
基于多模态异质动态融合的情绪分析研究
2022-06-21 08:29:48林鸿飞
中文信息学报 2022年5期
丁 健,杨 亮,林鸿飞,王 健
(大连理工大学 计算机科学与技术学院,辽宁 大连 116024)
0 引言
对人类的情绪进行科学的分析,一直以来都是一个颇具难度的任务。因为人类的情绪表现方式具有多元化的特点,不同的人对于自己的意见的表达形式和特点并不相同。[1]例如人们的表情、神态、动作、声音的表现形式对于每一个个体而言都不是遵循着同一套规律的。随着人工智能技术的发展,使得利用人工智能算法进行情绪分析成为了一个热门的研究方向。以往出现了很多利用单一模态数据的情绪分析工作,但是现实情况中的人们并非仅通过单一的形式表达自己的情绪,人们在交流过程中也是通过多种不同角度的信息对他人的情绪、情感进行推断的。所以,单一模态的情绪分析是不够完备的,而且单一模态的数据更容易受到噪声的影响,从而影响模型的鲁棒性。
多模态的情绪分析工作,需要适宜的多模态情绪分类的训练数据。随着互联网产业的高速发展,各种社交媒体平台也呈现出了蓬勃发展的态势。其中以Youtube等视频网站的社交媒体平台在世界范围内最为突出。而我国的抖音、快手等新兴的短视频平台也在迅速发展的同时得到了广泛的认可。这些社交媒体呈现出越来越蓬勃的生命力,社交媒体平台的用户们在其中分享自己的观点和生活的意愿也大幅度提升,人们可以更容易地获得包含着情绪、情感观点信息的不同模态的数据。这使得多模态情绪分析在近几年成为一个富有潜力的研究方向。不同于单模态情绪分析,如何利用好额外模态的信息是多模态情绪分析中的一个富有挑战性的工作。在人们讲话的过程中,其语言的表达形式、语音语调、神态动作、表情等特征是动态变化的,这使得多模态情绪分析过程会受到更多噪声的干扰,这也是多模态分析的一个挑战。
虽然近些年,多模态情绪分析任务有很多工作都取得了不错的结果,但是其依旧是一个具有挑战性的任务。Poria S等人[2]认为: 多模态情绪分析任务面临四大挑战:
特征空间维度高: 多模态情绪分析的特征空间由多个模态的特征向量组成,通常会有非常高的维度。以往为了解决这个问题,采用早期融合或决策级融合技术,但是表现并不理想。
数据通道的噪声: 每个模态数据中的噪声或错误的数据,会在多模态框架下造成更大的干扰。如何识别及丢弃这些干扰,是一个一直以来都很重要的研究方向。
多模态信息的组合: 从各模态提取到的特征,都需要以一种方式进行融合,融合过程中的挑战包括: 确定各模态在融合中的贡献、过滤其中的噪声,以及处理特征级别融合中的高维特征空间。
个体表达方式的差异: 个体之间对于意见的表达方式是存在差异的。当一个人采用高声调来表达自己的意见时,那么他的音频特征中可能会包含大量的情绪分析和意见挖掘的线索,但这只适用于这个个体。有些人的情绪特征可能更多地表现在面部表情上,那么这就为模型的泛化能力提出了要求。
应对这些挑战,是基于一个基本的事实: 多模态数据融合增加了模型对结果预测的准确性和可靠性[3]。在如何对多模态数据进行恰当的融合方面,产生了很多具有代表性的工作。由于研究者们收集数据的方式多种多样,数据的形式也有很多种类,所以应该考虑不同层次的多模态融合。按多模态融合与各模态建模的先后关系不同,多模态融合分为早期融合、晚期融合和混合融合。此外还有一种“模型级融合”,由研究者自己设计融合的过程。其实早在1971年Kettenring[4]就已经采用典型关联分析的方法对具有相关性的多模态数据进行分析。但目前,研究人员最倾向使用的融合方法依旧是单一的晚期(决策级)融合[2]。这虽然行之有效,但这些工作大多不会兼顾模态的自身内部以及模态之间的相互作用。之前的多模态工作普遍基于一个假设: 多模态数据的信息是均匀的,而现实世界中的各模态的数据往往是混乱的,每条数据中各模态的信息量也存在很大的差异。人们在表达自己的观点和意见的时候,可能会采用反语、隐喻等方式。此时的文本信息可能反而对于情绪预测起到反作用,而音频中的语音语调、视觉信号中的表情神态等信息的融合则对于预测更有帮助。在情感情绪分析任务中,对于每一条多模态的数据而言,各模态对于结果预测所起的作用是随数据的不同而动态变化的。这就使得以往的单一的模态融合方式无法起到理想的作用。
本文设计了一种动态的异质融合方式,同时具备多种不同的特征融合方式。并且为各个异质融合模块设计了一种动态权重因子,挖掘各模态融合中特征对于预测结果的重要程度,自适应地调整适合当前数据集的模态交互方式。从而在多模态融合过程中获取到更加鲁棒的模态间的一致性特征,并且使得各模态的融合过程更加具有可解释性。与此同时,本文受到Yu等人工作[5]的启发,又采用自监督学习对每个模态进行自监督训练以获得各模态的自身的差异化特征。最后,将以上的模型作为子任务,基于多任务学习的框架,联合训练各个子任务从而使得模型学习到模态之间的一致性特征和差异化特征。本文在CMU-MOSI[12]及CMU-MOSEI[13]数据集上对模型进行了测试,得到了较为理想的实验结果,其性能指标超过了大多数基线模型。
1 相关工作
在这一节中,主要介绍基于多模态融合的情绪分析、自监督学习、多任务学习这三个领域的相关工作,并阐述我们从中受到的启发。
1.1 基于多模态融合的情绪分析
利用计算机手段进行情绪情感分析的工作,可以追溯到Picard等人[6]于1995年的研究。Picard首次在此工作中提出了“情感计算”的概念,旨在使得计算机拥有类似于人类的观察、理解、生成情感特征的能力,并最终实现真正意义上的人机交互。而情绪分析又是情感计算中的一个子任务,在当今社会背景下有着广泛的应用。而随着人工智能技术、大数据技术等的高速发展,结合这些技术的情绪分析工作,无论从技术进步还是实际应用角度都是当前计算机科学研究中的一个热门方向。
Poria等人[7]于2017的工作中,通过对单个模态的情绪识别方法进行大量讨论之后,又在相同的数据集上进行了多模态融合方法的研究,并将单模态方法与之进行了充分的对比。由此验证了恰当的模态融合,大幅度地提升了情绪识别系统的性能。
早期的多模态融合工作多数以早期融合的方式为主,早期融合是特征级的模态融合策略,对多个模态的数据进行一系列的特征提取及构造之后进行融合。其融合方式较为直观,而且可以最大程度地保留模态自身的信息,所以至今也依旧有广泛的应用。早期的融合工作,例如Emerich于2009年发表的工作[8]中将语音与面部表情的特征在归一化之后进行拼接,从而构造出一个新的特征向量。实验表明,两种模态融合使得系统的性能和鲁棒性得到了提高,但由于这种简单的融合方式易使特征空间维度随着模态增多而过度提高,导致性能下降。之后也存在一些通过降维手段来试图解决特征空间维度过高的工作,但是效果并不十分的理想。2014年Google 公司的Mnih等人设计了注意力机制[10],这为本文的多模态融合提供了新思路。Tsai等人[9]结合Transformer提出了一种跨模态的Transformer,使得模型可以学习到模态间的注意力,以此调整模态融合的过程,并且使得这个过程更具有可解释性。
而另一种常见的融合方式为晚期融合,其思想是: 学习到各模态的权重、可信度,从而进行决策和协调。在保证性能优于单模态方法的前提下,晚期融合的过程更容易进行,且比起早期融合可以更好地保留模态之间的差异性,但也因此比早期融合更容易丢失模态之间的相关性。例如,Zadeh等人于2017年提出的TFN(Tensor Fusion Network)[11]模型可以从各模态学习到模态之间的相互联系,从而进行模态的晚期融合决策。
美国卡内基梅隆大学的Zadeh团队发布了CMU-MOSI[12]和CMU-MOSEI[13]情绪分析数据集,并且在此之上进行了大量的工作。
受到Zadeh等人提出的TFN模型的启发,我们认为这种多层次的模态融合方式可以更加完整地捕捉到模态间的相互作用。但是,对于不同的任务来说,各模态的信息对于结果预测的重要程度是不同的,模态的信息有强弱之分[27],弱模态在拥有少量关键特征的同时,还可能存在大量无用的噪声。而且,数据中各模态信息的重要性也是动态变化的。以往的多层次融合方式并不具备这种动态的调整能力。基于这样的想法,本文设计了一种动态的异质融合网络。通过可训练的权重因子单元,调节各种层次的融合过程的权重,从而实现更加有效的模态融合,同时还可以使得模型的融合过程更加具有可解释性。
1.2 自监督学习
传统的分类方法,都需要大量的标注数据来进行训练,但是带有标注的数据通常难以获取[14]。训练深度神经网络的过程中也需要大量的标注数据[15]。如果标注数据的数量过少,模型就容易在训练数据上过拟合,严重影响预测结果的准确性。在这种前提下,通常会尝试采用半监督或者弱监督的方法。自监督方法是半监督方法的一个子集,自监督方法通常应用于: 在不使用任何人标注数据的情况下,从大规模未标注数据中学习到数据的特征。在Qiu L等人2009年发表的工作中[17],基于情绪词典并结合简单的自监督学习方法,进行了情绪分类工作,对比基线模型取得了显著的性能提升。预训练模型也是自监督学习的应用之一,自2018起,Devlin等人基于Transformer提出了BERT[16]这种强大的NLP预训练模型,在多种NLP任务上取得了显著的效果。BERT的出现也使得基于文本的情绪分析工作取得了新的进展,Lan等人[18]在BERT的基础上,利用自监督学习的损失优化了针对文本的连续性的建模能力,并在Stanford Sentiment Treebank数据集上进行了验证,取得了较好的效果。
以往的自监督学习的情绪分析方法,通常仅仅利用了单个文本模态的信息。但是现实世界中,对于情绪的预测,会利用多种来源的信息,包括不限于: 人物的神态、表情、动作、说话的音调等。虽然在机器人控制领域已经有一些多模态的自监督学习方法,但是在情绪分析领域还较少出现。本文利用Yu等人[5]设计的自监督学习方法学习每个模态的表示,再结合本文提出的动态异质融合网络,从多模态数据中捕捉到了更多的关键特征,从而加强了模型的性能。
1.3 多任务学习
人类可以在学习过程中同时学习多个任务,并且能够使用在特定任务中学到的知识来帮助学习其他任务。受到这种人类学习能力的启发,多任务学习(MTL)旨在: 通过利用不同任务中学习到的知识来改善整体的泛化性能[20]。相比于学习单个任务,多任务学习在训练过程中存在两个重要的问题: 首先,研究者应该如何共享不同任务的神经网络的参数,目前主要有软共享和硬共享这两种方法。其次是采用怎样的策略来平衡多个任务的学习过程。国内在多任务的情绪分析领域,尤其是结合了多模态的研究工作,在近几年也呈现出发展态势。吴良庆等人[21]提出了一种多模态的多任务融合学习网络,将每个模态看作是一个子任务,再通过共享子任务参数的方式进行融合。林子杰等人[22]将多任务学习方法应用到预训练模型中,并采用硬共享策略训练多种模态的分类任务,有效避免过拟合的风险。
当前大部分的基于多任务学习的多模态方法,普遍只建立了单个模态的任务,然后用多任务学习策略共享每个子任务的参数而实现。这种单一的架构,难以兼顾多模态信息中的一致性和差异性信息。本文采用多任务学习策略,连接了一个动态的异质融合网络的子任务与三个单模态自监督子任务,通过异质融合方式学习模态间的一致性特征,再利用三个单模态子任务学习模态自身的独特特征,更好地实现了模态间的相互作用,使得模型在情绪预测任务中获得了更高的性能。
2 多任务多模态自监督异质动态融合网络
多模态学习不可避免地要进行多个模态的融合,以此建立模态之间的相互作用,从而使得增加模态之后,达到提高模型性能的目的。以往大多数的多模态融合工作,虽然取得了很多进展,但是对于不同的数据最适宜的模态融合方式也很可能是不同的。受到Zadeh等人的TFN(Tensor Fusion Network)模型[11]中层次化模态融合的启发,本文提出了一种异质动态融合网络(Heterogeneous Dynamic Fusion Network,HDFN)结构。在对多个模态进行层次化融合的基础上,还加入了可训练的动态权重调节因子。本文在多任务学习的框架中加入了HDFN后,不仅整体性能得到了提高,而且能更透明地实现模态的融合过程,便于了解模态之间如何进行相互作用,从而更清晰地了解到模态间相互作用的强弱关系。
在本节中,主要介绍本文所提出的模型,称之为多任务多模态自监督异质动态融合网络(Multi-task Multimodal Self-Supervised Heterogeneous Dynamic Fusion Network,MM-SS-HDFN)。受到Yu等人的工作[5]的启发,本文也采用了三个单模态的子任务联合一个采用HDFN结构的多模态子任务的多任务学习架构,不仅实现了多模态融合过程的动态自适应及自我调整,而且还通过多任务学习的方法,兼顾模态的差异性特征和一致性特征。在2.3节将介绍该模型的整体结构。
2.1 基本概念
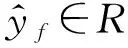
2.2 特征提取
对于不同模态的数据,应该使用不同类型的特征提取方法。本文为三个模态(文本、声音、图像)的输入数据(Xt,Xa,Xv)选择了不同的特征提取方法,从而从数据中获得相对最恰当的表示。
文本模态: 对于文本模态的数据(Xt),本文采用当今应用最为广泛的文本预训练模型BERT(Bidirectional Encoder Representation from Transformers)来进行编码,从而获得对应的嵌入表示作为文本特征Ft,以此作为模型的文本模态的输入。
音频、视频模态: 对于音频和视频模态的数据,采用多模态开发工具包(CMU Multimodal SDK)[23]提供的特征作为输入数据(Xa,Xv)。然后,利用长时期记忆网络(LSTM,Long Short-Term Memory)提取其中的时序特征,从而获得输入到模型网络中的特征向量Fa,Fv。
从各模态提取特征的过程如下:
数据经过特征提取过程之后,获得了来自了三个模态的表示:Ft,Fa,Fv。
2.3 模型整体结构
本文所提出的MM-SS-HDFN模型的整体结构如图1所示,其组成共分为以下两个部分:
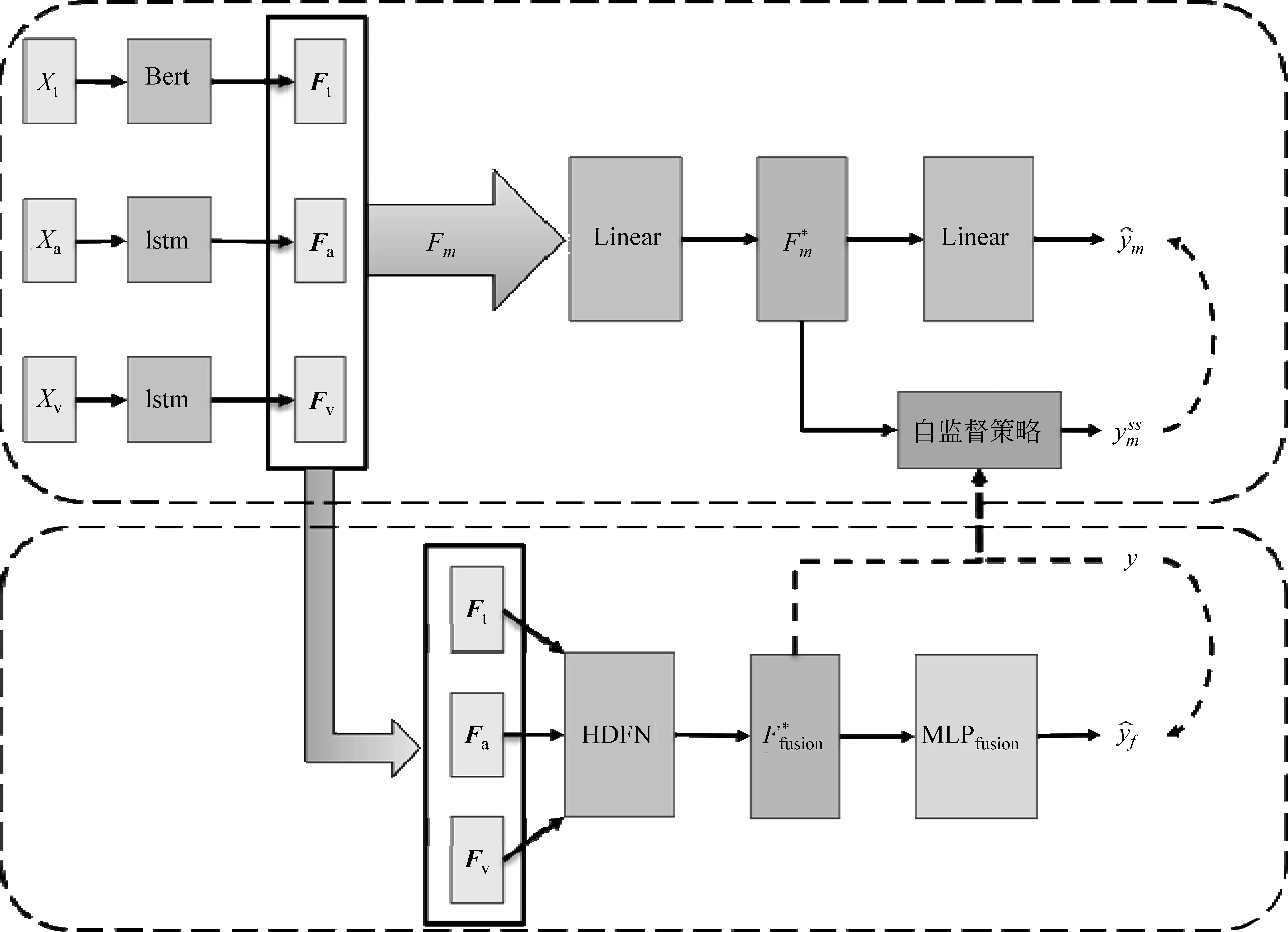
图1 多任务多模态自监督异质动态融合网络整体架构图
多模态异质动态融合子任务模块(HDFN):将各模态的特征同时作为输入,进行动态的异质融合,从而使得模型可以学习到相对理想的多模态表示,然后通过分类器输出该网络的预测结果。本文将在2.3.1节详细介绍这一模块。
单模态自监督子任务模块:每个模态的输入都对应一个独立的自监督学习模块。它们彼此的结构完全一致,仅仅是输入的数据的模态不同。每个子任务模块都会采用自监督学习的策略生成一个预测结果。此部分的算法主要基于Yu等人设计的单模态标签生成模块(ULGM, Unimodal Label Generation Module)[5],公式详见2.3.2节。
最后,本文利用多任务学习的方法,将这些子任务联结起来。利用硬共享(hard-sharing)的策略共享模型的参数,并且采用了一种权重调整的算法平衡子任务的输出。本文将在2.3.3节给出多任务学习的目标函数。
接下来本文将从多模态异质动态融合网络、单模态自监督网络、多任务学习目标函数这三个方面进行具体的介绍。
2.3.1 多模态异质动态融合网络
多模态异质动态融合网络用于进行多模态子任务的训练。该多模态情绪分析模型受到了TFN模型[11]、吴良庆等人[21]的多模态情绪识别方法的启发,采用层次化的结构进行多模态的融合,分别学习单模态、双模态、三模态的表示。这是一种异质的融合方式,本文采用这种差异化的异质融合方式的原因在于: 不同模态的信息对于本任务预测结果的帮助是不一致的,甚至有些时候某个模态的信息对于当前任务的结果预测甚至是噪声和干扰,故而采用了这种异质的模态融合方法,这使得HDFN模型在充分结合三种模态之间联系的前提下,更加充分地差异化地利用模态内部的信息。此模块分为以下几个结构: 多模态特征输入层、HDFN模块、特征(融合后)表示层、分类器层。下面将依次进行详细介绍。
多模态特征输入层:原始数据通过特征提取网络之后,已经提取到了三个模态的表示(Ft,Fa,Fv),无须进行进一步的处理,可直接输入到HDFN模块,用于特征融合。
HDFN模块:从各模态学习到的表示,首先在此处需要进行层次化的异质重组,模型的结构如图2所示。对于M种模态的数据,就一共需要进行M个层次的异质融合。
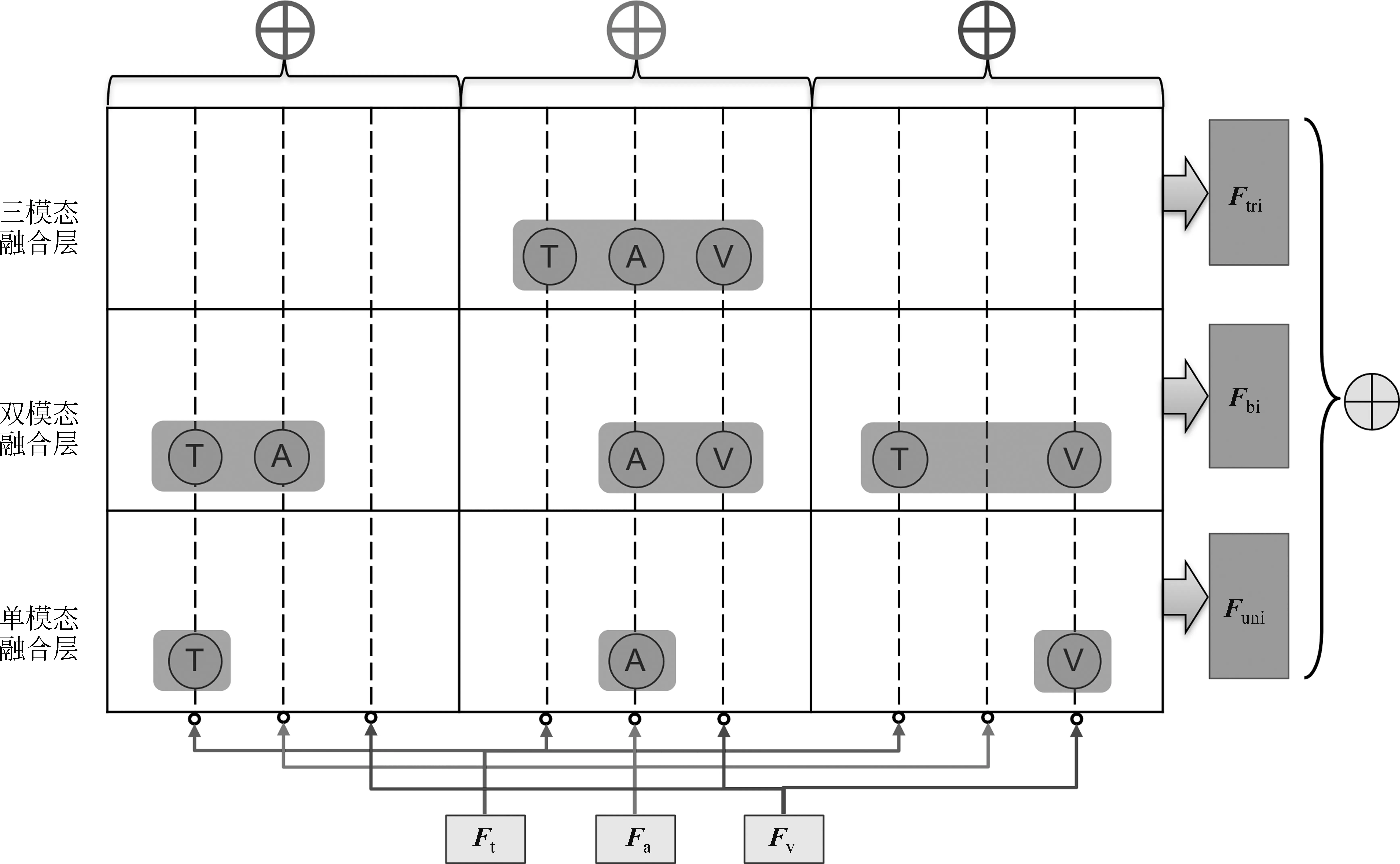
图2 多模态异质动态融合网络(HDFN)架构图
本文采用的数据有三种模态,所以一共有三个级别的融合: 单模态级、双模态级、三模态级,其公式分别如式(1)~式(3)所示:
单模态:
(1)
双模态:
(2)
三模态:
(3)
由此,分别得到了三种层次的模态融合表示,其中单模态因为不需要融合,所以直接用作单模态级的表示(Funi)。双模态级的表示(Fbi)是单个模态的表示的两两组合,而三模态级的表示(Ftri)是三个模态的表示的组合。按照多模态表示学习的理论,每一种模态的特征表示Fm,都属于其自身的语义空间Sm。从数学意义上讲,多模态的特征空间可以映射到一个包含全部模态特征的空间SM中,且多模态的特征空间必然会存在共享语义空间Sshare。为了更好地学习到多模态表示的联合分布,可以采用任意一种神经网络f(·)(本文此处选择了多层感知机)将多模态表示从高维空间映射到一个低维空间,从而获得模态间的互信息。按照常规的多模态融合,只需要对[Ft;Fa;Fv]进行降维,从而学习到多模态融合特征在低维空间的表示。譬如:hf=ReLU(f([Ft;Fa;Fv]))。但由于对最终的输出起着决定性作用的特征表示并非只有三个模态的共享语义特征,我们也应注意到每个模态的差异性特征对于结果预测的作用。而且从Zadeh等人的实验[11]中可以看出,在融合的过程中,可能出现某些模态的特征对最终预测的影响很大,而其他模态对于预测的影响很小,甚至是噪声的情况。所以本文采用了分层次的模态融合方式,如式(4)~式(6)所示。
理想状态下,可以通过这种多重的融合方式学习到最佳的融合方式,使得所获得的融合特征的表示更符合当前数据的特点。实际上,即使是对于同一来源的多模态的数据集,其最适宜的模态融合方式也是动态变化的。为了应对这样的情况,本文设计了一种动态调整结构,命名为Γ-单元,用来动态地调整各融合方式的权重,从而使得融合的性能更佳。本文为HDFN中的每一层级的每种异质融合子模块设计了一个可训练的Γ-单元。每个Γ-单元由一个MLP构成,最后通过一个ReLU激活函数对其进行归一化,将输出的权值范围限定到0~1的值域区间。通过Γ-单元生成的γ-因子就可以使得模型捕捉到每一种异质融合方式对于最终结果预测的重要程度,以此作为各种异质融合方式的权重,从而动态地调整融合过程。这就是本文设计的Γ-单元的基本原理,计算如式(7)~式(8)所示。
其中fh表示任意一种的异质融合形式,而Ffh表示每一种异质融合的特征表示,即:
综上所述,由于式(4)~式(6)不具备自我调节的能力,且过程不可见。这使得模型无法根据实际需要有所侧重地去捕捉模态融合后的特征。所以,我们采用Γ-单元对其进行了改进,如式(9)~式(11)所示。
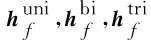
(12)
特征表示层: 将获得的多模态融合特征的表示hf通过一个线性层将异质融合表示投影到低维空间,如(13)所示。
(13)
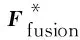
(14)
2.3.2 单模态自监督网络
单模态自监督网络用于处理三个单模态的子任务,它们将在训练的过程中与多模态融合网络共享模态特征的表示,其基本架构如图1中的上半框所示。由于不同的模态之间存在着维度的差异,不利于计算,所以将输入的模态表示Fm投影到一个新的特征空间中,如(15)所示。
(15)
其中,m∈{t,a,v},也就是说Fm代表{Ft,Fa,Fv}与多模态融合网络的输入是一样的。
2.3.3 多任务学习目标函数
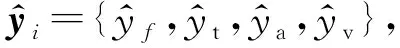
(18)
3 实验与分析
本节包括以下四个部分: 实验使用的数据集、对比实验的基线模型、实验设置、各模型的实验结果并分析MM-SS-HDFN模型与基线模型在性能上的差异、消融实验及分析。
3.1 实验数据
本文采用的实验数据是美国卡内基梅隆大学的Zadeh等人发布的CMU-MOSI数据集[12],及CMU-MOSEI数据集[13]。MOSI数据集发布于2016年,MOSEI数据集发布于2018年。它们都是利用社交媒体数据得到的多模态情绪情感分析数据集。MOSI包括了从93个Youtube的视频中获取的2 199个独白类型的短视频片段。MOSEI则包括了来自5 000个视频的23 453个视频片段。数据的标注由人工完成,视频的标注即为情绪的评分,分数的值为从-3到+3的七个等级,其中负值代表消极情绪,正值代表积极情绪,0分代表无情绪。在实验过程中,为保证结果的公平性,本文对MOSI按照6:1:3的比例划分训练集、验证集、测试集,对MOSEI按7:1:2的比例进行划分,具体的统计信息如表1所示。
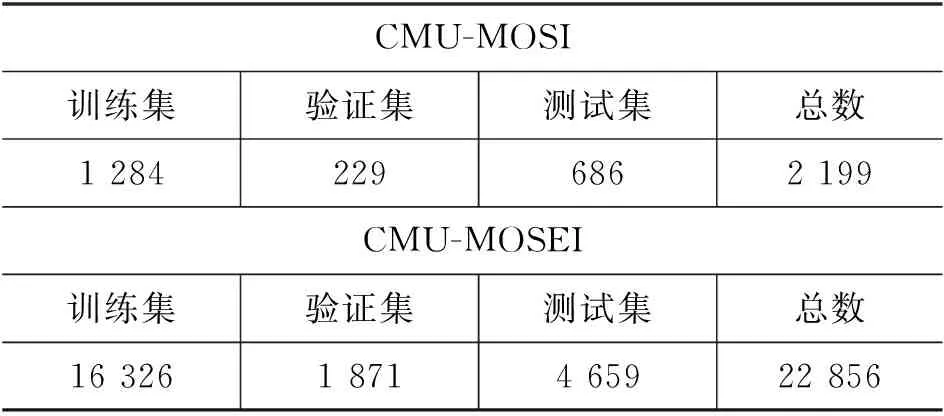
表1 数据集的统计信息
3.2 对比基线模型
为了验证MM-SS-HDFN模型的性能,本文将其与主流的多模态情绪分析的基线模型进行了对比。下面将对本文采用的基线模型进行简单的介绍。
EF-LSTM(Early-Fusion LSTM): 采用了早期融合的LSTM模型。在对模态特征进行编码之前,对各模态的特征向量进行拼接,将拼接后的特征向量作为LSTM的输入。
LF-LSTM(Late-Fusion LSTM): 晚期融合的LSTM模型。分别为每个模态设计一个LSTM网络,以此对各模态的特征进行编码,并对这几个LSTM的最后一个隐藏层所输出的隐向量进行拼接,作为多模态的特征表示,再通过分类器进行输出。
MTL(Multi-Task Learning)[22]: 这是一种基于多任务学习的情绪识别模型。引入了单模态的情绪识别子任务与多模态任务进行共同训练,通过共享层连接各个子任务的模型结构,可以更好地捕捉模态中的情绪倾向的特征。根据文中的实验结果,采用MM-BERT-Linear的共享层策略时取得的效果最佳,本文也将采用这个结果与MM-SS-HDFN模型进行对比。
MFN(Memory Fusion Network)[24]: 该模型由Zadeh等人于2018年提出,用于存在时序关系的多模态任务。利用门控结构随时间的顺序存储汇总跨模态的模态交互信息,从而对各模态的融合进行持续的建模并实现跨模态的交互。
TFN(Tensor Fusion Network)[11]: 该模型由Zadeh等人于2017年提出。TFN模型通过建立多维的张量,并通过扩展各模态的特征向量的维度后,相互之间进行外积运算,从而使得模型整体捕获了单模态、双模态、三模态的相互作用。
RAVEN(Recurrent Attended Variation Embedding Network)[25]: 这是一种基于注意力机制的模型,利用文本模态之外的模态特征调整文本模态的特征表示。该文指出了文本模态之外的信息对理解语义具有重要的作用。
MulT(Multimodal Transformer)[26]: 这是一种多模态的Transformer模型,是一种对于传统的Transformer的拓展。通过采用双模态的跨模态注意力机制,它实现了跨模态的特征对齐。
SS-MM(Self-Supervised Multi-task Multimodal)[5]: 该模型通过多任务学习策略,连接了多模态融合任务及三个单模态的自监督任务,使得模型可以同时兼顾模态间的一致性及差异性信息。
3.3 实验设置
本文的MM-SS-HDFN模型是在Yu等人的Self-MM模型[5]的基础上改进而来,在多模态融合的模型部分进行了改进和细化,增强了模型的整体性能和可解释性。部分参数细节与Self-MM模型类似,由于多个模态融合后的特征空间维度非常高,所以本文采用了Adam优化算法进行优化。BERT采用了5e-5的初始学习率,其他部分采用1e-3的学习率。
我们在CMU-MOSI和CMU-MOSEI数据集上对本文所提出的模型及各基线模型进行了情绪分析实验。由于情绪标签有-3~+3共七个值,本文的实验以区分消极情绪和积极情绪(即情绪极性预测)为主要任务。对于情绪分类任务,将y<0的数据标记为消极情绪,将y>0的数据标记为积极情绪,不对0值的数据进行评价。对于情绪回归任务选用MAE(平均绝对误差,Mean Absolute Error)和皮尔逊相关系数(Pearson Correlation,Corr)作为评价指标,并利用二分类准确率(Acc-2)和F1值作为分类性能的评价指标。
3.4 实验结果与分析
在这一节,先将本文的模型与基线模型的性能进行了对比和分析,之后进行了消融试验,以验证本文所提出的模型设计的合理性。
3.4.1 与基线模型的对比及分析
在表2上,分别展示了各模型在CMU-MOSI和CMU-MOSEI数据集上的情绪分析性能。可以看到,本文的MM-SS-HDFN模型在两个数据集上的分类性能均领先于当前的模型,且在MOSEI上的回归性能表现也领先其他模型,但MOSI数据集上的回归表现却并非最佳。我们认为,这是由于MOSEI的数据数目远超MOSI,使得测试实验更加稳定造成的,也就是说模型在MOSEI上的表现可能更具有代表性和普适性。

表2 在各数据集上各模型的实验结果
首先,通过TFN及MFN这两种经典的多模态情绪预测模型的实验结果,可以观察到对文本模态采用BERT对文本模态进行处理可以显著地提升各性能指标。这说明,即便是在多模态的研究工作中,使用单个模态的预训练模型也对提升多模态模型的整体性能是很有帮助的。将BERT加入到多模态融合模型后,模型的性能提升,意味着预训练的过程有利于模态之间的融合,使得模型更容易捕捉到关键特征。而TFN模型属于与本文的HDFN类似的层次化融合模型,受BERT提升较为明显启发,本文也对文本模态进行了BERT的预训练。
通过与EF-LSTM、LF-LSTM、TFN、RAVEN等模型的对比可以显而易见地看出: 由于本文的模型采取了混合融合的策略,相比于单纯的早期融合或者晚期融合,混合融合的策略可以从数据中学习到更丰富的信息,从而使得整体的性能远高于传统的单一融合策略的方法。而相比于MTL这种纯粹的多任务多模态的模型,本文的方法在回归性能上存在一定劣势,但分类的性能明显优于MTL。这说明MTL模型虽然针对情绪强弱的区分任务误差较小,但是捕捉情绪的极性特征的能力弱于MM-SS-HDFN。本文的MM-SS-HDFN模型在回归性能上略高于SELF-MM模型,两个模型在回归性能上的表现基本一致,而在分类性能上MM-SS-HDFN表现得更有优势。总体来看,MM-SS-HDFN在所有的模型中具有最好的分类性能,拥有较为可靠的捕捉情绪的极性特征的能力,在回归指标上也仅次于MTL模型,但情绪分类是本文的主要目标,且MM-SS-HDFN的分类性能明显优于MTL模型,在很大程度上具有较大的优势。
值得注意的是,通常而言对多个模态的信息进行对齐(align)是有利于模型性能的提升的。但本文没有采用对齐的数据,我们将在后续的工作中结合模态对齐的工作对模型做进一步改进。
综上所述,可以看到,MM-SS-HDFN在两个数据集上的表现均较为突出。这说明,结合了多任务和自监督方法的多模态融合,比传统的多模态融合拥有更大优势。通过多任务学习的策略引入的自监督模型捕捉到了更多的特征,从而提升了模型整体的性能。
3.4.2 消融实验
为了探索本文提出的HDFN(异质动态融合网络)在模型整体中的贡献,以及每个异质融合结构对训练结果的影响,在两种数据集上进行了两组不同的消融实验,分别为:
模型整体消融试验: 本组实验中分别设置了无Γ-单元的异质融合网络、带有Γ-单元的三模态动态融合网络(去掉了异质融合)来取代原模型中的HDFN网络进行消融实验。同时,还设计了一个不包含HDFN的多模态多任务模型,来检验HDFN对于整体性能的提升。实验结果如表3所示。其中减号“-”表示在这组实验中删掉的模型结构。
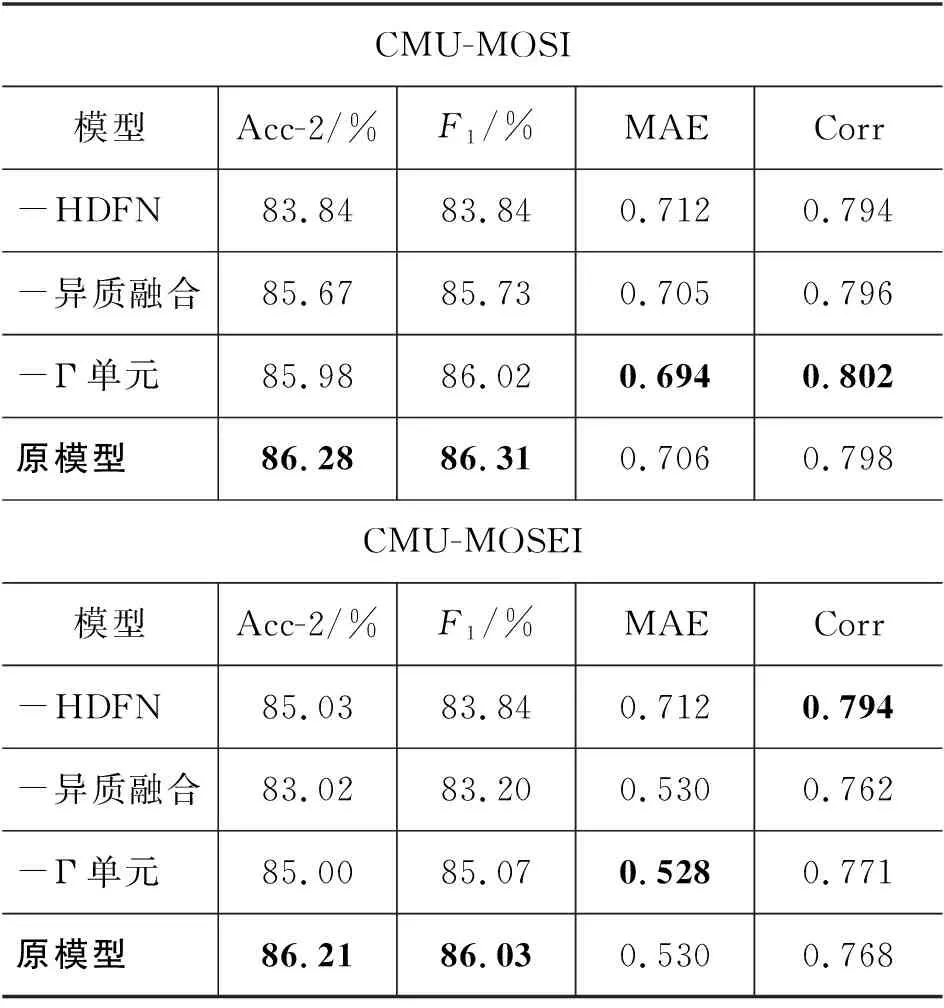
表3 模型整体消融实验的结果
异质融合消融实验: 分别将HDFN中的各层次(单模态级-Uni,双模态级-Bi,三模态级-Tri)的异质融合结构进行了不同程度的删减,以此来探索各级的异质融合结构在多模态情绪预测中所起的作用,实验结果如表4所示。其中,减号“-”表示在这组实验中删去的异质融合结构。
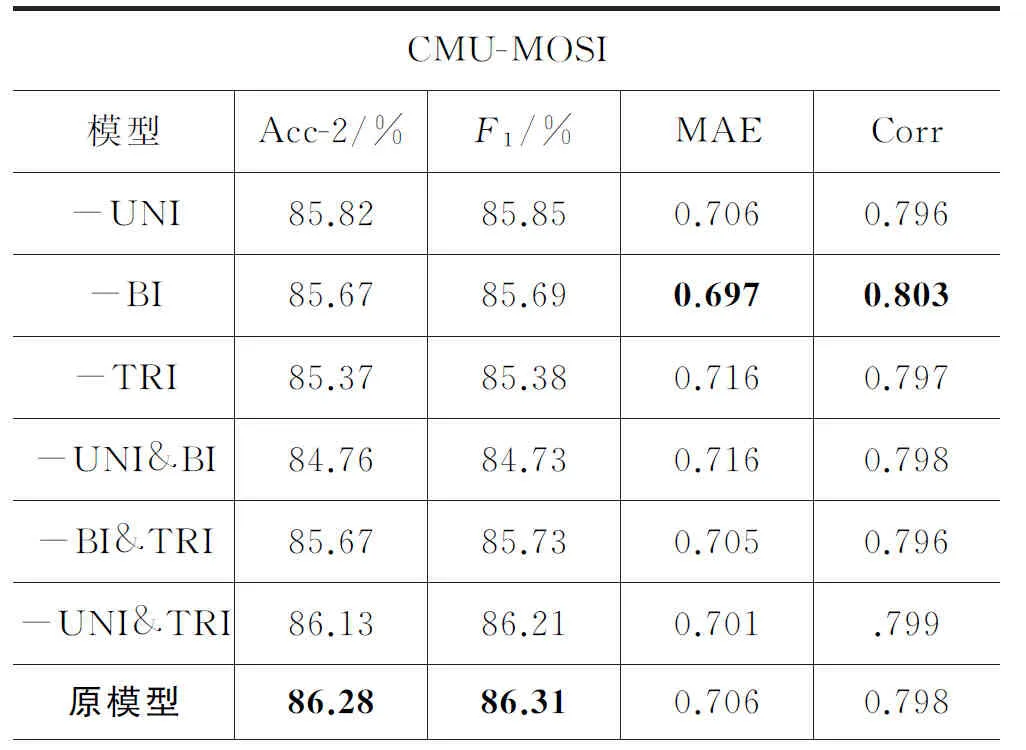
表4 异质融合消融实验的结果
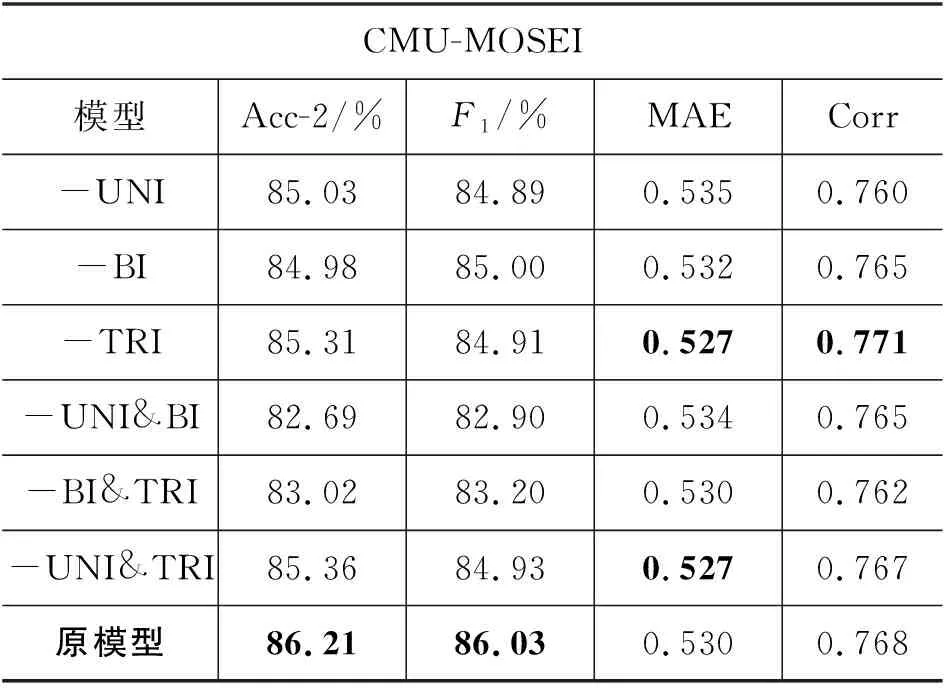
续表
由模型整体的消融实验结果可以看出: 在去掉了模态动态异质融合结构之后,整体模型的性能出现了显著下降。这说明本文设计的HDFN在情绪预测过程中,比单纯的多任务自监督学习方法捕捉到了更多有用的特征。而“-异质融合”和“-Γ-单元”的模型在分类性能上比原模型在MOSI数据集上的性能下降程度较少,但失去了异质融合方式的模型性能下降更加明显。而失去了异质融合方式的模型,在MOSEI数据集上性能下降更为明显,但从基本规律上来看,与MOSI上的表现类似。这两组实验印证了: 异质的融合方式对于情绪分类的性能影响更大。
值得注意的是,将本文提出的MM-SS-HDFN模块中各单元的γ因子去除之后,HDFN中仅保留了特征扩展的部分,失去了动态的自适应调节能力。虽然此时的模型性能产生了一定程度的下降,但也并没有超过SS-MM(自监督的多任务多模态)模型。而SS-MM模型与本文的工作在架构上是相似的,差异主要体现在本文提出的HDFN模块之中。这说明,仅依靠特征扩展并不能使模型性能提高,γ因子的调节作用与层次化的特征扩展共同作用才是提高模型性能的关键。我们还可以看出,它们在回归性能上的差距不明显。本文采用的动态异质融合方式,更侧重于加强模型捕捉情绪分类的极性特征的能力。
本文进行的异质融合结构的消融实验结果表明: 每一层级的异质融合方式对于模型整体的重要性存在着一定差别,而且其中存在着较为复杂的相互作用。从消融实验结果可以看出,模型在两组不同的数据集上表现出了一些相似的特性(详见表4)。在仅保留一种融合形式的情况下,根据“-UNI&TRI后的模型”在两组不同的数据集上的实验结果都可以看出: 只使用双模态的融合方式,可以使得模型的性能得到最大程度的保留,与原模型性能差距不大。而从“-UNI&BI后的模型”在两个数据集上的表现又可以注意到: 仅使用三模态拼接的简单融合,是会导致性能明显下降的,这是因为本文采用的Γ-单元对融合方式进行动态的权重调节,受到权重因子的影响,必然使得特征信息衰减,使得模型性能大幅下降,此时权重因子产生了负面的效果,这也与实际情况是相符的。
结合“-UNI”、“-BI”、“-TRI”这三组实验结果还可以看出: 双模态融合与三模态融合这二者缺少一方时,模型性能下降较大,这说明双模态和三模态这两种不同层次的融合方式之间,对于特征的捕捉存在着较强的互补作用。这也验证了本文所提出的三种不同层次的异质融合方式共存的必要性。
而模型在两个不同的数据集上的消融实验结果存在一些共性的同时,也存在着一定的差异,这更加印证了: 不同数据的各模态信息对结果预测的权重是动态变化的。值得注意的是: HDFN结构在删减两个结构后(即: “-UNI&BI”、“-BI&TRI”、“-UNI&TRI”),比删减一个结构(即: “-UNI”、“-BI”、“-TRI”)的模型性能在MOSEI上的下降更明显。而MOSEI的数据数目大概是MOSI的10倍,数据的各模态信息质量存在差异的可能性更大。这意味着本文提出的HDFN模块的各组成部分不是冗余的,其中的一些结构在数据量足够大的时候起着重要的作用。结合两组“-Γ-单元”的消融实验结果,更表明了本文利用权重调节因子对不同层次的融合单元起到了调节作用体现了本文提出的这种层次化的动态自适应融合方式的存在价值。
4 结论
本文提出了一种层次化的异质动态模态融合方法,该方法对多个模态进行层次化的异质融合,并通过可训练的动态权重因子,根据具体的任务和数据,动态地调节各种异质融合方式的权重。这使得模型能够从多种模态的信息中捕捉到最关键的特征信息,减少弱模态中与任务无关的特征信息对结果预测的干扰,通过调整权重的方式自动地为模型选择出最佳的融合方式。实验表明,将本文提出的方法加入到多任务学习的框架中之后,提高了模型整体的性能,在测试集上性能优于主流基线模型。在消融实验中,可以看到模态之间确实存在复杂的相互作用,不同的融合方式对于结果预测的重要程度也存在一定的差异。本文的模型使得各模态的融合过程更加具有可解释性。
在未来的工作中,我们将在捕捉各模态的差异性信息上做出改进,尝试加入正则项及半监督的方法,更好的处理弱模态的差异性信息,从而正确地区分弱模态中的有价值的信息及无用的噪声,进一步提高模型的鲁棒性和性能。
猜你喜欢
中国生物医学工程学报(2019年6期)2019-07-16 07:52:40
自动化学报(2016年3期)2016-08-23 12:02:56
电测与仪表(2016年5期)2016-04-22 01:13:46
湖北经济学院学报·人文社科版(2015年8期)2015-12-29 05:53:07
云南师范大学学报(自然科学版)(2015年5期)2015-12-26 12:46:16
中央民族大学学报(自然科学版)(2015年2期)2015-06-09 08:45:26
物理实验(2015年10期)2015-02-28 17:36:52
上海电机学院学报(2015年4期)2015-02-28 14:30:00
计算物理(2014年2期)2014-03-11 17:01:39
计算机工程(2014年6期)2014-02-28 01:26:17
