
融合标签语义特征的BERT 微调问句分类方法
2022-06-13 16:46亢文倩
电视技术 2022年5期
亢文倩
(昆明理工大学 信息工程与自动化学院,云南 昆明 650500)
0 引 言
问句分类是问答系统的一个重要处理过程[1],是在用户给定自然语言问句的前提下,将问句与预定义类别形成映射,并用类别标签表示。该类别标签作为对问句答案范围的语义约束,用于检索与标签对应的答案,尽可能地缩减检索空间,提升检索效率。传统的问句分类方法大致分为基于规则的方法、基于机器学习的方法以及基于深度学习的方法三种。
基于深度学习的问句分类方法近年来成为研究的热点,相较于机器学习方法常用卷积神经网络(Convolutional Neural Networks,CNN)模型[2-3]、长短期记忆网络(Long Short-Term Memory,LSTM)模型[4-6]等网络结构,这些方法可以端到端地获取文本特征,大大降低了人力成本和时间成本。但由于深度学习的特性,在节省资源的同时也受到数据稀疏的影响。深度学习模型处理下游自然语言处理(Natural Language Processing,NLP)任务的前提是,训练数据和测试数据属于同一个领域,也就是说它们必须拥有共同的特征空间和相同的数据分布,否则分类精度会大大降低。如果要对新领域的问句进行分类,则需要在新领域对模型重新进行训练,故而深度学习分类器的可重用性较低。
深度迁移学习将深度学习方法与迁移学习相结合,对于上述问题是一种很有效的解决方法。例如,双向编码器表征量(Bidirectional Encoder Representations from Transformers,BERT)[7]使 用Transformer 作为主要框架,首先预训练模型并初始化参数,其次根据下游任务的使用目标域数据对参数进行微调,可以替代Word2Vec 应用到文本分类等11 项NLP 任务中。SUN 等人[8]对比了在文本分类上BERT 模型的不同微调方法的性能。由于BERT模型从训练数据中提取特征,因此忽略了文本标签所提供的语义信息。
PURI 等人[9]对分类任务进行自然语言描述,将其作为输入并对模型训练,将所有任务转化为QA 任务,输出为自然语言答案。KISHALOY 等人[10]提出了一种零样本学习方法(TARS),在上述模型基础上,将文本分类转化成二进制分类。TARS 模型在情感分析领域的分类适配性较高,而在问题、主题类型的分类正确率较低。
通过对以上方法的研究与分析,本文将类别标签用于BERT 微调分类器的训练,比较标签和问句的语义相似度,获取两者的关联性,提出一种融合标签语义特征的BERT 微调问句分类方法,简称L-BERT-FiT。
1 算法模型及实现
鉴于深度迁移学习强大的泛化能力和特征提取能力,L-BERT-FiT 主要由以下3 部分组成如图1所示。
(1)定义虚拟标签词典。首先,模型访问训练集和测试集,获取已知的标签文本,生成一个虚拟的标签词典。在对模型进行预训练时,将该词典中的标签与问句形成一一对应的元组<预测标签,问句>作为输入。
(2)特征提取。将输入的预测标签视为文本×1,问句视为文本×2,则将分类任务视为计算文本×1和×2 相似度任务。提取×1 的语义信息和×2 的语义信息,并比较两者的相关性,将其作为输入特征,调节BERT 参数。
(3)BERT 微调。在上述预训练完成后,使用微量的目标域数据对BERT 模型进行参数微调,并使用SoftMax 函数作为输出层的线性激活函数,选择分类结果(正确/错误)。
1.1 预处理
获取源领域和将要进行预测分类的目标域类别标签生成标签词典。例如,源域包含两个类别的问句“Society”“Computers”“Entertainment”“Sports”,目标域的问句可能属于类别“Science”“Business”“Education”“Health”,则生成的虚拟标签词典则为{Society,Computers,Entertainment,Sports,Science,Business,Education,Health}。
如图2 所示,在BERT 训练时,输入的元组格式为<预测类标签,问句>。BERT 将输入的文本的格式转化为“[CLS]y[SEP]x[SEP]”,其中y代表类标签,x代表问句,[SEP]标志用于间隔两个文本输入,[CLS]标志位于输入起始位置。

图2 L-BERT-FiT 生成的词嵌入
1.2 特征提取
如图2 所示,BERT 将输入文本x中的每个单词转换为词嵌入E,每个词嵌入都由3 部分组成:Token 嵌入+Segment 嵌入+Position 嵌入。并对E进行加权映射得到三个向量Query(Q)、Key(K)和Value(V),其中Q=K=V。然后,计算输入的特征矩阵[11]:

K,Q,V的输入维度为dK,dQ,dV,SoftMax激活函数用以获取权重。由于BERT 中的Selfattention 机制是多头的,即可以获得多个Attention输出,则Transformer-encoder 输出的最终特征矩阵为[11]:

式中:h代表h个Attention head,W O代表线性映射,将向量映射到高维空间更易获取所需信息。参数矩阵
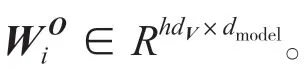
1.3 语义相似度计算
获取到特征向量后,需要计算标签向量A和问句向量B的语义相似度.这里使用特征向量的点积(cosine)来进行计算:
最后,使用SoftMax 函数形成一个概率分布,比较同一问句与不同标签的相似度,取值最高的输出为TRUE,其余的输出为FALSE。
2 实验条件与结果分析
2.1 实验数据
2.1.1 数据集
实验数据集采用的是Yahoo! Answers数据集[12]。此数据集为英文问答数据集,共含有10 个不同的问句类别。人为地根据不同的类别标签将数据集划分为3 个不同的领域,每个领域包含4 种类别的问句,如表1 所示:

表1 实验数据集的领域划分
在实验过程中,选择不同的领域作为源域和目标域。选取10 000 条源域数据作为训练集,用以预训练模型;500 条目标域数据作为开发集,用以微调BERT;4 000 条目标域数据作为训练集,用于测试模型在目标域的分类效果。
2.1.2 数据预处理
对数据集中的问句进行降噪处理,去除标点及特殊符号,去除多余空格,将大写字母转换为小写;并将原始数字标签替换为文本标签,处理结果如表2 所示。

表2 预处理前后的数据元组对比
2.2 实验环境及参数设置
本实验在Google colab 上利用Python3.7 编写,使用Flair 框架。模型网络层数为12,注意多头个数h=12,参数总量为110 MB。词嵌入大小为512,隐藏维度768,dropout=0.1。epoch 的最大数量为20,每批执行110 次迭代,最大batch 为16,初始学习率为0.000 1。
2.3 实验结果
为了宏观地反映L-BERT-FiT 模型的跨领域问句分类性能,对每个模型分别进行5 组跨领域分类实验,每组实验分别进行3 次,实验结果取3 次的平均值。
由表3 可见,L-BERT-FiT 的分类性能在不同领域存在波动,当L-BERT-FiT 由领域1 迁移至领域3 时,精度相较BERT-FiT 提升最高,提升4.28%。当L-BERT-FiT 由领域2 迁移至领域1 时,精度相较BERT-FiT 提升最低,仅提升了1.38%。这可能与不同域之间的距离和提取的特征数量有关,但总体上实验结果得到了显著提升。
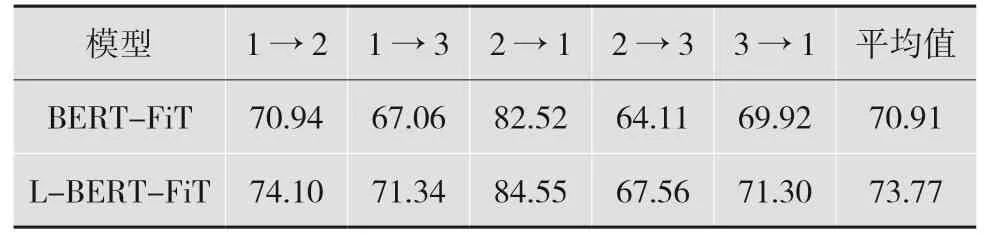
表3 L-BERT-FiT 与BERT 微调模型在跨域问句分类中的精度(单位:%)
由表3 可以得出结论,与BERT 微调相比,L-BERT-FiT 的平均精度提高了约2.86%,进一步提升了深度迁移学习模型——BERT 微调的跨领域的问句分类效果。
3 结 语
本文提出了一种融合标签语义特征的BERT 微调问句分类方法,提取类别标签的语义信息和问句与标签的语义相似度作为特征对BERT 模型进行微调。实验证明,这种方法在新领域问句集中获得了较好的分类结果。
然而在模型训练时,输入的<预测标签,问句>一对一元组会导致如下问题:输入元组的数量成倍增长,大大增加了计算时间和成本。未来的工作将着手于解决计算负载的问题,降低模型的时间成本。问句作为短文本,面临着特征稀疏的问题,未来将对问句进行数据增强,进一步提升分类精度。此外,由于环境限制,实验使用了BERT-BASE 版本,目前已经有更多的BERT 变体,如ALBert、RoBERTa、ERNIE 等,未来将研究这些版本是否对跨领域问句分类任务有着更好的效果,进一步提高模型的推理能力。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
乐器(2021年1期)2021-09-10
开放教育研究(2020年2期)2020-03-31
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
长江学术(2016年4期)2016-03-11
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
广西民族研究(2014年6期)2015-05-05
长江学术(2015年1期)2015-02-27
