
基于LLVM的C/C++隐式类型转换安全性检测
2022-06-24 10:01刘嘉华鄂龙慧
计算机应用与软件 2022年4期
万 明 刘嘉华 鄂龙慧 朱 江
(南京南瑞信息通信科技有限公司 江苏 南京 210003)
0 引 言
现代编程语言通过部署类型系统来控制对象使用和错误检测[1]。类型系统可以分为静态类型、动态类型、强类型和弱类型。由于C/C++是静态弱类型语言,允许通过默认或强制的方式转换变量的类型,因此只能依赖于编程人员良好的编程能力和习惯来避免在运行时引入类型错误,从而避免出现安全问题。然而编程人员水平参差不齐,且在开发过程中难免会有所疏忽,所以由类型错误所引起的安全问题屡见不鲜。据统计,微软公司所有软件已发现的代码执行漏洞中大约有75%是类型和内存错误[2]。市场占有率高达63.16%的谷歌浏览器被发现了存在于Histogram组件中的编号CVE-2017-5023的类型混淆漏洞,该漏洞允许远程攻击者通过发送一个精心构造的网页来执行受害者电脑上的任意代码[3]。同年,在苹果浏览器Safari内核的webkit组件中也发现了编号为CVE-2017-2415的类型混淆漏洞,使得几乎所有的苹果设备都受到了威胁[4]。由此可见,类型转换问题不能完全依赖于编程人员的编程技能和人为审计来规避,研发一个有效的针对性的检测方法是很有必要的,这将在很大程度上帮助编程人员规避软件中的安全隐患,增强软件的健壮性。
为此,本文借鉴了动态类型语言Python语言和Go语言中的类型系统[5],提出了一种针对C/C++隐式类型转换产生的类型安全问题的编译期检测方法。该方法在编译期作用于LLVM中间代码,对代码中的隐式类型转换操作进行检测,若匹配到相应的模式即给出必要的提示或终止编译过程。实现上,我们将该方法编译为一个动态链接库文件,通过LLVM opt工具加载动态链接库来对代码进行类型转换安全性检测。
1 相关工作
面对如今动辄上百甚至数千万行代码的重量级软件,编译器在处理一些类型转换错误时缺乏必要的提示,使得编程人员很难在代码海洋里揪出这些不起眼的错误。因此,人们开始着眼于构建一个类型转换错误检测工具,以帮助编程人员在开发过程中规避由类型问题引发的安全隐患。这些工具大体可以分为两个类别:基于嵌入对象中的vtable指针的方法[6-9]和基于不相交元数据的方法[10-12]。
基于vtable指针的解决方案无须跟踪活动对象,但具有根本的局限性,即它们不支持不具有vtable的非多态类。UBSan[6]使用静态强制转换执行显式的运行时检查,从而有效地将其转换为动态强制转换。为防止非多态类失败,UBSan需要手动将其列入黑名单。然而,C++编译器中可用的现有类型检查基础结构本质上很慢(因为它是在假设只有很少的动态检查会被执行且大多数检查是静态的前提下设计的),因此UBSan由于开销过大仅被用作测试工具,而不是一个在线检测工具。Clang控制流完整性(CFI)[8]旨在提高速度,但尚未发布性能数据。而且,像该组中的所有解决方案一样,它不能支持非多态类。
基于不相交元数据的方法最早出现的是CaVer[10]。代替手动列入黑名单的方式,CaVer使用不相交的元数据来支持非多态类。然而,由于元数据跟踪效率低(尤其是在堆栈上)且检查速度较慢,因此该方法开销仍然过高,对于某些浏览器基准测试,这种开销高达100%。此外,该方法无法处理线程之间共享的堆栈对象且在对象分配范围上表现较差,最终导致类型混淆检测范围减小。
TypeSan[11]实现了一个sanitizer编译器组件,为程序添加了独立设计的元数据类型来记录类型跟踪信息,在编译期间为程序插入额外代码片,这些代码片段在运行时跟踪C++程序中所有cast操作相关的类型转换操作,能够检测出C++中cast操作符使用不当的情形。与CaVer相比,提升了3~6倍的性能,但是仍具有较大的时间开销和内存开销(4~10倍基准值)。
HexType[12]在TypeSan的基础上,改进了记录类型跟踪信息的元数据,并严格区分了安全cast和不安全cast,对C++中的cast操作符有选择地进行跟踪,做到了比TypeSan更高效的cast错误检测。但是,和TypeSan一样仍然是给程序插入额外的代码片段,在运行时检测类型转换错误中的其中一种情形(cast操作符的使用不当)。
综上所述,现有的工具大多集中于检测C++中cast操作符的使用不当,新出现的方法主要仍在改进cast操作符使用不当的检测过程中的效率问题,面对更为普遍存在的隐式类型转换,仍没有一种有效的方法来检测其是否安全合理。
2 技术背景
2.1 类型转换
类型转换分为显式类型转换和隐式类型转换。C++中,显式类型转换对应四种cast转换操作符:static_cast、dynamic_cast、const_cast和reinterpret_cast。四种不同的cast操作允许编程人员对变量进行强制类型转换以满足开发过程中的不同需求。如果cast操作选择不当将会产生安全隐患。显式类型转换错误示例如下:
1 class Parent
2 {
3 int x;
4 };
5 class Son : Parent
6 {
7 double y;
8 };
9 Parent *p=new Parent();
10 Son *s;
11 s=static_cast
12 s→y;
该示例通过子类指针s错误访问父类成员x。cast操作符将int类型转换为double类型,使得子类s可以访问比x更大的未初始化空间,造成图1所示的越界读。
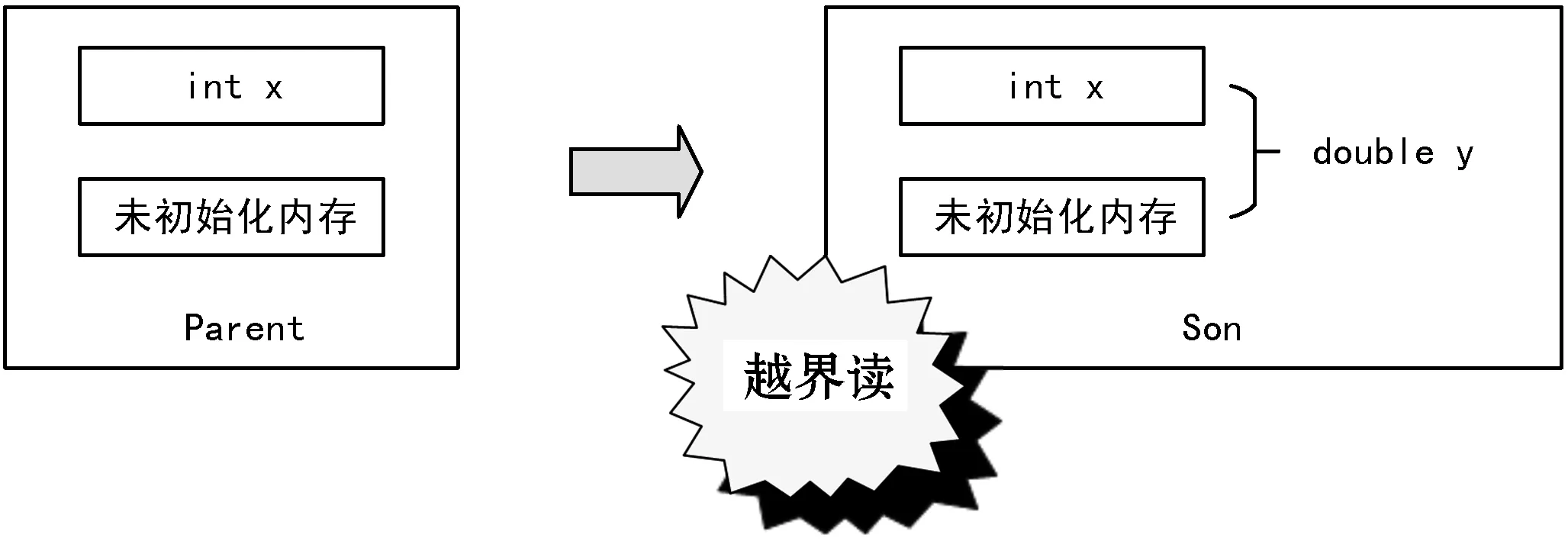
图1 cast操作使用不当导致的越界读
不同类型变量间,直接用赋值符“=”进行赋值时,右操作数不指明转换的类型,则进行的是隐式类型转换。除了赋值操作,函数调用时形式参数的引用也存在隐式类型转换,这类隐式类型转换和赋值形式的隐式类型转换有一点不同,函数调用时形式参数的隐式类型转换可能会产生直接的安全问题。C/C++中一个熟知的内存复制函数memcpy可以对变量进行复制,由于memcpy函数的参数是指针变量,内存拷贝操作没有相应的安全检测,有潜在的安全风险。像memcpy这样能直接操作指针变量的函数有不少,在实际开发过程中也经常出现由该情况引起的安全漏洞。本文提出的方法将着重解决该类问题。隐式类型转换错误示例如下:
1 struct Example1
2 {
3 int x;
4 void *func();
5 };
6 struct Example2
7 {
8 int x;
9 long y;
10 };
11 int main()
12 {
13 Example1 *e1=new Example1();
14 Example2 *e2=new Example2();
15 e2→x=0;
16 e2→y=0x1234;
17 memcpy(e1,e2,sizeof(Example1));
18 e1→func();
19 return 0;
20 }
该示例错误地将int型变量赋值给了函数指针,调用函数e1->func()时变成了对0x1234这块内存的解引用,程序试图去请求访问0x1234地址的内存,显然地址0x1234在程序段中并不是一个合法的可读地址,从而造成了内存访问违例(对应linux下的segmentfault错误)。
2.2 LLVM
本文提出了一种针对C/C++隐式类型转换产生的类型安全问题的编译期检测方法。该方法基于LLVM中间代码检索出程序代码中的类型转换语句,提取并比对变量类型以判断该类型转换是否会引入安全隐患。我们将该方法编译为一个动态链接库文件,以作为LLVM中间代码的分析优化器,由LLVM opt工具加载执行。
LLVM[13]编译器以其提供的优化特性而出名,其中的代码优化阶段允许开发人员利用LLVM提供的丰富的接口以实现自定义pass,也就是我们所说的优化器。LLVM架构如图2所示。

图2 广义LLVM架构
如图3所示,自定义的优化器通过opt工具加载以在编译期检测类型转换操作。opt工具又被称为模块化的LLVM优化器和分析器,它接受LLVM IR(LLVM输出的以.ll为拓展名的中间代码)和LLVM字节码(LLVM输出的以.bc为拓展名的中间代码)格式作为输入,通过-load选项选择要加载的优化器。

图3 编译过程中检测类型转换
3 方案设计
本节给出类型转换安全的定义,并基于C/C++的一些语言特性,实现对类型转换是否安全的一个判定算法。
3.1 类型处理
C/C++中的类型可以分为基本类型、枚举类型、void类型和派生类型,由于本文的关注点是类型转换问题,因此只考虑基本类型和派生类型。
基本类型,即bool、char、short、int等。
派生类型,包括指针类型、数组类型、结构类型、联合体类型和函数类型。
不同数据类型可能占用不同的存储空间,占用不用存储空间的类型之间转换存在越界读的风险。本文对所有的数据类型按占用的存储空间大小进行分组(以64位机器为标准):
① 占用1字节类型:bool、char、unsigned char;
② 占用2字节类型:short、unsigned short;
③ 占用4字节类型:int、unsigned int、float;
④ 占用8字节类型:long、unsigned long、double、long int、long long;
⑤ 占用16字节类型:long double;
⑥ 指针类型(数组类型可以视为指向数组开始元素的指针);
⑦ 结构体、联合体等由多种类型复合而成的复杂数据类型。
typedef定义的类型别名,在编译器做宏展开之后根据实际占用空间进行分类。
此外,在考虑变量类型的同时,还应当考虑其作用域。C/C++中可在以下区域声明变量:
① 局部变量,在函数或代码块内部声明;
② 全局变量,在函数外部声明;
③ 形参,在函数的参数定义中声明。
局部变量只能在函数内部被该函数或代码块内的语句使用,在函数外部不可见。全局变量定义在函数外部,通常是在程序顶部,在整个程序的生命周期内都是有效的,在任意函数内部均可访问。形式参数即函数参数,可以作为函数内部的局部变量使用。
变量在定义时就确定了作用范围,不同的变量其生命周期也可能有所不同。本文为了对不同变量的作用域和生命周期进行管理,确保能够在必要的时候对变量进行跟踪,按定义变量的位置对变量的作用域和生命周期进行了划分:
① 外部变量:所有定义于函数外部的变量,包括函数和全局变量;
② 内部变量:所有定义于函数内部的变量,包括局部变量和形式参数。
之所以这样处理,是因为考虑到带返回值函数的函数返回值也可以在赋值操作的过程中作为赋值符号“=”的右值参与隐式类型转换,也可以作为函数调用的参数,所以从实际效果上看,带返回值的函数实际上是一类特殊变量,变量类型由函数返回值(函数)类型决定。由于C/C++语法规定函数不允许嵌套定义,即函数必须定义在其他任意函数的外部,因此从某种意义上带返回值的函数可以当作全局变量处理。基于此分析,本文在检测过程中将函数和全局变量视为一类一起检测,省去了对函数和变量的区分操作,一定程度上提高了检测效率。
3.2 类型存储
基于LLVM的中间代码可以提取出被测程序的变量类型信息,该类信息被写入变量表。变量表的数据结构如下:
//类型划分
enum
{
SINGLE,//1字节
DOUBLE, //2字节
QUAR, //4字节
OCT, //8字节
HEX, //16字节
POINTER, //指针类型
COMPLEX, //复杂类型
}type;
//作用域划分
#define OUTER 1 //外部变量
#define INNER 0 //内部变量
struct
{
long nameHash; //对变量名Hash
int type;
int scope;
complex_type typeLayout; //复杂类型存储对应结
//构树,否则为null
}TypeInfo;
SINGLE、DOUBLE、QUAR、OCT、HEX、COMPLEX、OTHER分别对应1字节、2字节、4字节、8字节、16字节、复杂类型和其他类型。某个划分可能包含不止一种变量类型,这种划分方式大大简化了C/C++中的变量类型数量,基于该简化模型可以更好地对类型转换进行归类,提高检测效率。
校验复杂数据类型间的转换较基本类型而言更为复杂。为了比较两种复杂数据类型的结构一致性,本文将复杂数据结构存储为一颗名为typeLayout的树。该树的数据结构中包含了复杂数据结构各个成员变量相对于起始内存空间的偏移。复杂类型存储树数据结构如下:
//复杂类型存储树节点
typedef struct LayoutNode
{
long memberHash;
int offset;
LayoutNode child;
}LayoutNode;
//复杂类型存储树
typedef struct typeLayout
{
int scope;
long complex_structure_name_hash;
LayoutNode root;
}typeLayout;
3.3 类型提取
本文通过类型信息提取算法抽取出被测程序的类型信息。该算法以程序源码文件为单位,遍历函数中的每一条语句,如果在语句中发现类型定义,则将该处的类型信息(变量名称、变量类型、作用域)以ExtractTypeInfo函数抽取出来。该函数的伪代码如下:
1 ExtractTypeInfo(type):
2 if type is complex_type
3 NoteAsComplexType(type)
4 typeLayout = AnalyseComplexType(type)
5 CollectInfo(type, typeLayout)
6 else
7 CollectInfo(type, NULL)
在实际提取过程中,会出现这样一种情形:在被测程序中有A、B两个函数,两个函数中均存在变量名为example但类型不同的变量。由于在提取变量的过程中没有对同名变量做区分,后出现的变量将会覆盖前面出现的变量的类型,导致类型信息提取过程中的信息丢失。
为此,在提取变量类型的过程中,我们使用如下方法来处理不同函数有相同变量名的情况:在对变量名进行Hash操作时,先用该变量所在的位置和变量名进行拼接组成一个新串,对拼接得到的新串再进行Hash操作。这样直接通过Hash值区别了不同作用域下的同名变量。
3.4 检测算法
在占用不同存储空间大小的变量间进行类型转换显然是存在风险的,如将int型变量转为double型变量,程序原本只能读4字节的内存空间,却在转换后读取8字节,会造成越界读的安全问题。
对基本类型而言,我们定义了一个类型转换操作表。该操作表以一个5×5大小的二维数组basic_conversion_set存储。如表1所示,int型变量向double型变量转换时是不安全的,因此basic_conversion_set[QUAR][OCT]=US(UNSAFE);而double型变量向int型变量转换时,虽然会有精度损失,但是并不算安全问题,因此basic_conversion_set[OCT][QUAR]=S(SAFE)。而对于同级别类型之间的转换,主要考察其值域是否匹配,例如对于int型变量x,当x=1时,将其转换为unsigned int是安全的;但是当x=-1时,该转换是不安全的。特殊的,指针、整数和浮点值均可以隐式地转换为bool类型:非0值转换为1,0值转换为0。

表1 基本类型类型转换操作表
对指针类型而言,其指向内存的某一块区域,编程人员可以对该区域进行操作。涉及指针类型的转换:
① 一个指向任何对象类型的指针都可以转换为void*类型;
② 两个void*类型变量之间可以互相转换,而且可以显式地将void*转换为另一个类型;
③ 除此以外的其他操作都是不安全的。
对复杂类型而言,可以将其视作多种数据类型组成的集合,其安全转换必须满足以下条件:
① 类型占用的内存空间大小相同;
② 成员变量相对于起始地址的偏移相同;
③ 成员变量间的转换是安全的。
基于上述分析,我们实现了类型转换的安全性判定算法,且整个检测过程执行如下:遍历程序中的每条语句,判断语句中是否存在变量;如果语句中存在变量,进一步判断是对该变量的定义还是引用;如果是定义则执行类型信息提取算法;如果是引用则执行安全性检测算法。该算法的伪代码如下:
1 VerifySafety(statement)
2 {
3 if NotImplicitTypeConvertion(statement)
4 return
5 else
6 TypeInfo origin = GetOriginInfo(statement)
7 TypeInfo target = GetTargetInfo(statement)
8 if(size(origin.type)>size(target.type))
9 UNSAFE
10 else if(origin.type && target.type are BASIC)
11 CheckBasicType(origin, target, basic_conversion_set)
12 else if(origin.type || target.type is POINTER)
13 CheckPointerType(origin, target)
14 else if(origin.type || target.type is COMPLEX)
15 CheckComplexType(origin, target)
16 else
17 SAFE
18 }
该函数首先对语句进行判断,如果该语句包含类型转换操作,那么进一步提取语句中进行类型转换的两个变量的类型信息。根据提取到的类型信息,先比较两者的内存空间占用,只有在内存空间相同的情况下才进行后续判断。
4 实 验
4.1 实验环境
本文基于LLVM编译器实现对类型转换的安全性检测,为了更方便地使用LLVM编译环境,选择了Ubuntu18.04操作系统。实验所用计算机的处理器为Intel Core i7- 4790 3.60 GHz 8核,内存32 GB,编译器选择gcc 8.1.0,项目构建选择cmake 3.13.4,LLVM选择了9.0.0。
4.2 实验数据
本文从美国国家标准与技术研究院[14](National Institute of Standards and Technology,NIST)的软件保障参考数据集[15](Software Assurance Reference Dataset,SARD)中选取了与类型转换相关的四个子集以验证上述方法的有效性。SARD以CWE[16](Common Weakness Enumeration)列表为基准,为列表中出现的各种类型的安全性问题设计了大量的测试用例。SARD类型转换测试集如下:
CWE194_Unexpected_Sign_Extension
CWE195_Signed_to_Unsigned_Conversion_Error
CWE196_Unsigned_to_Signed_Conversion_Error
CWE843_Type_Confusion
其中,CWE194和CWE843对应不同数据类型之间互相转换的情况,而CWE195和CWE196对应相同数据类型有符号和无符号之间互相转换的情况。文件夹下每个文件对应该类型相关的一组测试用例,测试用例的正误以函数名区分:good表示该例安全,应当通过;bad表示该例不安全,应当报警。

图4 函数名区分测试用例正误
4.3 实验结果
从上述数据集中提取出的测试用例共计1 147个,其中成功检测1 126个,错误检测21个,准确率为98.17%。我们对错误的21个测试用例进行分析,其中一部分是由于在分析建模时,我们为了简化分析,未考虑C/C++的存储类,如auto等;另外一部分是由于测试用例中的成员变量类型相同,但是具有不同的排列顺序。C/C++为提高内存的读写效率,变量在存储时遵守对齐机制,可以通过特定的宏来定义默认的对齐值。结构体、联合体在对齐机制的作用下,成员变量的排列顺序可能会影响结构体占用的内存空间大小。
如图5所示,A结构体和B结构体的成员变量及其类型完全相同,但是实际上,A结构体在64位机器下占用的内存大小为16字节,而B结构体占用的内存大小为24字节。考虑到这类情况的出现,本文方法的准确率实际上要高于98.17%。
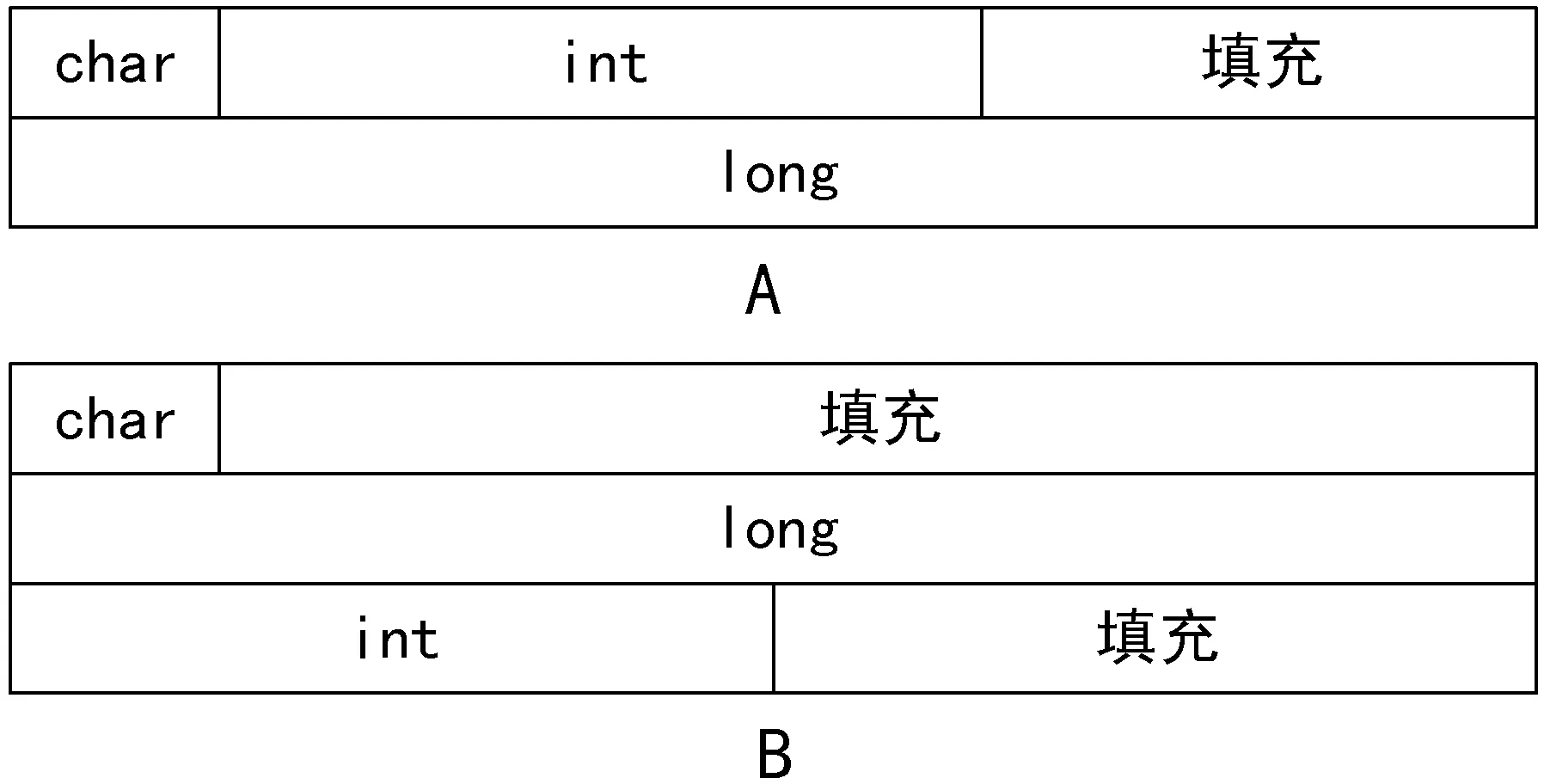
图5 结构体成员变量的对齐方式
5 结 语
为帮助编程人员规避由类型转换所带来的安全风险,本文提出了一种针对C/C++隐式类型转换产生的类型安全问题的编译期检测方法。该方法在编译期作用于LLVM中间代码,通过编写并加载自定义的优化器来实现类型转换的安全性检测。自定义优化器继承了LLVM内置的pass,依次遍历程序源代码中的每条语句,判断语句中是否存在变量;如果语句中存在变量,则进一步判断是对该变量的定义还是引用;如果是对变量的定义,则提取变量的类型信息并保存;如果是对变量的引用,则依据源变量和目标变量的类型判断其是否符合安全规则。实验结果表明,本文提出的方法能够有效地检测C/C++中出现的隐式类型转换操作的安全性。
猜你喜欢
销售与市场(营销版)(2022年8期)2022-08-16
在线学习(2020年3期)2020-09-10
娃娃画报(2019年4期)2019-05-14
广东第二课堂·小学(2017年9期)2017-09-28
数学教学通讯·初中版(2014年6期)2014-08-11
小学生·多元智能大王(2014年6期)2014-07-09
软件工程(2014年3期)2014-03-15
恋爱婚姻家庭·养生版(2010年8期)2010-05-14
小雪花·初中高分作文(2009年8期)2009-11-16
