
一种基于谱归一化的两阶段堆叠结构生成对抗网络的文本生成图像模型*
2022-06-23 03:26徐慧英朱信忠
计算机工程与科学 2022年6期
王 霞,徐慧英,朱信忠
(浙江师范大学数学与计算机科学学院,浙江 金华 321004)
1 引言
近年来,深度学习在图像识别、图像生成和图像去模糊等方面取得了突破性进展,作为图像生成领域的重要分支,文本生成图像是一项结合计算机视觉和自然语言的综合性交叉任务。文本生成图像将一句描述性语言文本作为输入,最终输出一幅与文本内容一致的图像。制作一幅与文本语义相同且生动、逼真的图像是一项具有挑战性的任务。这项任务虽有一定的难度,但是学者们对其众多应用场景还是充满了期待,目的是让文本生成图像这项任务真正在实际生活中体现出实用价值,并试图在广告设计、绘图插画等各行业得到发展。总而言之,研究文本生成图像算法不仅在学术研究,也在生活应用中有重要意义。
文本生成图像的任务分为识别输入的语句信息和制作与语句信息相对应的图像2部分,最初的主流方法是变分自编码器VAE(Variational Auto-Encoder)[1]和DRAW(Deep Recurrent Attention Writer)[2]。生成对抗网络GAN (Generative Adversarial Networks)[3]被提出后,凭借有效的对抗学习机制使文本生成图像任务有了更好的实现途径,因此相继出现了一系列基于GAN的文本生成图像方法。2016年,文献[4]提出了GAN-INT-CLS(Matching-aware discriminator and Learning with manifold interpolation)模型,首次使用流行插值和具有判别意识的判别器2种方案解决了生成图像缺乏多样化的问题,大大提高了图像生成能力,但是仍无法合成高分辨率的图像。文献[5]提出了能更好地根据文本描述控制图像中物体具体位置的网络GAWWN(Generative Adversarial What-Where Networks)。2017年,文献[6]提出了一种堆叠生成对抗网络StackGAN(Stack Generative Adversarial Network)模型,把生成高质量图像的复杂问题分解成2个相对简单的子问题:首先将文本描述与随机噪声相结合作为输入,生成64×64像素的低分辨率图像;接着将第一阶段的生成结果和文本描述作为输入,最终生成 256×256像素的高分辨率图像。但是,整个过程还是存在训练不稳定和梯度消失等问题。2018年,文献[7]进一步提出将实验任务分成3步的模型(StackGAN++),逐步生成 64×64,128×128,256×256的图像,使生成的效果有了很大提升。但是,更加复杂的网络结构使整个生成过程计算量大增,效率较低。随后AttnGAN(Attentional Generative Adversarial Networks)[8]将输入文本编码成句子级别的特征和单词级别的特征,并且在各阶段引入了自注意力机制,通过逐层训练得到最终结果,由于其复杂的结构大大增加了训练的难度,仍存在训练效率不高的问题。2019年,文献[9]提出通过输入单词级的特征以及结合自注意力机制和感知损失来控制文本生成图像的过程。2020年,文献[10]将自注意力机制融入单层生成对抗网络来完成这一任务,弥补了只能计算局部区域像素的缺陷。文献[11]提出了一种基于协同上采样的双生成器注意网络DGAttGAN(Dual Generator Attentional Generative Adversarial Network),建立了2个具有独立生成目的的生成器,将对象生成和背景生成分离,可以从文本描述中生成高质量的多目标图像。根据现有研究,如何提升网络训练稳定性和提高生成图像的质量是亟待解决的问题。
为了提高网络训练稳定性和图像质量,本文一方面将谱归一化运用到两阶段的判别器网络中,限制每层网络参数的梯度在指定范围内,从而减缓判别器的收敛速度,在保持参数矩阵结构不被破坏的前提下实现提高网络训练稳定性的目的;另一方面将感知损失函数加入生成器网络中,使生成图像更加真实自然。
2 文本到图像生成对抗网络的构建
2.1 条件生成对抗网络
生成对抗网络由一个生成器和一个判别器构成,为了到达纳什平衡,采用对抗的方式进行学习。生成器G的输入是服从正态分布的随机噪声z,输出是假图像G(z),目的是尽量去学习真实的数据分布。判别器D的输入是来自真实数据集的图像x和生成器输出的假图像G(z),输出是判别器给图像真实度打的分值D(x)与D(G(z)),取值为0~1,分值越高,说明图像越接近真实图像,其目的是尽量正确判别输入数据是来自于真实数据还是生成数据。生成器G和判别器D交替训练,其损失函数如式(1)所示:
Ez~pz[log(1-D(G(z)))]
(1)
其中,x是来自真实数据集pdata的真实图像,z是来自服从高斯分布pz的噪声矢量。
由于生成对抗网络根据噪声z生成图像的方式过于自由,对于较复杂的数据,容易变得不可控,得到的图像可能存在偏差较大的情况,因此文献[12]提出条件生成式对抗网络cGAN(conditional Generative Adversarial Network),通过在生成器和判别器中加入约束条件来解决该问题,换句话说就是为模型添加额外的辅助信息y。这一策略的作用是监督生成式对抗网络,其训练过程与生成式对抗网络(GAN)相同,此时条件生成式对抗网络的损失函数如式(2)所示:
Ez~pz[log(1-D(G(z|y)))]
(2)
与式(1)的区别是在生成器和判别器的输入中都添加了额外的辅助信息y,使无监督生成变成了有监督生成,在保持多样性生成的同时也指定了相应的生成对象。本文的网络模型正是采用了条件生成对抗网络,并采用文本描述向量化技术[13]将文本内容转化为作为附加信息条件的向量。
2.2 谱归一化
由于生成对抗网络会出现模式坍塌等问题[14],因此在后续的研究中学者们也提出了诸多解决方法[15,16]。归一化层的提出主要是为了克服深度神经网络难以训练的问题,将输入的数据映射到[0,1],这样不仅可使网络训练更加稳定,还可以提高训练过程中模型的精度。
谱归一化[17]通过严格约束每一层网络权重矩阵的谱范数来约束判别器的Lipschitz常数,从而增强条件生成对抗网络在训练中的稳定性。相比于其他的归一化技术,谱归一化只需要调整Lipschitz常数,在文献[17]中已证实了这一结论。
根据Lipschitz常数定义可得式(3):
(3)
其中,M为大于0的常数,f(x)为定义在实数集上的函数。

(4)
对网络的每一层g,以h作为输入,在此本文不讨论有偏置项,则g(h)=Wh,有:
(5)
而在整个网络f(x)=WL+1aL(WL(aL-1(WL-1(…a1(W1x)…))))中,因为有‖g1∘g2‖≤‖g1‖Lip·‖g2‖Lip,所以有:
(6)
其中,L为网络层数,Wl为第l层的权重。
若要将每层网络的Lipschitz常数限制为1,即‖g‖Lip=1,则需要σ(W)=1。
故通过式(7)对权重矩阵W做谱归一化处理,得到:σ(W)=1。
(7)
2.3 感知损失函数
感知损失函数是由文献[18]提出的,具有接近人眼视觉感知特性,可以使生成的图像更加真实自然,并且文献[19]的结论表明其增强了文本内容与生成图像的一致性。
(8)

3 基于谱归一化的两阶段堆叠结构生成对抗网络
3.1 目标函数
本文模型采用生成器网络和判别器网络交替训练的方式,其目的分别是最小化生成器损失LG和最大化判别器损失LD。采取文献[6]的方法在生成器网络的训练中加入如式(9)所示的LKL损失:
LKL=DKL(N(μ0(ρt),Σ0(ρt))|N(0,I))
(9)
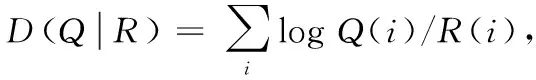
第一阶段的生成器网络损失LG1包括对抗损失、LKL损失(α=1)和感知损失函数Lper,判别器网络损失LD就等于对抗损失。目标函数计算如式(10)所示:
maxLD1=E(I1,t)~pdata[logD1(I1,ρt)]+
Ez~pz,t~pdata[log(1-D1(G1(z,c),ρt))],
minLG1=Ez~pz,t~pdata[log(1-D1(G1(z,c),ρt))]+
αDKL(N(μ0(ρt),Σ0(ρt))|N(0,I))+
(10)
其中,(Ι1,t)~pdata表示真实图像Ι1和文本描述t均来自真实数据分布pdata;z是服从正态分布的随机噪声;ρt是文本编码的特征向量;c是条件向量。

Figure 1 Structure diagram of the discriminator network model in this paper图1 本文判别器网络模型结构图
第二阶段生成对抗网络的目标函数LG2与LD2,如式(11)所示:
2)中国女篮的首发阵容结构要适应日本女篮“五小”的阵容布置,这种阵容结构比的是更快、更硬、更准,因此中国女篮要从体能、技战术到心理素质等有一个全方位的提升。
maxLD2=E(I2,t)~pdata[logD2(I2,ρt)]+
Ez~pz,t~pdata[log(1-D2(G2(m,c),ρt))],
minLG2=Ez~pz,t~pdata[log(1-D2(G2(m,c),ρt))]+
αDKL(N(μ0(ρt),Σ0(ρt))|N(0,I))+
(11)
其中,m=G1(z,c)是第一阶段的生成结果。
3.2 模型结构
为了进一步提高网络训练的稳定性,增强生成图像的质量,本文基于两阶段堆叠结构生成对抗网络提出一种结合谱归一化的文本到图像的生成对抗网络模型。该模型由2个阶段组成,其中第一阶段利用文本描述粗略勾画物体的主要形状和颜色,生成低分辨率图像;在第二阶段将第一阶段的结果和文本描述作为输入生成高分辨率图像。本文2个阶段的生成对抗网络均采用条件生成对抗网络,但是在2个阶段中均在判别器网络的每一层中加入谱归一化,如图1所示。图1a和图1b分别是改进后的第一阶段和第二阶段的判别器网络框架,由于本文生成器的网络框架与StackGAN模型中的生成器是一样的,所以这里不再赘述。本文提出的在网络中加入谱归一化不仅能约束每层的Lipschitz常数等于1,还能不破坏权重矩阵的结构。
在本文中,首先对数据进行预处理:采用文本编码器预训练好的文本特征向量ρt作为输入,但是ρt是一个1 024维的高维向量,因此接着通过一个条件增强模型,降维后得到128维的条件向量c。
第一阶段生成器网络的输入是c和随机噪声向量z生成64×64像素的低分辨率图像;接着判别器网络将64×64像素的图像经过下采样后得到一组向量,再将该组向量和文本特征向量ρt相结合,经过卷积层后输出概率分布,以此判断输入图像的真假。
第二阶段是将条件向量c与第一阶段的生成结果经过下采样模块后得到的向量相结合,通过生成器网络生成256×256像素的图像,再次输入判别器网络,最后判别输出质量较好、内容相对应的256×256像素的图像。
由于生成式对抗网络中生成器和判别器在交替训练时,判别器会很早达到一个可区分真假的理想状态,而判别器达到理想状态后无法给生成器提供任何的梯度信息去优化图像,导致网络出现模式坍塌以及不收敛等问题。本文模型与StackGAN最大的不同点在于判别器的设置,本文在判别器网络中的每一层卷积层后都加一层谱归一化,将每层网络梯度限制在固定范围内,减缓判别器的收敛速度,为生成器提供更多有效信息,从而提高网络训练的稳定性,生成质量更好的图像。本文还在生成器网络中结合了感知损失函数,联合原有的损失函数共同优化生成图像,进一步提升生成图像的质量,使得图像更为自然、真实。
4 实验与结果分析
4.1 数据集及评价指标
为了验证本文模型的有效性,本文在Oxford-102数据集[21]和coco数据集[22]上进行实验,并对结果采用评价指标Inception Score进行评价,其计算如式(12)所示:
I=exp(ErDKL(P(r|y)|P(y)))
(12)
其中,r为生成样本;y为Inception model预测的标签。一个好的生成模型应该生成多样且有意义的图像,因此,边缘分布P(y)和条件分布P(r|y)的KL散度应该越大越好。
4.2 实验结果与分析
由于测试集的图像数量较多且训练次数达到了120次,因此本节选取具有代表性的训练次数作为展示。图2和图3展示了不同训练阶段中不同训练轮次的生成图像效果,并与文献[6]的StackGAN模型进行了对比。
如图2所示,第一阶段不同迭代次数下的图像对比图中可以很清楚地观察到,在阶段一中,文献[6]的模型在迭代60次左右的时候就已经达到生成能力较好的状态,也就是此时判别器达到了区分真假图像的完美能力,不再继续给生成器反馈信息。而本文模型在判别器网络中加入了谱归一化后,减缓了判别器的收敛速度,判别器持续给生成器反馈信息,不断优化生成器网络,最后使得生成器生成的图像更加清晰。

Figure 2 Image comparison under different iteration times in the first stage图2 第一阶段不同迭代次数下的图像对比
图3是第二阶段文献[6]和本文模型生成的图像对比,由于本文模型减缓了判别器的收敛速度,所以在训练过程中不仅训练稳定也可让生成器接受到更多信息,生成更加具有多样性的图像。

Figure 3 Comparison of the images generated by models in reference[6] and this article in the second stage图3 第二阶段文献[6]和本文模型生成图像的对比
表1所示是本文模型与文献[6]模型、文献[8]模型的Inception Score值的对比。由于本文模型的实验设备有限,因此与文献[6]模型得到的数值有差距,但是仍可以看出,本文所提模型的生成效果有较明显的提升。从表1中可以得到,相比于文献[6]模型,本文模型在Oxford-102数据集上的实验结果提升了约9.25%,在coco数据集上提升了约8.19%。
图4所示为当生成器网络的损失函数加入感知损失函数后文献[6]、文献[8]与本文模型的生成图像对比,可以很明显地从图4中观察到本文模型生成的图像内容表现更好:颜色鲜明、生成内容明确。

Figure 4 Comparison of the generated pictures before and after the perceptual loss function is added to the generator network图4 生成器网络加入感知损失函数前后生成图像的对比

Table 1 Comparison of Inception scores of models on different data sets
本文模型生成的图像与其它模型的相比更加真实、自然。
5 结束语
针对文本生成图像任务,本文提出一种结合谱归一化的文本到图像生成对抗网络模型,沿用堆叠生成对抗网络的思想,在其基础上将谱归一化运用到判别器中,将每层网络梯度限制在固定范围内,减缓判别器的收敛速度,从而提高网络训练的稳定性。为了验证本文模型的有效性,在Oxford-102与coco数据集上进行了实验,并采用评价指标Inception Score与StackGAN模型进行了对比。无论是在个人主观观察还是客观评价指标对比上,本文所提的模型都取得了一定的进步。未来将进一步针对较复杂的数据集,将空间注意力与模型网络架构结合起来提高生成图像效果。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
速读·下旬(2021年11期)2021-10-12
数学小灵通·3-4年级(2021年5期)2021-07-16
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
大东方(2019年12期)2019-10-20
今日农业(2019年15期)2019-01-03
科学与财富(2017年22期)2017-09-10
商情(2017年1期)2017-03-22
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
