
基于指针网络融入混淆集知识的中文语法纠错
2022-06-18 01:58:54李嘉诚沈嘉钰李正华
中文信息学报 2022年4期
李嘉诚,沈嘉钰,龚 晨,李正华,张 民
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
0 引言
中文文本纠错任务可分为两类: 拼写纠错和语法纠错。对于拼写纠错,错误句子只存在替换类错误;而对于语法纠错,除了替换类错误,错误句子还存在冗余、缺失以及乱序等错误类型。本文聚焦于中文语法纠错(Chinese Grammatical Error Correction,CGEC)任务,该任务旨在通过自然语言处理技术,自动纠正包含语法错误的中文句子。中文语法纠错任务的示例如表1所示,其中,X是一个可能包含语法错误的句子,Y是纠正错误后的句子。
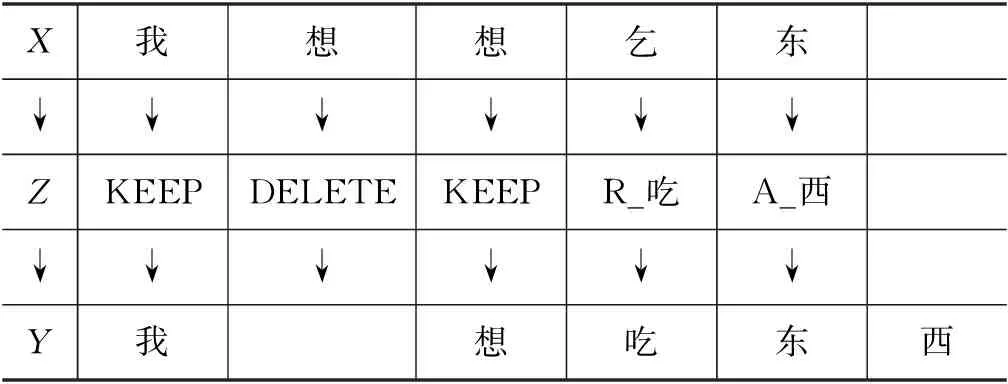
表1 中文语法纠错任务的示例
不像之前的很多研究[1-2]把语法纠错看作自回归的翻译任务,本文以Seq2Eidt语法纠错模型[3-4]为基准模型,该模型把语法纠错看作非自回归的序列标注任务,从而大幅提升了解码速度。Seq2Edit语法纠错模型以BERT[5]为上下文特征提取器,纠错过程如表1所示。首先,它为输入句子X预测一组字级别的编辑序列Z;进而把编辑序列Z作用于输入句子得到目标句子Y。在训练前,该模型需要把训练集中平行句对的正确句子预处理成一组与错误句子对应的编辑序列。
如表2所示,本文列出了不同错误类型在NLPCC 2018 GEC任务测试集中的数量[6],可以看出替换类错误在所有错误类型中的占比最多,大约占了50%。同时,Liu等[7]的工作表明,中文中超过90%的替换类错误由音近或形近字之间的误用导致。因此,字符之间的音近、形近知识对解决替换类错误非常重要。
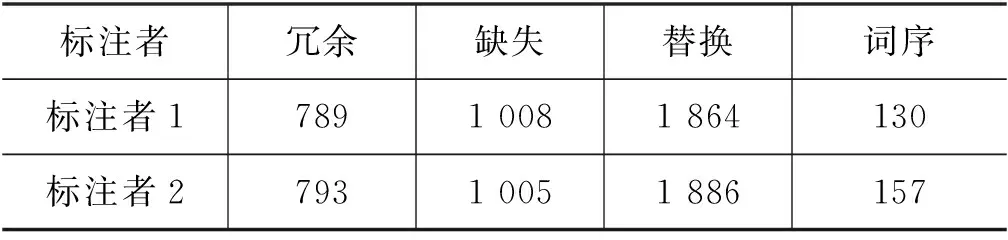
表2 不同错误类型在NLPCC 2018 GEC任务测试集中的数量
在中文拼写纠错研究中,很多研究者尝试以混淆集(Confusion set)的形式,将字符之间的音近、形近知识融入到模型中[8-9],取得了不错的效果。混淆集由一些汉字以及每个汉字对应的一组音近和形近字组成。例如,“乞”对应的音近字混淆集为“起杞启岂稽……”;“乞”对应的形近字混淆集为“疙吃屹迄乙……”。而对于中文语法纠错,虽然替换类错误在中文语法纠错数据集中占比最多,但还没有研究者尝试过将混淆集知识融入基于神经网络的语法纠错模型中。
为了更好地解决语法纠错中的替换类错误,本文尝试在模型和预处理两部分融入混淆集知识。在模型部分,本文提出一个基于指针网络融入混淆集知识的语法纠错模型。该模型在Seq2Eidt语法纠错模型基础上,利用指针网络[10]融入汉字之间的音近和形近知识。具体来说,模型分别计算两部分的概率分布,第一部分是Seq2Edit语法纠错模型输出当前字符在固定的编辑操作表中生成编辑的概率分布,第二部分是通过指针网络去计算当前字符替换为它对应混淆集中字符的替换编辑的概率分布,然后通过一个可学习的门控机制加权求和两部分的概率分布得到最终的概率分布。通过这种方法,模型可以充分考虑符号空间(混淆集中音近和形近知识)和语义空间(BERT的语义知识),从而更好地纠正替换类错误。
在预处理部分,即从错误-正确句对抽取编辑序列的过程中,本文发现普通的编辑距离算法不能很好地对齐中文语法纠错数据集中平行句对出现连续错误时的音近和形近字。因此,本文也提出了一种混淆集的编辑距离算法。利用该算法在预处理阶段抽取编辑,可以使得模型在训练过程中增加更多音近和形近字的替换类编辑,从而更好地纠正替换类错误。
实验结果表明,本文的基准Seq2Edit语法纠错模型已经在NLPCC 2018评测数据集上达到了目前最优性能。而本文提出的两点改进均能在此基础上提高性能,且作用互补。最终,本文所提出的模型在NLPCC 2018评测数据集上的F0.5值比之前的最优性能提高了2.1。本文用中文ERRANT[11]工具对提出的模型和基准模型不同错误类型的得分进行了分析,证明了本文模型的性能提升大部分来自于替换类错误的纠正。
本文主要的贡献总结如下:
(1) 本文提出一个基于指针网络融入混淆集知识的语法纠错模型,该模型可以有效融入音近、形近信息,更好地解决语法纠错中的替换类错误。据我们所知,这是首次将混淆集知识融入基于神经网络的语法纠错模型中的工作。
(2) 本文提出一种混淆集指导的编辑距离算法,该算法可以融入音近、形近知识去更好地对齐训练集中音近、形近字的替换类编辑,从而帮助模型更好地纠正替换类错误。
(3) 实验结果表明,本文提出的模型在NLPCC 2018评测数据集上达到目前最优性能。实验分析表明,和基准Seq2Edit语法纠错模型相比,本文模型的性能提升大部分来自于替换类错误的纠正。
1 相关工作
1.1 中文语法纠错
2018年,CCF国际自然语言处理与中文计算会议(NLPCC)举办了中文语法纠错竞赛[12]。该竞赛发布了一个中文语法纠错任务的标准数据集。下面介绍研究者们在该数据集上的最新工作,王等[1]采用基于多头注意力机制的Transformer模型作为基准模型,提出一种动态残差结构来增强Transformer挖掘文本语义信息的能力,从而更好地纠正中文语法错误。Zhao和Wang[2]在训练过程中采用动态的词频、同音等替换策略作用于错误句子,从而得到更多的错误-正确句对来提高模型的泛化能力,该方法在NLPCC 2018评测数据集上达到了目前的最优性能。Hinson等[13]结合了三个模型循环纠正包含语法错误的句子,三个模型分别为: 基于Transformer的Seq2Seq模型,基于LaserTagger[14]的Seq2Edit模型和拼写纠正模型。同时,他们还开发出中文的ERRANT[11]工具,该工具可以给出模型在不同错误类型的得分。在后续的实验部分,把本文提出的模型与上述工作进行了性能上的对比。
在中文语法纠错研究中,语法纠错模型主要分为两种,序列到序列(Seq2Seq)模型和序列到编辑(Seq2Edit)模型。由于Seq2Seq模型存在解码速度慢、需要大量的训练数据等问题,本文采用Seq2Edit模型来完成中文语法纠错任务。最近,研究者们尝试引入英文中的Seq2Edit模型到中文语法纠错任务中。例如,Hinson等[13]将英文中的Seq2Edit模型LaserTagger[14]引入中文,该模型结合BERT编码器与一个自回归的Transformer解码器来预测编辑。Liang等[4]在中文语法错误诊断(Chinese Grammatical Error Diagnosis, CGED)[15]竞赛中首次将英文中的Seq2Edit模型GECToR[3]引入到中文。该模型结合BERT编码器与非自回归的线性变化层去预测编辑。因为GECToR模型简单并且效果好,本文采用它作为本文的基准模型。
1.2 文本纠错中使用混淆集的方法
在中文拼写纠错研究中,为了解决音近和形近字的误用,很多研究者尝试去融入混淆集知识到模型中。Wang等[8]提出一个带有指针网络的Seq2Seq模型来解决拼写纠错问题,该模型要么通过指针网络从输入句子中复制一个字,要么从当前字符对应的混淆集中选择一个字,这种方法是利用混淆集去限制解码空间。Cheng等[9]提出了SpellGCN模型,利用图卷积神经网络(GCN)去注入字符之间的音近和形近知识到语言模型(BERT)中进行拼写纠错任务。
在语法纠错研究中,研究者们也探索了将混淆集融入基于统计机器学习的语法纠错模型的方法。在基于语言模型的语法纠错模型中,Bryant和Briscoe[16]在生成候选答案时,针对时态、冠词、介词等错误,使用混淆集来生成候选答案。再用统计语言模型来评估纠正是否合理。在基于分类的语法纠错模型[17]中,给定一个存在语法错误的句子,对于句子中每一个存在于混淆集中的词,分类器根据当前位置的上下文特征,选择在混淆集中且概率最大的候选单词。以上将混淆集融入语法纠错模型的方法,都只针对特定的错误类型,并且采用的都是基于统计机器学习的模型。
目前还没有研究者尝试过融入混淆集知识到基于神经网络的语法纠错模型中来解决语法纠错数据集中占比最多的替换类错误。因此,本文提出一个基于指针网络融入混淆集知识的语法纠错模型。该模型在Seq2Eidt语法纠错模型基础上,利用指针网络融入汉字之间的音近和形近知识。
1.3 指针网络
指针网络[10]被广泛应用在采用Seq2Seq模型的文本摘要任务[18]中。因为语法纠错任务中大部分的字符都是正确的,Zhao等[19]首次将指针网络应用到基于Seq2Seq的语法纠错中,使得模型可以直接从输入的句子中复制正确的字到输出,取得了不错的效果。本文将指针网络引入到Seq2Edit语法纠错模型中,利用指针网络从当前字符的混淆集中选择字来进行替换,使得模型可以更好地纠正替换类错误。
2 方法
2.1 问题定义
中文语法纠错的目的是纠正中文句子中存在的语法错误。给定一个可能包含语法错误的中文句子X=(x1,x2,…,xm),xi指句子X的第i个字,语法纠错模型输出一个句子Y=(y1,y2,…,yn),yi指句子Y中的第i个字。X和Y的长度可以相等,也可以不相等。本文采用非自回归的Seq2Edit语法纠错模型来解决中文语法纠错问题。
2.2 基准Seq2Edit语法纠错模型
在Seq2Edit语法纠错模型中,输入句子X=(x1,x2,…,xm),模型输出一组与X对应的编辑Z=(z1,z2,…,zm),zi∈Φ,是xi对应的编辑。Φ是编辑操作表,所有编辑操作表的统计信息如表3所示。
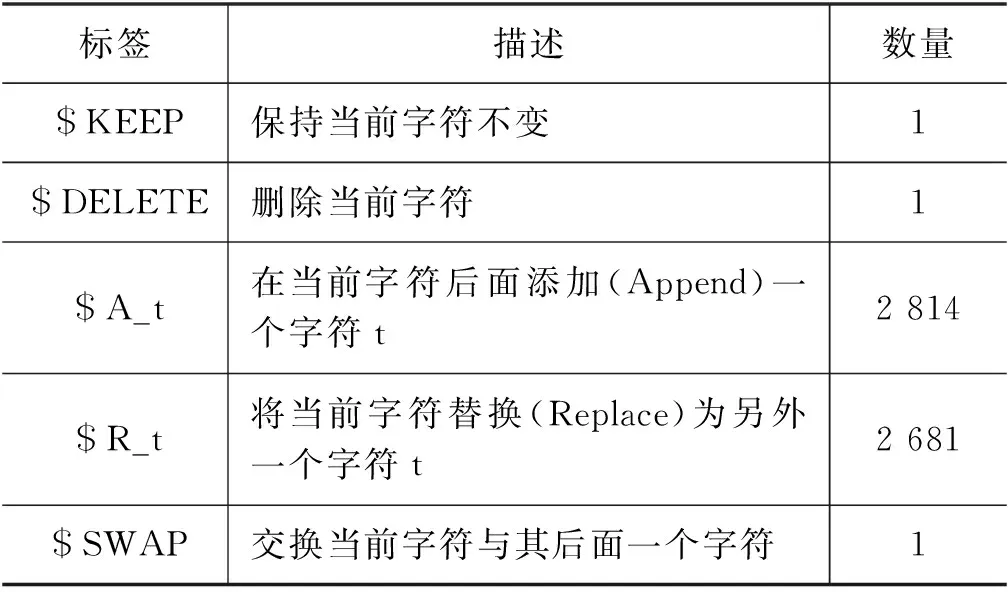
表3 Seq2Edit语法纠错模型编辑操作表
该模型采用BERT作为上下文特征提取器,输入是可能包含语法错误的句子X=(x1,x2,…,xm),用BERT编码句子X后,把BERT最后一层的输出作为整个句子上下文相关的字表示向量H={h1,h2,…,hm},再把xi对应的字表示向量hi经过一个线性变换层和softmax操作去预测当前第i个字的编辑为z的概率p(z|X,i),如式(1)、式(2)所示。
其中,hi∈db。Ws∈db×|Φ|,bs∈|Φ|分别是线性变化层的权重矩阵和偏置向量。si,z是第i个字的编辑预测为z的得分。Φ是所有可能的编辑操作集合,z′是Φ中的编辑。db是BERT的隐藏层维度。如式(3)所示,损失函数选择交叉熵,是正确编辑序列中的第i个编辑。
(3)
如图1所示,该模型解码时采用迭代式纠正[20]: 把模型预测的编辑序列Z作用于输入句子X得到输出句子Y,再把Y当作输入重新送入模型,重复这个过程直到达到最大迭代次数或者模型输出的句子与输入句子一致时。
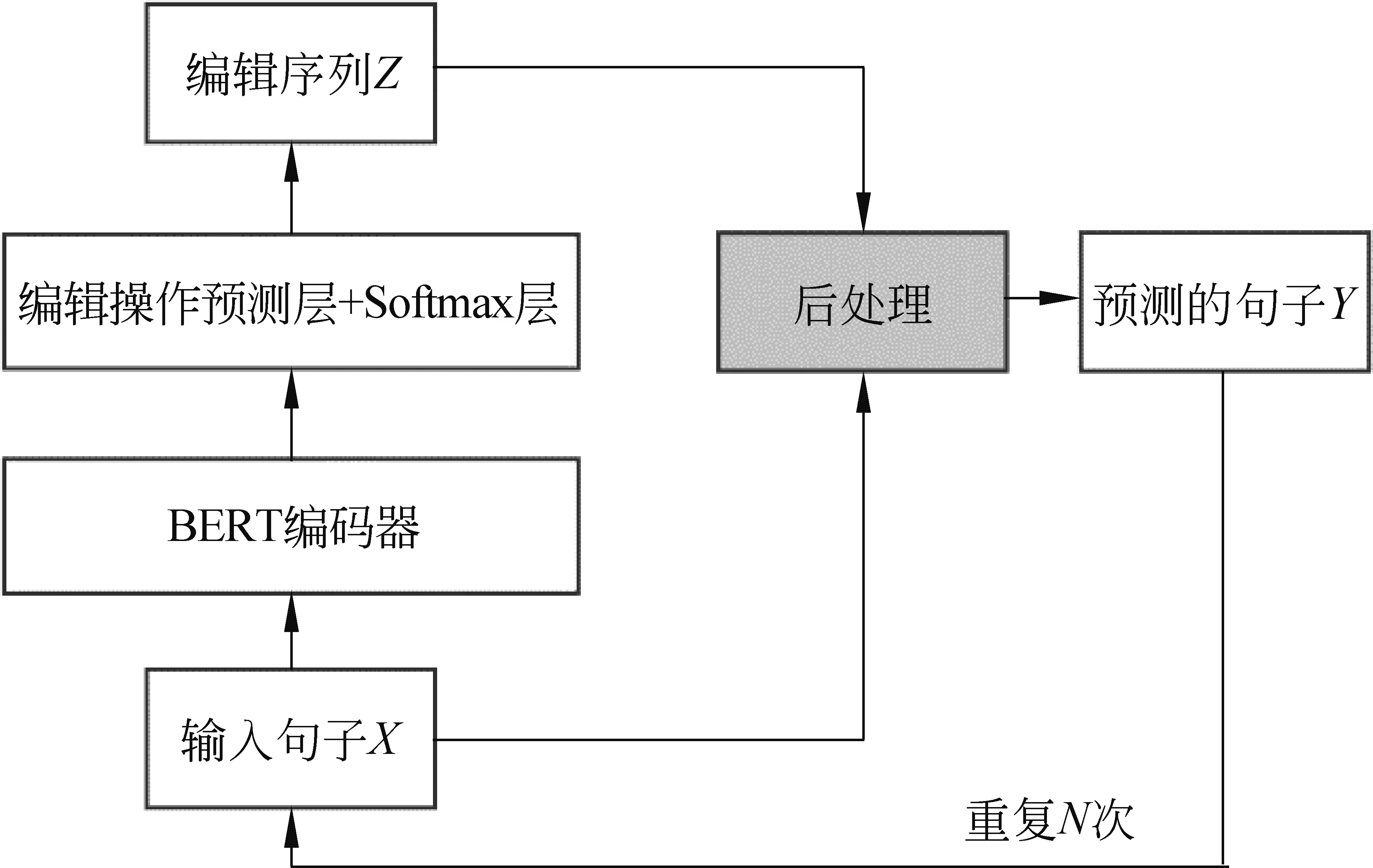
图1 基准Seq2Edit语法纠错模型
2.3 基于指针网络融入混淆集知识的语法纠错模型
混淆集由一些汉字以及每个汉字对应的一组音近和形近字组成。本文定义C(xi)是xi对应的一组混淆集字符。
指针网络被广泛应用在采用Seq2Seq模型的文本摘要任务和语法纠错任务中。因为其能从可变长度的候选集合中去选择一个候选项,本文通过指针网络去计算当前字符替换为它对应混淆集中字符的替换编辑的概率分布。
如图2所示,基于指针网络融入混淆集知识的语法纠错模型在基准Seq2Eidt语法纠错模型基础上,利用指针网络融入汉字之间的音近和形近知识。该模型除了从固定的编辑操作表中生成编辑外,还允许指针网络从当前字符的混淆集中选择字进行替换。如式(4)所示,最终编辑的概率分布p(z|X,i)是生成编辑的概率分布pgen(z|X,i) 和当前字符替换为它对应混淆集中字符的替换编辑的概率分布pcon(z|X,i)的加权求和,平衡因子αi∈[0,1]由一个可学习的门控机制来得到。
(4)
从固定编辑操作表中生成编辑的概率分布pgen(z|X,i)的计算公式和2.2节基准Seq2Edit语法纠错模型相同。本文通过指针网络来计算当前字符替换为它对应混淆集中的字符的替换编辑的概率分布pcon(z|X,i)。首先,如式(5)所示,将C(xi)中的字符通过字嵌入层得到向量表示Ei,Ei中的每一行是C(xi)中一个字符的字向量表示。其次,通过式(6)~式(8)来计算pcon(z|X,i)。

图2 基于指针网络融入混淆集知识的语法纠错模型
其中,hi∈db,是BERT编码X得到的第i个字的上下文相关的字表示向量。Ei∈dl×dc,是第i个字的混淆集中字符的字向量表示。dl是当前字符对应混淆集中字符C(xi)的个数,dc是字嵌入层的维度。qi是hi经过线性变化层得到的查询向量(Query),Ki和Vi是Ei经过不同的线性变化层得到的键值向量(Key)和实值向量(Value)。qi和Ki点乘得到注意力分值si∈dl,再通过一个Softmax操作得到归一化后的概率pcon(z|X,i),这里的z∈Φc(xi),Φc(xi)是将字符xi替换为xi的混淆集C(xi)中的字符的替换编辑集合,z′是Φc(xi)中的编辑。Wq∈db×dc,Wk、Wv∈dc×dc是线性变化层的权重矩阵。平衡因子αi的计算如式(9)所示。
αi=sigmoid(softmax(si)Viwα+bα)
(9)
其中,wα∈dc,bα∈1分别是线性变化层的权重矩阵和偏置向量。损失函数选择交叉熵,其公式与式(3)相同,不过式(3)中的概率需要替换为式(4)得到的最终编辑概率。
2.4 混淆集指导的编辑距离算法
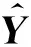
本文使用训练集中的一个真实例子来描述混淆集指导的编辑距离算法抽取的编辑与普通的编辑距离算法抽取的编辑的差异,如表4所示。
例1X: 每天漫漫得进步。
Y: 每天都在慢慢地进步。
表4展示了两者抽取编辑的不同,其中如果一个字对应多个编辑操作,则用“&”连接。对照X和Y,可以看出X存在两个语法错误,一个是缺失类错误,缺少了“都在”,一个是音近导致的替换类错误,“漫漫得”应该被替换为“慢慢地”。自然而然我们希望编辑距离算法抽取的编辑可以很好地对齐两类错误。然而如表4上半部分所示,普通的编辑距离算法从X和Y抽取的编辑并没有得到理想的对齐效果,究其原因,这是由于普通的对齐算法把“漫”和“慢”看作是两个完全不一样的字,导致“漫”和“都”与“漫”和“慢”在编辑距离算法中替换操作的代价一样。
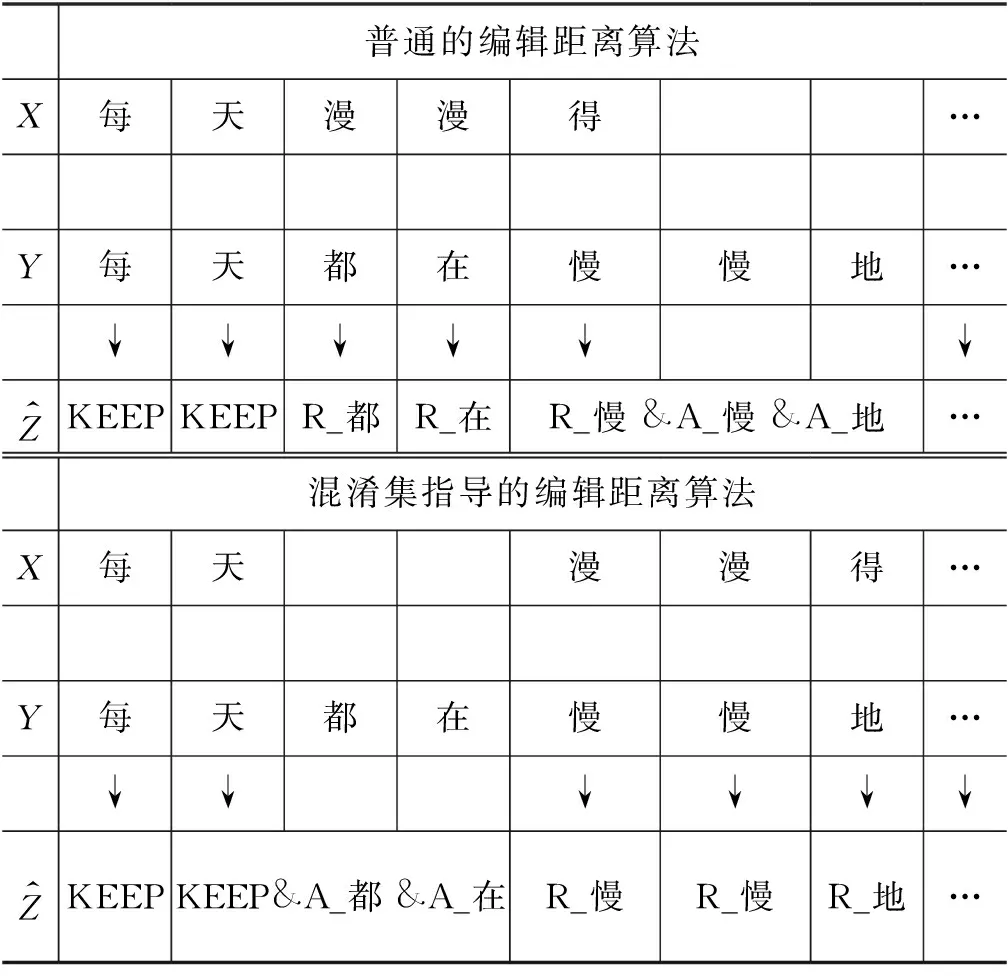
表4 不同编辑距离算法抽取编辑的差异
本文利用混淆集知识来指导编辑距离算法的抽取编辑过程,本文把混淆集中音近和形近字之间的替换操作代价设为0.5。(在普通的编辑距离算法中,两个一样的字的替换操作代价为0,而两个不一样的字的替换操作代价为1)。在混淆集指导的编辑距离算法下,表4上半部分的对齐方式X和Y的编辑距离为5,而表4下半部分的对齐方式X和Y的编辑距离为3.5,因此,混淆集指导的编辑距离算法选择了下面更好的对齐方式。下面详细描述抽取编辑的过程。
Step1: 首先,本文使用混淆集指导的编辑距离算法来对齐源句子与目标句子,为源句子的每个字找到目标句子中的一个子序列与其对应。[每→每],[天→天],[漫→都,在,慢],[漫→慢],[得→地],[进→进],[步→步]。
Step2: 从源句子中的每个字对应目标句子的子序列中得到编辑。如果一个字对应目标句子的子序列有多个字,那么也会考虑源句子中的字与目标句子的子序列每个字的编辑距离。[每→每]: KEEP,[天→天]: KEEP、A_都、A_在,[漫→都,在,慢]: R_慢,[漫→ 慢]: R_慢,[得→地]: R_地,[进→进]: KEEP,[步→步]: KEEP。
Step3: 在训练时,本文为源句子中的每个字只留下一个编辑,有多个编辑的,本文只留第一个非KEEP类的编辑,这样本文得到每个字对应的唯一的编辑操作。每: KEEP,天: A_都,漫: R_慢,漫: R_慢,得: R_地,进: KEEP,步: KEEP。
3 实验
3.1 数据集
所有数据的统计信息如表5所示。
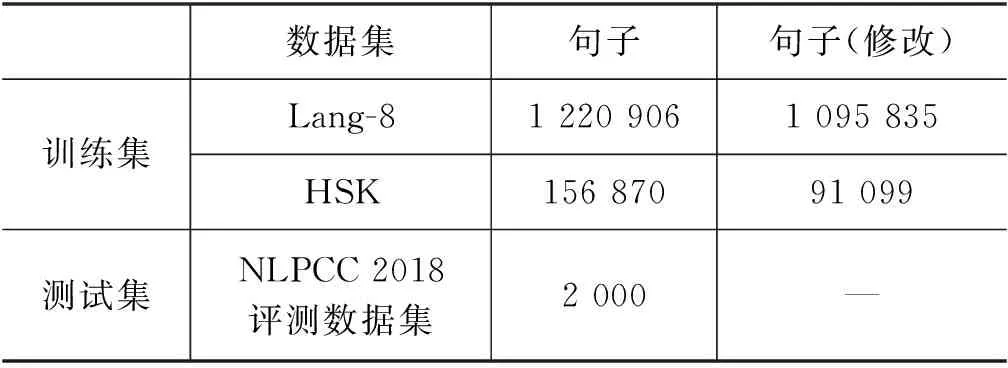
表5 数据集统计信息
3.1.1 训练集
本文使用的训练集包括NLPCC 2018 GEC任务官方提供的Lang-8数据集以及HSK数据集,其中Lang-8数据集采集自Lang-8网站。Lang-8网站是一个多语言学习者平台,不同国家的学习者在该平台练习写作,然后由母语者对他们的写作进行修改。因为一个句子可以由多个人修改,所以错误句子可能对应多个纠正答案。HSK数据集收集自北京语言大学构建的动态作文语料库[21]。两个数据集的平行语料共有1 377 776对,本文去除数据集中错误和正确句子一样的句对,剩余数据集包含1 186 934对。其中包括Lang-8数据1 095 835对,HSK数据91 099对。本文从剩余语料中随机选择百分之一的数据共11 869对作为开发集,其余的数据共1 175 065对作为本文的训练集。
3.1.2 测试集
本文选用NLPCC 2018 GEC任务的评测数据集来评测本文的模型,该数据集收集自PKU中文学习者语料库。两个标注者遵循最小编辑距离的修改原则对其进行了标注,官方数据集包含错误句子和M2格式的官方参考(Gold)编辑。
3.1.3 混淆集
本文采用SIGHAN 2013年比赛[22]提供的混淆集。主要有两类: 音近字混淆集和形近字混淆集。本文将两类混淆集合并、去重后作为一个混淆集来使用。
3.2 评价指标
本文使用官方的MaxMatch[23]工具包去评测不同模型的性能,给出精确率、召回率和F0.5指标。
3.3 模型训练细节
本文使用中文预训练模型BERT-wwm-ext[24]来初始化本文的编码器,使用Adam优化器来训练模型,共训练12个轮次,并应用早停机制,当开发集的编辑预测精确率两轮没有提升就结束训练。在前两轮,本文设置学习率为1e-3,并冻结BERT的参数,只训练其余模块的参数。在后面的轮次,本文设置学习率为1e-5,训练整个模型的参数。Batch size设置为128。对于所有的实验,本文都更换随机数种子进行了4次实验,并汇报平均结果。本文从训练集中统计出现频率大于10次的编辑作为编辑操作表,共包含5 498个编辑。在预测时,默认的迭代次数为5。
对于基于指针网络融入混淆集的语法纠错模型,本文使用随机初始化参数的200维字嵌入层作为混淆集中字符的字向量表示,并在训练过程进行更新。其他训练细节和基准Seq2Edit模型一致。
3.4 基准模型
MaskGEC[2]: 该方法在训练过程中采用动态的词频、同音等替换策略作用于错误的句子上,从而得到更多的错误-正确句对来训练模型。
异构循环预测模型[13]: 该方法使用基于Transformer的Seq2Seq模型,基于LaserTagger[14]的Seq2Edit模型和拼写纠正模型循环纠正错误句子。
Transformer增强架构[1]: 该方法通过动态残差结构来增强Transformer挖掘文本语义信息的能力。
Seq2Edit模型[3]: 该方法采用非自回归的Seq2Edit模型GECToR[3]来解决中文语法纠错任务。
3.5 实验结果
表6展示了本文提出的模型与其他先进的模型在NLPCC 2018评测数据集上的得分。与其他模型相比,本文的基准Seq2Edit模型已经优于上述所有工作,达到了目前的最优性能。而本文的应用了混淆集指导的编辑距离算法和基于指针网络融入混淆集知识的模型的F0.5值比基准Seq2Edit模型又高了0.73。MaskGEC[2]利用了Lang-8训练集,但在训练过程中动态地采用词频、同音等替换策略应用到错误的句子上产生新的错误-正确句对来训练模型,可以看作一种数据增强的手段。异构循环预测模型[13]利用了Lang-8训练集,采用了基于Transformer的Seq2Seq模型,基于LaserTagger[14]的Seq2Edit模型和拼写纠正模型来循环纠正错误句子。Transformer增强架构[1]通过动态残差结构来增强Transformer挖掘文本语义信息的能力,它们除了使用Lang-8和HSK的数据,还使用了742万人造数据,F0.5值达到了34.41,而本文没有使用任何的人造数据,性能就优于它们。

表6 不同纠错模型在NLPCC 2018 评测数据集上的结果比较
3.6 不同改进对模型性能的影响
我们做了四组实验来验证本文方法的有效性。表7展示了不同改进在NLPCC 2018评测数据集上的结果。可以看出基准Seq2Edit模型的F0.5值已经达到了38.33,而本文提出的两种改进在此基础上又有了一定的提升。
第1组和第2组实验比较预处理阶段采用普通的编辑距离算法和混淆集指导的编辑距离算法抽取编辑对性能的影响。使用不同的编辑距离算法抽取编辑,训练集中有39 003个句子抽取的编辑发生了改变,开发集中有400个句子抽取的编辑发生了改变,大约占总数据的3.6%。如表7所示,相比采用普通的编辑距离算法抽取编辑的基准Seq2Edit模型,本文使用混淆集指导的编辑距离算法预处理数据集后,基准Seq2Edit模型的F0.5值有0.21的提升。
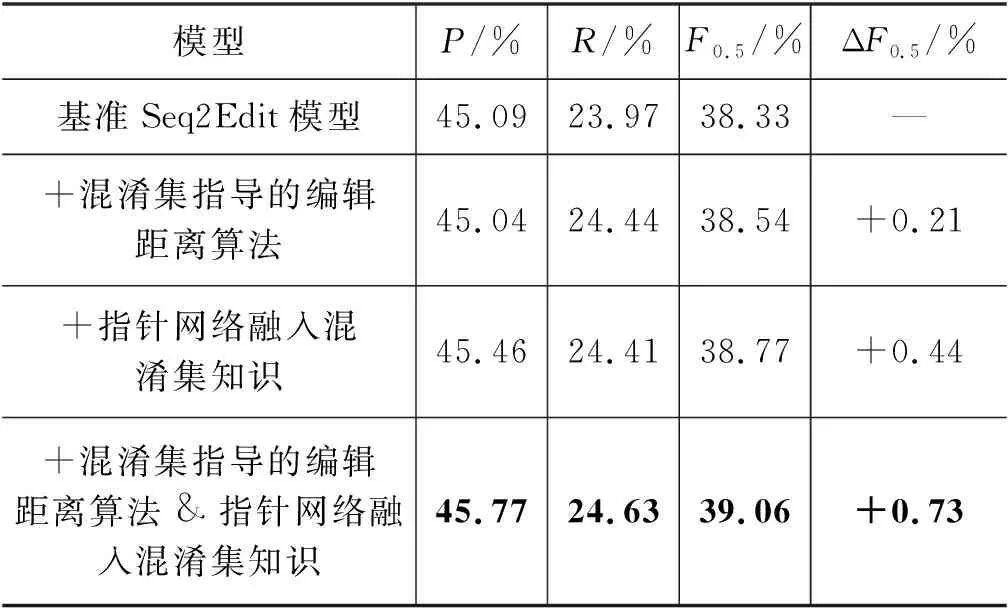
表7 不同改进对模型性能的影响
第1组和第3组实验比较基准Seq2Edit模型和基于指针网络融入混淆集知识的模型对性能的影响。由表7可以看出,基于指针网络融入混淆集知识的模型比基准Seq2Edit模型的F0.5值提高了0.44。
最后,第4组实验在预处理阶段采用混淆集指导的编辑距离算法抽取编辑,模型采用基于指针网络融入混淆集知识的模型。其F0.5值达到了39.06,比基准Seq2Edit模型提高了0.73。混淆集指导的编辑距离算法更好地对齐了音近和形近字的替换类编辑,使得基于指针网络融入混淆集知识的模型得到了更充分的训练,从而超过了两者单独相加提高的性能。
3.7 对不同错误类型的影响
为了证明本文提出的模型可以比基准Seq2Edit模型更好地解决语法纠错任务中的替换类错误。本文采用Hinson等[13]开发的中文ERRANT工具对本文提出的模型和基准Seq2Edit模型不同错误类型的纠错能力进行了分析。图3展示了本文的模型和基准Seq2Edit模型在不同错误类型的TP和FP值,其中TP表示模型预测正确的编辑数量,FP表示模型预测错误的编辑数量。从图3(a)可以看出,整体来看,本文的模型比基准Seq2Edit模型多了32个预测正确的编辑。具体到替换类错误,本文的模型比基准Seq2Edit模型多了26个预测正确的编辑,占了整体的81.25%。从图3(b)可以看出,整体来看,本文的模型比基准Seq2Edit模型少了62个预测错误的编辑。具体到替换类错误,本文的模型比基准Seq2Edit模型少了29个预测错误的编辑,占了整体的46.77%。因此,本文模型的性能提升大部分都来自于替换类错误的纠正。

图3 本文的模型与基准Seq2Edit模型在不同错误类型的TP和FP值
4 总结
为了更好地解决语法纠错中占比最多的替换类错误,本文尝试在模型和预处理两部分融入混淆集知识。在模型部分,本文提出了基于指针网络融入混淆集知识的语法纠错模型。在预处理部分,本文提出了混淆集指导的编辑距离算法来更好地抽取音近和形近字的替换类编辑。实验证明,本文的模型在NLPCC 2018评测数据集上达到了目前最优性能。进一步的分析证明了本文的性能提升主要来自于替换类错误的纠正。在未来,本文计划将基于指针网络融入混淆集知识的模型迁移到拼写纠错任务。
猜你喜欢
电脑爱好者(2022年15期)2022-05-30 01:29:23
小学生学习指导(低年级)(2019年12期)2019-12-04 03:39:42
电子制作(2019年19期)2019-11-23 08:41:50
娃娃画报(2019年5期)2019-06-17 16:58:10
少儿美术(快乐历史地理)(2018年7期)2018-11-16 05:31:14
广东第二课堂·小学(2017年9期)2017-09-28 14:51:06
公民与法治(2016年19期)2016-05-17 04:18:15
读者·校园版(2015年7期)2015-05-14 13:11:40
电测与仪表(2015年5期)2015-04-09 11:30:42
单片机与嵌入式系统应用(2014年9期)2014-03-11 15:35:09
