
密度峰值优化的球簇划分欠采样不平衡数据分类算法
2022-06-21 06:47刘学文王继奎杨正国李强易纪海李冰聂飞平
计算机应用 2022年5期
刘学文,王继奎*,杨正国,李强,2,易纪海,李冰,聂飞平
(1.兰州财经大学 信息工程学院,兰州 730020; 2.甘肃省电子商务技术与应用重点实验室(兰州财经大学),兰州 730020;3.西北工业大学 光学影像分析与学习中心,西安 710072)(∗通信作者电子邮箱wjkweb@163.com)
密度峰值优化的球簇划分欠采样不平衡数据分类算法
刘学文1,王继奎1*,杨正国1,李强1,2,易纪海1,李冰1,聂飞平3
(1.兰州财经大学 信息工程学院,兰州 730020; 2.甘肃省电子商务技术与应用重点实验室(兰州财经大学),兰州 730020;3.西北工业大学 光学影像分析与学习中心,西安 710072)(∗通信作者电子邮箱wjkweb@163.com)
在集成算法中嵌入代价敏感和重采样方法是一种有效的不平衡数据分类混合策略。针对现有混合方法中误分代价计算和欠采样过程较少考虑样本的类内与类间分布的问题,提出了一种密度峰值优化的球簇划分欠采样不平衡数据分类算法DPBCPUSBoost。首先,利用密度峰值信息定义多数类样本的抽样权重,将存在“近邻簇”的多数类球簇划分为“易误分区域”和“难误分区域”,并提高“易误分区域”内样本的抽样权重;其次,在初次迭代过程中按照抽样权重对多数类样本进行欠采样,之后每轮迭代中按样本分布权重对多数类样本进行欠采样,并把欠采样后的多数类样本与少数类样本组成临时训练集并训练弱分类器;最后,结合样本的密度峰值信息与类别分布为所有样本定义不同的误分代价,并通过代价调整函数增加高误分代价样本的权重。在10个KEEL数据集上的实验结果表明,与现有自适应增强(AdaBoost)、代价敏感自适应增强(AdaCost)、随机欠采样增强(RUSBoost)和代价敏感欠采样自适应增强(USCBoost)等不平衡数据分类算法相比,DPBCPUSBoost在准确率(Accuracy)、F1分数(F1-Score)、几何均值(G-mean)和受试者工作特征(ROC)曲线下的面积(AUC)指标上获得最高性能的数据集数量均多于对比算法。实验结果验证了DPBCPUSBoost中样本误分代价和抽样权重定义的有效性。
不平衡数据分类;密度峰值;球聚类;代价敏感;欠采样
0 引言
在异常检测[1-4]、信用欺诈检测[5-7]、医保欺诈检测[8]、电信诈骗检测[9-10]等应用场景中,传统分类模型往往较难取得理想的效果,因为传统分类模型着重关注总体分类精度,在巨大的样本数量差距下,少数类易被“忽视”。因此,研究者们提出了两种策略来增加对少数类的“关注度”:一是对数据进行重构,即减少多数类样本数量或增加少数类样本数量,使多数类和少数类样本数量趋于平衡;二是在分类模型[11]和思想上聚焦于少数类的分类准确度[12]。两种策略都能有效地提高分类算法在不平衡数据上的分类性能。
数据重构策略主要包括特征选择和重采样方法,其中重采样方法包括欠采样[13-14]、过采样[15-17]以及结合欠采样和过采样的混合采样方法[18-19]。过采样方法通过增加不平衡数据中的少数类样本来平衡数据分布,欠采样通过减少不平衡数据中的多数类样本来平衡数据分布。在较大规模的数据中,欠采样方法能显著减少训练数据的数量从而提升训练速度。随机欠采样(Random UnderSampling, RUS)方法[13]是最简易的欠采样方法之一,其使用完全随机的方法移除多数类样本,显然,RUS方法并没有考虑到多数类样本所携带的信息,极可能将一些对后续分类过程有价值的样本移除。
分类思想改进也是提高不平衡数据分类性能的重要策略,代表方法包括集成学习[20]和代价敏感学习[21]等。现有研究中,将重采样与分类思想改进策略相结合的方法的分类效果可能比单一策略更好。文献[22]中结合随机欠采样和集成学习方法,提出了EasyEnsemble和BalanceCascade方法。EasyEnsemble从多数类样本中随机抽取与少数类样本数量相等的多个独立子集,分别与少数类样本组合成新训练集,独立训练多个自适应增强(Adaptive Boosting, AdaBoost)分类器[20],最终输出集成分类器。BalanceCascade与EasyEnsemble的不同之处在于,每次迭代利用分类阈值从训练集中移除分类正确的样本。相较于RUS,上述两种方法减少了多数类样本的信息损失,但是显著增加了训练时间。有研究者基于AdaBoost提出了随机欠采样增强(Random UnderSampling Boosting, RUSBoost)方法[23],该方法在迭代过程中对多数类进行随机欠采样并与少数类组成临时训练集,然后使用临时训练集和权值训练弱分类器。RUSBoost仍然使用随机欠采样的方式平衡数据分布,当不平衡比例非常高时,可能需要非常多的迭代次数。
文献[21]中将集成学习和代价敏感学习相结合,提出了代价敏感自适应增强(Cost-sensitive AdaBoost, AdaCost)方法。AdaBoost赋予每个样本同等的误分代价,AdaCost则可对不同样本赋予不同的误分代价,例如对少数类样本赋予更高的误分代价,可以降低迭代过程中的累积误分风险。文献[14]中采用AdaCost的样本权重更新策略,提出了基于欠采样和代价敏感的不平衡数据分类算法——代价敏感欠采样自适应增强(UnderSampling and Cost-sensitive Boosting, USCBoost)。与随机采样方法不同,USCBoost只选取权重较大的多数类样本和所有少数类样本作为临时训练集,训练速度较快。USCBoost采用类依赖代价,为少数类样本定义比多数类样本更高的误分代价,但是该方法并没有考虑到同类样本内部之间也存在差异[24]。
文献[25]中提出了密度峰值聚类(Clustering by fast search and find of Density Peaks, DPC)算法,该算法利用“密度”和“峰值”信息发现样本的潜在层次结构,基于这种结构可对球形和非球形数据进行聚类。文献[26]中提出了球k均值聚类算法(Ballk-means),该算法将类簇视为球并将其划分为“稳定区域”和“活动区域”,只计算“活动区域”与“近邻簇”中心之间的距离,从而有效减少了质心距离计算量。受DPC和Ballk-means思想的启发,本文提出了密度峰值优化的球簇划分欠采样不平衡数据分类算法DPBCPUSBoost (Boosting algorithm based on Ball Cluster Partitioning and UnderSampling with Density Peak optimization)。本文的主要工作如下:
1)利用了“密度峰值”定义多数类样本抽样权重。考虑样本的潜在空间结构,对于密度和峰值都较大的样本,DPBCPUSBoost赋予其更大的抽样权重。
2)结合了“Ballk-means”思想调整多数类样本抽样权重。DPBCPUSBoost将存在“近邻簇”的多数类球簇划分为“易误分区域”和“难误分区域”,并增大“易误分区域”内的样本抽样权重。
3)结合了“密度峰值”定义误分代价。DPBCPUSBoost同时考虑类依赖代价和样本依赖代价,赋予少数类更高误分代价的同时,也考虑到类簇内部样本分布的差异,对于密度和峰值都较大的样本赋予更高的误分代价。
为验证DPBCPUSBoost算法的有效性,在10个KEEL不平衡数据集上进行实验。实验结果表明,相较于AdaBoost、AdaCost、RUSBoost和USCBoost算法,DPBCPUSBoost在准确率(Accuracy)、F1分数(F1-Score)、几何均值(Geometric Mean, G-mean)和受试者工作特征(Receiver Operating Characteristic, ROC)曲线下面的面积(Area Under Curve, AUC)指标上均取得了较好的效果。
1 相关工作
本文涉及的变量较多,因此,在表1中对出现次数较多和较重要的变量进行了说明。

表1 变量及说明Tab. 1 Variables and descriptions
1.1 DPC算法
文献[25]中认为类簇中心应该具有以下特点:类簇中心与比它密度更高的样本相距较远;类簇中心被更低密度的样本所围绕。
文献[25]中定义了样本的“局部密度”和“峰值”,并认为“局部密度”和“峰值”都较大的样本成为类簇中心的概率更大。
由式(2)可知,样本的峰值为与“密度高于它且离它最近”的样本之间的距离。
为便于理解,通过表2、图1~2的示例来展示类簇中心的选取过程。表2为二类别含噪声的人工数据集信息(数值四舍五入保留三位小数),样本的分布情况如图1所示,类簇中心选取的决策图如图2所示。在图1~2中,圆形表示多数类样本,菱形表示少数类样本,矩形表示噪声样本。
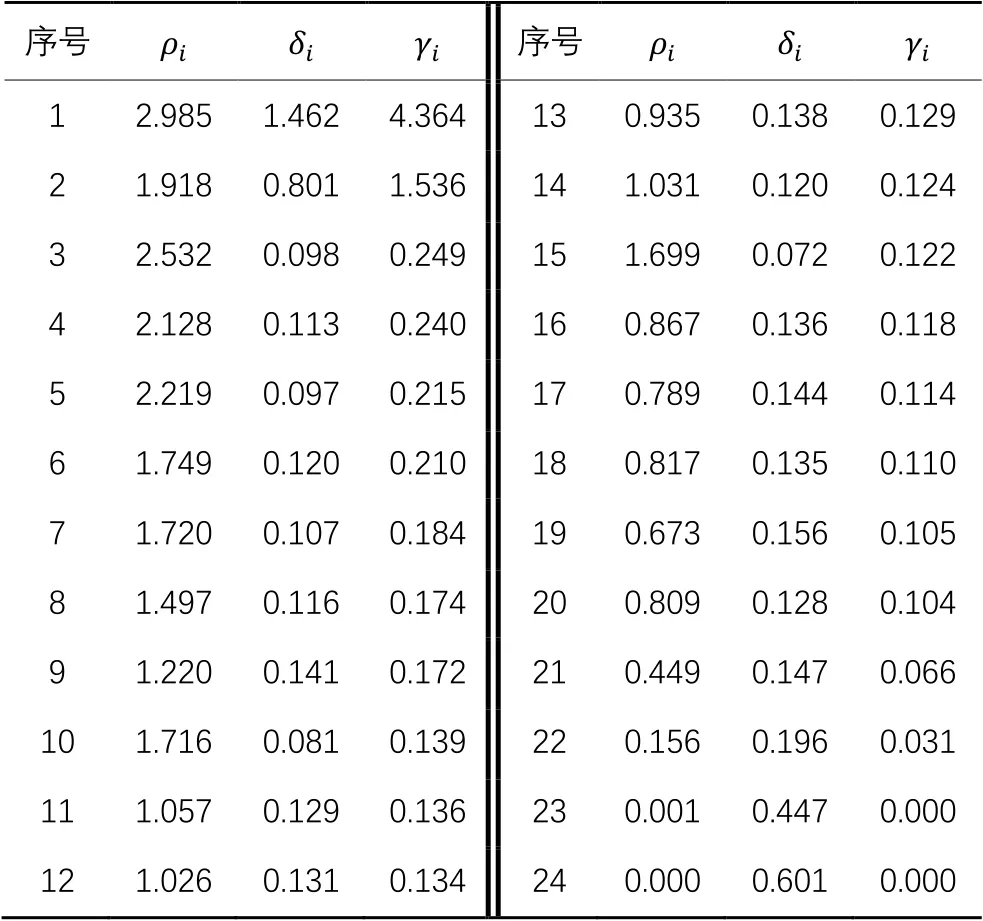
表2 样本信息Tab. 2 Sample information
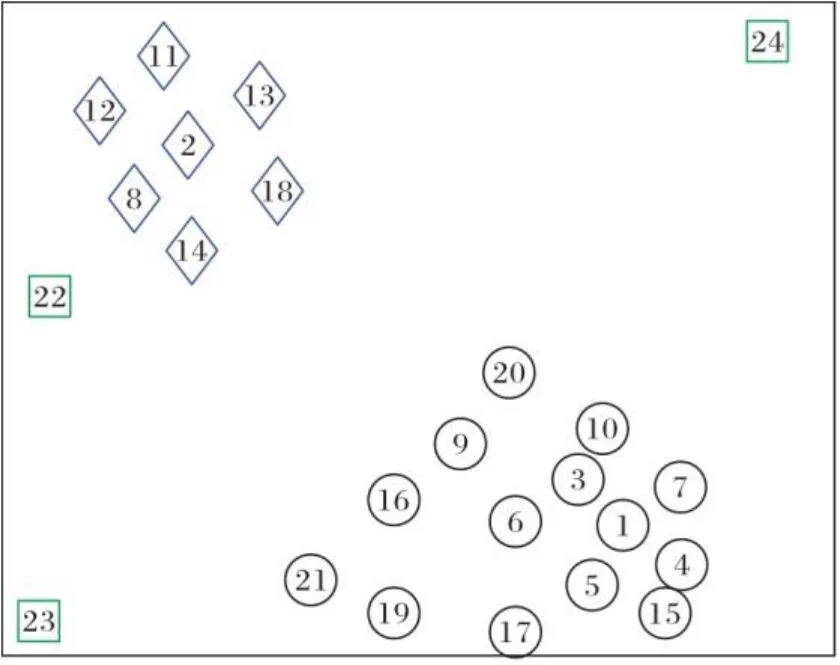
图1 样本分布Fig. 1 Sample distribution
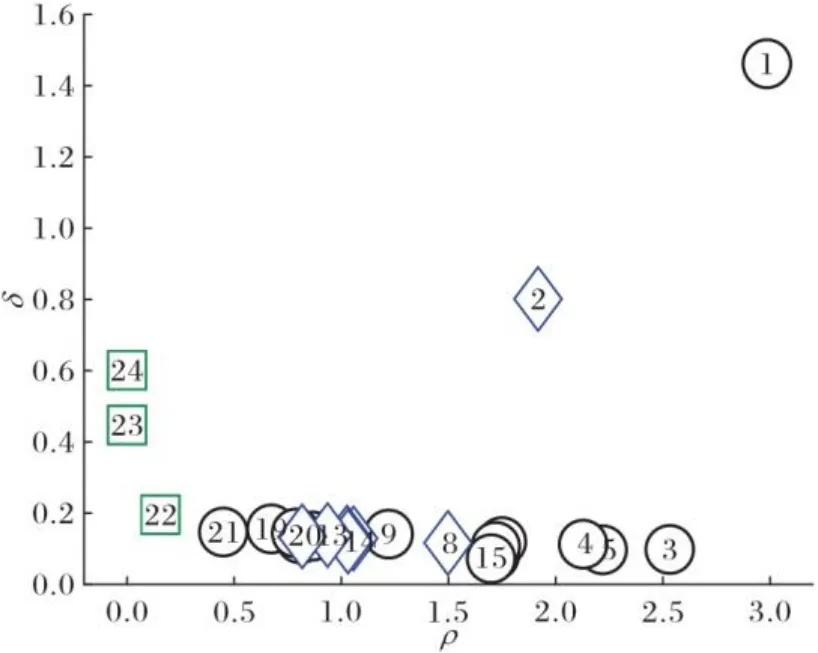
图2 决策图Fig. 2 Decision diagram
从图2可以看出,相较于大部分样本位于下方,样本1和样本2位于右上角,根据文献[25]的方法,可以选取样本1和样本2作为两个类簇的中心。
1.2 Ball k-means算法
为减少k-means算法迭代过程中的质心距离计算量,Ballk-means[26]算法将球簇划分为“稳定区域”和“活动区域”。
球簇内“稳定区域”以外的区域为“活动区域”,若球簇的近邻簇数量多于一个,“活动区域”会被细分为多个“环形区域”。
文献[26]中通过理论证明,当前轮次迭代过程中,“稳定区域”内的样本不会被划分到任何其他的簇中,而“活动区域”内的样本可能会被划分到近邻簇,因此,只需在每轮迭代中计算“活动区域”内的点与近邻簇中心点之间的距离,从而极大减少了距离计算量。
1.3 USCBoost算法
文献[14]中结合AdaCost算法的代价调整函数提出了USCBoost算法,该算法在每轮迭代过程中只选取权值较高的多数类样本参与分类器训练,具体步骤如算法1。
算法1 USCBoost算法。
b) Else
c) 欠采样后的多数类样本与全部少数类样本组成临时训练集,并归一化样本权重;
2 结合密度峰值代价和欠采样的分类算法
本文受DPC和Ballk-means的启发,利用密度峰值定义随机抽样权重,将多数类球簇划分为“易误分区域”和“难误分区域”,并增加“易误分区域”内样本的抽样权重,在初次迭代中,依据不同的抽样权重对多数类样本进行欠采样。本文结合密度峰值和样本类别分布信息定义新的误分代价,并通过代价调整函数使高误分代价的样本在迭代过程中更快地增加样本权重。
2.1 定义抽样权重
在DPC算法中,中心点必须同时满足“具有较高密度”和“离其他更高密度点较远”这两个条件,因此,值的大小可以反映样本作为局部中心的可能性。如表2、图1~2所示,值最大的两个样本分别作为不同类簇的中心,而值较大的样本成为局部中心,值较小的样本则分布在类簇边缘。因此,本文方法在欠采样中尽量保留这些中心点。
因为在决策边界区域内的多数类样本容易被误分,因此,需要提高这些样本的抽样权重,使其能够在训练分类器的过程中获得更多关注。Ballk-means方法将球簇划分为“稳定区域”和“活动区域”,与之类似,本文将多数类球簇划分为“易误分区域”和“难误分区域”,少数类球簇不作划分。令表示少数类球簇的中心,表示多数类球簇的中心,为多数类球簇的半径,这两个区域的定义如下。
图3为划分球簇的示意图,实线表示球簇的边界,多数类球簇内弧形虚线与多数类球簇边界线所围成的区域为“易误分区域”,多数类球簇内“易误分区域”以外的区域为“难误分区域”。
如果少数类球簇是多数类球簇的近邻簇,则对多数类球簇中落入“易误分区域”内的样本的抽样权重进行调整;如果少数类球簇不是多数类球簇的近邻簇,或者样本落在“难误分区域”内,则不对抽样权重进行调整。

图3 划分球簇Fig. 3 Dividing ball clusters
抽样权重调整后,对其归一化:
USCBoost算法初次迭代时采用RUS方法对多数类样本进行欠采样,在之后的迭代过程中则根据样本权重的大小顺序进行欠采样。当不平衡比例非常高时,初次迭代训练的分类器质量会非常差,进而影响之后的训练过程。而本文则按照权重对多数类进行欠采样,这种方式尽量保留了决策边界区域内的有价值的多数类样本[12,27]。
2.2 定义误分代价
由表2中的样本信息、图1中样本分布情况和图2中的决策图可知,和值越小的样本,越不可能成为局部中心点,和值越大的样本越有可能成为局部中心,而这些中心点的重要性在分类过程中的价值要更高,误分代价也更大。因此,本文利用对不同样本定义不同的代价。
2.3 复杂度分析
综上,相较于采用欠采样方法的RUSBoost和USCBoost,DPBCPUSBoost的时间复杂度和空间复杂度更高。但是,对于没有采用欠采样方法的AdaBoost和AdaCost,由于这些算法在迭代训练弱分类器时输入了全部的样本,而DPBCPUSBoost只输入了欠采样后的小部分样本,因此DPBCPUSBoost的迭代训练过程相较于上述两个算法消耗了更少的时间和空间。DPBCPUSBoost的算法步骤如算法2。
算法2 DPBCPUSBoost算法。
b) Else
c) 将欠采样后的多数类样本与全部少数类样本组成临时训练集,并归一化样本权重;
3 实验与结果分析
实验使用的系统为64位Windows 10,程序开发环境为Matlab 2019a,硬件为酷睿I5处理器和8 GB运行内存。实验涉及的对比算法均参照原文及网络资料实现,所使用数据集为网络公开数据集。
3.1 实验设置
为验证DPBCPUSBoost的有效性,在10个KEEL不平衡数据集(https://sci2s.ugr.es/keel/imbalanced.php)上进行实验,数据集信息如表3所示,其中不平衡比例为多数类样本数量比少数类样本数量。
KEEL不平衡数据集是由原始数据集转换后得到的二类别不平衡数据集,例如在vehicle3中,少数类是原vehicle数据集中的类别3,多数类则由剩余类别组成,例如在ecoli-0-6-7_vs_5中,少数类由类别0、6和7组成,多数类由类别5组成。本文使用的KEEL数据集均已用五折交叉验证方式划分为5个子数据集。
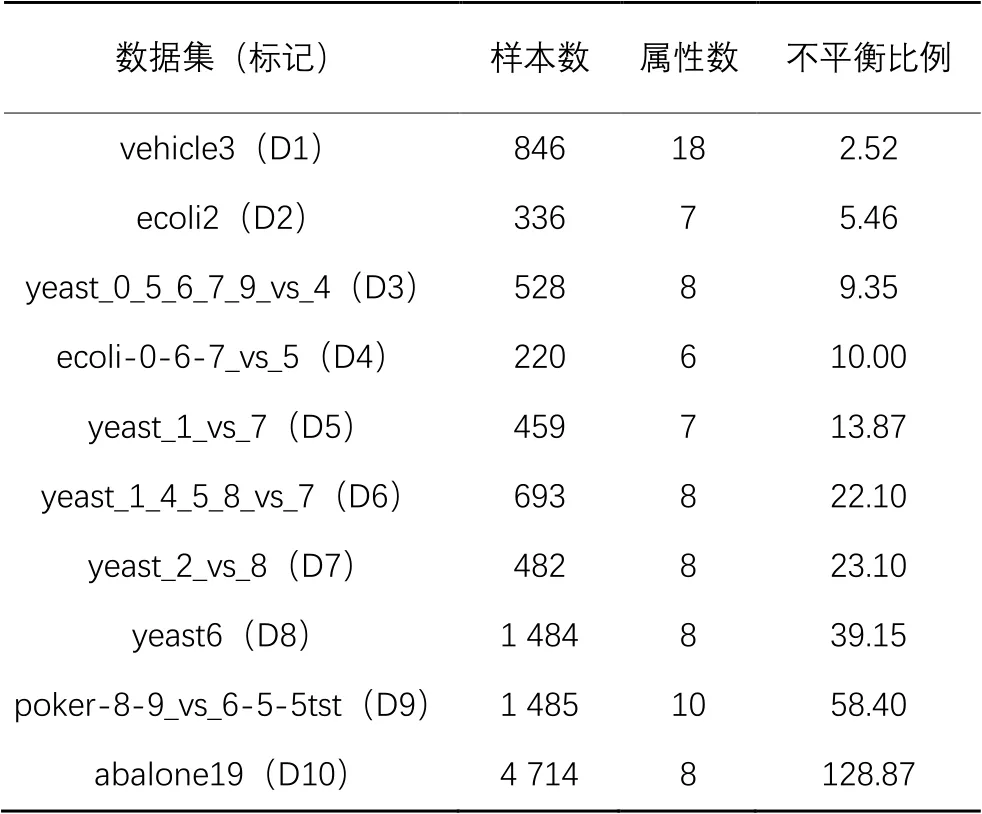
表3 实验数据集Tab. 3 Experimental datasets
本文选取AdaBoost、AdaCost、RUSBoost和USCBoost与DPBCPUSBoost进行对比实验。AdaBoost是经典的集成算法,可以用于不平衡数据分类;AdaCost在AdaBoost样本权重更新步骤中加入了代价调整函数;RUSBoost在AdaBoost训练分类器之前对多数类进行随机欠采样;USCBoost结合了随机欠采样方法和代价敏感学习方法;DPBCPUSBoost在USCBoost的基础上采用了新的误分代价计算方法和欠采样方法。将上述5个相关算法进行对比实验,能够验证DPBCPUSBoost的有效性。实验中各算法的迭代次数设置为10,DPBCPUSBoost的截断距离截取阈值设置为2,AdaCost和USCBoost采用相同的误分代价,其他均使用默认参数。
本文选取决策树桩(Decision Stump)作为弱分类器,Decision Stump是单层决策树,其结构简单,适合用作集成学习中的分类器。
3.2 评价指标
本文采用Accuracy、F1-Score、G-mean和AUC作为分类性能的评价指标。其中:F1-Score是精确率(Precision)和召回率(Recall)的调和均值;G-mean是召回率和特异度(Specificity)的几何均值;ROC曲线是以假正例率(False Positive Rate, FPR)为横坐标、真正例率(True Positive Rate, TPR)为纵坐标绘制出来的曲线,曲线下的面积(AUC)越大,说明分类器效果越好,ROC曲线不易受正负样本分布影响,能够比较客观地评价模型性能。
混淆矩阵是绘制ROC曲线的基础。在二分类混淆矩阵中:真正例(True Positive, TP)表示实际为正例的样本被预测为正例;假正例(False Positive, FP)表示实际类别为负例的样本被预测为正例;真负例(True Negative, TN)表示实际为负例的样本被预测为负例;假负例(False Negative, FN)表示实际类别为正例的样本被预测为负例。
Accuracy、F1-Score和G-mean等评价指标可通过混淆矩阵和以下计算式得出:
3.3 分类性能对比
为验证本文算法的有效性,对各算法的分类性能进行测试。表4为AdaBoost和AdaCost的测试结果,表5为RUSBoost、USCBoost和DPBCPUSBoost的测试结果,图4展示了各算法取得最高性能的数据集数量。

表4 AdaBoost和AdaCost的分类性能测试结果 单位:%Tab. 4 Classification performance test results of AdaBoost and AdaCost unit:%
由图4可知,AdaCost的性能总体上优于AdaBoost,因为其在样本权重调整过程中,提高了有更高误分代价样本的权重;USCBoost的性能总体上优于RUSBoost,因为其不仅结合了代价敏感学习,而且在欠采样过程中保留了较高权重的样本。
DPBCPUSBoost初次迭代利用样本抽样权重对多数类样本进行欠采样,RUSBoost和USCBoost初次迭代使用RUS对多数类进行欠采样。因此,为验证DPBCPUSBoost改进欠采样方法的有效性,对这3个算法初次迭代后的性能进行测试。表5为各个算法在不同数据集上初次迭代和10次迭代后的分类性能测试结果。
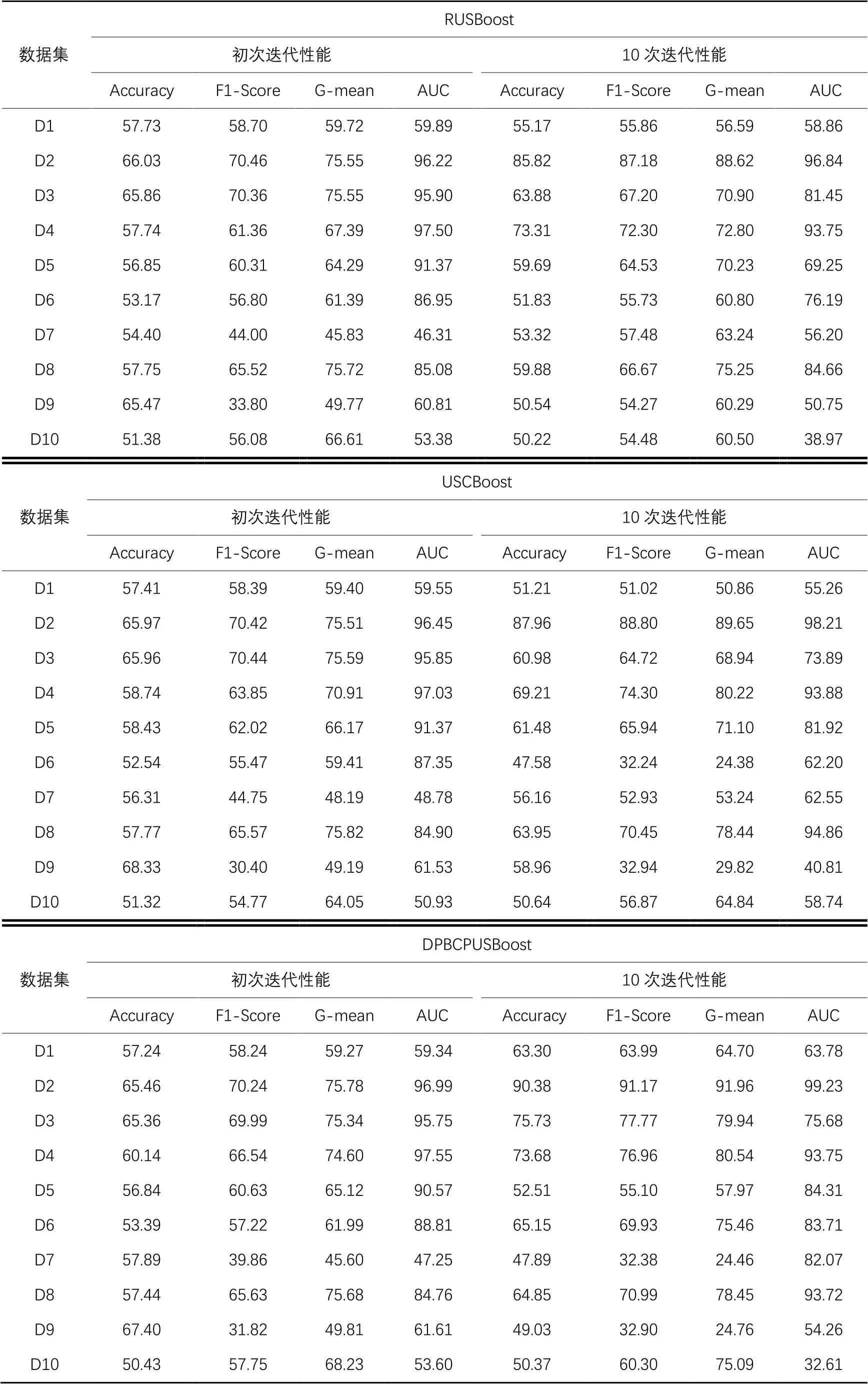
表5 RUSBoost、USCBoost和DPBCPUSBoost的分类性能测试结果 单位:%Tab. 5 Classification performance test results of RUSBoost, USCBoost and DPBCPUSBoost unit:%

图4 不同算法取得最高性能的数据集数量Fig. 4 Number of datasets of different algorithms with highest performance
由表5初次迭代后的性能对比实验结果可得出两个结论:
1)初次迭代后,DPBCPUSBoost在AUC、G-mean和F1-Score指标上获得最高性能的数据集数量分别为5个、5个和4个,均多于RUSBoost和USCBoost。
2)初次迭代后,DPBCPUSBoost在Accuracy指标上获得最高性能的数据集数量为3个,要少于RUSBoost,因为Accuracy指标易受多数类样本数量影响,例如在不平衡比较高的abalone19(D10)数据集上,RUSBoost在AUC、G-mean和F1-Score指标上的表现均要差于DPBCPUSBoost。
初次迭代后的分类性能测试结果表明:相较于随机欠采样方法,DPBCPUSBoost使用样本抽样权重进行欠采样具有一定的优势,这是因为DPBCPUSBoost尽量保留了决策边界区域内易误分的多数类样本,使得分类器更加关注这些区域内的样本,但是在一些类重叠度较高的数据集上,该方法可能会降低分类性能。
图4、表4~5中的实验结果表明,10次迭代后,DPBCPUSBoost在Accuracy、F1-Score、G-mean、AUC指标上获得最高性能的数据集数量分别为5个、7个、7个和5个,总体上分类性能优于其他4个对比算法,因为DPBCPUSBoost兼顾了类内、类间样本的分布情况,并利用密度峰值对不同样本定义了不同的误分代价。
3.4 运行时间对比
图5给出了本文提出的DPBCPUSBoost和对比的AdaBoost等4个算法在10个数据集上的50次平均运行时间的结果。
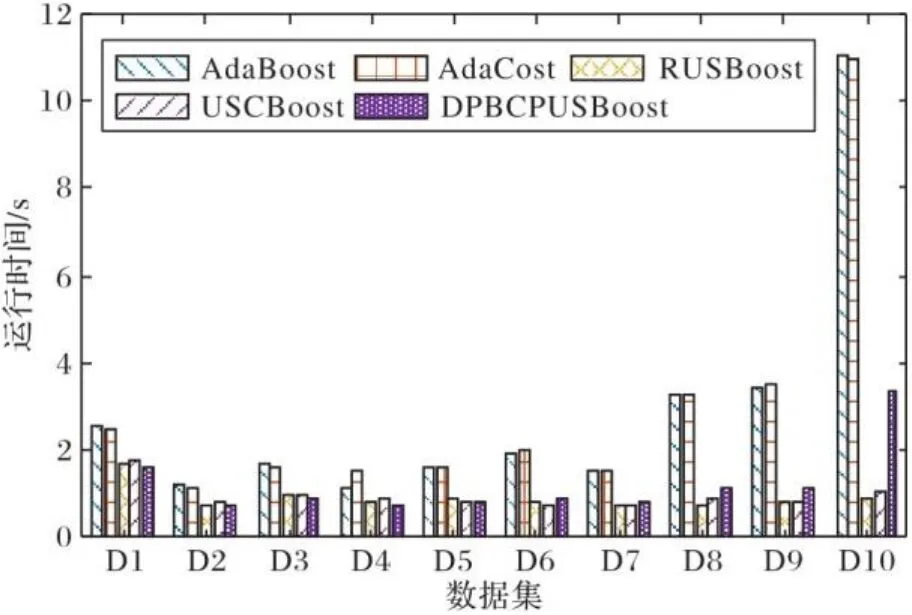
图5 不同算法在不同数据集上的运行时间Fig. 5 Running time for different algorithms on different datasets
由图5可知,AdaBoost和AdaCost的运行时间明显多于RUSBoost、USCBoost和DPBCPUSBoost,这是因为AdaBoost和AdaCost没有对多数类样本进行欠采样,训练集中存在更多的多数类样本,因此训练时间会更长。DPBCPUSBoost的运行时间要多于RUSBoost和USCBoost,这是因为密度峰值的计算消耗了较多时间,DPBCPUSBoost采用密度峰值定义代价和抽样权重的方式,以增加复杂度为代价提升了分类性能。
4 结语
本文针对不平衡数据分类问题提出了DPBCPUSBoost,该算法结合密度峰值信息使不同样本具有不同的误分代价,同时考虑了类间样本分布和类内样本分布情况。DPBCPUSBoost利用密度峰值定义抽样权重,并对多数类球簇中的“易误分区域”内样本的抽样权重进行调整,使决策边界区域附近的多数类样本获得更多关注。在多个不平衡数据集上的对比实验验证了DPBCPUSBoost的有效性。但是,对于密度不均匀的数据,密度峰值不能较好地反映数据潜在结构,进而影响了误分代价的计算。因此,设计能更精准反映数据潜在结构信息的误分代价是未来研究的主要方向。
[1] ZHOU X K, HU Y Y, LIANG W, et al. Variational LSTM enhanced anomaly detection for industrial big data [J]. IEEE Transactions on Industrial Informatics, 2021, 17(5): 3469-3477.
[2] 胡姣姣,王晓峰,张萌,等.基于深度学习的时间序列数据异常检测方法[J].信息与控制,2019,48(1):1-8.(HU J J, WANG X F,ZHANG M, et al. Time-series data anomaly detection method based on deep learning [J]. Information and Control, 2019, 48(1): 1-8.)
[3] 张跃飞,王敬飞,陈斌,等.基于改进的Mask R-CNN的公路裂缝检测算法[J].计算机应用,2020,40(S2):162-165.(ZHANG Y F, WANG J F, CHEN B, et al. Pavement crack detection algorithm based on improved Mask R-CNN [J]. Journal of Computer Applications, 2020, 40(S2): 162-165.)
[4] LIN P, YE K J, XU C Z. Dynamic network anomaly detection system by using deep learning techniques [C]// Proceedings of the 2019 International Conference on Cloud Computing, LNCS 11513. Cham: Springer, 2019: 161-176.
[5] 刘颖,杨轲.基于深度集成学习的类极度不均衡数据信用欺诈检测算法[J].计算机研究与发展,2021,58(3):539-547.(LIU Y, YANG K. Credit fraud detection for extremely imbalanced data based on ensembled deep learning [J]. Journal of Computer Research and Development, 2021, 58(3): 539-547.)
[6] ZHU H H, LIU G J, ZHOU M C, et al. Optimizing weighted extreme learning machines for imbalanced classification and application to credit card fraud detection [J]. Neurocomputing, 2020, 407: 50-62.
[7] LI Z C, HUANG M, LIU G J, et al. A hybrid method with dynamic weighted entropy for handling the problem of class imbalance with overlap in credit card fraud detection [J]. Expert Systems with Applications, 2021, 175: Article No.114750.
[8] 易东义,邓根强,董超雄,等.基于图卷积神经网络的医保欺诈检测算法[J].计算机应用,2020,40(5):1272-1277.(YI D Y, DENG G Q,DONG C X, et al. Medical insurance fraud detection algorithm based on graph convolutional neural network [J]. Journal of Computer Applications, 2020, 40(5): 1272-1277.)
[9] 刘枭,王晓国.基于密集子图的银行电信诈骗检测方法[J].计算机应用,2019,39(4):1214-1219.(LIU X, WANG X G. Dense subgraph based telecommunication fraud detection approach in bank [J]. Journal of Computer Applications, 2019, 39(4): 1214-1219.)
[10] LU C, LIN S F, LIU X L, et al. Telecom fraud identification based on ADASYN and random forest [C]// Proceedings of the 2020 5th International Conference on Computer and Communication Systems. Piscataway: IEEE, 2020: 447-452.
[11] 王伟,谢耀滨,尹青.针对不平衡数据的决策树改进方法[J].计算机应用,2019,39(3):623-628.(WANG W, XIE Y B, YIN Q. Decision tree improvement method for imbalanced data [J]. Journal of Computer Applications, 2019, 39(3): 623-628.)
[12] 徐玲玲,迟冬祥.面向不平衡数据集的机器学习分类策略[J].计算机工程与应用,2020,56(24):12-27.(XU L L, CHI D X. Machine learning classification strategy for imbalanced data sets [J]. Computer Engineering and Applications,2020, 56(24): 12-27.)
[13] 陈木生,卢晓勇.三种用于垃圾网页检测的随机欠采样集成分类器[J].计算机应用,2017,37(2):535-539,558.(CHEN M S, LU X Y. Three random under-sampling based ensemble classifiers for Web spam detection [J]. Journal of Computer Applications, 2017, 37(2): 535-539, 558.)
[14] 王俊红,闫家荣.基于欠采样和代价敏感的不平衡数据分类算法[J].计算机应用,2021,41(1):48-52.(WANG J H, YAN J R. Classification algorithm based on undersampling and cost-sensitiveness for unbalanced data [J]. Journal of Computer Applications, 2021, 41(1): 48-52.)
[15] KAYA E, KORKMAZ S, ŞAHMAN M A, et al. DEBOHID: a differential evolution based oversampling approach for highly imbalanced datasets [J]. Expert Systems with Applications, 2021, 169: Article No.114482.
[16] ENGELMANN J, LESSMANN S. Conditional Wasserstein GAN-based oversampling of tabular data for imbalanced learning [J]. Expert Systems with Applications, 2021, 174: Article No.114582.
[17] WANG X Y, XU J, ZENG T Y, et al. Local distribution-based adaptive minority oversampling for imbalanced data classification [J]. Neurocomputing,2021, 422: 200-213.
[18] GAO X, REN B, ZHANG H, et al. An ensemble imbalanced classification method based on model dynamic selection driven by data partition hybrid sampling [J]. Expert Systems with Applications, 2020, 160: Article No.113660.
[19] ZHU Y W, YAN Y T, ZHANG Y W, et al. EHSO: evolutionary hybrid sampling in overlapping scenarios for imbalanced learning [J]. Neurocomputing, 2020, 417: 333-346.
[20] FREUND Y, SCHAPIRE R E. Experiments with a new boosting algorithm [C]// Proceedings of the 13th International Conference on International Conference on Machine Learning. San Francisco: Morgan Kaufmann Publishers Inc., 1996:148-156.
[21] FAN W, STOLFO S J, ZHANG J X, et al. AdaCost: misclassification cost-sensitive boosting [C]// Proceedings of the 1999 16th International Conference on Machine Learning. San Francisco: Morgan Kaufmann Publishers Inc., 1999: 97-105.
[22] LIU X Y, WU J X, ZHOU Z H. Exploratory undersampling for class-imbalance learning [J]. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 2009, 39(2): 539-550.
[23] SEIFFERT C, KHOSHGOFTAAR T M, VAN HULSE J, et al. RUSBoost: a hybrid approach to alleviating class imbalance [J]. IEEE Transactions on Systems, Man, and Cybernetics — Part A: Systems and Humans, 2010, 40(1): 185-197.
[24] 万建武,杨明.代价敏感学习方法综述[J].软件学报,2020,31(1):113-136.(WAN J W, YANG M. Survey on cost-sensitive learning method [J]. Journal of Software, 2020, 31(1): 113-136.)
[25] RODRIGUEZ A, LAIO A. Clustering by fast search and find of density peaks [J]. Science, 2014, 344(6191): 1492-1496.
[26] XIA S Y, PENG D W, MENG D Y, et al. Ballk-means: fast adaptive clustering with no bounds [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(1): 87-99.
[27] HART P. The condensed nearest neighbor rule (corresp.) [J]. IEEE Transactions on Information Theory,1968, 14(3): 515-516.
Imbalanced data classification algorithm based on ball cluster partitioning and undersampling with density peak optimization
LIU Xuewen1, WANG Jikui1*, YANG Zhengguo1, LI Qiang1,2, YI Jihai1, LI Bing1, NIE Feiping3
(1.School of Information Engineering,Lanzhou University of Finance and Economics,Lanzhou Gansu730020,China;2.Key Laboratory of E‑Business Technology and Application of Gansu Province(Lanzhou University of Finance and Economics),Lanzhou Gansu730020,China;3.Center for OPTical IMagery Analysis and Learning(OPTIMAL),Northwestern Polytechnical University,Xi’an Shaanxi710072,China)
It is an effective hybrid strategy for imbalanced data classification of integrating cost-sensitivity and resampling methods into the ensemble algorithms. Concerning the problem that the misclassification cost calculation and undersampling process less consider the intra-class and inter-class distributions of samples in the existing hybrid methods, an imbalanced data classification algorithm based on ball cluster partitioning and undersampling with density peak optimization was proposed, named Boosting algorithm based on Ball Cluster Partitioning and UnderSampling with Density Peak optimization (DPBCPUSBoost). Firstly, the density peak information was used to define the sampling weights of majority samples, and the majority ball cluster with “neighbor cluster” was divided into “area misclassified easily” and “area misclassified hardly”,then the sampling weight of samples in “area misclassified easily” was increased. Secondly, the majority samples were undersampled based on the sampling weights in the first iteration, then the majority samples were undersampled based on the sample distribution weight in every iteration. And the weak classifier was trained on the temporary training set combining the undersampled majority samples with all minority samples. Finally, the density peak information of samples was combined with the categorical distribution of samples to define the different misclassification costs for all samples,and the weights of samples with higher misclassification cost were increased by the cost adjustment function. Experimental results on 10 KEEL datasets indicate that, the number of datasets with the highest performance achieved by DPBCPUSBoost is more than that of the imbalanced data classification algorithms such as Adaptive Boosting (AdaBoost), Cost-sensitive AdaBoost (AdaCost), Random UnderSampling Boosting (RUSBoost) and UnderSampling and Cost-sensitive Boosting (USCBoost), in terms of evaluation metrics such as Accuracy, F1-Score,Geometric Mean (G-mean) and Area Under Curve (AUC) of Receiver Operating Characteristic (ROC). Experimental results verify that the definition of sample misclassification cost and sampling weight of the proposed DPBCPUSBoost is effective.
imbalanced data classification; density peak; ball clustering; cost-sensitive; undersampling
TP181
A
1001-9081(2022)05-1455-09
10.11772/j.issn.1001-9081.2021050736
2021⁃05⁃10;
2021⁃09⁃19;
2021⁃10⁃14。
国家自然科学基金资助项目(61772427);甘肃省高等学校创新能力提升资助项目(2021B‑145,2021B‑147);甘肃省自然科学基金资助项目(17JR5RA177);甘肃省重点研发计划项目(21YF5FA087)。
刘学文(1996—),男,江西赣州人,硕士研究生,主要研究方向:机器学习、人工智能; 王继奎(1978—),男,山东滕州人,副教授,博士,CCF会员,主要研究方向:机器学习、人工智能; 杨正国(1987—),男,甘肃积石山人,副教授,博士,CCF会员,主要研究方向:机器学习、人工智能; 李强(1973—),男,甘肃兰州人,教授,硕士,CCF会员,主要研究方向:机器学习、人工智能; 易纪海(1974—),男,黑龙江伊春人,讲师,硕士,主要研究方向:机器学习、人工智能; 李冰(1997—),女,山西运城人,硕士研究生,主要研究方向:机器学习、人工智能; 聂飞平(1977—),男,江西吉安人,教授,博士生导师,博士,CCF会员,主要研究方向:机器学习、人工智能。
This work is partially supported by National Natural Science Foundation of China (61772427),Gansu Provincial Institutions of Higher Learning Innovation Ability Promotion Program (2021B-145, 2021B-147), Natural Science Foundation of Gansu Province (17JR5RA177), Key Research and Development Program of Gansu Province (21YF5FA087).
LIU Xuewen, born in 1996, M. S. candidate. His research interests include machine learning,artificial intelligence.
WANG Jikui, born in 1978, Ph. D., associate professor. His research interests include machine learning, artificial intelligence.
YANG Zhengguo, born in 1987, Ph. D., associate professor. His research interests include machine learning, artificial intelligence.
LI Qiang, born in 1973, M. S., professor. His research interests include machine learning, artificial intelligence.
YI Jihai, born in 1974, M. S., lecturer. His research interests include machine learning, artificial intelligence.
LI Bing, born in 1997, M. S. candidate. Her research interests include machine learning, artificial intelligence.
NIE Feiping, born in 1977, Ph. D., professor. His research interests include machine learning, artificial intelligence.
猜你喜欢
中国畜牧杂志(2022年10期)2022-10-12
计算机仿真(2022年7期)2022-08-22
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
语文世界(初中版)(2018年10期)2018-11-06
语文世界(初中版)(2017年5期)2017-06-22
软件导刊(2017年4期)2017-06-20
作文与考试·初中版(2017年12期)2017-04-19
价值工程(2017年11期)2017-04-18
作文大王·中高年级(2008年12期)2008-12-19
