
基于可见光-近红外光谱的煤岩识别方法实验研究
2022-07-06 05:36徐良骥孟雪莹
光谱学与光谱分析 2022年7期
徐良骥,孟雪莹,韦 任,张 坤
1. 深部煤矿采动响应与灾害防控国家重点实验室,安徽 淮南 232001 2. 安徽理工大学空间信息与测绘工程学院,安徽 淮南 232001
引 言
煤岩识别是实现智能化选煤和综采工作面无人化的前提。 近年来随着计算机技术的迅速发展,煤矿生产自动化水平显著提高,也使得综合开采工作面的无人化操作和选煤厂智能化选煤的实现成为可能[1]。 智能化技术的实现在很大程度上提高煤炭生产的安全性[2]。 煤岩识别技术的实现对煤炭绿色开采、 精准开采具有重大的实际意义[3]。
近年来,遥感技术在矿区煤炭勘探开采、 煤和岩石的性质测定、 土壤和水体的污染监测等方面得到广泛应用[4,5]。 在煤炭资源勘探开发各阶段遥感技术主要应用于资源调查评价、 矿区卫星测图、 矿产资源开发及矿区环境监测等领域[6],在煤炭开采过程中,可以利用遥感图像对矿区地层分布特征进行提取。 对于土壤与水体污染监测方面,遥感技术更是可以直接利用地物光谱反射率进行地物提取与监测。 近年来,井下无人开采成为国内外研究的热点,而煤岩识别正是井下无人开采的关键,在传统煤岩识别过程中,人工识别效率低下,因此如何准确的实现煤岩识别成为该研究领域亟待解决的问题。 宋亮等[7]研究了基于可见光-近红外和热红外联合分析煤和岩石分类方法; 王卫东等[8]研究了基于激光三维扫描与动态称重的煤岩石光电分选系统; Yang等[9]利用可见光和近红外(VIS-NIR)反射光谱进行煤岩石识别; Wang等[10]使用太赫兹时域光谱法对煤和岩石进行表征和分类。 本文基于可见光-近红外光谱和样本成分含量研究煤岩的识别方法。
1 实验部分
1.1 研究区概况
实验样本共29份,其中煤样15份,岩石样本14份,样本来源如下:
从谢桥矿采集煤和岩石样本共11份,其中煤样7份,岩石样本4份,7份煤样按顺序命名为XQM1,…,XQM7,岩石样本按顺序命名为XQG1,…,XQG4。 煤的类型主要为烟煤,岩石类型主要为砂岩、 和泥岩。
从潘二矿采集煤和岩石样本共18份,其中煤样8份,岩石样本10份,8份煤样按顺序命名为P2M1,…,P2M8,10份岩石样本按顺序命名为P2G1,…,P2G10。
谢桥矿位于安徽省颍上县东北部,距颍上县城约20 km,现生产能力超过800万吨/年、 配套800万吨选煤厂的特大型现代化矿井。 潘二煤是淮南矿业集团所属的一座年设计生产能力为300万吨的大型现代化矿井。 该矿位于安徽省淮南市西北部约30 km的潘集区境内。 矿井地处淮河以北属江淮平原,西南部与潘一矿井接壤,西北部与潘北矿井毗邻。

图1 部分煤和岩石样本Fig.1 Some coal and rock samples
1.2 煤岩光谱差异机理分析
图2所示为煤和岩石样本的反射光谱,由图可知,煤的整体反射率较低,上升平缓,而岩石的反射率偏高,且有吸收谷。 在1 450 nm附近,由于水分子O—H官能基伸缩振动的第一倍频,岩石在此处有较强吸收谷。 在1 900 nm附近,由于岩石中的二价Fe离子和煤样中的Al2O3,岩石存在更强的吸收谷。 在2 130~2 250 nm波段内煤与岩石存在较大差异,这是由于Al元素在煤中主要以Al2O3的形式存在,而在岩石中则主要以Al(OH)3形式存在,Al(OH)3的Al—OH晶格振动使得其在2 210 nm附近具有强吸收峰[11]。

图2 原始光谱反射率曲线Fig.2 Original reflectance spectra
近红外光谱的主要吸收带是含氢基团C—H,O—H,N—H等的一级倍频和C—O,C—N,C—C等的多级倍频。 煤中的有机物主要包括碳(C)、 氢(H)、 氧(O)、 氮(N)等,主要指工业分析指标的挥发分和固定碳; 无机物包括水和碳物质,主要指工业指标的水分和灰分。 根据中国国家标准GB/T 5751《中国煤炭分类》和国际标准ISO 11760 Classification of coals对煤炭的定义标准, 煤炭是主要由植物遗体经煤化作用转化而成的富含碳的固体可燃有机沉积岩, 含有一定量的矿物质, 其灰分产率小于或等于50%[12]。 据此, 灰分和挥发分的含量差异可用于进行煤岩识别分析。
1.3 光谱数据的采集
美国ASD公司生产的地物光谱仪FieldSpec 4的光谱范围是350~2 500 nm,有两种采样间隔分别为1.4 nm(350~1 000 nm)和2 nm(1 000~2 500 nm); 该实验的重采样间隔为1 nm。 数据采集在暗室中进行,选择50 W的卤素灯为光源、 25°裸光纤镜头接收反射波段。 测量时将样本放入直径为100 mm,高2 mm的透明玻璃培养皿中,光源距离样品40 cm,光线与样品成45°角,探头距样本10 cm位于光源对面,探头光纤末端位于煤、 岩石样本正上方。 在对样本进行光谱测量前需要进行白板校正,每个样本采集30条曲线,对获取的煤和岩石样本反射光谱曲线采用ViewSpecPro软件进行预处理(剔除异样数据、 断点修复,光滑处理等),最后将各组曲线的算术平均值作为样本的原始光谱反射率值,如图2所示。
1.4 样品成分含量检测
采用GB212—2008煤的工业分析方法对煤和岩石样本的水分、 灰分、 挥发分进行测定。 测定结果如表1所示,具体测定步骤如下:
(1)样本水分的质量分数(Mad)采用空气干燥法[13]。
称取粒度粒径为0.15 mm煤样、 岩石样本(1±0.1) g,称准至0.000 2 g,平摊在称量瓶中。 每个样本设置三个对比样,将样品置于105~110 ℃鼓风干燥箱内,于空气流中干燥到质量恒定。 根据煤样的质量损失计算出水分的质量分数(Mad)。

表1 两矿煤样工业指标测试结果Table 1 Test results of industrial indicators ofcoal samples from two mines

续表1
(2)样本的灰分(Aad)采用快速灰化法[13]。
①在预先灼烧至质量恒定的灰皿中,称取粒度小于0.2 mm的一般分析实验煤样(1±0.1) g,称准至0.000 2 g,均匀地摊平在灰皿中,使其每平方厘米的质量不超过0.15 g。 将盛有煤样的灰皿预先分排放在耐热瓷板或石棉板上。
②将马弗炉加热到850 ℃,打开炉门,将放有灰皿的耐热瓷板缓慢地推入马弗炉中,待5~10 min后煤样不再冒烟时,以每分钟不大于2 cm的速度把其余各排灰皿顺序推入炉内炽热部分(若煤样着火爆燃,停止该实验、 作废)。
③关上炉门并使炉门留有15 mm左右的缝隙,在(815±10) ℃温度下灼烧40 min。
④将灰皿从炉中取出,放在空气中冷却5 min,然后移入干燥器中冷却至室温(约20 min)后,称量。
⑤进行检查性灼烧,温度为(815±10) ℃,每次20 min,直到连续两次灼烧后的质量变化不超过0.001 0 g为止。 以最后一次灼烧后的质量为计算依据。
(3)样本的挥发分(Vad)测定[13]:
①在预先于900 ℃温度下灼烧至质量恒定的带盖瓷坩埚中,称取粒度小于0.2 mm的一般分析实验煤样(1±0.1) g,称准至0.000 2 g,然后轻轻振动坩埚,使样品摊平,盖上盖,放在坩埚架上。
②将马弗炉预先加热至920 ℃左右,打开炉门,迅速将

图4 煤和岩石样本挥发分实验炉Fig.4 Set up for determining the volatilematter in coal and gangue
放有坩埚的坩埚架送入恒温区,立即关上炉门并计时,准确加热7 min; 坩埚及坩埚架放入后,要求炉温在3 min内恢复至(900±10) ℃,此后保持在(900±10) ℃,否则此次实验作废,加热时间包括温度恢复时间。
③从炉中取出坩埚,放在空气中冷却5 min左右,然后移入干燥器中冷却至室温(约20 min)后称量。
煤和岩石氧化物含量采用XRF检测,检测结果如表2所示。
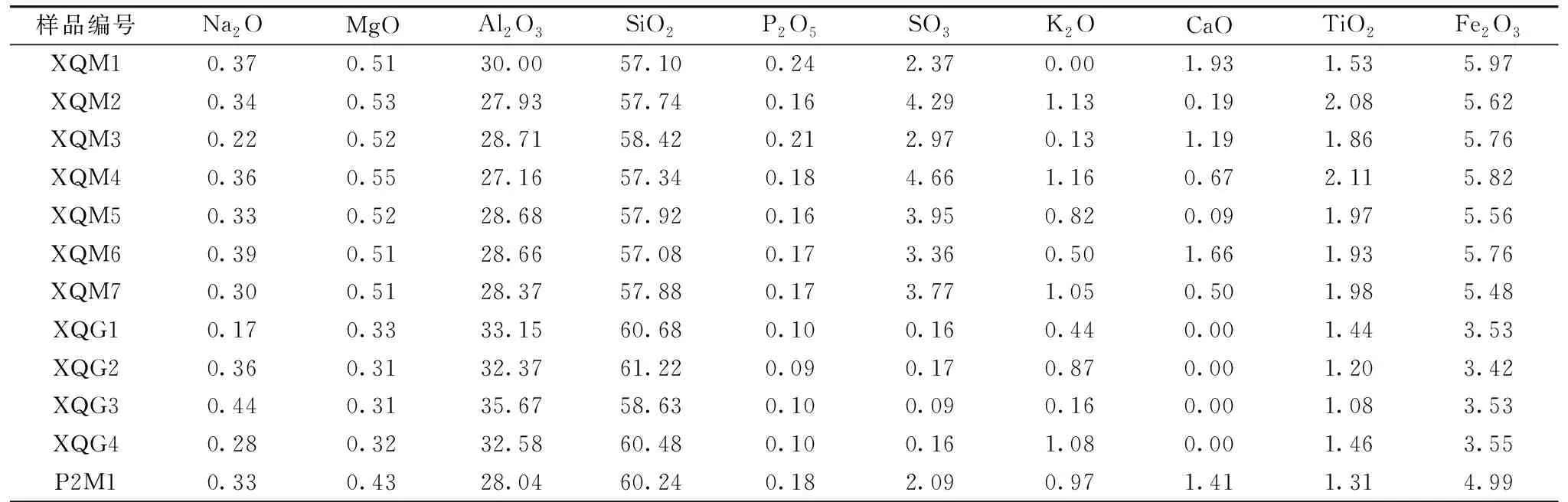
表2 两矿煤和岩石样本氧化物百分比含量Table 2 Oxygen percentage contents of coal and rock samples from two mines
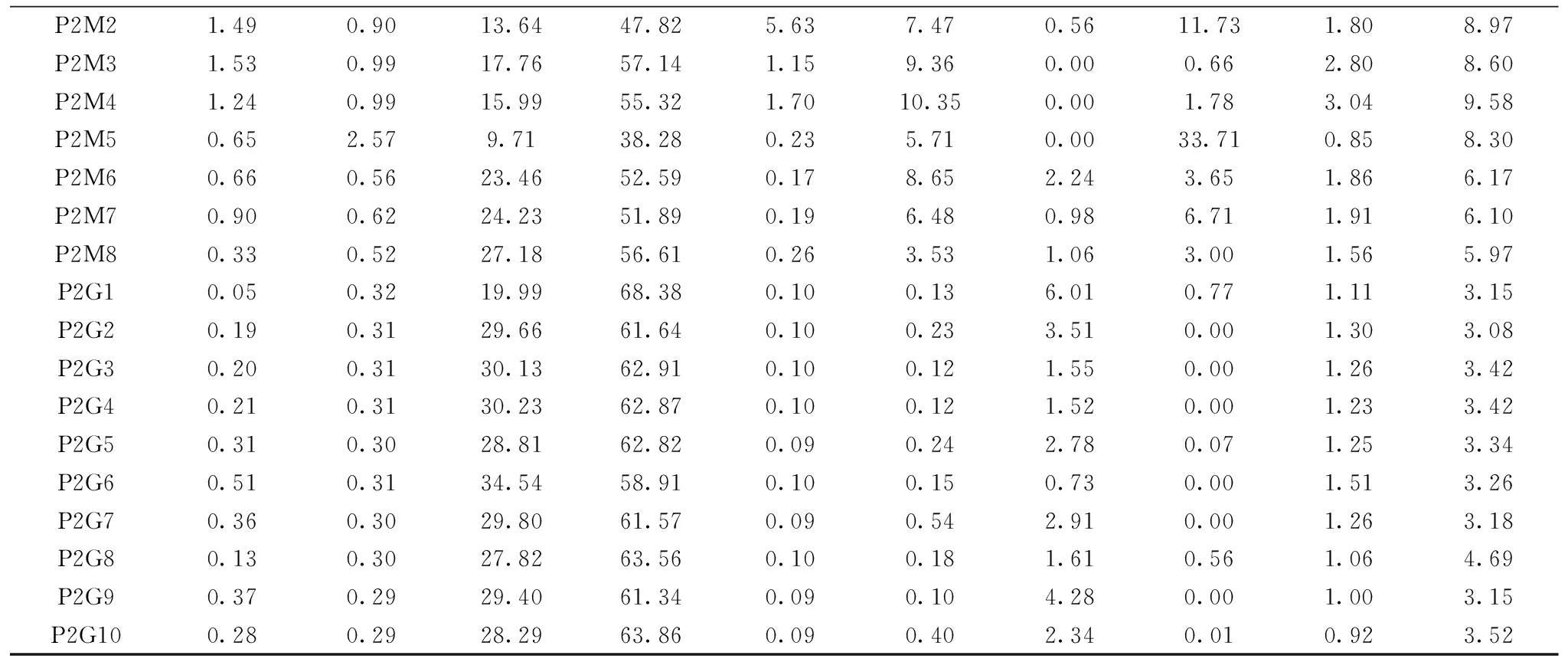
续表2
1.5 建模方法及参数选择分析
主成分分析是目前较常用的一种光谱特征信息提取方法,在处理线性问题时能够取得很好的效果。 核成分分析则将数据映射到高维特征空间,利用主成分分析实现非线性的特征提取,改善主成分分析在非线性数据分布情况下分析结果不理想的状况。 与其他机器学习算法相比, 支持向量机(SVM)算法更适合于本实验的小训练样本、 多维度成分因素、 非线性关系问题[14]。 因此选择PCA-SVM、 PCA-BP和KPCA-SVM共三种方法进行煤岩识别的建模。 其中,惩罚因子由网格搜索法获得,经过多次建模试验确定最优迭代率和学习率。 模型复杂度低,未出现过拟合现象。
2 结果与讨论
2.1 基于可见光-近红外光谱的煤和岩石识别模型
(1)主成分分析结合支持向量机(PCA-SVM)模型
煤岩识别的本质是一个二分类的问题,并不需要区分煤或岩石具体的矿物类型。 将煤作为识别向量标签“0”,岩石作为识别向量标签“1”,对煤岩的特征值进行训练,将煤岩的特征值作为自变量,煤岩的识别标签“0”和“1”作为因变量,最后利用训练的模型对验证集进行识别。 其中,煤岩对应的特征值分别为它们在可见光-近红外波段的反射率和工业分析与XRF仪器测量出的成分含量。 随机建立训练集20个样本和验证集9个样本,对样本反射率进行主成分分析,确定主成分得分值利用5倍交叉验证确定最优惩罚参数和最优方差参数,进行支持向量机模型建立,并将验证集代入模型验证。 随机建立的20组主成分分析结合支持向量机识别模型的最优参数、 建模精度、 验证结果如表3所示。
由表3可知,主成分分析结合支持向量机模型中,建模精度最高为100%,最低精度为55%,平均精度为83.75%。 验证集模型识别精度最高为66.67%,最低为22.22% ,平均识别精度约为45.97%。
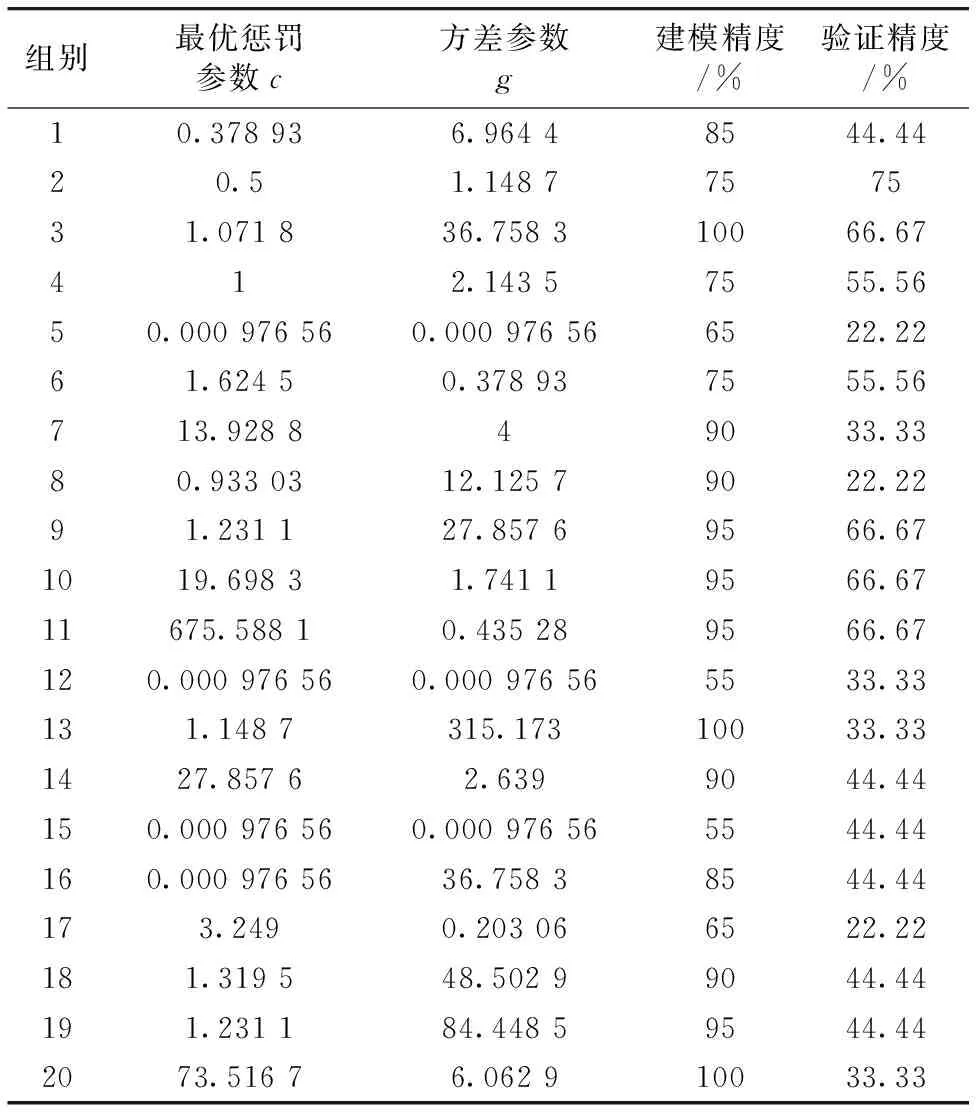
表3 基于可见光-近红外光谱的PCA-SVM模型的模型精度Table 3 Model accuracy of PCA-SVM model based onvisible-near infrared spectra
(2)主成分分析结合BP神经网络(PCA-BP)模型
对样本光谱反射率数据进行主成分分析,得到28个主成分。 首先对BP神经网络中的初始参数进行设置,构造神经网络结构,参数如下: 迭代次数(epochs)=10 000,学习率(Ir)=0.05,训练目标误差(goal)=0.001。 整个神经网络匹配系统分为四个部分: 输入端、 一个隐含层、 一个输出层、 输出端。 神经网络结构如图5所示。
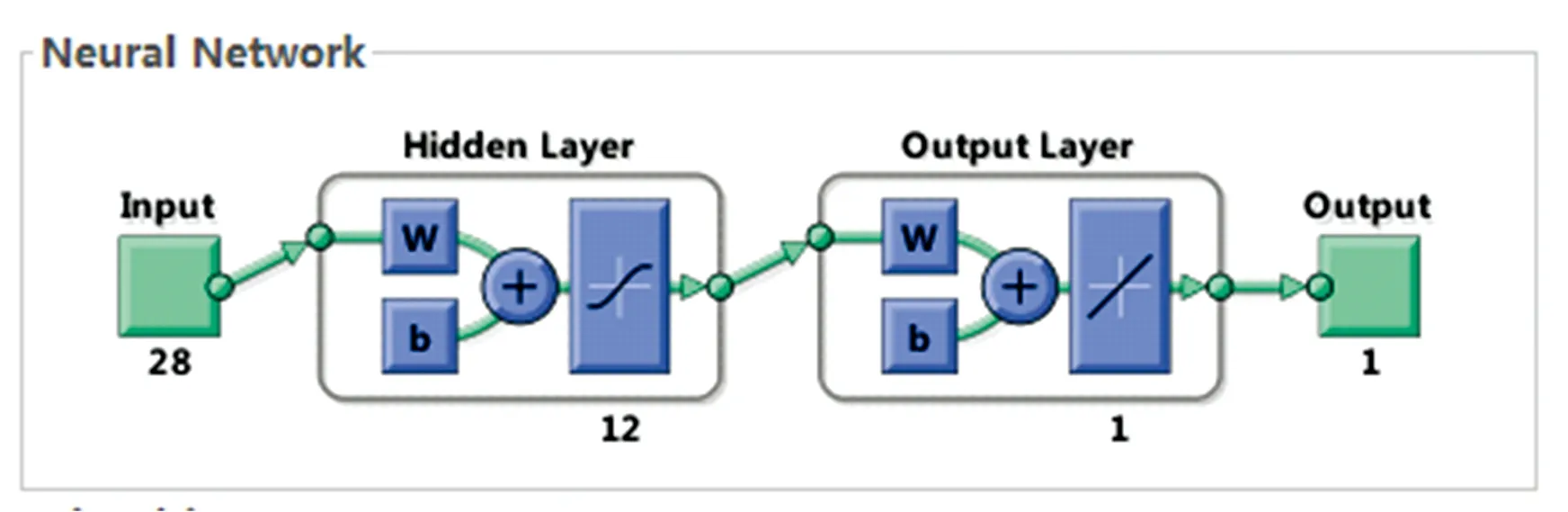
图5 基于可见光-近红外光谱的PCA-BP神经网络模型结构Fig.5 Model structure of PCA-BP neural networkbased on visible-near infrared spectra
将主成分数据代入BP神经网络模型中进行煤和岩石识别分类,20组数据的PCA-BP神经网络模型的预测精度如图6所示。

图6 PCA-BP神经网络模型识别率Fig.6 PCA-BP neural network model recognition rate
基于样本反射率光谱数据的PCA-BP神经网络模型识别率最高为54.55%,最低为26.25%,平均识别率为43.33%。
(3)核主成分分析结合主成分分析(KPCA-SVM)模型
对样本反射率进行核主成分分析,确定主成分得分值利用5倍交叉验证确定最优惩罚参数和最优方差参数,进行支持向量机模型建立,并将验证集代入模型验证。 20组KPCA-SVM模型最优参数、 训练集、 验证精度如表4所示。
由表4可知,核主成分分析结合支持向量机模型中,建模精度最高为100%,最低精度为85%,平均精度为95.5%。 验证集模型识别精度最高为100%,最低为66.67%,平均识别精度约为90.56%。
2.2 基于样本成分含量的煤和岩石识别模型
(1)主成分分析结合支持向量机(PCA-SVM)模型
对样本的14个成分含量进行主成分分析,确定主成分得分值利用5倍交叉验证确定最优惩罚参数和最优方差参数,进行支持向量机模型建立,并将验证集带入模型验证。 基于样本成分的PCA-SVM模型最优参数、 训练集、 验证精度如表5所示。
由表5可知,主成分分析结合支持向量机模型中,建模精度最高为100%,最低精度为70%,平均精度为83.75%。 验证集模型识别精度最高为100%,最低为22.22%,平均识别精度约为50.56%。
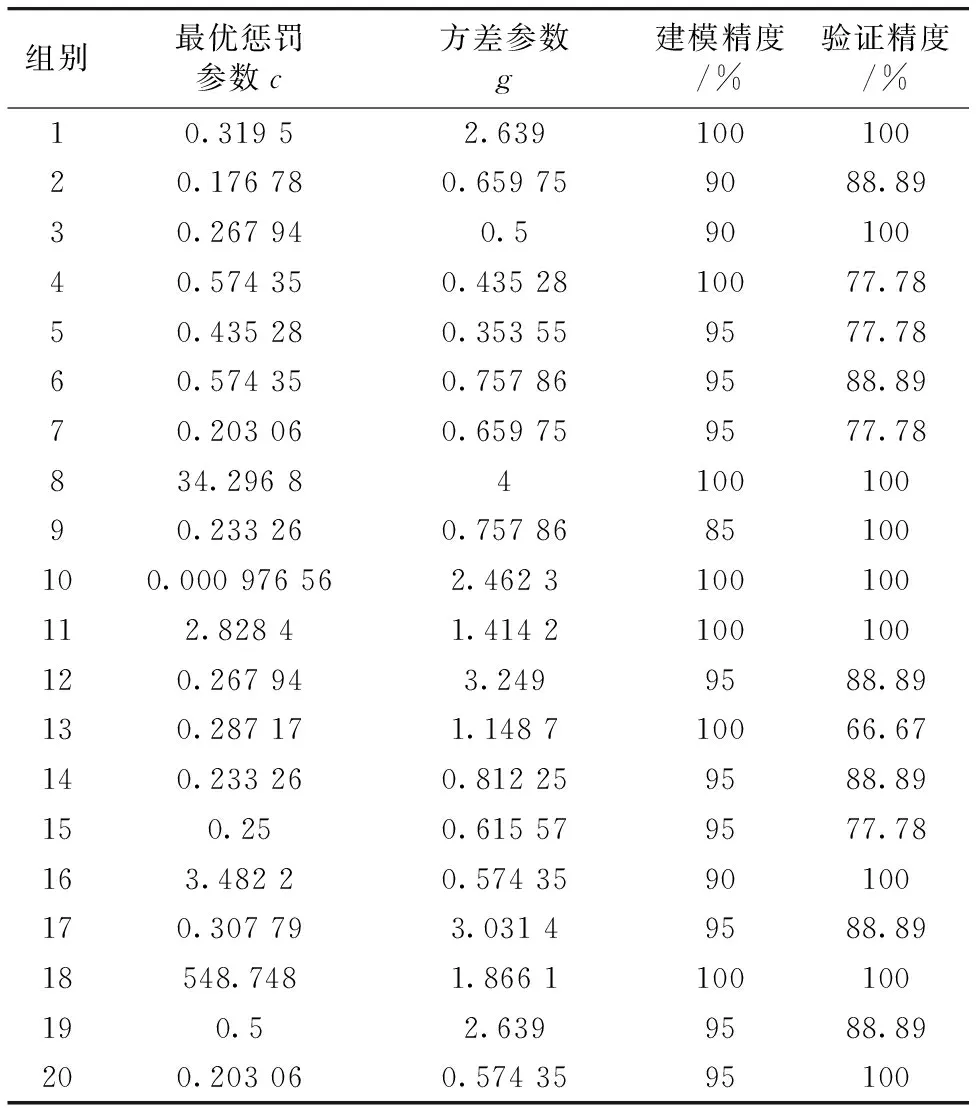
表4 KPCA-SVM模型的模型精度Table 4 Accuracy of KPCA-SVM model
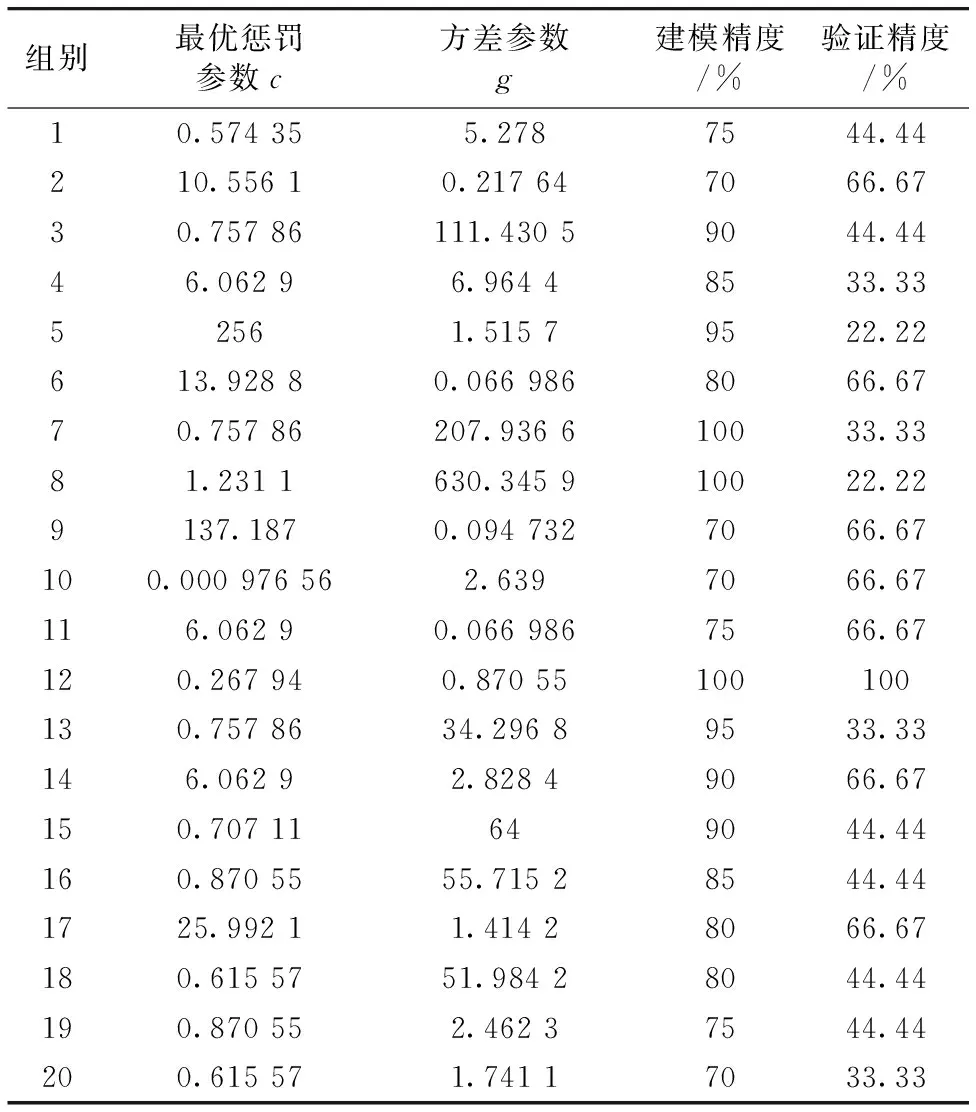
表5 基于样本成分的PCA-SVM模型的模型精度
(2)主成分分析结合BP神经网络(PCA-BP)模型
对样本光谱反射率数据进行主成分分析,得到12个主成分。 首先对BP神经网络中的初始参数进行设置,构造神经网络结构,参数如下: 迭代次数(epochs)=10 000,学习率(Ir)=0.05,训练目标误差(goal)=0.001。 整个神经网络匹配系统分为四个部分: 输入端、 一个隐含层、 一个输出层、 输出端。 神经网络结构如图7所示。
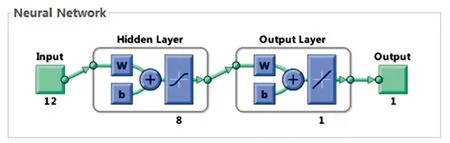
图7 基于样本成分的PCA-BP神经网络结构Fig.7 Structure of PCA-BP neural network based onsample components
将主成分数据代入BP神经网络模型中进行煤和岩石识别分类,20组数据的PCA-BP神经网络模型的预测精度如图8所示。

图8 基于样本成分的PCA-BP神经网络模型识别率Fig.8 Recognition rate of PCA-BP neural networkmodel based on sample components
基于样本成分的PCA-BP神经网络模型识别率最高为77.78%,最低为22.22%,平均识别率为46.11%。
(3)核主成分分析结合主成分分析(KPCA-SVM)模型
对样本成分进行核主成分分析,确定主成分得分值利用5倍交叉验证确定最优惩罚参数和最优方差参数,进行支持向量机模型建立,并将验证集带入模型验证。 20组KPCA-SVM模型最优参数、 训练集、 验证精度如表6所示。
由表6可知,核主成分分析结合支持向量机模型中,建模精度最高为100%,最低精度为95%,平均精度为98.5%。 验证集模型识别精度最高为100%,最低为77.78%,平均识别精度约为95%。
3 结 论
针对可见光-近红外光谱法煤岩石识别时易发生煤与岩石误分类的问题,综合采用主成分分析结合支持向量机模型(PCA-SVM)、 主成分分析结合BP神经网络模型、 核主成分分析结合支持向量机模型(KPCA-SVM)进行了研究,并将最终的识别率、 精度列在表7中。
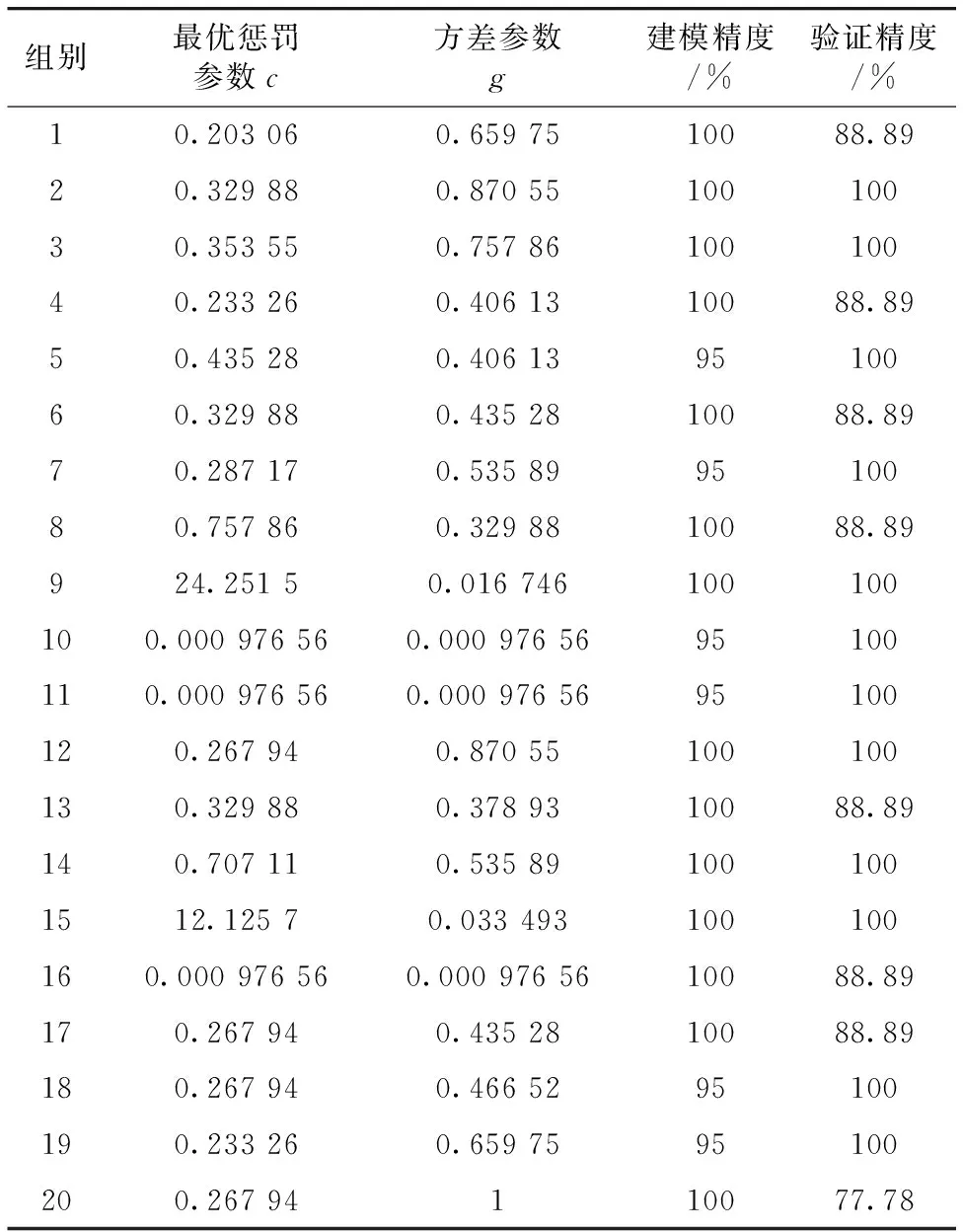
表6 基于样本成分的KPCA-SVM模型的模型精度Table 6 Model accuracy of KPCA-SVM modelbased on sample components
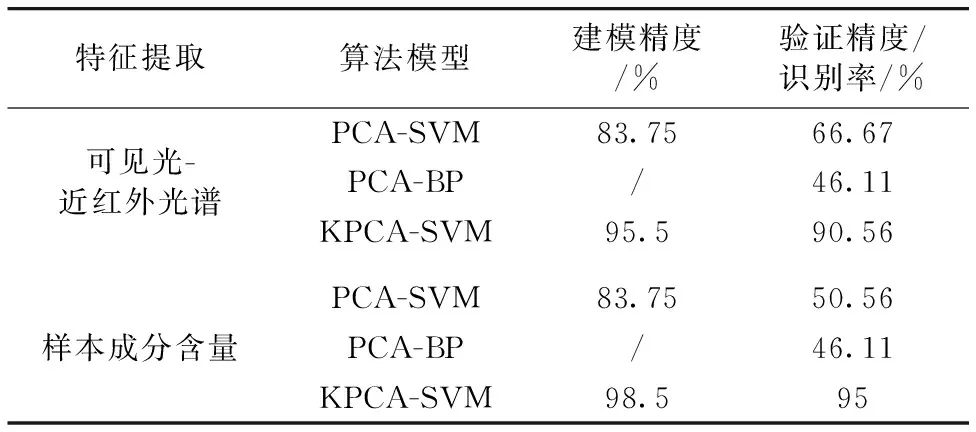
表7 算法模型精度/识别率比较Table 7 Algorithm model accuracy/recognition rate comparison
(1)基于可见光-近红外光谱的KPCA-SVM模型建模精度最高为100%,最低精度为85%,验证模型精度最高为100%。 基于样本成分含量的KPCA-SVM模型建模精度最高为100%,最低精度为95%。 验证模型精度最高为100%。 可见,基于可见光-近红外光谱和煤岩成分含量进行煤岩识别是可行的,在建模方法中KPCA-SVM表现较佳,优于PCA-SVM和PCA-BP两种方法。
(2) 基于样本成分含量对煤、 岩石的分类过程中,KPCA-SVM的建模精度高于PCA-SVM,平均建模精度为98.5%; 同时KPCA-SVM的验证精度高于PCA-SVM和PCA-BP两种方法的验证精度,平均精度为95%。
(3) 提取了煤岩的光谱数据和成分含量两种特征,结合PCA-SVM,PCA-BP和KPCA-SVM三种算法模型,建立了六种煤岩识别的方法。 由表7可知,基于煤岩成分含量的KPCA-SVM的模型方法识别率达到了95%,高于其他五种方法的识别率,故该模型最优。
猜你喜欢
煤(2022年8期)2022-08-08
煤矿安全(2021年9期)2021-10-17
小学科学(学生版)(2021年7期)2021-07-28
科技创新导报(2021年33期)2021-04-17
小学科学(学生版)(2020年11期)2020-12-14
小学科学(学生版)(2020年10期)2020-10-28
同煤科技(2019年5期)2019-11-01
小学生必读(低年级版)(2019年5期)2019-08-30
煤(2019年4期)2019-04-28
中国煤层气(2015年4期)2015-08-22
