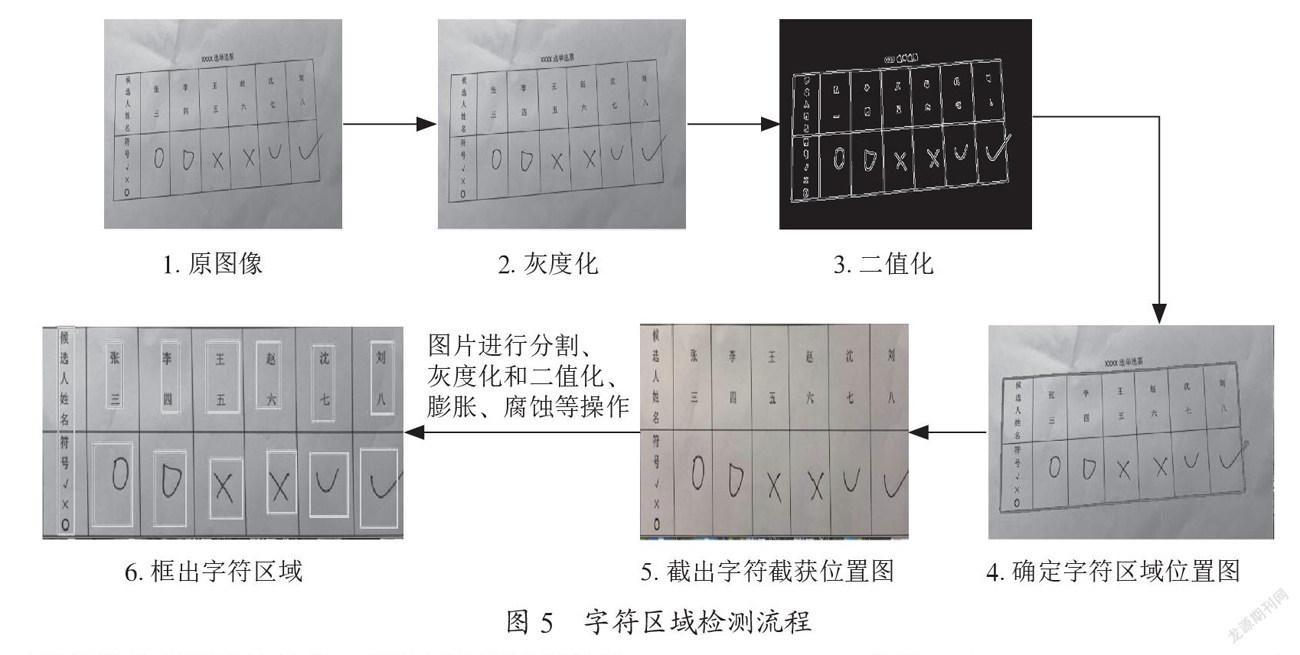
使用数字图像处理技术,对用高拍仪获取的选票图像进行灰度化、二值化等处理,利用高斯滤波对选票图像进行平滑、过滤、降噪处理,检测出特殊手写字符“√,×,○”所在区域的轮廓,提取轮廓,利用透视变换对选票图像进行分割处理进而去除不符合文字特点的边框[4]。处理流程如图5所示。
(1)对要处理的选票图像进行灰度化处理。对获取的选票图像的灰度化处理作为图像处理的预处理步骤,为图像分割、图像识别和图像分析等操作做准备,灰度化处理将彩色图像转化为灰度图像,根据每一张图像是由像素点矩阵构成对图像的处理,所以就可以看作是对像素点矩阵进行处理,而一个像素点的颜色由蓝、绿、红三个变量表示,通过对这三个变量的赋值来改变这个像素点的颜色,因此将BGR格式转换成灰度图片来实现选票图像灰度化处理效果[5]。
(2)将灰度化的选票图像进行二值化处理。接着对扫描得到的图像进行二值化处理,而二值化处理对颜色、灰度等信息作处理,还可以用来去掉不必要的信息,来提高图片的质量进而提高识别速度,并为手写符号特征提取打下基础。在这里通过将图像的像素点矩阵中的每个像素点的灰度值变为为0或者255让整个图像凸显出黑白效果,有利于对图像的进一步处理,使处理变得简单[6]。
图5 字符区域检测流程
(3)对图像进行高斯滤波处理。高斯滤波用于图像处理的降噪过程,用来去除高斯噪声,高斯滤波将整幅选票图像的每一个像素点本身的值和邻域内的其他像素值经过加权平均后得到每个像素点的新值,用一个卷积、掩模板确定的邻域内像素的加权平均灰度值来替代模板中心像素点的值[7]。
(4)对图像进行腐蚀膨胀处理。膨胀对选票图像求局部最大值的处理是对图像中的高亮部分进行扩张,让白色区域变多。腐蚀是选票图像中的高亮部分被蚕食,让黑色区域变多。在这里通过一次膨胀让轮廓突出,通过一次腐蚀去掉细节再通过一次膨胀使特殊手写字符区域的轮廓突出,并去除掉一些边框线条,而后通过查找轮廓的方法就可以计算出字符区域的位置[8]。
2.2.2 字符识别——Tesseract-OCR对选民意向字符进行识别
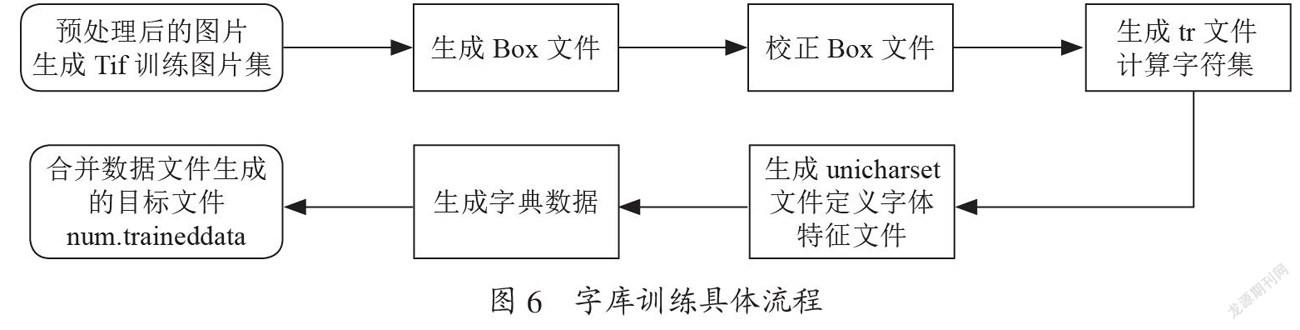
通过训练特殊手写字符“√,×,○”的专用字库提高识别准确率,jTessBoxEditor对选票中的特殊手写字符“√,×,○”进行训练,形成专门的字库,可以大大提高对图片文字的识别准确率[9]。同时,结合谷歌开源OCR引擎Tesseract实现对特殊手写字符“√,×,○”的准确识别,首先计算图片中原点与各文字区域框的距离远近,用sorted函数实现按升序排列。再调用Tesseract对按此顺序排列的一系列文本框进行识别,将识别数据按sorted升序排列写入字典中,最终通过循环检票输出识别结果并写入result.txt文本文档[10]。特殊手写字符“√,×,○”字库训练具体流程如图6所示。
图6 字库训练具体流程
2.2.3 将识别结果放入指定文档并进行分类展示在界面中
纸质选票图像的几何结构区优先识别问题可归类于选票表格几何结构优先识别问题,因此,可通過分析特定选票图像中的表格设计结构来解决选票图像几何结构区优先识别的难题[11]。
文字区域检测(图片预处理:灰度化、二值化等系列处理)后,通过定义所拍摄每张选票图片的左顶角为原点,并以选票水平向右为X轴正向,竖直向下为Y轴正向,建立一套标准坐标系。计算图片中原点与各文字区域框的距离远近,用sorted函数实现按升序排列。具体实现方法思想为,计算图片原点与各文本框的距离。如将左下角坐标(x1,y1)作为统一参考点,具体算法为,首先在所有框里选出y值越大的优先排序(y降序),再在这些框里按x值越小的优先排序(x升序),从而经由双重排序算法求出各框与图中原点距离的远近。文本识别Tesseract识别按此顺序排列的一系列文本框后,将识别数据按sorted升序排列写入字典中。最终可以通过循环检票输出最终识别结果写入result.txt文本文档,并进行分类展示在界面中。确定识别顺序具体操作如图7所示。
系统优化——系统功能基本已经实现,经过测试,选票识别速率和识别准确性还未能达到目的。我们通过优化图像处理算法,采用合适的滤波器最大程度还原图像质量,保护图像的细节信息。同时,我们加大了样本图片的训练,我们结合系统需要,打印出1 000份相同的空选票作为数据集的载体,随机寻找不同年龄段的群众,进行选票的随机填写,获得了1 000张数据集,并对样本图片进行训练,获得了识别手写字符“√,×,○”的专用字库,最终系统对手写字符“√,×,○”的识别速度和识别精度得到了大大的提高,在之前系统基础上完善了选举模型的信息流程部分[12]。通过对比测试结果可以看出本系统已基本可以满足需求。系统优化前后识别结果对比如图8所示。
图7 确定识别顺序具体操作
图8 系统优化前后识别结果对比
3 硬件设计
本系统使用高拍仪快速获取尺寸一致的样本图片。高拍仪具有操作简单、拍摄速度快、省电、拍摄清晰、可设定获取图片格式等优点,可以很好地满足检票系统获取样本图片高质量、低成本、快速、图片格式固定等需求。通过使用高拍仪获取选票图片的设计大大缩短了选票样本图片获取时间,提高了获取选票样本图片的质量,使系统对手写字符“√,×,○”的识别效率得到了很大的提高。高拍仪获取样本图片过程如图9所示。
图9 获取样本图片
4 检票识别结果显示与系统调试
显示界面运用GUI设计工具,通过Python语言交互式编程环境来设计和实现,在整体项目实施中充分考虑了代码的可移植性、可维护性及可复用性[13]。
运行系统,以6位候选人数据采集为例,其数据采集终端界面如图10所示。
上传批量选票后,点击“开始识别选票”按钮,统计结果通过“选票识别结果统计”窗口在用户界面呈现,选票统计结果显示界面如图11所示。测试结果表明,该系统最终实现了对手写纸质选票快速精准的自动识别及计票统计工作。
图10 数据采集终端界面
图11 选票统计结果显示界面
在测试过程中,系统对样本图片的预处理过程存在拒识、字符定位不准等问题,通过改进图像获取方式,优化图像处理算法,采用合适的滤波器来最大程度还原图像质量,保护图像的细节信息,提高图像预处理效率。在字符识别过程中,字符识别准确率低,通过提高样本随机性,加大样本训练数量来积累字库,从而提高字符识别准确率。另外,在识别结果的显示界面上,存在信息展示不够清晰等问题,通过重新设计界面模块,提高结果显示清晰度。经过系统优化,使系统可以更好地应用于实际生活中的各种检票场景。
5 结 论
以“纸质选票—智能计票”为主线,对大量不同情况下的选票完成监督学习训练,为紙质选票的传统人工唱票计票方式提供智能化解决方案。系统基于谷歌开源OCR引擎Tesseract的字符识别技术,针对某些需要手写式投票的场合,设计并实现基于视觉检测方法的选票自动识别统计系统,对手写符号“√,×,○”进行自动识别及选票数目统计工作。系统结构简单,使用方便,可视性强,在实际应用中可以减轻选票统计时的工作量,同时增加选举的可靠性,可以在多数需要手写投票的活动上进行推广。
参考文献:
[1] 彭程,韩啸,等.深度卷积神经网络下选票系统智能化识别研究与实现 [J].计算机应用,2019,39(S2):85-90.
[2] 曾悦,马明栋.基于Tesseract_OCR文字识别的研究 [J].计算机技术与发展,2021,31(11):76-80.
[3] 王君,柳清瑞,藤淑娟,等.基于表格的手写体字符识别技术研究 [J].小型微型计算机系统,2002(7):890-893.
[4] 李俊山,李旭辉,朱子江.数字图像处理:第3版 [M].北京:清华大学出版社,2017.
[5] 章毓晋.图像处理和分析 [M].北京:清华大学出版社,1999.
[6] 李红俊,韩冀皖.数字图像处理技术及其应用 [J].计算机自动测量与控制,2002(9):620-622.
[7] 周作梅,宋兰霞.频域滤波器在数字图像处理中的应用研究 [J].信息与电脑(理论版),2021,33(15):198-200.
[8] 邹宏伟.基于OpenCV的数字图像处理技术研究与实现 [J].无线互联科技,2019,16(22):118-119.
[9] 潘浩,李兰.基于Tesseract引擎样本训练的验证码识别 [J].信息与电脑(理论版),2020,32(1):138-139+142.
[10] 张中良.基于机器视觉的图像目标识别方法综述 [J].科技与创新,2016(14):32-33.
[11] 张站.基于符号识别技术的选举计票系统研究 [D].合肥:安徽大学,2012.
[12] 谢金宝,刘晖波.电子选举系统的基本框架与信息流程 [J].计算机工程,2000(S1):97-102.
[13] 康计良.Python语言的可视化编程环境的设计与实现 [D].西安:西安电子科技大学,2013.
作者简介:聂霜霜(2000—),女,汉族,湖北襄阳人,本科在读,研究方向:字符识别技术、图像处理技术;杨轶男(2002—),女,汉族,山西运城人,本科在读,研究方向:字符识别技术、图像处理技术;卫晶(2000—),女,汉族,山西临汾人,本科在读,研究方向:字符识别技术、图像处理技术;马建钟(2002—),男,汉族,福建龙岩人,本科在读,研究方向:字符识别技术、图像处理技术。
猜你喜欢
农业工程学报(2022年11期)2022-08-22
农业工程学报(2022年7期)2022-07-09
电脑知识与技术(2022年9期)2022-05-10
电脑知识与技术(2022年9期)2022-05-10
计算技术与自动化(2022年1期)2022-04-15
教育教学论坛(2018年5期)2018-01-22
科技视界(2016年26期)2016-12-17
新教育时代·教师版(2016年26期)2016-12-06
企业导报(2016年10期)2016-06-04
