
基于深度学习的普通金属矿石快速分拣系统的研究
2022-06-24 10:01许志勇马小林周炜程
计算机应用与软件 2022年4期
许志勇 马小林 陈 壮 周炜程
(武汉理工大学信息工程学院宽带无线通信与传感器网络湖北省重点实验室 湖北 武汉 430070)
0 引 言
金属矿产资源是自然资源的重要组成部分,是国家经济建设的基础物质资料,随着我国经济的飞速发展,对金属矿产资源的需求也迅速增长[1]。金属矿石开采后的第一道工序就是粉碎矿石和泥块,粉碎后需要进行数次洗矿。前两到三次洗矿粗选,使用高压水枪洗去松散的泥块以及矿石表面附着的大面积泥土,每次洗矿后,再人工分拣出粘结性较强的泥块。在粗选之后,还需要使用洗矿机进行细选,洗去矿石表面附着的顽固泥土,以确保矿石的高质量[2]。如果泥土含量过多,会极大地增加之后工序的难度,严重时甚至会堵塞矿机,造成财产的损失并威胁工作人员的安全。如何提高洗矿效率、减少矿石的含泥量,已经成为迫切需要解决的问题。
孙海波[3]通过改进回采工艺,增大水枪压力等方法提高选矿效率;黄春源等[4]采用圆振筛+直线筛+浓密机组合进行洗矿工艺改造,大大提高了矿浆流动性,避免管道和分矿箱堵塞。但这些方法着重提高洗矿工艺,对粘结性强的泥块的处理能力还显得不足,存在着水资源消耗过大,人工参与较多以及工艺改造成本高问题。
丁涛等[5]提出了一种基于视觉识别技术的矿石在线分选机的系统,将图像处理技术应用于矿石选矿上。其根据矿石和脉石不同的光学特性,通过机器视觉技术,判断出脉石的具体位置,并进行剔除处理。但是这种方法效率较低,并且抗干扰性能差。矿石和泥块的分拣数量巨大,形态复杂,在实际情况还会有大量碎泥和碎石作为噪声,单纯的机器视觉技术已经不能满足需求。
近年来,随着深度学习(Deep Learning,DL)技术的成熟,这项技术被越来越多地应用在目标拣选上。深度学习通过逐层初始化人工神经网络解决了大规模多层神经网络在训练速度上的难题,以此奠定了DL的基础。王鹏等[6]设计了一种基于机器视觉的多机械臂煤矸石分拣机器人系统,应用了深度学习方法中的目标检测技术对煤矸石抓取特征并识别,能够实现对煤矸石高效、快速分拣。这验证了基于深度学习的目标检测器在矿石分拣方面的优势。
为了克服传统洗矿操作含泥量过大问题,满足对大量矿石和泥块的快速分拣要求,本文提出了一种矿石泥块混合物分拣的原型验证系统。本系统创造性地使用了深度学习中的目标检测方法,在选定目标检测框架后,通过使用大量的矿石泥块混合物的数据集对模型进行训练,结合设计的图像采集与无线快速传输装置、云服务器等设备,实现了对矿石泥块混合物的快速分拣。
1 系统整体设计
基于深度学习的金属矿石快速分拣系统如图1所示。该系统由图像采集与传输装置、云服务器等构成。

图1 金属矿石快速分拣系统的整体架构
系统总体工作流程如下:(1) 矿石粗选时产生矿石和泥块的混合物,在进行下一次工序前,通过图像采集与传输装置将混合物的图片上传至云服务器;(2) 云服务器将接收的图片存储到指定位置,并使用目标检测算法对图片中的矿石、泥块进行检测,检测的结果在终端予以显示;(3) 根据检测结果生成泥块的位置信息,发送控制信号给下位机,控制分拣装置进行分拣。
2 硬件系统实现
2.1 图像的采集与传输
考虑到装置的成本和简易性,采用STM32F407作为主控板芯片。本系统对图像分辨率要求不高,采用OV5640作为摄像头,存储器大小FLASH:1 MB,RAM:192 KB。在实际生产中,存在大量矿石和泥块待分拣,需要保证图像传输的实时性,采用Marvell 88W8801无线传输模块。图像采集与传输装置的工作流程如图2所示。
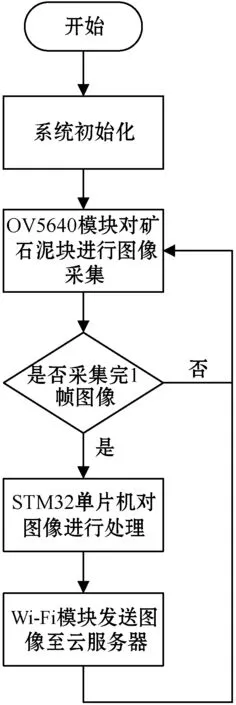
图2 图像采集与传输的工作流程
STM32F407自带一个数字摄像头接口(DCMI),用于接收外部CMOS摄像头OV5640模块输出的高速数据流,不断地对矿石和泥块进行图像采集。装置采用1 920×1 080分辨率,由于一帧图像的数据远远超出了DMA传输的最大数目65 535字节的限制,需要完成多次DMA中断。在中断中改变图像数据存储地址才能将图像数据存储到SRAM中。
未经压缩的RGB565图像格式数据流太大,会阻碍图像的传输与存储,降低图像传输速率,本装置对图像进行了JPEG格式压缩。通过对原始图像进行图像预处理、离散余弦变化、量化及熵编码[7],并将最终压缩好的数据封装上JPEG文件头、文件尾、数据段,即成为标准的JPEG格式文件。
采集到的图像经过主控芯片处理,通过SDIO接口连接Wi-Fi模块发送出去。Wi-Fi模块传输速率为72.2 Mbit/s,支持802.11b/g/n无线标准,支持TCP/IP网络协议栈[8],工作在STA站点模式,通信IP地址设为192.168.0.8。无线通信上位机显示采用FLASK网络套接字(Socket)编程[9]:首先打开套接字,将其初始化为数据流套接字,并开始监听;之后调用函数连接AP(无线接入点),连接成功则接收数据;最后对接收后的数据进行解码,就可以显示清晰的图像。
图像采集与传输装置的实物图和上位机显示结果如图3所示。

图3 图像采集与传输装置的实物图和上位机显示结果
2.2 云服务器
目标检测模型部署在云服务器上,并采用GPU加速。云服务器为阿里云的GPU轻量型服务器,系统为Ubuntu 16.04,CPU:Intel Xeon E5- 2682 V4,GPU:Nvidia Tesla P4/8,内存6 GB,系统盘40 GB固态硬盘。服务器后端采用FLASK、Gunicorn、Nginx架构及HTTP协议,完成图片的存储和识别结果的推理。
服务器前端的网站显示界面如图4所示,在输入用户名和密码后,可以将传入图片的识别结果显示到界面上。

图4 前端显示界面
3 矿石和泥块检测算法
3.1 检测算法对比
在深度学习的推动下,目标检测的技术近年来得到了飞速的发展,使用深度学习中的CNN来进行目标检测已经成为了主流的技术,出现了诸如Fast R-CNN、Faster R-CNN、R-FCN、YOLO、SSD等算法。其中Faster R-CNN、YOLO和SSD是现今应用最广泛的三种架构[10]。
Ren等[11]提出的新的Faster R-CNN算法,引入了RPN网络提取的proposals,通过共享卷积层实现proposals和目标特征的提取,使得运算速度大大提升。Redmon等[12]提出YOLO算法,将目标检测和目标识别同时实现,发挥了速度快的特点,但精度有所下降。Liu等[13]提出SSD算法,结合了YOLO回归思想和Faster R-CNN的anchor机制,实现了速度与准度并存。
由于本文所实现的装置只要求识别1种目标,同时由于矿石和泥块数量巨大,对精度要求不追求完美。根据表1中三种模型在公共数据集VOC2007、VOC2012和COCO的精度和速度表现,本系统选择以VGG-16[14]为网络的SSD512目标检测框架作为实验模型。
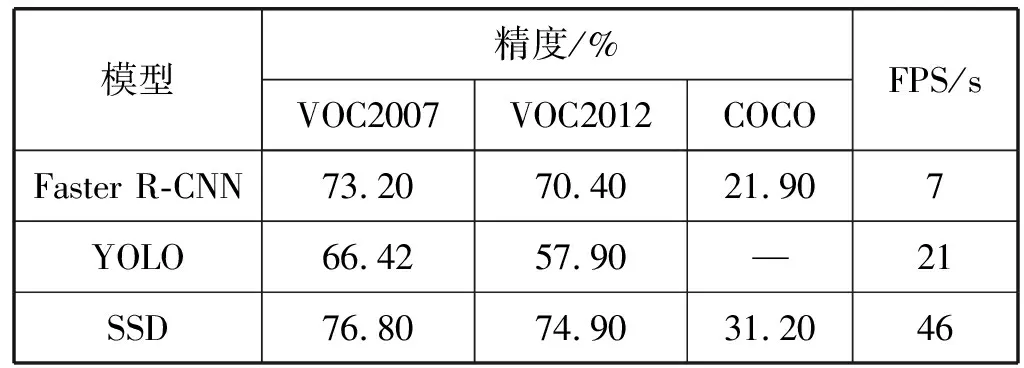
表1 三种模型在公共数据集上的表现
VGGNet(VGG-16)是卷积神经网络的经典网络,由输入层、卷积层、全连接层和输出层四个部分组成。输入层用于直接输入原始图像数据;卷积层主要用于提取输入数据的特征,包括两部分,一部分是卷积核,另一部分是下采样层,对目标图像进行降维,以减少数据处理量;全连接层相当于一个分类器,用来实现信号的纵向传导,每一层的神经元节点分别连接线上的权值,然后经过加权组合来获取下面一层的输入;输出层用于推理结果输出。
相比于SSD300模型,SSD512模型使得网络能提取到更细微的特征,且较大地扩充了先验框的数量,使得模型的识别准确率提高一个档次。
3.2 数据采集与预处理
本文为了研究初选的矿石和泥块识别任务,在实验前,使用CMOS相机,采用1 920×1 080和1 080×1 920两种像素对矿石和泥块的数据图进行实地采集。为了满足数据集多样性的要求,模拟实际场景,增加识别网络的鲁棒性,特地选取了表面粗糙度、干湿度、裹泥量和本身自然形态都不相同的矿石泥块混合物作为样本。再从拍摄角度入手,以不同的光照和角度,对此前收集的目标样本进行大量的图片采集。在采集中,添加了一些碎石和碎泥作为噪声,增加所训练网络的抗干扰能力。采集的部分图片如图5所示。

(a)

(b)图5 数据集采集的部分图片
最终采集了4 600幅矿石泥块混合物图片,根据SSD官方模型采用的PASCAL VOC竞赛数据集[15]格式,使用LabelImage软件对感兴趣的区域进行了标注,所标注目标的4元组参数(Xmin,Ymin,Xmax,Ymax),分别表示标注框的左上和右下角坐标,并只对图像中的泥块进行了标记,即只有泥块Mud和背景Background两种Classes,信息保存在了xml文件中。
根据常见数据集的划分规则,本实验将训练集和测试集按8 ∶2比例进行划分,即训练集计3 680幅,测试集计920幅。训练集用于网络参数的训练,测试集用于目标预测的性能评估。
为进一步提升网络的鲁棒性,还采用数据增强的方法提高其泛化能力,使用相应变换函数,对输入图像进行翻转、裁剪和平移等操作。数据集通过迭代器输入网络,迭代器在每次图像输入时会进行随机的图像增强变换,进一步扩充了数据量。
3.3 算法实现
根据SSD512的输入数据要求,将输入的.jpg文件调整到512×512的像素大小,并转化为Array形式,再将像素点值矩阵X用式(1)减去均值,通过转置函数转置,以Tensor形式输入到网络中去。
X=X-(104.0,117.0,123.0)
(1)
SSD512网络模型属于前馈神经网络,以VGG-16作为目标检测分类的基础架构,输入为512×512像素大小的图片,在5层网络后,丢弃全连接,并添加额外的卷积层,卷积层的大小逐层地递减,以此提取不同粒度的特征。选取规定的7个多尺度下的卷积层(Conv)作为特征层(Feature map),在特征层每个单元上,按照不同长宽比分别提取4到6个先验框,总共可以获取24 564个先验框。整个SSD网络前向结构如图6所示。

图6 SSD512 网络前向结构图
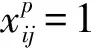

(2)
位置损失Lloc是预测框l和真实标签回归框g之间的平滑L1损失。平滑L1损失见式(3),由此推导的位置损失见式(4)。
(3)
(4)
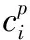
(5)
(6)
根据上述位置和置信度损失,总体目标函数可用两者加权和表示为:
(7)
式中:c是SoftMax函数对每个类别的置信度;N是匹配先验框的数量;权重项a取1。
(1) 网络模型的训练。图像数据输入网络后,经过网络的前馈,可以求得总体目标损失函数L(x,c,l,g)。结合损失函数,通过SGD梯度下降方法,使得网络不断学习,参数不断更新,位置的回归和类别的分类精确度不断上升,最终能达到一个理想的模型权值。
(2) 网络模型的测试。在模型训练的过程中,每隔一段时间对模型的精准度进行测试。测试时,将测试集图片经预处理输入到训练过后的SSD512网络模型中去,得到输出预测框位置loc值和置信度conf值。对loc值进行解码(decode),并和24 564个先验框比较,通过筛选规则将conf值小于给定阈值的框筛除掉。可以得到很多互相重叠的框,对这些框运用NMS(非极大值抑制)算法[16],即可得到最终的框选结果。根据预测结果可以分析出此时网络的学习情况。
NMS算法流程:假设有N个框,每个框的分类得分为Sb(1≤Sb≤N)。新建集合H,将N个框放入集合H中,同时初始化一个空集M,用来存放最优框。① 将H中框box按得分Sb进行排序,选出得分最高框box_m,将box_m移动至集合M中;② 遍历H中的框box,分别与框box_m计算交并比(IOU),表示为:
(8)
③ 若IOU高于某个阈值,则将此框box从集合H中去除。不断重复步骤①到步骤③,直到集合H为空,集合M即最终框选结果。
3.4 实验平台与超参数设置
SSD算法的训练和测试都在Linux PC上完成,其软件配置为Ubuntu 16.04、Pytorch(0.3.1)、CUDA(9.0),使用双GPU服务器进行并行训练。
由于随机参数的初始化将消耗大量的算力和时间用于降低模型损失值,本实验采用了迁移学习方法。迁移学习所训练的卷积层具有提取通用图像特征的本领[17],将经大数据集ImageNet[18]数据下训练好的预训练模型,共享底层结构权重参数,然后修改其顶层网络结构,在新任务训练中可以大大加速收敛速度。
考虑到硬件设备的条件限制、原始权重经过大数据训练,以及矿石和泥块本身存在多样性不高的问题,经过尝试和调整,将各实验参数设置如表2所示。

表2 参数设置
4 实 验
4.1 评价指标
本算法中用于评价目标检测算法的指标如下:
(1) 精确率(Precision,P)。
(9)
式中:TP代表true positive,即正样本中被预测正确的数量;FP代表false positive,即负样本被预测为正样本的数量。
(2) 召回率(Recall,R)。
(10)
式中:FN为false negative,即正样本被错误地分为负样本的数量。
(3) 平均准确率(Average Precision,AP)。
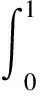
(11)
式中:P(R)表示精准率随召回率变化的函数。
(4) 平均精确率均值(mean Average Precision,mAP)。
(12)
式中:N为检测类别的数量。
4.2 实验结果
本系统算法的评估使用的是SSD512网络模型中的位置损失Lloc(式(4))和置信度损失Lconf(式(5)),在对训练的日志文件中的位置损失值和置信度损失值进行提取后,绘制了如图7所示的算法模块的位置损失值和置信度损失值的散点图。

(a)

(b)图7 SSD512模型的损失值散点图
本实验1次迭代输入16幅数据,总共迭代近30 000次。每迭代10次,记录一下训练损失值。从图7(a)位置损失和图7(b)置信度损失可以看出,在0到5 000次迭代时,训练损失下降较慢,在迭代5 000次后,训练损失下降速度开始加快,在迭代10 000次后,训练损失趋于平滑其中位置损失值在0.15附近波动,置信度损失值在0.75附近波动,网络趋于稳定。
此外,每10个Epoch,对920幅的测试集进行1次测试,测定出mAP。mAP变化曲线如图8所示。
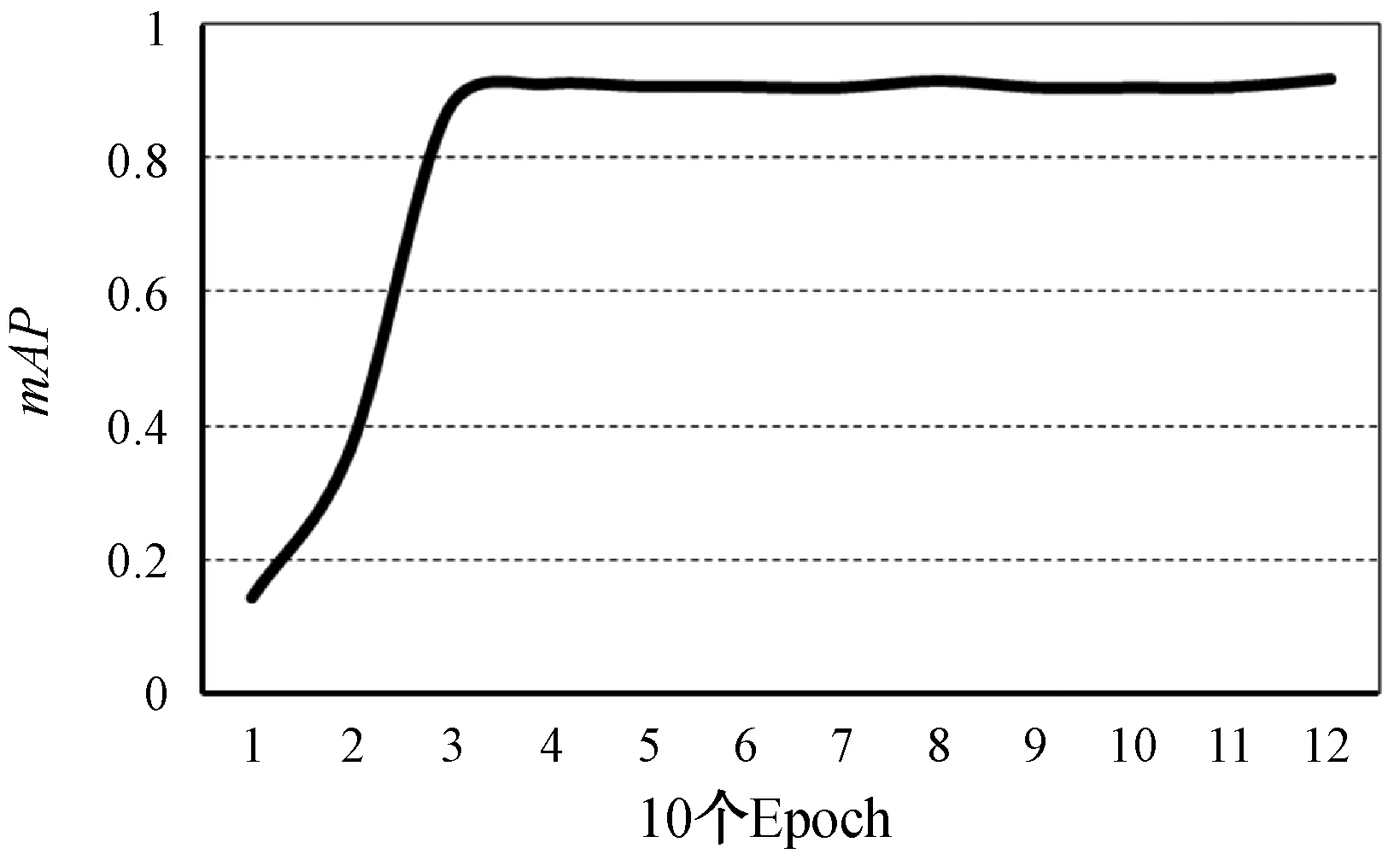
图8 10个Epoch后的mAP大小曲线
可以看出,在35个Epoch之后,mAP数值趋于稳定,在0.91附近波动。
4.3 结果分析
从上述现象中可以看出,得益于迁移学习的特征提取优势,在较少的Epoch下,损失函数收敛,达到了91%的精准度。具体为,在0到5 000次迭代训练的过程中,损失函数抖动较大,但整体呈现下降趋势,此时神经网络正在学习矿石泥块之间的特征。在5 000次之后,矿石泥块之间区别的重要特征已经学习完成,且由于本身数据集之间区分度不大,损失函数发生加速下降。在10 000次后模型进入学习的平台期,此时模型的识别mAP已经达到91%左右,并不再上升,这表明模型的训练已经完毕。
泥块的识别mAP达到91%后不再继续上升,主要原因是数据集中有部分矿石裹泥量过大,甚至已经完全覆盖矿石表面。这种矿石图像从图像角度,已经和泥块没有任何差别,在标注过程中依旧把这些矿石标注为矿石,就会降低泥块的识别率。这种情况在实验和实际情况中是不可避免的,只能通过前期高压水枪的冲刷尽量冲去表面附着的大量泥巴。
图片测试时,一帧图片的检测时间大约维持在0.05 s左右,能够满足实时性检测要求。图9为使用训练后的网络识别的结果图。

(a)

(b)图9 网络识别后的结果图
图9中,mud值代表泥块置信度,其取值范围为0~1,mud数值越大,表明是泥块的可能性越大。可以看出,网络对传入的一幅矿石泥块混合物图片进行了识别,并对可能是泥块的目标进行了标注,标注的数值越大,表明网络判断该目标是泥块的可能性越大。建立的模型已经提取出了矿石、泥块的特征,并可以根据学习到的特征精准地识别出矿石和泥块。矿石表面的附着的泥巴过多,与泥块基本没有区分度,则会发生置信度大于0.5的误判。而整个的泥块,无论是干是湿,都能够产生置信度为1左右的正确判决。
5 结 语
本文提出了一种基于深度学习的普通金属矿石快速分拣系统,主要由图像采集与传输装置、云服务器等构成。通过SSD512目标检测算法对输入的矿石泥块混合物数据集进行学习实验,结果显示生成的模型能够完成对矿石泥块混合物的识别任务,且识别准确率达到了91%左右,具有良好的鲁棒性。由于矿石泥块识别对精度要求并不能追求完美,所以使用该模型作为系统的核心算法模块是满足要求的,能够实现整个系统装置的良好运作。
未来的算法研究方向主要着重于两方面,一是继续优化网络结构,使得检测的准确率得到更大的提升;二是研究网络的压缩算法,得到更轻型的网络,从而提高本文提出模型的识别效率,增加识别的实时性。
猜你喜欢
电子技术与软件工程(2022年15期)2022-11-11
今日农业(2022年15期)2022-09-20
小型微型计算机系统(2022年4期)2022-05-09
红蜻蜓(2021年3期)2021-07-14
红领巾·萌芽(2021年10期)2021-01-01
小天使·二年级语数英综合(2019年10期)2019-11-08
中国科技纵横(2016年20期)2016-12-28
读者·校园版(2015年19期)2015-05-14
小资CHIC!ELEGANCE(2014年15期)2014-09-27
海外英语(2013年8期)2013-11-22
