
基于改进GBDT算法的农产品冷链物流资源需求预测的研究
2022-07-06 03:57黄成明胡坚
中国储运 2022年7期
文/黄成明 胡坚
随着“互联网+”的不断发展,农产品电商发展迅速。但当前农产品冷链物流面临调度效率低下问题,这不但对企业效益造成损失,还会引发农产品健康安全问题,如何提升农产品冷链物流智能化程度,是全社会亟需解决的问题。针对上述问题,本文提出了一种基于改进GBDT(Gradient Boosting Decision Tree,梯度提升决策树)算法的农产品冷链物流资源需求预测模型,创新性的提出了一种新的-Huber损失函数,能在提高收敛速度的同时,降低对异常值的惩罚,从而提高预测精度。通过实验证明该模型能对物流节点的需求进行精准预测。
引言。
近年来,随着消费升级步伐的加快,农产品质量的新鲜与健康,成为消费者对农产品选购的主要要求。而传统以地区为主的农产品运输、销售与保存模式,会在基础物流环节损失25%~30%的经济利益,大量保鲜期短的肉类、含水量高的蔬果等农产品在物流运输过程中腐烂变质,对广大人民的利益造成损失、健康造成威胁。在此背景下,农产品流通对冷链物流的要求和依赖越来越高。在引入专业的农产品冷链物流储藏设备的基础上,还要不断研发新技术,不断形成与优化冷链物流建设体系,以保障农产品在物流运输中的新鲜、健康与安全。
1.研究现状。
随着近年来移动互联网的崛起和大数据技术的发展,在房价预测、各电商平台销售额预测、电影票房预测、人口增长分析等问题上预测算法具有很高的预测精确度和泛化能力。当前,在需求预测上主要采用的算法有线性回归、时间序列算法、BP神经网络算法、GBDT算法等。而GBDT算法在实际应用中由于表现出突出的预测精确度和泛化能力,被业界使用最为广泛,在改进GBDT算法方面的相关研究也一直在进行。有研究者提出了一种改进GBDT算法,即使用多棵决策树和Boosting算法结合弥补单棵决策树算法的缺陷,有效的提升了分类的精确[1];贵州大学电气工程学院的学者基于LightGBM梯度提升框架结合histogram决策树算法寻找决策树的最优分割点应用于短期负荷预测和数据挖掘领域,有效提高了预测精度和运行速度[2];华北电力大学的研究者将灰色投影法和GBDT算法结合创造了PG相似日选法用于解决在天气因素导致的光伏发电功率预测不准确问题,同时提升了算法的预测精度和防止过拟合的能力[3];广西大学的研究者提出了一种在随机森林算法和GBDT算法的基础上构建的RF-GB算法,并与多因子模型相结合,一定程度上提升了GBDT算法的性能[4]。
2.GBDT算法原理。
梯度提升树GBDT算法属于集成学习,是拟合残差作为提升树,并将多个弱学习器进行线性组合的加法模型。而在基学习器的选取上,梯度提升树GBDT算法以决策树作为基分类器,而其中C4.5、ID3、CART是三种较为常见的决策树算法,且由于CART(Classification and Regression Tree)算法具有无需进行特征标准化、可以不必计算特征之间的相关性而自动挑选特征进行训练,故通常以CART算法作为GBDT算法的基学习器。CART回归树的生成过程是以损失函数的最小化为衡量标准,假定数据集为
其中和分别表示样本空间中的输入和输出变量。我们将样本空间分为训练集和测试集后,递归地将训练数据集的输入空间划分为两个子区域,计算每个子区域的输出值,构建出一颗决策树。在这个过程中,通常以平方损失函数作为选择最优切分变量j与切分点s的依据,通过求解:

其中,c1、c2分别为训练数据集的两个子区域R1、R2的均值。找到使式(1)取最小值的参数(j,s),即为最优的切分变量j与切分点s。使用(j,s)进行区域划分并计算对应的子区域的输出值,迭代这个过程,直到达到误差最小或树的深度满足停止条件时结束,最终生成决策回归树。GBDT算法首先初始化弱学习器,再对每个样本计算负梯度即残差,并将残差作为样本新的真实值构成新的训练数据进行训练,由此得到一棵新的回归树。由于GBDT算法在迭代过程中拟合的是负梯度,所以使用CART回归树作为基学习器。然后对该回归树叶子区域计算最佳拟合值并更新强学习器得到最终学习器。最终学习器表达式为决策树的加法模型:

其中f(x)为梯度提升树函数表达式;I为决策回归树函数表达式,由拟合残差计算得到;Rm为样本空间;cm为样本空间中输入样本xi对应的输出yi的均值;M为决策回归树的棵数。GBDT是一种提升思想的算法,可以应用于分类问题和回归问题。在实际中采用此算法时主要有三个难点问题,第一是每次学习得到一个基学习器后,在下一次迭代前需要考虑改变样本的权重;第二是如何计算基学习器的权重并累加成为强学习器;第三是如何选取合适的损失函数。本文主要解决第三个问题,提出一种改进的损失函数以提升GBDT算法的预测精度。
3.基于-Huber损失函数改进GBDT算法
为了提高算法的鲁棒性,降低异常值对损失函数的影响,1964年P.J.Huber等人提出了Huber损失函数,其定义如下:
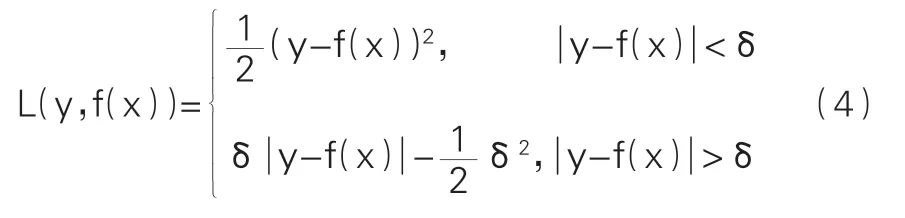
其中参数δ是一个非负数,当样本值和预测值之差的绝对值即残差小于该参数时,Huber损失函数即为平方损失函数,当残差大于等于该参数时,Huber损失函数即为平均绝对误差,这是两个常用的损失函数的表达形式。因此,Huber损失函数兼具了两者的优点。本文基于γ-Huber损失函数改进GBDT算法,即在构建GBDT算法的决策回归树的过程中,使用γ-Huber损失函数作为选择最优切分变量j与切分点s的依据。此时,在式(1)所表示的数据集下,我们需要求解表达式(6):

通过式(6)求得最优切分变量j与切分点s,生成GBDT算法中的决策回归树。
4.冷链物流需求预测与结果分析。
本文将在农产品冷链物流的资源需求预测上使用基于-Huber损失函数的改进GBDT算法。通过采集物流节点的农产品冷链物流历史数据,进行数据清洗、特征工程、建立模型、需求预测等步骤,对物流节点未来一段时间内的资源需求进行预测分析。本文通过爬虫等多种方式采集了某物流节点马铃薯产品相关数据,数据集包含了疫情状况、产品价格、产量、气候、历年各月份产品物流量等数据。其中历年各月份产品物流量数据作为数据集中的标签数据,在数据清洗阶段我们取多个年份的产品物流量数据的平均值作为标签数据。为了验证本文提出方法的有效性,本文在构建GBDT算法的决策回归树过程中使用-Huber损失函数并取不同的值进行实验,实验获得参数γ取不同值时GBDT算法的预测准确率如表1所示。

表1参数取不同值时GBDT算法的预测准确率
在具有相同的决策回归树深度时,实验结果表明,-Huber损失函数改进GBDT算法在预测效果上有较高的预测准确率,且随着参数的取值不同而略有不同,在参数取值为1时具有较好的预测效果。
5.结语。
我们在本文中提出了一种新的可以降低传统平方损失函数惩罚的-Huber损失函数并基于此损失函数对GBDT算法进行了改进。通过采集冷链物流节点的物流商品数据,并利用基于-Huber损失函数的改进GBDT算法对数据进行训练。最后算法模型预测结果显示,基于-Huber损失函数的改进GBDT算法在有异常值的情况下能明显降低损失函数对异常值的惩罚强度且具有更优的预测效果和算法鲁棒性。
猜你喜欢
中国储运(2022年6期)2022-06-18
物流技术与应用(2022年5期)2022-06-17
上海理工大学学报(2021年3期)2021-07-20
消费导刊(2020年41期)2021-01-27
软件(2020年3期)2020-04-20
上海节能(2020年3期)2020-04-13
电子制作(2018年16期)2018-09-26
电子制作(2017年24期)2017-02-02
专用汽车(2016年5期)2016-03-01
决策与信息·下旬刊(2013年1期)2013-03-11
