
命名实体识别技术在“数字敦煌”中的应用研究
2022-06-30 01:49巩一璞王小伟王济民王顺仁
敦煌研究 2022年2期
巩一璞 王小伟 王济民 王顺仁







内容摘要:命名实体识别是自然语言处理基础任务之一。针对“数字敦煌”项目应用命名实体识别技术存在的实体边界难以确定等问题,通过构建小规模敦煌石窟专有名词数据集,对基于BERT-BiLSTM-CRF的命名实体识别基本方法,和基于Multi-digraph的词汇增强方法进行了实验对比,结果表明基本方法已具备较高的识别准确率,而基于词汇增强的方法对未登录词识别效果提升显著。最后将训练得到的模型应用于“数字敦煌”资源库命名实体识别任务,证明了方法的有效性。
关键词:命名实体识别;BERT;LSTM;词汇增强;数字敦煌
中图分类号:K854.3 文献标识码:A 文章编号:1000-4106(2022)02-0149-10
Practical Research of NER Technology in the “Digital Dunhuang” Project
GONG Yipu1,2,3,4 WANG Xiaowei1,2,3,4 WANG Jimin5 WANG Shunren1,2,3,4
(1. Dunhuang Academy, Dunhuang, Gansu 736200;
2. National Research Center for Conservation of Ancient Wall Paintings and Earthen Sites, Dunhuang, Gansu 736200;
3. Key Scientific Research Base for Conservation of Ancient Wall Paintings of NCHA, Dunhuang, Gansu 736200;
4. Research Center for Conservation of Cultural Relics of Dunhuang, Dunhuang, Gansu 736200;
5. Swiss Federal Institute of Technology in Lausanne, CH-1015 Lausanne, Swiss)
Abstract:Named Entity Recognition(NER) is one of the basic tasks of NLP studies(Natural Language Processing). The purpose of this study is to determine the entity boundaries in the NER tasks of the“Digital Dunhuang” project, and to construct a small-scale proper noun dataset for terms relevant to Dunhuang. By comparing the basic methods of NER, which are based on the BERT-BiLSTM-CRF model, with a vocabulary enhancement methodology based on a multi-digraph model, research shows that the basic NER strategy achieves an acceptable recall score, while the method based on vocabulary enhancement provides a noticeable improvement to the recognition of unlogged vocabulary words. Finally, after a period of training the model was applied to the “Digital Dunhuang” NER task and proved to be a highly effective methodology.
Keywords:NER; BERT; LSTM; vocabulary enhancement; Digital Dunhuang
一 引 言
敦煌石窟内容博大精深,具有丰富的历史、艺术、科學、社会、文化价值。当前,随着数字人文研究的兴起,将新技术融入敦煌学研究已成为一个热点。命名实体识别作为自然语言处理基础任务之一,是指利用计算机程序对文本中出现的人名、地名、机构名以及专有名词术语进行自动识别并分类,是信息抽取的重要环节[1]。针对敦煌石窟保护、研究工作积累的海量数字化文献资源开展命名实体识别技术研究,一方面可用于各类文本内容的关键词提取和结构化处理,实现文本数据的分析挖掘;另一方面,也可用于“数字敦煌”项目实体链接、智能检索、个性化推荐、知识图谱等服务,通过知识重构进一步提升检索能力;此外,将命名实体识别技术与敦煌壁画数字化图像相结合,通过跨媒体计算,开展图像语义理解研究,可以实现对敦煌壁画内容的自动描述,从而进一步挖掘壁画价值。因此,开展命名实体识别技术在敦煌石窟的应用研究具有重要意义。
当前,在通用命名实体识别领域,采用纯数据驱动的深度学习方法,从大规模公开语料中学习文本语义信息,已经取得了较好的识别效果[2-4]。然而在数字人文领域,相关研究依然较少。哈佛大学利用文本挖掘技术构建了中国历代人物传记资料库[5],武汉大学采用人机协同的方式构建了敦煌壁画主题词表[6],上海图书馆利用命名实体识别技术挖掘馆藏数字化资源[7],但这些成果多数采用基于规则匹配的方法或面向通用领域的自然语言处理工具,对于一些专业词汇分词准确率不高,需要人工进行审核。近年来,针对古汉语、少数民族语言等领域,有学者通过构建专用数据集,开展了基于深度学习的命名实体识别模型研究,也取得了一些研究成果[8-13]。但是,总体来看,缺乏开放共享的专业语料库,依然是制约数字人文领域命名实体识别研究的主要因素。
与通用命名实体识别工作相比,数字人文等特定领域命名实体识别,因行业数据准备不充分,主要存在实体边界难以确定、未登录词识别困难等两方面的问题。针对中文实体边界的确定,通用命名实体识别方法可通过中文分词工具或公开语料训练得到较为准确的词语边界识别模型,但是在特定领域,由于待识别实体往往就是领域内的专有名词术语,所以仅使用公开数据集以及通用方法很难准确界定词语边界。另一方面,针对特定领域的未登录词或不断出现的新词,已有模型并未学习过此类词汇的特征,因此也很难正确识别。对于以考古、宗教、历史、文保等题材为主的敦煌石窟研究文献和出版物而言,其涵盖领域专有名词类别庞杂、数量众多,但由于缺乏相关研究,目前还未形成统一的语料标注规范以及标准的命名实体识别数据集。如果对这些文本数据仅使用通用命名实体识别工具进行识别,很难取得理想效果。
针对上述问题,本文通过文献调研分析,选择BERT-BiLSTM-CRF模型作为命名实体识别基本方法,同时考虑到敦煌学研究领域已经形成《敦煌学大辞典》等权威著作,因此选择基于Multi-digraph的词汇增强方法作为对比模型,验证二者在敦煌石窟命名实体识别任务中的实际效果。文章首先构建了一个小规模的敦煌石窟专有名词数据集作为训练语料,并对两种方法的选型依据及工作原理做了介绍;之后利用本文数据集将两种模型从多个维度进行了实验对比,验证了本文方法在敦煌石窟命名实体识别任务中的适用性及有效性;最后将上述方法在“数字敦煌”资源库中进行了实际应用,结果表明本文方法有效扩充了“数字敦煌”资源库实体链接覆盖范围,通过洞窟文字内容的结构化呈现,提升了系统检索能力。
二 相关工作
命名实体识别遵循自然语言处理技术变迁历程,从早期基于“词典+规则”的方法过渡到统计机器学习模型,当前处于神经网络模型阶段。这一阶段的发展主要得益于互联网上不断丰富的大数据资源以及词向量模型的提出。词向量是表达单词含义的低维向量,传统机器学习方法依赖人工选择特征构建特征向量,存在高维向量数据稀疏以及特征包含语义信息不完整等情况。使用词向量技术不仅可以解决以上问题,而且从异构文本中也可获取统一向量空间下的特征表示,因此相比传统特征构建方法更具优势。2013年,Google团队提出了Word2vec词向量计算工具,实现了对不同词间相似和类比关系的向量表达[14]。将词向量作为文本特征,利用RNN、CNN等深度神经网络进行命名实体识别,是当前的基本方法。由于传统RNN模型存在梯度消失和爆炸等问题,于是产生了以LSTM[15]为代表的RNN变体,有效解决了RNN缺陷。使用双向LSTM网络来建模上下文语义,在此基础上使用CRF网络建模标签序列,二者结合在命名实体识别任务中取得了较好效果[2],得到了广泛应用。
传统词向量模型虽然解决了词的语义表达问题,但由于上下文无关,因此无法实现多义词的动态表征。2018年华盛顿大学提出的ELMo模型使用一个双向LSTM网络预训练获得上下文相关的语义表示,实现了对词的复杂特征以及多义词的建模[16]。之后OpenAI提出GPT预训练模型,使用Transformer解码器代替LSTM更好地捕获了长距离语言结构,有效提升了模型能力[17]。Google公司基于上述研究提出了BERT预训练模型,该模型使用双向Transformer编码器作为网络结构,同时提出掩码语言模型和预测下一句两个新的无监督学习任务,通过在海量语料中训练,实现了更好的上下文语义建模,最终在11个自然语言处理任务中取得了当时最好成绩[3]。
BERT等预训练模型实现了词的动态语义表达,但是,针对中文特定领域面临的问题,还需要对相关方法做进一步提升。一种思路是使用特定领域大量无标注语料资源预训练BERT等语言模型,之后针对下游具体任务设计特定神经网络并使用少量标注数据对模型进行微调,实现更好的识别效果[18]。但是,该方法需要极高的数据量和算力做支撑,阻碍了其在特定领域的应用。另一种思路是在神经网络模型中加入词典等人工特征,利用外部知识增强模型对词语边界及未登录词的识别能力。考虑到中文特定领域通常拥有较为权威的行业词典等资源,因此,词汇增强的命名实体识别方法更为实用。
近年来,词汇增强的命名实体识别方法主要有动态模型设计和编码层词汇嵌入两个研究方向。其中, Lattice LSTM[19]、LR-CNN[20]、CGN[21]等方法通过设计动态模型融入词汇信息,有效提升了命名实体识别准确率,但普遍存在计算复杂度较高或可迁移性差等问题。与上述方法不同,编码层嵌入是指以字向量嵌入为基础,同时通过不同方法嵌入外部词汇信息,然后接入通用序列標注模型,实现词汇增强效果,如WC-LSTM[22]、Multi-digraph[23]等方法。其中,WC-LSTM方法存在词典信息缺失问题,Multi-digraph方法使用一种有向多图数据结构来捕获词典增强信息,同时使用上下文对来自不同词典的信息进行加权融合,解决了词典匹配冲突的问题。
基于上述分析,当前深度神经网络与动态词向量技术相结合是命名实体识别建模的主流方案,与此同时,词汇增强的命名实体识别方法也可以有效提升模型准确率。但上述技术在敦煌石窟是否适用,能否在实际业务数据上取得较好的识别效果,还有待进一步的实践检验。
三 数据和方法
1. 研究数据
(1)数据来源
本文选取敦煌石窟公共网发布的莫高窟、榆林窟等文化遗产中54个洞窟的内容介绍作为实验语料,共计46211字,对其中专业领域命名实体进行人工标注,构建训练数据集。
此外,本文将探索词汇增强的方法对敦煌石窟命名实体识别任务的提升效果,选择《敦煌学大辞典》作为词汇数据来源,共计5858个词条。
(2)实体类别
敦煌学作为一门综合性学科,相关文献资料中通常包含宗教、历史、艺术、考古、建筑等多个领域的专业词汇,因此,在数据集标注时,对于实体边界和实体类别的定义,需要邀请领域专家进行专题研究,制定相关分类规范。考虑到本文侧重于命名实体识别技术在敦煌石窟的适用性研究,因此,本文通过对待标注文本内容分析,仅将语料中的命名实体简单划分为三个类别,分别是“历史朝代”“人物称谓”和“专有名词”。三者对应文本类别标签分别定义为“TIME”“PER”和“PRO”。
历史朝代:包括洞窟开凿年代、历史事件发生时期等时间名词。这类名词通常表述形式丰富,导致实体边界较难确定。例如“前秦苻坚建元二年”中既包含朝代,同时还有君主名称以及年号等信息,但总体上还是指一个特定历史时期,因此本文将类似情况总体标注为“历史朝代”。
人物称谓:包括各类宗教人物及形象的称谓、历史人物名称、敦煌学相关人物名称等,例如“罗睺罗”“须阇提”。这类名词多来源于梵语或史书记载,较为生僻,同时部分无标准译名,不同文献可能存在多种汉字表达,通用命名实体识别方法很难准确识别,本文将这类名词统一标注为“人物称谓”。
专有名词:该类别包含内容较为丰富,既有壁画内容描述,如“兜率天宫”“忉利天”等,又有壁画名称如“维摩诘经变”“劳度叉斗圣变”,此外,对于洞窟形制描述也归于此类,如“覆斗顶”“中心塔柱”等。由于这类名词多为各领域专业词汇,较为晦涩,且表述形式多样,存在词边界确定以及未登录词识别困难问题,因此将这类术语统一标注为“专有名词”。
(3)实体标注
命名实体识别属于序列标注任务,常用序列标注方式有BIO和BIOES两种,二者形式相近,本文选择BIOES标注方案。具体标注类别及实体标签如表1所示。
在对命名实体进行标注之前,首先对原始文本进行预处理。根据原始文本句子长度分布统计,将全部训练语料切分为911个句子,每个句子占一行,最大长度为128字。之后根据实体类别定义对语料集进行人工标注,标注完成后,对数据格式进行调整,以满足模型输入要求。最终敦煌石窟命名实体识别数据集中标注“历史朝代”实体537条,“人物称谓”实体370条,“专有名词”实体4266条。
(4)数据集划分
为了满足实验要求,将标注完成的数据集划分为训练集、验证集和测试集,三者分别占全部标注数据的65%、17.5%和17.5%。其中,根据测试集中标签在训练集中出现的比例,设计细分了“测试集—高”和“测试集—低”两个不同的集合,分别对应测试集中75%的标签出现在训练集中和测试集中10%以下的标签出现在训练集中,用于检测模型对未登录词的识别效果。
(5)词典构建
针对本文词汇增强方法,对《敦煌学大辞典》收录词条进行处理,构建实体词典。为了与本文构建数据集相匹配,对《敦煌学大辞典》中部分词条进一步人工分词,然后将全部词条按“历史朝代”、“人物称谓”和“专有名词”三类进行划分,同时从互联网检索补充部分“历史朝代”数据,最终得到“历史朝代”词条60个,“人物称谓”词条932个,“专有名词”词条5686个,作为基础词典。此外,为了检验词典准确性对模型效果的影响,将本文数据集中全部标注实体按照实体类别构建精简词典,该词典仅包含出现在数据集中的实体,其中“历史朝代”词条95个,“人物称谓”词条76个,“专有名词”词条1169个。同时,将各标注实体扩充至对应基础词典,构成扩充词典,该词典中包含所有来自《敦煌学大辞典》的实体以及所有出现在本文数据集中的实体,扩充后“历史朝代”词条95个,“人物称谓”词条954个,“专有名词”词条5794个。
2. 基于BERT-BiLSTM-CRF的基本方法
当前主流基于深度神经网络的中文命名实体识别模型包括字符编码层、序列建模层和标签预测层。本节针对每一层择优选择技术方案,构建基于BERT-BiLSTM-CRF的敦煌石窟命名實体识别基本方法。
字符编码层:主要是将句子中的每个字符或词语映射到一个固定维度的稠密向量空间。对于中文特定领域命名实体识别任务,由于采用词语级向量编码存在中文分词错误传播问题,因此本文采用基于字符级别的向量编码作为基本输入特征。在字符级向量技术选型方面,动态词向量技术可以根据上下文语境实现多义词的动态表征,因此本文选择BERT预训练模型作为文本向量化方案。
序列建模层:经过字符编码层输出的字级别特征向量序列直接传入序列建模层,学习句子级别语义及结构信息。LSTM神经网络可以通过门控机制保证时序信息的长距离传播,是一种经典的序列建模模型[2]。因此本文采用主流BiLSTM作为序列建模层网络结构,对于输入序列中当前位置字符,分别通过正反向LSTM网络输出双向隐藏状态,然后将两个隐藏状态向量连接,即可提取到当前字符的上下文语义及结构信息。
标签预测层:序列建模层能够为标签预测提供足够的上下文信息,但却无法建模标签之间的依赖关系,为此,通常在标签预测层使用CRF对网络进行优化。CRF能够计算标签间的转移概率并输出全局最优标签序列,因此可以进一步提升本文命名实体识别任务准确率。
以句子“中晚唐的维摩诘经变”为例,如图1所示,经过字符编码层对输入句子中每个字生成相应字向量,之后输入BiLSTM层建模上下文序列,最后将结果输入标签预测层,通过CRF网络得到每个字的预测标签。
3. 基于Multi-digraph的词汇增强方法
虽然BERT-BiLSTM-CRF模型在当前主流命名实体识别任务中取得了较好效果,但是,通过对本文构建的数据集进行分析发现,各实体类别中均只有少数实体被经常使用,绝大多数实体标签使用频率很低,这会在一定程度上造成模型在训练过程中的边际效应,即模型比较容易达到一个可接受的结果,但想要进一步提升模型表现却很困难。因此,根据前文分析,本节选择基于Multi-digraph的词汇增强方法,作为与上一小节基本方法的对比,借助《敦煌学大辞典》等领域专用词典,来探索外部知识对模型未登录词识别能力的提升效果。
基于Multi-digraph的词汇增强方法序列建模层和标签预测层与基于BERT-BiLSTM-CRF的基本命名实体识别方法相同,区别在于Multi-digraph方法提出在字符编码层采用一种有向多图数据模型,来建模输入字符和与之对应的实体词典信息,最终将该有向多图输入一个改造后的GGNN图神经网络,构造具有统一特征表达空间的特征向量[23]。
以句子“维摩诘所说经又名净名经”为例,每个字符代表有向图中的一个节点,则句子可以表示为S={vc1,…,vc11}。假设词语“维摩诘”来自于佛教人名词典PER,“维摩诘所说经”和“净名经”分别来自于两个不同的专业词典PRO1和PRO2,则模型需要额外6个节点D =,其中,上标表示该节点对应的专业词汇词典,下标为s表示开始节点,下标为e表示结束节点,这样每2个节点为一对,用来记录句子中与该词典匹配到的每个实体的开始位置和结束位置。之后为节点之间添加有向边,除了对句子中每个邻接字之间从左向右添加一条有向边外,同时对每个在词典中匹配到的命名实体,从D中对应的实体开始节点到S中该实体所含每个节点,最后到D中实体结束节点添加有向边。例如词语“维摩诘”对应S中的vc1,vc2,vc3,则会构建以下边:(,vc1),(vc1,vc2)(vc2,vc3)(vc3,),每个边与一个实体类别标签关联,再利用这些边构建对应标签的邻接矩阵,从而完成有向图的构建。此外,由于经典的GGNN网络只能针对单一的图,并不适用于面向不同标签构建的多图结构,因此,Multi-digraph方法通过拼接不同标签所对应的邻接矩阵,并通过统计将不同标签的贡献系数,以权重的方式赋值在对应邻接矩阵特定边上的方式对该网络做了改进,使模型能够学习到来自不同词典信息的加权组合。
基于Multi-digraph的词汇增强方法通过这种有向多图的数据结构,利用图神经网络自动编码外部词典信息,之后将特征向量输入BiLSTM-
CRF网络提取上下文语义及结构信息,最终完成实体标签预测。
四 实验分析及技术应用
1. 实验设计及评价指标
为了检验本文基于BERT-BiLSTM-CRF的基本命名实体识别方法以及基于Multi-digraph的词汇增强方法在敦煌石窟相关语料中的适用性以及实际效果,本章基于前述敦煌石窟命名实体识别数据集,设计并开展以下实验:1)针对本文提出的基本方法,分别使用静态词向量和动态词向量作为字符编码方案,以BiLSTM-CRF为网络结构,验证动态词向量技术在本文命名实体识别任务中的优越性;2)实验对比基于BERT-BiLSTM-
CRF的命名实体识别基本方法和基于Multi-digraph的词汇增强方法,探究词汇增强方法对命名实体边界确定和未登录词识别的提升作用。
本文采用命名实体识别任务常用的精确率P、召回率R和F1值作为模型评价指标。其中精确率P代表了预测结果中识别正确的命名实体数量占全部预测结果的比例;召回率R代表了预测结果中预测正确的命名实体数量占该句中命名实体实际数量的比例;F1值是模型精确率和召回率的一种加权平均。
2. 运行环境及实验过程
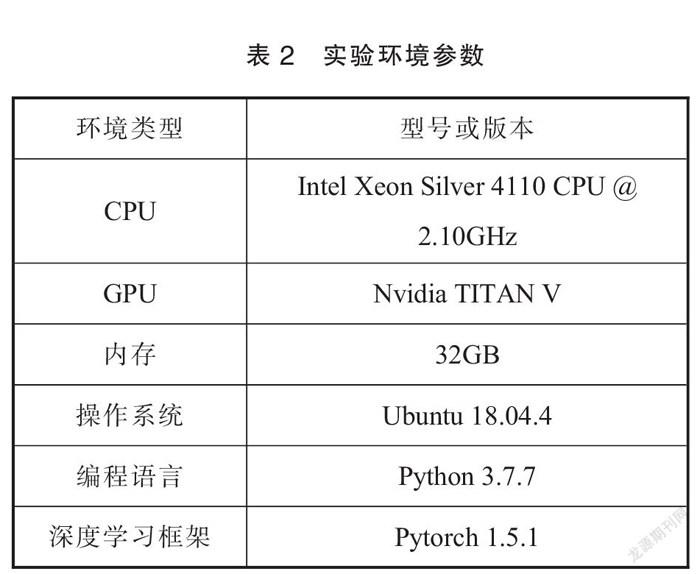
本文实验运行环境如表2所示。
根据实验设计,本文提出的四个对比模型分别为Word2vec-BiLSTM-CRF、BERT-BiLSTM-
CRF、Word2vec-MultiDic-BiLSTM-CRF以及BERT-
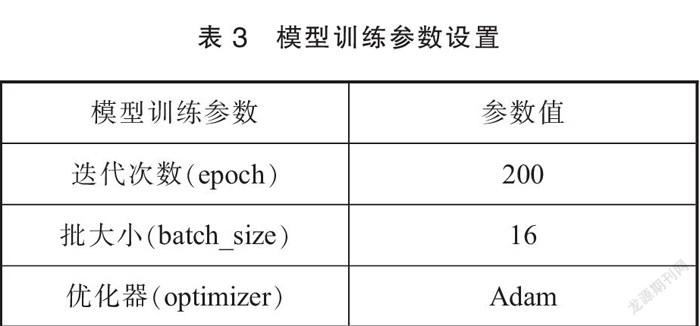
MultiDic-BiLSTM-CRF。其中Word2vec字向量使用“Chinese Word Vectors”项目[24]基于百度百科预训练的字向量,特征向量维度为300维;BERT模型使用Google公司发布的“BERT-Base, Chinese”预训练模型,特征向量维度为768维;MultiDic表示词汇增强的方法,词典数据分别使用第三章第一节介绍的基础词典、扩充词典和精简词典。对于词汇增强的模型,原文[23]中仅基于静态词向量开展了相关实验,本文对该模型做了简单修改,将其与BERT预训练模型进行适配,并对使用两种字向量的模型效果进行了对比。模型序列建模层和标签预测层均采用相同的BiLSTM-CRF结构,主要训练参数如表3所示。
为了使模型最优,在训练时针对每个模型选择不同隐藏层大小,同时Adam优化器也会根据训练过程自动调节学习率。以BERT-MultiDic-BiLSTM-CRF模型为例,如图2所示,在200个训练周期中,当隐藏层为1400时,模型损失函数不断震荡,无法收敛,而当隐藏层大小为256时,模型的损失值不断减小并趋于稳定,在较小的训练周期实现了收敛,因此,将该模型的隐藏层大小确定为256。
3. 结果分析
实验第一部分针对本文命名实体识别基本方法,开展Word2vec-BiLSTM-CRF与BERT-BiLSTM-CRF模型的对比实验,验证基于BERT的动态词向量技术对本文任务的提升作用,实验结果如表4所示。
从实验结果看,基于BERT动态词向量的命名实体识别模型在本文任务中效果优于传统静态词向量方法。在“测试集—高”上,提升效果并不显著,这主要是因为该测试集与训练集的标签重叠率较高,使得模型能够尽可能多地学习到该实体在句子不同位置以及不同语境下的信息,增加了模型的鲁棒性,弥补了静态词向量相对于BERT缺乏上下文信息的缺点。而在“测试集—低”上,包含大量未登录词,虽然两种字符编码方案效果均不理想,但是,由于BERT在上下文语义建模方面的优势,使其相对静态词向量模型效果有较大幅度的提升。
实验第二部分开展基本方法与词汇增强方法的对比实验,用于检验词汇增强方法对本文任务的提升效果,其中,词汇增强方法分别使用本文构建的基础词典、扩充词典和精简词典。实验同时使用Word2vec静态词向量和BERT动态词向量作为字符编码方案进行对比,最终实验结果如图3所示。
从结果看,基于BERT的动态词向量编码方法总体上优于传统静态词向量方法,但是就词典的增强效果而言,对本文任务提升最为显著的还是在未登录词较多的“测试集-低”上,且基于传统静态词向量的模型提升幅度更大。在该测试集上,使用Word2vec静态词向量时,利用基础词典、扩充词典和精简词典使本文任务F1值较基本方法分别提升6%、16%和34%;而在使用BERT詞向量时,三种词典对本文任务F1值分别提升2%、3%和24%。之所以词典增强方法对静态词向量模型效果提升更明显,主要是因为基于BERT的模型已经较为充分地学习了前后文信息,使模型具备较高的识别精度,因此,词典对其增强作用难以凸显。但是,综合来看,即便使用精简词典,基于BERT词向量的模型还是比静态词向量模型F1值高出14%。在“测试集—高”的实验结果上,也可以看到类似现象。
由此可见,字符编码方案的选择是影响模型最终识别效果的重要因素之一,同时,在未登录词较多的场景中使用基于词汇增强的方法也可以较好地提升模型效果,其中词典的精度是影响模型准确率的又一重要因素。随着词典精度的提升,模型识别效果不断提高。在本文实验中,未登录词较多的“测试集—低”在使用基于BERT词向量及精简词典的词汇增强方法后,其F1值已经接近于“测试集—高”在使用基于BERT-BiLSTM-CRF的基本方法时的识别结果,二者仅相差7%左右。这是因为词汇增强方法中词典精度的提升将使模型更加信任词典数据,当词典变得非常精确,与当前任务数据高度契合时,模型对实体边界的判定及未登录词的识别精度也将达到非常高的水准。
4. 技术应用
根据实验结果,将本文训练得到的命名实体识别模型在“数字敦煌”资源库进行了初步应用。本文选取莫高窟第285窟文字简介{1}作为识别语料,使用实验结果最好的BERT-MultiDic-BiLSTM-CRF词汇增强模型进行命名实体识别,对识别结果进行简单处理,构建了以洞窟编号和实体为节点,以实体类型为边的图数据结构,并使用Neo4j数据库进行数据管理,可视化效果如图4所示。
与“数字敦煌”资源库当前内链实体相比,通过本文命名实体识别技术应用,较为全面地提取了洞窟内容介绍中的各类专业名词术语,极大地丰富了内链词库,与此同时,也实现了洞窟内容的结构化呈现,有效提升了系统检索能力。而结合本文命名实体识别技术,通过进一步实体关系挖掘,构建敦煌石窟知识图谱,可以实现实体之间更深层次和更长范围的关联,优化资源库内容推荐、检索等服务质量,提升资源库知识发现能力。
五 总结及展望
本文针对“数字敦煌”命名实体识别任务存在的实体边界难以确定以及未登录词识别困难等两方面问题,通过文献调研,分别提出基于BERT-
BiLSTM-CRF的命名实体识别基本方法和基于Multi-digraph的词汇增强方法。文章通过构建一个小规模的敦煌石窟专有名词数据集作为训练语料,将本文选择的两种模型从多个维度进行了实验对比。结果表明,本文基本方法已具备较高的识别准确率,而基于词汇增强的方法对未登录词识别提升效果显著。文章最后将实验训练得到的模型应用于“数字敦煌”资源库命名实体识别任务,证明了本文方法的有效性。
通过本文研究,未来可以从数据、算法以及技术应用三个方面进一步开展此项工作。在数据方面,本文存在标注数据集规模太小、标注不准确等问题,因此,后续工作首先应该结合敦煌学专家意见,制定敦煌石窟专有名词标注规范,进而构建完善的专有名词数据集;此外,本文实验表明在基于词汇增强的方法中,词典的精度对任务识别准确率有较大影响,因此应该基于《敦煌学大辞典》等权威著作,进一步构建准确、完备的词典数据库。在算法方面,应该及时关注本领域最新研究进展,不断优化模型设计,实现在小规模数据集上更好的识别效果,同时也应该关注模型计算效率及模型部署等实际应用中面临的问题。在技术应用上,一方面可以结合实体关系提取任务,构建敦煌石窟知识图谱,实现知识结构化表达以及关联分析;另一方面,也可以与敦煌石窟数字化图像结合开展图像语义理解研究,实现壁画内容自动描述。总之,期望通过上述研究可以进一步提升敦煌石窟数字化资源的知识发现能力,更好地挖掘石窟艺术价值。
参考文献:
[1]刘浏,王东波. 命名实体识别研究综述[J]. 情报学报,2018(3):329-340.
[2]Lample G,Ballesteros M,Subramanian S,et al. Neural architectures for named entity recognition[C]. north american chapter of the association for computational linguistics,2016:260-270.
[3]Devlin J,Chang M,Lee K,et al. BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding[J]. arXiv:Computation and Language,2018.
[4]Cui Y,Che W,Liu T,et al. Pre-Training with Whole Word Masking for Chinese BERT[J]. arXiv:Computation and Language, 2019.
[5]Harvard University,Academia Sinica,Peking University.China Biographical Database[EB/OL]. https://projects.iq.harvard.edu/cbdb,2020-10-15.
[6]武汉大学. 敦煌壁画主题词表[EB/OL]. http://dh.whu.edu.cn/dhvocab/home,2020-10-15.
[7]朱武信,夏翠娟.命名实体识别在数字人文中的应用——基于ETL的实现[J]. 图书馆论坛,2020(5):16-20.
[8]崔丹丹,刘秀磊,陈若愚,刘旭红,李臻,齐林. 基于Lattice LSTM的古漢语命名实体识别[J]. 计算机科学,2020(S2):18-22.
[9]任明,许光,王文祥. 家谱文本中实体关系提取方法研究[J]. 中文信息学报,2020(6):45-54.
[10]朱顺乐. 基于深度学习的维吾尔语命名实体识别模型[J]. 计算机工程与设计,2019(10):2874-2878,2890.
[11]董瑞,楊雅婷,蒋同海. 融合多种语言学特征的维吾尔语神经网络命名实体识别[J]. 计算机应用与软件,2020(5):183-188.
[12]孔祥鹏,吾守尔·斯拉木,杨启萌,李哲. 基于迁移学习的维吾尔语命名实体识别[J]. 东北师大学报(自然科学版),2020(2):58-65.
[13]丽丽. 蒙古文化知识图谱的构建与研究[D]. 内蒙古大学,2020.
[14]Mikolov T,Chen K,Corrado G S,et al. Efficient Estimation of Word Representations in Vector Space[C]. international conference on learning representations,2013.
[15]Sundermeyer M,Schlüter R,Ney H. LSTM neural networks for language modeling[C]//Thirteenth annual conference of the international speech communication association. 2012.
[16]Peters M E,Neumann M,Iyyer M,et al. Deep contextualized word representations [C]. north american chapter of the association for computational linguistics,2018:2227-2237.
[17]Radford A,Narasimhan K,Salimans T,et al. Improving language understanding by generative pre-training[J].2018.
[18]Lee J,Yoon W,Kim S,et al. BioBERT:a pre-trained biomedical language representation model for biomedical text mining[J]. Bioinformatics,2019(4):1234-1240.[19]Zhang Y,Yang J. Chinese NER Using Lattice LSTM[C]. meeting of the association for computational linguistics, 2018:1554-1564.
[20]Gui T,Ma R,Zhang Q,et al. CNN-Based Chinese NER with Lexicon Rethinking.[C]. international joint conference on artificial intelligence,2019:4982-4988.
[21]Sui D,Chen Y,Liu K,et al. Leverage lexical knowledge for chinese named entity recognition via collaborative graph network[C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing [EMNLP-IJCNLP]. 2019:3821-3831.
[22]Liu W,Xu T,Xu Q,et al. An Encoding Strategy Based Word-Character LSTM for Chinese NER[C]. north american chapter of the association for computational linguistics,2019:2379-2389.
[23]Ding R,Xie P,Zhang X,et al. A Neural Multi-digraph Model for Chinese NER with Gazetteers[C]. meeting of the association for computational linguistics,2019:1462-1467.
[24]Li S,Zhao Z,Hu R,et al. Analogical reasoning on chinese morphological and semantic relations[J]. arXiv pre-print arXiv:1805.06504,2018.
