
改进YOLOv3的多模态融合行人检测算法
2022-06-10 12:16邓佳桐程志江叶浩劼
中国测试 2022年5期
邓佳桐,程志江,叶浩劼
(新疆大学电气工程学院,新疆 乌鲁木齐 830049)
0 引 言
利用深度学习中的视觉技术[1]识别行人的精确位置,提高夜间光照下的行人检测效率。在过去的几十年,行人检测一直受到计算机视觉界的关注[2-3],广泛应用于无人驾驶、救援、监视、机器人等领域。多源传感器信息融合研究领域中有可见光和红外图像的融合,近年来也得到了深入的研究[4-5],但在夜间光照不足和小尺度目标下行人检测仍是待解决的问题[6]。
可见光单模态难以检测夜间光照较差、目标密集、小尺度目标及目标部分遮挡条件下的行人问题,而红外则弥补了可见光的缺点,红外相机根据物体的放热原理检测出行人。因此,将红外图像的行人检测结果与可见光的检测结果相结合,从而提高夜间行人检测准确性。
近年来,多模态融合技术被提出用于行人检测。文献[7]研究了前期和后期融合两种深度融合架构,用深层模型融合可见光和红外图像并在KAIST数据集上引入的模型和训练方法进行评估。文献[8]用SURF算法提取经过ICA处理后的红外图像,用加权融合算法进行图像融合。为了测试红外相机在无遮挡、部分遮挡和严重遮挡情况下的有效性,文献[9]中检测器采用扩展ACF(aggregated channel features)实现复杂场景下的行人目标检测并提出基于双目立体视觉行人检测方法。文献[10]提出视觉对比机制与ROI融合检测红外图像行人,但在复杂昏暗光照下效果不佳。文献[11]提出一种新的融合区域网络RPN(region proposal network),用于多光谱视频数据的行人检测,实验验证了融合多光谱图像信息的最佳卷积层,但只考虑了单独的特征层融合,在检测小目标的行人中检测准确率不佳。
针对目前算法存在的不足,本文以YOLOv3为基本框架作为行人检测算法,具有以下几方面的特点和创新:
1)可见光和红外光多模态输入的特征提取网络为Darknet-VI框架,有效提取两路模态的特征。
2)检测层中引入空间金字塔池(spatial pyramid pooling,SPP)以及内卷算子 (Involution),减少传统卷积网络的参数量和计算量,有效提升检测速度。
3)在Neck检测层中设计ResFuse模块并与注意力机制 CBAM(convolutional block attention module)组合,构成新的CBL-RC模块,提高网络的特征提取能力。
使用可见光和红外光模式融合解决夜间行人检测准确率低问题,并实现精确的实时行人检测。在KAIST数据集上进行了实验,实验研究结果分析表明,改进的YOLOv3算法可以满足复杂环境下的实时性和高效性要求。
1 YOLOv3算法
1.1 YOLOv3网络结构
YOLO算法[12]在2016年由Joseph Redmon首次提出。YOLOv3的特征提取基于Darknet53框架[13]。首先,主干特征提取网络前向传播得到13×13的特征图;然后,通过与前一个网络中大小相同的特征层卷积压缩通道数并上采样,得到尺寸为26×26的特征图;以此类推,26×26大小的特征图相同处理获得52×52特征图。最终得到输出层尺寸分别为 (13,13,18)大目标,(26,26,18)中目标,(52,52,18)小目标。YOLOv3网络架构的总体框架如图1所示。
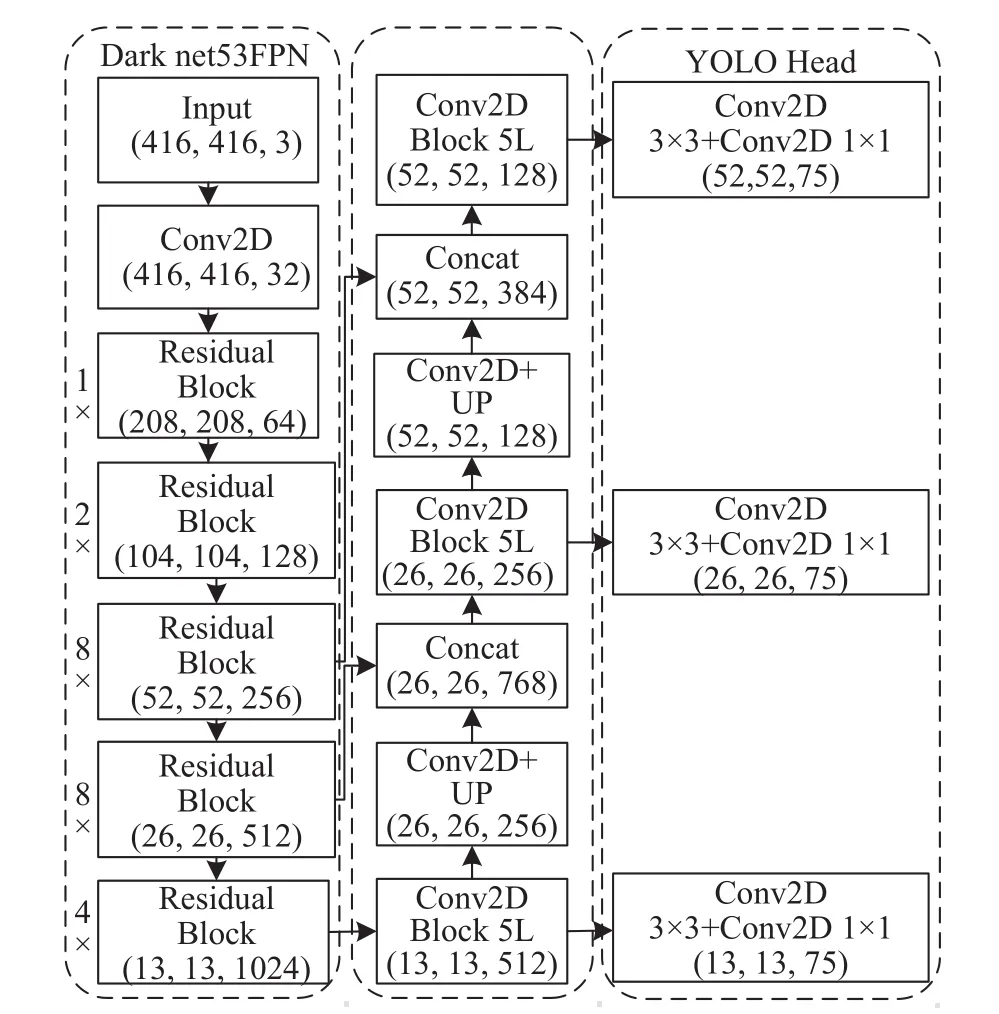
图1 YOLOv3网络结构总体框架
残差网络Darkent53先通过一个卷积核为3×3,步长为2的卷积操作进行宽高压缩得到输入特征图,使用64个3×3卷积核提取特征。在残差结构中经相同卷积操作后下采样,从而构成残差结构堆叠。
1.2 目标边界框预测
每个边界框中心点对应的cell可得到预测边界框的x,y,w,h,预测边界框与真实的groundtruth接近。目标预测边界框如图2所示,其公式如(1)~(6)所示。
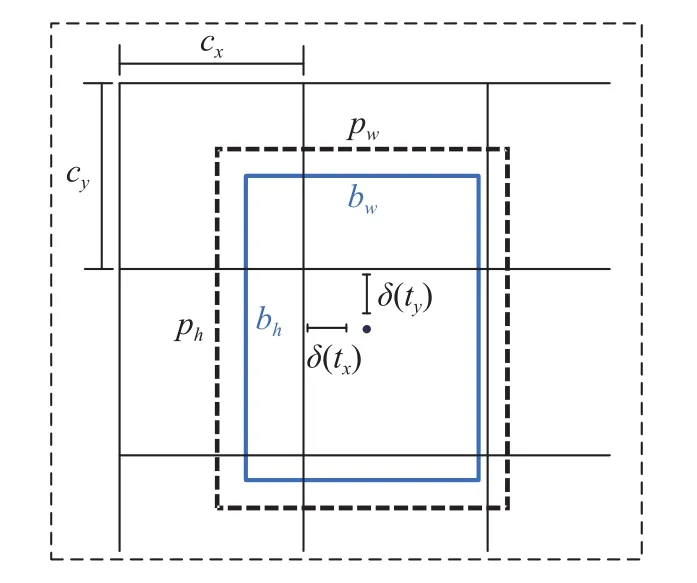
图2 目标边界框预测

式中:cx,cy——各个cell的左上点坐标;
tx,ty——输出 0~1 间隔偏移量;
tw,th——相对先验框的宽和高;
bx,by——边界框的长宽;
pw,ph——手动锚框相对特征图的宽和高;
Pr(object)——预测目标类别概率;
IOU(object)——预测框和目标框的交并比;
t0——预测目标置信值。
2 多模态融合的行人检测模型构建
改进的Darknet-VI网络框架作为YOLOv3-Invo的主干网络,Darknet-VI分别从可见光和红外光模式中提取特征。
本文改进的YOLOv3-Invo算法多模态融合的行人检测网络结构如图3所示。首先,选择相应的可见光和红外光图作为输入,分别提取其特征并进行级联融合拼接。在检测层中引入空间金字塔模块和内卷算子,通过通道输送到其他检测层中,提高了模型的准确性和效率;深度可分离卷积堆叠中设计ResFuse结合CBAM。最后,多模态融合的特征图输入到YOLO检测层中,输出检测行人的位置及概率。
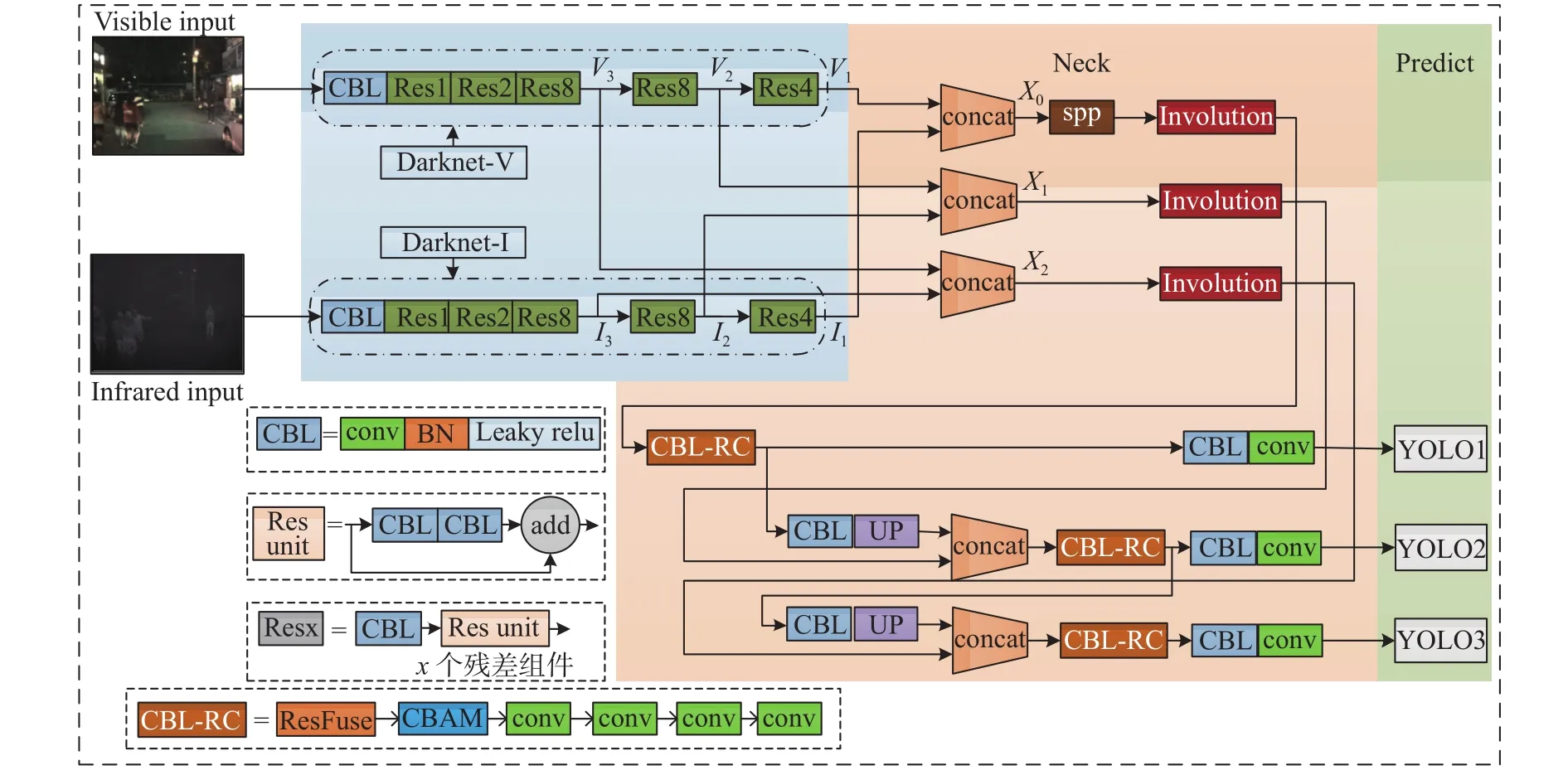
图3 Involution-YOLO算法多模态融合行人检测网络结构图
2.1 多模态特征提取和融合
本文采用双通道Darknet-VI结构作为多模态特征提取网络模块,可见光的特征提取网络记为Darknet-V,相应的特征图记为 {V1,V2,V3};红外光的特征提取网络记为Darknet-I,相应的特征图记为{I1,I2,I3}。通过concat将2种模态的特征图进行级联融合,输出融合结果记为 {X0,X1,X2}。多模态特征信息提取模块设计示意图如图4所示。

图4 多模态特征提取模块框架
特征融合模块采用级联融合方式,通过增加通道数及卷积操作将两个不同特征图拼接起来。每个输出通道的卷积核是互不相关的,可见光输入的通道为V1,V2,V3,红外输入的通道为I1,I2,I3,则 concat的输出通道如公式(7)。
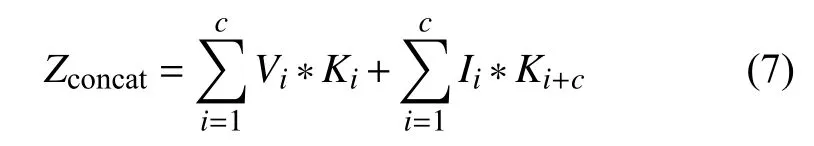
式中:*——卷积;
Zconcat——输出通道;
Vi——可见光输入通道;
Ii——红外光输入通道,i=1,2,3。
2.2 引入空间金字塔池化层
本文在concat级联融合后的第一个尺度检测层引入空间金字塔池化层,各个尺度检测层向下依次传递,分别输入到YOLO2、YOLO3中,使得行人检测效果更优。SPP模块实现了不同尺度特征的融合池化后得到的特征图尺寸大小和深度不改变,空间金字塔池化模块如图5所示。

图5 空间金字塔池化层
2.3 内卷算子
Involution算子概念由李铎和胡杰等人在2021年CVPR论文[14]中首次提出,相比传统的卷积更加轻量和高效。其计算量分为核生成和乘加运算两部分。
内卷算子运算中内卷核有空间特异性和通道共享性。内卷核在空间维度中卷积核不同,可满足不同位置上自适应地分配权重,且每一组内通道共享一个卷积核,从而大幅度减少了计算复杂程度。
在Involution设计中,通过每一组计算共享的内卷核的数量,再对输入乘加运算得到内卷输出特征映射,内卷核定义如公式(8)。

内卷核的卷积核形状输入特征映射的形状决定。在原始输入张量条件下产生的Involution使输入和输出核对齐,其核产生的函数符号记为Φ,各个位置(i,j)的函数映射抽象如公式(9)。
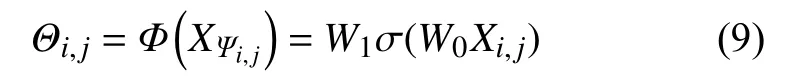
其 中,Ψi,j为 坐 标 (i,j)领 域的 一 个 量 度集 合。W0∈RC/r×C,W1∈R(K×K×G)×C/r,W0和W1为共同构成两个线性变换,r为通道缩减比率,内核生成函数为Φ:RCRK×K×G。
δ表示批准归一化和交错两个线性投影的非线性激活函数,公式如(10)所示。
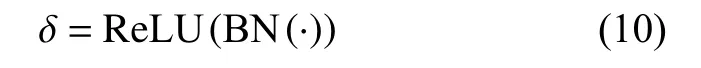
内卷核 Θi,j∈RK×K×1(G=1)是在 (i,j)处以一个像素为条件的函数Φ产生,进行通道到空间的重排;重排后的Involution进行乘加运算,其 ⊗ 代表跨C个通道的张量分别与内卷核做乘法运算,⊕代表在K×K空间领域内元素与内卷核的核心做求和计算。Involution内卷算子示意图如图6所示。
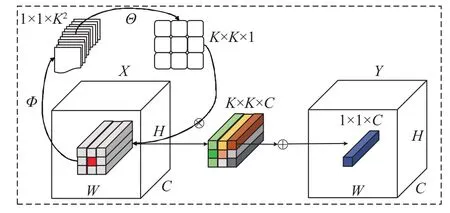
图6 Involution内卷算子示意图
2.4 改进的Neck部分
普通的深度卷积堆叠模块由5个深度卷积层、批准归一化和激活函数组成。改进的深度卷积堆叠CBL-RC模块由8个CBL深度卷积模块组成,采用新设计的ResFuse模型替换第一个普通卷积块,ResFuse模块与七个卷积层输出的特征图进行了加法运算后作为CBAM的输入;结合注意力机制CBAM模块,使提取特征能力更强。
在通道注意力机制模型中,提供一种中间特征图F∈RC×H×W作为输入,整体注意力过程见公式(11)。
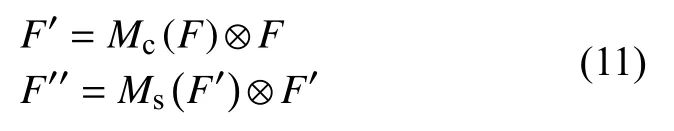
式中:⊗——元素乘法;
F″——最后的输出特征图;
F′——空间模块的输入特征图;
F——模块的输入特征图;
Mc∈RC×1×1——一维通道注意力层;
Ms∈R1×H×W——二维空间注意力层;
C——通道数;
H——高度;
W——宽度。
最大池化层和平均池化层聚合特征后得到两个空间描述符号其传递到共享网络生成通道注意力机制Mc。经过多层感知机MLP(multi-layer perception)操作后得到共享网络并运用到每个描述符,使元素求和并输出特征向量,通道注意力计算见公式(12)。

在空间注意力机制模型中,聚合特征图的通道消息通过平均池化层和最大池化层操作,卷积层连接并进行卷积操作后Sigmoid运算得到生成的空间注意力特征图Ms,空间注意力的计算见公式(13)。
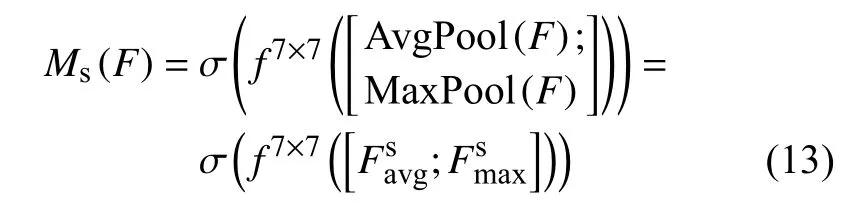
生成的空间注意力特征图Ms作为输入,将特征图输出并传递给卷积,整体改进的Neck网络结构图如图7所示。
图7 改进的Neck网络结构
2.5 实现流程
本文实现流程如图8所示。筛选出符合的可见光和红外行人数据集,通过LabelImg工具进行标注并将数据集划分训练集、验证集,通过脚本将数据集转换成.xml文件与之一一对应的.jpg图片后,使用本文改进的YOLOv3框架进行训练。
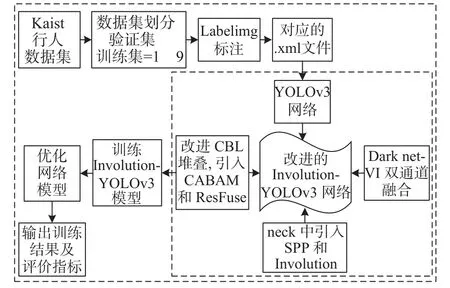
图8 多模态融合行人检测流程图
3 实 验
3.1 实验环境及训练参数
本文的实验环境见表1。输入图像大小为416×416,初始学习率为0.001,批处理大小(batch size)为20,模型总共训练了100个epoch,采用Adam优化器。
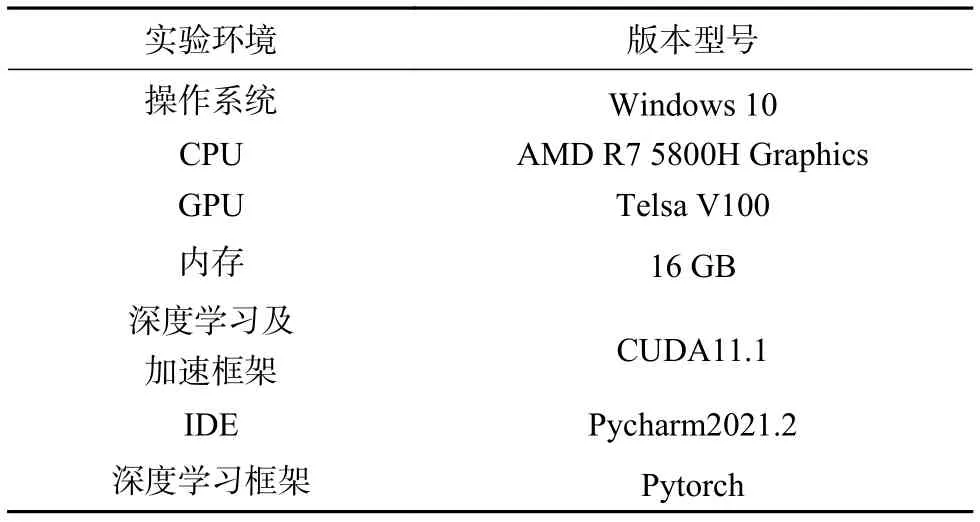
表1 实验环境
3.2 数据集
本文使用KAIST公开多模态行人数据集进行训练。该数据集是由Hwang[15]等人创建,在本文中,该数据集set00-set05为训练数据集,set06-set11为验证数据集,set00-set02,set06-set08为白天,set03-set05、set09-set11为夜晚,本文针对弱光环境下多模态行人检测,所以提取每部分弱光、行人遮挡的数据集进行训练。因为KAIST数据集是通过视频剪辑出来的图片,每张图片间相似度较高,为防止过拟合,将原始数据每隔5帧取一张图片,最后筛选出2 090对可见光和红外图像,将验证集和训练集比例分为1∶9进行训练。
3.3 实验结果与分析
3.3.1 单模态和多模态融合算法检测效果比较分析
为了证明本文提出的改进多模态融合算法的有效性,本文将融合的结果与可见光单模态的检测结果进行比较,效果明显优于可见光单模态效果。在KAIST数据集中选取了微弱环境下光照条件、目标密集情况、目标尺寸不一致、目标位置被遮挡以及目标正常尺寸大小5种条件下的图像,如图9所示,其中图9(a),图9(b)中行人背景环境比较暗,行人密集且目标特征不明显。图9(c),图9(d)中行人目标尺寸大小不一致且目标位置又被遮挡情况。则图9(e)是与前面4种情况对比的正常情况下的行人。

图9 不同环境下行人检测实验图
从图10至图12融合实验检测结果对比图,其中图10基于可见光单模态的行人检测结果图;图11基于可见光和红外多模态融合的行人检测结果图;图12基于本文改进的YOLOv3-Invo多模态融合算法的行人检测结果图。

图10 可见光单模态的行人检测结果图

图11 可见光和红外多模态融合的行人检测结果图

图12 改进的YOLOv3-Invo多模态融合算法的行人检测结果图
从图10中的(a),(b),(d)可以看出仅可见光单模态检测单一行人均出现漏检情况,可见光单模态中微弱光照情况下行人目标几乎难以肉眼识别,但本文改进的YOLOv3-Invo多模态融合算法检测效果优于单模态及YOLOv3-spp+多模态融合算法。图10(d)中被白车几乎完全遮挡的红帽行人和灰衣行人,却被检测出为同一个行人,并且黑衣行人未被检测出。图11(d)检测出黑衣行人,但仍未将红帽行人和灰衣行人进行区分,而本文提出的算法图12(d)能够有效区分,图13为算法的 P-R 对比图。
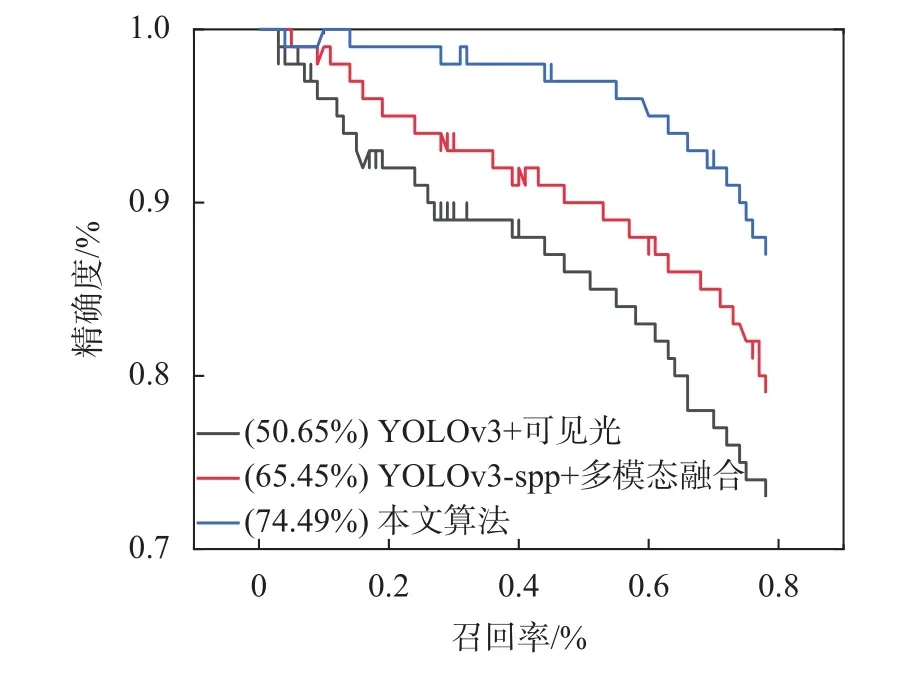
图13 算法的P-R对比图
3.3.2 改进算法在检测指标上的比较分析
目标检测中常用的评价指标有精确度(precision)、召回率 (Recall)、平均精度 (averageprecision,AP)、平均精度均值(mean average Precision,mAP)以及调和平均F1。其计算公式见(14)~(18)。

式中:TP——被模型预测为正类的正样本;
FP——被模型预测为正类的负样本;
FN——被模型预测为负类的正样本;
P(r)——P-R曲线;
N——检测目标类别的数量。
为了验证本算法的有效性,将可见光单模态算法、可见光和红外多模态融合算法及本文算法进行对比,算法检测指标对比结果见表2所示。

表2 算法检测指标对比
从表2可知,从评价指标进行对比,将可见光和红外融合的算法采用Darknet-VI作为特征提取网络,在精度上和召回率相比可见光单模态提高了5.61%和6.32%,mAP也提升了14.8%。改进的YOLOv3-Invo算法因增加内卷算子并在深度卷积堆叠模块中结合CBAM,其检测精度为93.81%,比YOLOv3+可见光提高了13.85%,比YOLOv3-spp+多模态融合提高了8.24%。改进算法在召回率上比单模态提高了9.14%,比YOLOv3-spp+多模态融合提高了2.82%。在微弱环境、目标密集和遮挡情况下仍然能有效检测出行人,说明本文提出的YOLOv3-Invo算法具有相对好的鲁棒性。
图11是本文行人检测算法对应的P-R曲线,在图种可看出YOLOv3-Invo的P-R曲线明显优于单模态和可见光和红外融合算法。
为了验证本算法的性能,将本算法和YOLOv3+可见光、YOLOv3-spp+多模态融合进行MR(Miss Rate)进行对比,见表3所示。从表3可知,本文算法的MR值为12%,与可见光和红外融合算法(32%)降低了20%,相比可见光单模态的MR降低了39%。

表3 算法在KAIST数据上的MR值
4 结束语
本文提出了一种改进YOLOv3-Invo的多模态融合行人检测算法,在Neck检测网络层引入了Involution内卷算子并设计了ResFuse模块并结合CBAM注意力机制模块。相比传统的卷积更加轻量和高效,在精度上提升了13.85%,在召回率上提升了9.41%,使得检测的目标更加精确,提高特征提取能力并减少误检漏检情况。
从检测实验对比结果可看出,本文算法在夜晚光照和小目标遮挡情况下,本文算法的检测效果较理想。下一步,研究考虑用不同的特征提取网络和图像融合方法来训练模型,使用其他深度学习检测算法来提高检测精度,增加算法的泛化能力,并将优化算法部署在嵌入式系统中。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
昆明医科大学学报(2022年3期)2022-04-19
中国传媒大学学报(自然科学版)(2021年1期)2021-06-09
意林(2021年5期)2021-04-18
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
扬子江(2019年1期)2019-03-08
电子制作(2018年19期)2018-11-14
小天使·一年级语数英综合(2017年6期)2017-06-07
