
基于交叉层级数据共享的多任务模型
2022-06-21 06:45陈颖于炯陈嘉颖杜旭升
计算机应用 2022年5期
陈颖,于炯,*,陈嘉颖,杜旭升
(1.新疆大学 软件学院,乌鲁木齐 830091; 2.新疆大学 信息科学与工程学院,乌鲁木齐 830046)(∗通信作者电子邮箱yujiong@xju.edu.cn)
基于交叉层级数据共享的多任务模型
陈颖1,于炯1,2*,陈嘉颖2,杜旭升2
(1.新疆大学 软件学院,乌鲁木齐 830091; 2.新疆大学 信息科学与工程学院,乌鲁木齐 830046)(∗通信作者电子邮箱yujiong@xju.edu.cn)
针对多任务学习模型中相关度低的任务之间存在的负迁移现象和信息共享困难问题,提出了一种基于交叉层级数据共享的多任务模型。该模型关注细粒度的知识共享,且能保留浅层共享专家的记忆能力和深层特定任务专家的泛化能力。首先,统一多层级共享专家,以获取复杂相关任务间的公共知识;然后,将共享信息分别迁移到不同层级的特定任务专家之中,从而在上下层之间共享部分公共知识;最后,利用基于数据样本的门控网络自主选择不同任务所需信息,从而减轻样本依赖性对模型的不利影响。相较于多门控混合专家(MMOE)模型,所提模型在UCI census-income数据集上对两个任务的F1值分别提高了7.87个百分点和1.19个百分点;且在MovieLens数据集上的回归任务的均方误差(MSE)值降低到0.004 7,分类任务的AUC值提高到0.642。实验结果表明,所提出的模型适用于改善负迁移现象的影响,且能更高效地学习复杂相关任务之间的公共信息。
多任务学习;信息共享;负迁移;神经网络;迁移学习
0 引言
多任务学习在一个模型之中同时学习多个不同任务,能通过任务之间的信息迁移有效提升模型学习效率[1],目前已广泛应用于自然语言处理、机器翻译、计算机视觉等领域[2-6]。通过对模型进行正则化或改进任务之间的迁移学习以提升模型预测能力仍是现有多任务学习研究的主流方向。然而,由于现实世界中的多任务之间关系复杂甚至相互冲突,这将导致模型性能显著下降,即负迁移现象,同时,Tang等[7]提出的seesaw现象也是多任务模型面临的一个难点,众多模型[1,8-10]性能均受该现象影响。为改善负迁移现象,研究者们就如何更有利地学习任务之间的公共信息做了大量工作,如:Cross-stitch网络[9]、Sluice网络[10]等提出了学习静态线性联合来融合不同任务高维表征,但却未考虑样本独立性对相应任务的影响;多门控混合专家(Multi-gate Mixture-Of-Experts, MMOE)模型[8]基于输入样本联合底层专家,为每个任务设置了一个门控网络,使样本的线性转换作为门控网络选择底层专家的权重,从而使每个任务均依赖于相应样本空间,但该模型忽略了专家之间的差异性和交互性,即对每个专家一视同仁,不同任务使用相同的专家输出,这将受到seesaw现象的影响;PLE(Progressive Layered Extraction)模型[7]既考虑了样本独立性,也对共享专家和特定任务专家进行了分离,从而有效提升了模型的预测能力,减轻了负迁移和seesaw现象的影响,但对于共享专家而言,深层次知识抽取会提升其泛化能力从而给共享知识加入噪声,背离其提取底层表征中公共知识的初衷,且特定任务专家学习共享知识只能通过门控网络,公共知识的重要度仅依赖于输入样本,因此,特定任务专家无法深入学习共享信息。
针对上述问题,本文提出了能在不同层级专家内部进行迁移学习的交叉层级数据共享多任务(Cross-Layer Shared multi-task, CLS)模型。该模型利用特定的门控网络建模任务对样本空间的依赖性;同时,分离特定任务专家和共享专家,不同任务除使用相同的共享专家外,亦有独立的特定任务专家学习特定信息;最后,统一多层级共享专家,将共享专家学习到的先验知识以特定的路由方式传输给不同任务的不同层级的专家,使不同层级的专家使用部分共享专家内部相同层级的输出,既准确记忆公共知识,亦使任务不绝对依赖门控网络,从而深入学习共享信息。在两个真实公开数据集以及一个合成数据集上的实验结果表明,CLS模型的性能优于基线多任务模型,验证了其有效性和可行性。
本文的主要工作如下:1)利用先验知识捕获任务之间的公共信息,并将信息迁移到不同的特定任务专家之中,提出了层级共享路由机制;2)保留浅层共享专家的记忆能力和深层特定任务专家的泛化能力,统一多个层级的共享专家,提出了交叉层级共享网络;3)引入门控单元,联合交叉层级共享网络,提出了可挖掘深层语义信息的CLS模型。
1 相关工作
深度学习背景下,多任务模型通常使用隐藏层的硬参共享或软参共享来学习任务之间的关系,其中,最基本的模型是硬参共享模型[1]。
硬参共享模型是最常用的多任务学习方法,其在所有任务中使用相同的隐藏层,并同时对特定任务保留不同的输出层。硬参共享模型显著降低了过拟合的风险,当需要学习的任务越多,模型就越需要找到一个能捕获所有任务信息的表示,在原始任务上出现过拟合的可能性就越小;但在任务之间相互冲突时,该模型容易受到负迁移带来的不利影响。针对该问题,Cross-stitch网络[8]、Sluice网络[9]等提出了学习线性组合的权值,从而使任务有选择性地融合其余任务的信息;然而这些模型中不同任务的高维表征用相同的静态线性权重联合会出现seesaw现象。
软参共享模型中,每个任务均有其自身的模型以及参数,通过对模型参数之间的距离进行正则化使参数尽可能相似[11],或利用门控网络和注意力网络来做信息融合以提高预测精度。Jacobs等[12]最早提出了将门控网络应用于联合底层专家的模型,但没有考虑任务之间样本的区别;因此文献[8]中针对每个任务设置一个门控网络,明确地从数据中建模任务关系以优化每个任务;Ma等[13]利用AutoML(Automated Machine Learning)技术提出了一种新的子网路由框架,通过二进制随机变量来控制子网之间的连接,并使用神经架构搜索[14]来探索最优结构,以在保持多任务模型计算性能的同时实现更加灵活的参数共享。在此基础上,多层级的多任务模型被提出,用于挖掘高维数据深层语义信息,如ML-MMOE(Multi-Layer MMOE)、PLE等。
此外,一些具备更高效共享学习机制的其他多任务模型也被研究者研究[15-17],如:Hadash等[18]提出了一个同时学习排序任务和评级任务参数的多任务框架,通过共享底层表示改进了文献[1]中的文本推荐任务;Akhtar等[19]利用多任务框架和任务之间的相关性,将多任务模型应用于推荐系统以分析用户的多种情感,从而提升多任务学习性能;Zhao等[20]为能捕捉任务之间的差异、有效优化多个目标,引入了基于输入样本的门控网络[8],但该门控网络无差别地对待所有专家,只通过控制门控网络的权重参数优化不同目标,很难解决复杂相关任务之间的信息共享[11]。CLS模型准确分离共享专家和特定任务专家,对于相关度复杂的任务,不绝对依赖于专家顶端的门控网络与共享专家进行交流,共享信息在专家内部即能进行学习,从而更细粒度、简单且高效地学习公共知识,有效减轻负迁移现象。
2 交叉层级共享多任务模型
交叉层级共享网络的核心思想是在每个专家的内部均对公共知识进行学习,不同层级专家学习部分相同的共享信息。前者将共享专家学习到的公共信息以层级共享路由方式映射到不同层级的特定任务专家之中,不同层级的特定任务专家即可更深入地学习共享信息,从而更有利于信息共享和信息交流;后者可保留浅层共享专家的记忆能力,亦可维持特定任务专家的泛化能力。然后,使用了一个高效的门控网络,该门控网络能够自主学习选择怎样的共享信息来提高模型性能。最后,结合交叉层级共享网络和高效的门控网络,提出了交叉层级数据共享多任务模型。
2.1 交叉层级共享路由机制
对于复杂且相互竞争的任务,仅利用门控网络学习共享专家公共知识,可能会导致特定任务专家受到不必要的参数干扰。利用共享专家和特定任务专家之间知识的层级共享,可以更加细粒度地学习共享信息,任务相关度高时,能更准确地学习不同任务之间的公共信息;任务相关度低时,公共知识也能作为特定任务专家每层的输入数据来进行学习,对于不需要共享的冲突信息,特定任务专家学习过程中只需给予其更低的重要度,即可降低干扰信息的影响,不再增加额外计算成本。这样既能充分利用共享专家学习到的不同任务间的共享信息,更是弱化了门控网络的作用,减轻了共享信息仅能通过门控网络选择而导致的依赖性。
在交叉层级共享网络中,所有专家使用相同的底层输入表征,在输入表征之上分离建模特定任务专家组件和共享专家组件,特定任务知识和公共知识在不同专家内部通过训练自动学习,无需人为区分。以两个任务的情况为例,如图1所示,输入层之上,分为TaskA、TaskB的特定任务专家组件,其中间灰色标志组件为共享专家。TaskA中,每两个层级的特定任务专家共享一个层级的共享专家,如ExpertA1、ExpertA2两者共用一个共享专家中的输出数据,共享专家的层数由特定任务专家的层数决定。共享专家中所有会在不同层级的特定任务专家中重复使用的数据已在图1中用虚线箭头标出。对于ExpertA1、ExpertA2,其输入层均不使用共享专家中的输出数据,ExpertA1的Layer2和ExpertA2的Layer4使用专有的共享专家输出数据。因此,对于具有K个任务的交叉层级共享网络,第k个任务的输出为:
其中:wk为第k()个任务输出层的可训练参数;x为输入表示;Ck(x)是由前层神经网络和共享专家最后一层神经网络的输出组成的向量。

图1 交叉层级共享网络Fig. 1 Cross-layer shared network
共享专家的神经网络层数由特定任务专家决定,两者层数相等。例如,当一个网络具有两层专家,每个专家具有三层神经网络时,共享专家神经网络的层数同为三层,所以,第一层特定任务专家的输入依次为:(x,concat(Ek(1,1),),,其中,Ek(i,j)表示第k个任务第i层专家的第j层神经网络的输出,表示共享专家第l层神经网络的输出,此处默认mk和ms的值为1。同理可得,第二层特定任务专家的输入依次为:(),concat(Ek(2,1),),concat(Ek(2,2),)),而对于每一层特定任务专家的输入,其为前一层特定任务专家的输出与相应共享专家的输出。
在此,定义不同层级专家的共享率p为:
其中:Q表示共享专家的神经网络层数;q表示用于层级共享的隐藏层层数。p表示:在共享专家所有层的输出数据中,为同一任务不同层级专家共享的数据所占总数据的比例。当特定任务专家只有单层神经网络时,共享专家的输出数据不传给任何一个特定任务专家,此时模型退化为单任务模型,共享率为0;当其具有两层神经网络时,同一任务的每层特定任务专家具有不同的共享专家输出数据,共享率为0,由此往后,层数增加,共享率增加。
交叉层级共享网络采取共享专家和特定任务专家分离的方法,使得不同类型的专家能够专注地学习所需要学习的知识,即:共享专家专注学习不同任务之间的公共知识,特定任务专家分别学习不同任务所需信息,消除共享知识和特定任务知识之间的参数冲突带来的不利影响。这意味着,每个任务都会影响共享专家的参数取值,以及时调整共享专家内部公共特征学习的权重,而特定任务专家的参数取值只受到相应任务的影响。采用交叉层级共享方法后,特定任务专家内部每一层神经网络都可以学习到部分公共知识,从而能更加细粒度地学习松散相关任务间的公共知识,且无需付出高昂的计算代价,对相互冲突的任务也不会引入更多的无关信息。此外,还联合了不同层级专家之间的信息共享,保留浅层神经网络的记忆能力,充分利用共享信息,缓解参数爆炸和共享信息抽象化、复杂化给模型性能带来的不利影响。
2.2 门控网络
考虑到不同任务对输入数据样本空间的依赖性,在每层专家的输出层后加了一个定制共享门控网络[7],网络结构如图2所示。
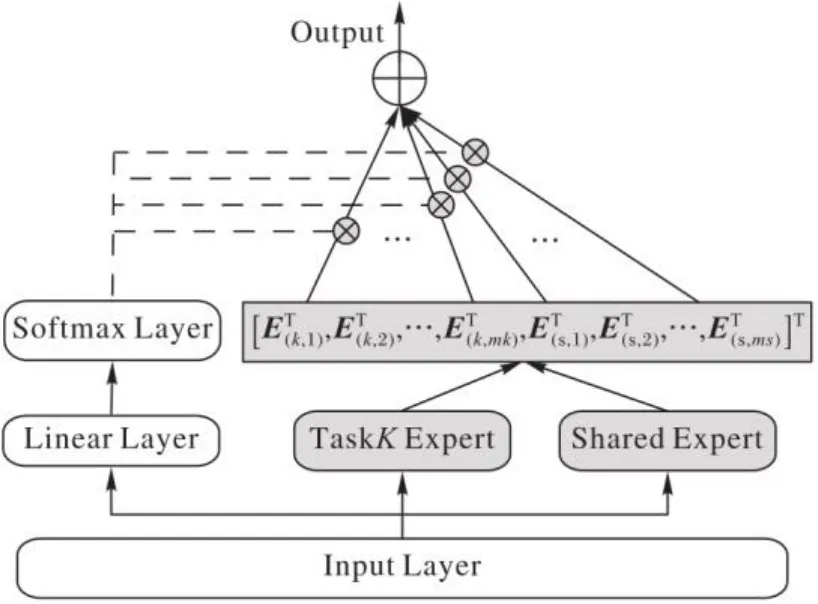
图2 门控网络模型Fig. 2 Gated network model
不同于MMOE简单地使用输入数据的线性转换来建模不同专家的权重,该门控网络通过对输入层数据的加权来控制不同专家的重要度,能灵活选择共享专家传递的共享信息。在该门控网络中,输入层的数据经过单层前馈神经网络和softmax激活函数后,作为门控网络选择矩阵的权重,从而灵活地学习需要的共享知识,第k个任务的门控网络的输出为:
其中:E(k,mk)表示第k个任务的第mk个子网的输出;表示共享专家中第ms个子网的输出。
最终,第k个任务Tower层的输出为:
其中tk表示任务k的Tower层。
门控网络作用于每个特定任务专家的顶层,灵活选择特定任务专家的输出信息和共享专家的输出信息。任务之间的相关度较高时,门控网络会给予共享专家输出信息更高的权重。当任务相关度较低时,门控网络便会选择性地将共享信息重要度降低,从而使特定任务专家能够专注地学习所需知识,不会因为接收到的无关信息降低模型性能。
2.3 CLS模型
简单的交叉层级共享网络无法更深层次地抽取输入表征中高阶的语义信息,为解决该问题,设计了一个CLS模型。在该模型中,所有专家被分为特定任务专家和共享专家,门控网络被应用于每个任务每个专家的顶层。如图3所示,每个任务的共享专家和特定任务专家均由多个子网组成,并在专家内部所有子网的不同层级之间实现信息共享,除每个专家的顶层门控网络与子网内部层级共享策略不同以外,所有特定任务专家与共享专家之间的信息共享策略均相同。
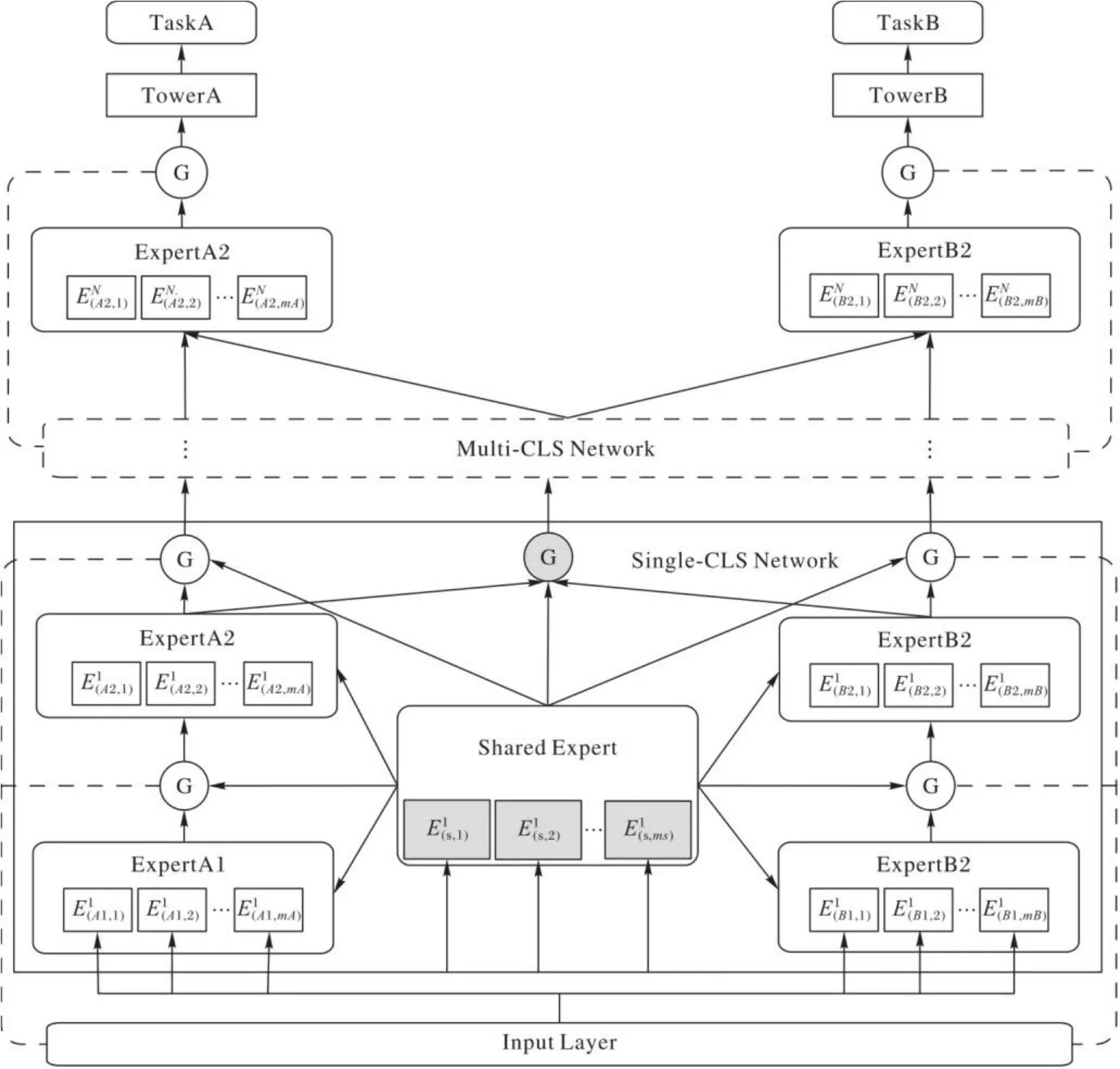
图3 多层级CLS模型Fig. 3 Multi-layer CLS model
CLS模型中特定任务专家与共享专家的数据联合方法同交叉层级共享网络相同,每个专家顶层的门控网络共享策略已经在2.2节提到。因此,在交叉层级多任务模型中,第k个任务第n()层的输出为:
其中:wk,n为第k个任务第n层交叉层级网络以为输入的可训练参数;为前一层交叉层级网络的输出;为第k个任务第n层的选择矩阵,需要注意的是,共享专家的选择矩阵与特定任务专家的选择矩阵不同,其为所有任务的输出向量和共享专家的输出向量组合而成,组合方式同式(6)相同,不再赘述。
因此,模型中任务k的最终输出为:
CLS模型通过共享专家与特定任务专家内部的信息交流,使得不同层级之间的专家也能对相同的共享信息进行学习。将不同任务之间的信息交互分布于每个专家内部,能更加高效地学习共享信息,减轻任务之间复杂相关度对特定任务专家知识学习的影响。
3 实验与结果分析
CLS模型主要关注更加高效的知识共享,为了验证其性能,将CLS模型在合成数据集、UCI census-income数据集和MovieLens数据集上和基线模型进行对比。由于现实世界中多任务模型常应用于不同任务类型的场景中,如两个任务分别为分类任务和回归任务,因此还在不同任务类型上对模型进行了实验。此外,还分析了门控网络对于模型性能的影响以及CLS模型在不同任务相关度上的表现,进一步验证了CLS模型在共享知识学习和改善负迁移现象上的有效性。
3.1 合成数据集上的实验
3.1.1 数据集
Synthetic Data是基于控制任务相关度而从系统中生成的数据[8],在本文实验中,依照文献[8]中原有的数据生成规则,使αi和βi服从N(0,0.01)的正态分布,设置。同时,如表1所示,共包含两部分合成数据,在验证模型性能时,共生成120万条数据样本,其中100万条为训练数据,10万条为验证数据,其余数据为测试数据。
在验证任务相关度对模型性能的影响时,共使用了12万条数据,任务相关度分别设置为[0.2,0.5,0.8,1],训练集、验证集、测试集的数据分配策略同上。
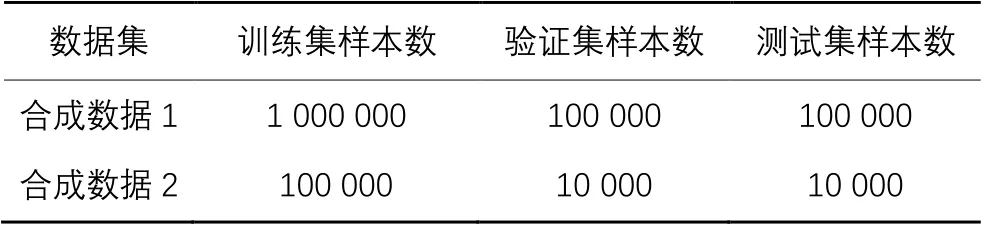
表1 实验中使用的合成数据集Tab. 1 Synthetic datasets used in experiments
3.1.2 对比模型
将本文提出的交叉层级数据共享多任务(CLS)模型与以下模型进行对比:
1)Shared-bottom模型[1]。该共享底层模型是广泛应用于多任务模型中的方法,其基本理念是使不同的任务共享一个知识抽取网络,仅tower层输出相分离。
2)MMOE模型[8]。该模型提出对每个任务使用基于输入样本的门控单元控制每个专家的重要度,从而使不同的任务在同一个专家上具备一定的选择能力。
3.1.3 实验步骤
合成数据集上一共进行了两个实验:
1)第一个实验的目的是为了评估在大规模数据集上模型的性能,因此依照合成数据的生成方式[8],共生成了120万条数据。实验过程中,为保证公平性,使共享底层模型设置为一个三层[256,128,64]的多层感知机(Multi-Layer Perceptron, MLP)网络;MMOE的神经元个数及专家个数的参数设置依照原文献中的实验结果,分别为16和8;CLS模型中需要调整的参数为每个专家神经元个数,在保证模型不过拟合或欠拟合的情况下进行参数调整,最终一共设置两层专家,共享率为2/3,每个专家为两层的神经网络,每层网络及门控网络神经元个数均为16。同时,保证共享底层模型、MMOE、CLS的模型参数依次减少,其中CLS模型的参数个数少于任何一个对比模型。对于每个模型,其任务相关度(即皮尔逊相关系数)为0.6,所有模型初始学习率为0.000 01,迭代次数为300。
2)第二个实验的目的是验证不同任务相关度对模型性能的影响。此实验中,对MMOE和CLS模型进行了对比实验,任务相关度依次控制为[0.2,0.5,0.8,1]。针对每个任务相关度生成了12万条数据,其中MMOE中设置8个专家,每个专家4个神经元,CLS模型具有两层专家,每个专家均为两层神经网络,每层8个神经元。模型用Adam优化器进行训练,学习率从[0.000 1,0.001,0.01]中进行网格搜索。CLS的模型参数少于MMOE的模型参数,迭代次数为300。
在第一个实验中,统计了随着迭代次数的增加,各模型在大规模数据上均方误差(Mean Square Error, MSE)值的变化。在第二个实验中,同样用MSE值来衡量不同任务相关度对不同模型性能的影响。
3.1.4 结果分析
在合成数据1上的实验结果如图4所示。从图4可以看出,所有任务中共享底层模型的表现较不理想。随着迭代次数的增加,所提模型的MSE值均低于MMOE模型,保持良好的效果,而且MSE值的波动较为平稳,模型性能较为稳定。这表明,相较于MMOE和共享底层模型,CLS模型中的交叉层级数据共享并未给特定任务专家引入过多噪声,在大规模数据上具有较好的表现,具备处理超大规模数据的能力。
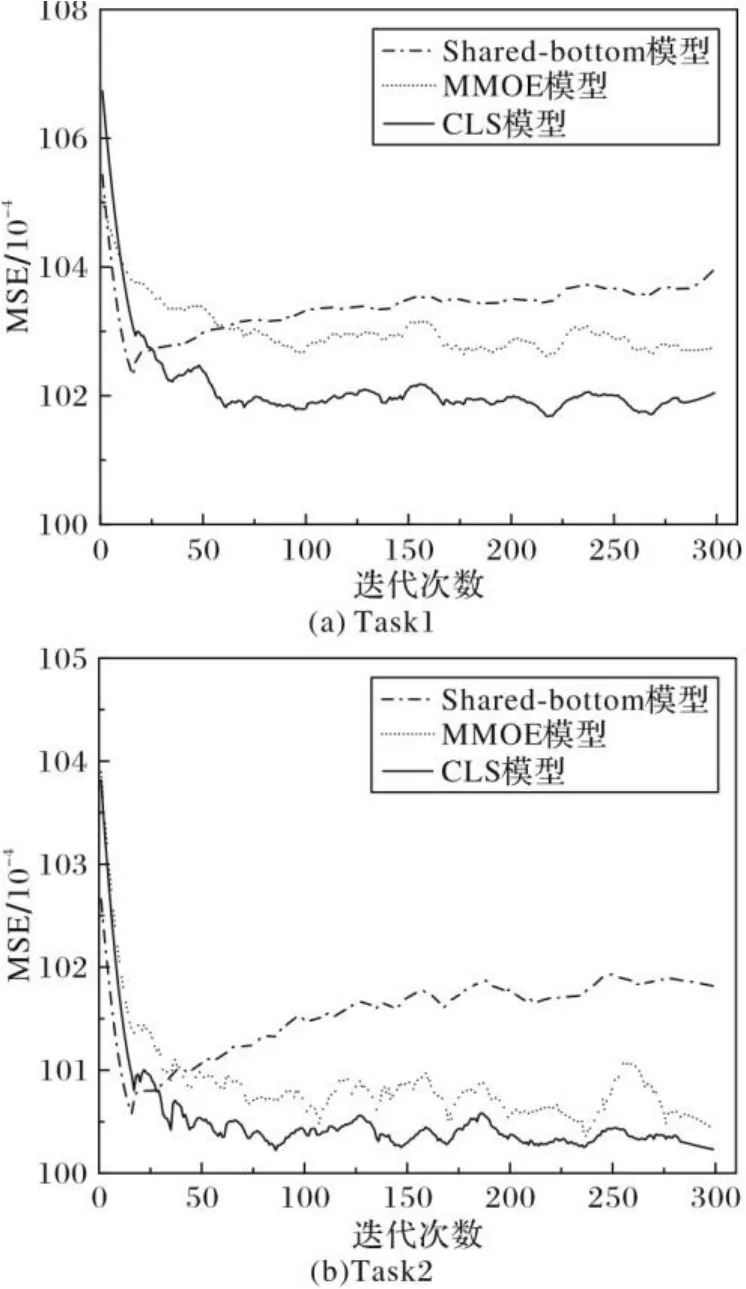
图4 三种模型的MSE比较Fig. 4 MSE comparison of three models
关于任务相关度对模型性能的影响如图5所示。在这个实验中,比较了MMOE模型和CLS模型在不同任务相关度上的表现,可以看出:
1)任务相关度较低时,MMOE模型表现不佳;而对于所提出的模型,任务相关度对模型性能的影响不明显。这表明,即使在相关度低的任务上,因为对共享信息的充分学习,所提模型的性能未受影响,不同任务之间相互冲突的信息亦并未造成负迁移现象。
2)在不同相关度、不同任务上,所提出模型的表现均优于MMOE。即使具备更少的可训练参数,所提出CLS模型的性能均超过具备更多可训练参数的MMOE模型。

图5 不同模型在不同相关度上的性能比较Fig. 5 Performance comparison of different models with different correlations
3.2 真实数据集上的实验
3.2.1 数据集
UCI census-income数据集:该数据集是从1994年美国人口普查数据库中抽取得到,包含299 285个成年人的统计数据实例,共计40个特征。为了验证多任务模型的效果,将其两个任务标签分别设置为Income和Marital status,前者预测其年收入是否大于$50 000,后者预测其婚姻状况,两个任务均为分类问题,其相关度为0.176 8[8]。
MovieLens数据集:该数据集是推荐系统领域广泛使用的数据集,包含943个用户对1 682部电影的100 000条评分(1~5分),其中每个用户对不同电影的评分数据不少于20条。在此数据集中,训练集和测试集数据的比例为7∶3;将对用户的年龄预测视为回归任务,用户对电影的评分预测视为分类任务,即当评分大于3时,表示用户喜欢这部电影,否则为不喜欢该电影,其任务相关度约为0.055。表2给出了两个数据集在实验中的数据分布细节。
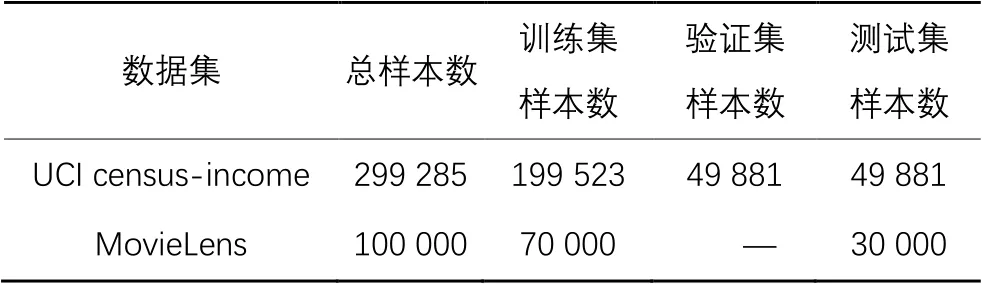
表2 实验中使用的真实数据集Tab. 2 Real datasets used in experiments
3.2.2 对比模型
Single-task[21]:使用两个分离的MLP网络来分别预测不同任务,该模型中两个任务具有相同的输入数据。
Cross-stitch模型[9]:该模型使用两个交叉共享单元学习两个任务之间的公共知识,一个系数矩阵来学习不同任务隐藏层的输出,通过自动调整系数矩阵中参数的值控制不同任务之间的共享知识学习。
PLE模型[7]:该模型分离特定任务专家和共享专家,并使用门控网络选择性地学习共享专家和特定任务专家的知识。
CLS-0:本文提出的交叉层级共享网络,为了验证交叉层级共享网络的作用,在此网络中使用的门控单元与MMOE中相同,其余数据共享和输出与2.1节提到的相同。
此外,对比模型还包括共享底层模型、MMOE模型以及本文提到的CLS模型。
3.2.3 实验步骤
在两个真实数据集上进行了对比实验,第一个为UCI census-income数据集,在这个数据集上,对比了单任务模型、共享底层模型、Cross-stitch模型以及MMOE模型。为验证交叉层级共享网络的作用,同时比较了CLS-0和CLS的模型性能。本文实验中,对比模型的参数均参照原文献中针对相应数据集得出的最佳结果,CLS-0和CLS中需要调整的参数包括神经元个数。根据文献[7-8]中所用对比模型在该数据集上的参数设置,单任务模型和共享底层模型均为一个三层的MLP网络,其神经元个数依次为[32,16,8],Cross-stitch模型、CLS-0和CLS的神经元个数为32,MMOE设置8个专家,每个专家4个神经元,PLE模型依照原文献设置两层专家网络,每个专家为单层神经网络,包含16个神经元。所有模型初始学习率为0.001,迭代次数为400。
第二个数据集为MovieLens数据集,在这个数据集上对比了共享底层模型、Cross-stitch模型、MMOE模型以及PLE模型和本文提出的CLS-0、CLS模型。共享底层模型为[128,64,32]的三层神经网络,MMOE、PLE和Cross-stitch模型的参数设置同上不变,CLS和CLS-0模型神经元个数设置为16,所有模型中,初始学习率为0.000 1,迭代次数为400。
在以上两个数据集的实验中,第一个实验使用了AUC(Area Under Curve)、F1-score、ACC(ACCuracy)指标来衡量分类任务模型性能;第二个实验,由于两个任务类型的不同,分别使用MSE和AUC来衡量不同模型在两个任务上的表现。此外,还定义了一个新的评价指标——多任务模型综合值(Multi-task model Comprehensive Value, MCV),来衡量多任务模型在不同任务上的综合表现。给定一个多任务模型,该模型每个任务的指标值为,其MCV定义为:在同一样本中,具备相同任务的任意多任务模型的每个任务指标值的综合之和,MCV值越大,表示模型性能越佳。
3.2.4 结果分析
在UCI census-income数据集上各模型性能的表现如表3所示,用加粗字体标注出了所提模型在两个任务(Task1-Income、Task2-Marital)上的AUC值、F1-score、ACC值以及每个指标的MCV,同时比较了CLS-0和各对比模型之间的性能差异,可以看出:
1)CLS-0模型的共享策略使得模型性能相较于所有基线模型有显著的提升,进一步验证了CLS-0模型的交叉共享机制能够更深入地学习不同任务间复杂相关的共享信息。
2)加入的门控网络使得CLS模型在所有模型中表现最佳,相较于MMOE模型,对两个任务的F1值分别提高了7.87个百分点和1.19个百分点,表明了基于任务样本空间的门控网络有助于提升模型性能。
3)CLS-0模型的MCV-F1值相较于MMOE模型提升了7.63个百分点,在对专家内部的知识共享进行建模并考虑浅层共享专家的记忆能力后,模型性能在预测结果的F1值上有所提升。
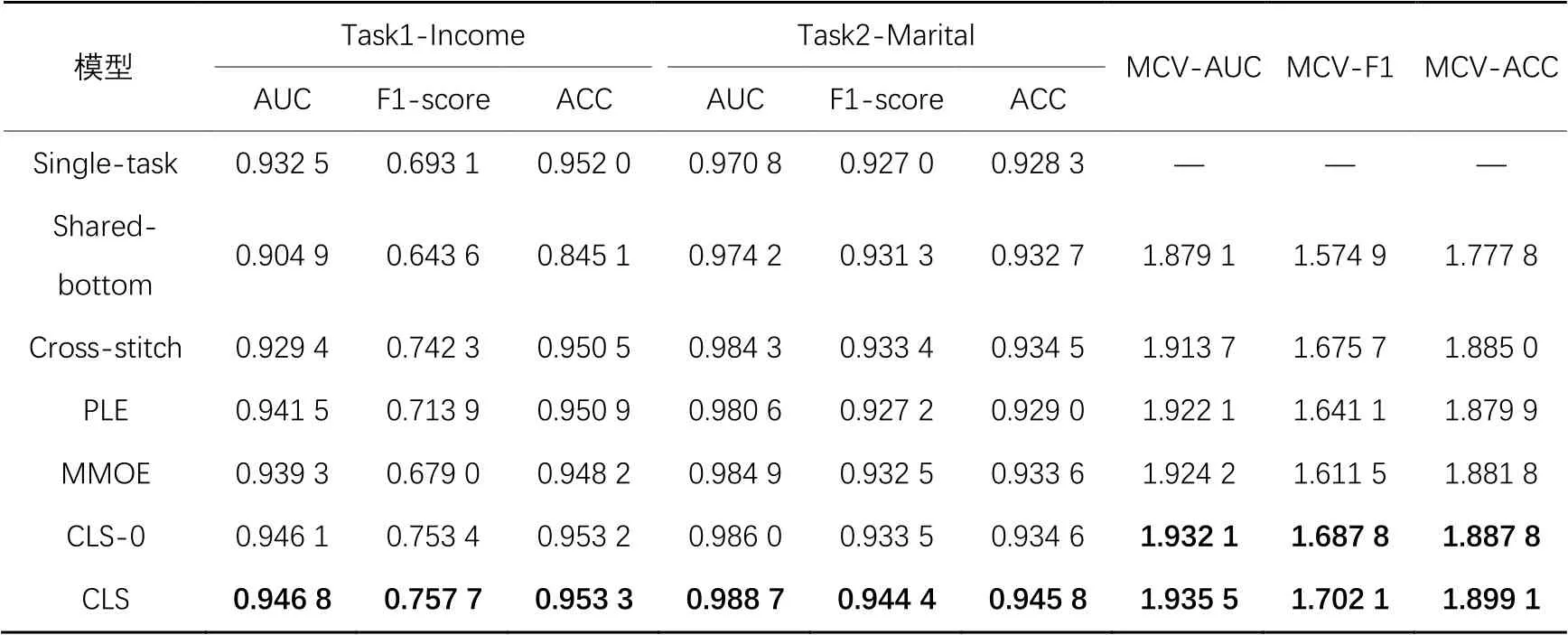
表3 UCI census-income 数据集上的实验结果Tab. 3 Experimental results on UCI census-income dataset
考虑到不同任务类型对模型性能的影响,在MovieLens数据集上同样做了对比实验。在任务分别为预测用户年龄和预测用户对电影的评分时,比较了共享底层模型、Cross-stitch模型、MMOE模型、PLE模型、CLS-0以及CLS模型的表现,其中预测年龄和预测评分的任务分别为回归任务和分类任务。使用MSE、AUC指标来评价模型的表现,如图6所示。
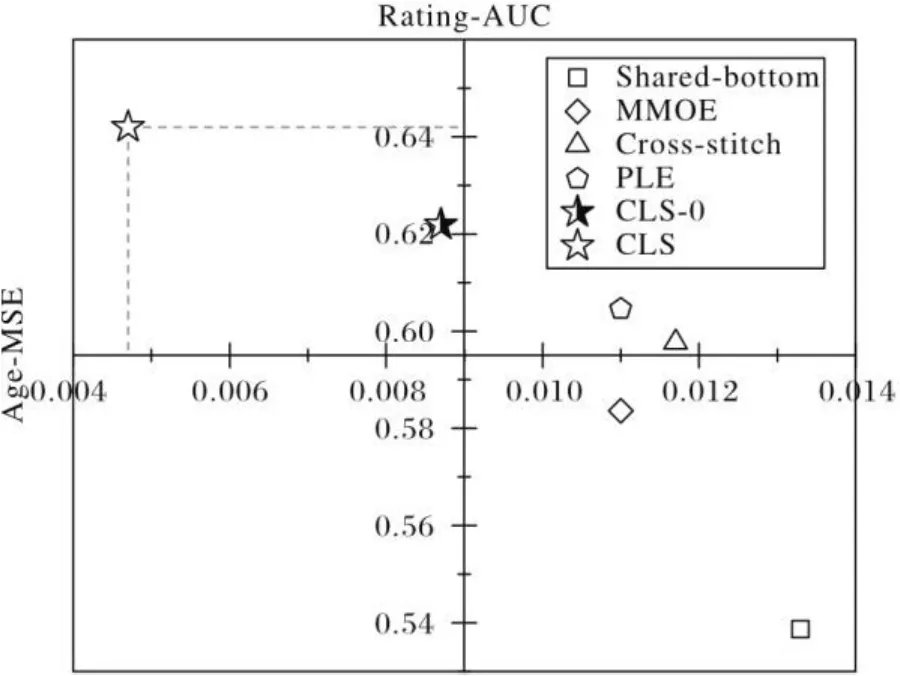
图6 不同模型在不同任务类型上的性能比较Fig. 6 Performance comparison of different models on different task types
可以得出:
1)共享底层模型在预测年龄和评分两个任务上均表现不佳。年龄任务和评分任务两者的相关度较低,而大部分多任务模型往往擅长处理任务相关度较高的情况,任务之间复杂度较低时,表现并不理想[7]。
2)Cross-stitch和MMOE两个模型均出现了seesaw现象,即在提升一个任务的性能时,伴随着另一个任务性能的下降。
3)CLS-0模型的交叉共享路由策略提升了模型性能;CLS模型在所有模型中表现最佳,回归任务的MSE值降低到0.004 7,分类任务的AUC值提高到0.642,并未受到seesaw现象的影响,显著优于其他基线模型。
4 结语
针对多任务模型中公共信息共享存在的负迁移问题,本文提出了交叉层级信息共享多任务模型。该模型结合特定的层级信息路由机制及不同层级专家之间的信息交叉共享,深入学习相关任务间的公共知识,提高预测目标准确度。实验结果表明,所提CLS模型不仅能稳定地处理大规模数据,且能在复杂相关的知识中有效学习到不同任务之间的共享表示,同时具备应对任务相关度较低场景的能力,有效避免了seesaw现象的不利影响。未来将持续探索更加高效的信息路由机制,以及研究怎样的层级信息共享方法更具备可解释性。
[1] CARUANA R. Multitask learning [M]// THRUN S, PRATT L. Learning to Learn. New York: Springer, 1998: 95-133.
[2] 章荪,尹春勇.基于多任务学习的时序多模态情感分析模型[J].计算机应用,2021,41(6):1631-1639.(ZHANG S, YIN C Y. Sequential multimodal sentiment analysis model based on multi-task learning [J]. Journal of Computer Applications, 2021, 41(6): 1631-1639.)
[3] 姜尧岗,孙晓刚,林云.基于多任务卷积神经网络人脸检测网络的优化加速方法[J].计算机应用,2019,39(S2):59-62.(JIANG Y G, SUN X G,LIN Y. Optimization acceleration method for face detection network based on multi-task convolutional neural network[J]. Journal of Computer Applications, 2019, 39(S2): 59-62.)
[4] BANSAL T, BELANGER D, MCCALLUM A. Ask the GRU: multitask learning for deep text recommendations [C]// Proceedings of the 2016 10th ACM Conference on Recommender Systems. New York: ACM, 2016: 107-114.
[5] SHAO C J, FU H M, CHENG P J. Improving one-class recommendation with multi-tasking on various preference intensities [C]// Proceedings of the 2020 14th ACM Conference on Recommender Systems. New York: ACM, 2020: 498-502.
[6] LU Y C, DONG R H, SMYTH B. Why I like it: multi-task learning for recommendation and explanation [C]// Proceedings of the 2018 12th ACM Conference on Recommender Systems. New York: ACM, 2018: 4-12.
[7] TANG H Y, LIU J N, ZHAO M, et al. Progressive Layered Extraction (PLE): a novel Multi-Task Learning (MTL) model for personalized recommendations [C]// Proceedings of the 2020 14th ACM Conference on Recommender Systems. New York: ACM, 2020: 269-278.
[8] MA J Q, ZHAO Z, YI X Y, et al. Modeling task relationships in multi-task learning with multi-gate mixture-of-experts [C]// Proceedings of the 2018 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2018:1930-1939.
[9] ISHAN M, ABHINAV S, GUPTA A, et al. Cross-stitch networks for multi-task learning [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE,2016: 3994-4003.
[10] RUDER S, BINGEL J, AUGENSTEIN I, et al. Sluice networks: learning what to share between loosely related tasks [EB/OL]. [2021-02-11]. https://arxiv.org/pdf/1705.08142v1.pdf.
[11] ZHANG Y, YANG Q. An overview of multi-task learning [J]. National Science Review, 2018, 5(1): 30-43.
[12] JACOBS R A, JORDAN M I, NOWLAN S J, et al. Adaptive mixtures of local experts [J]. Neural Computation, 1991, 3(1): 79-87.
[13] MA J Q, ZHAO Z, CHEN J L, et al. SNR: sub-network routing for flexible parameter sharing in multi-task learning[C]// Proceedings of the 2019 33rd AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2019:216-223.
[14] ZOPH B, LE Q V. Neural architecture search with reinforcement learning [EB/OL]. [2021-02-11]. https://arxiv.org/pdf/1611. 01578.pdf.
[15] WANG N, WANG H N, JIA Y L, et al. Explainable recommendation via multi-task learning in opinionated text data [C]// Proceedings of the 2018 41st International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2018: 165-174.
[16] WANG J L, HOI S C H, ZHAO P L, et al. Online multitask collaborative filtering for on-the-fly recommender systems [C]// Proceedings of the 2013 7th ACM Conference on Recommender Systems. New York: ACM, 2013: 237-244.
[17] QIN Z, CHENG Y C, ZHAO Z, et al. Multitask mixture of sequential experts for user activity streams [C]// Proceedings of the 2020 26th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2020: 3083-3091.
[18] HADASH G, SHALOM O S, OSADCHY R. Rank and rate: multi-task learning for recommender systems [C]// Proceedings of the 2018 12th ACM Conference on Recommender Systems. New York: ACM, 2018: 451-454.
[19] AKHTAR M S, CHAUHAN D S, EKBAL A. A deep multi-task contextual attention framework for multi-modal affect analysis [J]. ACM Transaction on Knowledge Discovery from Data, 2020, 14(3): Article No.32.
[20] ZHAO Z, HONG L C, WEI L, et al. Recommending what video to watch next: a multi-task ranking system [C]// Proceedings of the 2019 13th ACM Conference on Recommender Systems. New York: ACM, 2019: 43-51.
[21] ROSENBLATT F. The perceptron: a probabilistic model for information storage and organization in the brain [J]. Psychological Review, 1958, 65(6): 386-408.
Cross-layer data sharing based multi-task model
CHEN Ying1, YU Jiong1,2*, CHEN Jiaying2, DU Xusheng2
(1.School of Software,Xinjiang University,Urumqi Xinjiang830091,China;2.College of Information Science and Engineering,Xinjiang University,Urumqi Xinjiang830046,China)
To address the issues of negative transfer and difficulty of information sharing between loosely correlated tasks in multi-task learning model, a cross-layer data sharing based multi-task model was proposed. The proposed model pays attention to fine-grained knowledge sharing, and is able to retain the memory ability of shallow layer shared experts and generalization ability of deep layer specific task experts. Firstly,multi-layer shared experts were unified to obtain public knowledge among complicatedly correlated tasks. Then, the shared information was transferred to specific task experts at different layers for sharing partial public knowledge between the upper and lower layers. Finally, the data sample based gated network was used to select the needed information for different tasks autonomously, thereby alleviating the harmful effects of sample dependence to the model. Compared with the Multi-gate Mixture-Of-Experts (MMOE) model, the proposed model improved the F1-score of two tasks by 7.87 percentage points and 1.19 percentage points respectively on UCI census-income dataset. The proposed model also decreased the Mean Square Error (MSE)value of regression task to 0.004 7 and increased the Area Under Curve (AUC) value of classification task to 0.642 on MovieLens dataset. Experimental results demonstrate that the proposed model is suitable to improve the influence of negative transfer and can learn public information among complicated related tasks more efficiently.
multi-task learning; information sharing; negative transfer; neural network; transfer learning
TP311.1
A
1001-9081(2022)05-1447-08
10.11772/j.issn.1001-9081.2021030516
2021⁃04⁃06;
2021⁃06⁃22;
2021⁃06⁃22。
国家自然科学基金资助项目(61862060,61462079,61562086)。
陈颖(1999—),女,湖南娄底人,硕士研究生,主要研究方向:数据挖掘、机器学习; 于炯(1964—),男,北京人,教授,博士生导师,博士,主要研究方向:绿色计算、机器学习、数据挖掘; 陈嘉颖(1988—),女,新疆沙湾人,博士研究生,主要研究方向:推荐系统、数据挖掘; 杜旭升(1995—),男,甘肃庆阳人,博士研究生,CCF会员,主要研究方向:机器学习、数据挖掘。
This work is partially supported by National Natural Science Foundation of China (61862060,61462079, 61562086).
CHEN Ying, born in 1999, M. S. candidate. Her research interests include data mining, machine learning.
YU Jiong, born in 1964, Ph. D., professor. His research interests include green computing, machine learning, data mining.
CHEN Jiaying, born in 1988, Ph. D. candidate. Her research interests include recommender system, data mining.
DU Xusheng, born in 1995, Ph. D. candidate. His research interests include machine learning, data mining.
猜你喜欢
中国典型病例大全(2022年13期)2022-05-10
计算机应用(2022年2期)2022-03-01
中华养生保健(2021年18期)2021-02-13
初中生世界·八年级(2019年6期)2019-08-13
廉政瞭望(2019年5期)2019-06-10
学习导刊(2017年8期)2017-11-02
小学生导刊(低年级)(2016年9期)2016-10-13
小学生导刊(低年级)(2016年6期)2016-07-02
宠物世界·猫迷(2016年3期)2016-04-23
小学生导刊(低年级)(2016年4期)2016-04-12
