
基于长短期记忆神经网络的深水钻井工况实时智能判别模型
2022-07-06 06:30:04殷启帅杨进曹博涵龙洋陈柯锦范梓伊贺馨悦
石油钻采工艺 2022年1期
殷启帅 杨进 曹博涵 龙洋 陈柯锦 范梓伊 贺馨悦
1. 中国石油大学(北京);2. 中国石化集团经济技术研究院有限公司;3. 浙江工业大学
钻井工况是指现场钻井作业中的某一特定操作工序,包括接单根、起下钻、倒划眼、循环钻进等典型工况。深水钻井具有高投入、高风险等特点,对钻井时效与复杂事故率提出了更高要求,而深水钻井工况实时判别是提高钻井时效、减少复杂事故的基础和前提。传统深水钻井作业中,钻井工况主要通过基于编程方式的物理模型与经验模型进行判别,由于各个监测参数之间存在极其复杂的高度非线性映射关系,难以保证判别时效性和正确率。而机器学习方法可以从高维度拟合不同监测参数之间的非线性映射关系,并且是一个“黑盒子”,不需要明确的编程语言[1],就可以有效地完成特定的模式判别任务,笔者将机器学习方法应用于深水钻井工况智能判别。但受钻井长循环迟到时间影响,钻井工况由当前时刻以及其前后一段时间区间的数据共同决定,使得钻井工况判别具有长时间序列特征。
随着录井传感器技术的快速发展,综合录井仪获取了海量高品质综合录井数据,为基于人工神经网络的钻井工况智能判别提供了数据基础[2-5]。近年来,计算机性能与云计算能力的提升,进一步提高了机器学习在石油工业的应用前景[6],机器学习己经成为石油工程领域模式判别的有力工具[7]。
利用综合录井数据进行钻井工况判别是近年来国内外学者的研究热点和难点。2018年,Qishuai Yin等[8]通过编程语言为综合录井参数设定判断条件进行钻井工况判别,并进行了不可见非生产时间(Invisible Non-Production Time, INPT)统计分析,通过对钻井人员绩效评估提高了钻井作业效率,为钻井作业节省了作业时间和工程投资,实现了降本增效。2019年,孙挺等[9]提出了基于支持向量机(Support Vector Machine, SVM)的钻井工况判别方法,建立了多个智能判别模型,得出了模型参数的最优值。A. Arnaout等[10]建立了基于离散多项式的数学模型,用于钻井工况特定模式判别,预测结果与人工分类比较,显示该方法具有较高的准确性。2019年,Yuming Ben等[11]指出由于顶驱的振动很 难 简 单 根 据 井 口 顶 驱 转速(Rate per Minute,RPM)判别“旋转钻进”与“滑动钻进”,提出采用随 机 森林(Random Forest, RF)、卷 积 神 经 网 络(Convolutional Neural Network, CNN)和混合卷积神经网络/循环神经网络(Convolutional Neural Network/Recurrent Neural Network, CNN/RNN)判别“旋转钻进”与“滑动钻进”,结果表明机器学习模型远优于基于规则的模型,CNN的判别正确率在90%以上。2020年,Qishuai Yin等[12]利用误差反向传播神经网络(Backpropagation Neural Network, BP)建立了新型的钻井工况智能判别机器学习模型,并有效评价了钻井时效,在海上浅水批钻作业中得到成功应用,钻井时效提高了31.19%。
尽管近年来学者们尝试建立了一些基于机器学习的钻井工况判别模型,但上述模型均未考虑综合录井数据的长时间序列特性,导致模型较高的误报率。笔者利用综合录井数据建立了基于长短期记忆循环神经网络(Long Short-Term Memory Recurrent Neural Network, LSTM-RNN)的钻井工况实时智能判别机器学习模型。由钻头深度、井深、大钩高度、钻压、悬重、扭矩、转速、立管压力等8个综合录井参数作为输入特征向量,钻井工况作为输出向量,实现了旋转钻进、滑动钻进、接单根、静止、循环、向下洗井、划眼、向上洗井、倒划眼、起钻、下钻、其他(其余深水综合录井数据对应钻井工况均标记为“ 其他”)等12种钻井工况的智能判别。
1 神经网络优选及模型性能评价指标
人工神经网络是一种基于数值计算的知识处理系统,是一种灵感来源于人类神经元网络的机器学习模型,由许多简单处理单元相互连接而形成的复杂网络[13-14]。实现钻井工况智能判别的首要任务是根据样本集数据特征选择最佳的神经网络算法,再选用正确率、精度、召回率和F1分数等评价指标评估机器学习模型的分类判别性能。
1.1 钻井工况智能判别神经网络优选
基于钻井工况智能判别的长时间序列特征,对常见的3种神经网络算法进行结构剖析与原理对比分析,为钻井工况智能判别提供算法基础。
BP神经网络应用广泛[15-19],其隐藏层输出仅取决于当前时间步的输入特征,与在当前时间步之前的数据特征无关。可见BP网络不适合处理时间序列问题,更不适合处理长时间序列特征的钻井工况判别问题。
RNN神经网络是使用深度学习处理时序问题最常用的模型之一,因为其在时间步t时会将t−1时间步的隐藏层节点作为当前时间步的输入,因此在处理时序数据上有着优异的表现[20]。但由于RNN是一个链式结构,每个时间步使用的是相同的参数,导致在训练时会遇到梯度消失的问题,甚至梯度会收敛到0(梯度消失),使得RNN普遍存在“长期依赖”问题,即在时间间隔不断增大时,RNN丧失了学习到远处时刻的信息的能力[21-22]。因此,RNN网络不适合处理长时间序列特征的钻井工况智能判别问题。
1997年,Hochreiter和Schmidhuber[23]提出了LSTM-RNN神经网络,并证明了LSTM网络具有记忆长短时信息的能力,可以有效解决RNN的长期依赖问题。近年来,LSTM神经网络获得快速发展,并在石油工程领域得到了成功应用。2019年,Lee等[24]使用LSTM算法成功预测了页岩气产量。
LSTM之所以能够解决RNN的长期依赖问题,是因为LSTM引入了遗忘门ft、输入门it、输出门ot来控制特征的流通和损失,LSTM展开的链式结构如图1所示。

图1 展开的长短期记忆循环神经网络Fig. 1 Expanded LSTM-RNN
图1中,上方从左到右贯穿的长直线使得所学知识在上面直接传递而不轻易发生改变,从而使得LSTM网络具有了“长”记忆,解决了RNN的“长依赖”问题。“短期记忆”ht与 “长期记忆”ct的联合使用使得LSTM具有在长时间序列上学习“短期”模式与“长期”模式。当长期单元状态ct通过神经网络时,遗忘门ft“遗忘(删除)”部分记忆信息,输入门it“输入(添加)”部分记忆信息,最后经过输出门ot处理输出结果。
通过剖析BP、RNN与LSTM神经网络结构,考虑综合录井数据长时间序列特性,优选了擅于学习时间序列信息且可以处理长期相关性的LSTM神经网络作为钻井工况智能判别的最优算法。
1.2 分类判别机器学习模型性能评价指标
通常需要评估机器学习模型的泛化误差,选择泛化误差最小的模型,因此,需要使用测试集来测试模型的分类判别能力,并使用测试集的测试误差作为泛化误差的近似。本文采用了4个评价指标,正确率(Accuracy)、精度(Precision)、召回率(Recall)和F1分数(F1-score)[12]。
结合实际类别和模型预测类别进行分类,二分类的混淆矩阵如表1所示,多分类的混淆矩阵如图2所示,其中TP为真阳性,FP为假阳性,TN为真阴性,FN为假阴性。

图2 多分类问题的混淆矩阵Fig. 2 Confusion matrix of multi-classification problem

表1 二分类结果的混淆矩阵Table 1 Confusion matrix of binary classification result
不同指标直接反映了分类判别的性能。“正确率”是最常见的评价标准,即被正确分类的样本数除以样本总数。对于均衡分类问题,通常正确率越高,分类器越好。“精度”和“召回率”是一对矛盾的衡量标准。“精度”可以反映某一类测试样本,有多少预测是正确的,有多少预测是不正确的。“ 召回率”显示了某一类预测结果中有多少预测是正确的。“F1分数”是精度和召回率的调和平均值。
2 样本集数据分析与处理
由于采集的综合录井数据不可避免地具有一些冗余,因此基于录井参数的重要性开展输入向量降维处理是非常必要的。此外,数据清理与数据标记是监督式学习(Supervised learning)和建立预测分类模型的基本环节。最终,按照合理的比例将样本集分为训练集与测试集。
2.1 综合录井数据的输入特征向量选取
以综合录井参数作为神经网络模型建立的输入向量,通过隐藏层一系列非线性变换,得到了在输出层中不同钻井工况的概率。所有预测的钻机工况中,概率最大的工况就被判定为当前预测的工况。由于综合录井参数繁多,如果将所有参数作为独立输入特征向量,神经网络系统将是巨大的(输入特征冗余)。因此,凭借现场专家经验(先验知识)与笔者实习经历,根据各个录井参数对钻井工况识别的重要性影响程度,减少对综合录井参数的选取来降低输入向量的维度。2018年,Yin Qishuai等[8]证实采用最常用、最重要的8个综合录井参数(实时钻头深度、井的测深、大钩高度、钻压、悬重、扭矩、转速和立管压力)足够判别旋转钻进、滑动钻进、接单根、静止、循环、向下洗井、划眼、向上洗井、倒划眼、起钻、下钻和“其他”等12种钻井工况。因此,本节的LSTM网络由上述8个综合录井参数作为输入特征向量,上述12种钻井工况作为输出向量。
2.2 样本集统计分析
来自多个传感器的高速率时间序列数据流被综合录井仪采集,频率是1 Hz(每秒采集一次),用于工况判别的样本集如表2所示。
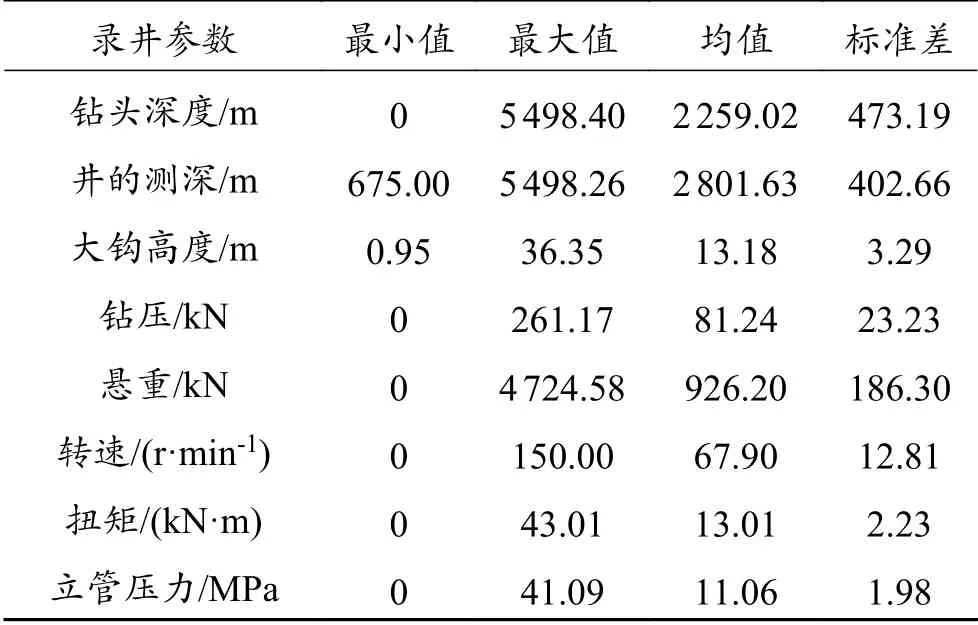
表2 样本数据集统计分析Table 2 Statistical analysis of sample data set
每个钻井时刻对应的钻井工况作为网络训练的输出,但在综合录井数据集中无法获得钻井工况状态。因此,模型训练前必须参考钻井日报手动标记钻井工况。用于分类任务的12个钻井工况的数据分布与数据标签见表3,可见滑动钻进、静止、向下洗井3种钻井工况的数据量分布小于5%,属于不均衡分类问题,后续需分析召回率(Recall)。
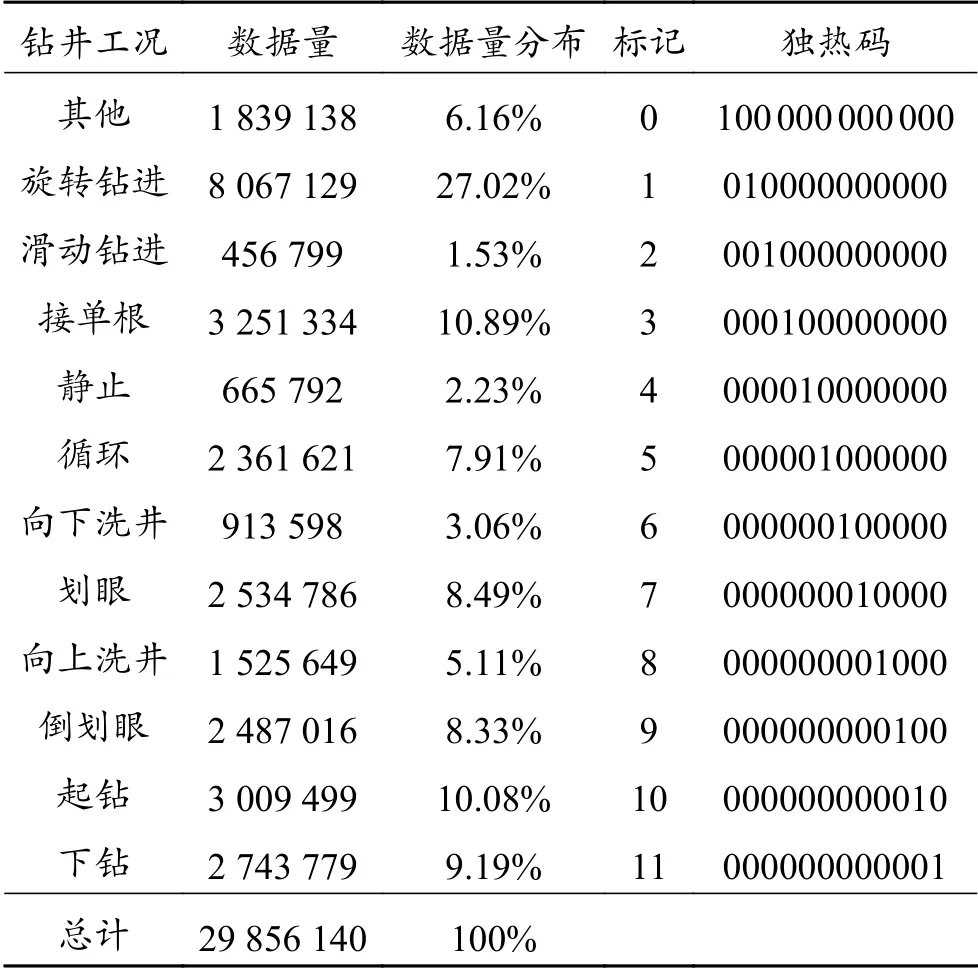
表3 12种钻井工况的数据量分布和独热码Table 3 Data bulk distribution and one-hot code of 12 conditions
本节所用的深水综合录井数据样本集总数为29856140行,其中75%为训练集,25%为测试集。11种典型钻井工况的人工标定法则见表4,其余深水综合录井数据对应钻井工况标记为“其他”。

表4 11种典型钻井工况的标记规则Table 4 Marking rule of 11 typical drilling conditions
3 长短期记忆神经网络设计
3.1 长短期记忆神经网络隐藏层设计
输入层和输出层的神经元数目分别等于输入特征(综合录井参数)和输出特征的数目。神经网络的隐藏层与每层节点个数至关重要但难以确定。通常,隐藏层越多,节点越多,预测的正确率越高,甚至可接近100%。但这样会导致“过拟合”问题,对测试集预测效果降低。实际应用中,使用最多的是具有10~30隐藏层的神经网络模型。本文测试了具有10、20、30隐藏层的神经网络模型,每个隐藏层的神经元数在10~100之间,共测试了30个LSTM模型,从图3结果可以看出,20隐藏层×70节点的神经网络测试集上正确率最高,高达94.09%。因此,最终选定了20隐藏层×70节点神经网络,其结构如图4所示。LSTM模型的超参数结构细节见表5。

表5 最佳LSTM模型的超参数和网络结构Table 5 Super parameter and network structure of optimal LSTM model
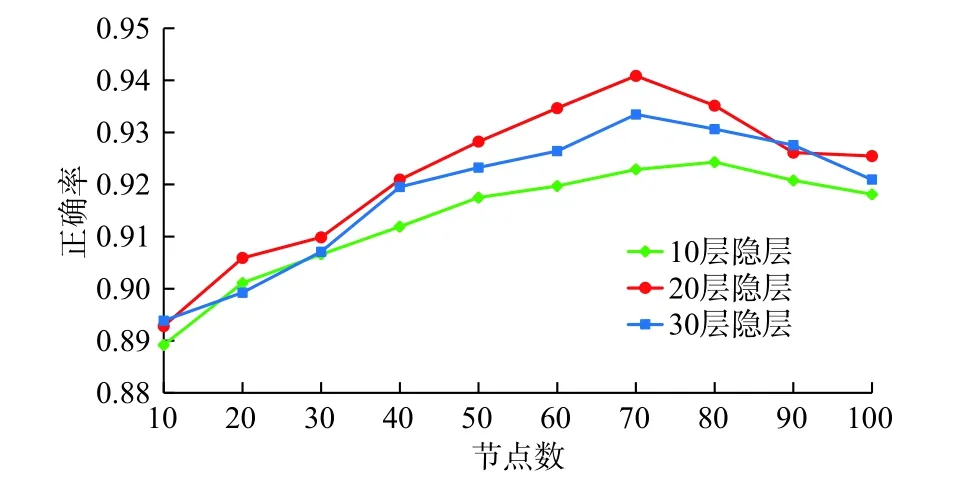
图3 不同隐藏层及节点的LSTM测试集上的正确率Fig. 3 Accuracy on LSTM test set at different hidden layers and nodes
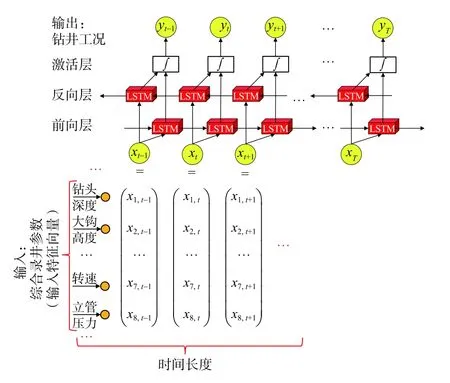
图4 基于LSTM的钻井工况智能判别模型Fig. 4 LSTM based intelligent drilling condition recognition model
3.2 移动窗口长度设计
现场实际作业中,由于传感器采集到的综合录井数据的波动,导致钻井工况判别结果不稳定,甚至产生不可控的误差。例如,有时会在短短30 s之内判别出多种钻井工况,这显然是不现实的也是错误的。移动窗口(Moving Window,MW)被引入来“ 平滑”处理预测结果,以避免由于输入数据的震荡波动导致的预测误差。因此,当前的钻井工况不仅仅是由当前的数据点决定的,也是由在该点之前的MW−1个数据点综合决定的,当前数据点的实际钻井工况是在整个移动窗口期间中频率最高的工况。此外,该移动窗口以数据采集的速率(本文1 Hz)往前移动,以执行下一数据点的钻井工况判别。本文中,移动窗口长度从10至60,每“5”间隔分别进行测试,结果如图5所示,可见正确率从10至30增加,从30至60开始减少。因此,最终数据窗口的长度选为30,符合现场作业要求。
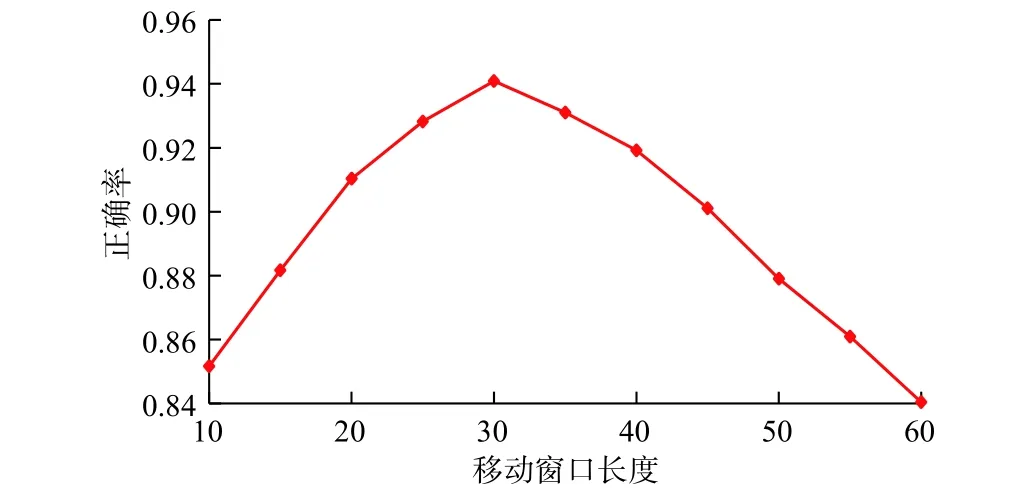
图5 不同移动窗口长度的LSTM网络测试集上正确率Fig. 5 Accuracy on LSTM test set at different moving window lengths
4 长短期记忆神经网络训练及性能评估
4.1 长短期记忆神经网络学习训练过程
使用图4和表5所示的神经网络结构,采用5-折交叉验证,每次训练持续100次迭代,LSTM网络通过Adam优化算法进行训练,然后计算评价指标。
不同迭代的正确率(Accuracy)与损失(Loss)如图6所示,可看出在100次迭代过程中,训练集上和测试集上的正确率都显著提高,最后训练集与测试集的正确率分别为95.41%和94.09%,损失分别为0.00015和0.000193。在迭代训练过程中,训练集上的正确率与损失,与测试集趋势是一致的,充分证明该模型“过拟合”不显著,泛化能力较好。

图6 迭代过程正确率与损失Fig. 6 Accuracy and loss of iterative process
4.2 长短期记忆神经网络混淆矩阵
利用混淆矩阵展示LSTM网络总体性能指标,结果如图7和表6、7所示。图7中水平坐标与垂直坐标分别表示预测的与实际的上述12种钻井工况的结果。图7(a)和表6所示训练集上滑动钻进、静止、向下洗井3种钻井工况的召回率(Recall)分别高达0.94、0.95、0.96;从图7(b)和表7可看出,测试集上的该3种钻井工况的召回率(Recall)分别为0.93、0.95、0.94,虽然较在训练集上略有降低,但仍然较高(大于0.93)。整体上,神经网络的正确率很高,且训练的LSTM网络在测试集上具有很好泛化能力。此外,完成一个样本的预测时间不到50 ms,远小于实时数据采集频率(1 Hz),实现了“实时”判别,为LSTM模型部署并应用于实时钻井数据的工况判别提供了时效保障,如此迅速的运算速度,符合工程实际情况,满足钻井工程的需要。
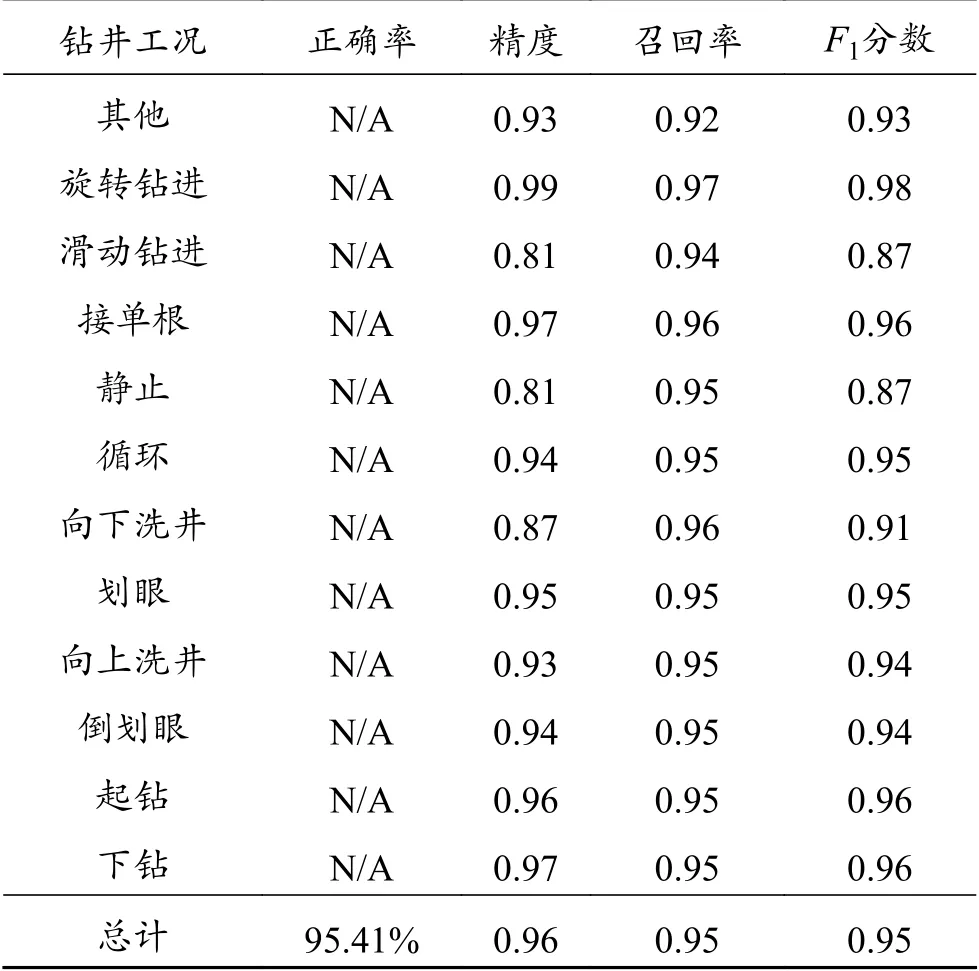
表6 训练集上的LSTM网络性能指标Table 6 LSTM performance indicator of training set
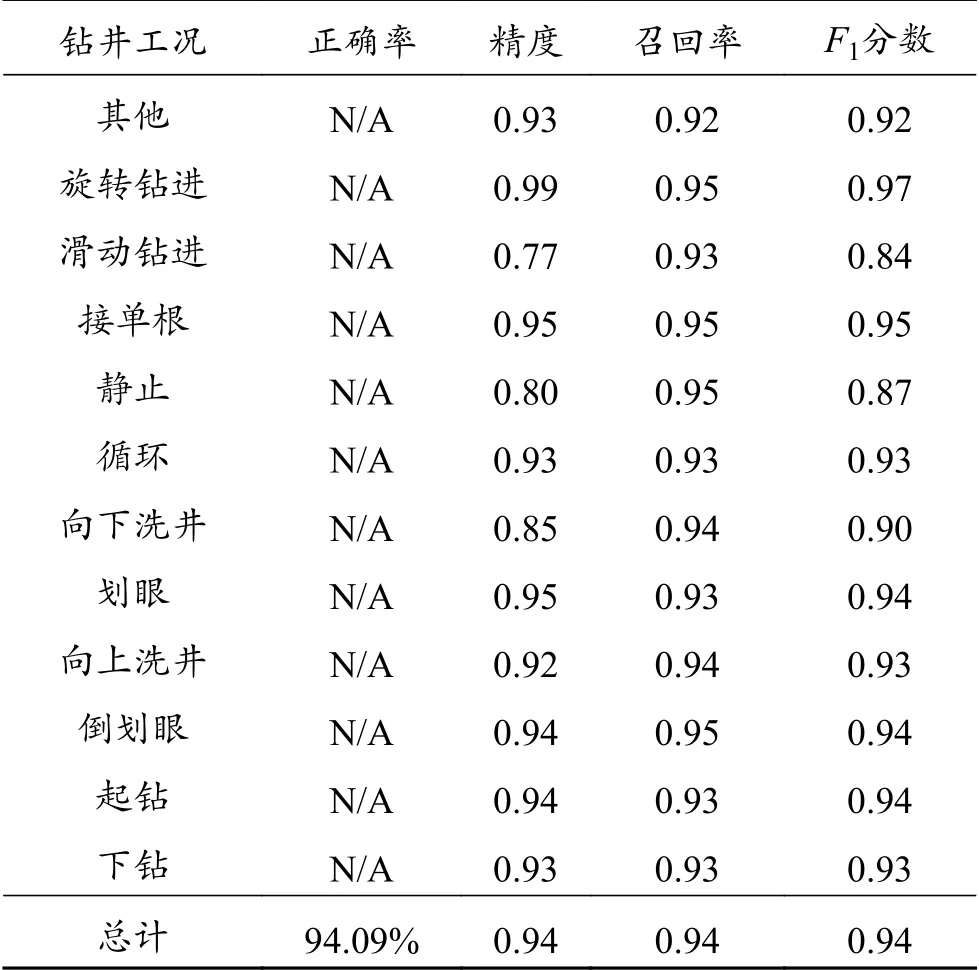
表7 测试集上的LSTM网络性能指标Table 7 LSTM performance indicator of test set

图7 LSTM网络的混淆矩阵Fig. 7 Confusion matrix of LSTM
5 结论
(1) 开展了BP、传统RNN、LSTM网络3种算法的结构深度剖析与算法原理对比分析,LSTM网络展现了在处理长时间序列高维度非线性复杂映射关系的独特优势,为深水钻井工况实时智能判别提供了算法基础。
(2) 由8个综合录井参数(钻头深度、井深、大钩高度、钻压、悬重、转速、扭矩和立管压力)作为输入特征向量,建立了20隐藏层×70隐节点的LSTM网络模型,实现了旋转钻进、滑动钻进、接单根、静止、循环、向下洗井、划眼、向上洗井、倒划眼、起钻、下钻和“其他”等12种典型钻井工况的实时智能判别,测试集上的精度达到94.09%,为后续钻井时效分析和复杂事故预警提供了机器学习模型基础。
(3) 提出了基于长短期记忆神经网络的深水钻井工况实时智能判别全流程,为研究深水钻井过程中其他分类问题提供了借鉴,并鼓励读者在类似研究中借鉴本文的研究思路。
猜你喜欢
中华养生保健(2020年7期)2020-11-16 01:14:26
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
录井工程(2017年3期)2018-01-22 08:39:51
数学物理学报(2017年5期)2017-11-23 07:51:31
录井工程(2017年1期)2017-07-31 17:44:30
录井工程(2017年4期)2017-03-16 06:10:53
家教世界·创新阅读(2016年11期)2016-12-27 18:49:15
天津护理(2016年3期)2016-12-01 05:40:01
故事会(2016年15期)2016-08-23 13:48:41
