
基于YOLOv4改进算法的人群异常行为检测研究
2022-06-16 03:29施新凯张雅丽李御瑾赵佳鑫
现代计算机 2022年7期
施新凯,张雅丽,李御瑾,赵佳鑫
(中国人民公安大学信息网络安全学院,北京 100038)
0 引言
随着经济文化的快速发展,人们的社会活动也与日俱增,交通出行站点、大型活动现场以及大型商场等公共场所会出现人群聚集的情况,人群聚集往往可能出现矛盾纠纷事件,主要包括打架斗殴、非法纵火、打砸公物等。利用智能视频异常检测技术能够对人群异常行为进行检测并预警,可以减少群体性非法事件的恶化,保障群众的生命财产安全。
Afiq 等将异常检测分为基于高斯混合模型、隐马尔可夫模型、光流法和时空技术等传统方法。传统的异常行为检测方法在区域选择及特征提取方面需要人工参与较多,客观性不足且多数异常场景较为单一,满足不了当今人群异常事件检测的精度和速度要求。基于深度学习的人群异常事件检测更有利于特征提取和场景迁移。彭月平等利用三维卷积神经网络(C3D)提取HOG 时空特征,提高了对人群行为的表征能力。胡学敏等将视频帧划分为大小相同且互不重叠的子区域以实现异常人群定位,然后将子区域输入改进的C3D 模型提取行为特征并输出正异常分类概率。罗凡波等将视频分割成多个子区域,并基于YOLOv3算法检测异常行为的诱因,然后利用光流法获取人群的平均动能判断人群是否出现异常。熊饶饶等提出一种新的综合光流直方图特征描述人群行为,采用SVM 作为分类器,并利用网格遍历搜索法结合交叉验证法获取最佳参数对分类器训练。李萌等提出一种相互作用力直方图(HOIF)用来描述运动信息特征,将其与显著性信息特征相融合送入支持向量机(SVM)进行学习训练,从而对人群事件进行分类。张娓娓等提出一种改进的C3DRF 检测方案,在保证对异常行为分类精度的同时,显著提升了训练效率。
但当前人群异常事件检测研究存在不足,主要因为异常行为在不同场景下定义不同,难以泛化;异常事件发生概率低导致正负样本不均衡,难以学习足够的异常行为特征;异常检测实时性差,无法满足当前视频目标追踪的需求。随着深度学习在目标检测领域的快速应用,用目标检测的方式检测人群中的异常目标,检测准确率以及实时性可满足对监控视频数据处理的要求。其中,YOLOv4算法在目标检测领域已经较为成熟,其检测准确率及检测速率均优 于SSD、YOLOv3、Faster-RCNN。目前,有关YOLOv4改进算法的研究中,主要改进思路是提高网络的特征提取能力,从而提升模型的MAP 值。陈梦涛等通过在原主干网路中嵌入新型注意力机制CA 模块,提升了网络对小目标的特征提取能力。康帅等提出了在YOLOv4 主干网中加入混合空洞卷积,提高了网络对行人特征的提取能力。
本文针对YOLOv4算法的主要改进方法是在主干网络区域增加两层卷积模块,为深层的网络传递更多的位置信息,且采用移动指数平均值(EMA)更新网络参数来优化训练模型;然后用Mixup 代替YOLOv4 中的Mosica 数据增强的方法,以便增大训练的数据集;最后改进YOLOv4的特征融合结构(PAN),从而在特征融合时传递更多的语义信息。
1 YOLOv4改进算法
1.1 改进Mixup替代Moscia函数
YOLOv4算法使用的是Moscia 数据增强的方法,在理论上与CutMix 有一定的相似性,Cut-Mix 是将两张图片进行拼接,Moscia 是每次读取四张图片进行缩放、翻转、合并成一张图片对其检测,如图1所示。

图1 YOLOv4采用的Moscia数据增强方法
为增大训练的数据集、提升算法的鲁棒性,本文采用Mixup 替代Moscia 数据增强函数。但Mixup 函数采用的是Beta 分布函数,Beta 分布函数原理是直接对图像进行叠加,对图像语义特征进行融合,而这样图像并不能展现原图像中丰富的语义信息。因此本文在其基础上对Mixup函数图像融合的方式进行了一定的修改,采用0.2~0.8的均匀分布来选取图像融合的系数,可以让原来的图像特征表达得更加丰富,效果如图2所示。

图2 Mixup改进版图像增强效果
1.2 主干特征提取网络改进
本文借鉴Resnet 残差网络的思想,加深网络长度为深层网络传递更多的位置信息。但如果在浅层的网络结构中增加更多的卷积结构会导致整体网络难以训练,且没有明显的效果提升;如果在深层网络添加卷积结构会导致整体网络参数增长比较大,进而引起模型检测速度的大幅度降低。于是在Darknet53 的基础上,在如图3 所示的主干网络区域增加两层卷积模块,主干特征提取网络的参数量增长较少,检测速度几乎没有下降。

图3 主干特征提取网络上增加两个卷积模块
1.3 EMA更新网络参数
为提高模型的测试指标并增加其鲁棒性,本文提出使用指数移动平均值(EMA)更新网络参数。EMA 是用来估计变量的局部均值,从而使得时刻变量的数值不只是取决当前时刻的数据,而是对时刻附近进行加权平均,使得更新得到的数值变得更加平滑,不会受到某次异常数据的影响,提升模型的鲁棒性。原EMA 算法如公式(1)所示。
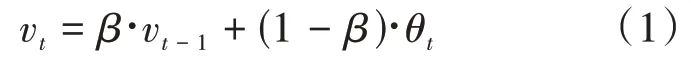
式中v表示第次更新的所有参数移动平均数,表示权重参数,θ表示在第次更新得到的所有权重参数。YOLOv4没有采用动态的系数来更新网络的权重,在此基础上对引入的EMA 算法做出相应的改进,本文的改进点主要是对模型每个epoch 训练得到的参数进行指数平均加权计算。算法如公式(2)所示。

式中等号右边的N是第次模型训练得到的结果,左边的N是加权计算得到的结果,N- 1是第-1 次模型加权计算得到结果,是一个占比参数。由于训练后期模型准确率逐渐提升,得到的模型参数准确性较高,因此训练后期N- 1需降低占比参数值,训练初始阶段需调高占比参数值。本实验主要将模型训练分为四个阶段,第一阶段设置为0.9950,第二阶段设置为0.9970,第三阶段设置为0.9990,第四段设置为0.9998,实验结果表明测试指标和鲁棒性高于原模型。
1.4 改进PAN结构
YOLOv4算法采用的是在FPN 的结构上改进的PAN 结构,FPN 结构是指自顶向下将特征提取网络结构中的高层特征与低层特征进行融合得到的特征图,PAN 结构是指自底向上将低层特征与高层特征融合得到的特征图。使用FPN+PAN 的特征融合方式相比较YOLOv3 中的FPN有着更高的语义信息,结构如图4所示。

图4 YOLOv4采用的PAN结构
为使模型融合特征效果得到进一步的提升,借鉴FSSD采用一种新的结构,采用的方式是将特征提取网络中高层特征进行上采样再将这些特征进行结合,再次使用FPN+PAN 的结构对这些特征进行特征融合,可以在特征融合时传递更多的位置信息和语义信息。改进后的PAN结构如图5所示。

图5 改进版的PAN结构
2 实验及结果分析
2.1 实验环境及数据集
本实验是在Ubuntu 18.0 操作系统的服务器上进行编程实验。GPU 使用的是英伟达2060,使用CUDNN 进行GPU 加速。采用的数据集是从互联网上搜集的持刀、纵火、烟雾图片数据集。
2.2 YOLOv4算法改进实验
通过将搜集的持刀、纵火、烟雾的图片数据进行过滤,获得火焰数据集样本图片357张图片,持刀的数据集样本图片398张,烟雾的数据集样本图片1865 张,将数据集通过labellmg 对图片进行标注,在训练模型的过程中,其中的参数设置如表1所示。
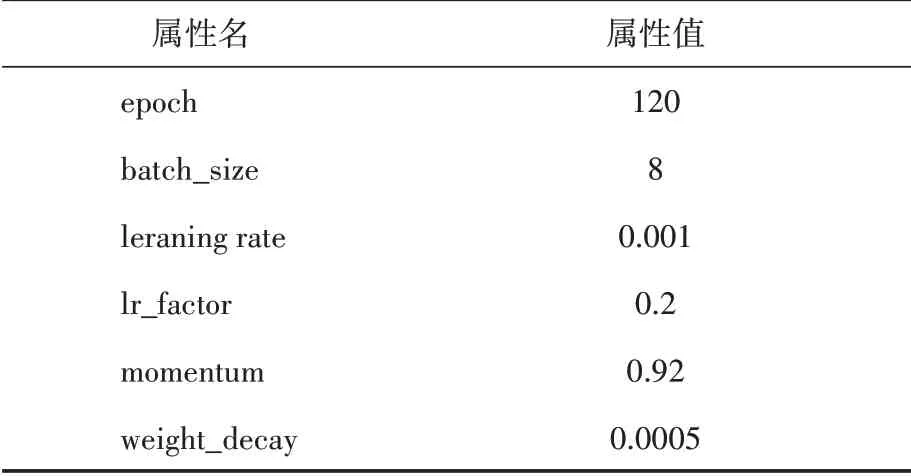
表1 YOLOv4改进算法模型训练参数
将改进版YOLOv4 算法与YOLOv4 算法训练的模型进行目标检测,其对比效果如图6所示。

图6 检测效果对比实验
其中fire、smoke、knife 三种类别的图像检测准确率均有提升,在图(a)中原版YOLOv4 算法检测knife类别时产生误检,而在图(b)中改进后的YOLOv4 算法能对knife 类别正确检测。实验结果表明改进后算法检测结果的置信度高于原版YOLOv4算法,改进后的算法鲁棒性更高。
2.3 实验结果分析
本实验主要从三个评价指标来评价该训练模型,分别是: 平均精度均值(mean average precision,MAP)、召回率(recall)、每秒检测图片的帧数(frames per second,FPS),其中需引入准确率(precision)。算法如公式(3)、(4)所示:

T表示预测到的正样本的正确数量,F表示预测到的正样本的不正确数量,F表示预测到的负样本的不正确数量。曲线围成的面积就是某一个类别的值,其中值是对所有类别的值进行求平均得到的。值越大,则表示该模型识别目标的精度越高。结果如图7、图8所示。
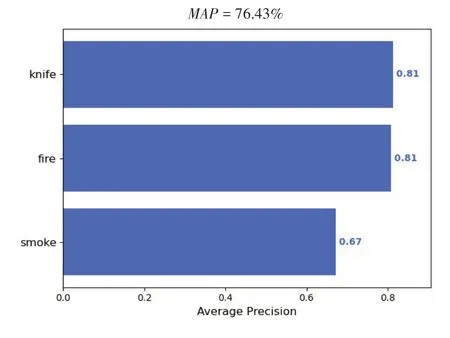
图7 原YOLOv4算法的MAP值

图8 改进版YOLOv4算法的MAP值
为进一步验证本文改进的YOLOv4算法的鲁棒性,将原YOLOv4 算法、EMA 改进网络参数(YOLOv4_ema)算法、本文改进算法三个算法在此数据集上进行验证实验。测试平均精度均值()、每秒检测图片的帧数(FPS)值,如表2所示。
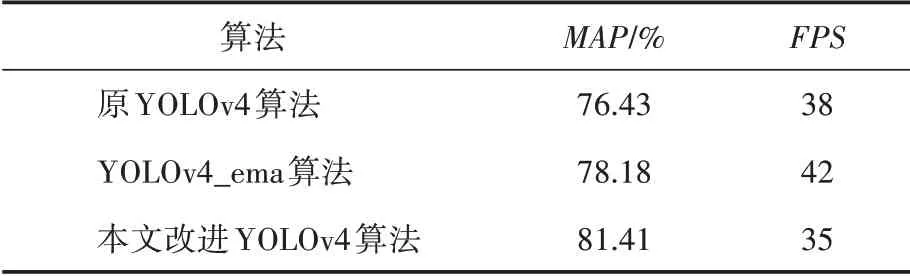
表2 YOLOv4改进算法对比结果
对比实验数据可知,本文改进版YOLOv4算法有更高的检测平均精度均值,值为81.41%,原 版YOLOv4 的值 为76.43%,YOLOv4_ema 的值为78.18%。实验表明,改进版YOLOv4模型的检测准确率更高,且鲁棒性更强,同时在处理视频的速度上,改进过的YOLOv4 算法FPS 略低于原版算法,但可以满足对监控视频进行实时检测的需求。
3 结语
本文提出了基于YOLOv4改进算法的人群异常行为检测方法,实验结果显示改进版的YOLOv4 算法在本数据集上训练模型得到的较原版算法提升了近5%,其中fire、smoke、knife的检测准确率较原版算法分别提升了4.64%、7.61%、2.68%;在处理视频的速度上,改进版YOLOv4 算法的FPS 略低于原版算法,但可以满足对监控视频进行实时检测的需求。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
阅读与作文(英语初中版)(2019年8期)2019-08-27
电机与控制学报(2018年9期)2018-05-14
百花洲(2018年1期)2018-02-07
智富时代(2018年12期)2018-01-12
智富时代(2018年12期)2018-01-12
瞭望东方周刊(2017年45期)2017-12-08
计算机应用(2016年10期)2017-05-12
中学生数理化·高一版(2017年1期)2017-04-25
中学生数理化·高一版(2017年1期)2017-04-25
