
基于运营商大数据的APP潜在用户挖掘研究
2022-06-13 03:00刘卉芳欧阳秀平李勇路中国联通广东省分公司广东广州510627
邮电设计技术 2022年5期
刘卉芳,廖 娟,欧阳秀平,林 敏,李勇路(中国联通广东省分公司,广东广州 510627)
0 引言
随着人口红利的消失,以及提速降费政策的影响,传统通信业务收入呈下滑态势,运营商的营业收入和净利润增长较为缓慢。在此大背景下,运营商不断探索新的商业模式以寻求业务增长点,其中,通过跨界合作促进流量增长,提升用户黏性,增加后向收入成为近年来运营商不断探索的新模式,也是未来运营商发展的重要途径。
跨界合作是指由2 个或2 个以上不同行业的企业,为达到共同的战略目标,交换、共享或共同开发新产品或服务的合作模式[1]。运营商的跨界合作主要以开拓新市场、增加后向收入为目标,合作模式主要有以下2种。
a)互相引流:合作双方结合自身优势共同开发出新的产品,通过优惠、让利使双方用户互相渗透,促进双方业务增长,较为典型的案例就是中国联通和腾讯公司共同推出的腾讯王卡产品[2]。
b)精准营销:运营商利用自身大数据优势为合作方挖掘潜在用户,并通过自有渠道、触点、外呼等方式进行营销,以抽取提成、佣金为目标,增加运营商后向收入,例如运营商与手机终端厂商合作,构建换机模型[3-4],对有换机需求的用户进行精准营销。
本文着重探索第2 种跨界合作模式,且着重关注互联网APP 的合作推广,例如在线教育、游戏、打车等行业的APP,均在快速成长期,推广需求迫切。本文通过对运营商大数据进行挖掘,提出构建APP 潜在用户识别模型,为运营商充分利用APP 大数据、实现异业合作、精准营销提供参考。
1 跨界合作体系框架
运营商跨界合作首先需要确定合作对象并了解对方用户规模与发展前景,同时分析潜在目标用户。当前异业生态产品配置相对主观,运营商选择较为被动,多数情况为等待合作方上门。圈选目标用户也主要利用年龄、性别等基础信息和流量、语音等传统通信数据,产品转化率不高。针对上述现状,本文提出以下解决方法。
a)提出运营商跨界合作体系构建的流程和方法。分析各垂直行业发展趋势,实现热门行业、成长行业自动监控,为异业产品创新提供数据参考。
b)提出基于上网日志数据构建潜在用户模型的方法。构建APP 贡献度衡量算法,从1 万多个APP 中挖掘出贡献度最大的APP 和行业,避免人为指定行业和APP的主观因素。
运营商跨界合作体系构建的流程和方法如图1所示。首先,通过上网日志数据监控用户规模较大的热门行业以及复合增长率较高的成长型行业,如图2 所示。成长行业的判断依据为当月用户规模5 万户以上,近1 年复合增长率大于0,且近半年的平均增长率大于0,对满足上述条件的行业计算近半年的复合增长率并从高到低进行排序。

图1 跨界合作体系框架
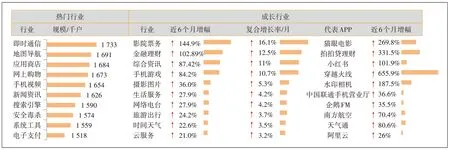
图2 热门行业和成长行业洞察监控示例
其次,选择一个目标行业重点分析,通过使用量分析各APP 的市场份额,通过使用流量分析各APP 的用户黏性,通过复合增长率分析各APP 的成长性和衰退性,最终圈定合作价值高的APP 进行产品创新,评估成本效益。接着,通过机器学习挖掘潜在用户,进行精准营销,降低营销成本,提升转化率。目前关于潜在用户挖掘的研究很多[6-7],但都是基于主观指定的几个行业或者热门APP 的使用数据,并没有针对所有APP 进行筛选研究,可能会忽略掉一些贡献度大的APP或者行业数据。本文将重点给出潜在用户挖掘的流程方法,并在此过程中构建用户的多维度偏好标签,具体实现方式可参考文献[5]。最后,本文通过用户偏好标签和潜在用户标签生成用户画像,为后续精准营销、维系挽留等策略提供参考
2 潜在用户模型构建
本文以推广作业帮APP 为例阐述运营商挖掘潜在用户的全流程方法。
2.1 数据准备
随机抽取某运营商200万个用户的基础信息数据(性别、年龄、终端品牌、产品、出账收入等)和2020 年某月的上网日志DPI 解析数据(APP 名称、所属行业、访问次数、使用流量等)。以作业帮APP流量大于0的用户为正样本,共计28.12 万,其余为负样本,共计171.88万。
从业务经验上来说,作业帮用户和非作业帮用户的APP 偏好存在差异,而这些差异有利于运营商识别潜在用户。因此,本文首先处理分析上网日志数据,统计正负样本中使用各种APP 的用户数,比较正负样本的上网行为差异。一些热门APP(如微信)对识别潜在用户的贡献微乎其微,因为正负样本均有97%以上的用户使用微信。本文需要挖掘的是正样本特有的偏好特征。例如,52.5%的正样本使用了百度贴吧,而仅有22.4%的负样本使用了百度贴吧,差值为30.1%,说明使用百度贴吧的用户更有可能是作业帮的潜在用户。55.6%的正样本使用了教育学习类APP(不包含作业帮),而仅有23.6%的负样本使用了教育学习类APP,差值为31.9%,说明使用教育学习类APP 的用户更有可能是作业帮的潜在用户。
从图3 和图4 可以得出使用了教育学习、词典翻译、手机阅读类APP 的“学习爱好者”,以及使用了动漫、手机游戏类APP 的用户都有可能是作业帮的潜在用户。但是,本文不能简单地判断只要使用了上述APP 的用户都有使用作业帮APP 的需求,还需要加入年龄、性别等基础信息,并且综合各种APP 的使用组合判断,因此,需要通过机器学习建模更精准地挖掘潜在用户。
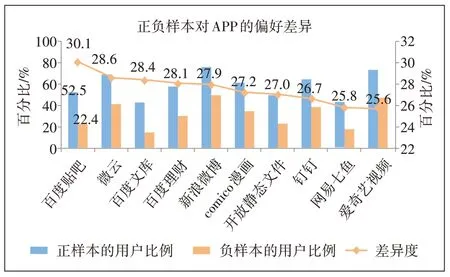
图3 正负样本偏好差异最大的TOP10APP
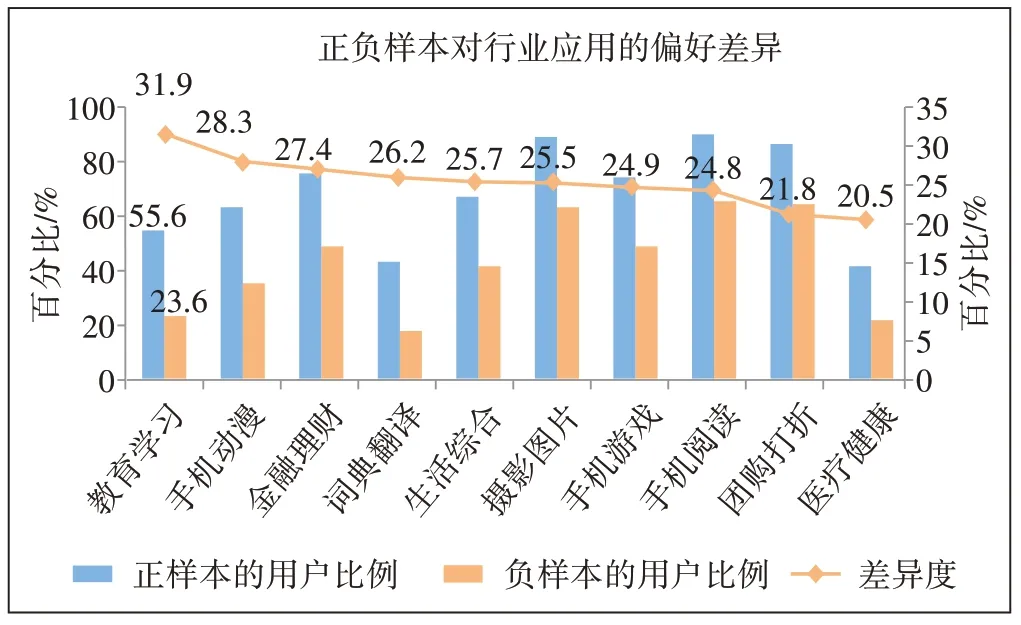
图4 正负样本偏好差异最大的TOP10行业
2.2 特征选择
特征选择的步骤如下。
步骤1,计算正负样本对各个APP 的偏好差异:正样本中某APP 用户的比例减去负样本中某APP 用户的比例,选取差异值最大的前30 个APP,如百度贴吧、微云、百度文库、钉钉等。
步骤2,将每个APP归属到一个行业,共计73个细分行业。按上述方法计算正负样本中对各个行业的偏好差异:正样本中某行业用户的比例减去负样本中某行业用户的比例,选取差异值最大的前20 个行业,如教育学习、手机动漫、金融理财、词典翻译等。
步骤3,提取步骤1 中的30 个APP 的用户流量使用值,步骤2 的20 个行业中各个行业使用的APP 个数,以及用户性别、年龄、终端品牌、月使用流量、产品、月出账收入等56个因子作为建模的基础因子。
2.3 特征工程
建模的基础因子选择好之后,对因子进行进一步加工。
2.3.1 连续变量WOE分箱


WOE 表示证据权重,用于衡量各个箱体对目标变量的影响度。IV 指标基于WOE 计算,可以反映基于当前分箱下,正负样本分布之间的差异性,IV 值越大表示差异越大。一般认为IV<0.02,变量基于当前分箱几乎没有贡献;IV<0.5 时,IV 值越大说明分箱效果越好;IV>0.5时,由于表现太好,可能存在“陷阱”,需要再次确认变量信息以及分箱数量是否合适。
本文对年龄、流量、月出账收入、步骤2 的20 个行业中各个行业使用的APP 个数、30 个APP 的流量值共计53 个变量进行WOE 分箱,通过调节分箱个数和合并箱体的方式令IV 值达到最大,从而确定分箱。主要实现步骤如下。
a)将数据集D 等频划分为10 份,记录各划分点,计算不进行任何划分时的IV0。
b)遍历各划分点,计算利用各划分点进行二分时的IV 值。此处可选择设定箱体样本个数的最小值,且必须同时包含正负样本,如若不满足则不在该点划分,分别计算IV值,比较得出最大值MAX(IV)。
c)设定一个阈值BETA,若MAX(IV)>IV0×(1+BETA),则进行划分,且MAX(IV)对应的点确定为实际划分点,小于该划分点的数据集定为DL,大于该点的数据集定为DR;若MAX(IV)≤IV0×(1+BETA),则停止。
d)分别令D=DL,D=DR,重复步骤a、b、c。
以年龄为例进行分箱,结果如表1 所示。IV=0.1,认为年龄字段有一定贡献,且在年龄≤24 和35~49 的区间,WOEi>0,说明该年龄段的用户更倾向于使用作业帮APP,由于学生年龄在7 岁以上,其父母年龄大多在35 岁以上,二胎父母年龄更高,因此分箱结果可以解释为孩子用自己手机或家长手机使用作业帮APP,符合现实意义。
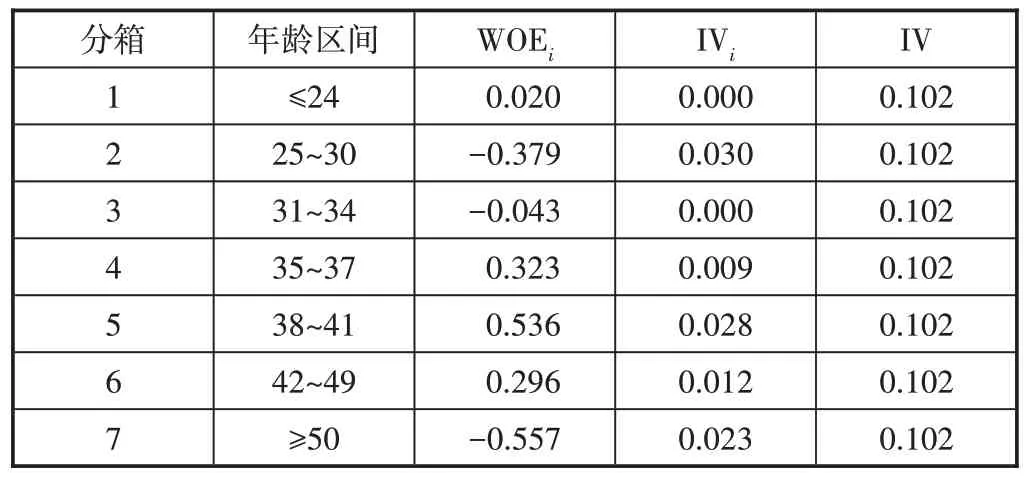
表1 对“年龄”进行WOE分箱的结果
2.3.2 one-hot变换
one-hot 的基本思想是将离散型特征的每一种取值都看成一种状态,若这一特征中有N个不同的取值,那么本文就可以将该特征抽象成N种不同的状态,one-hot 编码保证了每一个取值只会使一种状态处于“激活态”,也就是说这N种状态中只有一个状态位值为1,其他状态值都是0。
本文对分箱后的年龄、流量、月出账收入变量、行业数据、APP流量、性别、终端品牌、产品数据进行onehot 变换,从一个权重变为多个权重,提升模型的非线性能力。
经过特征工程后,每条样本的特征维度扩展为319维。
2.4 模型训练与应用
本文将样本数据按7∶2∶1 比例分为3 份,分别作为训练集、验证集、测试集。其中训练集用于训练模型,验证集用于调节算法的参数并对模型效果进行初评估,测试集用来评估各模型的泛化能力。本文分别采用逻辑回归、随机森林、GBDT 和LightGBM 4 种算法进行建模,其ROC 曲线如图5 所示,AUC 值分别为0.864 1、0.846 5、0.869 5、0.879 2。相对来说LightGBM模型效果最好。

图5 各算法模型ROC曲线对比
单纯用上述评估指标并不能很好地评价精准营销模型的应用效果,精准营销的目标是降本增效,本文设定评判模型效果的标准如下。
a)正样本的召回率尽可能高。即尽量覆盖潜在用户,避免遗漏太多。
b)在相同的召回率下,正样本的准确率尽可能高。即在相同的成交用户下,推广用户成本尽量小,即用尽量小的推广成本获取最大的用户转化率。
为了模拟实际应用效果,本文使用没有参与模型训练的测试数据集进行评估,图6 比较了采用各算法模型输出潜在用户的应用效果。从营销成本来说,如果转化的用户数相同(即正样本召回率一样),准确率越低意味着需要向更多的用户推广,即成本越高。图6 中曲线越往右意味着所需要的推广成本越低。从效益成果来说,在保证用户的转化率的前提下,召回率越高意味着销量越高,即效益越好。图6 中曲线越往上所产生的效益越好。因此,应用效果的优劣排序如下:LightGBM≥GBDT>逻辑回归>随机森林。为了比较基于机器学习模型和基于业务规则模型的效果差异,本文增加了基于百度贴吧筛选用户群和基于教育学习类APP 筛选用户群2个规则模型。基于教育学习类APP 的规则模型准确率为0.16,召回率为0.36。基于百度贴吧APP 的规则模型准确率为0.11,召回率为0.34。规则模型效果远不如机器学习算法模型。
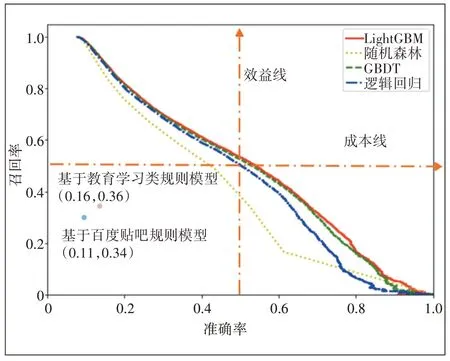
图6 各算法模型应用效果对比
3 结束语
跨界合作是未来运营商增加后向收入和提升用户黏性的重要途径,而实现降本增效的关键在于精准圈选目标用户。与传统互联网公司相比,运营商的优势是掌握各个APP 的流量数据,可以更全面地了解用户的上网偏好。本文提出运营商跨界合作体系构建的流程和方法,监控热门行业和成长行业,挖掘产品合作商机。以作业帮APP 为例,使用逻辑回归、随机森林、GBDT、LightGBM 4 种机器学习算法构建潜在用户模型,AUC值分别为0.864 1、0.846 5、0.869 5、0.879 2,并且从成本和效益2 个维度分析得出LightGBM 模型效果最好的结论,且机器学习模型优于基于百度贴吧和基于教育学习类APP 的业务规则模型。本文的处理流程和方法可以推广至其他APP的潜在用户挖掘。
猜你喜欢
华人时刊(2022年7期)2022-06-05
今日农业(2022年2期)2022-06-01
海峡姐妹(2020年5期)2020-06-22
通信产业报(2019年27期)2019-09-20
科学Fans(2019年11期)2019-02-05
领导决策信息(2018年16期)2018-09-27
人大建设(2017年10期)2018-01-23
通信产业报(2018年40期)2018-01-22
数学学习与研究(2017年3期)2017-03-09
计算机应用文摘·触控(2014年4期)2014-02-22
