
从图像到图像的场景重建技术研究
2022-06-09 04:53:48冉建国
激光与红外 2022年5期
冉建国,刘 珩,杨 鑫
(陆军工程大学,江苏 南京 210007)
1 引 言
夜间实施迷彩作业主要受限于光照条件,难以获取有效背景信息,成为伪装技术中的一大难题。考虑到红外数据不受白天黑夜的限制,本文提出将红外图像转换成彩色图像的构想。传统的场景重建技术,大多利用数学计算的方式从二维图像中恢复三维立体结构信息。尤其近年来消费级深度相机的出现,通过仪器设备,比如深度扫描仪,Kinect等仪器,将 RGB 彩色图信息与深度图信息进行融合计算,进而完成三维场景重建。这类传统的三维场景重建方法经过不断的研究改进,目前已经趋于成熟,如基于2D匹配图像的SFM(Structure from Motion)算法[1]、用RGBD相机实时三维重建的Kinect Fusion 算法[2-3]、基于RGB图像和模型的亮度变化连续性的Bundle Fusion 算法[4]。以 Kinect Fusion算法为例,其采用了Frame-to-Model 的方式注册(通过当前帧深度图像转换得到的点云,和根据上一帧相机位姿从模型投影获取的深度图像转换得到的点云进行配准),通过深度传感器拍摄的深度信息来对相机轨迹进行跟踪并实时重建场景的三维建模算法。迷彩的本质是无限接近于使用环境以方便隐藏目标。在目标上实施迷彩的伪装成效,主要取决于背景颜色的复制水平[5]。以上三种方法的共同特点是,在白天取景,且均是利用重构算法将2D图像转换为3D图像。迷彩伪装方案设计的关注点主要在背景颜色的采集上,夜晚无法有效获取光学数据,这对设计方法的结果有显著影响,红外热图的获取却不受影响。为此,我们提出了一种基于pix2pix的红外图像与可见光图像转换的设计方法,将可见光数据集和对应的热红外数据集训练后,进行了红外热图场景重建,获得了与地面背景真实情况基本一致的视觉特性。结果表明,使用pix2pix能够进行场景重建,得到了重要的背景颜色信息[6]。因此可以说pix2pix是一种有效的场景重建方法,解决了夜间可见光信息采集的难题。
2 原 理
2.1 生成式对抗网络
生成对抗网络(generative adversarial networks,GAN)是一种无监督机器学习算法生成数据的深度神经网络架构,理论上可用于场景重建模型,因为它可以学习图像数据的分布方式,但GAN采用无监督学习的方式在提取特征的过程中没有针对性,导致生成的图像颜色布局比较随意,主要颜色失真度较高,图像结构难以保持稳定[7]。生成器负责学习从一个噪声向量映射在潜在的输出图像的空间目标域,判别器负责将图像从训练图像或生成器产生的图像进行分类。生成器和判别器都是用反向传播训练的,它们都有各自的损耗函数。GAN的体系结构如图1所示。为了使生成网络生成的图像能以假乱真,达到逼真的目的,应尽量提高生成网络生成数据和真实数据之间的相似度。可使用目标函数测量这种相似度。生成网络和判别网络均有目标函数,训练过程中也分别试图最小化各自的目标函数。GAN最初的目标函数如下所示:
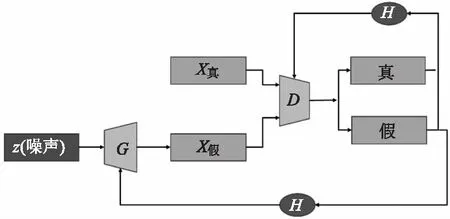
图1 GAN的架构Fig.1 The structure of the GAN
[log(1-D(G(z)))]
(1)
其中,D(x)是判别网络模型;G(z)是生成网络模型;p(x)是真实数据分布;p(z)是生成网络生成的数据分布;E是期望输出。在训练过程中;D(判别网络,discriminator)试图最大化公式的最终取值;而G(生成网络,generator)试图最小化该值。如此训练出来的GAN中,生成网络和判别网络之间会达到一种平衡,此时模型即“收敛”了。
2.2 提议方法
本文首次尝试红外图像与可见光图像转换达到场景重建的目的。在GAN中,生成器仅从潜在变量z产生图像。然而,在图像到图像的平移任务中,生成的图像必须与源图像相关。为了解决这个问题,可以使用条件GANs(cGAN),将附加信息y作为输入[8]。例如,接收源图像作为生成器和鉴别器的附加信息。cGANs的损失函数如下:
LG=-Ex~pdata(x)[log(1-D(x,z)]-
Ez~p(z)[log(D(z,x))]
(2)
LD=-Ex~pdata(x)[log(D(x,z))]
-Ez~p(z)[log(1-D(z,x)]
(3)
观察上式,能发现的一个明显特点是,两个公式把D部分中的x和z部分交换了一下,符合GAN的基本思想:鉴别器负责鉴定真实图像,生成器负责生成虚假图像。本文的框架是使用Isola等[9]人的工作,pix2pix是一个扩展的cGAN,用真实图像代替随机噪声,学习从输入图像到输出图像的映射,并使用一个损失函数来训练这种映射,生成器和判别器分别由 U-Net 和 PatchGAN 组成。在pix2pix中,损耗鼓励生成器生成一个类似于条件变量x的样本。它是训练图像x和生成图像G(x,y)之间每个像素差的绝对值的平均值。本文引入了一个多尺度融合网络,使用空洞卷积在同等参数数量情况下额外扩大了感受野。多尺度融合网络模块如图2所示。
卷积神经网络通过逐层学习的方式提取目标的特征,高层网络语义信息表征能力强,但是特征图的分辨率低,空间几何特征细节缺乏;低层网络几何细节信息表征能力强,但是语义信息表征能力弱。本文采用高层与低层跳跃互联的方法。从图2中可以看到,该结构的优势在于层与层之间并不孤立,每一层与其他层之间均有关联,优化了网络结构,缩短了传输路径,节省了运算时间。

图2 多尺度融合网络模块Fig.2 Multi-scale fusion network module
Pix2pix方法需要训练图像对,该图像对由红外图像和相应的彩色图像组成。在U-net架构中,编码器层和解码器层通过“跳跃连接”直接连接[9]。因为跳越连接可以跨越编码器-解码器网络的瓶颈传输低级信息(这些信息通常在输入和输出图像之间共享)。它有效地提高了图像转换的性能。在卷积PatchGAN中,不是对整个图像进行分类而是将每张图像分成N×N段,然后预测每一部分是真还是假。最后取所有答案的平均值,进行最终的分类。换句话说,只有特定规模的补丁结构才会受到惩罚。我们工作中的pix2pix框架如图3所示。通过判别器输出的对抗损耗和生成图像输出的损耗更新生成器的权值[10]。同时训练一个条件生成器和判别器,训练生成器根据输入图像(在本文中,是相应的红外热图)生成图像(在本文中是彩色背景图像)。该判别器的目的是对生成的彩色图像进行真假分类。
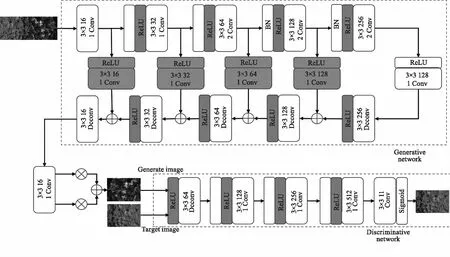
图3 Pix2pix网络结构图Fig.3 Pix2pix network structure diagram
本文优化模型改善了生成图像的清晰度,以真实背景数据为基础,尽可能地预测真实背景的主要颜色;其次,通过交换D部分的x和z,极大的减小了生成数据与真实数据间的差异[11]。最后,通过结构相似性分析和心理物理学实验进行效果评估检验模型在场景重建中的客观性与可靠性,对夜间伪装作业具有重要意义。
3 实验结果与分析
3.1 数据集
本文数据集借助大疆M300 RTK在南京汤山拍摄的成对数据集,由80张红外热图与彩色图像组成,每张图像大小为1024×1024像素,扩充后最终得到了260张非重叠的数据集。对于训练集,我们从这些图像中提取220对随机图像。另外,为了定量评估,我们将剩余的40张图像作为测试集(在训练集中看不到)。为了验证所提出算法的有效性,本文编写了Python程序并完成了相关实验。在使用64位Windows 10操作系统上选用Python搭建生成对抗网络。训练过程使用GPU芯片,显卡型号为TITAN V,显存大小为120G,虚拟环境采用Anaconda,PyTorch1.4.0,CUDA 10.0。
3.2 实现图像到图像的翻译
该方法不需要参考图像,但对于目前最先进的方法,以经验证明对参考图像的选择的敏感性。pix2pix网络不仅学习红外热图到彩色图像的映射,还学习一个损失函数来训练这种映射。由于判别器的训练相对于生成器来说是高速的,因此判别器损耗分为两部分来减缓训练过程。生成器和判别器模型都使用Liyuan Liu等[12]的RAdam版本进行训练,它既具有Adam快速收敛的优点,又具备随机梯度下降不易震荡的优势,令模型收敛至质量更高的结果,如图4所示。

图4 采用不同优化器后的训练损失对比Fig.4 Comparison of training losses with different optimizers
3.3 评价指标和结果分析
传统的质量指标在评估相似性时,这个值的下降部分是由于两类数据集之间的微小差异造成的。为了展示pix2pix网络将红外热图转换成彩色图像的良好结果,我们利用了不同的评价指标来度量,分别是结构相似指数(SSIM)、峰值信噪比(PSNR)、均方误差(MSE),如表1所示。

表1 使用不同方法生成的数码迷彩方案评价指标(平均值±std)Tab.1Digital camouflage scheme evaluation index generated by different methods(mean ±std)
图5(a)代表夜间用红外相机采集到的原背景图,图5(b)代表使用本文方法生成的彩色图像,图5(c)代表用光学镜头在白天采集到的彩色图像,由图5可以发现山体、道路、植被、天空等背景特征均能取得较好的还原,结合表1中的数据分析生成彩色图像的质量,SSIM值大于0.5,说明本文方法生成的彩色图像在场景重建方面有不错的效果。另外从心理物理学角度检验生成情况,类别判定法是一种对刺激的感知进行分类的心理物理学实验方法。该方法要求观察者在观察样本剌激之后,将刺激的视觉感知按照类别判定量表进行分类。采用该方法时,首先应正确划分类别判定量表,取有特殊意义的点,如判断色差时,可将无色差、恰可察觉色差、恰可接受色差等作为分类点。一般,类别判定法的分类可以根据需要分为5类、7类、9类等,也有一些研究为了避免观察者取中间值,而将类别划分为偶数,如6类、8类等。在实验过程中,观察者按照给出的类别判定量表对观察到的刺激进行分类,然后根据Torgerson的类别判定法和统计假设理论,转化为等距量表,如表2所示。

表2 类别判定量表Tab.2 Category determination scale
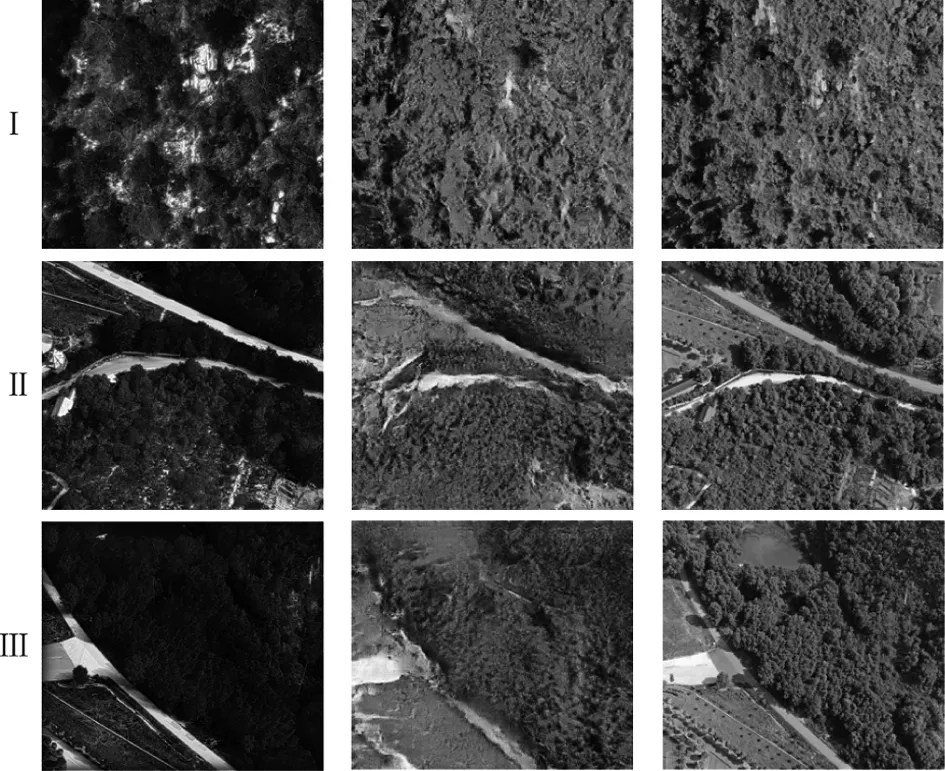

图5 生成的彩色图像与真实背景图像之间的对比Fig.5 The contrast between the generated color image and the real background image
在实验设计中,共安排了10名色觉正常的观察者参加,均为在校大学本科生,包括5名男性和5名女性,年龄介于20和25之间。每名观察者进行了两次,用来分析观察者间的精度。因此,本实验所获得的视觉评价数据共有100个,10名学生均选择类别1,无感知色差;可见经过生成的彩色图像能够实现场景重建人眼视觉要求。
4 结 论
本文使用了pix2pix架构来进行红外图像到彩色图像的转换,为夜间伪装方案设计提供了可行的技术途径。以图像到图像的生成对抗网络为支撑的网络架构可以进行场景重建,能有效应对夜间能见度不足无法采集背景信息的限制。针对模型效果评估的问题,根据机器视觉的特点提出利用结构相似性等一系列算法和心理物理学实验进行生成图像效果评估。实验结果表明,该方法能够将红外图像转换成逼真的彩色图像,并且在评价指标上取得了不错的效果,验证了所提出方法在场景重建中的有效性。
猜你喜欢
黑龙江大学自然科学学报(2022年4期)2022-11-17 08:08:06
作文小学中年级(2020年6期)2020-07-24 08:33:10
成都信息工程大学学报(2019年4期)2019-11-04 00:56:02
电子制作(2019年16期)2019-09-27 09:34:46
阅读与作文(英语初中版)(2019年8期)2019-08-27 03:59:25
小学生学习指导(低年级)(2018年11期)2018-12-03 05:05:00
自动化学报(2017年5期)2017-05-14 06:20:56
现代防御技术(2016年1期)2016-06-01 12:13:27
东北电力大学学报(2015年1期)2015-11-13 05:20:36
电子设计工程(2014年18期)2014-02-27 12:00:31
