
一种改进的卷积神经网络在手写字体识别中的应用研究
2022-06-15 10:21刘影徐辉刘世军张铁梅
商丘师范学院学报 2022年6期
刘影,徐辉,刘世军,张铁梅
(1.安徽电子信息职业技术学院 软件学院,安徽 蚌埠 233030;2.蚌埠学院 计算机工程学院,安徽 蚌埠 233030;3.海军士官学校图书馆,安徽 蚌埠 233012)
近年来,卷积神经网络在图像识别、目标检测、语音和文字识别等领域取得了突破性的进展,而优化卷积神经网络成为关注的焦点.卷积神经网络的结构设计起源于LeNet样式模型[1],该网络模型用于图像数据的特征提取和网络空间的子采样的最大池化操作.2012年,该思想被应用到AlexNet体系结构中[2]:在整个隐含层的卷积运算中,多次采用最大池化操作,从而使低维度的特征得到更直观的体现.2014年VGG16在图像识别率方面取得大的突破[3],受到学术界和工业界的高度关注.
针对手写字体的识别,卷积神经网络和传统的BP神经网络在算法优化和结构方面具有共同的缺点,例如训练时间长和容易陷入局部最优解从而导致过拟合现象等.近年来,随着计算机性能的不断提高,国内外学者为了提升卷积神经网络在文字、语音等领域的识别率,提出了许多优化策略.文献[4]提出了一种二进制的CNN深度信念网络用于行人的再识别,取得较好的效果,但该方案不能学习出人体边缘的高级特征.文献[5]提出了多通道输入的改进CNN方法,在输入图片数据之前对像素进行多尺度的分割操作,然后对应每个像素通道进行学习,实验结果表明有一定的效果.文献[6]采用了CNN与SVM相结合的方法进行手写数字识别,实验结果表明该方法优于传统的分类器.文献[7]通过改进CNN中隐含层特征融合的能力并且与其他传统的分类算法进行组合用于解决年龄识别的问题,但是该方法导致了模型结构复杂化.
本文提出了一种改进的卷积神经网络,用于手写字体的识别.在模型的训练过程中,采用多特征像素点融合的方式高维度的表达出手写字体的特性,充份提取图像的特征信息;并对卷积神经网络的目标函数进行正则化,使其跳出局部最优解,进而提升泛化能力.通过实验验证,提出的算法在一定程度上减少了训练和测试时间,且提高了识别的准确率.
1 手写数据集预处理
为了提高手写字体的识别精度,使用神经网络和传统的机器学习方法对图像进行检测和识别,首先要对手写字体的图像数据进行预处理,从而获取图像上具有代表的像素特征信息,核心流程包括灰度化、图像几何变换和图像增强处理等.
1.1 数据预处理
语义分割和字体识别是图像处理领域的重要的组成部分,常见的图像预处理方法为去均值、归一化、正常白化和PCA降维等.
(1)为了缓解神经网络模型在图像识别中过拟合的现象,一般采用去除均值的方法.因此采用灰度化、二值化和归一化处理,对原始手写字体图像RGB三个色彩通道分量加权平均得到灰度图像,然后采用全局阈值处理Ostu算法[7]自动选取最佳阈值T,最终达到二值化处理的目标.为了提高手写字体中不同笔画特征识别的准确性,将图像语义分割的像素点统一大小归一化成16×16或32×32像素.
(2)训练神经网络模型参数调整的时间通常比较长,其中一个重要原因是图像的维度高.本实验在数据输入之前进行PCA降维操作:一方面确保特征信息不丢失;另外一方面解决卷积神经网络模型本身的参数冗余问题,减少训练时间.除此以外,在采集手写字体数据集中,由于通过摄像头采集,过程中存在一定的倾斜,因此在预处理的过程中采用Hough变换[8]检测车道线图像的边缘直线并调整其倾斜程度.同时,本文还利用滤波器去除手写字体图像框线.
1.2 手写字体特征提取
特征提取是计算机视觉领域处理过程中的必要环节,核心是提取图像中具有代表性的字体信息[9].特征提取的结果是把手写字体图像上的点分成不同的子集,这些子集往往属于孤立的点、连续的曲线或者连续的区域,即特征向量的形成过程[10].
常见的手写字体特征主要包括统计特征和结构特征.统计特征是在二值或灰度值点阵图像的基础上,对数字图像点阵进行数学变换后提取的特征[11].结构特征主要描述手写体数字的几何结构,侧重于体现数字结构的本质特征[12].该方法能够很好的区分相似字体,可以得到识别正确率较高的分类结果,但易受到噪声等因素的干扰.本实验手写字体识别的原理如图1所示.

图1 手写字体识别原理图
2 改进的卷积神经网络
2.1 CNN网络基本结构

图2 卷积神经网络结构图Fig.2 Convolutional neural network structure diagram
卷积神经网络模型有许多经典的结构,例如:AlexNet、ZFNet、OverFeat、VGG、GoogleNetv1-v4和ResNetv1-v2等网络结构.这些典型的卷积神经网络结构核心包括输入层、卷积层、池化层、全连接层和输出层,具体如图2所示.
在卷积神经网络中,图像局部特征的抽取工作主要在卷积层和降采样层.相比于其他人工神经网络模型,其优点在于图像局部感受和权重共享,随着卷积层的增加,目标函数的优化变成非凹凸优化问题,间接的问题是选择超参数的初始值.较好的初始值能很好地优化函数收敛的稳定性,避免模型出现过拟合或者欠拟合的现象,从而得到最优值.假设卷积层为第i层,降采样层为第i+1层,则其特征层的计算公式如下:
xi=f(xi-1×wi+bi)
(1)
其中,xi为相应的卷积层;wi为训练的卷积核,即权重参数;bi为其偏置;f(x)为激活函数,常用的激活函数有sigmoid,tanch和Relu,其表达式为:
f(x)=max(0,x)
(2)
函数在模型训练过程中求导梯度不易为零,因此,本实验采用Relu函数.
卷积层之后是降采样层,降采样层的作用是对手写字体图像中每个特征图中的区域进行采样操作,常见的采样方式包括最大池化采样和均值采样.假设xi为降采样层,则最大池化层和均值采样的表达式如式(3)和(4)所示:
xi=f(wiMmax(xi-1)+bi)
(3)
xi=f(wiMmean(xi-1)+bi)
(4)
其中,Mmean(x)和Mmax(x)分别为均值采样和最大池化采样操作;wi为训练的权重;bi为其偏置.
由于神经网络的参数较多,降采样可以降低其复杂度.因此,使卷积神经网络高效运行和权值共享,局部感受野和时空下采样在书写字体识别中发挥着核心作用.
2.2 目标函数与改进算法
卷积神经网络属于有监督学习[13].其本质是采用前后向传播算法,不断地更新网络参数.对于深度学习而言,输入数据可看作一个损失函数fCNN,由数据损失和模型参数的正则化损失函数共同组成.深度模型的训练则在最终损失驱动下对模型进行参数更新并将误差反向传播至网络各层[14][15].模型的训练过程可以抽象为从原始数据向最终目标的直接“拟合”,而中间部件的作用是将原始数据映射为特征,再映射为样本标记(即目标任务)[16][17].图3显示了fCNN的各个基本组成部件.

图3 卷积神经网络基本流程图Fig.3 Basic flow chart of convolutional neural network
图3中的全连接层是将网络特征映射到样本的标记空间做出预测,目标函数的作用则用来衡量该预测值与真实样本标记之间的误差.现有的卷积神经网络中,交叉熵损失函数和l2损失函数分别是分类问题和回归问题中最为常用的目标函数.为了防止模型过拟合或实现其他训练目标(例如得到稀疏解),正则项通常作为对参数的约束加入目标函数中.
假设训练集共有N个训练样本,第i个样本的输入特征为ti,其对应的标记为yi∈{1,2,…,c},h=(h1,h2,…,hc)T为网络的最终输出,即样本i的预测结果,其中c即为分类任务的类别标签.为了提升卷积神经网络模型的泛化能力,交叉熵损失函数是目前最常用的分类目标函数,具体表达形式如式(5)所示:
(5)
已有研究证明,合页损失函数和坡道损失函数均为分类和回归中非凹凸损失函数的典型代表.尽管它们对噪声数据具有更好的抗扰性,但模型参数优化的时间和空间复杂度较高.为了进一步提升卷积神经网络模型在手写字体中识别能力和特征判别能力,本文提出一种新的损失函数,并对原始的卷积神经网络进行优化,该损失函数命名为“大间隔交叉熵损失函数”.目标是增大类与类之间的距离,减小类内差异等,从而进一步提升网络学习特征的判别能力.大间隔交叉熵损失函数扩大了类间距离,使得训练目标相比传统交叉熵损失函数更直接,并且可以防止模型过拟合.对于交叉熵损失函数和合页损失函假设卷积神经网络的输出结果为h,本质上是全连接层参数w与该层特征向量xi的内积,即h=wTxi,传统的交叉熵损失函数(softmax损失函数)如式(6)所示:
(6)
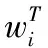
式(6)不仅满足传统交叉熵损失函数的约束,而且在确保正确分类的前提下增大了不同类别间的分类置信度,从而有利于进一步提升特征分类能力.
为了提升模型泛化能力,减少过拟合现象.本文提出了Elastic网络正则化项,假设网络的优化参数为w1,w2,λ1,λ2为其控制的正则项的大小,其表达式如式(7)所示:
(7)
传统的深度学习优化算法包括SGD、Momentum、RMSProp和Adam等[18][19][20].在实际应用中,梯度下降法容易出现局部最小值,收敛速度慢,对计算机硬件资源要求高.动量法在解决这个问题方面有很好的效果,它能够保留上一轮更新中的参数更新增量,并加入该轮的梯度,更新结果如下:
参数更新变化为:θ←θ+υ;
v的更新为:υ←αυ-ξΔθJ(θ)
其中α,ΔθJ(θ)分别是动量参数和当前轮次训练得到的梯度.v,ξ分别代表添加的模型训练过程动量元素的加速度和学习率.
3 实验结果及性能分析
本实验采用windows 10操作系统,运行内存为32GB.采用的平台为python3.6.1,flask0.12.,tensorflow1.3.0和keras2.3.1.
3.1 手写数据集描述
为了提升模型在实际数据中识别的效果,本实验采用了混合型数据进行卷积神经网络模型的训练和测试,并选择了由美国国家安全技术研究所制作的MNIST数据集,该数据集包含250人手写的阿拉伯数字图片.我们选用其中60000张图片作为训练集,10000张作为测试集.
为了验证卷积神经网络构建过程的泛化能力,本实验采用了国内某大学3个年级一年的学生上课的手写字体数据集.其中数字从0到9共2.2万张,常用的汉字字体2000多个,共1.8万张.将这4万张图片制成28*28的数字像素,并且利用公开标签工具Label进行人工标签16万个,自制成的数据集以json文件存储在磁盘中,其部分标签展示的结果如图4所示.
针对上述收集到的数据集和自制的手写数据集,按照图像处理过程进行特征处理,将灰度图像进行像素点增强处理和缩放保存.
3.2 分析与比较
根据图像分类识别的需求,并结合国内外科研指标和相关文献,实验中超参数的设置为:动量因子为0.2,自适应学习率为0.0001,惩罚因子为96.实验中对于不同网络层采用不同迭代次数,通过识别的准确率以及相应的损失率来评价卷积神经网络模型的性能,假设y′为识别的正确手写字体数目,y为测试和训练样本的总数,其识别率公式如式(8)所示:
(8)
通过对采集的混合数据集进行特征提取和训练,模型经过多轮次的迭代后,损失率达到稳定,将训练好的卷积神经网络在新的数据集上进行了验证,测试的准确率达到96.83%.
为了体验优化后的卷积神经网络应用效果,我们对训练的模型参数保存后进行了线下测试,其算法的损失率和线下字体识别结果如图5所示.
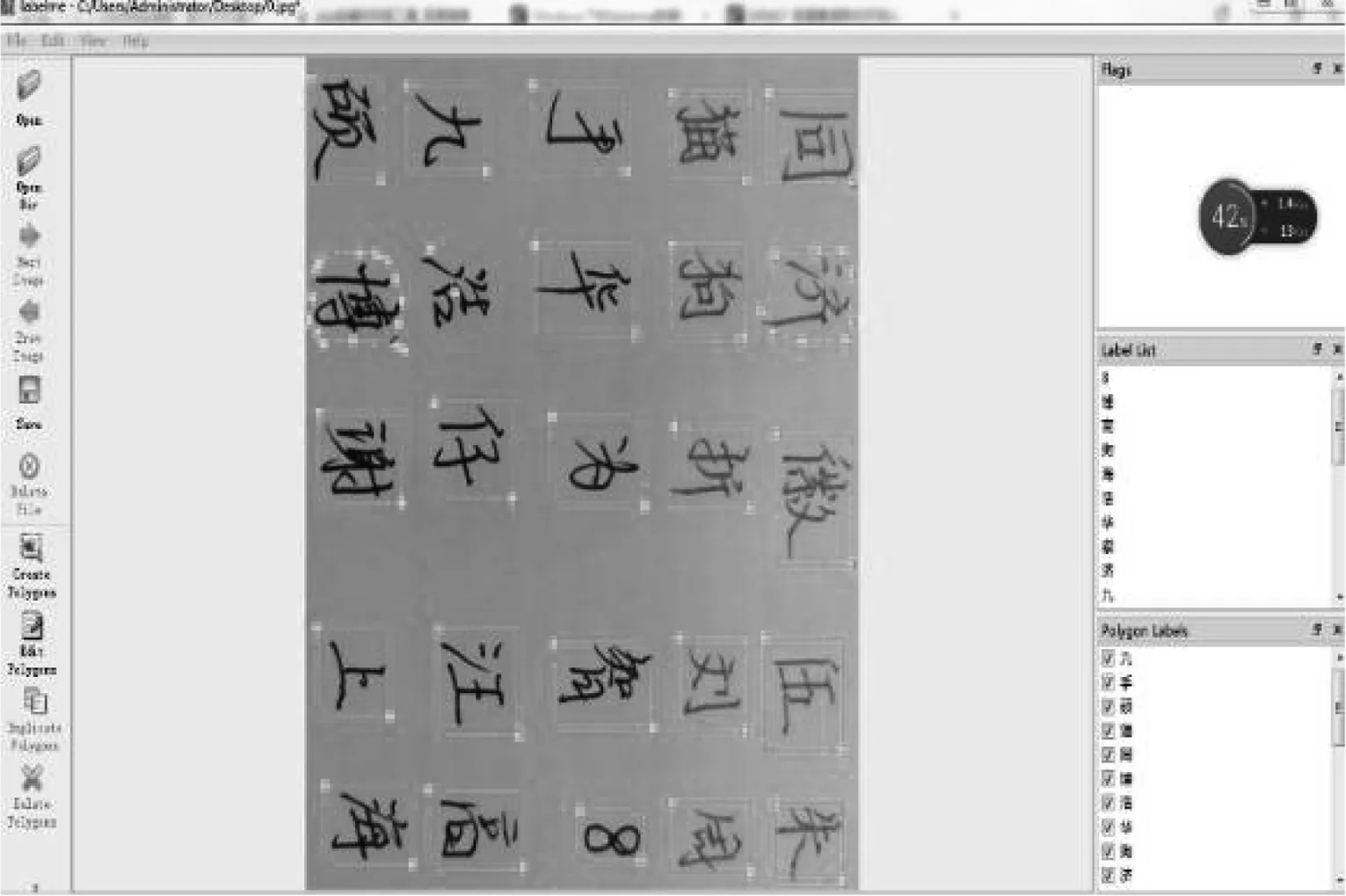
图4 人工制作的数据集部分标签样本Fig.4 Manually produced part of the data set label sample

图5 优化的卷积神经网络线下字体识别结果Fig.5 Optimized online-offline font recognition results of convolutional neural network
根据上述损失曲线和识别结果可以看出:当卷积神经网络迭代次数达到2000时,性能趋于稳定.为了进一步验证算法的优劣,我们将提出的方法与其他算法进行了对比,实验结果如表1所示.从表1可以看出,我们的方法识别准确率达到96.47%,高于其他4种方法,但训练时间多于文献[23]所提出的方法,识别时间大于HMM方法.
4 结 语
本文提出了一种改进的卷积神经网络用于手写字体的识别,分别从CNN卷积神经网络对手写字体特征提取方法和损失函数方面进行了改进.同时,实验在原有的随机梯度算法的基础上采用了Momentum算法对目标损失函数进行优化,加快训练过程的收敛速度,压缩了卷积神经网络结构对计算资源的依赖性.通过与SVM、改进的HMM、LetNet-5和改进的贝叶斯算法等模型进行实验对比,我们提出的方法在手写字体识别的准确率方面优于其他方法.下一步的工作重点是模型的融合,充分地利用卷积神经网络和其他算法模型的优点,从而更好地提高字体识别的准确率.

表1 不同算法在手写混合数据集的测试准确率与时间对比
猜你喜欢
故事作文·低年级(2021年12期)2021-12-21
数学小灵通·3-4年级(2021年5期)2021-07-16
作文成功之路·小学版(2020年7期)2020-08-24
娃娃乐园·综合智能(2020年2期)2020-03-12
今日农业(2019年15期)2019-01-03
电子制作(2018年18期)2018-11-14
自动化学报(2016年8期)2016-04-16
共产党员(辽宁)(2015年2期)2015-12-06
读者·校园版(2015年19期)2015-05-14
小雪花·成长指南(2014年10期)2014-10-31
