
多模态人机交互综述
2022-07-02 12:06陶建华巫英才喻纯翁冬冬李冠君韩腾王运涛刘斌
中国图象图形学报 2022年6期
陶建华,巫英才,喻纯,翁冬冬,李冠君,韩腾,王运涛,刘斌
1. 中国科学院自动化研究所,北京 100190; 2.浙江大学,杭州 310058; 3. 清华大学,北京 100084;4. 北京理工大学,北京 100081; 5.中国科学院软件研究所,北京 100190
0 引 言
受益于物联网的发展,人机交互设备在人们的日常生活中得到了广泛应用。近年来,计算机视觉、手势识别和人工智能等技术蓬勃发展,头戴式设备、显示屏和传感器等硬件技术取得了明显的进步,人机交互不再局限于单一感知通道(视觉、触觉、听觉、嗅觉和味觉)的输入输出模态(Bourguet,2003)。
多模态人机交互旨在利用语音、图像、文本、眼动和触觉等多模态信息进行人与计算机之间的信息交换。其中包括人到计算机的多模态信息输入与计算机到人的多模态信息呈现,是与认知心理学、人机工程学、多媒体技术和虚拟现实技术等密切相关的综合学科。目前,多模态人机交互与图像图形领域中的各类学术和技术联合得越来越紧密。多模态人机交互技术作为人—机—物的技术载体,在大数据与人工智能时代,其学术和技术发展前沿与图像图形学、人工智能、情感计算、生理心理评估、互联网大数据、办公教育和医疗康复等领域发展息息相关。多模态人机交互研究最早出现在20世纪90年代,多项工作提出了将语音和手势融合在一起的交互方法(Pavlovic 等,1997;Ando 等,1994;Cassell 等,1994)。近几年,沉浸式可视化(Jansen 等,2014)的出现为人机交互提供了一个新的多模态交互界面:一个融合了视觉、听觉和触觉等多个感知通道的沉浸式环境。
在学术界,多模态人机交互的学术成果在 IEEE-TPAMI(IEEE Transactions on Pattern Analysis and Machine Intelligence)、IEEE-TIP(IEEE Transaction on Image Processing)、IEEE-TASLP(IEEE/ACM Transactions on Audio, Speech and Language Processing)、IEEE-TNNLS(IEEE Transactions on Neural Networks and Learning Systems)、ACM-TOCHI(ACM Transactions on Computer-Human Interaction)等国际期刊和CHI(Computer-Human Interaction)、UbiComp(Ubiquitous computing)、CSCW(ACM Conference on Computer-Supported Cooperative Work and Social Computing)等国际会议呈现稳步增长,创新成果层出不穷。
在产业界,语音、人脸和手势等新型交互的应用从噱头转趋理性,聚焦于车载、直播等特定场景。触屏搭配一种新模态的交互方式,是当前多模态交互产品落地的主要形态。增强现实等新型输出/显示模态的技术逐渐成为未来多模态人机交互产品新的主要场景。
各国政府高度重视多模态人机交互。在“十三五”期间,我国设立多项重大重点项目支持多模态人机交互方向的研究。例如,国家重点研发计划项目“基于云计算的移动办公智能交互技术与系统”、“多模态自然交互的虚实融合开放式实验教学环境”等。美国海军开始构建下一代舰艇多模态人机交互模式,采用全息化的指挥模式,通过佩戴视觉和触觉传感器对舰船进行控制。英国海军公布的T2050未来水面舰艇概念,以多模态人机交互的方式,有效提高工作效率。
本文旨在综述多模态人机交互的最新进展,帮助初学者快速了解和熟悉多模态人机交互领域;对多模态人机交互方式进行分类整理,帮助该领域的研究者更好地理解多模态人机交互中的各种技术;对多模态人机交互领域面临的机遇和挑战进行梳理,启发相关研究者做出更有价值的多模态人机交互工作。
本文将从多模态信息输入与多模态信息输出两方面对多模态交互技术进行综述。其中,多模态信息输入过程涉及可穿戴交互技术以及基于声场感知的输入交互技术。多模态信息呈现过程涉及大数据可视化交互技术、混合现实交互技术以及人机对话交互技术。下面分别从大数据可视化交互、基于声场感知的交互、混合现实实物交互、可穿戴交互和人机对话交互5个维度介绍多模态人机交互的研究进展。内容框架如图1所示。
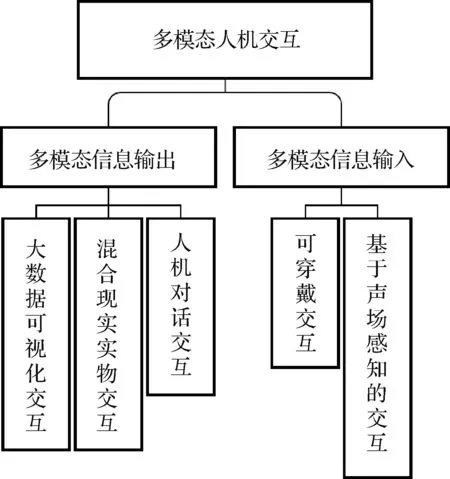
图1 本文内容框架Fig.1 The architecture of this paper
1 国际研究现状
1.1 大数据可视化交互
可视化是一种数据分析和探索的重要科学技术(叶帅男 等,2021),将抽象数据转换成图形化表征,通过交互界面促进分析推理,在城市规划(Deng等,2021)、医疗诊断(Park 等,2021)和运动训练(Chu 等,2022)等领域起着关键作用。在数据爆炸的今天,可视化将纷繁复杂的大数据转换为通俗易懂的内容,提升了人们理解数据和探索数据的能力。
传统的可视化交互设备,无论加载何种可视化系统,皆以2维显示屏、键盘和鼠标三者构成为主,通过键盘鼠标进行点击、拖拽、框选和移动等交互对可视化内容进行探索。然而,此交互界面只能支持平面式的可视化设计,包括数据映射通道、数据交互方式,无法满足大数据时代背景下的分析需求。
数据可视化在大数据时代下会产生呈现空间有限、数据表达抽象和数据遮挡等问题,沉浸式可视化的出现为高维度的大数据可视化提供了广阔的呈现空间,综合了多感知通道的多模态交互使用户可以利用多通道自然而并行地与数据交互。
1.1.1 大数据可视化设计
如何可视化复杂结构的海量数据依旧是一个挑战,尤其是具有3维空间信息的数据。传统的平面式呈现将视觉通道和视觉反馈局限于2维空间中(Ma 等,2014),同时也限制了设计空间。沉浸式设备的发展释放了用户的立体视觉,研究者们开始发掘3维交互空间在可视化中的潜力。
人们对3维的视觉感知来自于双目视差、遮挡和相对大小等深度提示(Renner 等,2013)。一方面,用户能够轻易识别3维物体的形态; 另一方面,3维中的视角倾斜会使2维平面图形产生形变,使用户难以识别(Munzner,2014)。因此,如何在3维环境中进行有效的可视化设计是大数据可视化交互领域的研究热点之一。
点是可视化中的重要标记。在2维平面中,通常可以采用点的位置、大小和颜色等视觉通道编码数据的不同属性。在3维环境中,Kraus等人(2020)通过用户实验发现相比于2维平面上的散点图,用户可以在虚拟现实环境下更加有效地识别3维散点图中的聚类。Alper等人(2011)提出了一种在3维环境中对图数据结构进行可视化的方法。该技术利用立体深度,通过将用户感兴趣的区域投影到更靠近用户视线的平面上进行突出显示。然而,上述可视化方法占据了3维位置的视觉通道,因此不能编码点在3维环境中的位置。为了解决上述问题,Krekhov和 Krüger(2019)以及Krekhov 等人(2020)提出了Deadeye技术,通过分裂呈现的方法对点进行突出显示。如图2所示,分裂呈现技术根据对每只眼睛呈现不同的刺激,将需要高亮的点在一只眼中显示。通过这种技术,需要高亮的点可以立即被视觉系统检测到。

图2 分裂呈现技术效果图(Krekhov 等,2020)Fig.2 Effect of split rendering technology (Krekhov et al., 2020)
线等视觉元素广泛应用于时空数据可视化中。然而传统的2维流图将同一区域不同时间的流动投影至一片区域中, 造成不同时间流动情况相互覆盖。时空立方体是一种在3维环境下对时空数据进行直观可视化的方法。时空立方体采用水平方向上的两个维度编码位置信息,采用垂直方向上的维度编码时间信息。Ssin等人(2019)提出了一种基于时空立方体对轨迹数据进行可视化的技术GeoGate。GeoGate是一种增强现实环境下的可视化系统。该系统扩展了时空立方体,并采用一个环形用户界面来探索多个位置数据集中实物之间的相关性。Filho等人(2019)提出了一种虚拟现实环境下的时空数据可视化系统。该工作使用时空立方体构建虚拟现实环境下的原型系统,将多维数据集与用户桌面的虚拟表示相结合。在展示地理流动数据的场景中,Yang等人(2019)通过增加高度,将2D地图中的流分开,通过实验得出将流按照不同高度展示可以提高用户辨别地图中流的准确率。
图可视化是信息可视化中的一个重要领域。传统的2维图布局会在数据量增大时出现严重的遮挡问题,为了解决此问题,Kwon等人(2016)提出了沉浸式环境下的图可视化的布局、渲染和交互技术的设计,提高了人们对大数量级图可视化的探索分析能力,如图3所示。

图3 沉浸式图可视化(Kwon 等,2016)Fig.3 Immersive graph visualization (Kwon et al.,2016)
1.1.2 非视觉感知的交互辅助
非视觉感知包括听觉、触觉、嗅觉与味觉。这些感知在日常生活中为人们提供了大量的信息,例如方位、声音和温度等,并与视觉一起帮助人们感知与理解周围的事物。近年来,多模态硬件技术愈发成熟,用以产生或模拟非视觉感知的设备逐步地小型化与商业化,这促使大数据可视化交互领域开始研究非视觉的交互方式。这种数据交互方法将用户沉浸在数据中,并在视觉感知外提供听觉、触觉等感知通道,提升用户的参与感与沉浸感,让用户感知在单一视觉通道上难以被发现的细节和模式。
在非视觉感知中,听觉是最容易实现的感知通道。通过物体发出的立体声,用户能够轻易辨识其所在的方位、远近等信息(Siu 等,2020);而语音则可高效地传递描述数据的语义信息(Kong 等,2019)。声音的音调、音色、音量以及听者所在的位置都可作为数据映射的通道并用以编码类别以及连续的数据类型,例如Franklin和Roberts(2003)将饼图中的类别信息、占比转化为各类型的声音;Xi和Kelley(2015)则提出了利用声音分析时序数据的工具。
触觉感知能够为用户提供物体纹理、温度和振动幅度等类别或连续的信息。利用振幅的大小,Prouzeau 等人(2019)将3维散点图中点云的密度映射为不同振幅的等级,提升了用户发现点云中心高或低密度的区域的感知能力。此外,数据物理化则是将抽象数据转化为可触摸实物的方法,通过让用户与实物触摸而不仅仅是观看来提升探索数据的效率,例如柱状图(Hu,2015)、节点链接图(Dragicevic 等,2021)等。
嗅觉与味觉具有易于记忆和识别的优势。利用各种气味所提供的类别信息以及气流流速、温度等连续信息,嗅觉与味觉同样能够编码离散与连续的数据。例如viScent(Patnaik 等,2019)提出了不同气味与数据类型的映射空间以将数据编码为不同的气味。
非视觉感知作为视觉感知的补充,能够提升用户分析理解数据的效率,例如在分析大量或高密度分布的数据可视化时,让用户感知视野之外或被遮挡的数据信息。另外,对于部分无法获取大数据可视化中视觉信息的人群而言,非视觉感知的交互能将可视化中的信息转化成非视觉信息传达给他们。然而,这些感知的使用往往带来额外的疲劳感,例如长时间触摸所导致的手臂疲劳,进而降低分析的时长。同时如何将高维、多变量等复杂数据进行非视觉感知的编码与设计仍尚待研究。
1.1.3 多模态交互设计
在大数据可视化交互领域,除了可视化设计,现有的研究重点还集中在探索更加自然直观的交互方式,以提升人们在3维空间对大数据可视化的操作效率。多模态交互结合单一模态的优点,充分发挥了人们对各个感知通道传达信息的高度接收与处理能力,增强用户对交互行为的理解,提高对大数据可视化的探索与分析效率。
1)基于接触的交互。以智能手机、平板为主的移动设备为可视化交互提供了高清晰度的画面和高精度的交互。基于接触的交互支持用户直接通过手部或者手持传感器触碰可视化标记,传递对数据的交互表达,这类自然的交互方式的操作精度较高,并且能够增强用户在探索大数据可视化时对信息的理解。如图4所示,Langner等人(2021)通过平板触控的方式准确地选择可视化图表以更新HoloLens中所见的增强内容。

图4 通过平板触控的交互(Langner 等,2021)Fig.4 Interaction through tablet touch(Langner et al.,2021)((a)map visualization;(b)nervous system visualization)
除了增强现实环境中基于触屏的交互方式外,接触式交互在虚拟现实中也很常见。例如,如图5所示,Usher等人(2018)的VR(virtual reality)系统可以通过跟踪用户手部动作来捕获用户勾勒出来的脑神经路径。与数据交互后产生的触觉反馈可以提升用户交互的直观性和沉浸感。研究者探索了虚实物体结合的交互方式,将真实物体作为虚拟标记在真实世界中的参照物给用户触碰来提升交互的精确性。例如,研究者将沉浸空间中的地图或数据点投影等2维可视化平面视为如图5所示的虚拟桌面并将其映射至真实桌面(Wagner 等,2021),用户可以直接点击桌面来操作对应数据。此外,Cordeil等人(2020)使用3个滑块轴将数据坐标轴实物化,用户可以通过操作滑块的位置来精准地选择轴空间内的数据。

图5 通过手部跟踪捕获勾勒的路径(Usher 等,2018)Fig.5 Capture the outlined path through hand tracking(Usher et al.,2018)
2)基于手势的交互。动作识别和传感器技术的发展让基于手势的交互逐渐成为常用的交互方式之一。基于手势的交互使用可跟踪设备或捕捉用户手指的移动来捕捉手部动作,帮助用户完成对数据的操控(Büschel 等,2018)。一种常见的手势交互技术是光线投射的目标指向,用户可以使用手柄等装置射出的光线来选择与光线相交的最近对象。为了增加这类交互方式的精确度,RayCursor(Baloup 等,2019)增加了如图6所示的沿投射光线方向的红色的控制光标来避免被遮挡散点的选择。此外,FiberClay(Hurter 等,2019)支持用户操控手柄射出的射线来完成对轨迹的筛选,如图7所示。

图6 虚拟桌面示意图(Wagner 等,2021)Fig.6 Schematic diagram of VirtualDesk(Wagner et al.,2021)

图7 基于光线投射的交互设计(Baloup 等,2019)Fig.7 Interactive design based on ray casting(Baloup et al., 2019)
除了光线投射技术的指向隐喻,其他诸如抓取、拖动等的隐喻也都有相关研究。如图8(a)所示,Wagner等人(2021)采用了虚拟手的隐喻,设计抓取和拉伸等动作完成对时空轨迹可视化的移动、缩放和选择等操作;Yang等人(2021a)利用双手合拢与展开的手势实现了散点图的缩放操作,如图8(b)所示;TiltMap(Yang 等,2021b)通过改变手柄的倾斜角度来实现如图8(c)所示的对地图可视化的不同视图之间的切换。这些交互方式通过直观的手势隐喻,帮助用户减轻了许多交互负担。

图8 3种基于手势隐喻的交互设计(Wagner 等,2021;Yang 等,2021a,b)Fig.8 Three interaction designs based on gesture metaphor (Wagner et al.,2021;Yang et al.,2021a,b)((a) virtual hand metaphor for grasping, stretching, and other interactions; (b) scaling interaction for visualizations with pinch gesture; (c) changing views with the tilt of the controller)
3)基于注视的交互。利用用户的视线信息进行注视交互也是探索大数据可视化时一种常见的交互模态。基于注视的交互通过眼动追踪技术捕捉用户的视线焦点,从而理解用户视线中传递的信息,例如当前关注的内容,或者用户的心理状态等。更进一步,系统可以基于这些信息完成交互,例如高亮用户关注的内容(Kwok 等,2019)。Sidenmark等人(2020)使用该技术辅助用户如图9所示在虚拟3维场景中选择一些被遮挡的物体:用户注视物体轮廓上的圆点,并使用视线控制圆点在物体未被遮挡的轮廓线上移动,从而精准地选中被部分遮挡的物体。Alghofaili等人(2019)则使用长短时记忆网络(long short-term memory, LSTM)模型对用户眼动数据进行异常检测,从而判断用户是否适应当前的虚拟环境,并在用户迷失时给予辅助反馈。

图9 通过眼动追踪技术完成目标选择的交互设计(Sidenmark 等,2020)Fig.9 Interaction design of target selection through eye tracking technology(Sidenmark et al.,2020)
4)基于移动导航的交互。移动导航也是探索呈现在虚拟的广阔3维场景里的大数据可视化中一个重要的交互模态。然而虚拟空间会出现与物理空间不匹配的情况,影响用户在虚拟空间中达到最佳观察点,降低探索能力。为此,交互式的移动导航可以辅助用户移动到最佳的观察点,甚至同时规避空间感知不一致性带来的生理不适。Abtahi等人(2019a)通过建立3个层级的真实速度到虚拟速度的映射,便于用户在狭小的真实空间内遍历数据可视化呈现空间。此外,虚拟移动技术更进一步地拓宽了遍历虚拟空间的可能性。此类技术包括指定位置进行直接传送(Funk 等,2019)、使用3维缩略图进行传送(Yang 等,2021a)以及使用手柄控制飞行动作(Drogemuller 等,2018)等。
1.2 基于声场感知的交互
基于声场感知的交互技术按照工作原理可分为以下3种:1)测量并识别特定空间、通路的声音频响特性或动作导致的声音频响特性变化;2)使用麦克风组/阵列的声波测距 (角) 实现声源的定位,可通过发声体发出特定载波音频提升定位精度与鲁棒性;3)机器学习算法识别特定场景、环境或者人体发出的声音。技术方案包括单一基于声场感知的方法与传感器融合的方案。
本节从基于声场感知的动作识别、基于声源定位的交互技术、基于副语音信息的语音交互增强以及普适设备上的音频感知与识别4个方面综述国际上基于声场感知的交互技术。
1.2.1 基于声场感知的动作识别
基于声场感知实现不同手势与动作的识别是人机交互的热点研究内容,基于手势或者姿态带来声场变化的基础,实现手势或动作的识别。比如使用耳机上的麦克风识别摘戴耳机是最直观的手势识别,Röddiger等人(2021)利用内耳麦克风识别出了中耳内鼓膜张肌的收缩等用于交互。对于双手手势的识别,很多研究者会增加扬声器来构建设备周围的声场,通过分析麦克风接受到的信号变化来识别相应的手势。对于笔记本电脑、屏幕等固定设备,研究者使用声场识别出了手在空中的挥动、停留等手势(Ruan 等,2016;Gupta 等,2012)。而手表和腕带等可穿戴设备上的应用则更加广泛,Han 等人(2017)通过手表上的特殊排布的麦克风阵列识别了手腕的转动、拍手臂、不同位置打响指等手势,BemBand(Iravantchi 等,2019)利用腕带上超声波信号完成了对于手掌姿态、竖拇指等手势的识别。除此之外,很多研究将声音信号与陀螺仪的运动信号结合以实现更加精细的动作识别,早期Ward等人(2005)利用两个腕带上的麦克风和陀螺仪进行过简单手势识别的探索。而近几年传感器精度和质量的逐步提升,更多相关研究提高了手势识别的准确度与精度,FingerSound(Zhang等,2017a)与FingerPing(Zhang 等,2018)均识别拇指在其他手指上的点击与捏合动作,且FingerPing利用了不同手势下的共振信息,减少了对于陀螺仪的依赖,TapSkin(Zhang 等,2016)识别出了手表附近皮肤上的点击等更精细的手势交互动作。除了手势动作本身,部分研究探索了用户在与其他物品交互时的行为和手势,Acustico(Gong 等,2020)利用腕带上贴近桌面的麦克风识别出了用户在桌面上点击的2维位置用于交互输入,Pentelligence(Schrapel等,2018)和WritingHacker(Yu 等,2016)利用笔上麦克风较准确地还原出用户书写的字迹,而Ono等人(2013)利用玩具上的麦克风识别出了用户的触摸位置。
1.2.2 基于声源定位的交互技术
声源定位通常依赖于精确的距离测量。通过不同的声学测距方法,可以得到声源与麦克风的距离;再通过三角定位法,即可得到声源的位置。声学测距的常用方法包括基于多普勒效应、基于相关和基于相位的测距方法,此外在雷达系统中广泛应用的调频连续波(frequency modulated continuous wave, FMCW)也在近些年应用于声学测距。基于以上声学测距技术,可以实现手势识别、设备追踪等交互技术。

1.2.3 基于副语音信息的语音交互增强
近年来有许多研究者研究了利用“言语中的非言语信息”来加强语音互动。Goto等人(2002)提出利用语音过程中的用户在元音处的短暂停顿自动显示候选短语辅助用户记忆,并提出了利用用户有意控制的音高移位切换语音输入模式(Goto 等,2003),以及利用语音中的停顿和音高区分连续对话中的人人对话和人机对话(Goto 等,2004)。Kitayama等人(2003)提出了利用自然语音交互中的口语现象和停顿进行噪音鲁棒的端点检测和免唤醒。Kobayashi 和Fujie(2013)研究了人—机器人对话中的副语言协议。Maekawa(2004)与Fujie 等人(2003)讨论了副语言产生和感知的原理。Fujie 等人(2004)研究了利用副语言信息改进对话系统。Harada 等人(2006,2009)研究了利用元音质量、音量和音高等属性的光标控制。House等人(2009)将这一思想延续到利用连续声音特征控制3维机械臂。Igarashi和Hughes(2001)研究了利用非言语信息的连续语音控制和速率的参数。
1.2.4 普适设备上的音频感知与识别
近年来,普适音频设备不断普及,产业界对于普适音频设备不断投入,众多研究者致力于研究普适设备上的音频感知与识别。普适音频设备对于音频数据的实时性采集使得其在声音实时分类事件上具有优势,如Rossi等人(2013)提出了利用智能手机麦克风实时进行环境声音识别的系统AmbientSense。普适音频设备的声音感知还常常用在健康与生理感知领域,用以捕捉、推断用户的生理信息。如Thomaz 等人(2015)提出利用腕部音频设备捕捉环境声音,进行识别后推断用户饮食活动的方法,帮助用户进行饮食自我监测。Amoh和 Odame(2015)提出利用可穿戴声学传感器结合卷积神经网络检测咳嗽的技术。与环境的声音检测类似,对于更广义上的用户行为,Lu 等人(2009)利用手机麦克风对人当前活动(开车、乘坐公交车等)的识别进行了探索。商业产品或应用也快速发展与成熟,其中最具有代表性的是苹果手机手表上的环境音感知(咳嗽、报警等)。
1.3 混合现实实物交互
通过真实物体实现与虚拟对象进行交互的方法称为“实物交互界面”(Ishii和Ullmer,1997)。在实物交互系统中,用户通过使用在真实环境中存在的实物对象与虚拟环境进行交互,由于用户对实物本身的各种特性(如形状、重量)非常熟悉,可以使得交互的过程更为精准和高效(Zhou 等,2008)。近年来,将实物交互界面技术融入虚拟现实和增强现实已成为本领域的一个主流方向,并逐渐形成了“实物混合现实”的概念,这也正是被动力触觉的概念基础。2017年,Zhao 等人(2017)将实物交互的触觉分为3种方式:1)静态的被动力触觉;2)具有反馈的被动力触觉(即相遇型触觉);3)主动的力触觉。由于主动力触觉装置比较昂贵,目前的研究很少,主要研究方向仍是静态的被动力触觉和相遇型触觉。关于被动力触觉的混合现实交互方式,目前国际上各个国家和机构的研究水平差别不大,但略有侧重。
1.3.1 静态的被动力触觉
在静态的被动力触觉方面,加拿大多伦多大学和美国芝加哥大学等团队曾提出过Thors Hammer(Heo 等,2018)以及PHANTOM(Massie和Salisbury,1994)两种比较具有代表性的研究。如图10所示,通过1 ∶1制作的物理实物道具提供逼真的动觉和触觉反馈,提高用户的触摸感受以及操作能力,并且可以通过对实物的触摸来对虚拟对象进行操作。静态的被动力触觉是在混合现实环境中实现触觉交互的一种早期探索,但这些刚性道具在形状上往往和虚拟道具不匹配,或者是道具数量有限,不能满足交互的需求。因此,可变换的被动力触觉便应运而生。加拿大多伦多大学的Araujo等人(2016)提出了Snake Charmer,可以动态地改变交互对象的纹理特征和材质信息,在虚拟环境中渲染不同的对象时仍能够保持触觉和视觉的一致性(Lee等,2006)。

图10 虚拟现实中的触觉反馈(Heo 等,2018)Fig.10 Haptics feedback in virtual reality(Heo et al.,2018)
1.3.2 相遇型被动力触觉及3种触觉设备
早在1993年,McNeely(1993)就提出机器人图形(robotic graphics)的概念,他认为触觉输出具有极大的价值,并建议使用机械臂或者机器人作为形状载体,动态地提供物理反馈。如今,这种方式已用于混合现实环境中,并有了深远的进步。对于有反馈的被动力触觉系统,从交互道具角度,有反馈的被动力触觉系统的交互载体主要有穿戴式、手持式和机器人式3大类(Huang 等,2020a)。与目前市场上主流的交互方式——如HTC Vive和Oculus Quest的交互手柄相比,基于被动力触觉的混合现实交互方式可以让用户在混合现实场景中更真实地操作物体,并提供力反馈。
1)可穿戴式触觉反馈设备。可穿戴式触觉反馈设备通过触觉手套、触觉服饰等方式,直接将机械系统产生的力反馈或者电反馈施加在用户的手部或身上,直观地进行被动力反馈触觉。美国斯坦福大学的Choi等人(2016)提出的Wolverine是一个典型的例子。Wolverine通过低成本和轻量级的设备,可以直接在拇指和3根手指之间产生力,以模拟垫式握持式物体,比如抓握茶杯和球。在低功耗的情况下能反馈超过100 N的反馈力。但是,这些可穿戴设备的缺点是,用户在混合现实环境中必须要时刻穿戴着反馈装置,有一定不适感,并且难以实现裸手交互。
2)手持式触觉设备。手持式触觉设备是通过用户单手或双手抓握指定的物体,从而对用户实现力反馈,具有代表性的研究如日本东京大学的Transcalibur(Shigeyama 等,2019)以及JetController(Wang 等,2021)。Transcalibur是一个可以手持的2维移动VR控制器,可以在2维平面空间改变其质量特性的硬件原型,并应用数据驱动方法获取质量特性与感知形状之间的映射关系。通过手持控制器可以有效实现用户抓握和操作物体,并且可以一定程度上降低用户的眩晕感。但手持式的触觉设备往往需要额外的定位装置,否则用户一旦在虚拟环境中放下手持式装置,便难以再次抓起。
3)机器人式触觉反馈设备。机器人式触觉反馈设备是以可移动或者可变形的机器人作为触觉代理装置,实现可移动和可变换的触觉方式。最早可以追溯到2015年,Cheng 等人(2015)使用TurkDeck的方法,借助工作人员将一系列通用模块搬运和组装为用户即将触碰到的被动实物,使用户不仅能够看到、听到,还能触摸到整个虚拟环境。Suzuki等人(2020)在此基础之上提出了Roomshift方法,通过实时控制混合现实交互空间的小车来移动环境中的实物物体,提供多种交互方式。Abtahi 等人(2019b)提出了Beyond the Force(P.Abtahi),通过可飞行的无人机作为触觉代理,提供动态的被动力触觉。图11所示的4轴飞行器目前可以支持3种功能: 被动触觉的动态定位、纹理映射和作为可交互的被动道具。而且,无人机在交互环境中任意移动,显著地拓展了交互的空间范围。

图11 相遇型被动力触觉装置(Abtahi 等,2019b)Fig.11 Encounter-type haptic devices(Abtahi et al.,2019b)
1.3.3 产业界进展
在产业界,Facebook和Microsoft是研究混合现实被动力触觉交互的中坚力量。2019年Facebook更新了交互装置Tasbi,一款具有震动和挤压两种反馈方式的触觉回馈腕带。2020年,Microsoft提出了PIVOT(Kovacs 等,2020),通过可变形的交互装置实现动态的相遇型触觉反馈。PIVOT是一个戴在手腕上的触觉设备,可以根据需要将虚拟对象呈现在用户的手上。Dexmo在2020年发布了新的触觉手套,Dexmo外骨骼手套制作精良,该产品面向企业市场。Dexmo触觉手套支持跟踪多达11个自由度的手势,可以灵巧地捕获用户完整的手部动作,从而使用户在虚拟环境中拥有逼真的手指感。不只是手部的力反馈,英国的TeslaSui生产了对全身提供被动力触觉的设备,其产品可将触觉反馈传输到身体的任何区域,从轻柔的触摸到体力的消耗感以及温度改变,并能输出运动捕捉和生物识别信息。采用带有性能监控和感觉刺激的TeslaSuit可以应用于公共安全、企业培训、体育和医疗康复等领域。
1.4 可穿戴交互
国际上可穿戴交互主要分为以手表手环形式为主的手势交互和触控交互的研究、皮肤电子技术与交互设计。
1.4.1 手势交互与触控交互
使用可伸展和贴皮式电子器件为实现皮肤界面提供了新的思路,可用于创造轻薄的电子皮肤,允许用户在其上实现触控并具有生理信号监测、视觉显示和触觉显示的功能(Withana等,2018)。实现触觉反馈将在皮肤界面的交互里变得尤为重要,这取决于皮肤自身的触觉感知能力。德国的Patric Baudisch团队尝试了通过腕带手表在皮肤上实现拖动的触感,可设计简单且容易被用户感知和记忆的字符和图标(Ion等,2015)。韩国科学技术院的人机交互团队探索了使用针阵列的触觉方式在手指上提供经过编译的信息(Je等,2017),以及通过气流在皮肤表皮实现非接触式的压力触感(Lee 等,2016)。加拿大多伦多大学利用记忆金属在手腕上实现挤压的触觉反馈(Gupta等,2017),通过控制驱动的线宽、力和速度产生不同感受的反馈。美国斯坦福大学的Sean Follmer团队通过设计手持式触觉设备来模拟虚拟操作物体的重力反馈(Choi 等,2017)。系统中两个音圈致动器通过不对称的皮肤变形产生与每个指垫相切的虚拟力,这些力可以视为虚拟物体的重力和惯性力。
1.4.2 电子皮肤交互
皮肤作为人们与外界接触的天然界面,已初步用于探索在信息交互中的作用并在若干方面的应用中体现了其优势。德国萨尔州大学的Jürgen Steimle团队近些年通过导电墨水、电极制作纹身纸,作为电子皮肤实现在皮肤上的显示、触摸和手势识别(Groeger和Steimle,2017;Olberding等,2014;Weigel和Steimle,2017)。相比于触摸屏,人们在自己的皮肤上移动手指显得更加灵活,而通过纹身纸的方式使得在皮肤表面附属的设备轻而薄,更容易被用户接受。来自于该团队的一项用户研究证明,用户在皮肤上进行的触摸手势和传统触摸屏手势较为一致,但同时也因为皮肤独有的特点,用户设计出了更为丰富的触控手势,证明了皮肤作为触控界面的可行性和优势(Weigel等,2014)。同样是对皮肤界面的探索,美国卡内基梅隆大学的Chris Harrison团队采取了在皮肤上投影的方式,通过肩戴投影(Harrison等,2011)或手表微投影(Laput等,2014;Xiao等,2018),将手臂、手背变成显示屏,并通过深度相机或红外线等方式支持手指在皮肤表面的触控。这种方式可以更好地支持探索人们使用皮肤界面的体验,但缺点也显而易见,即需要较为复杂的投影等附属设备。同时,该团队系统地研究了把身体的各个部位当做触摸界面时的可行性和用户的喜好程度(Harrison和Faste,2014),对后续的研究具有参考价值。这些项目的相似之处是在皮肤上发展和拓展触控交互的模式。
另一方面,研究者也在探索皮肤界面的独特用途,比如尝试把皮肤用做设计和创作的交互平台。加拿大Autodesk研究院探讨了如何利用人体手臂的皮肤构建一个3D建模和制造的平台,并展示了以皮肤为中心的建模技术(Gannon等,2015,2016)。韩国科学技术院的研究者们试图让用户在自己身上进行绘制来设计服装(Saakes等,2016)。挪威代尔夫特技术大学的Charlie C L Wang团队则允许用户在自己皮肤和手臂上进行服装设计的同时通过热感应来分析舒适度(Zhang 等,2017c)。美国麻省理工学院(Massachusetts Institute of Technology,MIT)的Media Lab开展了多项以人体和皮肤为基础的概念探索项目,向人们展示了可生材料、具有生物活性材料与人体皮肤结合时产生的设计、制造以及艺术价值(Yao 等,2015)。
1.5 人机对话交互
人机对话交互过程涉及语音识别、情感识别、对话系统和语音合成等多个模块,其主要框架如图12所示。首先,用户输入的语音通过语音识别和情感识别模块转化为相应的文本和情感标签。而后,对话系统将其用来理解用户所表达的内容,并生成对话回复。最后,语音合成模块将对话回复转换为语音,与用户进行交互。人机对话交互的性能不仅仅取决于对话系统的质量,高效鲁棒的语音(情感)识别与语音合成技术对于提高用户黏性发挥着至关重要的作用。
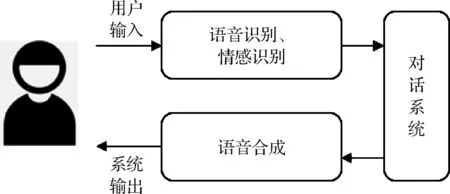
图12 人机对话交互框架图Fig.12 Human-computer diaglog framework
1.5.1 语音识别
目前国际与国内对于语音识别系统的研究已经不再局限于提升识别的准确度,而是研究在更加复杂场景下的语音识别模型的表现。总体概括来看,低延迟语音识别和低资源语音识别成为研究热点。
目前国际上针对低延迟语音识别主要从两方面进行研究,一方面是研究流式语音识别,实现边听边识别,以此来降低识别出每个标记的延迟;另一方面是研究非自回归语言识别,通过摆脱解码时的时序依赖从而加速整个系统的识别速度。
针对流式语音识别的研究主要有两种思路,一种是针对RNN-Transducer模型进行改进,提出了表现更好的 Transformer-Transducer (Zhang 等,2020a;Yeh 等,2019)、Conformer-Transducer (Huang 等,2020c;Guo 等,2021)。双通解码方法(Sainath 等,2019)的提出,进一步提升了基于Transducer的流式识别模型的准确率。另一种是对基于注意力机制的编码解码模型(attention-based encoder decoder, AED)的改进, 其实现思路主要是改进单调逐块注意力机制(monotonic chunk-wise attention, MoChA)(Chiu和Raffel,2018),其解决的主要问题是MoChA模型在Transformer上的适配以及对于通过辅助手段对模型切分编码状态的位置以及数量进行约束(Inaguma 等,2020a,b)。
针对非自回归语音识别方面的研究,国际研究上也日趋火热。非自回归语音识别因为摆脱了序列模型解码阶段的时序依赖,获得了广泛的速度提升,在自然语言处理(natural language processing,NLP)领域和语音领域均获得了很多关注。针对非自回归语音识别模型的提升整体上也是从两个角度来进行研究的,一方面是先通过编码器预测初始标签,解码器进行纠错或补全(Chi 等,2021;Higuchi 等,2021);另一方是通过解码器从空白序列出发,基于编码器的声学状态,预测得到完整的输出序列(Chen 等,2020a)。
近年来,国际上也掀起了针对低资源语音识别任务的研究高潮,普遍采用自监督技术或预训练技术(Schneider 等,2019;Baevski等,2020a,b;Sadhu 等,2021;Hsu 等,2021)。其中最具代表性的就是Facebook(已改名为Meta)提出的wav2vec系列工作(Baevski等,2020a,b),其将输入音频波形直接编码为声学向量表示,并通过矢量量化技术对声学向量表示进行聚类,整个预训练阶段使用对比算法进行自监督学习,然后在少量标注数据上进行微调。
1.5.2 语音情感识别
语音情感识别研究的早期阶段遵循传统的模式识别流程,即先进行特征提取,然后进行分类器设计。特征提取阶段大多依赖于手工设计的与情感相关的声学特征。大体上,这些声学特征可以分为3类,分别是韵律学特征、谱相关特征以及音质特征(Zhuge 等,2021)。开源工具openSMILE(韩文静等,2014)通常用于提取一些经典的情感声学特征集。受益于深度学习革命的到来,利用深度神经网络直接从原始数据中提取特征并进行分类的端到端学习范式逐渐占据主导地位。这些研究有的从时域的原始语音信号入手(Eyben 等,2010),有的则从频域的语谱图入手(Tzirakis 等,2018),此外也有一些研究同时结合两者进行端到端的语音情感识别(Li 等,2018)。由于语音情感识别的数据库通常都比较小,人工设计的深度神经网络往往容易过拟合,因此学习到的声学情感表征可能会面临着泛化能力不足的问题。为此,一些研究(Hershey 等,2017;Zhao 等,2018)采用在大规模音频数据库上预训练的深度神经网络(如基于卷积神经网络的VGGish(Bakhshi 等,2020)、Wavegram-Logmel-CNN(Zhao 等,2018)和PLSA(pretraining, sampling, labeling, and aggregation)(Kong 等,2020),以及基于Transformer的AST(audio spectrogram Transformer)(Gong 等,2021b)等)进行特征提取,当然也可以继续在语音情感识别数据库上进行微调。受益于最近大规模无监督预训练的兴起,目前已有不少研究采用自监督学习的方式从大量未标注的语音数据中提取有用的音频表征并用于下游的情感识别任务,如MockingJay(Liu 等,2020),Tera(Liu 等,2020),wav2vec 2.0(Liu 等,2021;Baevski 等,2020b;Pepino 等,2021)等。此外,为了挖掘语音信号中的语义信息,也有一些研究同时结合声学信息和文本信息进行多模态语音情感识别的研究(Li 等,2021;Yoon 等,2019,2020)。
1.5.3 语音合成
目前语音合成研究主要集中在韵律建模、声学模型以及声码器等模型的建模之中,以提高合成语音的音质和稳定性,并提高在小样本数据集上的泛化性。具体地,谷歌Deepmind研究团队提出了基于深度学习的WavetNet(van den Oord 等,2016)语音生成模型。该模型可以直接对原始语音数据进行建模,避免了声码器对语音进行参数化时导致的音质损失,在语音合成和语音生成任务中效果非常好。2017年1月,Sotelo等人(2017)提出了一种端到端的用于语音合成的模型Char2 Wav,其有两个组成部分:一个读取器和一个神经声码器。读取器用于构建文本(音素)到声码器声学特征之间的映射;神经声码器则根据声码器声学特征生成原始的声波样本。本质上讲,Char2 Wav (Sotelo 等,2017)是真正意义上的端到端语音合成系统。谷歌科学家提出了一种新的端到端语音合成系统 Tacotron(Wang 等,2017b),该模型可接收字符的输入,输出相应的原始频谱图,然后将其提供给 Griffin-Lim 重建算法直接生成语音。此外,由于 Tacotron 是在帧层面上生成语音,所以它比样本级自回归方式快得多。研究人员进一步将Tacotron和WaveNet进行结合(Shen 等,2018),在某些数据集上能够达到媲美人类说话的水平。为了提高合成效率,一些声码器加速工作也有显著进展(Valin和Skoglund,2019;Yamamoto 等,2020)。
1.5.4 对话系统
对话系统从应用角度划分,可以分为任务型对话系统和闲聊型对话系统;从方法上划分,可以分为基于管道的方法和基于端到端的方法。基于管道的方法需要分别实现自然语言理解、对话管理和自然语言生成3个模块,最终形成一个完整的系统。这种模块级联的方式会导致误差传递问题,因此基于端到端的方法目前成为主流的对话系统方案。
为克服端到端对话系统中存在知识难以融入学习框架的问题,Eric等人(2017)引入键值检索网络整合知识库信息。Madotto等人(2018)提出了Mem2Seq(memory to sequence)模型,采用指针网络实现将知识库嵌入到对话系统中。Wu等人(2019)改进了Mem2Seq模型,提出GLMP(global-to-local memory pointer)模型,将外部知识融入对话系统之前进行过滤,并且加入了骨架循环神经网络机制生成对话模板。
除了基于文本的对话系统,学者们在多模态对话系统方面做了许多工作。Barbieri等人(2018)根据对话上下文预测emoji表情。Haber等人(2019)设计了一种对话系统,让用户使用自然语言与机器谈论给定的视觉内容。
1.6 多模态融合
如何将不同模态的信息在人机交互系统中有效融合,提升人机交互的质量,同样值得关注。多模态融合的方法可分为3种:特征层融合方法、决策层融合方法以及混合融合方法(Debie 等,2021)。3种融合方法如图13所示。特征层融合方法将从多个模态中抽取的特征通过某种变换映射为一个特征向量,而后送入分类模型中,获得最终决策;决策层融合方法将不同模态信息获得的决策合并来获得最终决策;混合融合方法同时采用特征层融合方法和决策层融合方法,例如可以将两种模态特征通过特征层融合获得的决策与第3种模态特征获得的决策进行决策层融合来得到最终决策。
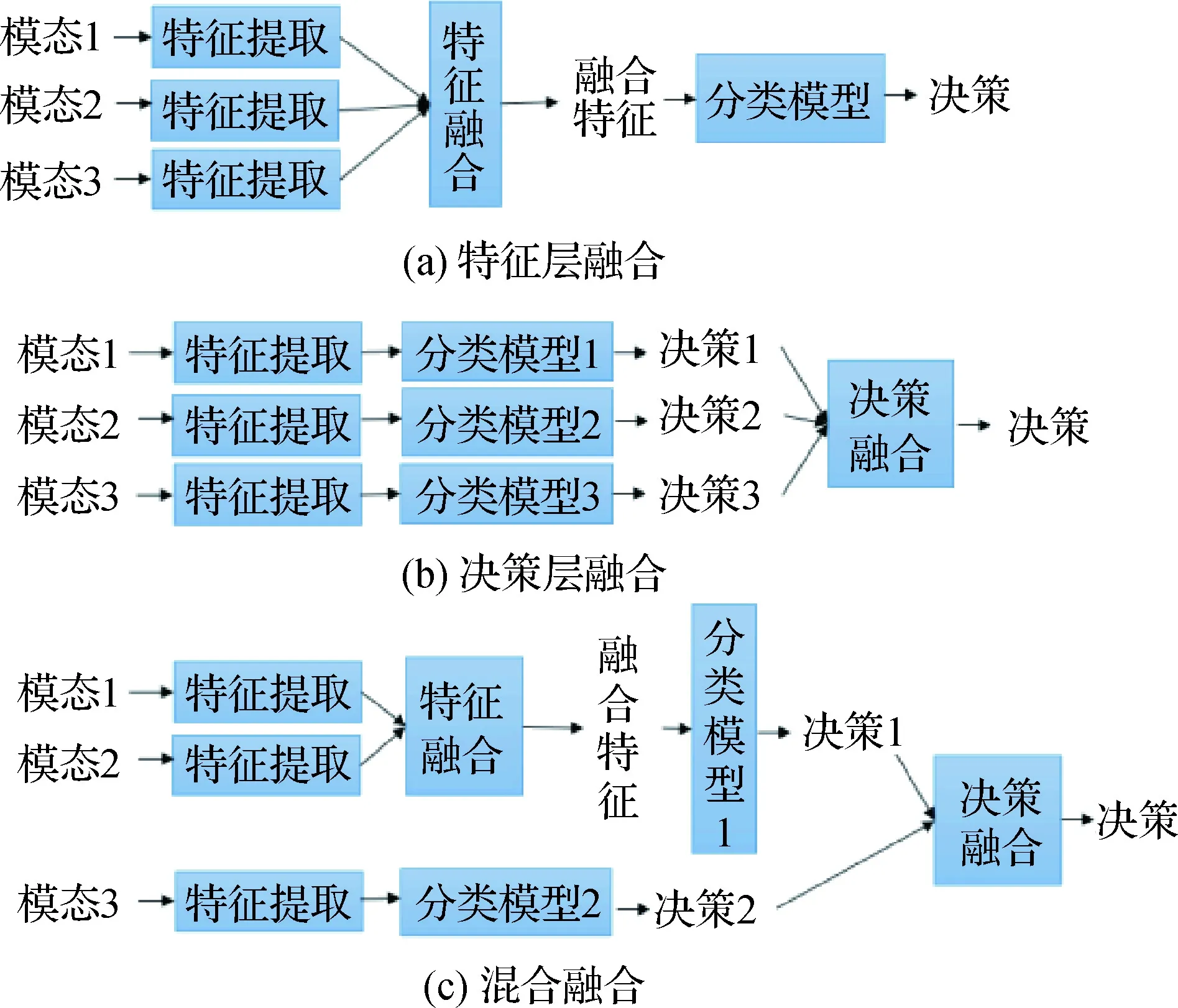
图13 3种不同的多模态融合方法Fig.13 Three different multi-modal fusion methods((a)feature level fusion;(b)decision level fusion;(c)hybrid fusion)
2 国内研究进展
2.1 大数据可视化交互
2.1.1 大数据可视化设计
在大数据可视化领域,国内的发展也已经逐渐走向成熟,每年都有许多可视分析系统不断涌现(Chen 等,2021;Wang 等,2021;Deng 等,2021)。近年,沉浸式大数据可视化得到了发展,浙江大学的Ye等人(2021)探索了如图14所示的无缝结合羽毛球比赛数据绘制的2D和3D可视化视图的问题,Chu等人(2022)探索了结合高度来凸显羽毛球数据中多个战术之间存在的差异性问题,如图15所示。由此可以看出,沉浸式大数据可视化对数据分析和展示问题提出了有效的解决方法。
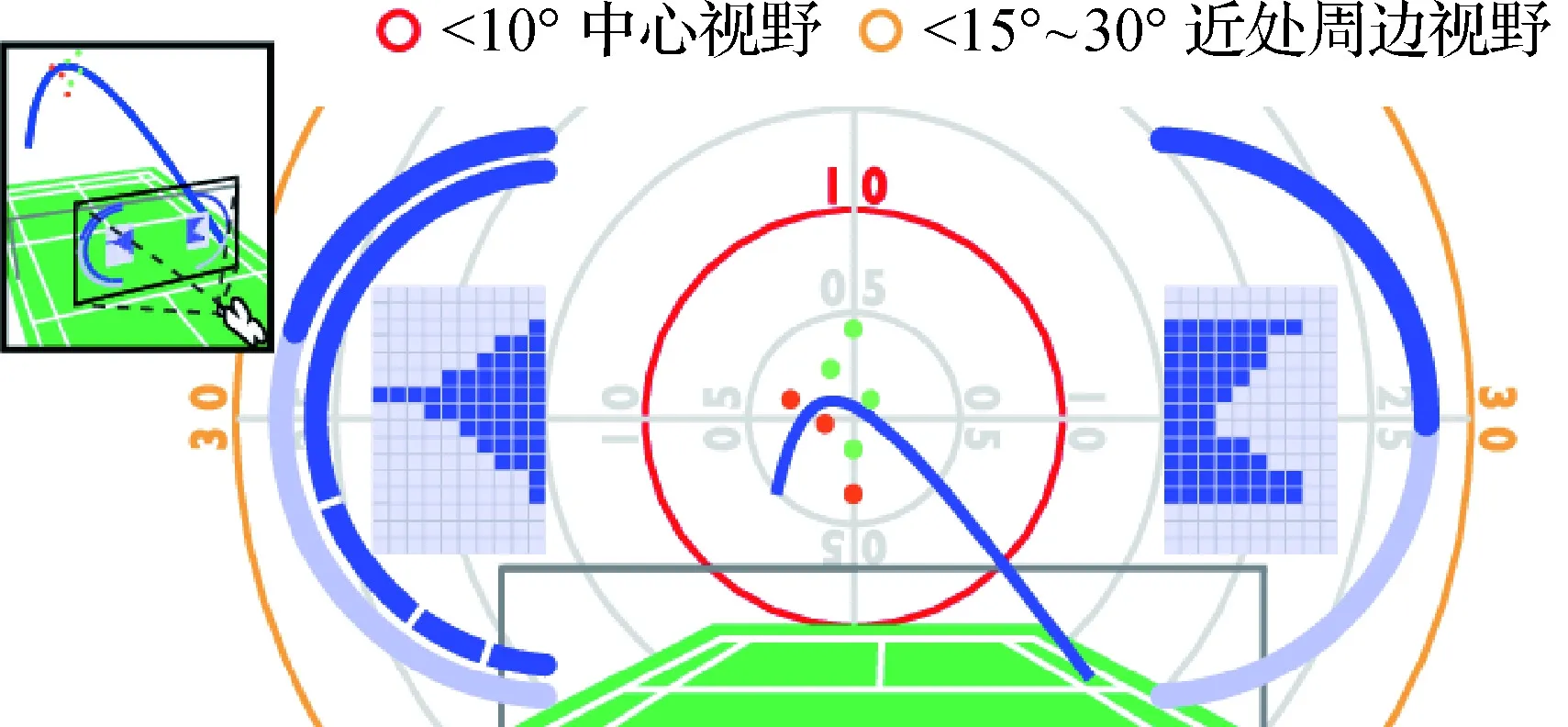
图14 2D和3D可视化结合的设计(Ye 等,2021)Fig.14 Design combining 2D and 3D visualization(Ye et al.,2021)

图15 3维羽毛球战术可视化(Chu 等,2022)Fig.15 3D badminton tactic visualization(Chu et al.,2022)
但是相比国外学者在沉浸式大数据可视化上的研究,国内仍处于起步阶段,所以接下来的发展还需要各高校继续深入研究。
2.1.2 非视觉感知的交互辅助
大数据可视化交互中,非视觉的感知交互方式以触觉最为常见。通过反馈力的大小与方向,用户可以使用触觉直观地感知到连续的高维数据信息。赵俭辉等人(2021)使用电磁力反馈设计了一种交互方法,并解决了虚拟手术中沉浸感不足的问题。如图16所示,用户在虚拟手术中操作的导丝可以获得真实手术环境下的多种反馈力,同时用户也获得了更逼真的手术体验,提高了术前虚拟训练的效果。在一部分沉浸式系统中,用户的3维感知也在分析中发挥了重要的作用。如图17所示,杭州师范大学的潘志庚等人(2021)通过一种数字对象和真实物体的孪生配准技术将虚拟世界中的物体渲染到真实世界中,从而将多种分析对象放置于分析者身旁。该技术充分利用分析者对于分析对象的3维感知。在教学实验中,该技术可以辅助参与者有效地进行磁感线的交互式学习。近几年,国内围绕嗅觉、听觉等通道的成果还较为匮乏并落后于国外。这些感知通道还需要研究者进一步探索其交互方式以及配套硬件设施。

图16 介入手术中导丝导管力反馈(赵俭辉 等,2021)Fig.16 Force feedback of guidewire during interventional surgery(Zhao et al.,2021)

图17 数字对象(左)以及渲染出的真实对象(右)(潘志庚 等,2021)Fig.17 Digital object (left) and the rendered real object (right)(Pan et al.,2021)
1)基于接触的交互。触控式大屏的出现对多人协同分析大数据可视化起到了促进的功能。仁光科技先后设计了13种自然交互对触控式的可视化大屏进行数据操作,例如手指触控、笔触触控,通过触控式交互可完成对数据的选择、可视化的拖拽缩放等。
2)基于手势的交互。西南科技大学的Wang等人(2020a)提出了一套基于手势的“所见即所得”的交互方式,可完成对体数据进行抓取移动等动作,与在真实场景里的交互动作一样。浙江大学的Ye等人(2021)设计了具象化的羽毛球挥拍隐喻用于飞行轨迹的筛选,羽毛球分析专家挥动VR手柄,根据空气动力学,系统会基于手柄的移动方向和移动速度模拟一条虚拟的羽毛球轨迹,并从已有数据中查询到与之相似的轨迹并进行分析。
3)基于注视的交互。视线追踪技术捕捉人们的视线焦点,可以代替手部对数据进行选择的操作行为,减少手部交互带来的疲劳。Hu等人(2021)提出的FixationNet可以根据人们的历史凝视位置、探索任务的对象以及用户的头部移动速度,预测其在VR中近期的注视情况,FixationNet提高了任务为导向的可视分析系统中用户的探索能力。
4)基于移动导航的交互。移动是沉浸式大数据可视化中最常用的交互之一,山东大学的Li等人(2020)提出了一种重定向行走方法,支持用户在物理空间中行走较小的距离,同时在虚拟环境里完成远距离的行走,解决了物理空间有限的问题。他们提出了一种基于Voronoi的方法来生成行走路径,并且采用重定位和曲率调整的静态图映射方法将虚拟空间的行走路径与物理空间进行映射,由此实现在物理空间中的连续移动,拓展了人们在沉浸式环境中的探索空间。
2.2 基于声场感知的交互
2.2.1 基于声场感知的动作识别
国内对于声场识别手势的研究相对较少。其中,国内学者提出的 PrivateTalk(Yan 等,2019)利用双耳耳机上的麦克风识别出了用户捂嘴时的语音,实现了语音交互唤醒的优化。魏文钊和何清波(2018)设计出了一套基于超声波识别手势交互的系统。
2.2.2 基于声源定位的交互技术
ReflecTrack(Zhuang 等,2021)利用工作生活中的反射面,使用智能手机上的双麦克风实现了22.1 mm精度的3维声学定位。该工作使用频率超出人耳听觉范围的FMCW声音信号,同时识别直接路径的声音信号和反射得到的声音信号,实现了只需要两个麦克风的声学定位技术。由于反射面在生活中很常见,基于该技术可以实现运动追踪和精细的手势识别等多种交互技术。FaceOri(Wang 等,2022b)利用任意智能设备的扬声器发出频率超出人耳听觉范围的FMCW声音信号,通过使用用户双耳佩戴的主动降噪耳机上的麦克风,利用超声波测距方法,创新头部相对智能设备的头部空间位置与角度的精准连续追踪技术,支持包括交互对象感知与健身动作识别等更加智能高效的人机交互技术。
2.2.3 基于副语音信息的语音交互增强
Qin 等人(2021)提出了基于单麦克风近距离风噪特征的凑近免唤醒语音交互技术ProxiMic,可用于手机手表耳机的手持或穿戴设备的凑近即说,该工作利用人距离麦克风近距离状态下说话的自然吐气特征,设计了基于风噪一致性的两步算法,用户轻声或气声亦可激活系统,具有私密性强、鲁棒性高和准确率高等特点。
2.2.4 普适设备上的音频感知与识别
国内在智能手机上的音频感知与识别研究较多,典型的如李凡等人(2021a,b)提出的两种在驾驶环境下进行音频感知与识别的工作:1)利用智能手机扬声器收集并基于自适应子带谱熵方法和神经网络进行驾驶环境下的呼吸道症状检测技术(李凡 等,2021a);2)利用智能手机扬声器与麦克风组成的声呐系统,基于物理原理实现车辆行驶速度的检测方法(李凡 等,2021b)。此外,陈超(2021)提出一种利用智能手机内置扬声器与麦克风实现对疲劳驾驶行为感知的检测技术。
2.3 混合现实实物交互
国内在被动力混合现实交互方面跟进较为迅速,与国际上的前沿水平相差不大。目前,虚拟现实用户主要通过视觉、听觉感知环境,而具有双向信息传递能力的触觉通道往往得不到支持。触觉呈现的功能缺失或位置精准度低下会造成用户对虚拟物体的感知失真,降低用户使用沉浸感。同时,触觉引导的欠缺也会导致用户交互效率大幅降低。北京理工大学、北京航空航天大学、中国科学院软件研究所和中国科学院大学等项目组,针对长时虚拟沉浸中的显触失配问题,提出了一系列基于被动触觉的虚实融合技术。
2.3.1 静态的被动力触觉
在静态的被动力触觉方面,Zhao 等人(2021)提出基于纹理感知特征的触觉信号采集方法,基于静电振动触觉显示技术及最小可觉差估计法的触觉感知信号量化、采集多通道纹理信息,并在此基础之上进一步提出基于静电力反馈的触觉渲染方法,提高虚拟纹理真实感。Guo 等人(2020)提出基于实例分割的被动触觉对象选择性渲染及特征化表达方法,平衡虚实融合系统中环境沉浸感与系统交互效能冲突,扩展虚实融合场景渲染自由度,实现虚实空间智能化融合。
2.3.2 相遇型被动力触觉及3种触觉设备
在相遇型被动力触觉方面,如图18所示,Jiang等人(2019b)提出了HiFinger方法。HiFinger是一种单手可穿戴的文本输入技术,可通过拇指对手指的触摸实现输入时的触觉反馈以及快速、准确、舒适地输入文本,适用于用户需要在虚拟环境中移动(如行走)的移动场景,有效地提供了一种混合现实环境中的输入解决方案。Zhang等人(2019)也开发了一种轻量的多指力反馈手套,通过一种在每个手指关节上使用分层干扰片的解决方案,在增强虚拟现实和远程操作系统的保真度方面具有巨大应用潜力。Li等人(2020)针对难以在虚拟环境中添加真实物体的问题,提出了一种基于连杆机构的原型框架HapLinkage。该框架提供了典型的运动模板和触觉渲染器,便于虚拟手动工具的代理设计。机械结构可以很容易地修改,能够轻松快速地为各种混合现实场景创建手动工具的原型,并赋予它们动力学和触觉特性。Xue 等人(2019)提出了MMRPet(modular mixed reality pet),一种可通过磁力组装的虚拟宠物交互装置,模拟逼真的被动力触觉。通过将虚拟宠物叠加在被跟踪的宠物实物上,兼具丰富的视觉信息和实物交互,同时宠物实物采用模块化的结构设计,各模块能够以不同方式相连接,构成不同形态结构的宠物实物,避免不同的虚拟宠物均需要一个单独的宠物实物作为被动力触觉反馈的提供者,使被动力触觉反馈方案更加灵活,同时赋予用户更多的交互自由。
2.3.3 产业界进展
在产业界,国内目前的发展较为迟缓,目前还没有非常完善的混合现实触觉解决方案。国内主要提供混合现实设备的公司,目前在触觉外设方面仍处于探索阶段。除HTC Vive的控制手柄之外,研究人员曾经提出过一种沉浸式地板。地板上安置有大量电动微型模块,它们会根据用户在混合现实中的内容改变地板的表面形状,提供一定的被动力反馈。此外,PPGun VR曾推出过一款枪型控制器,便于优化用户在虚拟环境中的射击体验。通过与主机相连的仿真步枪,用户可以真实地完成射击、填装子弹等一系列操作。但由于触觉代理对象种类繁多而且形状复杂,目前混合现实中的触觉并没有一套产业化的解决方案。
2.4 可穿戴交互
国内对可穿戴设备交互的研究主要集中在新型的传感技术来支撑手势、语音等交互行为,以及对交互意图理解和交互界面的优化等方向。中国科学院计算技术研究所陈益强团队从事普适计算的研究,包括用手表内置传感器进行用户手臂动作的捕捉,并依次进行用户动作建模及拓展其在空间环境里的交互场景(Wang 等,2019;Chen 等,2020b)。北京大学张大庆团队利用可穿戴设备和WiFi信号解析,对用户在空间中的动作和其自身的生理指标进行监测(Yang 等,2015;Wang 等,2016)。如提出一种基于转换的分割方法,利用一对接收器天线上的相位差方差作为显着特征,自动分割连续捕获的 WiFi 无线信号流中的所有跌倒和类似跌倒的活动。南京大学谢磊团队等对以可穿戴RFID(radio frequency identification)标签为基础的无线信号传感进行建模和解析,支持用户动作和行为的检测(Xie等,2010;Wang 等,2018)。系统中只在标签阵列后面部署一根RFID天线,持续测量标签阵列发出的信号,根据相应的信号变化识别手势,并将多根手指作为一个整体进行识别,然后提取多根手指的反射特征作为图像。
同时,国内的研究重视对人因元素的考虑和对用户行为的建模。清华大学史元春团队研究手表等小型触摸屏上的文字输入问题,通过新型的表盘界面设计与用户意图推理等技术的结合,创造出高效的文字输入技术(Yi等,2017;Han 等,2018)。要输入文本,用户可以转动表圈,用光标敲击圆形键盘上的键,为了最小化旋转距离,每个光标的位置在每次按键选择后根据需要下一个按键的概率进行动态优化。中国科学院软件研究所田丰团队在设备周围的手势交互技术实现和高效的适用于小屏幕的手表命令界面的设计等方面进行了创新(Han 等,2017,2018)。如一种新的手势是通过将屏幕上的一个角拖动到不同的方向和距离来执行的,每个角都映射到某个命令,并且可以卷曲/剥离以浏览命令下可用的值。Robin Bing-Yu Chen团队研究了用手掌和指间作为触摸界面在手势输入和文字输入等方面的应用(Huang 等,2016;Wang 等,2015)。该工作解决了两个人体工程学因素:手部解剖结构和触摸精度。手部解剖结构限制了拇指的可能运动,这进一步影响了交互过程中的身体舒适度。触摸精度是一个人为因素,它决定了用户可以如何精确地操作设置在手指上的触摸小部件,以及小部件的有效布局。清华大学史元春团队同时在触控、手势和语音等多模态输入通道下交互行为优化和自然等方面做出创新(Qin等,2021)。如用户可以将嵌入麦克风的设备放在嘴边,并直接对着设备说话,而无需使用唤醒词或按下按钮,为了检测靠近麦克风的语音,系统使用了用户说话并向麦克风吹气时观察到的爆音的特征。
2.5 人机对话交互
2.5.1 语音识别
国内与国外针对语音识别的研究整体趋势是趋同的,但是在聚焦的技术方面还是存在一定的差异。国内的实验研究也紧跟低延迟语音识别和低资源语音识别两个方向。
针对低延迟语音识别方面,国内以中科院、清华大学和西北工业大学为代表,围绕非自回归语音识别模型做了不少探索性的工作;在流式语音识别方面,国内划分成3种思路:1)字节跳动公司、腾讯公司和中国科学院自动化研究所对Transducer模型进行了实用化的改进,提升识别速度和准确率(Huang 等,2020b;Tian 等,2019,2021b;Tian等,2021a);2)百度公司聚焦于使用CTC(connectionist temporal classification)模型对连续编码状态进行切分,然后使用注意力模型进行解码,先后提出了SMLTA(streaming multi-layer truncated attention model)和SMLTA2(http://research.baidu.com/Blog/index-view?id=109);3)中国科学院自动化研究所、出门问问公司和阿里巴巴公司尝试实现将流式模型和非流式模型统一到一个框架中(Tian 等,2020;Zhang 等,2020b)。
受限于计算资源和数据规模,国内高校科研单位对于自监督与无监督语音识别的研究偏少,这部分研究主要集中于企业,有京东公司、字节跳动公司、猿辅导和滴滴,其工作偏向跟随和扩展性质,其代表工作包括SCALA(supervised contrastive learning)和BERT(bidirectional encoder representations from Transformers)的变体(Jiang 等,2019a,2021;Fu 等,2021)。
2.5.2 语音情感识别
国内语音情感识别的研究早期阶段也集中在区分性语音情感特征的提取以及分类器的设计(Sun 等,2021;赵力 等,2004;金学成,2007)。如,东南大学的赵力团队(Sun 等,2021)在2004年提出了一种利用全局和时序结构的组合特征以及MMD(modified Mahalanobis distance discriminant)进行语音情感特征识别的方法。而后受益于深度学习的发展,一些新型的深度神经网络逐渐用于语音情感识别并取得了不错的效果,包括深度信念网络(韩文静 等,2008)、基于高效通道注意力的CRNN(convolutional recurrent neural network)(韩文静 等,2014)和Sinc-Transformer (戴研研 等,2021)等。在数据库建设方面,中国科学院自动化研究所录制了CASIA(Institute of Automation, Chinese Academy of Sciences)汉语情感语料库,该数据库涵盖了4位录音人在纯净录音环境下以5类不同情感演绎的9 600句语音。
2.5.3 语音合成
在语音合成领域,国内研究与国际基本保持一致。为了提高模型的鲁棒性,百度公司提出了 Deep Voice和支持多说话人的Deep Voice 2(Ark 等,2017),它通过相应的神经网络代替传统参数语音合成流程中的每一个组件。为了提高模型在小数据上的泛化性(Jia 等,2018),中国科学院自动化研究所等科研机构通过将目标说话人的韵律与音色进行解耦(Wang 等,2020b),提高模型的泛化性,在小数据集的目标说话人上表现良好。国内各大互联网厂商也陆续推出基于个性化语音合成的算法服务,有助于语音合成推广到更加广泛的领域。
2.5.4 对话系统
针对融合知识的端到端对话系统,哈尔滨工业大学的研究人员改进了Mem2Seq(Madotto 等,2018)模型中存在的实物生成不一致的问题(Qin 等,2019),并且提出动态融合网络(Qin 等,2020)以提高对话系统的集外迁移能力。中国科学院自动化研究所的研究人员(Chen 等,2019)提出采用一种心理学模型将外部知识与端到端对话模型进行有机融合。
针对多模态对话系统,山东大学的研究人员(Cui 等,2019)提出UMD(user attention guided multimodal dialog system)模型,利用多模态编码器和解码器分别编码多模态话语和生成多模态响应。中国科学院计算技术研究所的研究人员(Debie 等,2021)建立一种开放域多模态对话数据集,推动了多模态对话系统的发展。
3 国内外研究进展比较
3.1 大数据可视化交互
在大数据可视化交互中,由于是在传统可视化的基础上发展起来,面向可视化设计、交互设计的研究比较早,研究成果相对成熟,但受限于平面化的展示空间与交互空间。沉浸式技术的发展拓展了数据的呈现,支持数据的3维可视化,由此释放了人们的立体视觉。受益于硬件技术的进步,非视觉的交互技术陆续提出并用于辅助视觉交互。头戴式设备、触摸式大屏和传感器的发展,为多模态可视化交互创造了可能性。国内外研究进展对比见表1。

表1 大数据可视化交互国内外研究进展对比Table 1 Comparison of domestic and foreign research progress on big data visualization interaction
最早沉浸式可视化是在IEEE VIS(Visualization conference) 2014年的研讨会上提出,自此,国外有大量学者开始探索沉浸式可视化,并提出了系列的可视化设计、基于不同感知通道的交互设计(Siu 等,2020;Prouzeau 等,2019;Patnaik 等,2019)以及多模态融合的交互设计,例如澳大利亚莫纳什大学的Tim Dwyer教授带领的团队对沉浸式地图可视化交互提出了系列工作,包括利用高度编码起讫点流图(Yang 等,2019)、对地图视图进行操作的基于接触的交互设计(Yang 等,2021b)等,巴西南大河联邦大学的Jorge Wagner为时空轨迹可视化的探索提出了虚拟桌面的隐喻(Filho等,2019)、对轨迹移动旋转筛选的一整套手势交互设计(Wagner 等,2021)。
然而,国内的大数据可视化交互研究主要集中在传统的平面式可视分析中,沉浸式交互集中在工业场景应用中,沉浸式可视化的发展带动了国内学者对可视化交互的研究。浙江大学巫英才团队开展了羽毛球轨迹分析(Ye 等,2021)与战术分析(Chu 等,2022)的工作,将羽毛球轨迹还原在3维空间中,利用挥拍隐喻对轨迹进行筛选,通过小倍数图布局对包含时序信息的战术数据进行展现,提高了专家数据探索的能力。相较于国外,国内基于不同感知通道的交互设计研究较为滞后,其中围绕听觉、嗅觉等通道的成果尤为匮乏。
总体而言,国内外在传统的大数据可视化交互的研究上较成熟,在基于多模态交互的沉浸式可视化的研究中,国外学者的工作较为多样,国内学者的研究较为单一,但是考虑到沉浸式可视化仍处于发展阶段,国内和国外的学者应该相互学习,推动该领域共同发展。
3.2 基于声场感知的交互
国内外研究进展见表2。

表2 基于声场感知的交互国内外研究进展对比Table 2 Comparison of domestic and foreign research progress on interaction based on sound field
在基于声场感知的动作识别方面,国内的研究相对较少,而国外对于利用耳机、腕带和手表等可穿戴设备进行动作识别有更加充分的探索。应用麦克风和陀螺仪等传感器,既实现了精细的手势交互动作,也对用户与其他物品的交互方式进行了研究。关于基于声源定位的交互技术,国内近期的相关工作减少了定位所需的麦克风数量,使日常场景下基于耳机和智能手机的定位成为可能。国外研究则对利用不同声学测距方法实现交互技术进行了更广泛的探讨,在被追踪设备主动和被动发声两个方向都进行了探索。在基于副语音信息的语音交互增强方向,国内近期工作实现了智能设备的凑近即说;国外研究则以多种方式利用语言中的非语言信息,加强了人机间的语音互动。对于普适设备上的音频感知与识别技术,国内工作主要集中于利用智能手机上的扬声器和麦克风来进行识别,但基于其他设备的研究较少;国外工作在利用手机、腕部设备等实现生理感知和环境识别等方面都有涉及。整体而言,国内在基于声场感知的交互技术方面虽然近些年发展较快,但是整体在技术深度与应用广度上仍然落后于国际先进水平。
3.3 混合现实实物交互
国内外进展见表3。总体而言,国内外在混合现实中的被动力触觉方向,研究进展较为类似,但研究重点略有不同。在科学研究中,国际上在相遇型触觉方面,通过使用一个或多个机器人协同控制,实现动态模拟交互空间的变化方面有着明显的优势。国外的机器人产业比较发达,可用的触觉代理往往多种多样,比如各种大小的机器人、小车和无人机等。此外,由于更高精度的定位设备的研究比较成熟,国际上对于大范围空间的交互进行了更多研究,而国内的研究往往是在用户面前的较小范围。国内的研究更关注于交互装置,以及如何通过单一、简单的交互装置来实现多种形式的触觉。通过少量或者简单的触觉代理,实现更为复杂的功能。除此之外,国内已经完成了相当一部分交互的测试工作,具有一定的参考价值。在产业界,国际上已经有了手部可穿戴式、全身可穿戴式和腕部携带式3种比较主流的产品,可提供力反馈甚至热反馈,有丰富的触觉交互内容。然而国内产业几乎没有混合现实触觉的解决方案,因此在触觉方面的设备比较少。伴随着虚拟现实中触觉技术的不断发展,相信国内产业界将在此方面有一定进展。

表3 混合现实实物交互国内外进展比较Table 3 Comparison of domestic and foreign research progress on mixed reality physical interaction
3.4 可穿戴交互
国内外研究进展见表4。

表4 可穿戴交互国内外研究现状Table 4 Comparison of domestic and foreign research progress on wearable interaction
3.5 人机对话交互
国内外研究进展见表5。

表5 人机对话交互国内外研究进展对比Table 5 Comparison of domestic and foreign research progress on human-machine dialogue interaction
4 结 语
本文系统综述了多模态人机交互的发展现状和新兴方向,深入梳理了大数据可视化交互、基于声场感知的交互、混合现实实物交互、可穿戴交互和人机对话交互的研究进展和国内外研究进展比较。针对每项研究内容的发展趋势与展望如下:
4.1 大数据可视化交互
在大数据可视化交互中,可视化设计的研究发展较早,成果比较成熟,然而如何利用人们的多感知通道提出交互设计,以增加对数据可视化的理解促进研究,是目前的研究热点之一。触觉、听觉等感知辅助可以减轻数据遮挡带来的观察不便,但是这又可能带来用户移动交互上产生的空间范围小、易发生碰撞等问题。因此,各模态的交互组合、适用的分析任务以及效率问题仍有待探索。
另外,由于目前设备的固有限制,人们在做出交互行为时,低精度的识别算法会影响分析效率,同时当人们长时间佩戴头戴式设备时,会出现疲惫与不适感。识别算法的提高、无形的交互动作和有形用户界面的合理结合以及设计可以减轻用户疲劳的手势组合,也是未来需要攻克的问题。
4.2 基于声场感知的交互
智能手机、手表和耳机等普适设备持有量持续快速增长,利用这些设备进行声场感知来提升用户的交互体验将成为一种趋势。现有工作主要面向单一设备开展研究,对跨设备的联合感知研究相对匮乏。然而,跨设备感知可以有效地扩展感知通道,实现对交互意图在感知能力上的提升,因此,基于跨设备分布式声场感知的交互技术将会是一个新的发展趋势。此外,类似智能耳机、智能音箱等设备的大规模使用,空间中麦克风具有常开特性,如何实现隐私保留的全域感知(全屋感知等)将成为另一个发展方向。利用房间中的声音信号,既可以实现实时的手势识别、运动追踪,也可以对人的生理信号、健康状况进行监测。使多种设备连结起来共同感知人和环境、实现跨设备的交互技术,将减少交互路径、使交互体验更加自然高效。
4.3 混合现实实物交互
基于被动力触觉的混合现实交互,就交互对象而言,是从单一的静态交互物体,逐渐向多个物体、多样化物体、可移动的交互对象、可变形的交互装置以及可提供动态力反馈的方向发展。
受益于科技的发展,多模态同步混合现实很有可能发展为混合现实中人机交互的主要模式。多模态同步混合现实是虚拟世界与现实世界相结合的统一概念,为理解和设计连接虚拟世界和现实世界的各种系统提供了一些思路。系统将被动力触觉和主动力触觉相结合,可以给用户更好的交互体验。交互的触觉代理会更小型化、更易获得、甚至就是日常生活中常用的物品。综上所述,触觉反馈在混合现实中有着重要的地位,并在未来有着很大的应用前景。
4.4 可穿戴交互
智能穿戴设备正逐步成为普适计算的载体和方式之一,朝着微型化、集成化、依赖无所不在的实时网络和传感器获取数据、通过大量数据的实时采集和计算分析、通过增强的视觉和触觉感官及认知体验来实现设备与用户、设备与环境、以及用户与环境之间的自然交互发展。面对智能穿戴技术迅猛发展和用户需求增加,必须提升已有的智能穿戴人机交互技术,拓展新的交互通道和交互方式,拓宽人机数据沟通渠道,增强设备采集和处理生物信号能力,探索高效自然的关键交互原则和交互技术。
4.5 人机对话交互
语音识别方面,自回归语音识别模型能够极大地降低系统的延迟,在非流式识别场景具有重要的应用价值,但是性能还有待提升;噪声、多说话人和说话人重合等复杂场景下的语音识别准确率需要进一步提高。语音合成方面,现有语音合成技术主要存在两方面的挑战:一是自然口语声音的伪造很难接近真人;二是资源受限条件下伪造声音的自然度和可懂度下降明显。进一步提高自然口语声音的合成自然度和提升资源受限条件下合成声音的音质是语音合成的未来发展趋势。在语音情感识别方面,学习范式上从监督学习逐渐过渡到基于大规模无标注数据进行预训练的无监督学习。对话系统方面,多模态预训练模型(Fei 等,2021)蓬勃发展,将多模态预训练模型的强大表征能力与对话系统结合,来提高多模态对话系统的性能将是未来值得探索的方向。
致 谢本文由中国图象图形学学会人机交互专业委员会组织撰写,该专委会更多详情请见链接:http://www.csig.org.cn/detail/2490。
猜你喜欢
汽车实用技术(2022年10期)2022-06-09
汽车实用技术(2022年9期)2022-05-20
工业设计(2022年4期)2022-05-17
师道·教研(2022年1期)2022-03-12
海外星云(2021年6期)2021-10-14
科学大众·小诺贝尔(2020年4期)2020-07-20
智富时代(2019年7期)2019-08-16
智富时代(2019年7期)2019-08-16
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
