
基于卷积网络的老年黄斑变性识别方法
2022-07-08 03:35王剑
电子技术与软件工程 2022年8期
王剑
(山西医科大学汾阳学院 山西省汾阳市 032200)
1 引言
老年黄斑变性(AMD)一种与年龄相关的眼部疾病。AMD 因其早期现象不明显、且不可逆性,成为了老年人(>50岁)中视力丧失的主要原因。目前世界人口的老龄化结构越来越明显,尤其以中国为主的发展中人口大国老龄化现象十分严峻,据有关报道研究,到2050 年,全球AMD 的患者数量将突破20 亿人。AMD 是由于黄斑退化导致视力下降的慢性疾病,通常,AMD 可以分为四个阶段,分别为无、早期、中间和晚期。当眼底出现少量的小玻璃疣时,此时不会对视力造成太大的影响,不会对AMD 进行分级,如果存在中小型玻璃疣,则对早期的AMD 进行分级。黄斑变性可以分为两大类型,一类是干性,另一类是湿性。干性黄斑变性的特点是当黄斑处的视网膜色素上皮细胞丢失时,眼底出现玻璃疣沉积,表现为瘢痕形式,最终可能造成不可逆转的视力丧失;湿性黄斑变性的主要特点是突发性,发展较快,其主要的原因是眼底出现了异常的新生血管,极易造成黄斑区出血,导致视力极速下降。一般来说,早期的AMD 是没有任何症状的,针对一些视力模糊,可能已经发展到了中期,而对于晚期的AMD 来说,通过眼底图像是极易分辨出来的,但是已经造成了视力的不可逆转。因此,AMD的早期的诊断,对于AMD 的进一步恶化具有重要的意义。眼底图像是诊断AMD 的主要手段,然而,眼底图像的诊断需要有医生的主观意见,并且由于医生个体间的差异,极易造成诊断的差异。因此,利用计算机进行自动化的黄斑变性诊断,可以为医生提供可靠的辅助诊断依据,不仅能为患者提供高效的医疗服务,而且能平衡各地的医疗资源,具有及其重要的现实意义。
针对以上问题,本文提出了一个十二层的深度卷积网络,通过患者的眼底图像来自动诊断AMD。与传统的自动诊断系统相比,基于卷积网络的诊断方法不需要手工提取特征,利用卷积的特性,可以自动的提取眼底图像的低级特征与高级语义特征。
深度卷积网络是近年来发展起来的一项人工智能技术,并且成为了医学图像分析领域的主要方法之一,文献提出了一种基于深度学习的自动筛选系统,将眼底图像分类为正常或萎缩性AMD。文献提出了基于残差网络的筛选系统,设计了一个基于残差结构的50 层网络,利用交叉熵损失函数和Adma 优化器进行训练。训练使用由400 张图像组成的私有数据集进行,其中验证集40 张,测试集200张,模型使用了ImageNet 数据库上的预训练权重,最终的准确率达到了0.98,灵敏度为0.95,特异性为1。文献,提出了一种自动筛查方法,可以在早期阶段从眼底图像中检测 AMD。该方法基于多实例学习框架。首先,检测中央凹以裁剪黄斑区域。 然后,进行迭代训练,直到到达设定的准确度,或者精度不在变化,或者超过训练时间阈值即停止训练。作者使用三种不同的模型(VGG16、ResNet-50 和Inception v3)评估了相同的方法,最终选择了性能较好的VGG16 模型。
2 数据收集
本文所使用的数据集来自MESSIDOR 公开数据集,以及Kaggle 平台Segmentation of OCT images(AMD)比赛数据集。该数据集是目前为止国外最大的眼底图像数据库,共有1200 张眼底图像,其中540 张正常图像,660 张异常图像,主要标记由糖尿病引发的视网膜疾病与黄斑水肿。Kaggle 平台提供的AMD 分割数据集中,AMD 眼底图像总共269 张。本文选取MESSIDOR 数据集中的540 张正常图像作为正样本,选取Kaggle 平台中的269 张AMD 图像作为负样本。
2.1 感兴趣区域提取
MESSIDOR 中的图像如图1 所示。眼底图像由两部分组成,眼底图和黑色背景,其中的背景信息是分类所不需要的,并且会影响网络的分类性能,因此,需要在进行分类之前对图片进行预处理操作,即提取图片的感兴趣区域(Region of Interest, ROI)
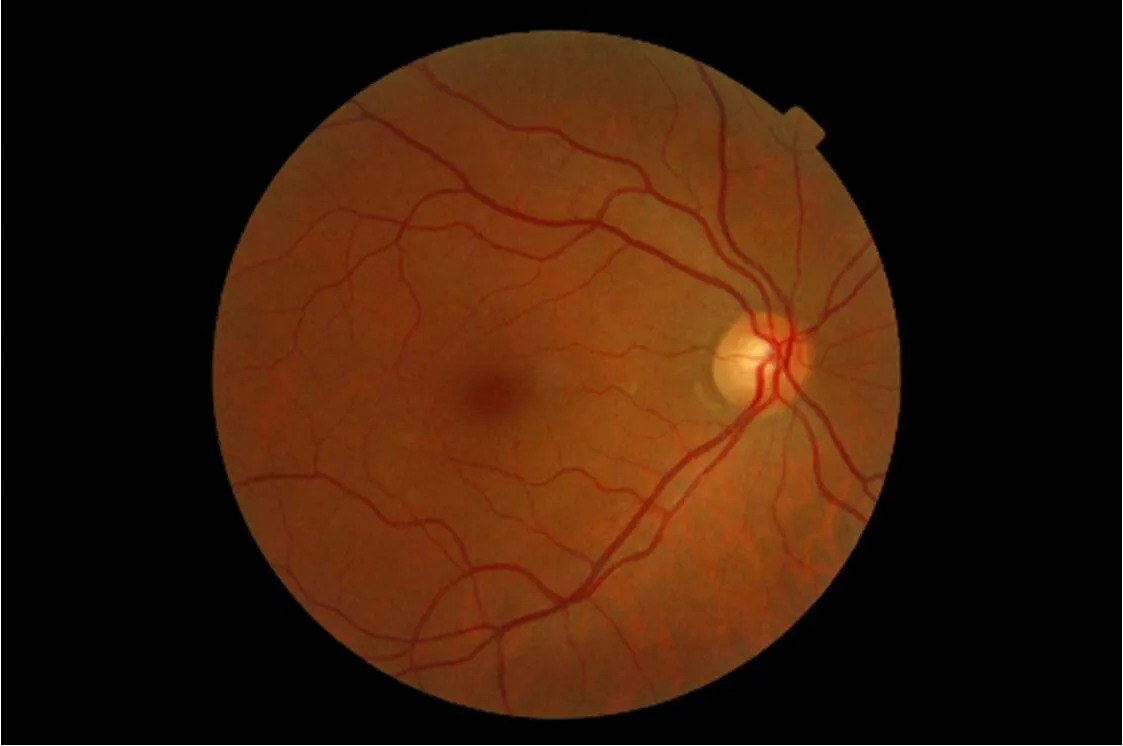
图1: MESSIDOR 中的正常眼底图像
感兴趣区域(ROI)是一张图片中重点所关注的区域。在眼底图像中即圆形或者椭圆形的视网膜区域。为了提取眼底图像的感兴趣区域,本文选取了文献中所介绍的最大类间方差法,自适应的完成前景与背景间的阈值计算。提取后的图像如图2 所示。
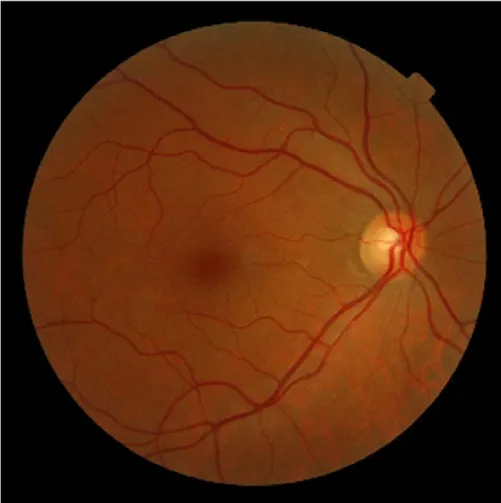
图2: 感兴趣区域提取结果
2.2 图像预处理
图像预处理操作的好坏直接影响深度学习网络的性能,是提升网络性能的关键。本研究所使用的眼底图像在分辨率指标方面表现较好,但是在对比度,亮度、以及噪声、尺寸方面却不太理想。为此本文使用了一系列的图像预处理方法,对数据集进行了预处理操作,之后的数据扩增方法在预处理后的数据集上进行扩增。
首先在对比度和亮度方面,本文采用了亮度均衡化和对比度均衡化的方法,这样能够使图像的信息不被亮度所干扰,得到图像的归一化数据。
为了保证图像的质量,本文选取了双边滤波器,来降低眼底图像中的噪声。
双边滤波器是一种充分使用了图像空间信息的非线性的滤波方法,该滤波器是源于高斯滤波器的。双边滤波器在充分使用像素值的同时,还能考虑其周边的图像信息,并做出适当的处理,最终在达到去噪的同时保留边缘信息的效果。
相比于传统的滤波器,例如高斯滤波去噪,双边滤波器的最大特点是能够很好的保存图像的边缘信息,而不会像传统滤波器那样使的边缘变得模糊,最终造成图像高频信息丢失的结果。综上所述,双边滤波器不单可以去除噪声,还能够保存眼底图像中的边缘与细节信息。而本文基于眼底图像的黄斑变性识别,对眼底图像的边缘信息较为敏感,因此在使用去噪方法后,因尽可能的保留边缘信息,所以选择了双边滤波器作为图像的去噪方法。在图像去噪以后,统一将图像设置为227×227 大小。
2.3 数据集扩增
医学图像与自然图像相比,面临的最大问题是数据集的匮乏,由于医学图像的特殊性,医学图像的收集与标注极为困难,为了提升模型的泛化性能,应尽可能收集较多的数据集。为了解决以上问题,本文使用了数据扩增的方法,主要包括旋转、平移、翻转、缩放等操作。旋转即对原始图像进行任意度数(<20°)的旋转偏移。翻转即对原始图像进行水平或者垂直翻转。裁剪即在原始图像随机裁剪出一部分,作为一张新的眼底图像,一般来说裁剪的区域应该大于70%。具体的如图3 所示。
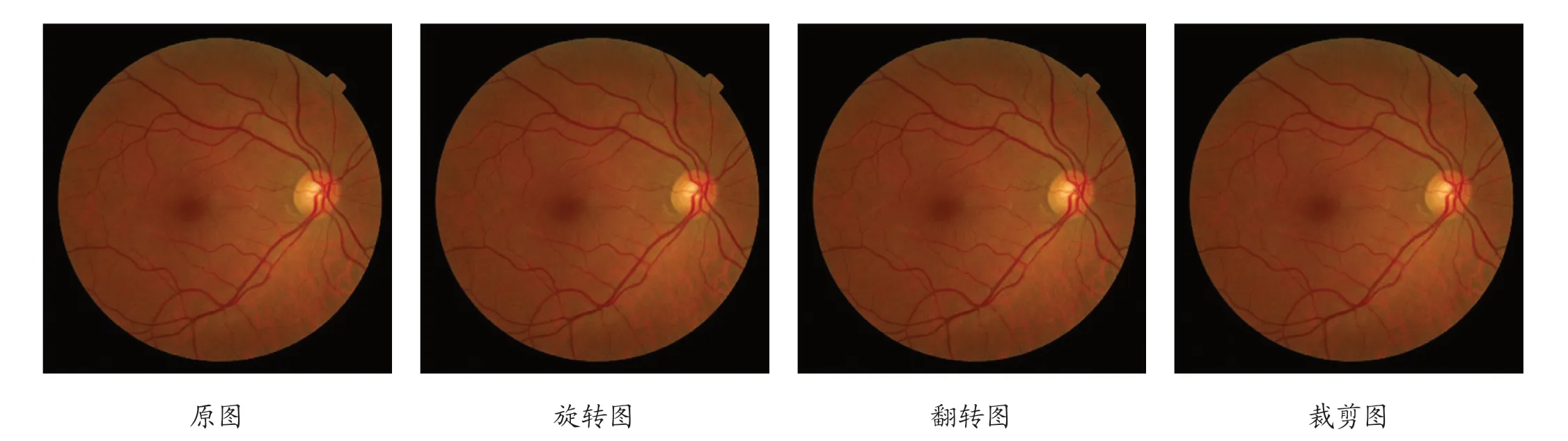
图3: 数据集扩增效果
3 方法
3.1 GoogleNet
GoogleNet 模型在ILSVRC2014 的竞赛中获得了冠军,GoogleNet 的成功,主要是来源于网络中使用了Inception 这一网络结构,通过这一结构不仅增加了网络的深度和宽度,而且缩减了网络中的参数,提升了一定的运算性能。
GoogleNet 中包含了9 个Inception 模块,网络层数较多,如果单独计算网络层数的话,GoogleNet 中的网络层达到了100 多层。GoogleNet 为了方便搭建深层网络,构建了基础模块,每个模块基本相同,只是输出图像大小和通道数略有不同而已。GoogleNet 使用的激活函数为ReLU 函数,网络所能达到的最大感受野大小为224×224。Inception 之所以能够减少参数,其主要的思路是在使用3×3 和5×5 进行卷积操作时,会使用1×1 的卷积进行降维操作,其原因是5×5的卷积计算量较大,所以增加了降维操作。GoogleNet 利用不同的卷积核进行并行连接,在保证感受野的同时还能对图像进行不同特征的提取,最后完成图像特征的拼接,丰富了图像的特征信息。GoogleNet 利用平均池化代替了全连接层,并且使用了Dropout 随机函数,避免网络的过拟合现象。GoogleNet 网络的成功,使得后续出现了InceptionV2,V3,V4 等模块,不断的提高Inception 的模块性能。
InceptionV2 模块,其主要的改进是在Inception 中加入了Batch Normalization。
Batch Normalization 是为了解决深度网络所带来的梯度消失而出现的,由于越深的网络,其网络层数也越多,而数据在经过每一层网络之后,其数据的分布也发生了改变。那么这会使得网络寻找数据的规律变难,为此在深度网络中一般都是使用较小的学习率,以及特定的参数初始化值,防止网络梯度消失,但是这样会造成网络训速度变慢。变慢的主要原因是数据的分布发生了变化,为了保证数据分布的一致性,加入了BN 层,在网络的每一层后加入BN 层,对数据进行归一化操作,保证数据的分布不改变,这样加入BN 层后,即可使用较大的学习速率,从而加快网络的收敛速度,在一定程度上还会防止梯度的消失,使得训练具有较多层次的网络结构成为了可能 。本文后续的网络设计,受到了该模块的影响,在设计时加入了Inception-V2 模块。
3.2 VGG
VGGNET 是由牛津大学和谷歌共同提出的一个深度卷积网络,VGG 其主要结构是卷积网络,在2014 年的ImageNet 比赛中获得了亚军,冠军则是3.1 节所介绍的GoogleNet。VGG 的版本较多,共有6 种不同结构,最常用的是VGG-16 版本,该版本的卷积层个数为13,全连接层的个数为3,还包括池化层,池化层为5 层。VGG 虽然是亚军,但其独特的设计理念还是引发了诸多研究者的青睐。
VGG 网络的结构特点是比较明显的,具体的,VGG 中的各卷积层结构基本相同,并且使用的池化操作也相同,都是将上一卷积层特征缩减一半,并且使用的都是较小的卷积核,因而深度也较深,保证网络的较大感受野。本文后续的网络设计,受到了该模块的影响,在设计时加入了VGG 网络的思想。
3.3 VG-AMD
为了提高深度卷积网络的准确性,在设计VG-AMD 时使用了Inception-V2 模块结构,具体如图4 所示。通过多个卷积核提取图像不同尺度的特征,最后进行融合,这样能够获得更好的图像特征。并且,在Inception V2 结构中,用两个3×3 的结构代替了5×5 的结构,在保持感受野不变的情况下,缩减了运算的参数,提高了运算的性能。
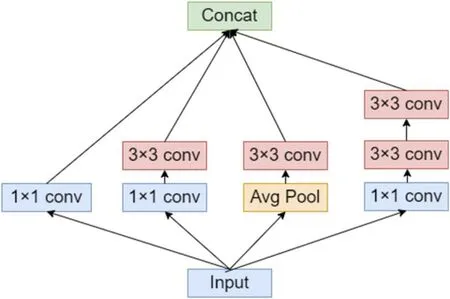
图4: Inception V3 结构
受到VGG 与GoogleNet 网络的启发,设计了如表1 所示的网络结构,命名为VG-AMD。

表1: VG-AMD 网络结构
VG-AMD 网络中,包含7 个卷积层,1 个全连接层,4 个池化层。7 个卷积层的目的是从眼底图像中提取不同的特征,其中使用了2 个Inception-v2 模块,代替普通的卷积层,其目的是提取更丰富的图像特征。4 个池化层可以降低图像的维度,最后一个池化层使用了平均池化,减少了网络参数。卷积层的步长为1,池化层的步长为2,全连接层后接softmax 层,完成二分类的分类任务,即眼底图像正常与眼底图像为黄斑变性两类。由表1 可见,图像的输入大小为227×227×3,通过第一次卷积层后,图像大小变为225×225,通道数为16,然后经过最大池化,降低图像大小,变为112×112。接着进行相同的卷积与池化操作,使图像变为22×22×256,并完成全局池化,输入到全连接层,最后利用softmax 完成概率输出。
4 实验与结果分析
本实验所提方法的实现是基于深度学习框架Pytorch 实现的,采用Adam 优化算法,在一块NVIDIA 3090GPU 上完成训练和测试。学习率设置为0.001,批次为100,批次大小设置为24,损失函数为交叉熵损失函数。实验将数据分为训练集与测试集,训练集占80%,测试集占20%。经过图像预处理,共获得1210 张正常眼底图像,612 张AMD图像,通过上述方法进行训练和测试,最终的结果如表2 所示。

表2: VG-AMD 网络训练与测试结果
由表2 结果可知,VG-AMD 在测试集上的准确率为93.1%,在训练集上的准确率为94.2%,相差只有1.1%,VG-AMD 并不存在过拟合的现象。虽然VG-AMD 的识别率达到了93.1%,并且AUC 值达到了0.93,但是要想进一步提高VG-AMD 的性能,修改网络结构是一方面,数据样本的数量也是比较关键的一个环节,数据样本的缺少,会造成网络泛化性能的偏低。
5 总结
本文提出了一种以卷积网络为基础的自动化黄斑变性诊断技术。通过公开数据集收集了实验所用图像,并进行了相关的预处理和数据增强操作,然后经过设计的VG-AMD 网络,可以自动的提取特征,并完成分类任务,准确率达到了93.1%,可以很好的作为医生诊断的辅助工具。
猜你喜欢
中国造纸(2022年9期)2022-11-25
电子制作(2019年11期)2019-07-04
保健医苑(2019年5期)2019-05-15
环球时报(2019-04-03)2019-04-03
电子制作(2018年16期)2018-09-26
系统工程与电子技术(2016年7期)2016-08-21
火控雷达技术(2016年2期)2016-02-06
西藏科技(2015年10期)2015-09-26
河南医学研究(2014年4期)2014-02-27
河北医科大学学报(2011年8期)2011-03-25
