
局部特征的局部敏感哈希专利二值化图像检索
2022-06-13 16:46董小灵
电视技术 2022年5期
董小灵
(国家知识产权局专利局 专利文献部,北京 100083)
0 引 言
用文字与图像相结合的方式来记载技术创新成果信息,文字部分用以客观、准确地描述整体技术专利说明书,是以方案为特征,图像部分是对文字部分描述的直观形象化补充。传统的专利检索技术是以文本内容为基础提供检索功能,而图像内容几乎不参与检索。换言之,传统的专利检索过程几乎忽略了图像内容信息。事实上,“一图胜万言”,图像等非文本数据能够在专利检索中发挥举足轻重的作用。
专利图像不包括外观设计图像,几乎全部是二值化图像(黑与白)[1],无色且大多数无纹理,仅有少数是低纹理。一方面,专利二值化图像源于矢量图像光栅化或者手工绘图的扫描数字化,经过这样的过程,原始图像的显著几何信息如纹理等几近消失;另一方面,专利二值化图像是由多种画法创建的绘图,如线的粗细、点虚线等,均取决于制图者的偏好或者技术领域的特性。因此,形状特征成为表述专利二值化图像内容信息的唯一图像特征。
形状特征是实现专利二值化图像检索的最为重要的低层视觉特征[2]。鉴于专利二值化图像的特殊性质并结合专利审查员的检索需求,本文运用局部特征技术提取专利二值化图像的特征描述矢量并对特征描述矢量进行必要简化,在此基础上,对专利二值化图像的特征描述矢量进行二值化处理,并结合局部敏感哈希方法设计检索索引结构,从而实现基于内容的专利二值化图像检索。
1 基于SIFT 的专利二值化图像特征提取与简化
尺度不变特征转换(Scale Invariant Feature Transform,SIFT)算法[3-4]是以特征点为基础的局部特征图像算法。运用此算法可以提取专利二值化图像的特征点,在此基础上,通过几何变换的方法缩减图像中对几何变换敏感的特征点数量,剔除专利二值化图像的冗余与无效特征点,压缩专利二值化图像特征点的数量规模,从而降低专利二值化图像的检索匹配复杂度。
1.1 基于SIFT 的专利二值化图像特征提取
运用SIFT 特征算法生成专利二值化图像特征向量的过程大体上可以划分为4 个主要步骤[5-6]。
第一步是尺度空间极值点检测,主要是检测图像在不同尺度中所有可能的特征点位置,运用高斯函数处理,对模糊化的图像做尺度变化,使图像在不同尺度获取代表性特征点。
第二步是过滤特征点与方向定位。为了取得稳定的特征点,除了将低对比度的候选特征点滤除之外,还需要将边缘处低对比度的特征点滤除。
第三步是为特征点分配适当的方向,主要是确定特征点的主要方向,将图像特征点的主要方向转换一致,达成旋转不变性。
第四步是建立特征点的特征向量,在找出特征点的位置、尺度与主要方向的基础上,形成特征点的特征向量。
1.1.1 尺度空间极值点检测
一幅专利二值化图像的尺度空间定位计算如下:

式中:(x,y)是空间坐标,L(x,y)是尺度坐标,I(x,y)表示原始图像,*为卷积运算,G(x,y)为高斯函数。
完成专利二值化图像的尺度空间定位后,采用高斯差分函数(Differential of Gaussian,DoG)[7-8],利用高斯差分函数中的不同参数对图像进行滤波并相减,得到高斯差分函数的DoG 关系公式(3),其中D(x,y)的关系由公式(4)推导而来。

式中:k为常数。
利用差分近似值替代微积分值,式(4)可写为式(5)的形式:

则有式(6):
建立高斯差分(DOG)化后的金字塔,即在DoG 尺度空间中检测极值点。极值点的检测是在DoG 尺度空间中,取某一像素点与相邻的8 个像素以及金字塔上下两层相邻的9 个像素等26 个像素进行比较,观察该像素为最大值或最小值时,则为极值点。
1.1.2 特征点位置的确定
为找出专利二值化图像的准确的特征点,利用拟合三维二次函数(3D Quadratic Function)删除若干不稳定的特征点,其中包括低对比度特征点和位于边缘的点,实现对特征点位置与尺度的精准定位,提升特征点的稳定性与抗噪能力。
对于低对比度特征点,基本上是以一个三维二次函数计算亚像素极大值。具体做法是将尺度空间函数D(x)依据泰勒级数展开(最高到二次项),如式(7)所示:

式中:D为DoG 的结果,x为特征点。根据D可以得到一个偏移量如式(8)所示:

如果x^ 值任何一个方向上都大于0.5,则意味着极值与附加采样点的偏移量非常接近,就会改变此采样点。这时候就需要通过差值来取代该采样点,x^ 值就会被添加到其他采样点上,这样就可以获取极值点的差值估算值。如式(9)所示:

为滤除边缘处的低对比特征点,将使用这些主曲率来判断特征点是否在边缘上。主曲率透过一个2×2 的Hessian 矩阵H求出,如式(10)所示:

导数可以由取样点相邻差估计求得D的主曲率和H的特征值(Eigen value)成正比。假设H的两个特征值分别为α、β,可以推导出矩阵Tr(H)对角线元素之和为两特征值的和,矩阵H行列值Det(H)为两特征值的积,如式(11)、式(12)所示:

令α=γβ,如式(13)所示,则有:

(γ+1)2/γ的结果在两个特征值相等时最小,随着γ增加,(γ+1)2/γ的值也会随着增加。当γ比较大的时候,就表示特征值的差异较大,则表示特征点位于图像的边缘部分。要判断特征点是否在图像的边缘上,需计算特征点在尺度空间中是否有较大的主曲率。因此,为了确定主曲率间比值的门槛值γ,采用式(14)进行计算:

在本研究中,计算出主曲率间的比值大于10[9],则该点被视为落入边缘点位,即将该点予以滤除。
1.1.3 特征点方向确定
为了在后续描述专利二值化图像特征点时准确描述图像特征点的方向,并且在图像特征点匹配时可以将图像特征点转变为主梯度方向,以达到图像特征点具有旋转不变性的特性,必须对各个图像特征点计算向量方向和大小,赋予一个主梯度方向。

以图像的特征点为中心,取一区域为16×16像素大小的邻域,再将其均匀分为16 个4×4 像素的子区域。对每个子区域进行区域内所有梯度强度与方向计算,梯度计算由式(15)、式(16)说明:式中:m(x,y)代表坐标位置上的梯度强度,(x,y)代表坐标位置上的梯度方向,L表示该区域内所有的像 素 位 置,L(x,y+1),L(x,y-1),L(x-1,y),L(x+1,y)分别代表特征点(x,y)上、下、左、右4 个相邻域像素点的灰度值。
依据上述式(15)、式(16)对每一个所提取的特征点作计算,可以得到特征点的梯度强度值与方向值。接下来计算每个特征点的主要方向。方向可以化作方向直方图的统计方式进行计算,其范围是[0,2π],则每个柱表示为10°共有36 个柱。统计出来的直方图结果峰值为这个特征点的像素梯度的方向。
方向直方图中峰值代表特征点的方向。确认方向直方图的最大值后,如果方向直方图的统计中,峰值在最大值80%以上,则可以归类为主梯度方向,即将所有高峰值最大值的80%的描述方向都列为主梯度方向。若梯度方向直方图超过80%的峰值不是只有一个,则属于多重方向的情形。大约仅有15%的特征点会被赋予多个方向,这些点可以加强特征点匹配的稳定性。
1.1.4 特征点描述向量
经过前述三个步骤,检测到所需要的图像稳定特征点,并且获得图像每一个稳定特征点的相关特性,即坐标位置、尺度空间及方向强度。在此基础上,对图像的稳定特征点进行特征描述,构成特征向量。以特征点为中心提取4×4 大小的区域,每个特征点所在的区域可以划分为16 个子区域。分别统计每个子区域内的方向直方图。每个子区域共计有8个方向,因此,每一个特征点的向量维度全部共有4×4×8=128 维。
1.2 基于SIFT 的专利二值化图像特征简化
用SIFT 算法提取专利二值化图像得到的特征点数量较多[10],对于专利二值化图像的描述相当充分,能够全面表述专利二值化图像的内容。但是过多的图像特征点也会产生冗余信息,直接影响专利二值化图像的检索匹配速度与效果。为了删除专利二值图像不必要与扭曲的SIFT 关键特征点,运用特征点简化算法去除关键点数量,仅保留具有高几何可变性的健壮关键特征点,以保持后续专利二值化图像检索的速度与准确度,其算法过程代码如下:
输入:
Tij:第i幅训练专利二值化图像的第j个关键特征点
变量:
R90ik:第i幅训练专利二值化图像90°旋转后第k个关键特征点
R180ik:第i幅训练专利二值化图像180°旋转后第k个关键特征点
S2ik:第i幅训练专利二值化图像尺寸扩大2 倍后第k个关键特征点
S0.5ik:第i幅训练专利二值化图像尺寸缩小一半后第k个关键特征点
Fi:简化后所保留的专利二值化图像关键特征点
程序:
//Pi训练专利二值化图像的关键特征点数量
//Gis是训练专利二值化图像不同几何变换的关键特征点数量
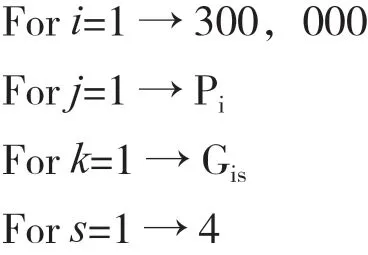
如果Tij能够同时实现R90ik、R180ik、S2ik和S0.5ik四种几何变换的匹配,则保存Tij在Fi中。
首先,对训练专利二值化图像集合中每1 件图像进行几何旋转与缩放。使用4 种几何变换:旋转90°,旋转180°,尺寸扩大2 倍,尺寸缩小1/2。从变换图像中提取特征点并且与原始图像进行比较。如果变换图像与原始图像相同特征点匹配(欧几里德距离小于3 000),则该特征点被视为对几何可变性具有鲁棒性。通过保留鲁棒特征点,可以高效减少专利二值化图像特征点数据库规模。然而,有可能一些图像提取很少鲁棒特征点,这使得图像匹配相当困难。因此设定每张专利二值化图像最少特征点阈值F相当重要。具体阈值F决定可参见式(19)。其中x-是训练专利二值化图像数据集合关键特征点的平均数量,σ是训练专利二值化图像数据集合关键特征点的标准方差,具体计算参见式(17)和式(18)。
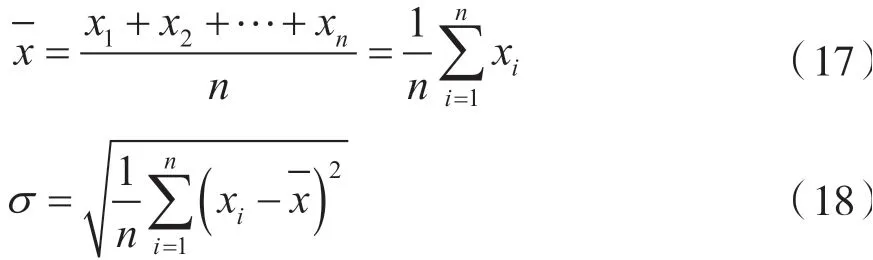
式中:n是训练专利二值化图像数据集合数量(本集合中数量为1 000 000 件)是所有训练专利二值化图像的关键特征数量平均值。对于本训练集合而言是141 个,σ是90 个。注意在关键点简化过程后决定这些值。每个训练图像阈值的确定如下:

式中:R是在F的关键点数量。offset是从原始图像中随机选取的关键点数量直至通过这样的调整机制,可以确保每个训练图像的关键点数目在平均值与方差值之和范围内。如果R是在范围内,则R是F。如果R大于,减少R中关键特征点数量直至F等于
本研究中训练专利二值化图像数量是1 000 000件,原始特征点共有216,734,674 个。在应用特征点去除程序后,关键特征点数量减少到43,324,865。关键特征点数量减少近80%。
2 基于LSH 的专利二值化图像索引机制
SIFT 算法能够很好地表达描述专利二值化图像的内容特征。但是专利二值化图像SIFT 特征的匹配时间过长,导致整个专利二值图像检索耗时冗长。为了减少专利二值化图像检索时间并且不影响检索准确度,对专利二值化图像的SIFT 特征进行二值化并结合局部敏感哈希(LSH)建立索引结构[11-12],以提升整个专利二值化图像检索系统的检索速度与效率。
2.1 产生二值化描述符
针对专利二值化图像的SIFT 特征点描述符计算8 个方向的平均值[13],接着依据每个方向的平均值分别对描述符内所对应的数值进行二值化。假设SIFT 特征点描述为F={fi|i=0,…,127},然后分类成8个序列Fd={f8j+d|i=0,…,15},d=0,…,7,其中d表示8个方向。算出8 个方向类别的平均值为Dd,计算公式为式(20)。最后比较其方向大小,判断是否为0或1,计算公式为式(21),共产生128 维度的二值化描述符B={bi|i=0,…,127}。
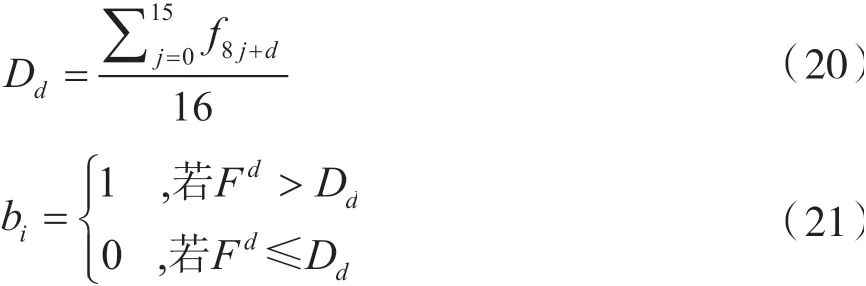
2.2 哈希函数的计算
根据专利二值化图像的SIFT 特征描述符特性产生哈希函数算法[14]H(M1,M2),如式(22)所示,其中M1和M2都是利用专利二值化图像SIFT 特征描述符的8 个方向所产生的平均值。
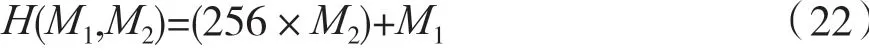
M1的产生是利用专利二值化图像SIFT 特征描述符9 个方向的平均值,两两比较其大小去判断是否为0 或1,如式(23)所示,接着把8 个0 或1 的比较结果合并成M1,如式(24)所示。
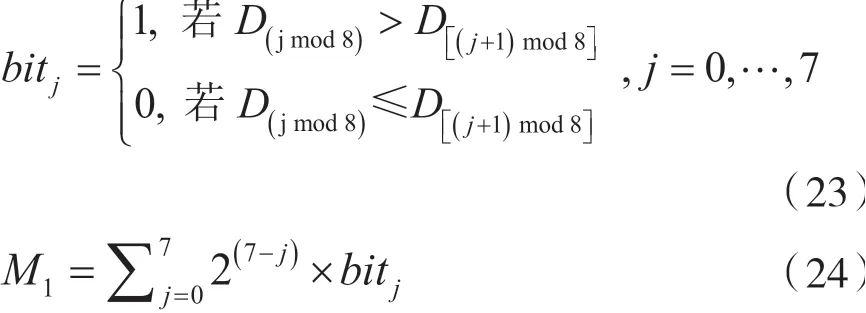
M2的产生也是利用专利二值化图像SIFT 特征描述符8 个方向的平均值,依照每个方向的平均值与其他两个邻近的平均值做累加并产生8 个累加值,如式(25)所示,然后在8 个里面找出其最大值的累加值编号,如式(26)所示。

2.3 哈希表的建立
依据哈希函数将专利二值化图像的SIFT 特征描述符存入哈希表中。但是若仅存储SIFT 特征描述B,则不能分辨出该特征描述符是属于哪一幅专利二值化图像,所以应当将每幅专利二值化图像的SIFT 特征描述符二值化后,经过哈希函数计算,将二值化描述符B与图像的ID,(B,In),共同存入哈希表中,其中I={In|n=1,…,N},N为专利二值化图像数量,下述为具体方法代码。
Input:F={fm|m=1,…,M}:专利二值化图像的SIFT 特征描述符集合
Output:T={TX|x=0,…,2 047}:哈希表的2 048个桶集合
For 每张专利二值化图像SIFT 特征描述符fm
ComputerD0,…,D7by(20)
将专利二值化图像SIFT 特征描述符转化为二值描述符

2.4 图像检索匹配
对专利二值化图像SIFT 特征描述符经过上述3 个步骤处理后,依据每个特征描述符经过哈希计算的结果,检索对应哈希表桶内的全部二值化描述,接着对测试的专利二值化图像与哈希表桶内的二值化描述符做海明距离比较[15-16],设定海明距离的阈值为T。若比较结果小于或等于阈值T,就判定该哈希表桶内的二值化描述符为相似描述符,并且记录对应的专利二值化图像ID。当计算完测试图像的所有特征描述符后,统计相似特征描述符数量最多的专利二值化图像为相似图像,下述为具体方法代码。
Input:F={fy|y=1,…,Y}:测试图像的特征描述符集合
C={Cn|n=1,…,N}:目标数据库图像集合,初始值为0
T:海明距离的阈值
Output:C={Cn|n=1,…,N}:目标数据库图像更新结合
For 测试图像的特征描述符fy

将专利二值化图像SIFT 特征描述符fm转化为二值描述符B´
从哈希表T 的桶内检索数据
从桶中产生一系列(B,In)
计算B´与B的海明距离

3 专利二值化图像检索算法的实验
为了验证上文所述的专利二值化图像检索算法的性能,选择专利二值化图像进行实验测试。开展本实验测试所搭建的基本硬件配置为Intel CPU Q9550 2.83 GHz,4 GB DDR2 800 内存。选择2010年至2020 年期间中国发明专利申请说明书与实用新型专利说明书的相关附图作为实验的图像数据集。作为实验的图像数据集主要包括测试图像集、查询图像集及目标图像集3 个部分。
测试图像集是指进行查询的专利二值化图像数据集合,在本实验测试中选择1 000 000 幅专利附图图像作为测试数据集,图像大小的范围为256×384 ~1 024×768。查询图像集是指作为查询输入的专利二值化图像数据集合,在本实验测试中从测试图像集中人工选取200 幅专利二值化图像数据。目标图像集是根据查询图像集200 幅专利二值化图像数据在测试图像集中人工确定的相似专利二值化图像数据,这部分数据是中国专利文献深加工项目的产物。
通过对测试图像集的专利二值化图像进行SIFT 特征提取与简化,形成优化的专利二值化图像关键特征点。在此基础上,对专利二值化图像关键特征点进行二值化后利于哈希算法形成不同规模大小的局部敏感哈希索引表,具体如表1 所示。从表1可知,随着专利二值化图像训练数据集合规模数量的变动,局部敏感哈希索引表大小也线性变动。

表1 不同规模专利二值化图像集合的哈希索引表大小
在对所述的专利二值化图像进行测试实验过程中,以查询图像集所包含的200 幅专利二值化图像作为作为查询图像用例在测试图像集中进行专利二值化图像检索的测试。首先,运用SIFT 算法提取专利二值化查询图像的特征点,再利用几何变换算法对专利二值化查询图像所提取的SIFT 特征点进行简化。其次,对简化后的专利二值化查询图像SIFT特征点进行二值化处理形成新的专利二值化图像的二值特征向量。随后,根据哈希函数对专利二值化图像的二值特征向量构建局部敏感哈希索引,最后,基于投票方式统计相似特征描述符数量最多的专利二值化图像为相似图像并返回图像标识号码。
根据专利二值化图像测试集合不同规模进行检索,本实验选用的专利二值化图像测试集合有6 种规模,分别是50 000,100 000,200 000,500 000,800 000 及1 000 000。不同规模的专利二值化图像测试集合的关键特征点数量简化前后数值如表2 所示。表3 表示200 幅专利二值化查询图像在不同规模的专利二值化图像测试集合中特征简化前后检索匹配具体时间值。从表3 可知,专利二值化图像特征简化前的检索匹配时间要长于特征简化后的检索匹配时间。换言之,专利二值化图像特征简化提升了整个专利二值化图像的检索匹配速度。
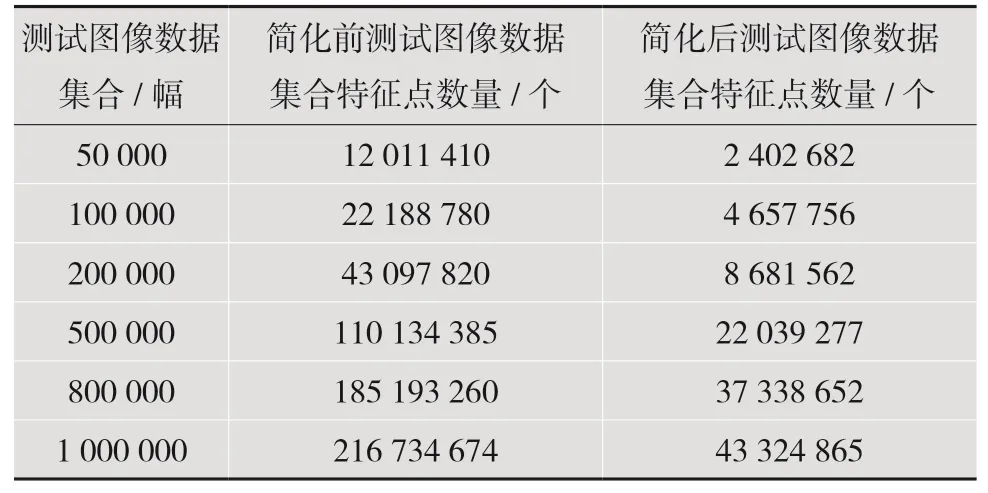
表2 不同规模专利二值化图像简化前后的SIFT 特征点数量

表3 专利二值化图像特征简化前后检索匹配时间值
表4表示200 幅专利二值化查询图像在不同规模的专利二值化图像测试集合中特征简化前后检索匹配查全率。从表4 可以发现,专利二值化查询图像检索匹配查全率在图像特征简化前要高于图像特征简化后,并且两者都随着专利二值化测试图像集合规模的增加而逐步降低。尽管专利二值化测试图像集合规模达到百万级,但是专利二值化图像检索特征简化前后匹配查全率并没有大幅度变化,并且最低匹配查全率仍然保持在85%以上。这样的测试结果表明,本研究所提出的专利二值化图像检索算法具有较高的查全率与较快的检索速度,可以运用在现实的专利二值化图像检索中。
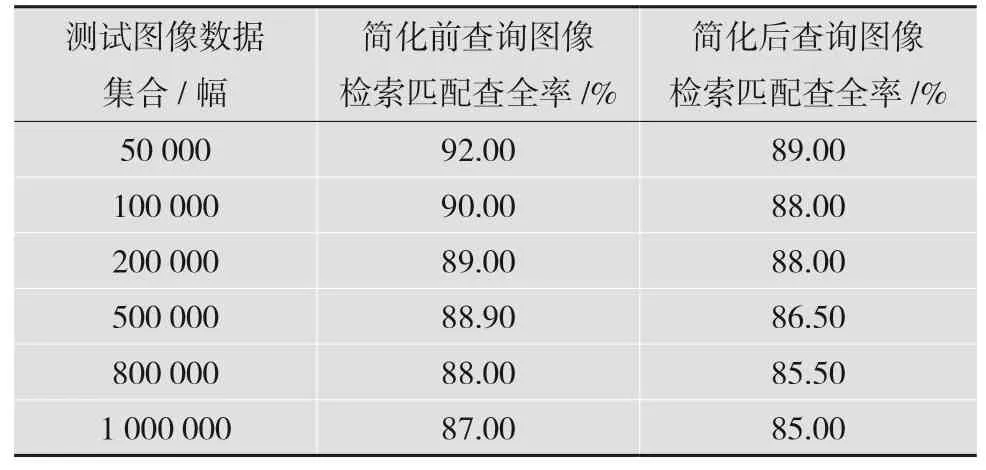
表4 专利二值化图像特征简化前后检索匹配查全率比值
4 结 语
专利二值化图像自身内在的复杂性与特殊性使得基于形状特征的专利二值化图像检索更具挑战性。通过对现有基于内容的图像检索技术系统研究,认识到局部特征提取技术对于构建专利二值化图像检索算法具有重要意义。针对SIFT 算法在专利二值化图像检索算法实际应用过程中所产生的特征矢量数量过多与特征矢量维度过高等两大问题,本文提出了专利二值化图像SIFT 特征向量的简化算法和索引构建机制。下一步将在改进专利二值化图像的局部特征提取算法和图像相似度量比较算法基础上,优化索引结构,来提升专利二值化图像检索算法的运行效率。
猜你喜欢
大数据(2021年6期)2021-11-22
电脑爱好者(2021年8期)2021-04-21
电脑爱好者(2020年20期)2020-10-22
计算机应用与软件(2020年6期)2020-06-16
科学与财富(2019年27期)2019-10-25
速读·下旬(2019年11期)2019-09-10
数码世界(2019年9期)2019-09-07
电子制作(2019年14期)2019-08-20
电子制作(2019年2期)2019-02-14
雷达科学与技术(2017年5期)2018-01-15
