
基于代码图像合成的Android恶意软件家族分类方法
2022-06-21 06:54李默芦天亮谢子恒
计算机应用 2022年5期
李默,芦天亮,谢子恒
(中国人民公安大学 信息网络安全学院,北京 100038)(∗通信作者电子邮箱lutianliang@ppsuc.edu.cn)
基于代码图像合成的Android恶意软件家族分类方法
李默,芦天亮*,谢子恒
(中国人民公安大学 信息网络安全学院,北京 100038)(∗通信作者电子邮箱lutianliang@ppsuc.edu.cn)
代码图像化技术被提出后在Android恶意软件研究领域迅速普及。针对使用单个DEX文件转换而成的代码图像表征能力不足的问题,提出了一种基于代码图像合成的Android恶意软件家族分类方法。首先,将安装包中的DEX、XML与反编译生成的JAR文件进行灰度图像化处理,并使用Bilinear插值算法来放缩处理不同尺寸的灰度图像,然后将三张灰度图合成为一张三维RGB图像用于训练与分类。在分类模型上,将软阈值去噪模块与基于Split-Attention的ResNeSt相结合提出了STResNeSt。该模型具备较强的抗噪能力,更能关注代码图像的重要特征。针对训练过程中的数据长尾分布问题,在数据增强的基础上引入了类别平衡损失函数(CB Loss),从而为样本不平衡造成的过拟合现象提供了解决方案。在Drebin数据集上,合成代码图像的准确率领先DEX灰度图像2.93个百分点,STResNeSt与残差神经网络(ResNet)相比准确率提升了1.1个百分点,且数据增强结合CB Loss的方案将F1值最高提升了2.4个百分点。实验结果表明,所提方法的平均分类准确率达到了98.97%,能有效分类Android恶意软件家族。
Android恶意软件家族;代码图像;迁移学习;卷积神经网络;通道注意力
0 引言
Android系统自出现以来凭借其开源性受到越来越多的用户与开发者的欢迎,所占市场份额逐年增长;但开放性的特点使它一度成为97%恶意软件攻击的首选目标[1]。在恶意软件数量不断增长的过程中,代码混淆、软件加壳等技术的应用也让恶意软件的抗检测能力不断增强,其越来越快的更新与迭代更是让安全厂商们应接不暇。为应对以上威胁,针对恶意软件家族的分类与检测技术逐渐成为主流。将不同的恶意样本根据行为划分至相应家族,对恶意家族中典型样本进行分析,可以极大减少工作量;研究恶意家族相关迭代版本也有助于研究人员发现恶意软件攻击规律,以增强安全软件的查杀能力。
近年来,卷积神经网络(Convolutional Neural Network, CNN)快速发展,并在图像识别和目标检测领域广泛应用。He等[2]提出了著名的残差网络,有效抑制了深层网络的梯度消失。之后,Hu等[3]又提出了通道注意力机制,对通道间的相互依赖关系进行了建模,近期的研究[4-6]已证实通道注意力在改善深度CNN中存在巨大的潜力。随着CNN结构越来越复杂、参数量越来越庞大,对算力也提出了更为苛刻的要求,而迁移学习的应用在很大程度上缓解了此问题。在大规模数据集上预训练好的模型已经习得了大量的泛化特征,将这部分特征参数迁移到新模型中不仅节省了训练时间,也提升了模型的最终训练效果。
代码图像广泛应用前,恶意代码静态分析方法需研究人员手工提取特征[7-10],费时费力,而CNN的普及则为代码图像化技术的发展提供了契机。代码图像化指将代码以二进制形式转换为像素点并构成图像,利用CNN自动学习图像深层抽象特征的能力,既可免去手工提取特征,在保持高识别率的同时也极大简化了检测流程。
在Android恶意代码图像化识别领域,目前主流的方法[11-14]均将安装包中的DEX(Classes.dex)文件转换为灰度图或RGB(Red-Green-Blue)格式彩图,但以上方法的缺点在于单个DEX文件所提供的信息量有限,不足以概括恶意软件的行为特征。除此之外,Android恶意代码图像化识别面临的挑战还包括以下三点:1)代码图像尺寸处理过程中容易丢失特征信息;2)代码图像不同于生活图像,存在其独特纹理且含有明显的噪声特征,对代码图像识别与分类需要特定的网络模型;3)代码图像数据集中普遍存在长尾分布现象,多数样本集中在前几类家族中,样本较少的家族难以得到较好的分类效果。
针对以上问题,本文提出了一种基于代码图像合成的Android恶意软件家族分类方法,方法流程如图1所示。本文方法的主要工作如下:
1)为解决DEX代码图像特征不足的问题,将DEX、XML(AndroidManifest.xml)与JAR(Classes.jar)文件合成为三维RGB图作为特征图像,合成的代码图像融合了多类特征信息,可从更多维分析恶意软件。
2)使用插值放缩法处理不同比例大小的图像,相较于截取填充法,插值放缩能够在不损失图像信息的情况下更大程度保留图像特征。在此基础上,针对不同插值算法在代码图像上的表现进行了对比与分析,最终使用Bilinear算法进行代码图像的放缩处理。
3)分类模型上将软阈值去噪模块(Soft Thresholding Block, ST Block)[15]与基于Split-Attention的ResNeSt[6]相结合,提出了STResNeSt(ST Block+ResNeSt),并使用在ImageNet上训练好的模型参数进行迁移训练。ST Block增强了模型的抗噪能力,与Split-Attention共同作用,有效增强了模型在代码图像上的特征提取能力。
4)使用了图像增强方案对Drebin数据集进行扩增,同时在模型训练过程中引入类别平衡损失函数(Class-Balanced Loss, CB-Loss)[16]。CB Loss能够根据不同家族的有效样本数在训练中为每个家族赋予相应的权重,是处理数据不平衡问题的有效方案。

图1 恶意软件分类流程Fig. 1 Flow chart of malware classification
1 相关工作
在代码图像化广泛应用之前,对恶意软件的静态分析通常需要研究人员手工提取特征。Santos等[7]提取操作码序列作为特征,并统计每个序列出现的频率,最后在支持向量机构造的分类器上实现了95.90%的准确率。Wang等[8]从APK(Android Application Package)的应用配置文件XML中提取出权限信息,对不同权限进行风险排序,并分析了多个权限组合引发的风险,最后使用支持向量机、决策树与随机森林根据权限集合对恶意软件进行分析。此外,Grini等[9]使用软计算方法,结合多类机器学习模型对500个家族的近10亿个样本进行分类,最终取得了89%的准确率。相较于以上方法,Qiu等[10]针对零日家族的识别使用了更为丰富的特征,提取出了API(Application Programming Interface)、权限以及网络地址等敏感信息对恶意软件进行分析。
Nataraj等[17]首次提出了代码图像化的概念,原理是将恶意代码以二进制形式转换为灰度图像,代码文件的每1个字节恰好对应灰度图像中一个0~255的像素值,之后采用GiST(Generalized Search Tree)算法对灰度图像进行纹理特征提取,并输入支持向量机进行分类。使用图像化处理恶意代码不仅保持了高准确率,同时极大减少了手工提取和筛选各类特征的开销,所以该方法一经提出便引起了轰动,随后代码图像化也应用到了Android恶意软件检测上。除了GiST算法,张晨斌等[11]还对DEX文件图像使用了包括Tamura在内的3种特征提取算法,通过4种算法提取出的纹理特征集合,最后构造了5种分类模型对恶意代码进行检测与分类。
文献[11]研究的问题在于,在图像训练前仍需提取图像的纹理特征,卷积神经网络的应用则极大改善了这一问题。文献[18]中将恶意代码文件二进制转换为灰度图后输入卷积神经网络中进行训练,卷积神经网络能够自动学习恶意软件的抽象特征,利用网络的自动表征能力,代码图像可直接输入网络进行训练。
文献[19]中使用Windows恶意代码文件的二进制数据、ASCII(American Standard Code for Information Interchange)字符和文件结构信息构建代码图像,输入带有SPP(Spatial Pyramid Pooling)结构的网络中进行训练。使用SPP结构的网络虽然解除了对输入图像大小的限制,但是该方法的局限在于图像尺寸的不统一,导致训练模型批尺寸只能设为1,这将导致训练时长成倍增长。
文献[12-13]中都将DEX文件映射为三通道的RGB彩色图像,与传统的单通道灰度图相比,该方法中使用的三通道RGB图像理论提供了3倍的信息量,能够充分发挥神经网络多通道的卷积运算优势,分类效果优于灰度图;但该方法只是将灰度图像进行简单的三维折叠,并没有考虑到通道间的关联关系,且单个DEX文件所能提供的信息量有限,并不足以概括恶意代码的行为特征。
2 代码图像合成
2.1 特征文件提取
特征提取部分选择了APK中的DEX、XML和反编译生成的JAR文件作为特征文件用于合成三维RGB代码图像。
在APK文件的内部结构中,XML与DEX是在Android恶意软件分析中最重要的两个文件。XML文件存放了软件包名、权限声明以及各个组件的注册信息,是用来整体描述Android应用的配置文件。DEX文件是存放Dalvik字节码的文件,能在Dalvik虚拟机中运行,此文件由构成各Java类的源码编译而成,本质上是所有应用程序的逻辑,是程序中信息含量最高的一个文件。将DEX文件转换为代码图像也是目前Android恶意代码图像化分析中最常用的一种方法。
DEX文件包含了程序所有的Java代码,但这些代码都被编译成Dalvik字节码用于在Dalvik虚拟机上运行,其中一些结构信息在判断代码特征时属于冗余部分。将DEX文件反编译成JAR文件,并对文件中的连续可见字符(ASCII范围:32~126)进行提取。JAR文件中的可见字符包含了具体的代码信息,相较于原始JAR文件,能更准确地体现恶意代码特征。
2.2 图像比例与图像缩放
灰度图也称为灰阶图,将黑色与白色间的对数关系分成不同的等级,称之为灰度。RGB色彩标准则是目前应用最广泛的一种颜色标准,一张RGB彩色图片是由不同程度的红、绿、蓝颜色通过叠加构成,目前大部分卷积神经网络的三通道输入设计正是受到RGB标准的影响。灰度图的灰阶范围为0~255,恰好对应了二进制中8 bit的表示范围,也就是1 B。将特征文件以二进制方式读取,将每8 bit转换为一个灰度像素值,以此生成代码图像。而RGB图片中一个像素点的通道数为灰度图的3倍,可使用三张形状相同的灰度图叠加而成。
在将文件转换成图像的过程中,因卷积网络对输入图片的大小有固定限制,故不可避免地要考虑图像尺寸参数。以Drebin[20]中的BaseBridge家族为例,提取出DEX文件后,最大的DEX文件为5 839 KB,而最小的仅有5 KB,文件大小不同导致无法确定统一的图像尺寸,故需解决两个问题:图像转换比例与图像缩放。
2.2.1 图像转换比例
文献[11]中在处理图像比例问题时,尝试固定图像宽度,并将较小文件使用0填充至固定长度。在本文情况下,如将宽度固定为ResNeSt规定的224像素,两个大小分别为5 839 KB和5 KB的DEX文件转换成图片后长度分别为26 692像素和23像素,使用0填充后,后者的有效信息量仅为0.08%,所以当数据集内样本大小差距过大时该方法并不适用。
针对以上问题的解决方案之一是根据不同的文件大小设定不同的宽度转换标准。为使代码图像尺寸符合网络规定的1∶1长宽比,可直接对文件大小值进行开方,对开方结果向下取整求得宽度值:。
以上方法的问题在于,对每个文件设定完全不同的转换比例会导致转换出的代码图像结构各异,不利于同类大小文件的特征对比。因此,本文选择对同一大小区间的文件设定相同的宽度值,经过计算后本文使用了表1中的转换比例,计算方法如下。
首先根据Drebin数据集中样本大小的分布情况划分出不同大小区间,如表1中的第一列所示。为使一个区间内的图像更趋近于网络要求的长宽比,取区间内的中位数并对其进行开方。以1 MB(Megabytes)~2 MB为例,区间中位数为1.5 MB,即1 536 000 B,开方取整后得到1 239,之后取离1 239较近的1 280(常见分辨率尺寸值)作为1 MB~2 MB区间的图像宽度值。故此区间内的代码图像宽度固定为1 280像素,长度则根据文件大小不同略有差异,但图像总体比例与模型要求的比例趋近,避免了后续缩放过程中对图像造成的大规模结构性改变。
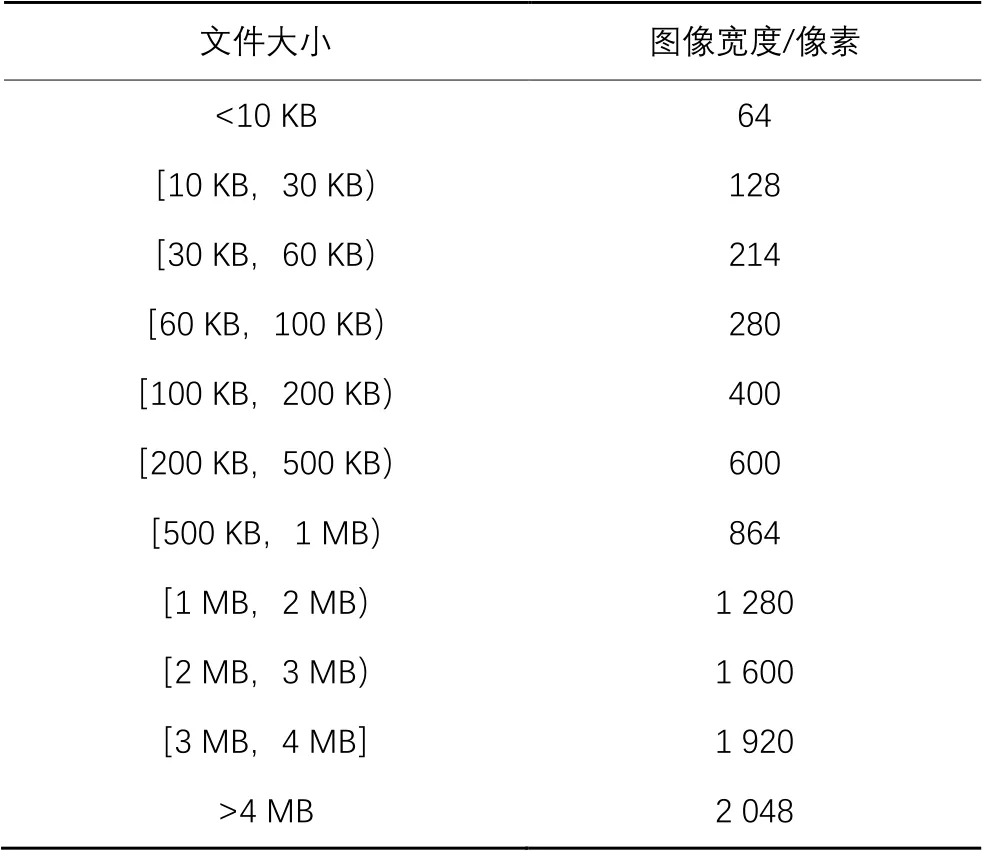
表1 代码图像转换比例Tab. 1 Ratio of code image conversation
2.2.2 图像缩放
根据表1的比例生成图像后,需要将图像插值缩放至模型网络规定的输入尺寸。常见的插值算法有Nearest、Bilinear、Bicubic和Lanczos与Box等。
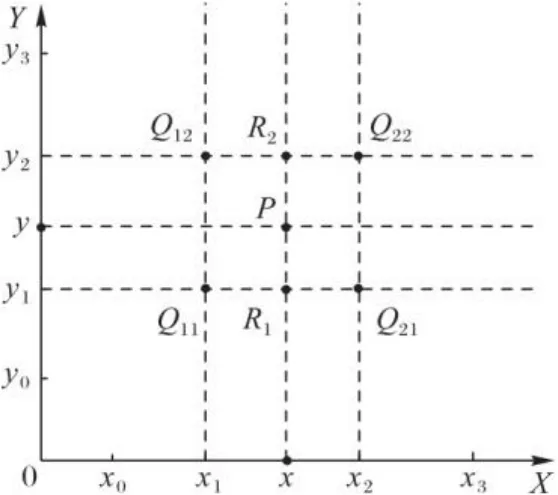
图2 插值坐标Fig. 2 Coordinates for interpolations
在Bilinear算法[21]中,通过计算距离最近的4个点的灰度值得到,计算过程包括两次线性插值运算。首先在轴方向上使用式(1)~(2)计算和的灰度值:
Lanczos和Box都采用了窗口采样的形式,并使用了以下两类基函数[23]:
由式(6)可见,Box因窗口值较小,上采样时与Nearest类似,对于插值点的计算只会使用若干采样点中的一个,效果较差。但Nearest的问题在于,下采样过程中图像缩小到一定程度时将对不相邻的点进行采样,导致输入像素的丢失,而Box则是对窗口内所有点进行下采样,确保了所有输入的像素都能贡献其相应的权重。
实验中将对以上介绍的5种插值算法进行对比与分析,从中选出最适合代码图像的插值算法后,将三张灰度图缩放至尺寸,并按红、绿、蓝的维度顺序合成为RGB代码图像。合成代码图像的图像纹理在不同家族中表现出了明显的差异,如图3中所示,图中的红、绿、蓝分别呈现出了XML、JAR与DEX二进制文件的纹理。
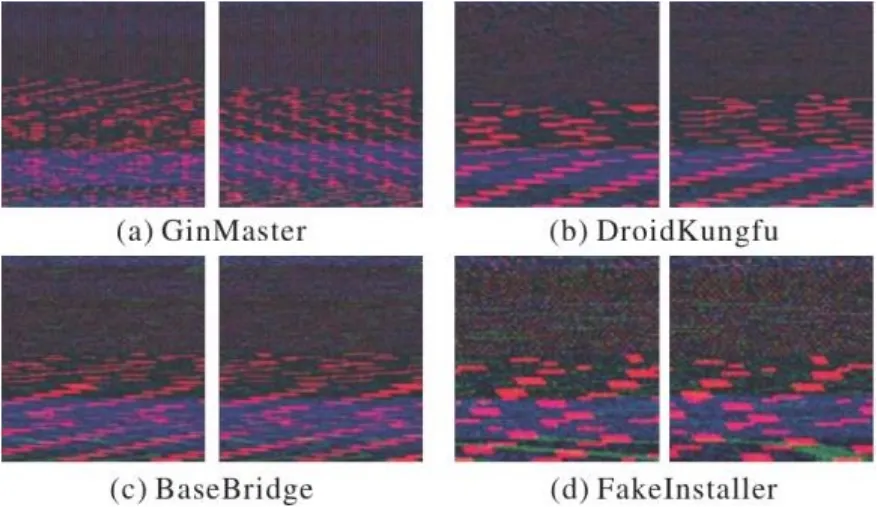
图3 不同家族样本的合成代码图像Fig. 3 Integrated code images of samples from different families
3 分类模型
代码图像由原文件直接生成,为处理此过程中产生的图像噪声,增强模型的特征选择能力,本文将Split-Attention注意力机制与去噪算法相结合提出了STResNeSt;同时在模型训练的过程中引入了CB Loss,以应对数据不平衡性导致的过拟合现象。
3.1 基于Split-Attention的ResNeSt
ResNeSt是以残差神经网络(Residual Neural Network, ResNet)为骨干网络,在SENet[3]和ResNeXt[4]网络的基础上发展而来。ResNeXt在ResNet的残差结构中提出了分组卷积的概念,通过基组(Cardinality)控制分组的数量,在不增加参数复杂度的前提下提高了准确率。SENet则引入了通道注意力机制,在训练过程中为每个特征通道赋予相应权重,并依照不同通道的权重提升有用的特征。ResNeSt在分组卷积通道注意力的基础上设计了ResNeSt Block,该模块允许特征图获取不同基组间的权重特征,用于增强特征的信息关联能力,提升分类效果。图4(a)展示了ResNeSt Block结构,图4(b)展示了ResNeSt Block中核心模块Split-Attention Block的结构。

图4 ResNeSt Block与Split-Attention Block结构
Tab. 4 Structures of ResNeSt Block and Split-Attention Block
如图4所示,为解决ResNet网络感受野过小和缺乏跨通道间信息交互能力的问题,ResNeSt将输入的特征图划分为个基组,并对每个基组继续进行切片(Split),将一个基组内的Splits数量记为,故最初的输入被切分为个Split。对这些Split施加卷积映射变换后,每个Split的输出表示为,其中。之后对一个基组内的所有Split进行元素相加便可获得基组的分组卷积结果,计算式如下:
之后通过通道软注意力机制实现对基组的加权融合。首先计算特征图经过激活函数Softmax后所得权重,当时,通过以下计算式计算:
3.2 软阈值去噪模块ST Block
考虑到代码图像的来源为整个代码文件,由此生成的图像必然存在与特征无关的噪声。以往的手工去噪工作繁琐且低效。大量的研究[24-26]已证实,将去噪分类器或算法加入分类模型中便可赋予模型主动抗噪能力。
文献[15]中将软阈值算法融入残差网络,提出了面向强噪声的深度残差收缩网络(Deep Residual Shrinkage Network, DRSN)。受此启发,本文将软阈值去噪模块嵌入ResNeSt Block的一核卷积层之后,提出了STResNeSt。将融合了Split Attention与ST Block的基础模块命名为STResNeSt Block,其结构如图5所示。
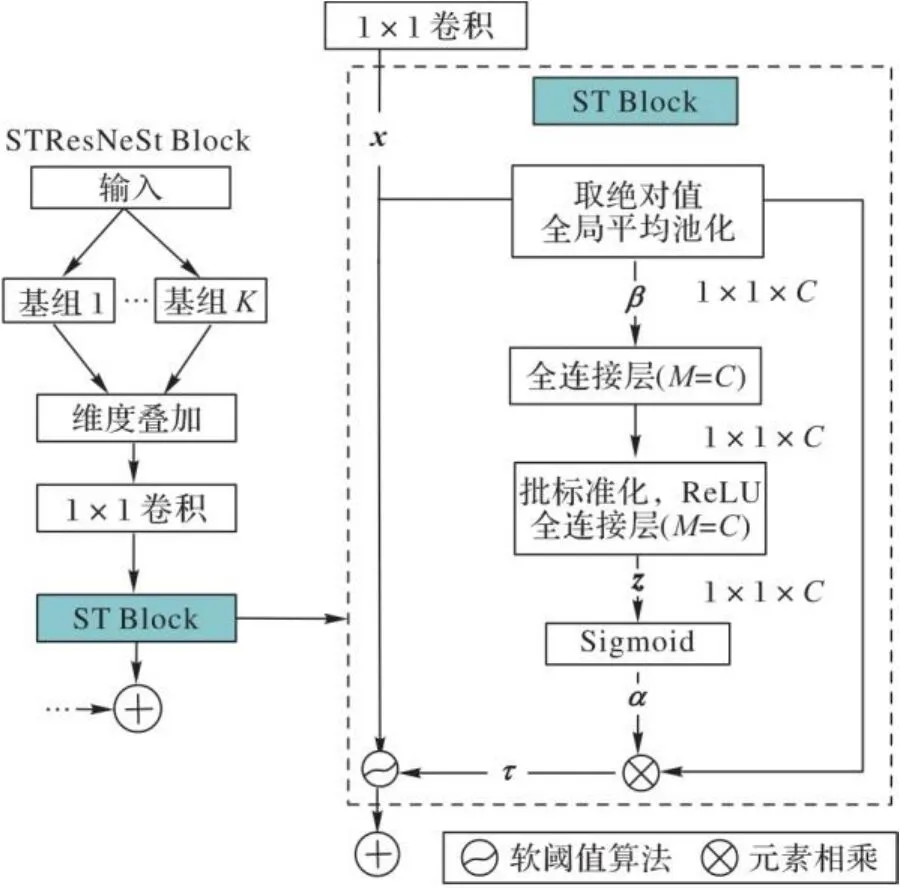
图5 STResNeSt Block结构
Tab. 5 Structure of STResNeSt Block
软阈值函数常用于噪声过滤,能够把有效信息转换成为正特征或负特征,将无效信息过滤为零特征,计算式如下:
3.3 类别平衡处理
本文实验中使用的Drebin数据集呈典型的长尾分布,存在较大的样本不均衡性,不少研究[27-28]通过增加重复样本、生成近似样本等重采样技术在一定程度上缓解此问题,因此本文也对Drebin数据集采取了同样的过采样方案(详见4.1节)。但随着过采样样本数的递增,此类样本对模型带来的收益将迅速递减,针对此问题,本文引用了文献[16]中的重加权方案:在模型训练中加入类别平衡损失函数CB Loss,根据不同类别样本的有效样本数对损失函数进行重新加权。
有效样本数(effective number of samples)的定义为样本的期望体积(expected volume),即样本能够覆盖的特征空间体积。以经过数据增强后的Drebin为例,对于原型样本较少的恶意家族类别,大部分样本都是在原型样本的基础上使用过采样等数据增强的方式得到,样本中存在较大的特征重叠可能性,故有效样本数较少。而原型样本较多的家族重叠样本少,故存在更多的有效样本数。
Softmax交叉信息熵(Cross-Entropy, CE)损失函数适用于本文的恶意家族多分类问题,其计算式如下:
4 实验与结果分析
4.1 实验环境、数据与评价标准
实验服务器的配置如下:Ubuntu 16.04操作系统,32 GB运行内存,CPU为Intel i9-10920X,使用NVIDIA 3090显卡搭配Cuda 11.1,深度学习框架选择PyTorch 1.6。实验中模型使用以ResNet-50为骨干网络的STResNeSt-50,对参数进行以下设置:学习率设为1E, Batch Size设为16,采用Adam作为优化器,使用CB Softmax Loss损失函数,CB Loss中的参数设为0.99。实验中对每个家族采用按比例抽取的方式分为80%的训练集与20%的测试集,实验结果取五折交叉验证后的平均值。
本文数据来自公开数据集Drebin,此数据集包括了178个家族在内的5 560个恶意样本。考虑到多数家族样本数较少,如数据集中有46个家族仅包含1个样本,故本文选取了样本数排名前10的家族,共计4 020个带家族标签的恶意样本。考虑到这些样本存在严重的不平衡性,不同家族间样本数比最大可达1∶10,因此本文采取了表2中的数据增强方法对样本进行扩增,新样本通过对原始样本的随机旋转、平移、裁减等一系列结构性操作得到。为保证实验结果的准确性,扩增的样本仅被添加进训练集中,测试集仍由原始样本构成。再结合使用3.3节中的类别平衡损失函数,尽最大可能减少样本不平衡引发的过拟合现象。数据增强前后的数据情况如表3所示。

表2 数据增强参数值Tab. 2 Parameter values of data augmentation
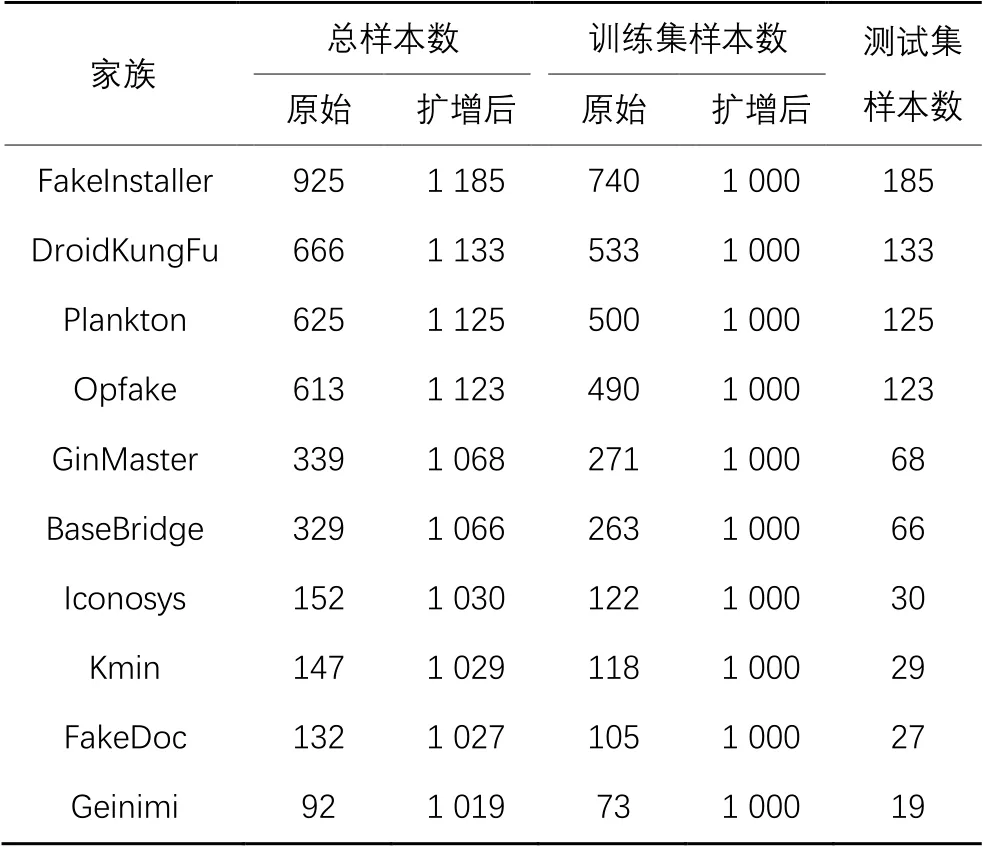
表3 实验数据集Tab. 3 Experimental dataset
4.2 迁移学习
本文模型除ST Block以外的部分始均使用了ResNeSt-50在ImageNet已训练好的参数,ST Block参数为随机标准化参数。将未训练过的STResNeSt-50与迁移学习后的STResNeSt-50进行了对比,图6为两个网络在30个epoch上的训练准确率、训练损失值、测试准确率与测试F1值对比。
实验结果表明,在恶意代码图像识别上使用经过ImageNet训练后的网络有以下优势:
1)网络收敛快。在预测准确率上的表现为:迁移学习后的网络在第一个epoch后就达到了接近95%,而未经训练的网络只有80%,更快的收敛能够极大缩短训练时长。
2)提升了预测效果。迁移学习后的网络相较未经训练的网络在准确率上提升了约1.2个百分点,在F1值上也有近1.8个百分点的提升。
3)改善了稳定性。图6中的虚线代表为未经训练的网络,不难发现其震荡幅度较大,而代表迁移学习网络的实线则更加平稳。
由此可见,虽然ImageNet多用于对象识别与目标检测的训练与评估,其数据库中的图像特征与代码图像存在区别,但是当一个网络经过ImageNet训练后,已经具备了一定的对图形信息的理解能力,即使应用在恶意代码图像识别中,这部分能力依然能够得到保留。

图6 迁移学习前后的网络对比Fig. 6 Comparison of networks before and after transfer learning
4.3 插值算法
为了检验不同插值算法对恶意代码图像分类精度的影响,本文对不同算法的性能进行了实验对比,结果如表4所示,其中还给出了使用不同算法进行插值缩放的耗时。
首先关注不同算法在时间效率上的差距。其中,Nearest因仅对最邻近的一个点插值采样,故计算速度最快,仅耗费了1.64 s。Bilinear和Bicubic分别为4点采样与16点采样,故时间效率呈递减状。Box与Lanczos为窗口采样,因Box窗口值较小,故在时间效率上领先于窗口较值大的Lanczos。
在精度上,Nearest的对最邻近采样策略导致其采样样本不足,精度上低于实验中其他算法;Box的采样窗口小,与Nearest相比仅在下采样时具备优势,导致精度也较低;Lanczos算法在上采样时具备优势,但实验数据集内的DEX与JAR文件普遍较大,导致多数插值情况为下采样插值,故准确率低于Bilinear与Bicubic。
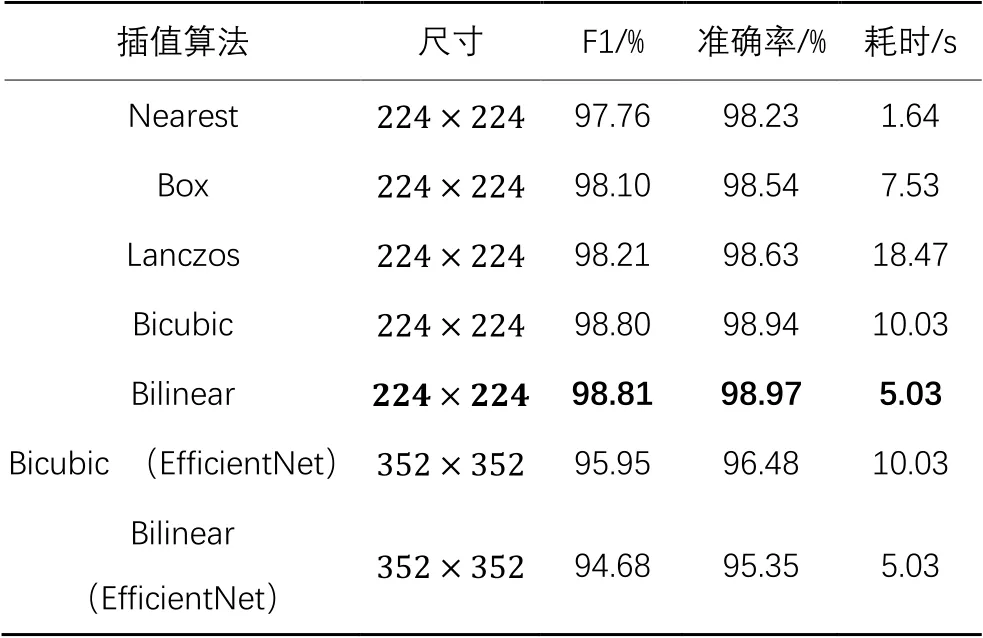
表4 不同插值算法的性能对比Tab. 4 Performance comparison of different interpolation algorithms
接下来将Bilinear与Bicubic进行对比,Bicubic采样点为Bilinear的4倍,但在实验中并没有呈现出应有的优势,原因可能在于插值后生成的图像尺寸小、清晰度低,并不能发挥Bicubic算法的优势。为验证以上猜想,将图像放大至再对二者进行对比。考虑到STResNeSt结构参数是在基础上设计,输入更大尺寸图像需要重新修改模型结构,也增加了训练时长,因此在轻型网络EfficientNet-B4[29]上进行验证。表4中的实验结果表明,在的代码图像上,Bicubic相较Bilinear算法提高了1.13个百分点的准确率和1.27个百分点的F1值,表明Bicubic算法在更大尺寸图像上具有优势。但在本文方法中仍将选择与模型适配度高的Bilinear算法进行插值缩放。
4.4 数据增强与类别平衡损失函数
为验证样本不平衡对分类精度造成的影响,本文首先将原始数据与经过数据增强的数据进行对比。表5中数据显示,数据增强后的数据在分类精度上无显著提升,原因在于在数据增强过程中虽然样本数增加,但有效样本数并无明显上升;同时,旋转、平移等结构变化的过程也可能使样本损失部分特征。
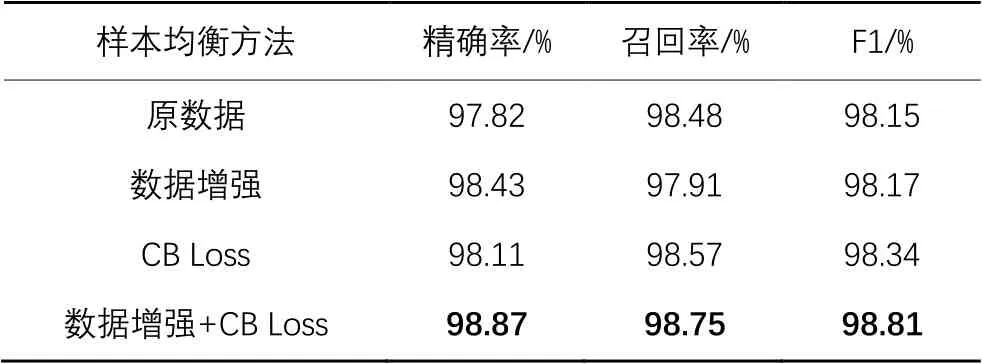
表5 不同样本均衡方法的性能对比Tab. 5 Performance comparison of different sample balancing methods
之后将训练中的损失函数替为CB Loss,但依然使用原始数据集。可见经过CB Loss训练后的模型在F1值上有了0.19个百分点的小幅提升,表明在损失函数中为不同类别赋予不同的权重能够缓解数据不平衡造成的影响。即便如此,较少的样本量依然限制了模型的效果。而将数据增强与CB Loss相结合后,可以看到其F1值达到了98.81%,在原数据的基础上实现了0.66个百分点的领先。
图7为不同家族的F1值在使用数据增强与CB Loss前后的不同表现,其中左侧的竖轴为F1值,右侧的竖轴为该家族样本在原始数据中的数量。从图7中能够看出,不同家族的F1值经过样本不均衡处理后都有了或多或少的提升。值得注意的是,样本数原本较少的家族如Geinimi、Iconosys等涨幅更为明显,Geinimi家族的F1值达到了约2.4个百分点的涨幅。
实验结果表明,数据增强能够增加样本多样性,降低模型对某些属性的依赖。类别均衡损失函数又能根据有效样本数为不同类别赋予相应的权重,有效降低了样本不均衡导致的负面影响。
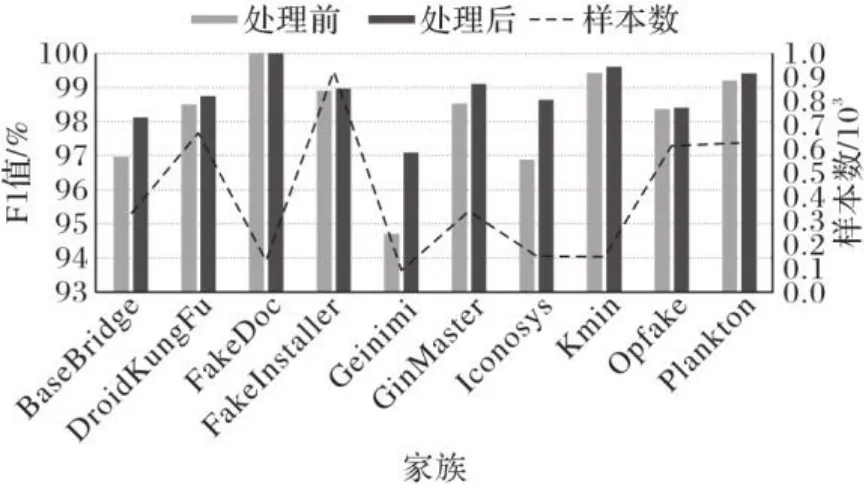
图7 不同家族的F1值Fig. 7 F1 scores of different families
4.5 分类模型
表6给出了基于ResNet改进的各类残差结构网络在恶意代码合成图像中的性能对比。
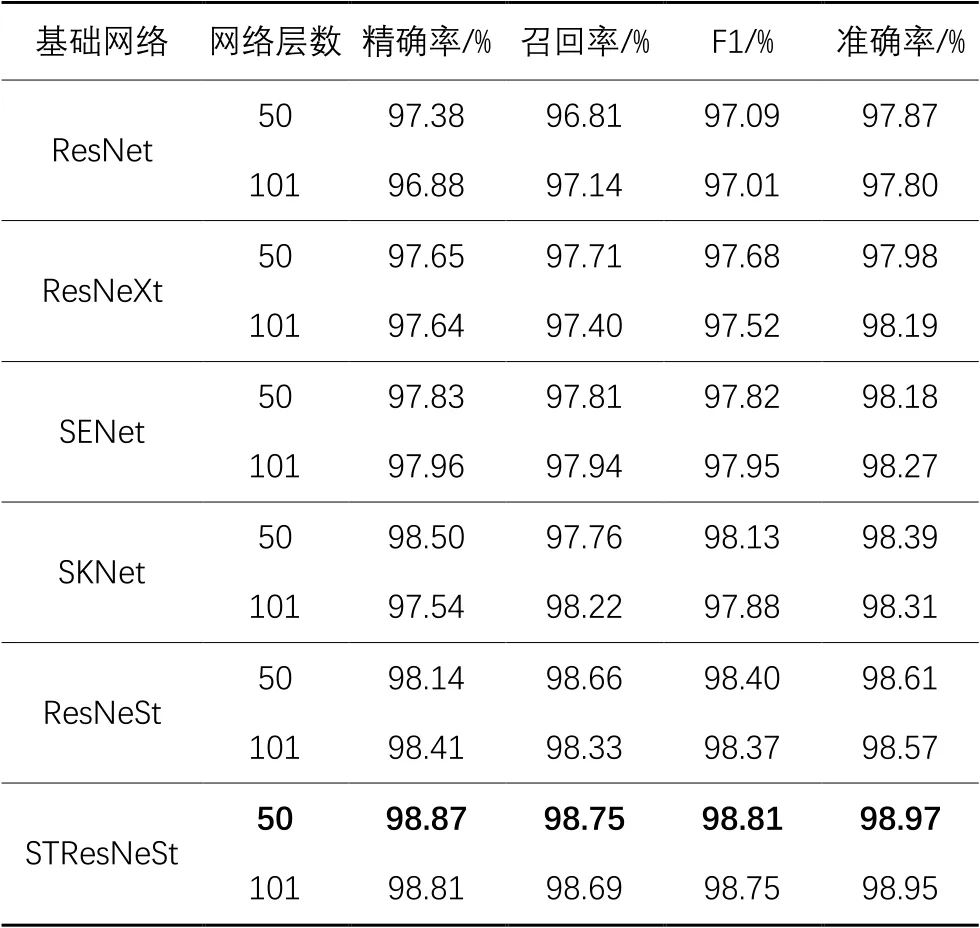
表6 不同残差网络的性能对比Tab. 6 Performance comparison of different residual networks
不难发现,虽然不同残差神经网络表现不一,但在代码图像合成方法上都取得了较好的效果,均达到了97%以上的准确率与F1值。
对比实验中ResNet准确率最低,因为其作为表6中所有网络的骨干网络,只采用了基本的残差结构。ResNeXt使用了Inception[30]中的网络结构,在ResNet中进行分组卷积,故效果优于ResNet。SENet则是通过引入了通道注意力提升网络的特征识别能力,在50结构上准确率上领先ResNet约0.31个百分点。SKNet[5]与ResNeSt结构类似,都在ResNeXt和SENet的基础上设计而来,均采用了多分支结构与注意力思想,但得益于ResNeSt中的Split Attention模块化的设计,ResNeSt在控制了参数量的情况下依然提升了准确率。STResNeSt与ResNeSt相比增加了软阈值去噪模块,针对代码图像中的噪声进行处理,增强了模型的特征选择能力,在恶意软件家族的分类准确率达到了98.97%,相较于ResNet实现了1.1个百分点的领先。
本文中还将50层结构与101层结构进行了对比。虽然101结构使用了更多的基础模块,但在代码图像上并没有展现出相较50结构的优势,原因在于代码图像与自然场景图像存在差异,代码图像的特征仅利用局部的梯度、边缘等信息就可判断,故101结构中的高层语义信息难以发挥其作用。
4.6 代码图像
从JAR文件中筛选可见字符串是代码图像合成前的步骤之一。将字符串筛选前后的JAR文件进行对比,将两个文件分别转换为RGB图,输入模型中进行训练。由表7可见,筛选后的JAR文件相较原始的JAR文件在准确率上提升了约1.04个百分点。
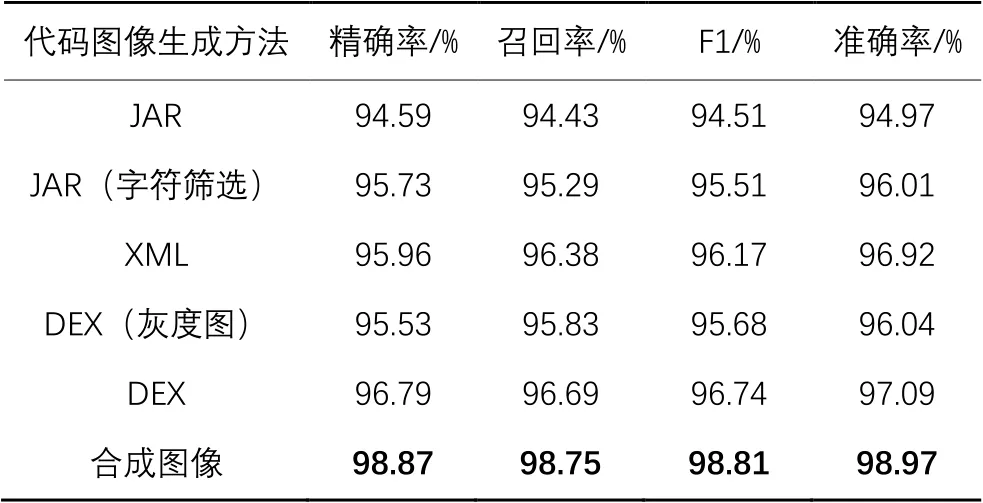
表7 不同代码图像生成方法的性能对比Tab.7 Performance comparison of different code image generation methods
接下来测试XML与DEX文件生成的代码图像。表7中的DEX图像生成方法分为DEX(灰度图)和DEX两种:前者为文献[11]中的方法,即将整个文件直接转换为一维灰度图;后者对DEX文件进行简单三维折叠后生成RGB图像,此方法被文献[12]与文献[13]采用。
将合成代码图像与上述代码图像进行对比,结果如表7所示,相较于XML和可见JAR文件的RGB图像,合成后的RGB恶意代码图像在准确率上分别提升了2.05个百分点和2.96个百分点,在与DEX(灰度图)、DEX的对比上也分别保持了2.93个百分点和1.88个百分点的优势,同时在F1值上的表现也最为出色。由此可见,合成的代码图像融合了多类文件的特征信息,提升了分类效果。
5 结语
为优化安卓恶意代码图像的分类效果,本文提出了代码图像的合成方法,并研究了代码图像生成中的图像比例与插值缩放问题,分类模型上将软阈值算法与Split-Attention相结合提出了STResNeSt,最后使用了数据增强与CB Loss处理数据不平衡。实验结果表明:1)合成后的代码图像为模型提供了更为丰富的代码特征,得到了更优秀的分类效果;2)Bilinear插值算法在代码图像上的精度表现优于同类算法,同时保持了较低的算法复杂度;3)引入了去噪模块的STResNeSt具备更强的特征选择能力,其分类精度高于同类残差结构网络;4)数据增强技术与CB Loss相结合有效减轻了不平衡数据给模型训练带来的负面影响,显著提高了小样本家族的分类精度。
本文对恶意代码图像化识别的思路进行了新的探索,但仍然存在一些不足之处,优化模型、降低复杂度以及在更多的样本中验证并改进本文方法是未来需要完善的工作。
[1] LI M B, WANG W, WANG P, et al. LibD: scalable and precise third-party library detection in Android markets [C]// Proceedings of the 2017 IEEE/ACM 39th International Conference on Software Engineering. Piscataway: IEEE, 2017: 335-346.
[2] HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE,2016: 770-778.
[3] HU J, SHEN L, SUN G. Squeeze-and-excitation networks [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7132-7141.
[4] XIE S N, GIRSHICK R, DOLLÁR P, et al. Aggregated residual transformations for deep neural networks [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 5987-5995.
[5] LI X, WANG W H, HU X L, et al. Selective kernel networks [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 510-519.
[6] ZHANG H, WU C R, ZHANG Z Y, et al. ResNeSt: split-attention networks [EB/OL]. [2021-03-02]. https://arxiv.org/pdf/2004. 08955.pdf.
[7] SANTOS I, BREZO F, NIEVES J, et al. Idea: opcode-sequence-based malware detection [C]// Proceedings of the 2010 International Symposium on Engineering Secure Software and Systems, LNCS 5965. Berlin: Springer, 2010:35-43.
[8] WANG W, WANG X, FENG D W, et al. Exploring permission-induced risk in Android applications for malicious application detection [J]. IEEE Transactions on Information Forensics and Security, 2014, 9(11): 1869-1882.
[9] GRINI L S, SHALAGINOV A, FRANKE K. Study of soft computing methods for large-scale multinomial malware types and families detection [M]// ZADEH L A, YAGER R R, SHAHBAZOVA S N, et al. Recent Developments and the New Direction in Soft-Computing Foundations and Applications, STUDFUZZ 361. Cham: Springer, 2018: 337-350.
[10] QIU J Y, ZHANG J, LUO W, et al. A3CM:automatic capability annotation for Android malware [J]. IEEE Access, 2019,7: 147156-147168.
[11] 张晨斌,张云春,郑杨,等.基于灰度图纹理指纹的恶意软件分类[J].计算机科学,2018,45(6A):383-386.(ZHANG C B, ZHANG Y C, ZHENG Y, et al. Malware classification based on texture fingerprint of gray-scale images [J]. Computer Science, 2018, 45(6A): 383-386.)
[12] HUANG T T H D, KAO H Y. R2-D2: color-inspired Convolutional Neural Network (CNN)-based Android malware detections [C]// Proceedings of the 2018 IEEE International Conference on Big Data. Piscataway: IEEE, 2018: 2633-2642.
[13] VASAN D, ALAZAB M, WASSAN S, et al. IMCFN: image-based malware classification using fine-tuned convolutional neural network architecture [J]. Computer Networks, 2020, 171: Article No.107138.
[14] 高杨晨,方勇,刘亮,等.基于卷积神经网络的Android恶意软件检测技术研究[J].四川大学学报(自然科学版),2020,57(4):673-680.(GAO Y C,FANG Y, LIU L, et al. Android malware detection technology based on deep convolutional neural network [J]. Journal of Sichuan University (Natural Science Edition), 2020, 57(4): 673-680.)
[15] ZHAO M H, ZHONG S S, FU X Y, et al. Deep residual shrinkage networks for fault diagnosis [J]. IEEE Transactions on Industrial Informatics, 2020, 16(7): 4681-4690.
[16] CUI Y, JIA M L, LIN T Y, et al. Class-balanced loss based on effective number of samples [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 9260-9269.
[17] NATARAJ L, KARTHIKEYAN S, JACOB G, et al. Malware images: visualization and automatic classification [C]// Proceedings of the 2011 8th International Symposium on Visualization for Cyber Security. New York; ACM, 2011: Article No.4.
[18] CUI Z H, XUE F, CAI X J, et al. Detection of malicious code variants based on deep learning [J]. IEEE Transactions on Industrial Informatics, 2018, 14(7): 3187-3196.
[19] 孙博文,张鹏,成茗宇,等.基于代码图像增强的恶意代码检测方法[J].清华大学学报(自然科学版),2020,60(5):386-392.(SUN B W, ZHANG P,CHENG M Y, et al. Malware detection method based on enhanced code images [J]. Journal of Tsinghua University (Science and Technology), 2020, 60(5): 386-392.)
[20] ARP D, SPREITZENBARTH M, HÜBNER M, et al. Drebin: efficient and explainable detection of Android malware in your pocket [C]// Proceedings of the 2014 Annual Network and Distributed System Security Symposium. Reston: Internet Society, 2014: 1-12.
[21] PRESS W H, TEUKOLSKY S A, VETTERLING W T, et al. Numerical Recipes: the Art of Scientific Computing [M]. 3rd ed. New York: Cambridge University Press, 2007: 123-128.
[22] KEYS R. Cubic convolution interpolation for digital image processing [J]. IEEE Transactions on Acoustics, Speech, and Signal Processing, 1981, 29(6): 1153-1160.
[23] TURKOWSKI K. Filters for common resampling tasks [M]// GRASSNER A S. Graphics Gems. Waltham: Academic Press, 1990: 147-165.
[24] LAWRENCE N D, SCHÖLKOPF B. Estimating a kernel fisher discriminant in the presence of label noise [C]// Proceedings of the 2001 18th International Conference on Machine Learning. San Francisco: Morgan Kaufmann Publishers Inc., 2001: 306-313.
[25] XIA S Y, WANG G Y, CHEN Z Z, et al. Complete random forest based class noise filtering learning for improving the generalizability of classifiers [J]. IEEE Transactions on Knowledge and Data Engineering, 2019, 31(11): 2063-2078.
[26] WU P X, ZHENG S Z, GOSWAMI M, et al. A topological filter for learning with label noise [EB/OL]. [2021-03-02]. https://arxiv.org/pdf/2012.04835.pdf.
[27] HE H B, BAI Y, GARCIA E A, et al. ADASYN: adaptive synthetic sampling approach for imbalanced learning [C]// Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence). Piscataway: IEEE, 2008: 1322-1328.
[28] ZOU Y, YU Z D, VIJAYA KUMAR B V K, et al. Unsupervised domain adaptation for semantic segmentation via class-balanced self-training [C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11207. Cham: Springer, 2018:297-313.
[29] TAN M X, LE Q. EfficientNet: rethinking model scaling for convolutional neural networks [C]// Proceedings of the 2019 36th International Conference on Machine Learning. New York: JMLR.org,2019: 6105-6114.
[30] SZEGEDY C, VANHOUCKE V, IOFFE S, et al. Rethinking the inception architecture for computer vision [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 2818-2826.
Android malware family classification method based on code image integration
LI Mo, LU Tianliang*, XIE Ziheng
(School of Information and Cyber Security,People’s Public Security University of China,Beijing100038,China)
Code visualization technology is rapidly popularized in the field of Android malware research once it was proposed. Aiming at the problem of insufficient representation ability of code image converted from single DEX (classes.dex)file, a new Android malware family classification method based on code image integration was proposed. Firstly, the DEX, XML (androidManifest.xml) and decompiled JAR (classes.jar) files in the Android application package were converted to three gray-scale images, and the Bilinear interpolation algorithm was used for the scaling of gray images in different sizes. Then, the three gray-scale images were integrated into a three-dimensional Red-Green-Blue (RGB) image for training and classification. In terms of classification model, the Soft Threshold (ST) Block+ResNeSt(STResNeSt) was proposed by combining the soft threshold denoising block with Split-Attention based ResNeSt. The proposed model has the strong anti-noise ability and is able to pay more attention to the important features of code image. To handle the long-tail distribution of data in the training process, Class Balance Loss (CB Loss) was introduced after data augmentation,which provided a feasible solution to the over-fitting caused by the imbalance of samples. On the Drebin dataset, the accuracy of integrated code image is 2.93 percentage points higher than that of DEX gray-scale image, the accuracy of STResNeSt is improved by 1.1 percentage points compared with the Residual Neural Network (ResNet), the scheme of data augmentation combined with CB Loss improves the F1 score by up to 2.4 percentage points. Experimental results show that, the average classification accuracy of the proposed method reaches 98.97%, which can effectively classify the Android malware family.
Android malware family; code image; transfer learning; Convolution Neural Network (CNN); channel attention
TP309.5
A
1001-9081(2022)05-1490-10
10.11772/j.issn.1001-9081.2021030486
2021⁃03⁃31;
2021⁃06⁃23;
2021⁃06⁃25。
2021年公共安全行为科学实验室开放课题(2020SYS06)。
李默(1995—),男,江西赣州人,硕士研究生,主要研究方向:恶意代码检测、机器学习; 芦天亮(1985—),男,河北保定人,副教授,博士,CCF会员,主要研究方向:网络空间安全、恶意代码检测; 谢子恒(1999—),男,浙江宁波人,主要研究方向:网络攻防、恶意代码检测。
This work is partially supported by 2021 Open Project of Public Security Behavioral Science Lab (2020SYS06).
LI Mo, born in 1995, M. S. candidate. His research interests include malware detection, machine learning.
LU Tianliang, born in 1985, Ph. D., associate professor. His main research interests include cyber security, malware detection.
XIE Ziheng, born in 1999. His research interests include cyber-attack and defense, malware detection.
猜你喜欢
包装工程(2022年9期)2022-05-13
集装箱化(2021年1期)2021-04-12
中国信息技术教育(2020年2期)2020-02-02
领导决策信息(2018年16期)2018-09-27
数学学习与研究(2017年3期)2017-03-09
新高考·高二数学(2016年7期)2017-01-23
股市动态分析(2016年17期)2016-10-20
股市动态分析(2016年17期)2016-10-20
股市动态分析(2015年16期)2015-09-10
计算技术与自动化(2014年1期)2014-12-12
