
深度学习在炼钢过程中的研究进展及应用现状
2022-06-16 07:36王仲亮包燕平
工程科学学报 2022年7期
王仲亮,顾 超,王 敏,包燕平
北京科技大学钢铁冶金新技术国家重点实验室,北京 100083
钢铁工业是国家生产力的重要体现,在国民经济发展与国防建设中起到物质基础的作用[1].近年来我国粗钢产量稳居全球首位,2020年更是首次突破10亿吨,达到10.65亿吨[2].同时,庞大的产能背后,钢铁行业也是能耗和污染大户,在当前全国统筹做好“碳达峰”“碳中和”背景下,传统炼钢工艺亟待向智慧化和绿色化转型.炼钢整体流程可划分为初炼、精炼和连铸三个阶段依次进行,每个阶段又有多道处理工序.我国粗钢产品约90%来自转炉炼钢,其余来自电炉[3],但无论采用何种初炼方式,炼钢全流程均具有工序高度复杂、控制过程非线性的特点,难以建立准确的数学模型进行描述,这使得智慧化之路面临挑战[4].为应对冶炼过程的上述特性,作为机器学习近年来兴起的重要分支,深度学习被引入到炼钢领域且已获得广泛应用,这是一种以人工神经网络为基本架构,对数据进行特征提取并实现知识学习的非线性建模算法[5−7],其已成为钢铁行业智慧化的重要手段之一.本文对深度学习原理进行了介绍,并将前人在深度学习应用于炼钢的工序过程所做的工作及其优缺点等进行了综合阐述.
1 深度学习原理及类型
深度学习目的在于模拟生物体内的神经网络处理外界信息的过程.与生物神经细胞可接受外界刺激或其他细胞信息类似,人工神经网络中的基本单元神经元可以起到相同的作用,可以接受来自其他神经元的输入或者是外部的数据,然后计算一个输出.如图1所示为神经元的工作原理,首先每个输入值被赋予一个权值,权值大小取决于这个输入数据的重要性,然后进行激活函数的运算,常见的激活函数有sigmod函数、relu函数和tanh函数等,目的是给输出值引入非线性,从而用于更好地描述现实问题[8].与神经细胞相同,当前神经元的输出可以作为其他神经元的输入,反之其他神经元的输出也可作为当前神经元的输入.

图1 人工神经网络神经元结构及工作原理Fig.1 Structure and working principle of artificial neural network neurons
图2为深度学习模型的基本结构,通常由一个输入层、一个输出层和若干隐藏层构建而成,其中每层都有若干神经元,每两个神经元之间都有对应权值来决定上级输入数据的重要性.深度学习模型的输入层用于接收数据,然后将输入数据传递给第一个隐含层,隐含层会针对这些数据进行函数运算,并在隐含层内部进行数据传输,最后一个隐含层会将计算结果传递给输出层,由输出层输出最终数据.
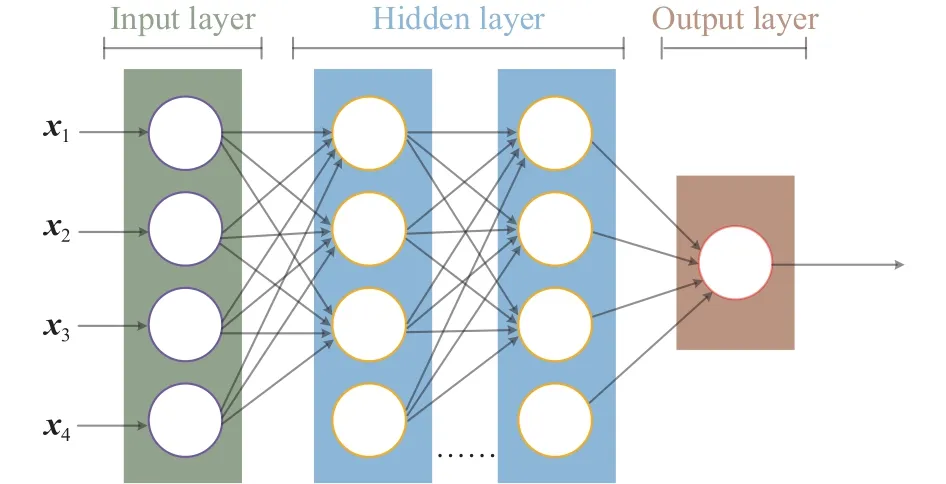
图2 深度学习模型基本结构Fig.2 Basic structure of the deep learning model
深度学习作为机器学习的一个重要分支,根据模型中神经元的互联方式以及各层的相互关系,可分为前馈神经网络、反馈神经网络和自组织神经网络.前馈神经网络指每一层神经元只接受来自前一层的数据输入,后层对前层没有数据反馈,初始输入数据经过在各层的向前传播,在输出层得到最终结果,如图3(a)所示[9].此类结构适用于模式识别、数据挖掘和非线性函数逼近,典型的前馈神经网络包括:利用梯度下降法的BP(误差反馈神经网络),ELM(极限学习机神经网络),RBF(径向基神经网络),以及包含卷积计算的CNN(卷积神经网络)等[10].反馈神经网络是指模型中神经元之间有反馈通道,所有神经元能够任意连接,数据信号可以进行双向传播,输入信号仅仅作为模型的初始状态,整个模型经过反复循环迭代逐渐收敛至平衡态,如图3(b)所示[11].因此,反馈神经网络是一种动态非线性网络,稳定性是其重要评价指标.此类结构适用于寻找问题最优解,典型的反馈神经网络包括:Hopfield神经网络、Hamming神经网络、WNN(小波神经网络)、BAM(双向联系存储网络)和BM(波耳兹曼机)等.自组织神经网络含有输入层和竞争层两层网络,无隐含层,两层之间各神经元间双向连接,且竞争层各神经元间也存在双向连接,如图3(c)所示[12].此类结构可在无监督情况下,自组织地改变网络结构和各神经元间权值,进而自动寻找原始数据中的特征规律,典型的自组织神经网络包括:SOM(自组织映射神经网络)、CPN(外对偶传播网络)和ART(自适应共振理论)等.

图3 神经网络分类.(a) 前馈神经网络; (b) 反馈神经网络; (c) 自组织神经网络Fig.3 Neural network classification: (a) feed-forward neural network; (b) feedback neural network; (c) self-organizing neural network
现今研究人员已经提出了上百种深度学习模型,优化算法更是层出不穷.但从实际应用角度来看,广泛研究且大规模使用的模型并不多.在表1中列出了BP、CNN、WNN和SOM等几种常用主流深度学习方法,并对比了他们之间的优缺点.

表1 几种深度学习主流方法特征对比Table 1 Comparison of the features of several mainstream methods of deep learning
2 深度学习在炼钢过程的发展与应用
2.1 深度学习在炼钢过程的发展
炼钢过程涉及热力学、动力学及动量热量质量传输等物理化学机理,但由于过程参数复杂,且前后工序存在遗传影响,在解释对应冶金现象时需要大量假设和简化.而与之相反,深度学习模型只要有足够多的样本训练就能达到较好的拟合效果,但不能从原理上对现象进行解析.在利用冶金工艺原理进行理论指导的同时将深度学习引入生产过程建模,可以实现优势互补.1943年,Mcculloch与Pitts参考神经细胞工作原理,首次提出神经元数学模型,即M−P模型,这标志着人工神经网络的开端[13].Rumelhart等[14]在 1986 年,Hinton和Salakhutdinov[15]在2006年两次推动了神经网络的巨大进步,先是促进了BP算法在学习训练中的应用,而后又掀起深度学习新的研究热潮.伴随着神经网络的波动发展,以及硬件设备计算能力的不断提升,深度学习在炼钢过程中的应用主要可分为三个阶段,分别如下:
2.1.1 应用探索阶段
神经网络依靠提取数据特征完成训练学习,模仿人脑活动过程,取得对应经验,因此在应用早期,常与炼钢专家系统相结合,共同为现场决策起辅助作用[16−19],解决某个工序点的问题.迫于当时生产数据难以实时采集,同时专家系统无法获取隐性知识,加之硬件计算能力有限,使得深度学习模型在炼钢过程中的应用研究没有大的发展,模型精度较低.但国内外学者都进行了有益探索,部分研究成果在实际生产中开始小范围研究性试用,如表2所示.

表2 深度学习模型探索使用案例Table 2 Deep learning model exploration use cases
2.1.2 初步结合阶段
20世纪末至21世纪初,炼钢技术迅速发展,深度学习模型也取得长足进步,完全由计算机控制的全工序“一键炼钢”成为国内外冶金从业者研究的热点.特别是以转炉动态控制为代表的实时响应模型与深度学习模型结合能够在短时间内完成计算分析,并对生产状况做出正确判断.通过初步结合应用,模型精度有所提升,转炉终点碳温双命中率可达95%,连续动态调整连铸二冷配水,铸坯表面实际温度与目标温度误差在±10 ℃以内[20−22].深度学习模型开始在全流程多工序点应用.
2.1.3 融合发展阶段
近年来,得益于工业传感器和数据存储的技术进步,炼钢过程中更多的数据信号被采集记录,例如初炼、精炼和连铸过程的物料加入、烟气信息、冷却水信息、设备本体状况、各工序的声音图像等,为数据驱动的深度学习模型提供了更多可利用的素材.模型精度的大幅提升使得大量钢铁企业将深度学习用于实际控制,实现了深度学习与炼钢过程的融合发展与全工序多维度应用[23],如图4所示为部分案例.
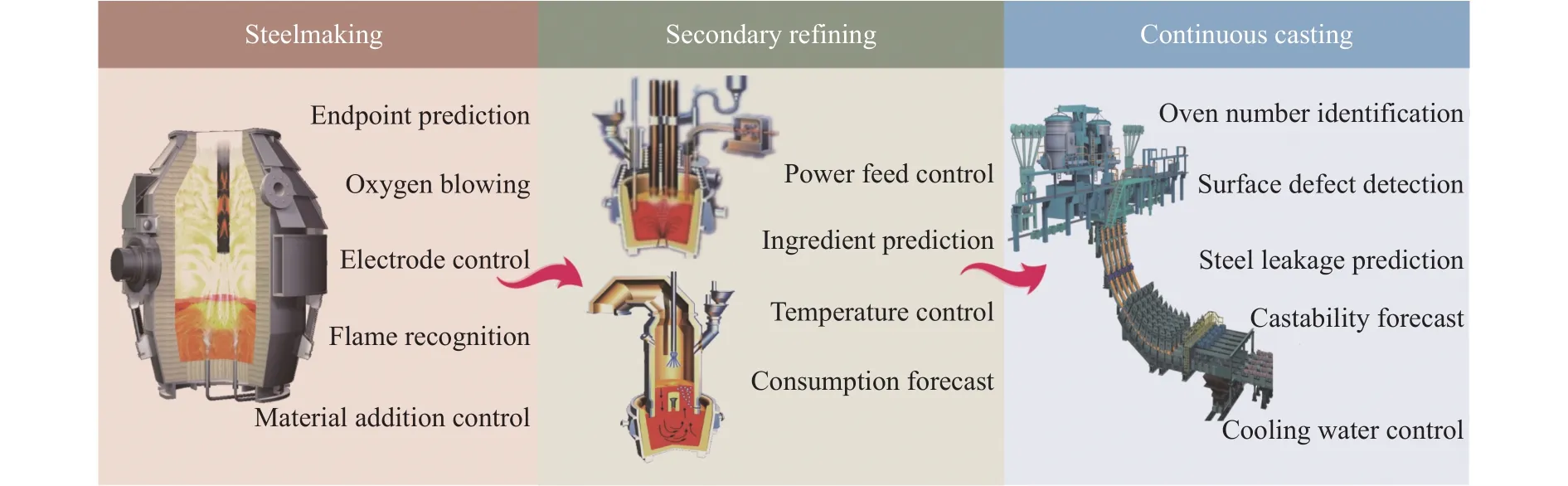
图4 深度学习模型在炼钢过程中的部分应用Fig.4 Partial applications of the deep learning model in the steelmaking process
2.2 深度学习在不同场景中的应用
2.2.1 工艺过程预测及控制
钢液在熔融金属反应容器内发生影响因素多、过程复杂的多元多相高温物理化学反应,于整个工艺过程结束时获得符合要求的温度和成分,期间会积累大量数据信息.但由于缺乏有效的数据分析处理手段,这些数据资源未能得到充分解析利用;另一方面,熔池内实时信息无法获取,难以直接对过程做出判断.通过引入深度学习方法,如BP神经网络、RBF神经网络、基于带外源输入的非线性自回归神经网络等,可以在利用数据的同时实现工艺过程的预测与判断.
(1)转炉终点预测.
由于原料成分的波动,吹炼参数及辅料加入有差异,造成转炉冶炼终点难以稳定控制,因此建立预测模型对实际生产具有重要指导意义.利用已有物料信息和实时操作数据,建立终点预测模型,有针对性地调整工艺,可实现对终点成分的控制.传统的BP模型存在收敛速度慢和容易陷入局部极小值的问题,周朝刚等[24]和李长荣等[25]分别利用优化算法改进BP神经网络,以石灰量、铁水量、铁水温度、萤石量、铁水碳含量、铁水磷含量、吹氧量等为评价参数对转炉终点磷含量进行了预测,误差值为±0.008%时,命中率可达93.33%.He与Zhang提出了一种基于主成分分析和BP神经网络对BOF(碱性吹氧转炉)终点磷含量进行预测的深度学习模型,利用主成分分析减少影响因素维数,应用结果表明,预测误差在±0.007%、±0.005%和±0.004%以内时,终点磷含量命中率分别为96.67%、93.33%和86.67%[26].高放等提出了基于FA−ELM(因子分析法−超限学习机)的转炉终点磷预测模型,较传统BP神经网络模型具有更高的准确性和更强的泛化能力[27].铉明涛等利用FOA(果蝇算法)优化后的GRNN(广义回归神经网络)预报转炉终点碳和温度,使模型具有精度高、训练简单和计算时间短等优点[28],更加适合反应速度快、数据量巨大的转炉冶炼过程.祁子怡等采用k−均值聚类算法确定隐藏层中心,采用最小二乘法调整RBF神经网络的权值,解决了RBF神经网络隐含层节点的个数及异类样本距离阈值难以确定的问题,提升了终点预报精度[29].同样,张辉宜等利用AP(近邻传播聚类算法)对RBF神经网络进行训练,大幅提高了Q235B终点预测命中率[30].Wang等通过结合GA(遗传算法)与BP神经网络的优点,建立了GA−BP神经网络组合模型,用于转炉终点锰含量的预测,预测误差在±0.03%和±0.025%以内时,命中率分别为90%和84%[31].
(2)电炉终点预测.
电炉炼钢相较于转炉炼钢过程废钢比更高,对于入炉原料把控显得更为重要,由于废钢成分的差异性,造成电炉终点碳具有不稳定性.电炉熔池中发生的化学反应与加料、送电等操作间存在强耦合作用,通过对操作过程进行有效学习,调整模型参数,可实现高命中率终点预报.刘志明等选择电耗、氧耗、生铁量、废钢量、碳粉量、天然气耗量、石灰量和上一炉留在电弧炉内的C、P元素的质量分数9个影响因素作为模型的输入,采用BP神经网络建立了终点碳预测模型,误差值为±0.004% 时,命中率可达 94%[32].马戎对 100 t电弧炉建立RBF神经网络模型预测钢水主要成分,并与BP神经网络对比发现该模型具有收敛速度快、可避免陷入局部极值的特点[33].刘锟等构建了网络结构简单、训练量小的增量神经网络,以废钢、铁水、装料制度、通电时间、吨钢氧耗和电耗作为输入特征,对电弧炉冶炼终点的温度、碳和磷含量误差值分别为±10 ℃、±0.02%和±0.004%时,命中率分别为93%、75%和86%[34].
(3)精炼过程温度控制.
炼钢过程中温度控制是极为重要的环节,转炉后流转过程中温度波动起伏大不仅会造成能源损失,对钢液品质也不利.为获得合理的精炼温度制度,保证连铸过程稳定的过热度,同时将信息化程度高的精炼工序所产生的数据充分利用,研究人员开发出不同深度学习模型用于该工序控制.李强与曹刚将专家系统和BP神经网络相结合,建立了LF(钢包精炼炉)钢水温度预测模型,误差值为±5℃时命中率达到85%[35].吴扬针对250 tRH−MFB(多功能钢液真空循环脱气精炼技术)采用具有较高容错抗干扰能力的NARX(基于带外源输入的非线性自回归神经网络)建立真空精炼钢液温度预测模型,误差值为±5 ℃时命中率达到了89.5%,并能准确计算出合金加入量[36].贺东风等[37]、付国庆等[38]、以及冯春松等[39]分别提出了基于传热机理和BP神经网络的精炼过程钢水温度预报混合模型,克服了单一的数学模型或智能模型的缺点,更适合实际炼钢过程应用.
2.2.2 物料消耗优化控制
随着钢铁企业对精益生产的重视程度日益提升,粗放的物料加入制度弊端越来越明显.但由于炼钢各工序变化因素多,物料消耗难以通过线性模型准确预知.将DBN(深度信念网络)、Elman神经网络和对角递归神经网络等引入物料管控过程,依据历史数据预测当前炉次加料量,能够起到良好的降本增效作用.
(1)供氧模型.
转炉炼钢过程中吹氧主要是为去除杂质元素,控制终点碳和温度,因而转炉冶炼吹氧量的确定,对于转炉炼钢至关重要.深度学习模型对历史吹炼数据进行优选,采用自学习的方式改变神经元之间的连接权值,分析不同条件所对应的供氧模式.付佳等先利用静态模型计算出原辅料的加入量以及理想状态下的供氧量,再利用得到的结果和给定的初始条件,使用BP神经网络预测出转炉吹炼实际所需供氧量[40].为克服BP神经网络收敛慢、易出现过拟合的缺点,艾晓礼等利用LM(列文伯格−马夸尔特)算法改进了BP神经网络,预测炼钢过程总吹氧量和动态吹炼过程二次吹氧量[41],李爱莲等[42]、张子阳与孙彦广[43]则分别采用灰色模型改进学习过程较慢的DBN和输出状态存在稳定性问题的Elman神经网络,依据大量原料成分及操作数据,建立了供氧量预测模型,通过加料信息预测炉次氧耗量.
(2)原辅料加入控制模型.
以铁水、铁矿石和废钢等为代表的炼钢原料在以合金、渣料等为代表的辅料资源配合下完成了从含铁资源到钢材产品的转化.但在物料加入过程中不能直接对钢水成分在线连续检测,且存在多项工艺参数扰动,难以建立准确的传统数学模型进行有效控制,因此需建立非线性的深度学习模型.杨志勇与任小佳利用BP神经网络对铁水预处理粉剂用量进行控制,避免了过吹和欠吹对生产节奏的影响,提高了预处理脱硫效率[44].为优化辅料加入量,张华等首先使用具有适应时变能力的DRNN(对角递归神经网络)进行终点预测,而后利用改进的SLS−PSO(随机局部搜索−粒子群优化)算法对优化模型求解,使得终点控制过程辅料节约量为15%左右[45].欧青立等对LF炉利用常规PID(比例−积分−微分)算法加料进行改造,设计了一种PSO(微粒群优化算法)的BP神经网络应用于配料称重系统,实现了快速精准配料的目标[46].
2.2.3 异常预报与质量评价
炼钢过程存在异常状况研判依据不强,精准预测和防控难度高,产品质量实时在线检测困难等问题.利用广义回归神经网络、卷积神经网络和残差神经网络等深度学习方法能够根据大数据挖掘提取预警阈值,并基于设定标准及时判定生产过程的质量问题,对炼钢工序过程形成具有自学习能力的异常状况预报及产品质量评价系统.
(1)火焰识别.
钢液冶炼过程中的物理化学变化无法直接观测,技术工人通常采用观测火焰的方法判断反应情况,但存在主观性强、火焰物性变化大等问题[47].随着深度学习研究的深化,对冶炼炉火焰图像进行特征提取,数字化之后利用神经网络完成分类预测的相关研究成果不断涌现.Ma等以AOD(氩氧脱碳法)冶炼的喷溅过程为研究对象,利用BP神经网络建立了喷溅预测模型,可实现对喷溅的准确判断并能有效控制[48].庞殊杨等采用抗干扰能力强、检测速度快的ResNet(残差神经网络)对转炉火焰数据集进行有监督的训练,训练完成后可对正常、轻微跳渣、跳渣、轻微固体喷溅、固液喷溅、液体喷溅、黑烟和火焰8种状态火焰进行高准确性实时监测,达到异常情况预报的目的[49].李超与刘辉对转炉终点时刻炉口火焰图像利用改进的多趋势二进制编码彩色纹理特征表述方法进行特征提取,并选用GRNN建立预测模型,该模型的收敛速度快,但空间复杂度高,当误差值为±0.02%时,命中率为95.7%[50].
(2)连铸坯表面缺陷检测.
连铸坯生产中卷渣、偏析、保护渣性能、结晶器锥度和震动不合理均会造成表面缺陷,生产企业一般采用人工观察和设备探伤相结合的检测方式,成本高且效率较低.如何满足现场环境快速实时检测要求是各生产企业面临的难题,将深度学习模型应用于铸坯图像识别中,既能避免人工造成的误判,又能快速发现并解决问题.毛欣翔等通过gRPC(谷歌远程过程调用)框架构建了基于YOLOv3模型的板坯表面缺陷检测系统,并搭建了基于循环式卷积生成对抗网络的缺陷数据生成平台,在完成检测要求前提下对表面缺陷图像进行有效扩充[51].Konovalenko等开发了一种利用Res-Net神经网络进行连铸坯缺陷分类的深度学习模型,对缩孔、裂纹和翘皮三种缺陷识别精度为96.91%[52].安波等通过传统BP和具有自组织功能的Kohonen两种神经网络并行运算,实际测试中数据采集、运算和判定总耗时小于3 s,铸坯质量判断准确率能够达到92%[53].韩舟利用增加动量因子改进后的BP神经网络建立了铸坯质量判定模型,误差值在±10%以内时,命中率达97.2%[54].
(3)连铸漏钢预报.
连铸是实现高温钢水由液态向固态转变的工艺,同时由于该工序钢液处于动态过程,因此也是最容易出现漏钢事故的环节.一旦发生漏钢事故,往往会造成设备损毁和人员伤亡的重大安全生产责任事故,国内外学者为解决这一问题将深度学习模型引入到连铸漏钢预报中.范建东等利用RBF神经网络结合漏钢温度特征曲线,建立了连铸漏钢预报模型,有效提高了预报精度并且降低了误报率[55].杨琴与彭力针对传统神经网络收敛速度和精度的问题,建立了具有较强泛化能力的量子小波神经网络模型,实现了快速准确的连铸漏钢预警[56].Zhang等利用GA−BP神经网络预测连铸过程漏钢,预测率为100%,准确率为97.56%[57].厉英等采用变步长的改进算法建立了BP神经网络模型,并引入动量项和防振荡项来避免局部极小值[58].
3 深度学习在炼钢过程中的优势与挑战
3.1 优势
3.1.1 特征提取简单
算法准确性高度依赖于数据特征提取,其可视作一个数据降维过程,即将原始数据转化为具有一定区分度和维度特征的数据.机器学习中人工提取特征的方法,例如过滤法、包裹法、嵌入法等,存在过程复杂、计算量大的缺点.深度学习在设计上模拟了人脑,可以尽可能优化损失函数,自动挖掘数据潜在特征,不需要确定性编程就可以赋予机器某项技能.炼钢过程提取的原始数据特征是影响结果预报的重要因子,且由于钢铁生产是一个动态调整过程,原始数据特征除了初始含铁物料(如废钢、生铁、矿石等)加入量是固定的,其他一些信息(如温度、工序时间和成分、吹氧量、补加渣量、合金加入量等)都随生产实际随时变化,这就造成了实际炼钢过程数据呈现高维特征的问题.若将这些原始数据全部作为输入参量进行传统过程模型计算,容易导致模型过于复杂甚至难以收敛.神经网络以样本学习的方式,直接从炼钢过程的输入输出关系中提取信息,通过反复训练不断调整神经元相互作用的权值,而无需借鉴先验知识的积累或人工逻辑的归纳与推理.
3.1.2 泛化能力强
泛化能力是指训练后的神经网络正确预测和识别训练样本集外其他样本的能力.根据机器学习的经典理论,模型参数量越大,模型的拟合程度越强,但同时泛化能力也会更差.然而在深度学习中并没有观察到这种现象,深度学习的模型通常有着巨大的参数量,测试数据远多于训练数据,实际应用中,在真实数据上训练的深度学习模型通常具有很好的泛化性能,增大模型的参数量,并不会使得泛化变差.在炼钢工业场景下应用,可将部分已有生产数据作为训练数据集,深度学习模型能够用于对结果做出预报.且随着生产数据积累,神经元之间的权值不断调整,通过自学习进一步提高模型泛化能力.这主要是由于平滑简单的函数比振荡复杂的函数有更好的泛化能力.深度学习模型从数据特征的低频成分开始学习,当达到数据的最高频率时,频率空间误差等于实域空间误差,所以模型学习也就此停止.因此,训练数据能够限制深度学习的拟合函数,对于低频的初始化,激活函数平滑性较好,从而使深度学习模型具有更好的泛化能力.
3.1.3 模型可塑性高
深度学习的网络结构和模型功能具有良好的可塑性,针对纷繁复杂的使用场景呈现出强大的智能化特性和普适能力.神经网络作为一种通用模型,可视为高维特征变换器,能够对任意非线性变化进行最优拟合,通过强化、竞争和代谢等机制自动寻找输入特征数据中的内在规律和控制属性,神经网络节点数以及各节点对应的权值都可以在运行中进行自适应调整.现代炼钢工艺主要有长流程和短流程两种路线,但各企业生产装备千差万别,操作制度也不尽相同.若用传统模型解决生产实际问题,只能应用于当前场景下,迁移至其他环境时,由于物料及设备的不同,需要重新建立模型,增加了改进成本.一机一模型的模式是影响智能制造在钢铁行业落地并可持续发展的关键环节.深度学习模型只需要输入特征数据重新训练,就能自动调整模型参数,以适应新的使用场景.这使得它具有很强的可塑性,同一个模型可以持续自我优化,在不同生产单位取得相似的使用效果.国内外各大钢铁企业及研究机构希望深度学习和人工智能可以更加致力于改善生产环境,提高产品质量,降低人力成本,纷纷在智能化发展方向布局,如表3所示.

表3 国内外炼钢企业智能化发展布局Table 3 Intelligent development layout of domestic and foreign steelmaking enterprises
3.2 挑战
3.2.1 数据依赖性高
深度学习模型的参数选择不依靠理论基础和先验知识,纯粹为数据驱动,这既是神经网络的优点,但同时也意味着其对数据质量和总量存在高度依赖.但实际生产中,一方面,钢铁企业通常不愿意对数据质量进行验证,因为这会额外增加生产成本.以炼钢厂的LF炉为例,即使做出使用的安全性模型,在预测到电极可能存在问题时,需要企业配合验证,甚至要停炉检查,这对炼钢厂是不小的成本.因此,冶金领域通过验证的标签数据极其宝贵.对于一些钢铁企业而言,工序过程台账是靠人工录入,记录信息可能存在偏差,即使通过在线系统采集,工艺发生的问题也往往记录不准确;同时工艺数据记录的好坏也不直接与基层工人的绩效考核关联,在不发生质量问题前提下,此类岗位没有足够动力去重视数据记录质量.另一方面,相比互联网场景下PB(皮字节)级大数据,钢铁行业搜集的数据量级较小,面向炼钢过程特定任务建模,很难获取足够的数据.以转炉终点预测模型为例,终点成分和温度是关键的检测指标,在对转炉冶炼流程建模时,其中最难的点在于连续冶炼中,如何准确地对将物料信息实时更新到模型,尤其是频繁加料操作过程.这也意味着,必须要有冶炼状态下的异常数据,才能验证模型是否可靠.此时相比生产数据有多大规模,数据能否覆盖所有生产状况显得更为关键.然而冶炼过程的异常数据往往很少,因为一旦出现不合格产品,钢厂会立即采取调整措施.所以为使深度学习模型获得高质量数据,需企业注重现场采集数据的可信度,既要提高传感器布置数量和测量精度,更离不开操作人员思想观念的提升,除保证正常运行过程数据准确记录外,也需要将异常数据进行归档总结.
3.2.2 预处理难度大
深度学习模型的成功依赖于高质量标记的训练数据,训练数据中存在标记噪声会大大降低模型在测试数据上应用的准确性,因此对炼钢过程信息采集、传输和运算提出了更高要求,如图5所示.由于炼钢过程复杂,采集的数据容易受现场环境以及传感器测量精度的影响,因此存在干扰信号,为了准确建立神经网络,原始数据需经预处理后再进行特征提取.并且各维数据来源及度量单位不同,未进行预处理前数据分布范围差异明显,取值范围跨度大的特征在计算权值时占主导地位.这些因素共同增加了炼钢过程数据的预处理难度,首先在现场取得数据后需要借助人工经验或理论计算将错误值剔除,这一过程不能简单依靠数据处理软件实现.剔除错误值后,数列会出现空位,影响模型运行的连续性,只有运用一些推测方法,如平滑曲线法、插值法、比例估算法等,进行残缺补足,才能将错误数据影响最小化.另外归一化处理方式的选择也会对模型产生影响,常用的归一化方式包括但不限于简单缩放、逐样本均值消减和特征标准化等,需根据实际情况进行方法优选.
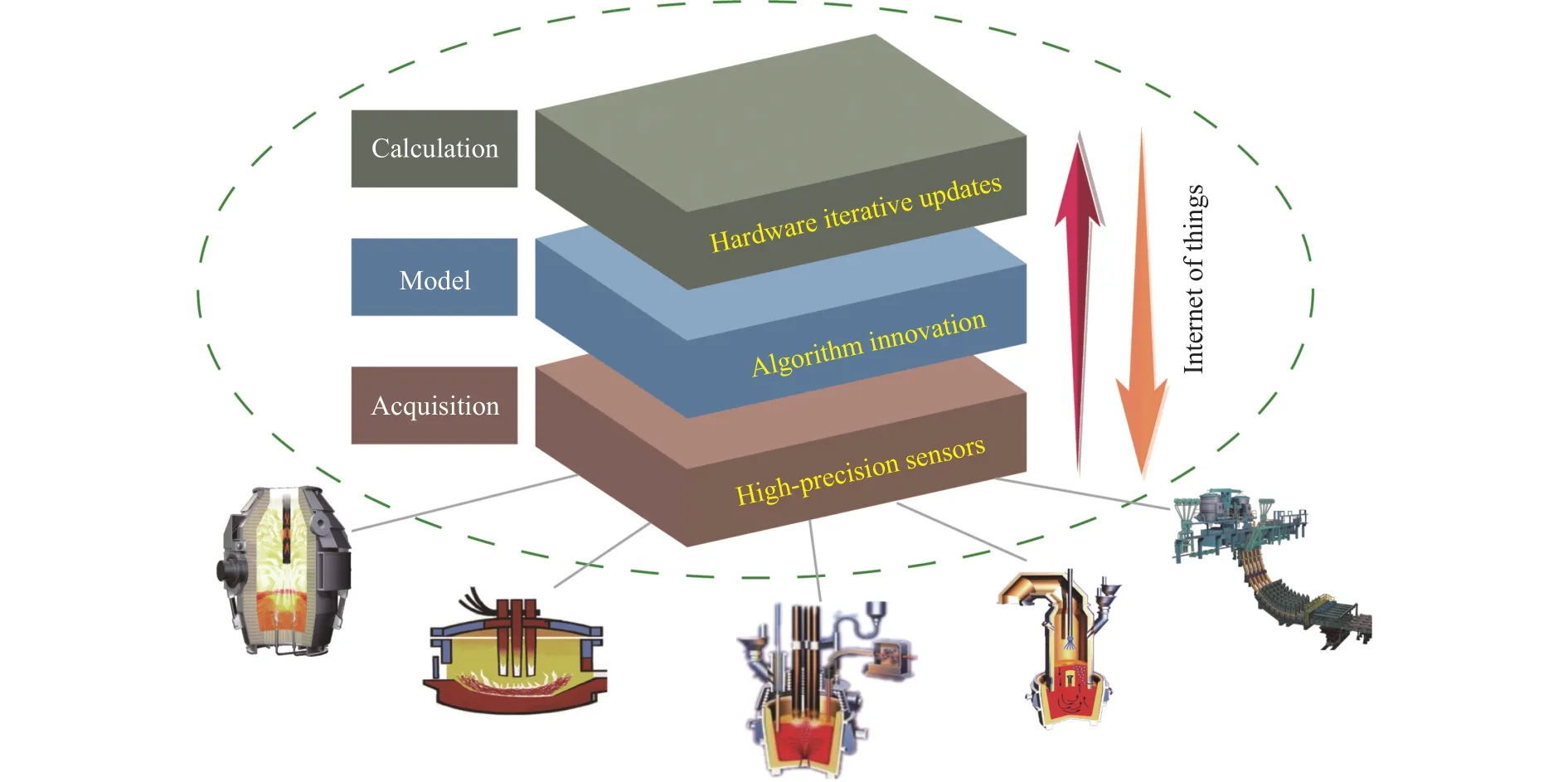
图5 炼钢过程信息采集、传输和运算的要求Fig.5 Requirements for information collection, transmission and operation in steelmaking process
3.2.3 生产安全性有待验证
深度学习模型本身缺乏可解释性,易出现难以解释的结果,在炼钢这个对机理分析要求苛刻的领域是比较忌讳的.在核心工序环节应用首先考虑的是生产安全,一旦出现问题,将造成很大的损失.以精炼过程合金加入为例,合金元素被誉为钢铁工业的“味精”,铁合金加入的时机以及用量,直接影响钢材产品的质量.利用神经网络根据钢液条件加入合金,可以有效提高合金收得率,降低吨钢合金耗量.但如果模型受到噪声干扰或因传感器失效,在无人为干预状况下,钢液内合金元素含量将低于下限或超过上限,产品不得不进行回炉或降级处理.深度学习工业生产安全性有待验证的核心原因是,炼钢过程的工艺复杂度与应用门槛都非常高,当前可供建模的特征数据量普遍匮乏不能覆盖所有工况,且缺乏必要冶金学机理,仅靠数据驱动的模型很难具备较好的说服力与可靠性.针对炼钢企业不同应用要求的最佳解决方案如表4所示,发生频率高、结果影响严重的场景是最适合利用深度学习模型来解决的,主要因为该场景下有足够的数据量,且数据标签完整,样本均衡.可首先在该场景下进行大规模推广应用,在取得稳定效果并验证了深度学习模型可靠性后,逐渐向其他场景发展.

表4 炼钢企业不同应用要求的最佳解决方案Table 4 Best solution for different applications required by the industry
4 总结及展望
钢铁行业的智能化当前仍处于发展初期,多数钢铁企业的智能化只是把各生产工序过程数据进行了数字化呈现和简单处理,距离完全利用数据驱动进行分析和决策尚需时日.尽管深度学习作为推动第四次工业革命的重要技术之一,在炼钢过程的应用极大促进了钢铁工业智能化的脚步,但由于其具有数据依赖性高、预处理难度大以及生产安全性有待验证的特点,当前仍集中应用于简单场景,无法全面开花.相信在不久的未来,以下几方面的技术发展将有助于深度学习模型在炼钢过程普及率的大幅提升,在生产过程中给出既快速又精准的决策.
(1)高精传感器的应用:高精度传感器是深度学习模型应用的基石,可以说传感器让智能化生产设备有了感知能力,可用于检测从距离、温度到压力、成分等的各种属性.随着钢铁行业智能制造的不断深入,对传感器要求也越来越高,相反,高精度数据信息获取将有效降低深度学习模型输入特征的噪声值,为模型建立和训练提供更多高质量标签数据.
(2)物联网的普及:如果将传感器作为智能化生产设备的感觉器官,那么物联网就是它的中枢神经.利用物联网技术将炼钢过程各工序节点的设备监控、物料消耗监测、过程取样检测相连接,实现了对钢材生产过程中各因素的实时数据采集,以供深度学习模型使用,同时由模型所发出的指令即时传达到执行端,可提高炼钢环节制造效率,减少不必要的资源消耗,优化工艺过程.
(3)计算硬件的迭代:深度学习模型运行效率高度依赖硬件计算能力,而且更大规模和更复杂的深度学习模型已经被证明非常有效,可以显著降低错误率.炼钢企业计算设备的更新甚至借助智能化平台开展云计算,将训练周期大大缩短,能够反复调试参数以获得最佳效果,对模型的成功应用起到至关重要的作用.
(4)算法的创新:算法是模型发展的内在驱动力,近年来各种创新算法雨后春笋般涌现.开发一种特征提取能力强、训练过程高效,具有自我反复纠错能力的深度模型,是当前炼钢流程所迫切期望的,除了在已有神经网络基础上改进,从根本上创新也是必不可少的.
借助深度学习模型,炼钢企业可以减少人为操作,以传感器数据采集、设备之间的数据传输和中央处理器的模型计算完成冶炼操作,以此来提高炼钢工艺过程的洁净度、效率和绿色化程度.未来深度学习模型在更多冶金场景下的应用,必将为钢铁行业带来新的发展动力,让炼钢这个传统劳动密集型行业焕发出智能化光彩.
猜你喜欢
现代电力(2022年2期)2022-05-23
快乐学习报·教育周刊(2022年16期)2022-05-01
昆钢科技(2022年1期)2022-04-19
昆钢科技(2022年1期)2022-04-19
新疆钢铁(2021年1期)2021-10-14
中学生数理化·中考版(2020年12期)2021-01-18
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
电子制作(2019年19期)2019-11-23
福建基础教育研究(2019年6期)2019-05-28
电子制作(2019年24期)2019-02-23
