
基于CNNBN的水果图像检测算法
2022-06-28 03:18:16张睿敏杜叔强周秀媛
兰州工业学院学报 2022年2期
张睿敏,杜叔强,周秀媛
(兰州工业学院 计算机与人工智能学院,甘肃 兰州 730050)
基于深度学习的图像目标检测算法已经得到广泛应用,但对于复杂场景方面的检测仍然存在很多未能解决的问题。例如,未训练目标对数据的依赖,数据集不充足等。传统的目标检测的步骤是:图像预处理、特征提取和模式分类[1],而果实图像背景复杂,并且干扰因素多、分布密集、小目标检测难,这严重影响了检测的效果。
本文以水果图像为例,在卷积神经网络CNN(Convolutional Neural Networks)算法检测基础上在最后一个卷积层之后、激活函数之前插入BN(BatchNorm)层,针对数据特点设计训练方案,使用BN算法对图像数据进行批规范化处理,这种方式会减小图像之间的绝对差异,突出相对差异,能够加快分类效果和训练速度。
1 CNN图像特征提取
1.1 CNN卷积层运算
在经典的模式识别方法中,如基于HOG、Gabor等局部特征的图像检测,有基于全局特征的图像检测[2],不管是基于局部特征还是全局特征,事先要手工对图像进行预处理。而CNN能够自动提取图像特征,CNN 网络主要有2个算子,一个是卷积层,另一个是池化层(Pooling)。卷积神经网络CNN提取图像特征首先要进行卷积操作。将一张图像看作是一个个像素值组成的矩阵,那么对图像的分析就是对矩阵的数字进行分析,而图像的特征,就隐藏在这些数字规律中,在卷积层内通过滑动窗口,在滑动窗口之内做卷积运算[3]。假设1副图像信息用7×7的矩阵表示,使用一个3×3的卷积核(filter)进行卷积,得到一个3×3的矩阵,把这个矩阵叫做特征映射,卷积过程如图1所示。

图1 卷积运算
首先对图像的每个像素进行编号,用χi,j表示图像的第i行第j列元素;对Filter的每个权重进行编号,用ωm,n表示第m行第n列权重,用ωb表示filter的偏置项[4];对Feature Map的每个元素进行编号,用αi,j表示Feature Map的第i行第j列元素[5];用f表示激活函数(这个例子选择ReLU函数作为激活函数),然后使用公式(1)计算卷积,即
(1)
对于Feature Map左上角元素α0,0来说,其卷积计算方法为
这样依次可以计算出Feature Map中所有元素的值,在图像特征提取过程中不同的卷积核提取不同的特征,图像在通过卷积运算后会得到图像的特征映射[6]。
1.2 像素匹配
在CNN进行图像特征提取时,如果图像经过了变形、旋转等基本操作后,CNN如何能够提取到正确的特征呢?具体提取方法如图2所示。

图2 图像像素
图3中有如上a、b、c三个features特征矩阵,其中像素值1代表白色,像素值-1代表黑色,CNN取3个特征矩阵在图像的像素图中通过滑动窗口进行匹配,特征a矩阵可以匹配到图像像素图的左上角和右下角,特征b矩阵可以匹配到图像像素图的中间交叉部分,特征c矩阵则可以匹配到像素图的右上角和左下角。因此,把3个特征小矩阵可以作为卷积核,每一个卷积核在图像上进行滑动,滑动一次就进行一次卷积操作[7],得到一个特征矩阵Feature Map,然后求其平均值,让所有的特征值回归到-1到1之间[8]。当使用全部卷积核进行卷积操作之后,平均值越接近1表示对应位置和卷积核代表的特征越接近,越是接近-1,表示对应位置和卷积核代表的反向特征越匹配,而值接近0的表示对应位置没有任何匹配或者说没有什么关联。
当图像为RGB或ARGB(A代表透明度)时,可以在多通道进行卷积操作[9],或对于堆叠卷积层来说,池化层之后可以继续接下一个卷积层,对池化层多个Feature Map的操作即为多通道卷积。
1.3 池化层(Pooling)操作
池化层的操作就是在内积结果上取每一局部块的最大值。即CNN 用卷积层和池化层实现了图片特征自动提取的方法。
池化可以将一幅大的图像缩小,同时又保留其中的重要信息。池化都是2×2大小,比如对于max-pooling来说,就是取输入图像中2×2大小的块中的最大值,作为结果的像素值,相当于将原始图像缩小了1/4。同理,对于average-pooling来说,就是取2×2大小块的平均值作为结果的像素值。池化操作具体如图3所示。

图3 池化操作
因为最大池化(max-pooling)保留了每一个小块内的最大值,所以它相当于保留了这一块最佳的匹配结果(因为值越接近1表示匹配越好)。这也就意味着它不会具体关注窗口内到底是哪一个地方匹配了,而只关注是不是有某个地方匹配上了。由此看出,CNN能够发现图像中是否具有某种特征,而不用在意到底在哪里具有这种特征。这也就能够帮助解决之前提到的计算机逐一匹配像素的死板做法。
当对所有的feature map执行池化操作之后,相当于一系列输入的大图变成了一系列小图。同样地,我们可以将这整个操作看作是一个操作,这也就是CNN中的池化层(pooling layer),通过加入池化层,可以很大程度上减少计算量,降低机器负载。
1.4 反向传播BP处理
使用卷积神经网络进行多分类目标检测的时候,图像构成比上面的图像要复杂得多,我们并不知道哪个局部特征是有效的,即使我们选定局部特征,也会因为太过具体而失去反泛化性。假设我们使用一个卷积核检测眼睛位置,但是不同的人,眼睛大小、状态是不同的,如果卷积核太过具体化,卷积核代表一个睁开的眼睛特征,那如果一个图像中的眼睛是闭合的,就可能检测不出来,针对此类问题就要使用反向传播算法(BP)确定卷积核的值。
反向传播算法就是对比预测值和真实值,继而返回去修改网络参数的过程[10],一开始随机初始化卷积核的参数,然后以误差为指导通过反向传播算法,自适应地调整卷积核的值,从而最小化模型预测值和真实值之间的误差。当然,在实际的CNN中不可能存在百分之百的正确,只能是最大可能正确。
2 CNNBN算法
本文在最后一个卷积层之后、激活函数之前插入BN(BatchNorm)层,使用BN算法对图像数据进行批规范化处理,这种方式会减小图像之间的绝对差异,突出相对差异[11],能够加快分类效果和训练速度。假设输入数据是β=χ1…m,共m个数据,输出是Yi=BN(X),为了保证非线性的获得,BN给输入数据增加两个参数β和γ,这两个参数是通过训练学习得到的[12],其具体计算过程如式(2)~(5)所示。
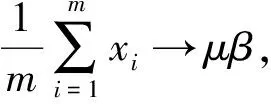
(2)
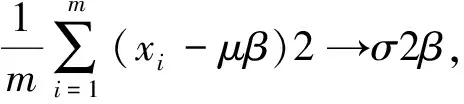
(3)
(4)
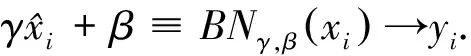
(5)
式(2)求出x的均值,式(3)求出此次Batch的方差,接下来式(4)对x做归一化,最后式(5)引入缩放和平移变量计算归一化后的值。在tensorflow中Batchnorm的代码实现如下:
def batch_norm_layer(x,train_phase,scope_bn):
with tf.variable_scope(scope_bn):
beta = tf.Variable(tf.constant(0.0,shape=[x.shape[-1]]),name='beta',trainable=True)
gamma = tf.Variable(tf.constant(1.0,shape=[x.shape[-1]]),name='gamma',trainable=True)
axises = np.arange(len(x.shape)-1)
batch_mean,batch_var = tf.nn.moments(x,axises,name='moments')
ema = tf.train.ExponentialMovingAverage(decay=0.5)
def mean_var_with_update():
ema_apply_op = ema.apply([batch_mean,batch_var])
with tf.control_dependencies([ema_apply_op]):
return tf.identity(batch_mean),tf.identity(batch_var)
mean,var = tf.cond(train_phase,mean_var_with_update,
lambda:(ema.average(batch_mean),ema.average(batch_var)))
normed = tf.nn.batch_normalization(x,mean,var,beta,gamma,1e-3)
return normed
首先新建2个变量beta和gamma,平移、缩放因子,接着计算此次批量的均值和方差,然后通过Exponential Moving Average(decay=0.5)函数滑动平均做衰减[13]。训练阶段计算runing_mean和runing_var,使用mean_var_with_update()函数,测试的时候直接把之前计算的值拿去用 ema.average(batch_mean)。
CNNBN模型训练时通过给定输入向量和输出的目标向量,求出隐层以及输出层中各个单元的输出[14],然后进一步求出目标值和实际输出值之间的偏差值e(这个过程是前向传播过程);接着拿e的值看它是否在设定的允许范围之内,如果是,训练结束,固定权值和阈值;如果e的值不在允许范围之内,返回去计算网络层中神经元的误差值,并且求出误差的梯度,进一步更新权值,继续求隐层,输出层各单元的输出[15](向后传播过程),不断循环这个过程,最后得到一个稳定的权值和阈值,其训练过程如图4所示。

图4 CNNBN模型训练流程
3 实验及分析
本文采用3 000多张图像作为训练数据集,图像是自然场景下使用海康威视HIKVISION B12V2-I 6MM型摄像头在果园采用不同角度、不同光线、不同高度拍摄的,拍摄图像的尺寸为1 920像素*1 080像素,JPG格式,然后使用Labelme软件给图片标记上PASAL VOC标签。在远程云服务器上使用Anaconda作为IDE,搭建TensorFlow2.1.0深度学习框架,训练时将所有训练集图像统一缩放800*800尺寸大小,然后将整个图像输入,训练集和验证集以4:1的比例随机划分。同时通过如下代码定义了相关的评估量:
def loss(logits,label_batches):
cross_entropy=tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits,labels=label_batches)
cost = tf.reduce_mean(cross_entropy)
return cost
def get_accuracy(logits,labels):
acc = tf.nn.in_top_k(logits,labels,1)
acc = tf.cast(acc,tf.float32)
acc = tf.reduce_mean(acc)
return acc
首先定义训练最小化损失的损失函数loss(),其次定义评价分类准确率的量acc。训练时,当loss值减小,准确率acc值增加,说明训练才是收敛的。在设计loss函数时,有两个主要的问题:①对于最后一层长度为7*7*30长度预测结果,计算预测loss通常会选用平方和误差。然而这种loss函数的位置误差和分类误差是1∶1的关系。②输入的整个图有7*7个网格,大多数网格实际不包含被检测对象(当被检测对象的中心位于网格内才算包含检测对象)。直接选用整图训练模型,这样做的好处在于可以更好的区分目标和背景区域,在提升目标定位度的同时牺牲了一些正确率。通常一个网格(cell)可以直接预测出一个检测目标对应的bounding box,但是对于某些尺寸较大或靠近图像边界的被检测对象,需要多个网格预测的结果通过非极大抑制处理生成bounding box。
在训练和测试时,每个网格预测B个bounding boxes,每个bounding box对应5个预测参数,即bounding box的中心点坐标(x,y),宽高(w,h),和置信度评分。这里的置信度评分(Pr(Object)*IOU(pred|truth))综合反映基于当前模型bounding box内存在目标的可能性Pr(Object)和bounding box预测目标位置的准确性IOU(pred|truth)。如果bouding box内不存在物体,则Pr(Object)=0。如果存在物体,则根据预测的bounding box和真实的bounding box计算IOU。如果将输入图像划分为7*7网格(S=7),每个网格预测2个bounding box(B=2),有20类待检测的目标(C=20),则相当于最终预测一个长度为S*S*(B*5+C)=7*7*30的向量,从而完成检测和识别任务。相关检测数据对比如图5所示。图中:正确率表示正确检测和识别的比例;目标定位度表示目标定位的正确性;相似性表示类别的相似性;其它为其它性能指标,如检测速度等;背景识别任何目标的背景。

图5 检测数据对比
因为算法训练模型时直接选用整图,这样能够更好的区分目标和背景区域。从实验结果也可以看出虽然检测正确率稍有牺牲,但目标定位度有较大的提升。目标定位度较准,在机器人采摘系统中非常重要。另外,实验中将proposals的数量限制为300个,因为proposals的数量影响算法的检测速度,这样R-CNN的平均精度mAP(mean Average Precision)值为32,检测偏差mAP的值为31.6,检测时间(sec/img)为0.36;而CNNBN 的平均精度mAP(mean Average Precision)值为31.1,检测偏差mAP的值为30.3,检测时间(sec/img)为0.33,如表1所示。

表1 各算法实验参数
通过与已有同类检测算法的对比,从数据可以看出,在检测正确率基本持平的情况下,本算法的检测速度有所提高,目标定位正确率较高,可以对任何背景的水果图像都能进行检测,适用范围更广泛,说明本研究算法具有一定的优势与可行性。
猜你喜欢
艺术家(2023年8期)2023-11-02 02:05:28
小哥白尼(军事科学)(2022年2期)2022-05-25 13:19:30
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
科技创新与应用(2021年23期)2021-08-30 11:46:16
无线互联科技(2020年15期)2020-11-10 06:00:58
科技传播(2020年6期)2020-05-25 11:07:46
红领巾·萌芽(2019年8期)2019-08-27 15:30:15
电子制作(2019年11期)2019-07-04 00:34:38
雷达科学与技术(2018年3期)2018-07-18 00:59:32
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
