
基于长-短时序特征融合的资源负载预测模型
2022-06-21 06:55王艺霏于雷滕飞宋佳玉袁玥
计算机应用 2022年5期
王艺霏,于雷,滕飞*,宋佳玉,袁玥
(1.西南交通大学 信息科学与技术学院,成都 610000; 2.北京航空航天大学 中法工程师学院,北京 100000;3.北京航空航天大学 杭州创新研究院(余杭),杭州 310000)(∗通信作者电子邮箱fteng@swjtu.edu.cn)
基于长-短时序特征融合的资源负载预测模型
王艺霏1,于雷2,3,滕飞1*,宋佳玉1,袁玥1
(1.西南交通大学 信息科学与技术学院,成都 610000; 2.北京航空航天大学 中法工程师学院,北京 100000;3.北京航空航天大学 杭州创新研究院(余杭),杭州 310000)(∗通信作者电子邮箱fteng@swjtu.edu.cn)
高准确率的资源负载预测能够为实时任务调度提供依据,从而降低能源消耗。但是,针对资源负载的时间序列的预测模型,大多是通过提取时间序列的长时序依赖特性来进行短期或者长期预测,忽略了时间序列中的短时序依赖特性。为了更好地对资源负载进行长期预测,提出了一种基于长-短时序特征融合的边缘计算资源负载预测模型。首先,利用格拉姆角场(GAF)将时间序列转变为图像格式数据,以便利用卷积神经网络(CNN)来提取特征;然后,通过卷积神经网络提取空间特征和短期数据的特征,用长短期记忆(LSTM)网络来提取时间序列的长时序依赖特征;最后,将所提取的长、短时序依赖特征通过双通道进行融合,从而实现长期资源负载预测。实验结果表明,所提出的模型在阿里云集群跟踪数据集CPU资源负载预测中的平均绝对误差(MAE)为3.823,均方根误差(RMSE)为5.274,拟合度(R2)为0.815 8,相较于单通道的CNN和LSTM模型、双通道CNN+LSTM和ConvLSTM+LSTM模型,以及资源负载预测模型LSTM-ED和XGBoost,所提模型的预测准确率更高。
资源负载预测;卷积神经网络;长短期记忆网络;格拉姆角场;双通道;时间序列预测
0 引言
工业互联网作为新一代信息技术与制造业深度融合的产物,日益成为新工业革命的关键技术支撑和深化制造强国的重要基石。但在工业互联网场景下,边缘设备的资源使用率问题日渐突出,其能源消耗也在不断上升。通过对全球数据中心进行随机使用,统计得到全球服务器的处理器使用率只有17.76%[1],较低的资源使用率意味着更多的投资成本和较高的能源消耗,因此提高工业互联网设备中心的资源使用率,特别是处理器的使用率,具有较高的经济和环保价值。
需要对资源负载进行预测,预测方法大多是与时间序列相关的,一般可以分为三类:传统的统计模型、基于机器学习的智能算法和混合算法。传统的统计模型[2-9],比如自回归(Auto-Regressive, AR)模型、移动平均(Moving Average, MA)模型、AR与MA相结合的自回归移动平均(Auto-Regressive Moving Average, ARMA)模型,以及整合移动平均自回归(Autoregressive Integrated MA, ARIMA)模型等,被广泛应用于对时间序列的预测。机器学习模型采用一系列的机器学习方法来实现预测,比如多层感知器(Multi-Layer Perceptron, MLP)[10-11]、自组织特征映射(Self-Organizing Feature Mapping, SOFM)神经网络[12]、支持向量机(Support Vector Machine, SVM)、K近邻法(K-Nearest Neighbor, KNN)[13]、自然启发算法、深度置信网络(Deep Belief Network, DBN)和人工神经网络(Artificial Neural Network, ANN)等[14]。其中神经网络是现在针对应用变形最多的方法,例如带有反向传播算法的前馈神经网络,即反向传播神经网络(Back Propagation Neural Network, BPNN)是预测中最常用的神经网络类型[15-17],此外还有许多模型将自周期方法与人工神经网络相结合来提高预测的精度。混合算法是将一些其他算法与基于机器学习的算法结合起来的智能算法,通常是对数据提前做处理,然后再对处理后的数据进行预测,例如将周期性检测技术与遗传反向传播算法训练的神经网络相结合等。但是现有的资源负载预测模型通常只考虑了负载时间序列的长时序依赖性,对于时间序列中存在的空间特性和短时序依赖性并未很好地利用,导致这些方法在长期资源负载预测中,准确率相对较低。
根据前期研究的积累发现,在现有的深度学习模型中,卷积神经网络(Convolutional Neural Network, CNN)和长短期记忆(Long-Short Term Memory, LSTM)网络都可以用于时间序列预测,且CNN和LSTM在短期预测方面的准确率相近,但是对于多步时序预测,LSTM的拟合度(R-squared,R2)下降趋势相较于CNN要平缓一些,在时间序列分析领域,CNN有利于提取时间序列的短时序依赖特性,而LSTM在提取时间序列的长时序依赖特性方面具有优势。
基于上述分析,本文提出了一种基于长-短时序特征融合的组合模型预测方法,分别提取时间序列的短时序依赖信息和长时序依赖信息,以及空间特征,然后通过双通道融合技术对所提取的特征进行相互补充,从而实现可靠的资源负载预测。
本文的主要工作如下:
1)提出了一种基于CNN和LSTM的端到端的双通道资源负载预测模型,其中CNN用于提取时间序列的空间特征和短时序依赖特征,LSTM用于提取时间序列的长时间依赖特征,从而实现多角度的时间序列特征提取。
2)设计了一种多输入的深度学习模型,一个输入为时间序列,通过格拉姆角场(Gram Angle Field, GAF)变为具有三通道的彩色图像,从而可以更好地利用机器视觉中的神经网络;一个输入为时间序列,通过LSTM来提取时间特征,并且设计了双通道来对时间序列短时序依赖和长时序依赖特征进行提取和相互补充,从而实现高质量的长期时序预测。
1 相关工作
1.1 CNN模型
卷积神经网络(CNN)通过固定尺寸的卷积核在图像上进行卷积计算,并且通过前向反馈来提取图像的特征[18],由于其具有强大的网格数据处理能力,已经被广泛地应用于计算机视觉领域来提取图像的特征。CNN的结构主要包括输入层、卷积层、池化层、全连接层和输出层这五部分,其中卷积层和池化层将输入层的信息进行特征转换和特征提取,全连接层将从卷积层和池化层得到的局部信息连接起来,输出层将从全连接层得到的信息映射为输出信号,并输出。典型的CNN结构如图1所示。
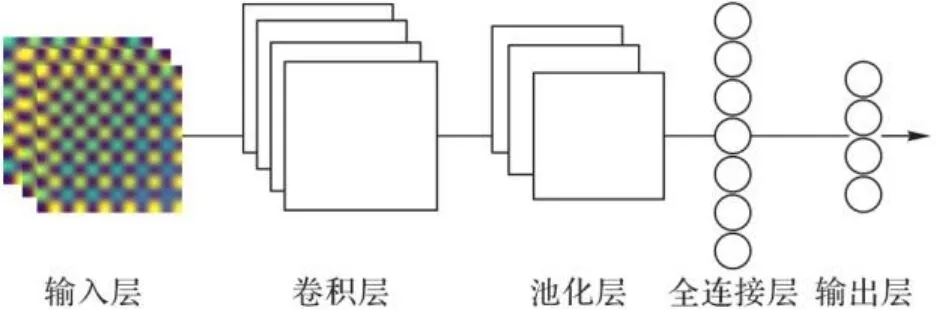
图1 CNN结构Fig. 1 Structure of CNN
在CNN结构中,最重要且独特的是卷积层,因为该层是通过卷积核来提取输入变量的特征,实现输入信息的特征映射,卷积层值需要连接上一层的部分神经元即可,而卷积核的尺度要小于输入层输入信息的尺度。在特征映射过程中,各个元素的计算式如式(1)所示:
1.2 LSTM模型
长短期记忆(LSTM)网络是一种循环神经网络(Recurrent Neural Network, RNN),主要被用于学习时间序列中隐藏的、不容易被发现的规律。RNN在隐藏层中具有反馈循环机制,从而来存储时间序列中之前的信息,输入的是一个包含特定时刻和过去时刻的特征。因此,它可以将上下文信息关联起来,在许多领域都有较好的表现;但是随着网络层数和迭代次数的增多,它的局限性也愈发明显,在输入的特征过长时,会存在长期依赖性,而RNN的后续节点会逐渐忘记之前的信息,并且会导致梯度递减和梯度爆炸等问题。为了解决RNN的弊端,LSTM[19]被提出,LSTM和RNN的不同之处在于,RNN中所有的隐藏层都连接了上一个隐藏层的所有神经元,如图2所示;而LSTM在隐藏层中使用了三个门控单元,分别是输入门、输出门和遗忘门,用来更新或丢弃历史信息,其网络结构如图3所示。图3中,表示各个门,“”表示对信息进行过滤运算,“”表示对信息进行叠加运算。

图2 RNN的时间展开Fig. 2 Time expansion of RNN
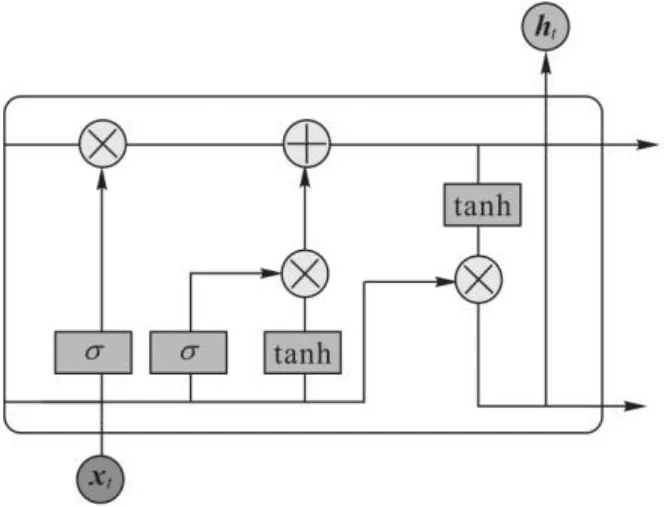
图3 LSTM结构Fig. 3 Structure of LSTM
对于遗忘门,通过sigmoid函数来控制信息的过滤,如式(2):
对于输入门,则是将输入的信息选择性地进行过滤,如式(3):
同时,在时间步t,原输入应为,根据RNN的前向传播,输入在经过线性变换之后还需要使用激活函数进行激活,如式(4):
对于输出门,按照式(6)~(7)得到门概率分布,对输入到下一个时间步的信息进行过滤。
2 基于长-短时序特征融合的预测模型
本章主要介绍所提出的基于CNN和LSTM的长-短时序特征融合的双通道多输入预测模型。
2.1 总体架构
针对现有时间序列预测模型中存在的不足,以及CNN在时间序列短时序特征提取方面的优势和LSTM在时间序列长时序特征提取方面的优势,本文提出了一种基于长-短时序特征融合的双通道多输入组合预测模型GAF-CNN-LSTM,其网络结构如图4所示。
由图4可以看出,两个通道都用来提取各自通道输入的数据样本的特征,不同的是ConvLSTM模型通道主要用来提取时间序列的短时序依赖特征,而LSTM模型通道主要用来提取时间序列的长时序依赖特征,从而得到两个输入样本的短时序依赖特征张量和长时序依赖特征张量。为了能够使两个通道所提取的特征对最终预测结果的影响达到平衡,需要设置两个张量和的维度相同,都为,将这两个张量拼接为一个维度为2n的张量P,最后将张量P输入到全连接神经网络层,进行张量的维度变换,从而得到最终的预测结果。

图4 GAF-CNN-LSTM模型结构Fig. 4 Structure of GAF-CNN-LSTM model
2.2 ConvLSTM通道
为了能够提取时间序列的短时序依赖特征,基于现有的研究,本文提出用基于CNN的卷积LSTM模型ConvLSTM来对时间序列样本进行短时序依赖特性提取。
在ConvLSTM模型中,主要通过卷积层来提取时间序列样本的特征,而卷积层更多地用于三通道图像等规则数据的特征提取。为了能够更好地利用卷积层提取短时序特征的特性,本文将短期时间序列通过格拉姆角场(GAF)转变为三通道的彩色图像,从而构成一个静态时序图。
GAF是由Wang等[20]提出的一种将时间序列转变为图像的技术。时间序列转换为图像的过程主要包括三部分:首先将输入的时间序列数据归一化到;然后将规范化之后的时间序列信号从笛卡儿坐标转换为极坐标,并且保留输入信号的时间信息;最后,通过三角余弦函数将极坐标中的每个时间点与其他时间点进行时间相关性比较,从而得到一个的格拉姆矩阵,其中n为一个时间序列中采样点的个数。
通过角度和半径来表示时间序列的值和其对应的时间戳,其中用式(9)计算角度:
然后,通过ConvLSTM通道提取该通道数据样本的时空信息,其中,局部邻域和过去状态的输入决定了网格单元的未来状态,状态之间的转换由卷积算子实现,具体的网络结构如图5所示。
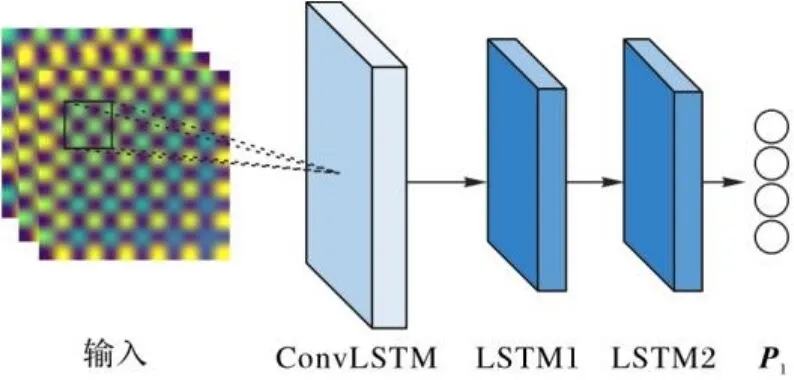
图5 ConvLSTM通道模型结构Fig. 5 Structure of ConvlSTM channel model
ConvLSTM网络层主要是通过卷积运算来对时序中的权值进行计算,从而将图像的空间特征提取出来,并且通过将上一层的输出当作下一层的输入,从而提取静态时序图的短时序特征,其主要计算式如下:
在输入的样本中,存在样本数据分布不均匀的现象,为了缓解样本不均对模型准确性的影响,使用BatchNormalization层来对数据进行归一化,同时也可以防止网络过拟合。
通过两个LSTM层来进一步提取时间序列中的时序特征,最后通过全连接层(Fully Connected layer, FC)输出ConvLSTM通道得到的维度为n的张量P1()。
2.3 LSTM通道
根据前期实验结果发现,LSTM在获取时间序列的长时序依赖特性方面有很大的优势,为了提取时间序列样本的长时序依赖特性,本文在长时序依赖特性提取通道中使用LSTM模型来获取特征向量。本文所设计的LSTM通道的结构由两层LSTM组成,最后通过全连接层FC得到张量P2()。
随着信息化建设进程加速,网络技术行业应用范围迅速扩展,涉及知识更新迅速。导致高校出现师资技术水平跟不上行业发展速度、教学资源更新难度大等问题。当新技术出现,往往高校教师很难获取第一手学习资料,也很难获取行业岗位经验。也为高校教师教学和指导学生带来较大难度。于是出现学生所学知识无法与市场人才需求无缝接轨,如何将企业一线技术引入到教学中成为高职计算机网络专业改革的一个难点和痛点。
2.4 向量融合
为了将时间序列的长时序依赖特性和短时序依赖特性融合起来,同时为了能够使长时序依赖特性和短时序依赖特性的权重相同,本文通过张量拼接的形式将两个通道分别提取的时间序列样本的长、短时序依赖特性进行融合,并且通过全连接层FC对融合后的张量进行转换,得到所需要的输出形式。拼接后的张量可表示为式(17),FC层的张量转换可表示为式(18):
3 实验与结果分析
3.1 数据集
本文实验所使用的数据集是阿里云2018年发布的最新大数据平台集群跟踪数据集cluster-trace-v2018,该数据集中包含了4 000多台机器、每台机器8天内的资源使用情况,其中资源包括CPU、内存以及网络输出量和网络输入量等多个值,由6个表组成,采样的时间间隔为10 s。数据集中共有69 121个时间点的数据,将6个连续的时间序列划分为1个时间间隔,即1 min为1个时间间隔,选取最后的2 000个时间间隔为测试集来评判算法的有效性,其余的时间间隔用来训练网络。本文主要研究数据中心CPU的资源负载预测模型,为了使得模型预测结果更准确,本文选取了CPU和内存两个资源值作为每台机器每个时刻的特征值,通过CPU和内存来预测未来6个时刻的机器CPU负载值。
3.2 模型数据集构建
在构建时间序列预测模型的输入时,通常采用滑动窗口将数据样本进行切分,构成固定长度的时间序列,本文针对所构建的多输入组合预测模型,将数据样本分别由不同的方法进行样本构建,从而达到多输入的目的。
对于ConvLSTM通道,其输入应为图片,所以本文首先利用GAF将一个时间间隔长度的时间序列转变为三通道的彩色图片,再将一个数据样本中所需的时间序列图片拼接起来,构成一个静态时间序列图,如图6所示。
对于LSTM通道,本文采用滑动窗口构建时间序列样本,步长为60 s。
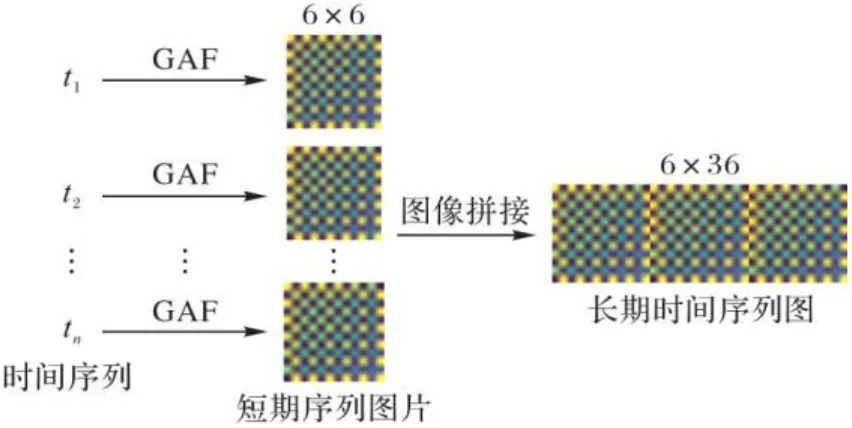
图6 ConvLSTM通道数据样本构建Fig. 6 Sample construction of ConvLSTM channel data
3.3 评价指标
本文在对模型进行评价时,主要采用了三个评价指标:均方根误差(Root Mean Square Error, RMSE)、平均绝对误差(Mean Absolute Error, MAE)和拟合度(R2),这三个指标都是在深度学习的回归问题中常用的指标。
均方根误差是将真实值与预测值做差然后平方之后求和,主要用来衡量观测者和真实值之间的偏差,其RMSE的计算式如式(19),其值越小,说明模型的准确度越高。
平均绝对误差是所有预测值与真实值偏差的绝对值的平均,主要用来反映预测值误差的实际情况,其MAE的计算式如式(20):
其中:m为测试样本总量;为数据点的真实值;为数据点的预测值;为数据点的平均值。
3.4 实验配置
本文在实验中所设计的ConvLSTM通道和LSTM通道的配置分别如表1~2。然而,第一个输入通道即ConvLSTM通道中的LSTM隐藏层的维度为10,第二个输入通道即LSTM通道中两个LSTM隐藏层的维度分别为36和20,这两个通道中虽然都包含了LSTM网络层,但这些LSTM网络层是相互独立的。
表1 ConvLSTM通道配置
Tab. 1 ConvLSTM channel configuration

网络层参数ConvLSTM2D卷积核大小为64,卷积步长为(3,3)LSTM(两层)隐藏层为10FC(两层)输入维度为36,输出维度为6
3.5 消融实验
为了验证本文所设计的多输入双通道的组合预测模型的准确性,以及将时间序列转变为图片的有效性,本文主要将时间序列转变为图像后分别输入单通道和双通道模型进行对比,以及对双通道模型分别输入图片和时间序列进行对比,分别计算各个模型的均方根误差、平均绝对误差和拟合度,以其在6个时刻的平均值作为评价依据,结果如表3所示。
由表3中的数据对比可以看出,在所有的实验中,单通道预测的准确度整体低于双通道。为了验证对两个通道的输出张量和融合方式的有效性,本文在实验过程中采用了两种方式融合:一种是直接通过张量拼接的方式,其模型预测结果如表3中的ConvLSTM+LSTM模型结果;另一种是通过多层感知器(MLP)来对张量进行基于权重的融合,其模型预测结果如表3中的ConvLSTM+LSTM+MLP模型结果。由表3可知,在进行长-短时序特征融合时,张量直接拼接的模型准确性要优于基于权重融合的模型准确性。这是由于在进行张量融合时,使用MLP进行权重融合时会造成模型参数增多,而参数越多,对数据的质量要求就越高,因此对于同样的数据,直接进行张量拼接的效果要优于权重融合的效果。
表2 LSTM通道配置
Tab. 2 LSTM channel configuration

网络层参数LSTM1隐藏层为36LSTM2隐藏层为20FC输出维度为6
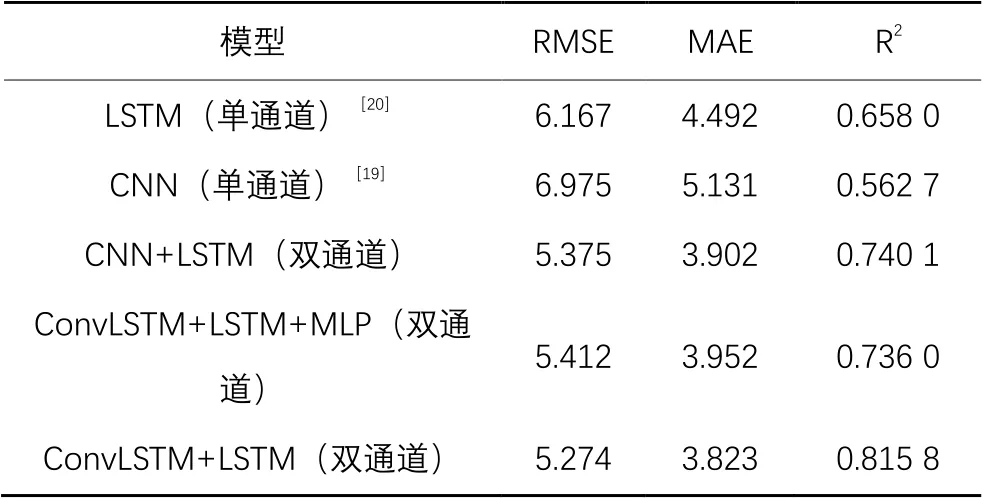
表3 单通道与双通道结果对比Tab. 3 Comparison of single-channel and dual-channel results
图7给出了双通道模型下,对于多步预测的预测值和实际值的对比,其中实际值为实际CPU负载值,预测值为双通道模型预测的CPU负载值,表示预测的第i个时刻的结果对比。通过图7可以看出,双通道下模型的预测结果较为准确。
图8给出了单通道下多步预测中,每一时刻CNN与LSTM的预测结果的R2对比。由图8可以看出,CNN不适合做多步预测,其准确度下降趋势大于LSTM的下降趋势。而在双通道中,可以将这两个模型进行优势互补,当某个通道模型的预测结果出现较大偏差时,双通道可以考虑另外一个所预测的结果,或者对两个结果进行结合,从而提高整体时间序列预测结果的准确性。
图9给出了当两个通道输入都为时间序列(time_time)和两个通道中LSTM输入时间序列、ConvLSTM输入为图像(image_time)时预测结果的R2对比。通过图9可以看出,两个通道输入都为时间序列的模型准确度低于两通道输入分别为时间序列和图像的模型准确度,将时间序列转变为图像可以进一步提高大数据中心资源负载预测的准确性。
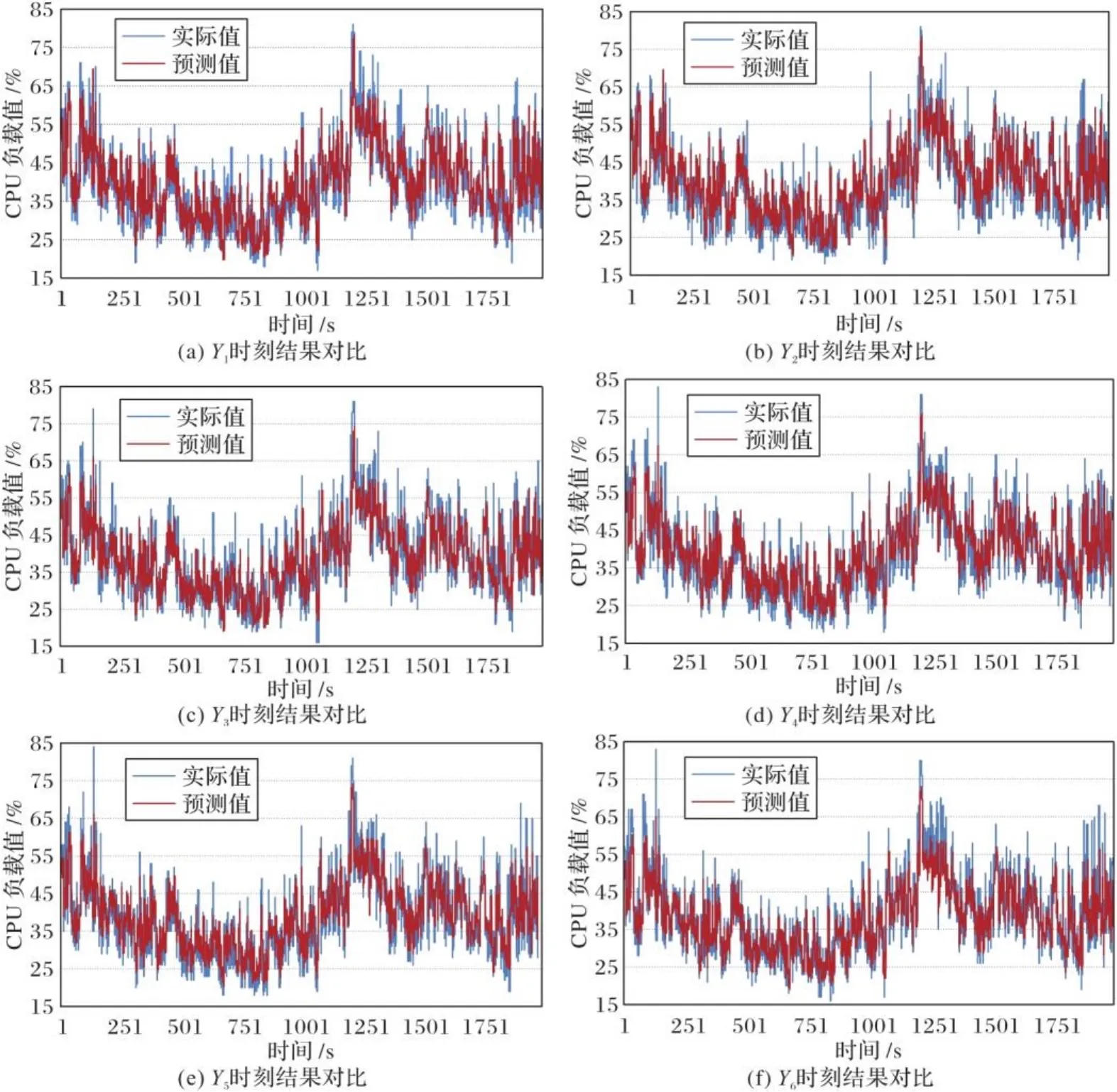
图7 双通道模型预测值与实际值对比Fig. 7 Comparison between predicted values of dual-channel model and actual values
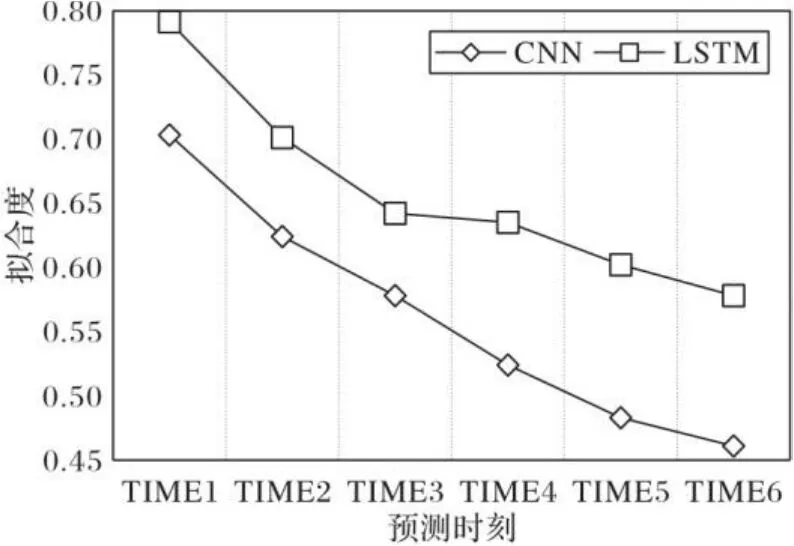
图8 CNN与LSTM的R2对比Fig. 8 Coparison of R2 between CNN and LSTM
3.6 基准算法对比实验
同时将本文方法与LSTM-ED(LSTM Encoder-Decoder)组合模型[21]和传统的线性回归方法XGBoost[22]进行了对比实验。LSTM-ED是一种基于长短期记忆编解码器的预测方法,通过建立时间序列的数据内部表示来提高LSTM的存储能力。该模型主要由两个主要组件组成:一个编码器和一个解码器,前者构建一个表示,该表示封装了来自时间序列数据的信息,后者将构建的表示“解码”为输出。在本文中,将数据集划分为等长的时间序列,然后输入到LSTM-ED模型进行长期资源负载预测。XGBoost是大规模并行boosted tree的工具,Boosting方法通过将成百上千个分类准确率较低的树模型组合起来,构建为一个准确率很高的预测模型。这个模型会不断地迭代,每次迭代生成一棵新的树,该模型已经在大量机器学习和数据挖掘挑战中被广泛地认可。
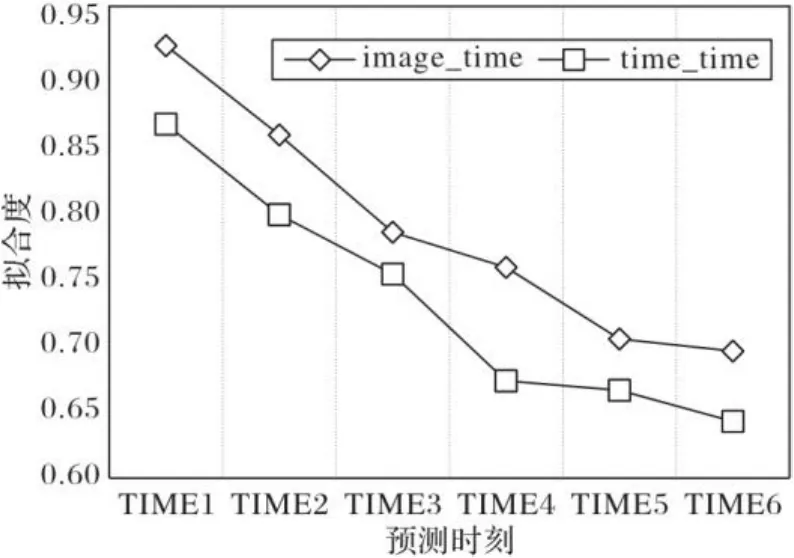
图9 不同输入的R2对比Fig. 9 Comparison of R2 with different inputs
实验对比结果如表4所示,由表4可以看出本文所提模型在长期资源负载预测中优于LSTM-ED模型,其主要原因是LSTM-ED通过编码器和解码器来实现时间序列预测,该方法可以提高LSTM的存储能力,也就是可以更好地提取时间序列的长时序依赖特性,但是对于时间序列的短时序依赖特性以及空间特性仍然没有提取,而本文所提方法通过ConvLSTM模型很好地将时间序列的短时序特性以及其空间特性提取出来,同时使用双通道模型将所提取的短时序特性和长时序特性进行融合,从而得到更为有效的长期资源负载预测模型;而且与XGBoost相比,本文提出的模型整体预测性能也优于XGBoost模型。
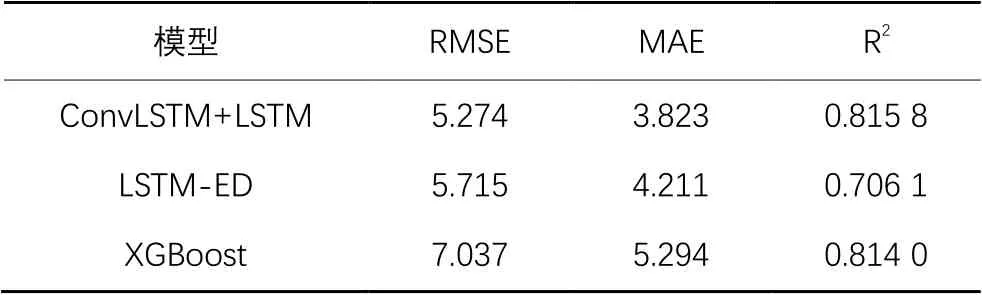
表4 本文模型与基准模型性能对比Tab. 4 Performance comparison of proposed model and benchmark models
3.7 模型性能
为了评估本文模型的性能,对GAF-CNN-LSTM模型和LSTM-ED模型在训练过程中损失函数值的下降趋势进行对比,其结果如图10所示。
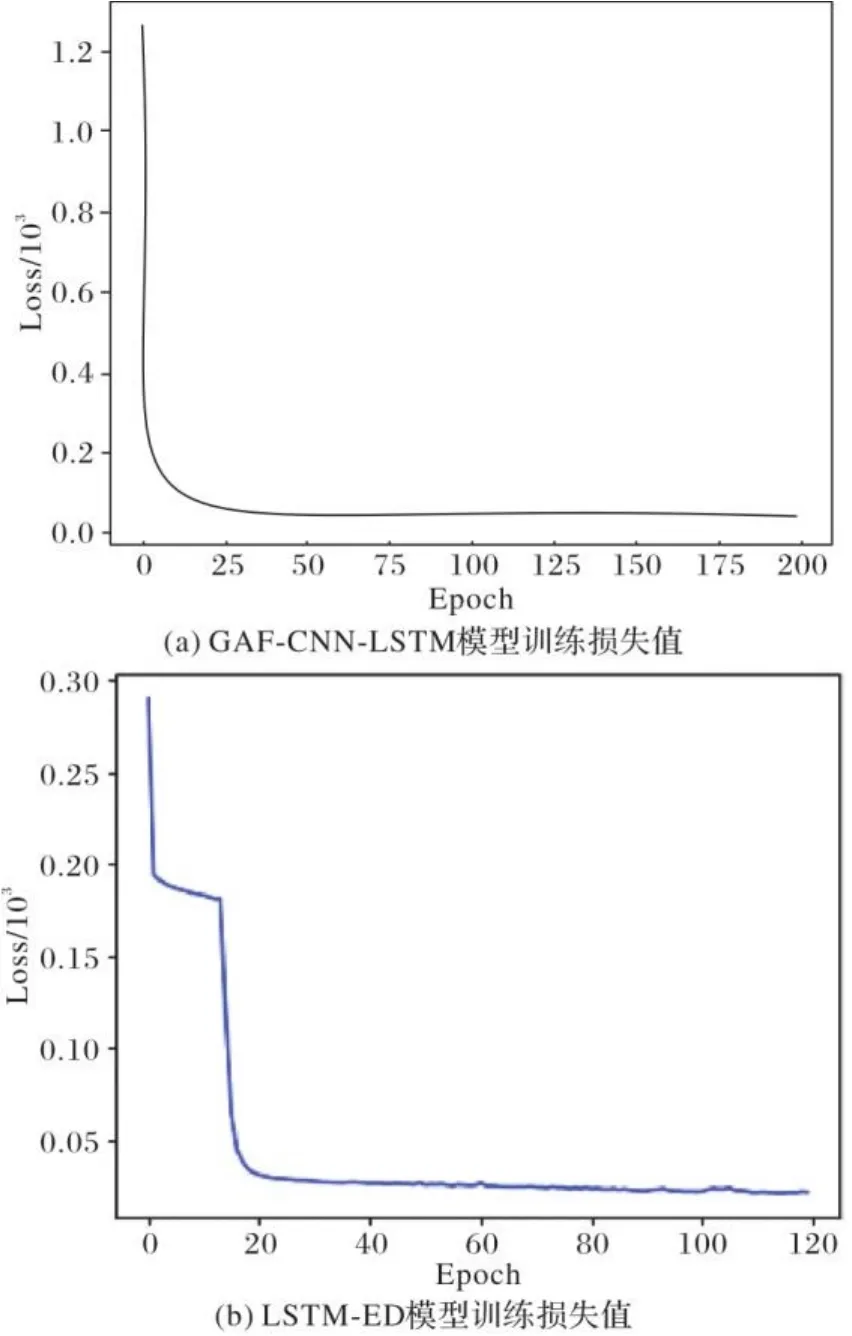
图10 不同模型训练损失函数对比Fig. 10 Comparison of training loss functions of different models
通过图10可以看出,在训练过程中,GAF-CNN-LSTM模型的损失函数在大约训练20次之后已经达到收敛,并一直处于稳定状态,而LSTM-ED模型的损失函数在训练40次后趋于稳定,且在下降过程中并没有平稳下降,能够得出本文所提模型相较于LSTM-ED模型在训练过程中更稳定,但由于本文所提模型网络结构更加复杂,所以在模型训练时间上效率相较于LSTM-ED和基本线性回归模型XGBoost略低。
4 结语
本文提出了一种基于多输入的双通道时间序列预测模型GAF-CNN-LSTM,利用全连接层对双通道中每一通道所提取的特征进行优势互补,具体来说就是利用ConvLSTM提取深层空间特征,利用LSTM提取时间序列的时序依赖特征,然后通过全连接层将两个通道所提取的特征相结合得到最终预测结果。此外,为了更好地利用卷积神经网络,本文将时间序列通过GAF转变为图像,使其可以更好地提取空间特征。通过将所提模型在真实数据集上的预测结果与实际数据相对比,表明本文所提出的多输入双通道模型能够有效地提取时间序列数据的长-短时序特征和空间特征,对资源负载的预测精确度优于当前基准算法。
[1] SUN X, ANSARI N, WANG R. Optimizing resource utilization of a data center [J]. IEEE Communications Surveys amp; Tutorials, 2016, 18(4): 2822-2846.
[2] PREVOST J, NAGOTHU K, KELLEY B, et al. Prediction of cloud data center networks loads using stochastic and neural models [C]// Proceedings of the 2011 6th International Conference on System of Systems Engineering. Piscataway: IEEE, 2011:276-281.
[3] ZHANG Q, ZHANI M F, BOUTABA R, et al. HARMONY: dynamic heterogeneity-aware resource provisioning in the cloud [C]// Proceedings of the 2013 33rd International Conference on Distributed Computing Systems. Piscataway: IEEE, 2013:510-519.
[4] KUMAR T L M, SURENDRA H S, MUNIRAJAPPA R. Holt-winters exponential smoothing and sesonal ARIMA time-series technique for forecasting of onion price in Bangalore market [J]. Mysore Journal of Agricultural Sciences, 2011, 2(1): 602-607.
[5] LI Q, HAO Q F, XIAO L M, et al. An Integrated approach to automatic management of virtualized resources in cloud environments [J]. Computer Journal, 2011, 54(6): 905-919.
[6] SUN Y S, CHEN Y F, CHEN M C. A workload analysis of live event broadcast service in cloud [J]. Procedia Computer Science, 2013, 19(1): 1028-1033.
[7] VERCAUTEREN T, AGGARWAL P, WANG X, et al. Hierarchical forecasting of web server workload using sequential Monte Carlo training [J]. IEEE Transactions on Signal Processing, 2007, 55(4): 1286-1297.
[8] ARDAGNA D, CASOLARI S, COLAJANNI M, et al. Dual time-scale distributed capacity allocation and load redirect algorithms for cloud systems [J]. Journal of Parallel and Distributed Computing, 2012, 72(6): 796-808.
[9] ROY N, DUBEY A, GOKHALE A. Efficient autoscaling in the cloud using predictive models for workload forecasting [C]// Proceedings of the 2011 International Conference on Cloud Computing. Piscataway: IEEE,2011: 500-507.
[10] RAJARAM K, MALARVIZHI M P. Utilization based prediction model for resource provisioning [C]// Proceedings of the 2017 International Conference on Computer. Piscataway: IEEE, 2017:1-6.
[11] KATTEPUR A, NAMBIAR M. Service demand modeling and performance prediction with single-user tests [J]. Performance Evaluation, 2017, 110(4): 1-21.
[12] CAO L. Support vector machines experts for time series forecasting [J]. Neurocomputing, 2003, 51(4): 321-339.
[13] EDDAHECH A, CHTOUROUS S, CHTOUROU M. Hierarchical neural networks based prediction and control of dynamic reconfiguration for multilevel embedded systems [J]. Journal of Systems Architecture, 2013, 59(1): 48-59.
[14] DANG T, TRAN N, NGUYEN B M, et al. PD-GABP: A novel prediction model applying for elastic applications in distributed environment [C]// Proceedings of the 2016 3rd National Foundation for Science and Technology Development Conference on Information and Computer Science. Piscataway: IEEE, 2016:240-248.
[15] ZHANG G, PATUWO B E, HU M Y. Forecasting with artificial neural networks: the state of the art [J]. International Journal of Forecasting, 1998, 14(1): 35-62.
[16] VENKATESAN. A genetic algorithm based artificial neural network model for the optimization of machining processes [J]. Neural Computing and Applications, 2009, 2(1): 135-140.
[17] VAZQUEZ C. Time series forecasting of cloud data center workloads for dynamic resource provisioning [D]. San Antonio: The University of Texas at San Antonio, 2015: 10-15.
[18] REN S, HE K, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017,39(6): 1137-1149.
[19] 胡荣磊,芮璐,齐筱,等.基于循环神经网络和注意力模型的文本情感分析[J].计算机应用研究,2019,36(11):3282-3285.(HU R L, RUI L, QI X, et al. A novel approach to contextual sentiment analysis based on a neural network and attention model [J]. Application Research of Computer, 2019, 36(11): 3282-3285.)
[20] WANG Z, OATES T. Imaging time-series to improve classification and imputation [C]// Proceedings of the 2015 24th International Conference on Artificial Intelligence. Menlo Park: AAAI Press, 2015: 3939-3945.
[21] NGUYEN H M, KALRA G, KIM D. Host load prediction in cloud computing using long short-term memory encoder-decoder [J]. Journal of supercomputing, 2019, 75(11): 7592-7605.
[22] CHEN T, GUESTRIN C. XGBoost: a scalable tree boosting system [EB/OL]. [2016-06-09]. https://arxiv.org/pdf/1603. 02754.pdf.
Resource load prediction model based on long-short time series feature fusion
WANG Yifei1, YU Lei2,3, TENG Fei1*, SONG Jiayu1, YUAN Yue1
(1.School of Information Sciences and Technology,Southwest Jiaotong University,Chengdu Sichuan610000,China;2.Sino‑french Engineer School,Beihang University,Beijing100000,China;3.Beihang Hangzhou Institute for Innovation at Yuhang,Hangzhou Zhejiang310000,China)
Resource load prediction with high accuracy can provide a basis for real-time task scheduling, thus reducing energy consumption. However,most prediction models for time series of resource load make short-term or long-term prediction by extracting the long-time series dependence characteristics of time series and neglecting the short-time series dependence characteristics of time series. In order to make a better long-term prediction of resource load, a new edge computing resource load prediction model based on long-short time series feature fusion was proposed. Firstly, the Gram Angle Field (GAF) was used to transform time series into image format data, so as to extract features by Convolutional Neural Network (CNN). Then, the CNN was used to extract spatial features and short-term data features, the Long Short-Term Memory (LSTM) network was used to extract the long-term time series dependent features of time series. Finally, the extracted long-term and short-term time series dependent features were fused through dual-channel to realize long-term resource load prediction. Experimental results show that, the Mean Absolute Error (MAE), Root Mean Square Error (RMSE) and R-squared(R2) of the proposed model for CPU resource load prediction in Alibaba cloud clustering tracking dataset are 3.823, 5.274, and 0.815 8 respectively. Compared with the single-channel CNN and LSTM models, dual-channel CNN+LSTM and ConvLSTM+LSTM models, and resource load prediction models such as LSTM Encoder-Decoder (LSTM-ED)and XGBoost, the proposed model can provide higher prediction accuracy.
resource load prediction; Convolution Neural Network (CNN); Long Short-Term Memory (LSTM) network; Gram Angle Field (GAF); dual-channel; time series prediction
TP391
A
1001-9081(2022)05-1508-08
10.11772/j.issn.1001-9081.2021030393
2021⁃03⁃16;
2021⁃06⁃08;
2021⁃06⁃11。
四川省科技项目(2019YJ0214) ;北京市自然科学基金资助项目(4192030)。
王艺霏(1996—),女,山西吕梁人,硕士研究生,主要研究方向:云计算、大数据挖掘; 于雷(1972—),男,山东淄博人,副教授,博士,主要研究方向:大数据计算中心能耗优化与仿真、基于深度学习的图像处理、自然语言处理与分类; 滕飞(1984—),女,山东淄博人,副教授,博士,CCF会员,主要研究方向:云计算、医疗信息、工业大数据挖掘; 宋佳玉(1995—),女,四川成都人,硕士研究生,主要研究方向:大数据挖掘、时间序列预测; 袁玥(1997—),女,四川泸州人,硕士研究生,主要研究方向:大数据挖掘、深度学习。
This work is partially supported by Science and Technology Project of Sichuan Province (2019YJ0214), Natural Science Foundation of Beijing (4192030).
WANG Yifei, born in 1996, M. S. candidate. Her research interests include cloud computing, big data mining.
YU Lei, born in 1972, Ph. D., associate professor. His research interests include energy consumption optimization and simulation of big data computing center, image processing based on deep learning, natural language processing and classification.
TENG Fei, born in 1984, Ph. D., associate professor. Her research interests include cloud computing, medical informatics, industrial big data mining.
SONG Jiayu, born in 1995, M. S. candidate. Her research interests include big data mining, time series prediction.
YUAN Yue, born in 1997, M. S. candidate. Her research interests include big data mining, deep learning.
猜你喜欢
导航定位学报(2022年5期)2022-10-13
农业工程学报(2022年12期)2022-09-09
计算机仿真(2022年7期)2022-08-22
计算技术与自动化(2022年1期)2022-04-15
小猕猴智力画刊(2022年3期)2022-03-28
农业工程学报(2022年1期)2022-03-25
意林·作文素材(2021年23期)2021-01-22
上海师范大学学报·自然科学版(2019年5期)2019-12-13
电脑爱好者(2015年22期)2015-09-10
分析化学(2015年8期)2015-08-13
