
Two-Machine Hybrid Flow-Shop Problems in Shared Manufacturing
2022-07-04 05:43:02QiWeiandYongWu
Qi Weiand Yong Wu
Ningbo University of Finance&Economics,Ningbo,315175,China
ABSTRACT In the “shared manufacturing” environment,based on fairness,shared manufacturing platforms often require manufacturing service enterprises to arrange production according to the principle of “order first,finish first”which leads to a series of scheduling problems with fixed processing sequences.In this paper,two two-machine hybrid flow-shop problems with fixed processing sequences are studied.Each job has two tasks.The first task is flexible,which can be processed on either of the two machines,and the second task must be processed on the second machine after the first task is completed.We consider two objective functions:to minimize the makespan and to minimize the total weighted completion time.First,we show the problem for any one of the two objectives is ordinary NP-hard by polynomial-time Turing Reduction.Then,using the Continuous Processing Module(CPM),we design a dynamic programming algorithm for each case and calculate the time complexity of each algorithm.Finally,numerical experiments are used to analyze the effect of dynamic programming algorithms in practical operations.Comparative experiments show that these dynamic programming algorithms have comprehensive advantages over the branch and bound algorithm(a classical exact algorithm)and the discrete harmony search algorithm(a high-performance heuristic algorithm).
KEYWORDS Hybrid flow-shop;dynamic programming algorithm;computational complexity;numerical experiments;shared manufacturing
1 Introduction
1.1 Problem Statement
In this paper,we study two two-machine hybrid flow-shop scheduling problems with fixed processing sequences.In this problem,a set ofnjobsJ={J1,J2,···,Jn} is processed in a twomachine two-stage flow-shop with machineM1at Stage 1 and machineM2at Stage 2.Each jobJihas two tasksAiandBi,where taskAiis flexible which can be processed on either of the two machines(M1andM2)foraitime units,and taskBiis inflexible which must be processed onM2forbitime units.TaskBicannot be processed until taskAiis completed,and pre-emption is not allowed.The processing order of the jobs is given in advance.Without losing generality,we assume that the jobs are processed according to the subscript order,i.e.,for any two tasks processed on the same machine,the task with a small subscript must be completed before the task with a large subscript.The objectives are to minimize the makespan(the maximum completion time)and minimize the total weighted completion time.
Hybrid flow-shop problems are widely used in the traditional manufacturing industry[1],computer graphics processing[2],medical operation scheduling[3],and other fields.For the research on the hybrid flow-shop problem,please refer to the latest review[4].A typical application scenario of the two-stage hybrid flow-shop scheduling is as follows.In integrated circuit manufacturing or mechanical manufacturing,product processing usually includes two stages:preliminary processing and finishing processing.The factories are equipped with two sets of equipment,one set of low-precision equipment for preliminary processing and the other set of high-precision equipment for finishing processing.However,when necessary,the high-precision equipment can also be degraded for preliminary processing.Reasonably arrange the processing sequence and processing machines can make all products complete as soon as possible.
The scheduling problems with fixed processing sequences refer to the scheduling problem in which the processing order of the jobs is determined in advance.This kind of problem is originally mainly applied to the stock control systems[5].In recent years,with the integration of the sharing economy into the traditional manufacturing industry,there has been a shared manufacturing mode that shares manufacturing resources and demands on the network platform and matches supply and demand through advanced algorithms[6].“Alibaba Taobao Factory”and“Aerospace Cooperative Manufacturing Network” in China,“Wanju-gun Local Food Processing Center” in Korea,and many other share manufacturing practices have been vigorously developed.Based on fairness,shared manufacturing platforms often require manufacturing service enterprises to arrange production according to the principle of “order first,finish first” which forms a constraint of fixed processing sequences.Suppose the two-stage hybrid flow-shop scheduling problem with two machines described above is considered in the shared manufacturing environment.It is equivalent to adding the constraint of fixed processing sequences in the above typical application scenario.Obviously,the mathematical model of this problem is the scheduling model described in the first paragraph of this section.
1.2 Related Problems and Results
Wei et al.[2]first considered this two-stage hybrid flow-shop scheduling problem without fixed processing sequences constraint(denoted by SHFS)in 2005.They proved that this problem is ordinary NP-hard and presented an approximation algorithm with polynomial-time computational complexity whose worst-case ratio is 2.For the same problem,Jiang et al.[7]designed an improved approximation algorithm whose worst-case ratio is 1.5.Recently,for the case where every job has a deadline and must be processed in a given order,Wei et al.[8]proposed efficient algorithms.
The research results of other hybrid flow-shop scheduling problems with two stages close to the problems studied in this paper are as follows.A special hybrid flow-shop scheduling problem with two machines was considered by Vairaktarakis et al.[1].In their problem,the two tasks of each job can be processed on any one of the two machines,i.e.,there are four processing methods in total.An excellent approximate algorithm was presented whose worst-case ratio is only 1.618.Zhang et al.[9]studied another similar problem where the later task of each job can be jointly processed by multiple machines,but the former task cannot.An approximate algorithm was presented in their paper whose worst-case ratio is only 2-ε.For the special case of the above problem raised by Zhang et al.[9],an improved approximation algorithm was presented by Peng et al.[10–12]respectively studied two hybrid flow-shop problems where all batching machines are at two stages.The objective function of the former problem considered by Wang et al.[11]is to minimize the total weighted completion time.Mixed-integer linear programming(MILP)was constructed,and an efficient heuristic algorithm was presented.The objective of the latter problem studied by Tan et al.[12]is to minimize the total weighted delay time.They proposed an iterative decomposition method to solve it.Some scholars have also studied the two-stage hybrid flow-shop where no buffer capacity exists between the two stages.For the latest research results on such problems,please refer to the research of Dong et al.[13–15].For other latest studies on two-stage hybrid flow-shop under different parameter conditions and objective functions,please refer to Feng et al.[16–21],etc.However,these problems do not consider the constraint of fixed processing sequences.
The earliest scheduling problem with fixed processing sequences was presented by Shafransky et al.[22].They considered the model with fixed processing sequences in an open-shop problem,showed this problem is NP-hard in the strong sense,and proposed a very accurate polynomial-time approximate algorithm whose worst-case ratio is only 1.25.Lin et al.[5]studied a two-stage differentiation flow-shop to minimize the total completion time and proposed a dynamic programming algorithm.Hwang et al.[23,24]firstly studied the general two-machine flow-shop problem with a given sequence and presented an optimal algorithm for each of the two special cases.Then,they studied the general flow-shop scheduling with batching machines and proposed optimal algorithms for several models.With the gradual emergence of the application value of the scheduling problem with fixed processing sequences,the related research has increased a lot in recent years.Lin et al.[25]considered a relocation scheduling problem with fixed processing sequences corresponding to resource-constrained scheduling on two parallel dedicated machines.They proposed polynomial-time optimal algorithms or approximate algorithms for several models with different objective functions.Halman et al.[26]further gave a fully polynomial-time approximation scheme for the above problem.Cheref et al.[27]studied a scheduling problem considering production and delivery with a given sequence.They showed that this problem is NP-hard and proposed a dynamic programming algorithm with good effect.A server scheduling problem on parallel dedicated machines with fixed processing sequences was considered by Cheng et al.[28,29].For the two-machine case,a polynomial-time approximation algorithm was presented;for the case where each loading time is unit,two heuristic algorithms were proposed;and for the general case,a pseudo-polynomial algorithm was presented.However,the two-stage hybrid flow-shop scheduling with fixed processing sequences and the goal of minimizing makespan or total weighted completion time has not been considered yet.
1.3 Our Results
In the “shared manufacturing” environment,we introduce the constraint of fixed processing sequences into the two-machine two-stage hybrid flow-shop scheduling problem SHFS.We consider two objectives of this problem:to minimize the makespan and to minimize the total weighted completion time.For each problem,we analyze the computational complexity and present a dynamic programming algorithm.According to the three-field representation,these two problems can be expressed in the following form:
(1)FS2|FJS,Hybrid|Cmax,
which are denoted by SHFSFC and SHFSFW.
Firstly,we give the structural characteristics of one optimal solution and prove that these two problems are both ordinary NP-hard.Then we propose the dynamic programming algorithms and calculate their time complexity.Finally,we show the advantages of these algorithms over the existing exact algorithms and heuristic algorithms in practical efficiency and effect by numerical experiments.
The rest of this paper is arranged as follows:In Section 2,we first give the basic symbolic assumptions and the characteristics of one optimal solution,then analyze the computational complexity of the problems;In Sections 3 and 4,the dynamic programming algorithms for SHFSFC and SHFSFW are proposed,respectively;In Section 5,we compare the dynamic programming algorithms presented in this paper with the existing algorithms through numerical experiments to obtain the actual efficiency and effect of these algorithms.Finally,we conclude the paper and give the future research ideas in Section 6.
2 Symbolic Assumptions,Structure of One Optimal Schedule,and Complexity of the Problems
The basic symbols to be used in the following are given,properties of one optimal schedule of SHFSFC(SHFSFW)are analyzed,and the computational complexity of each problem is proved in this section.
2.1 Symbolic Hypothesis
The symbols and their meanings to be used below are as follows:
·ai:The processing time of taskAi(the first task of jobJi)on machineM1orM2;
·bi:The processing time of taskBi(the second task of jobJi)on machineM2;
·Ci:The completion time of jobJi;
·wi:The weight of jobJi;
·V1:The job set {Ji|Aiis processed on machineM1};
·V2:The job set {Ji|Aiis processed on machineM2}.
2.2 Structure of Optimal Scheduling
The two problems studied in this paper do not consider the buffer capacity between the two stages.That is,the buffer capacity is deemed to be infinite.So the tasks processed on machineM1can be processed as early as possible,i.e.,there is no idle onM1until completion.If jobJi∈V1,taskBicannot be processed until taskAiis completed.So,there may be an idle time on machineM2before taskBistarts to be processed.But if jobJi∈V2,taskAiandBican be processed immediately after taskBi-1onM2without any idle time.
From the above analysis,it is easy to find that the following proposition holds whether the objective is to minimize makespan or total weighted completion time.
Proposition 2.1There exists one optimal schedule of SHFSFC(SHFSFW)that satisfies the following properties at the same time:
(1)TaskA1is processed onM2,and taskAnis processed onM1;
(2)M1has no idle time until processing is complete;
(3)There is no idle time onM2between any task of the job inV2and its previous task;
(4)There is no idle time onM2between the second taskBiof jobJi∈V1and its previous task,or the starting processing time ofBiis exactly equal to the completion time ofAi.
Proof:
(1)Supposeφ1is an optimal schedule of SHFSFC(SHFSFW)whereA1is processed onM1andAnis processed onM2.We construct a new scheduleφ1based onφ1as follows:Change the processing mode ofJ1andJn,i.e.,A1andB1are all processed onM2andAnis processed onM1;Keep other task processing arrangements unchanged.SinceB1cannot be processed onM2untilA1is completed onM1inφ1,there is an idle time ofa1time units before taskB1starts to be processed onM2inφ1.ThereforeA1can be processed on the above idle time onM2inφ1without affecting the completion time ofB1.And sinceJnis the last job,no task is processed onM1after the starting processing time ofAn(denoted byS(An))inφ1.SoAncan be processed onM1fromS(An)toS(An)+aninφ1without affecting the completion time ofBnonM2.Obviously,φ1is feasible,and the makespan and the total weighted completion time inφ1are all equal to them inφ1.So we have thatφ1is also an optimal schedule which implies property(1)holds.
(2)Supposeφ2is an optimal schedule of SHFSFC(SHFSFW)satisfying property(1)where there exists an idle time between two successive processed tasksAiandAjon machineM1.Next,we construct a new scheduleφ2based onφ2as follows:Advance the start processing time of taskAjto the completion time of taskAiso that there is no idle time between them;Keep other task processing arrangements unchanged.Since the buffer capacity between two stages is not considered,the taskAjis processed in advance,and taskBjremains intact,the starting processing time ofBjis still larger than the completion time ofAj,i.e.,φ2is still feasible.Considering that the processing schedules of all second tasks have not changed inφ2,the completion time of each job is the same inφ2andφ2.Forφ2is an optimal schedule of SHFSFC(SHFSFW),φ2is also an optimal schedule.OnM1,by a similar method,all idle times beforeM1finishing processing can be eliminated,and the schedule is still optimal,which implies property(1)and(2)hold simultaneously.
(3)Supposeφ3is an optimal schedule of SHFSFC(SHFSFW)satisfying property(1)and(2)where there is an idle time onM2between the taskAi(orBi)of jobJi∈V2and its previous task.Next,we construct a new scheduleφ3based onφ3as follows:Advance the start processing time of taskAi(orBi)to the completion time of its previous task onM2,so that there is no idle time between them;Keep other task processing arrangements unchanged.Since the processing arrangements of the jobs inV1have not changed,φ3is feasible.And for the completion time of the job inφ3is equal to or less than that inφ3,the makespan and the total weighted completion time inφ3are all less than or equal to them inφ3.According thatφ3is an optimal schedule,φ3is also an optimal schedule.Obviously,by a similar method,all idle times onM2between any task of the job inV2and its previous task can be eliminated,and the schedule is still optimal,which implies property(1),(2),and(3)hold at the same time.
(4)Supposeφ4is an optimal schedule of SHFSFC(SHFSFW)satisfying property(1),(2),and(3)where there is an idle time onM2between the second taskBiof the jobJi∈V1and its previous task,and the starting processing time ofBiis larger than the completion time ofAi.Next,we also construct a new scheduleφ4based onφ4as follows:Advance the start processing time of taskBito the larger value of the completion time of its previous task onM2and the one ofAi,so that there is no idle time betweenBiand its previous task or the starting processing time ofBiis exactly equal to the completion time ofAi;Keep other task processing arrangements unchanged.Obviously,through a simple analysis similar to the proof of(2)or(3),we can have thatφ4is also an optimal schedule and then get property(1),(2),(3),and(4)hold at the same time.
To sum up,we can get Proposition 2.1 holds.
According to Proposition 2.1,it is easy to obtain there exists an optimal schedule of SHFSFC(or SHFSFW),which is shown in Fig.1 below.That is,there exists an optimal schedule of SHFSFC(or SHFSFW)in whichA1andAnare processed onM1andM2,respectively,and the continuous processing tasks are divided by some idle times before the second tasks of some jobs inV1onM2.These continuous processing tasks are calledContinuous Processing Modules(denoted by CPM)in the following study,which will help design dynamic programming algorithms in Sections 3 and 4.
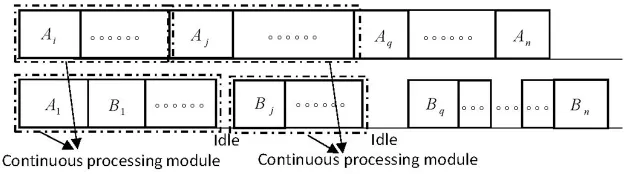
Figure 1:The structure of an optimal schedule
2.3 Computational Complexity of the Problems


It is known that Partition Problem is NP-hard,so it is easy to have that SHFSFC is also NP-hard.
Obviously,the above proof process still holds whenε=0,so it can be obtained that Theorem 2.2 holds even if the processing time of the second task for every job is 0.
Theorem 2.3SHFSFW is NP-hard.
Proof:Considering that the jobs are processed in subscript order,we haveCmax=Cn.So whenw1=w2=···=wn-1=0,wn=1,problem SHFSFC is a special case of problem SHFSFW.We have proved that SHFSFC is NP-hard,so SHFSFW is also NP-hard.
3 A Dynamic Programming Algorithm of Problem SHFSFC
According to Proposition 2.1,there is an optimal schedule of Problem SHFSFC,which is composed of several continuous processing modules and the idle times between continuous processing modules.Therefore,the following dynamic programming algorithm includes two stages:Construct the optimal continuous processing modules and connect the optimal continuous processing modules through idle times to form an optimal schedule.Firstly,the strict definition of continuous processing module for SHFSFC is given:
Definition 3.1A sub-schedule consisting of a job subset {Ji,Ji+1,···,Jj} is called a continuous processing module of Problem SHFSFC if it satisfies the following conditions(see Fig.2),denoted by four elements CPM(m,i,j,l).
(1)The first task of jobJiAiis processed onMm(m=1 or 2);
(2)No matter onM1orM2,there is no idle time between any two continuously processed tasks;
(3)The difference between the complete time of subset {Ji,Ji+1,···,Jj} onM1andM2is equal tol.
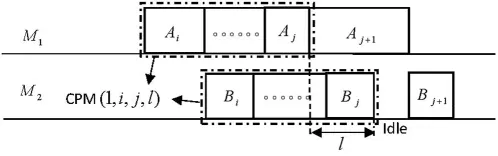
Figure 2:The continuous processing module(1,i,j,l)
It is easy to see that CPM(m,i,j,l)can be constructed by CPM(m,i,j- 1,l′)using two different methods(as shown in Fig.3).The first method to get CPM(m,i,j,l)is to add jobJj∈V1to CPM(m,i,j-1,l′)(see Fig.3a).And the second method to get CPM(m,i,j,l)is to add jobJj∈V2to CPM(m,i,j-1,l′)(see Fig.3b).We assume thatf(m,i,j,l)is the minimum load generated by the continuous processing module on machineM1composed of job subset{Ji,Ji+1,···,Jj}.
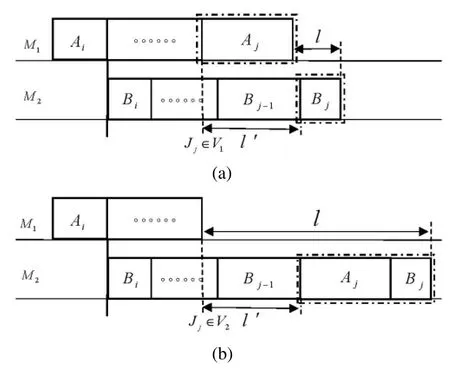
Figure 3:The two ways from CPM(1,i,j-1,l′)to CPM(1,i,j,l)as shown in(a)and(b)


In the following discussion,we let
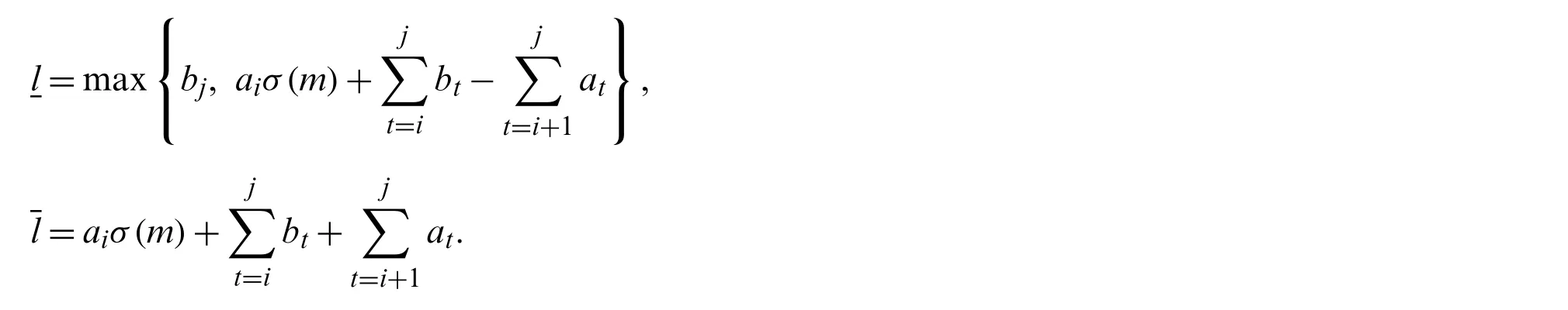
Obviously,in the sub-schedule composed of job subset {Ji,Ji+1,···,Jj},the difference in completion time between two machineslmust be obtained in the intervalThe maximum completion time of CPM(m,i,j,l)isf(m,i,j,l)+l.So,whenlis fixed,minimizing the maximum completion time is equal to minimizingf(m,i,j,l).Therefore the optimal continuous processing module is obtained whenf(m,i,j,l)is minimum.The dynamic programming algorithm for calculating the loadf(m,i,j,l)of the optimal CPM(m,i,j,l)on machineM1is given below:

The initial conditions and recurrence formula in dynamic programming algorithm CPM(C)are clearly valid.So we mainly analyze the recurrence relation below.Given a set of required parametersm,i,j,l,the load generated by the optimal CPM(m,i,j,l)onM1f(m,i,j,l)can be obtained by two different methods.The first method is to put taskAjonM1and taskBjonM2(as shown in Fig.3a).So we havel′+bj=l+ajwhich impliesl′=l+aj-bj,subject tol′≥aj,i.e.,l≥bj.According to the value range ofl,we havel≥bjalways holds.Therefore the relation(1)in Recurrence Relation holds.The other method is to putAjandBjboth onM2(as shown in Fig.3b).So we havel=l′+aj+bjwhich impliesl′=l-aj-bj,subject tol′≥0,i.e.,l≥aj+bj.Therefore the relation(2)in Recurrence Relation holds.
After the optimal continuous processing modules are constructed,the whole schedule can be constructed by recursively connecting these optimal continuous processing modules.It should be noted that every two continuous optimal continuous processing modules are separated by an idle time onM2.First,we let the Partial Schedule(m,i)be a sub-schedule of the job set{Ji,Ji+1,···,Jn},denoted by PS(m,i),where the first jobJi∈Vm,m∈{1,2}.Then letg(m,i)be the minimum makespan of PS(m,i).Next,we give a dynamic programming algorithm to calculate the makespang(m,i)of the optimal PS(m,i).For the convenience of narration,we set up a virtual jobJn+1with processing timean+1=bn+1=+∞.

The initial conditions,recurrence formula,and target value in dynamic programming algorithm DP(C)are clearly valid.So we also mainly analyze the recurrence relation below.When the optimal CPM(m,i,j,l)is given,PS(m,i)can be structured by the optimal PS(m,j+1).Since there is an idle time between CPM(m,i,j,l)and PS(m,j+1),according to Proposition 2.1,we can getmis equal to 1 in PS(m,j+1),i.e.,taskAj+1is processed onM1as shown in Fig.4.It is easy to getg(m,i)=minf(m,i,j,l)+g(1,j+1)wheni <n,andg(m,i)=minf(m,i,j,l)+g(1,j+1)+lwheni=n.According that there is an idle time between jobJjandJj+1,l <aj+1must be satisfied.So Eq.(5)holds.
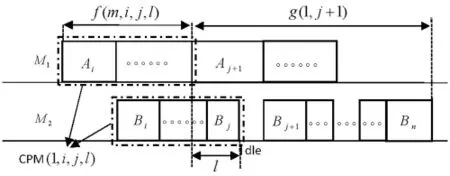
Figure 4:From CPM(m,i,j,l) and PS(m,j+1) to PS(m,i)


4 A Dynamic Programming Algorithm of Problem SHFSFW
This section will construct a dynamic programming algorithm for problem SHFSFW using a method similar to Section 3.First,we construct the optimal continuous processing modules and calculate the objective value of every optimal continuous processing module by a dynamic programming algorithm.Then,we use optimal continuous processing modules to construct an optimal partial schedule.Finally,the objective of the optimal schedule is calculated by backward recursion.However,the goal of SHFSFW is to minimize the total weighted completion time,which is different from makespan.It has no direct relationship with the load of the jobs on machineM1.So,we need to add a parameterhthat represents the load of the jobs onM1for constructing the continuous processing module.So we use five elementsm,i,j,h,linstead of four elements in Section 3 to structure the continuous processing module.The strict definition of the continuous processing module for SHFSFW is given below.
Definition 4.1A sub-schedule consisting of a job subset {Ji,Ji+1,···,Jj} is called a continuous processing module of Problem SHFSFW if it satisfies the following conditions,denoted by five elements CPM(m,i,j,h,l).
(1)The first task of jobJiAiis processed onMm(m=1 or 2);
(2)No matter onM1orM2,there is no idle time between any two continuously processed jobs;
(3)The load generated by the subset {Ji,Ji+1,···,Jj}onM1is equal toh;
(4)The difference between the complete time of subset {Ji,Ji+1,···,Jj} onM1andM2is equal tol.
It is easy to see that CPM(m,i,j,h,l)can be structured by CPM(m,i,j-1,h′,l′)using two different methods(as shown in Fig.5).The first method to get CPM(m,i,j,h,l)is to add jobJj∈V1to CPM(m,i,j-1,h′,l′)(see Fig.5a);The second method to get CPM(m,i,j,h,l)is to add jobJj∈V2to CPM(m,i,j-1,h′,l′)(see Fig.5b).We assume thatf(m,i,j,h,l)is the minimum total weighted completion time of CPM(m,i,j,h,l)on machineM1composed of job subset{Ji,Ji+1,···,Jj}.Using the discussion similar to Section 3,we can get the dynamic programming algorithm aboutf(m,i,j,h,l)as follows.
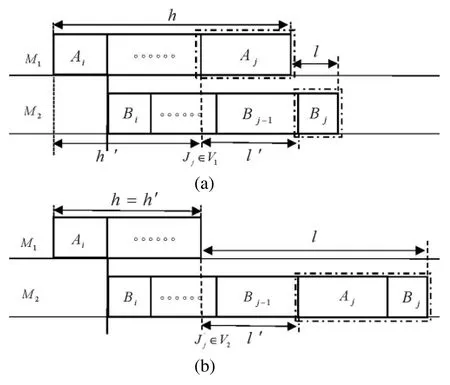
Figure 5:The two ways from CPM(1,i,j-1,h′,l′)to CPM(1,i,j,h,l)as shown in(a)and(b)

Next,we define the Partial Schedule(m,i)of SHFSFW.Let Partial Schedule(m,i)be a subschedule of the job set {Ji,Ji+1,···,Jn},denoted by PS(m,i),where the first jobJi∈Vm,m∈{1,2}.Then letg(m,i)be the minimum total weighted completion time of PS(m,i).Next,we give a dynamic programming algorithm to calculateg(m,i).For the convenience of narration,we construct a virtual jobJn+1with processing timean+1=+∞,bn+1=+∞.


5 Analysis of Algorithm Effect Based on Numerical Experiments
5.1 Time Complexity Analysis
We analyze the computational complexity of two problems,design dynamic programming algorithms for them,and calculate the time complexity of the algorithms in Sections 2–4.These results are summarized in Table 1.

Table 1:The detailed results of the two models
We took SHFSFC as an example to test the operation efficiency of the dynamic programming algorithms designed in this paper through numerical experiments.The numerical experiments were carried out in Matlab R2017 on a laptop with built-in an Intel Core i5 8250u CPU,8 GB LPDDR3 RAM,and Windows 10.The processing time of each flexible taskaiwas obtained by a random partition of a given number ∑intonvalues.The processing time ofbiwas produced as a uniformly distributed random number within[0,10].The experiments were performed for 10 ≤n≤230 with an interval of 20 andwith an interval of 100.We conducted a total of 12×10=120 experiments with different combinations ofnand ∑And we generated 30 random test instances for each experiment.The average running results of all experiments are listed in Table 2,where the top row representsthe leftmost column representsn,and the unit of the data in the table is in seconds.
It can be seen from Table 2 that even ifnreaches 230 and the total processing time of all flexible tasks reaches 1000,the time used by algorithm DP(C)only needs less than 85 s.Therefore,we can conclude that the actual effect of the algorithm is entirely acceptable.
Table 2:The average running times(in seconds)for 10 ≤n ≤230 and
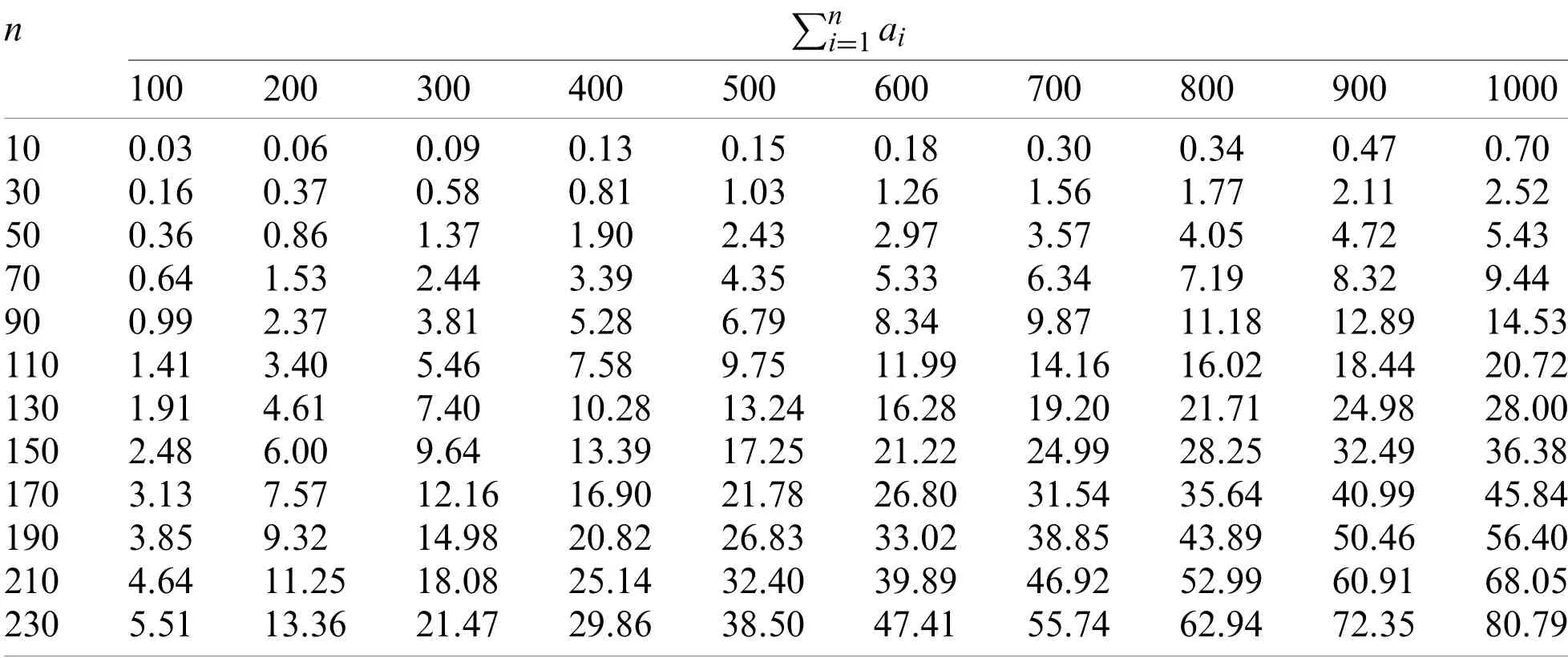
Table 2:The average running times(in seconds)for 10 ≤n ≤230 and
n ∑ni=1 ai 1002003004005006007008009001000 100.030.060.090.130.150.180.300.340.470.70 300.160.370.580.811.031.261.561.772.112.52 500.360.861.371.902.432.973.574.054.725.43 700.641.532.443.394.355.336.347.198.329.44 900.992.373.815.286.798.349.8711.1812.8914.53 1101.413.405.467.589.7511.9914.1616.0218.4420.72 1301.914.617.4010.2813.2416.2819.2021.7124.9828.00 1502.486.009.6413.3917.2521.2224.9928.2532.4936.38 1703.137.5712.1616.9021.7826.8031.5435.6440.9945.84 1903.859.3214.9820.8226.8333.0238.8543.8950.4656.40 2104.6411.2518.0825.1432.4039.8946.9252.9960.9168.05 2305.5113.3621.4729.8638.5047.4155.7462.9472.3580.79
Using the data in Table 2,we can discuss the relationship between the running time of the algorithm and the total processing time of all flexible tasks when there are fewer jobs(n=10),a lot of jobs(n=110),and a large number of jobs(n=210)(as shown in Fig.6).It can be got from Fig.6 that:(1)The running time of algorithm DP(C)increases with the increase of the total processing time of all flexible tasks;(2)The more the number of jobs,the faster the running time of the algorithm increases with the increase of;(3)Whennis given,the growth rate of the algorithm processing time is similar,i.e.,the running time of the algorithm is nearly linear with ∑.
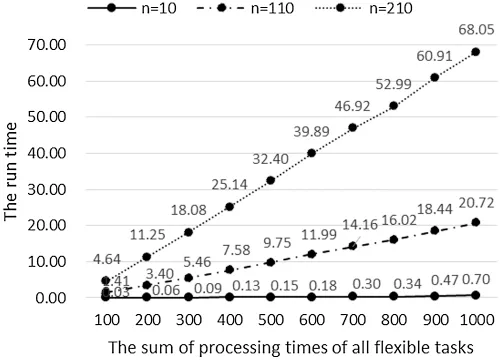
Figure 6:When n=10,110,210,the running time changes with
Similarly,the data in Table 2 is used to analyze the relationship between the running time of the algorithm and the number of jobs when the total processing time of all flexible tasks is smalland huge(as shown in Fig.7).It can be got from Fig.7 that:(1)The running time of the algorithm increases with the increase of the number of all jobs;(2)The growth rate of the algorithm running time becomes faster with the increase of the number of all jobs;(3)The larger the total processing time of all flexible tasks,the faster the algorithm processing time increases with the increase of the number of all jobs.
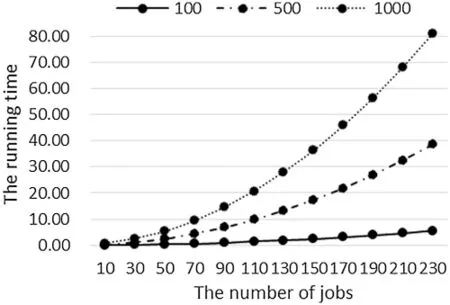
Figure 7:When the running time changes with n
5.2 Comparison with Other Commonly Used Algorithms
Since there is no other algorithm for the two-stage hybrid flow-shop problem studied in this paper,we compare the high-quality algorithms for a similar problem with the dynamic programming algorithms given in this paper to analyze the effect of our algorithms.
We usually design polynomial-time optimal algorithms to solve P problems[30].But there exist two kinds of algorithms for solving NP-hard problems.The first one is the exact algorithm,which gives the optimal solution,but the time complexity is exponential,including the enumeration algorithm,branch and bound algorithm[31].The second one is the heuristic algorithm,which usually gives the approximate solution of the problem,but the time complexity is polynomial,including the genetic algorithm[20,32],(Iterated)green algorithm[33],fireworks algorithm[34],artistic neural network algorithm[35],(discrete)harmony search algorithm[36],etc.These algorithms are widely used in solving various scientific and engineering problems.From the analysis of the existing literature,it is found that the branch and bound algorithm is the most commonly used and relatively practical algorithm in the accurate solution of hybrid flow-shop problems[31,37].Regarding the heuristic algorithm,the research in literature[36]shows that a discrete harmony search algorithm has advantages compared with a genetic algorithm,greedy algorithm,and harmony search algorithm,both in running time and the average relative percentage deviation,in solving hybrid flow-shop problems.The average Relative Percentage Deviation(denoted by RPD)is usually used to measure the approximation of heuristic algorithms[38],and its specific definition is as follows:in whichCAis the objective value calculated by AlgorithmAandC*is the optimal objective value which can be got by the exact algorithm.
We still took problem SHFSFC as an example to compare dynamic programming algorithm DP(C)(the algorithm given by us),the branch and bound algorithm(given by Moursli et al.[31],denoted by B&B),and the discrete harmony search algorithm(given by Zini et al.[36],denoted by DHS)regarding the running time and the average relative percentage deviation.
The numerical experiments were carried out in the same software and hardware environment as in Section 5.1.The time complexity of B&B and DHS is independent of ∑but only related to the number of jobs.So,we only conducted grouping experiments according tonto unify the comparison standards.We considered the efficiency(running time)and performance(RPD)of the three algorithms in the small-scale-jobs case(5 ≤n≤50)and the large-scale-jobs case(100 ≤n≤300).The numerical experiments were carried out for 5 ≤n≤50 with an interval of 5 in the small-scale-jobs case and 100 ≤n≤300 with an interval of 50 in the large-scale-jobs case.The processing time of each taskai(orbi)was produced as a uniformly distributed random number within[0,10].Twenty random instances for every experiment were produced.The average values of running time and RPDs were selected as the experimental results.The average running time of each algorithm under the two experimental conditions is shown in Table 3.

Table 3:The average running time(in seconds)of DP(C),B&B,and DHS for two kinds of experiments
As shown in Table 3,DP(C)and DHS can complete the operation in 100 s in both two cases.In particular,DHS can be completed in 20 s,showing its advantage in time complexity.However,for B&B,when the number of jobs reaches 45,some instances cannot be completed in 1200 s;when the number of jobs reaches 50%,70% of the instances cannot be completed in 1200 s;and all large-scale-jobs experiments cannot be completed in 1200 s.
The relationship between running time andnof each algorithm in the small-scale-jobs case is shown in Fig.8.For this case,we can get that:(1)DHS has the most advantage in time complexity,followed by DP(C),while B&B has obvious disadvantages;(2)The running time of each algorithm increases with the increase of the number of jobs and one of B&B increases much faster than the other two algorithms.
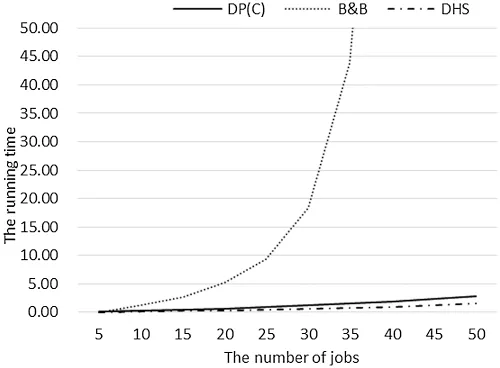
Figure 8:The average running time of DP(C),B&B,and DHS for small-scale-jobs experiments
Similarly,using the data in Table 3,the relationship between running time andnof each algorithm in the large-scale-jobs case is shown in Fig.9.Since B&B cannot complete the operation within 1,200 s,only DHS and DP(C)are compared here.For this case,we can get that:(1)DHS has obvious advantages in time complexity,and the running time of each algorithm is within the acceptable range;(2)With the increase ofn,the running time of each algorithm increases.The growth rate of the running time of DP(C)increases with the increase ofn,while the growth rate of DHS is relatively flat.
Table 4 shows the results of the three algorithms on the relative percentage deviation under small-scale-jobs experiments and large-scale-jobs experiments.
Using the data in Table 4,we plot the relationship between the average RPD of algorithm DHS and the number of jobs in Fig.10.

Table 4:The average RPDs of DP(C),B&B,and DHS for two kinds of instances
From Fig.10,we can get that:(1)Since DP(C)and B&B are both exact algorithms,their average RPDs are 0.The average RPD of DHS is large in the small-scale-jobs case and decreases rapidly with the increase of the number of jobs,which means that the accuracy of DHS increases quickly with the rise of the number of jobs.However,in the small-scale-jobs case,the difference between the solution of DHS and the optimal solution is more than 25%,especially when the number of jobs is less than 15,the error is more than 50%;(2)In the large-scale-jobs case,with the increase ofn,the reduction speed of the average RPD slows down.In all large-scale-jobs experiments,the average RPD is above 0.1.Even ifnreaches 300,the gap between it and the optimal solution is still 12%.
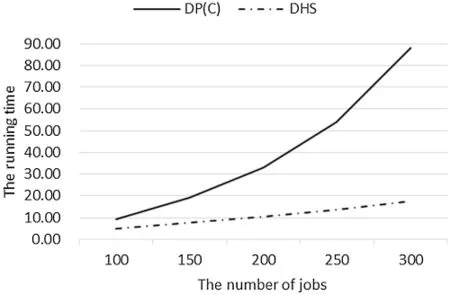
Figure 9:The average running time of DP(C)and DHS for large-scale-jobs experiments
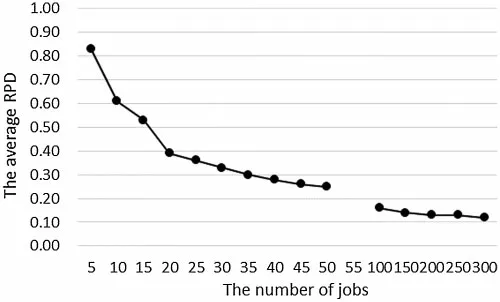
Figure 10:The average RPD of DHS changes with the number of jobs for two kinds of experiments
5.3 Summary of Comparison
According to the comparative analysis of numerical experimental results in Sections 5.1 and 5.2,we can get the following results:
(1)From the perspective of algorithm time complexity,DHS has advantages,followed by DP(C).The gap between the two can be ignored in the small-scale-jobs case.Although there is a certain gap in the large-scale-jobs case,DP(C)is still within the acceptable range.B&B has significant disadvantages in running time,and when the number of jobs is greater than 45,its running time becomes unacceptable;
(2)From the perspective of algorithm accuracy,DP(C)and B&B are both exact algorithms so that they can give the optimal solution.But B&B cannot provide the optimal solution within the time limit when the number of jobs is immense.DHS is a heuristic algorithm.In the small-scale-jobs case,the accuracy is low,and the gap with the optimal solution is more than 25%.In the large-scale-jobs case,the accuracy is improved,but the gap with the optimal solution is still more than 12%;
(3)The running time of DP(C)is small,and the accuracy is better than DHS 50% in the small-scale-jobs case.Although there is a certain gap between DP(C)and DHS,the running time of DP(C)is still in the acceptable range.And the algorithm accuracy is better than DHS 12% in the large-scale-jobs case.
6 Conclusions
This paper studies two two-stage hybrid flow-shop problems with two machines and fixed processing sequences,widely used in shared manufacturing,stock control systems,and other manufacturing areas.Two objectives of minimizing makespan and total weighted completion time are considered.For these two models,we first show they are both ordinary NP-hard,present a dynamic programming algorithm for each model,and analyze the time complexity of each algorithm.Then,the relationship between the running time and the combination of the total processing time of the flexible tasks and the number of jobs is obtained by numerical experiments.Finally,the advantages and disadvantages of the dynamic programming algorithms presented in this paper are compared with the exact algorithm B&B and the heuristic algorithm DHS,which have advantages in solving hybrid flow-shop problems.
In future research,we will study the polynomial-time approximation algorithm with a smaller worst-case ratio for this problem and extend the dynamic programming algorithm’s design method given in this paper to other scheduling problems with fixed processing sequences.
Acknowledgement:This work was partially supported by the Zhejiang Provincial Philosophy and Social Science Program of China(Grant No.19NDJC093YB),the National Social Science Foundation of China(Grant No.19BGL001),the Natural Science Foundation of Zhejiang Province of China(Grant No.LY19A010002)and the Natural Science Foundation of Ningbo of China(The design of algorithms and cost-sharing rules for scheduling problems in shared manufacturing,Acceptance No.20211JCGY010241).
Funding Statement:This study was funded by the Zhejiang Provincial Philosophy and Social Science Program of China(Grant No.19NDJC093YB),Recipient:Qi Wei.And the National Social Science Foundation of China(Grant No.19BGL001),Recipient:Qi Wei.And the Natural Science Foundation of Ningbo of China(Acceptance No.20211JCGY010241),Recipient:Qi Wei.And the Natural Science Foundation of Zhejiang Province of China(Grant No.LY19A010002),Recipient:Yong Wu.
Conflicts of Interest:The authors declare that they have no conflicts of interest to report regarding the present study.
 Computer Modeling In Engineering&Sciences2022年5期
Computer Modeling In Engineering&Sciences2022年5期
- Computer Modeling In Engineering&Sciences的其它文章
- New Hybrid EWMA Charts for Efficient Process Dispersion Monitoring with Application in Automobile Industry
- A Map Construction Method Based on the Cognitive Mechanism of Rat Brain Hippocampus
- Optimal Scheduling for Flexible Regional Integrated Energy System with SoftOpen Point
- Fractal Dimension Analysis Based Aging State Assessment of Insulating Paper with Surface Microscopic Images
- Underwater Diver Image Enhancement via Dual-Guided Filtering
- Reinforcement Effect Evaluation on Dynamic Characteristics of an Arch Bridge Based on Vehicle-Bridge Coupled Vibration Analysis