
基于纵向联邦学习的社交网络跨平台恶意用户检测方法
2022-07-06 14:30卫新乐张志勇毛岳恒班爱莹
小型微型计算机系统 2022年7期
卫新乐,张志勇,宋 斌,毛岳恒,班爱莹
(河南科技大学 信息工程学院,河南 洛阳 471023) (河南省网络空间安全应用国际联合实验室,河南 洛阳 471023)
1 引 言
随着在线社交网络(Online Social Networks,OSNs)的飞速发展,截至2020年3月,第45次《中国互联网发展状况统计报告》显示,OSNs用户规模达到9.04亿,互联网普及率达64.5%,2020年第1季度微博、微信,月活跃用户分别达到了5.5亿和12.03亿人次.因此,OSNs帮助人们在建立社会性网络应用服务的同时,也逐渐成为恶意用户试图执行非法活动和恶意危害的首要目标[1].恶意用户会潜伏在多个OSNs平台中,试图窃取用户隐私、发布虚假信息、渗透政治话题等[2-4],这些恶意行为给当今社会造成了不良的影响和巨大的危害.目前,大多数研究人员利用传统的机器学习方法,如半监督聚类、支持向量机的分类器等,通过对恶意用户行为特征进行提取和训练,在OSNs平台取得了高质量的检测效果.如Shi等人[5]提出了一种基于空间和时间特征的恶意用户检测算法;WU等人[6]提出了一种基于多类特征的混合算法,利用大规模的特征数据构建不同分类器,实现高效率的检测.然而,这些传统机器学习方法的成功应用,都是建立在社交大数据基础之上的,而在实际应用场景中,恶意用户具有分散性,潜伏性、复杂性等特征,单方的数据很难满足检测要求,需要双方乃至多方的数据联合进行训练,方达到令人满意的检测效果;其次,随着法律法规的健全,重视用户隐私和数据安全已经成为世界性的公认趋势,如欧盟颁布的《通用数据保护条例》(General Data Protection Regulation,GDPR)[7]中规定,未经用户同意,擅自将各方用户数据集中到一处已经被明令禁止.因此,如何在大数据场景下,确保用户数据安全和隐私保护[8],毫无疑问是OSNs中一个重要的研究课题.
在此背景下,联邦学习(Federated Learning)应运而生,各参与方不披露底层数据,以一种加密的参数交换方式共建模型,保障了用户的数据安全和隐私保护.联邦学习最先由谷歌的McMahan等人提出,用来解决移动设备上语言预测模型的更新问题[9-11].由于移动设备大多存有用户的隐私数据,为防止模型更新过程的用户隐私泄露,谷歌的研发人员设计了基于联邦学习的Gboard系统[12,13].如文献[11]提出了联邦平均(Federated Averaging)的概念,使得所有移动设备的数据都能被有效利用,从而不断优化联邦模型.文献[12,13]采用了一种隐私保护方法(同态加密)对移动设备上的模型进行加密训练,防止模型训练中发生隐私泄露等问题.在此基础上,Yang等人[14]针对联邦学习中数据分布的特点,将联邦学习分为按数据样本划分的横向联邦学习(Horizontal Federated Learning,HFL)、按数据特征划分的纵向联邦学习(Vertical Federated Learning,VFL),Cheng等人[15]提出了一种适合纵向联邦学习的安全联邦提升树算法,其具备与传统机器学习方法相同的精确度.
针对上述联邦学习机制的研究,本文提出了一种以纵向联邦学习为核心的社交网络跨平台恶意用户检测方案:1)搭建了基于纵向联邦学习的社交网络跨平台恶意用户检测层次化架构,建立了数据预处理层、样本对齐层、联邦学习层、数据应用层等多层次应用架构;2)对安全联邦提升树算法进行分析和改进,提出了一种面向多方隐私保护的恶意用户检测算法;3)依托实际应用场景CyVOD对实验进行了仿真和验证.
2 社交网络跨平台恶意用户检测层次化架构
为确保用户数据安全和隐私保护,同时联合多方数据实现对恶意用户的精确检测,本文构建了数据预处理层、样本对齐层、联邦学习层、数据应用层,搭建了基于联邦学习的社交网络跨平台恶意用户检测层次化架构,具体的层次化架构如图1所示.
1)数据预处理层
数据预处理是建模过程中非常关键的一环,在实际应用场景中由于具体功能需求、技术水平、存储方式等原因,各参与方数据不是以结构化的形式存在,因此,本文在数据预处理层中设定了一个有效的问题处理机制,采用数据清洗、随机采样、数据分箱、数值归一化等预处理操作,保障了模型训练过程的鲁棒性.本文采用的有效的问题应对机制具体如下:①出现重复、缺失等问题,对样本数据采用删除法、填补法等操作进行处理;②出现分布不均衡时,对样本数据进行随机采样处理,提高模型预测和分类效果;③出现连续型特征变量时,对样本数据采取分箱处理,即对连续性特征变量采取离散化处理,增加模型的稳定性;④出现数据维度差异明显时,对样本数据进行归一化处理,提升模型训练速率和收敛方向.
2)样本对齐层
样本对齐层是指各参与方建模前,使用一种加密的ID匹配技术,保障用户数据安全和隐私保护前提下,对齐各参与方共有用户.本方案采用RSA非对称加密算法和哈希机制的安全求交集方案[16],来提取各参与方共有样本数据.
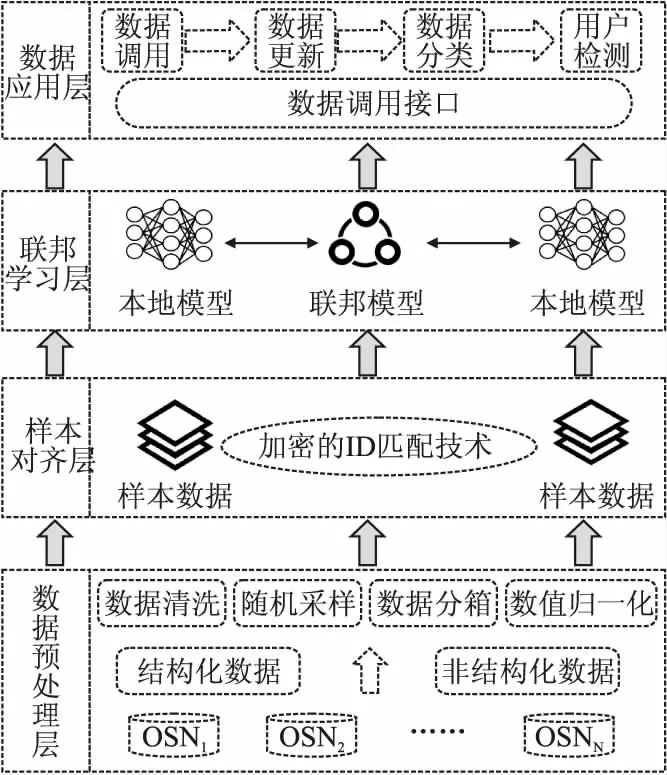
图1 社交网络跨平台恶意用户检测层次化架构Fig.1 Hierarchical architecture of cross platform malicious user detection in social networks
3)联邦学习层
联邦学习层是指通过一种加密的参数交换方式进行模型训练,如图2所示,各参与方在确定双方共有样本后,在机器学习定义下可以协同训练一个全局模型,但是,为了防止模型训练中存在的隐私泄露问题,联邦学习层需要引入可信的协作方,利用隐私保护技术(如同态加密)对样本数据加解密并协调训练过程.具体步骤为:
步骤1.协作方生成密钥对,并将公钥发送给对各参与方,各参与方对样本数据进行加密处理;
步骤2.各参与方以加密的参数交换方式计算中间结果,中间结果被用来计算梯度和损失值;
步骤3.各参与方将计算加密的梯度和损失值并上传给协作方;
步骤4.协作方利用私钥将梯度和损失值解密,并将这些梯度信息回传给各参与方,各参与方根据这些梯度信息更新当前的模型参数.
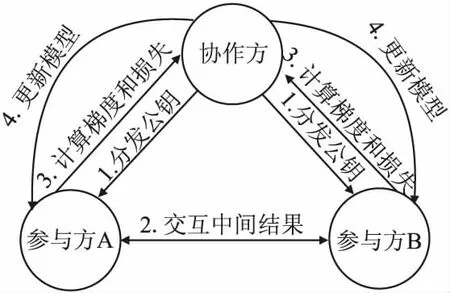
图2 联邦学习训练过程Fig.2 Federated learning training process
4)数据应用层
经联邦学习层训练后,各参与方更新本地训练模型参数,将预测结果进行输出.此时,数据应用层通过封装的数据调用接口,将预测结果回传到终端设备,终端设备对本地数据进行更新和分类,并为恶意用户提供检测依据.
3 面向多方隐私保护的恶意用户检测算法
本文将各参与方建模过程中存在隐私泄露的数据称为敏感数据,为确保敏感数据安全,本文在社交网络跨平台恶意用户检测层化架构中构建了一种面向多方隐私保护的恶意用户检测算法,该算法对安全联邦提升树算法进行分析和改进,采用加法同态加密对敏感数据进行加密处理,保证各参与方在不暴露彼此数据便可进行多方训练.同时,在目标函数中引入了正则化惩罚项,有效的提升了模型的泛化能力和检测效果.为区分算法中各参与方扮演的角色,分别定义为主动方(ActiveParty)和被动方(Passive Party).
定义1.主动方:提供用户的样本数据和标签值,并在训练过程中扮演协作方的角色,参与对敏感数据的加解密和协调训练过程.
定义2.被动方:一般只提供用户的样本数据,仅为数据提供方.
3.1 算法实现过程
本文设定算法目标函数为损失函数与正则化惩罚项之和,引入正则化惩罚项目的是控制模型的复杂度,防止出现过拟合的现象,使得算法在求解过程中更具分类效率,则目标函数为:
(1)
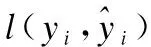

(2)
此时,将公式(2)带入公式(1)中,展开的目标函数如式(3)所示:
(3)

(4)
而本文设定算法的正则化惩罚项函数如式(5)所示:
(5)
其中,γ为复杂度参数、T为叶子节点数、λ为叶子节点权重值w的惩罚度参数.因此,将公式(5)代入式(4)后,可将目标函数进一步展开为如式(6)所示:
(6)
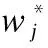
(7)
(8)
样本空间I的每一次划分后,都会将当前节点的样本划分为两个不相交的样本空间,设定IL,IR分别为左右节点的样本空间,IR+IL=I表示当前节点的总样本空间.因此,左右节点的一阶梯度之和、二阶梯度之和,如式(9)所示:
(9)
最后,为求得样本空间I的最优划分,我们利用每一次节点分裂后的值减去分裂前的值,找到其最大值,则最优划分如式(10)所示:
(10)
3.2 恶意用户检测算法
由上述算法实现过程可以看出,每一次迭代目标函数t的过程,通过求解损失函数l关于前t-1棵树的预测结果y(t-1)的一阶导数gi和二阶导数hi,并根据gi和hi,来获取最优权值和最优划分.因此,我们不难发现,最优权值和最优划分的计算依赖于gi和hi,而gi和hi计算依赖于样本中的类标签yi,如果训练过程中直接将gi和hi进行交换,存在隐私泄露的风险,所以,本文算法设定gi和hi必须由主动方计算得到,并使用加法同态加密将gi和hi加密,使得被动方在训练过程无法利用导数信息推出标签信息.算法流程如图3所示,具体的算法过程如下:

图3 恶意用户检测算法流程Fig.3 Malicious user detection algorithm flow
1)主动方首先计算梯度值gi和hi,i∈{1,…,N},其中N为样本个数,并使用加法同态加密对其加密,然后将加密后的gi和hi发送给被动方.
2)被动方首先对当前的所有特征进行分桶,并将每个特征值映射到每个桶中;其次,被动方根据分桶后的特征值,将相应的加密梯度信息进行聚合,并将聚合结果Gd,v和Hd,v发送给主动方.
3)主动方对接收的聚合结果Gd,v和Hd,v进行解密,获取当前节点的最优划分Dividemax,并返回当前的节点特征ID和阈值ID给被动方.
4)被动方接收特征ID和阈值ID对当前样本空间I进行划分,记录当前的记录ID、特征ID以及阈值ID,并将记录ID和划分后左侧样本空间IL发送给主动方.
5)主动方根据记录ID和IL对当前节点进行划分,并进入下一节点的划分.
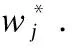
7)训练完成后,主动方将当前节点的记录ID和特征的阈值发送给被动方.
8)被动方比较当前的阈值结果,得出搜索决定,并将搜索决定发送给主动方.
9)主动方接收到搜索决定,开始前往相应子节点.
10)迭代7)-9)过程,直至到达每一个叶子节点得到分类标签和权值,并将遍历的类标签加权求和,输出正常用户和恶意用户的类标签集合.
算法1.恶意用户特征划分算法
输入:样本个数N,样本空间I,特征维度D,加密的一阶梯度{[[gi]],[[hi]]}i∈I
输出:样本空间I的划分
1.Begin
2.PassivePartyExecution:
3. ford=1 toDdo // d为用户特征id
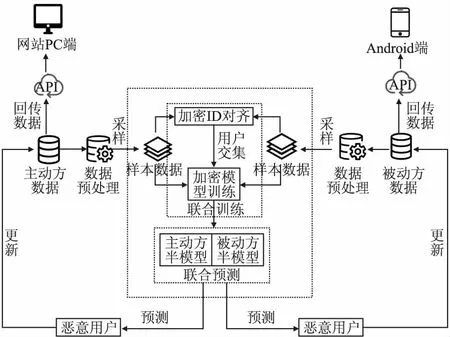
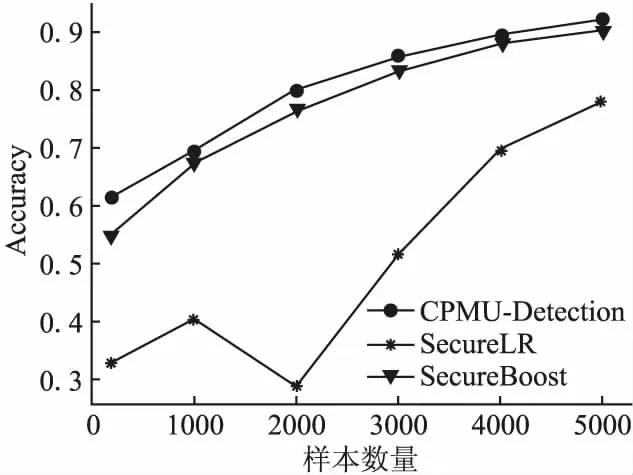
4. 根据特征d的百分位数,得到划分集合Sd={sd1,sd2,…,sdl}//Sd为划分点的候选集合
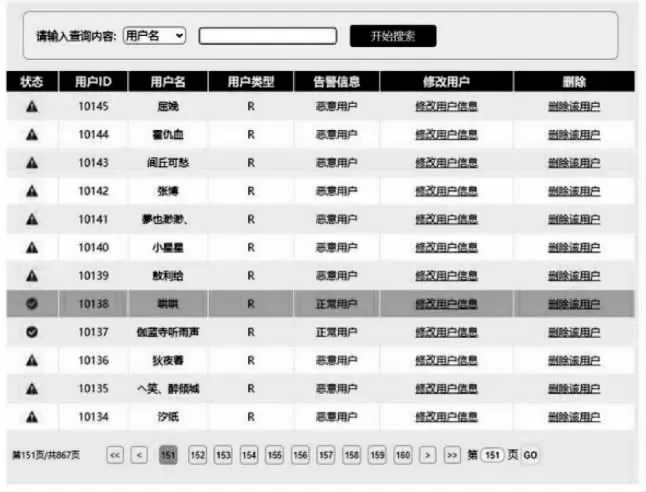
5.Gd,v=∑[[gi]]wheresd,v-1 6.Hd,v=∑[[hi]]wheresd,v-1 7.endfor 8.ActivePartyExecution: 10. fori1 toNdo //遍历所有参与方 11. ford= 1 toDido //遍历参与方i的所有特征 12.GL←0,HL←0 13. forv=1 tolddo //遍历特征d的阈值 16.GR←G-GL,HR←H-HL 18.endfor 19.endfor 20.endfor 21.当得到最优划分时,返回特征id和阈值id给被动方 22.PassivePartyExecution: 23.根据特征id和阈值id确定选中特征的阈值,并划分当前的样本空间I 24.End 本文搭建的基于纵向联邦学习的社交网络跨平台恶意用户检测框架,依托于多媒体社交网络平台CyVOD[17]的Android移动端和PC网站端为实际应用场景,其中Android移动端为主动方、PC网站端为被动方,实验环境使用两台服务器(CentOS 7.7 (Core)×2,Intel(R) Xeon(R) Gold 5118 CPU,32GB RAM),模拟实验的各参与方,其中选取一台服务器作为主动方和协作方,平台底层使用docker-compose+kubefate1.4为底层架构.具体检测框架如图4所示,负责对数据预处理、加密样本对齐、加密模型训练以及数据输出、终端应用等过程. 图4 社交网络跨平台恶意用户检测框架Fig.4 Cross platform malicious user detection framework for social networks 本文选取CyVOD的Android移动端和PC网站端为参与双方,在此基础上搭建了社会情景元数据(视频、政策、指南、通知、帖子、虚假信息)实验研究平台(1)http://www.sigdrm.org/socialmetadata/,提取Android端、PC端的用户行为特征、内容特征、传播特征,共68个用户点击动作,PC端28个用户静态属性特征52982条数据,Android端40个用户动态属性特征1150465条数据,共计1203447条数据.评估指标采用ROC曲线(受试者工作特征曲线)、AUC值(Area Under ROC Curve)和精确度ACC(Accuracy),3个指标评估模型性能,使用真正例率(Ture Positive Rate)、假正例率(False positive Rate)为横、纵坐标轴,AUC值为ROC曲线下的面积,ROC曲线越凸AUC值越大,代表模型性能越好,ACC值表示预测值和真实值符合的程度,并根据样例的真实类别与预测类别可以划分为TP(Ture Positive)、FP(False Positive)、TN(Ture Positive)、FN(False Negative)4种类型,其ROC、ACC的计算公式为: (1) (2) (3) 4.2.1 特征重要性分析 本文搭建的基于纵向联邦学习的社交网络跨平台恶意用户检测层次化架构,选取Android移动端和PC网站端的用户行为特征、内容特征和传播特征进行实验,通过加密机制聚合双方或多方提供的多维度特征进行模型训练,以达到更好的建模效果.如图5所示,各参与方建模过程中用户特征的重要性分析,其中Android移动端的用户特征变量X3、X1、X0、X2为模型贡献度的前4个变量,分别代表用户对虚假信息的分享、点赞、收藏、评论的点击数;PC端的用户特征变量X4代表用户的积分信用值,X9、X6、X5、X2分别表示用户对视频、政策、指南、通知的分享操作. 图5 用户特征重要性分析Fig.5 Importance analysis of user characteristics 4.2.2 准确性分析 为验证提出的社交网络跨平台恶意用户检测(Cross-platform malicious user detection,CPMU-Detection)模型的准确性,本文从PC网站端、Android移动端的数据集中随机选取了1000、2000、3000、4000、5000条记录分别进行实验,选取3/4的数据作为训练集,1/4的数据作为测试集,实验设定学习率为learning_rate=0.05,树的最大深度为max_dept=5,迭代次数为bin_num=50,正则化惩罚项为penalty=L2,加密方式为同态加密,同时引入具有联邦思想的基线模型进行对比,即安全联邦逻辑回归(Secure federated logistic regression,SecureLR)模型[18]、安全联邦提升树模型(Secure federated tree-boosting,Secureboost),实验结果如图6所示,可以看出在不同样本数量下本文提出的CPMU-Detection模型均优于其他基线模型,当样本数量增加至5000时,准确率为92.04%,相比较SecureLR模型、Secureboost模型,准确率分别提升了14.03%和1.918%,因为SecureLR模型在训练过程中需要引入第3方(云服务器)协调训练过程,当样本数量为2000时,各参与方交互过程复杂,导致精确率下降,而本文所使用的模型,封装是一种端到端的梯度提升树算法,无需第3方的加入,从而明显提升效果,对比同样采取无第3方的Secureboost模型,本文在模型中加入了正则化惩罚项,有效的提升了模型的泛化能力和准确率. 图6 3种模型检测结果的准确率Fig.6 Accuracy of three models 为了更明显地看出CPMU-Detection模型的检测能力,如图7所示,使用ROC曲线、AUC面积评判不同算法对应的模型性能,可以看出本文采用的CPMU-Detection模型,ROC曲线明显往左上角凸,且AUC面积最大,表示该模型的分类结果越好.最后,我们在CyVOD平台部署并运行基于纵向联邦学习的社交网络跨平台恶意用户检测程序,PC网站端和Android移动端在保证双方用户数据安全的前提下,联合双方共同建模实现了社交网络跨平台恶意用户的精准检测.如图8所示,PC网站端管理员可及时处理恶意用户,对检测的恶意用户进行标记处理,从而进一步维护了OSNs的生态网络质量. 图7 3种模型的ROC曲线图Fig.7 ROC curves of three models 4.2.3 安全性分析 为确保CyVOD的PC网站端和Android移动端建模阶段的用户数据安全和隐私保护,本文假设其中一方为半诚实抑或诚实但好奇的参与方,参与方诚实地遵守协议,但也会试图从接收到的信息中学习除输出以外更多的信息.而往往发生隐私泄露经常在模型训练阶段,在此阶段参与方可抽取训练数据或训练的特征向量推断出涉及用户隐私的敏感信息. 图8 PC网站端恶意用户检测结果显示页面Fig.8 Malicious user detection results display page on PC website 表1 双方持有的敏感数据Table1 Sensitive data held by bothparties OSNs的迅速发展,逐渐成为了恶意用户试图执行非法活动、恶意危害社交网络所承载生态环境的首要目标.为实现对恶意用户的精确检测,本文提出了一种以纵向联邦学习为核心的社交网络跨平台恶意用户检测方案,该方案通过构建数据预处理层、样本对齐层、联邦学习层、数据应用层等层次化架构,提出了一种面向多方隐私保护的恶意用户检测算法,切实保证了模型的准确性和用户隐私的安全性,最后通过在CyVOD实现了仿真和应用.然而,该方案中为防止用户隐私泄露,往往需要各参与方之间更为紧密和直接的交互,训练过程中容易发生崩溃,未来考虑使用一种更加灵活、高效的隐私保护方案,如可信执行环境(Trust Execution Environment,TEE)[19],保证机密性和完整性的前提下,能够容忍发生崩溃的容错机制.4 实 验
4.1 数据集和评估指标
4.2 实验结果与分析



5 结束语
猜你喜欢
全国流通经济(2020年6期)2020-06-19电脑爱好者(2020年6期)2020-05-26会计之友(2019年1期)2019-03-06中国计算机报(2018年30期)2018-11-12价值工程(2018年21期)2018-08-29课堂内外(小学版)(2017年5期)2017-06-07中国房地产·学术版(2016年7期)2016-10-21
