
基于数据挖掘的学生体质健康测试平台设计及应用研究
2022-07-08 09:21张雪琴江帆席本玉
电子设计工程 2022年13期
张雪琴,江帆,席本玉
(西安交通大学城市学院,陕西西安 710018)
近些年来,国内在校大学生身体素质不断下降,大学生的身体健康问题频发。根据2020 年大学生身体素质调查结果可知,相较于2010年,大学生的身体素质持续下降,其中肺活量指标下降了近10%,大学生体质健康问题受到多方关注[1-2]。现阶段我国的大学生体质数据处于无序状态,难以从中发掘相关数据的变化规律[3]。随着数据挖掘技术的兴起,利用数据挖掘工具对大学生体质数据进行挖掘处理,对学生体质健康进行测试成为一个新的发展方向[4-5]。国内基于数据挖掘原理对现有体质数据进行了多方探索[6-8]。如采用Clementine12.0 数据挖掘软件挖掘高校学生体质各项指标的关联规则,确定体质中影响各项指标的因素[9];应用SQL Server 数据挖掘服务发现大学生体质数据中存在的验证性规则[10];采用支持向量机法进行学生身体评价指标的数据挖掘,并给出身体状况评价结果,指导大学运动课程的科学制定等[11-12]。由于我国学生体质测试数据量庞大,而数据挖掘工具软件的应用较少,尤其缺乏有效的数据挖掘算法。基于此,文中拟对大学生体质测试数据进行特征分析,并在传统C4.5 决策树算法的基础上,提出一种改进的决策树分类算法,有效降低数据计算量,提升预测准确度,并将改进算法嵌入大学生体质数据监测系统,从多维角度实现对学生身心状况的测试和评价。
1 基于决策树的数据挖掘
1.1 C4.5 决策树算法
数据挖掘是从大量、不完整、模糊的数据中提取隐含、未知、可靠信息和知识的过程,具有数据量大、离散变量、动态规则相关性的特点[13]。决策树是以分类为目的的学习算法,是数据与对象值间的映射关系,决策树顶部作为根节点,所有数据集作为起点,根据属性来区分不同的分支节点,通过分类最终生成叶节点,由预测规则建立决策树自上导下的路径,获得净现值大于或等于零的概率来进行可行性判断。目前应用较为普遍的决策树算法包括ID3、C4.5、CART 算法等[14-15]。
C4.5 决策树分类算法在ID3 算法的基础上进行了改良,算法通过信息增益比率量化属性判别能力。设S表示以 |S|个数据样本为依据的集合,定义n个不同的类Ci(i=1,2,…,n),假定类Ci中样本个数为 |Ci|,则样本分类的期望信息为:

式中,Pi=是任一样本属于第i类的概率。若属性A中具有m个不同值{x1,x2,…,xm},则将属 性A和S划分为m个子集{S1,S2,…,Sm},其 中Sj中样本在A中具有相同值xj(j=1,2,…,m)。假定子集Sj中属于第i类样本的有 |Sij|个,将A划分为子集的信息期望为:

分支获得的信息增益为:

由式(3)可看出,信息期望越小,则信息增益越大。
1.2 改进的C4.5算法
C4.5 决策树算法针对不同属性的数据采用不同方式,对于连续属性的数据,首先需要进行离散化处理,进行数据段排序后,对不同片段数据进行处理,这样会生成大量的多叉树,导致效率下降[16],且不能有效地处理训练集体积超过主存容量的情况。因此,对C4.5 决策树算法数据进行进一步优化、精简处理。
设数据集D中包括两种属性:大小分别为y和n的正例集PD和反例集ND,决策树判定数据集的首要条件是掌握一定的信息量,设掌握的信息量为:

令决策树根节点属性为X,X=(X1,X2,…,Xs),由X将数据集D分为S个子集X=(D1,D2,…,DS),各子数据集属性为X,并含有正比例集PD和反比例集ND,则数据子集的期望信息为:

由式(4)和式(5)可知,数据集D根节点属性X的信息熵为:

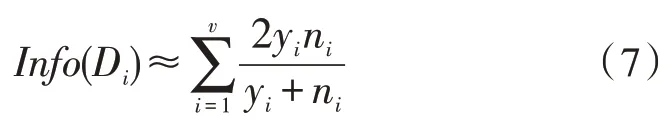
分裂信息度量为:

确定信息增益率为:

设训练集S中包括c种属性,根据排序方式使分裂的连续属性A具有n+l个不同数据段,具有n个数据划分点,改进的算法仅需要计算最优点的信息增益率,即计算c-l个划分点。
2 基于C4.5 算法的体测系统设计和实现
2.1 系统结构
选取西北5 所高校在校大学生体质健康数据进行挖掘分析。相较于传统数据分析,C4.5 算法进行数据挖掘的过程是一种自动发现知识的过程,通过数据预处理,采用决策树算法挖掘并分析观测数据。学生体质健康挖掘主要是解决大数据下各用户群体的体测参数,获取具有价值的数据依据。图1为数据挖掘流程。

图1 学生体测数据挖掘流程
在系统中,采集的数据包括静态数据和动态数据。静态数据主要是各高校公布的学生基本信息,动态数据则是历年学生体测数据。系统管理人员采用Excel 文件,将上报的数据导入MySQL 数据库中,包括学生的来源信息、体测成绩、锻炼项目等,其中学号、姓名、年龄构成学生来源信息,而身高体重、肺活量、耐力等级、速度灵敏度则构成体质健康测试成绩。表1 给出了部分学生体测数据信息。

表1 学生体测项目信息
2.2 数据预处理
后台数据库通过MySQL 数据库进行数据存储,并直接调用MySQL 数据库中的Nevicat 对MySQL 工具进行操作,以表格的形式存储数据,考虑到MySQL数据库的容量,根据具体的存储需求设置相应的数据存储周期。
由于初始采集的数据中存在大量不完整、含噪声的数据,因此,根据系统数据挖掘引擎进行数据预处理[17]。首先将各类测试项目信息、评价标准、学生信息等集成转化为概括性数据,对数据进行属性分类。在数据清理中主要对各类导入系统中的学生体测成绩进行处理。以体测总成绩为例,将具体的成绩划分为“差”、“良”、“优”等类型,将学生所在学校表示为i1、i2、i3,将身高、速度灵敏度、肺活量等标识为i4、i5、i6,项目依次类推;判断类型“是”、“否”分别表示为“1”和“0”,根据不同的类别定义进行数据处理,并在数据处理前删除存在的重复数据。
2.3 决策树算法的设计
对在MySQL 数据库中保存的各类型参数,采用改进的C4.5 决策树算法进行数据挖掘和信息关联。算法原理如图2所示,首先,求取预处理数据集中连续属性的最佳分割点,并计算各属性信息增益速率[18],选择信息增益速率最大属性来定义该决策节点的属性类型。通过递归算法求取节点属性可能值对应的样本子集的信息增益率,直到各子集中的数据属于同一类型,生成决策树。根据定义类型对生成的决策树进行修剪操作,获得最优决策树,在最优决策树中提取分类规则,并进行数据的重新分类。
图2 算法原理图
2.4 算法测试和结果分析
文中采用C++编程语言实现算法的编程,将初始采集的大学生体测原始数据导入系统进行处理,获得的最优决策树如图3 所示。从决策树中可以看出,影响大学生身体健康的最大因素为肺活量测试项目,对于肺活量测试失败的个体,其中身高和体重成为造成肺活量测试失败的最大影响因素。肺活量通常反映着人体的身体状况,对于积极锻炼的学生,肺活量相对表现更好,通过平时的锻炼,这部分学生能够在肺活量测试中获得更好的成绩,而肺活量测试不达标的学生,身高、体重指标也不达标,在这群个体中普遍存在着肥胖的现象,需要在日常中更注重体育锻炼。

图3 学生体测最优决策树
3 结论
采用改进的C4.5 决策树算法进行数据挖掘,建立决策树来分析影响学生体测指标的因素,跟踪大学生身心健康状况,并有针对性地增强学生锻炼积极性。研究获得的主要结论有:
1)采用改进的信息熵,利用简化函数关系来计算分裂信息度量,在保证预测结果精度的前提下,优化信息增益率计算,通过去除连续属性数据中非必要划分点的信息增益率计算,来提高算法的运行效率。
2)建立MySQL 数据库的在校大学生体测数据参数,引入改进的C4.5 决策树算法进行数据挖掘,并对西北某5 所高校进行实例验证,结果表明,肺活量测试项目是影响大学生身体健康最大因素,其中身高和体重成为造成肺活量测试失败的最大影响因素。
猜你喜欢
九江学院学报(自然科学版)(2022年2期)2022-07-02
世界科学技术-中医药现代化(2021年8期)2021-12-21
大众投资指南(2021年35期)2021-02-16
中国交通信息化(2020年1期)2020-07-27
科学咨询(2020年42期)2020-01-08
电子制作(2018年16期)2018-09-26
运动精品(2017年12期)2017-05-10
电子技术与软件工程(2016年24期)2017-02-23
电子制作(2017年24期)2017-02-02
武术研究(2014年9期)2014-10-27
