
基于深度学习的模糊测试策略研究
2022-07-01 08:17周安民
现代计算机 2022年8期
肖 玮,周安民,贾 鹏
(四川大学网络空间安全学院,成都 610065)
0 引言
软件技术在给人们带来便利生活的同时,也带来了潜在的信息安全问题。作为计算机安全重要的一部分,软件安全指在受到恶意攻击的情况下软件依然能够正确运行,以及确保软件能在授权范围内被合法使用的思想。与之相对的则是软件中存在的漏洞。
通常在一般情况下漏洞不会影响程序功能,但如果攻击者加以利用,就有可能使之执行攻击者编写的恶意代码进而危害用户的信息安全。因此漏洞检测在软件和系统安全中起着至关重要的作用,模糊测试技术作为一种有效的漏洞挖掘技术,得到了广泛的研究和应用。自1990年Miller 等提出了第一个模糊测试工具后,逐渐发展出了许多有效的方法和框架。近年来的研究通过引入污点分析和符号执行等一些新技术,提高了模糊测试的效率,并且在软件程序中发现了许多漏洞。
目前最流行的灰盒模糊测试工具AFL 根据二元组(跳转的源地址,目标地址)来记录执行分支信息,从而获取目标程序的执行流程和代码覆盖情况。AFL 首先从初始种子队列中选择种子进行一系列变异,将变异后的测试用例作为输入文件执行目标程序。如果程序发生崩溃则将测试用例收集到触发crash 的文件集合中,否则根据记录的分支覆盖信息判断该测试用例是否探索到新的路径分支,执行到新路径的测试用例将被加入种子队列等待变异。其策略基于代码覆盖率反馈扩充种子队列,随着覆盖率的提升种子队列越来越长。如果对每一个种子都进行充分的变异,将会耗费大量的时间并且效率很低。因此AFL 在种子队列中动态维护了一个能覆盖当前探索路径的最小集合,选择执行快且体积小的种子并标记为favored。这个集合大大缩小了AFL 需要重点变异的种子范围,同时标记了种子的优先级,保证AFL 优先选择执行更快和规模更小的种子进行变异。
这种策略使AFL 可以在有限时间内执行更多的输入文件,但实验表明AFL 的测试通过率不足30%。AFL 只是考虑了种子的一些局部特征,但种子的质量与许多特征有关,如关键字段校验值、种子的信息熵以及种子的特定长度等。目前的策略对种子的结构特征考虑不足,如何有效地利用这些特征判定种子的质量是一个关键问题。
为了聚合种子中各维度的结构特征并对种子质量进行一个综合判定,本文提出了一种基于深度学习的模糊测试策略。该方法通过学习模糊测试前期的输入文件和执行效果来预测种子的优劣,使具有更多有利于提升覆盖率特征的种子有更大的概率被选中变异。
本文的主要贡献是提出了一种基于深度学习的输入文件分类方法,学习输入文件结构中的高层特征,预测输入文件的覆盖率提升情况。基于这种分类方法本文改进了AFL 的模糊策略。在模糊测试中使用深度神经网络模型判断种子价值,选择高价值种子优先进行变异,结果表明,该方法提升覆盖率和发现崩溃的能力均优于AFL。
1 相关工作
根据深度学习在模糊测试中解决的问题,目前的研究主要集中在:种子文件生成、测试用例生成、测试用例过滤、变异算子选择和可利用性分析。其中在测试用例生成方面的研究较多,而在种子选择中使用深度学习的研究较少。
Wang 等利用深度神经网络LSTM 从大量有漏洞和没有漏洞的程序路径中学习隐藏的易受攻击特征,训练一个预测模型来分类路径是否存在漏洞。然后对能够覆盖易受攻击的程序路径的测试用例进行优先执行,并为这些测试用例分配更多的能量,产生更多的变异输入。Chen 等使用监督学习用于自适应和种子调度,根据在相同或相似程序上做出的种子调度决策中学到的知识,确定哪些新种子将产生更好的效果。Lyu 等收集触发唯一崩溃或新路径的输入文件作为训练数据,生成有效的文件作为种子。Godefroid 等基于神经网络使用样本输入训练适合模糊测试生成输入的语法。Wang等利用从大量现有输入中学习到的知识来生成新的输入。Böttinger 等使用强化学习产生高价值的新输入Rajpal 等设计了基于AFL 的静态模型,利用LSTM 模型来预测输入中关键的字节,并根据以前的模糊经验变异这些字节以最大化边缘覆盖。文献[9]通过训练过的神经网络预测测试用例是否会触发新状态的转换,如果不能触发状态转换则会丢弃该测试用例,只执行能触发状态转换的测试用例;文献[10]训练神经网络预测输入在执行路径分布上的熵,优先执行模型不能确定其执行路径的输入。Zong 等基于定向模糊测试框架AFLGo 设计,通过不断更新模型并且使用更新后的模型对被过滤的测试用例进行再过滤,保证了模型的精确度和低假阴性率。在非定向模糊测试中,使用深度学习进行测试用例过滤的时间开销和训练模型在长期模糊测试中的表现并不匹配。
2 基于深度学习的模糊测试策略
基于深度学习的模糊测试框架的结构如图1所示,包括训练数据准备、模型训练和模型预测。在训练数据准备阶段,通过模糊测试目标程序收集大量的测试用例。同时获取每个测试用例的覆盖率状态,并对比初始覆盖位图记录该测试用例的覆盖率提升情况。预处理以上数据生成向量化的训练数据,然后训练一个深度神经网络模型。在模型预测部分利用模型预测种子队列中的种子文件,选择预测效果好的种子优先进行变异测试。

图1 基于深度学习的模糊测试框架的结构
2.1 数据获取
由于不同的目标程序接受的输入文件类型各不相同,本文对输入文件进行统一编码,可以直接想到的方案是按字节编码,即向量元素为范围[0,255]之间的数据,长度为输入文件的字节长度。在fuzzguard 中就采用了这种方案,将每个字节的值看作一个量值,这样就忽略了目标程序将输入文件的有些比特位作为状态值处理的情况。因此本文对输入文件的二进制表示进行处理,即将文件的每个比特位映射到输入向量的每个元素上,这样对不同程序的多种格式输入可以使用统一的方法进行处理。输入文件被编码为序列=<,,…,>,其中是输入的字节长度,x= bit,x∈{0,1}。每个输入的标签使用一个二维向量表示,提升覆盖率的输入标签为<0,1 >,未提升覆盖率的输入标签为<1,0 >,即=<,>,y∈{0,1} 。
AFL 将程序发生跳转时的基本块二元组进行计算,作为一条边的索引值。有两种情况的测试用例会被保留到种子队列中,一种是发现未探索到的边,另一种是已探索到的边执行次数量级增加。种子队列只保存首次触发以上两种情况的输入,这些输入数目很少,通常与程序的复杂程度(边数量)成正比。在模糊测试到一定阶段后,程序很难发现新的边,种子队列数目也会停止增长。这会造成训练数据不平衡的问题,影响到最终模型的预测效果。为了解决这个问题,将所有与已收集种子覆盖边相同的输入标签设为<0,1 >,即使用所有提升了初始覆盖率的输入作为正样本数据。
由于变异的随机性,AFL 会产生一部分重复的输入文件(约10%~20%),输入模型将会影响训练的效果,因此本文对收集到的原始数据进行了去重操作。
2.2 模型训练
设计了数据和标签的表示后,需要选择一个深度学习网络。通常情况下测试用例是大小不定的文件,这意味着输入网络的向量是一个长度不确定的序列,并且目标程序可能会依次处理这些数据。循环神经网络(Recurrent Neural Network,RNN)可以处理变长序列数据,目前已经成功应用在自然语言处理领域。输入的二进制格式也可以近似成一种语言来用RNN处理,但RNN 在处理较长序列时会出现梯度消失和梯度爆炸问题。长短期记忆(long short-term memory,LSTM)是一种特殊的RNN,较RNN 更高效稳定,能够在长序列中有更好的表现。LSTM结构的主要输入输出如图2所示。

图2 LSTM结构的主要输入输出
在LSTM 内部结构中,由当前输入x和上一个状态传递的h获得一个拼接向量,通过训练得到四个状态、z、z、z,拼接向量乘以权重矩阵后,由Sigmoid 激活函数得到0 到1 之间的数值,作为门控状态z、z、z,由tanh激活函数得到-1到1之间的数值,作为输入。
在实际的训练中,细胞节点有很多个,需要训练的参数随着神经网络层次的不断加深也越来越多。考虑到复杂的神经网络训练时间成本过高的问题,本文采用一层LSTM 网络结构,将输入序列切分为128位的数据块输入网络。
深度学习与传统机器学习方法的不同在于它能够自动学习特征,深度神经网络的训练就是在进行特征学习和寻找最优参数。在训练过程中模型不断地更新参数,使损失函数趋于收敛。本文训练的模型执行的是一个二分类任务,因此选择损失函数为二分类交叉熵,其定义为:
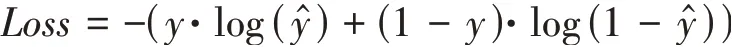
其中,̂是模型预测样本是正例的概率,是样本标签,如果样本属于正例,取值为1,否则取值为0。 为了使模型更好地收敛,本文使用Adam优化算法。
2.3 模糊测试策略改进
输入序列经过LSTM 层和线性层后输出两个节点,通过激活函数得到该输入属于标签中某一类的概率。在多次训练之后得到能够准确预测输入类别的模型,使用该模型来指导种子选择。
具体算法流程如算法1 所示,本文在AFL的模糊测试策略上做出了改进。AFL 从维护的种子队列中选择种子大小和执行时间乘积最小的种子优先测试,种子队列中其余种子有很小的概率被随机选中变异测试。这是出于提升模糊测试速度的考虑,但种子提升覆盖率的效果与种子大小和执行时间并没有直接的关系。本文提出的模糊测试策略本质上是基于种子的结构特征决定种子的优先级,种子的关键结构特征能直接影响是否通过重要分支执行到更深的路径。

3 实验评估
本文基于AFL2.57b 实现,加入数据集获取模块和种子选择模块实现了本文提出的方法,选取了真实的目标程序和LAVA-M 测试集中的程序进行实验评估。
在深度神经网络层的构建中,本文选择了PyTorch,它是2017年Facebook 人工智能研究院(FAIR)团队在GitHub 上开源的深度学习框架。PyTorch 具有简洁高效的优点,同时PyTorch 具有的易用性和社区活跃度使它在各类场景中都有丰富的应用。
3.1 实验环境
模糊测试实验在64 位ubuntu16.04 系统中完成,内存为8 G。模型训练在Nvidia 2080Ti GPU上进行,内存为12 G,超参数设置如表1所示。

表1 超参数设置
3.2 模型准确率分析
实验首先选取地目标程序bmp2tiff、tiff2 pdf、gif2png、readelf 分别进行数据集收集、预处理和训练得到模型,对应的损失曲线和模型在测试集上的准确度如图3所示。

图3 深度学习模型的损失曲线和准确度(续)

图3 深度学习模型的损失曲线和准确度
模型准确度和损失在训练20 轮后趋于稳定, 并且预测准确度在95%以上。训练模型得到最终稳定的准确率如表2。对比文献[9]中的实验结果,本文在预测准确率上有一定的提高,这对模型的应用效果有至关重要的影响。
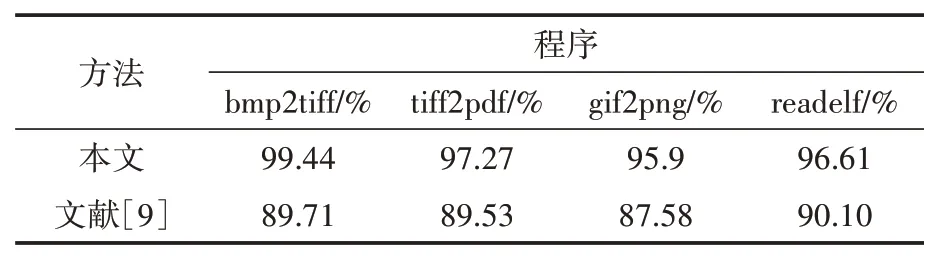
表2 模型得到最终稳定的准确率
3.3 模糊测试性能分析
为了评估本方法的有效性,在选取的目标程序gif2png、base64、who、size 中进行了12 个小时的模糊测试,记录了代码覆盖率和发现crash 数量,代码覆盖率即AFL 中测量的边覆盖率。在相同的实验环境和时长下对AFL 进行了测试,实验结果见表3。

表3 代码覆盖率和发现crash数量
在这4 个目标程序中,gif2png、tiff2ps、mupdf 和size 的测试覆盖率均有提升, gif2png、base64、who 和size 发现的crash 数量有提升,gif2png 的覆盖率和发现crash 数目提升最为明显。
以上分析表明,使用输入的二进制结构和覆盖率变化状态进行训练的模型指导种子选择能够较好地提高模糊测试的效果,增加探索到的新路径,并为发现更多的crash提供可能性。
4 结语
本文简述了基于深度学习进行模糊测试的基本原理和构架,以真实的目标程序作为实验对象,进行了训练数据收集、模型训练、模型预测、策略改进和实验评估,结果分析验证了模型的可行性和实用性。未来将会进一步研究深度学习理论, 提高模型对种子效果的预测能力,从而进一步提高代码覆盖率与发现漏洞的可能性。
猜你喜欢
今日农业(2022年15期)2022-09-20
价值工程(2018年3期)2018-01-23
试题与研究·高考理综生物(2016年4期)2017-03-28
计算机应用(2016年9期)2016-11-01
百科知识(2015年18期)2015-09-10
小星星·阅读100分(高年级)(2015年4期)2015-05-26
意林(2010年13期)2010-05-14
新媒体研究(2009年24期)2009-07-05
现代电子技术(2009年6期)2009-05-31
雕塑(1996年4期)1996-07-12
