
面向柔性作业车间调度的改进混合蛙跳算法*
2022-06-08 06:48:02王玉芳葛嘉荣
组合机床与自动化加工技术 2022年5期
王玉芳,缪 昇,葛嘉荣
(南京信息工程大学 a.江苏省大气环境与装备技术协同创新中心;b.自动化学院;c.江苏省大数据分析技术重点实验室,南京 210044)
0 引言
柔性作业车间调度问题(flexible job-shop scheduling problem,FJSP)作为作业车间调度问题(job-shop scheduling problem,JSP)的一个分支,它打破了机器唯一的限制,即待加工工件可以在可选机器集中选择一台或者多台机器进行加工,这无疑更加符合当前复杂的生产制造环境,因此FJSP受到了越来越多的关注,并取得重大进展[1-4]。
作为一个典型的NP-Hard难题,在过去的30年中,随着科学技术的发展,许多的算法被用于解决这类问题,诸如遗传算法[5]、粒子群算法[6]、模拟退火算法[7]、禁忌搜索算法[8]等,这些算法在求解FJSP上都取得了良好的效果。基于这类智能算法的启发,近年来,也是有越来越多的仿生智能算法被提出,并且在解决FJSP上展现了优越的效果,连裕翔等[9]提出了一种改进的Jaya算法,融合M.G和N7两种邻域结构的禁忌搜索算法,使混合算法在分散搜索与集成搜索之间达到平衡,在解决FJSP上显示出了良好的性能。赵诗奎[10]提出一种融合改进邻域结构的混合算法,结合关键工序设计了相应的移动操作,对已有邻域结构进行了优化与扩展,提高了邻域结构的精准有效性。
蛙跳算法(shuffled frog leaping algorithm,SFLA)作为一种新型的仿生物学智能优化算法,具有概念简单,调整的参数少,计算速度快,全局搜索寻优能力强,易于实现的特点[11-12]。张晓星等[13]构建了以最大完工时间和总加工能耗最小为优化目标调度模型混合蛙跳算法,设计了多种局部搜索操作以及邻域操作来防止算法陷入局部最优,但在种群初始化时并未考虑启发式规则,这就大大削弱了算法的性能,延长了算法寻找到最优解的时间。艾子义等[14]提出了一种基于新型蛙跳算法的柔性作业车间调度模型,加入全局和局部结合的协调优化搜索策略,并且取消了种群重组,大大简化了算法结构,但在解码过程中并未考虑启发式解码规则,而传统的解码规则会使得算法陷入局部最优,降低收敛速度。
受已有研究启发,本文提出一种改进的混合蛙跳算法(improved shuffled frog leaping algorithm,ISFLA),首先,利用启发式规则按比例生成高质量的初始种群,加快算法的收敛速度;其次,采用贪婪解码的方法代替传统解码方式,加强对解空间的搜索和最优解的挖掘;最后,加入了考虑机器平衡的局部搜索方法,很好的弥补了算法局部搜索能力不足的缺点。
1 问题描述
作为一个典型的NP-Hard难题,FJSP可以描述如下:有台机器m(M1,M2,…,Mm)处理n(J1,J2,…,Jn)个工件,每个工件有若干道工序,Oij表示工件i的第j道工序,每道工序可以在不同机器上进行加工,且在不同的机器上的加工时间是不相同的。调度目标是通过为各工序选择合适的机器进行加工以及调整各个机器上工序加工的先后顺序来使最大完成时间最小。本文中的时间均为抽象的单位时间,此外,在加工过程中还需要满足下列的约束条件:
(1)调度开始前所有工件和机器都处于准备就绪状态且所有工件都可以从零时刻开始被加工;
(2)每台机器在同一时间只能加工一道工序;
(3)同一个工件的同一道工序在同一时间只能被一台机器加工;
(4)同一个工件的工序有前后加工顺序约束,加工完上一道工序才能开始下一道工序的加工;
(5)不同的工件之间没有加工顺序的束。
定义如下数学描述:n为工件总数;m为机器总数;i为工件序号,i=1,2,3,…,n;h为机器序号,h=1,2,3,…,m;ei为第i个工件的工序数;j为第i个工件的工序号,j=1,2,3,…,ei;Oij为第i个工件的第j道工序;mij为第i个工件的第j道工序的可选机器集中机器的个数;Oijh为第i个工件的第j道工序在机器Mh上加工;tijh为第i个工件的第j道工序在机器Mh上加工的时间;sij为第i个工件的第j道工序的开始时间;cij为第i个工件的第j道工序的完成时间;K为一个特别大的正数;Ci为工件Ji的完成时间;Wh为第h个机器的负载,h=1,2,3,…,m。
约束条件如下:
s.t.
ci0=0
(1)
sij+xijh×tijh≤cij
(2)
Ci(j-1)≤sij
(3)
cij≤Cmax
(4)
sij+tijh≤skl+K(1-yijhkl)
(5)
Ci(j-1)≤sij+K(1-yijhkj)
(6)
(7)
sij≥0,cij≥0
(8)
式(1)表示虚拟的第零道工序完工时间为零;式(2)和式(3)表示同一个工件包含的工序必须按照先后顺序处理;式(4)表示任意工序的完成时间不超过总的完成时间,式(5)和式(6)表示在某一时刻的一台机器上只允许处理一道工序;式(7)表示在某一时刻同一道工序只能在一台机器上处理;式(8)表示任意工序的开始时间和完成时间都是非负的,且任意工件都可以从0时刻开始加工。
2 ISFLA算法
在传统的SFLA中,每一个青蛙的位置代表一个解,若干个青蛙组成的种群代表一个解的集合,种群被划分为不同的组,即模因组,对每个模因组执行搜索过程,当达到终止条件后,重新将模因组合并成新的种群,这个过程称作种群重组。搜索和重组过程持续进行直到满足终止条件。
在FJSP中,每一个青蛙代表一个个体,即一个可行解,每一个可行解都有一个评价其优劣的指标,即目标值。考虑到传统SFLA依靠位置更新公式来产生新解,这种方式难以应用于FJSP这种离散问题中,所以需要对SFLA离散化,构建合理的编码解码以及搜索重组方式。
2.1 编码
FJSP包含两个基本问题,即工序调度问题和机器分配问题[15],因此,该问题的解决方案通常由两部分组成[16-18],工序串和机器串,工序串表示所有工件的加工顺序,机器串表示工件对应所选择的加工机器号。一个3×3的FJSP实例如表1所示。其中“2”表示第一个工件的第一道工序在1号机器上加工的时间为2,“-”表示该工件的该道工序不能在该机器上加工,以此类推。一个完整的解决方案可以表示为{[1 3 2 1 2 3][3 3 2 1 1 2]},第一部分{[1 3 2 1 2 3]}表示工序加工顺序,数字代表工件号,数字出现的次数则代表对应工件的第几道工序。第二部分{[3 3 2 1 1 2]}表示对应工件所选择的加工机器。
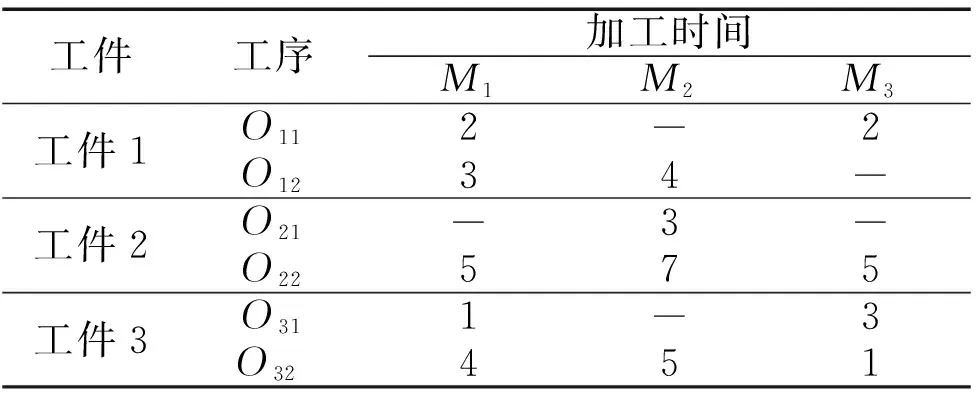
表1 3×3FJSP实例
2.2 解码
解码是为了将工序串和机器串转换所求的目标值,在此基础上合理地安排各个工件在机器上加工,从而使得目标值最优。本文为了实现染色体解码对解空间的高效搜索,设计了一种进化贪婪插入法(evolutionary greedy insertion,EGI),其解码过程如图1所示。

图1 EGI解码过程示意图
工序Oij即将在机器Mb上加工,根据当前加工情况,有三段空闲可供选择,Idle1、Idle2和Idle3三段空闲时间均大于等于Oij的加工时间。Idle1的开始时间小于Oi(j-1)结束时间,故不满足约束条件。Idle2和Idle3都满足约束条件,而Idle2更接近Oij的加工时间,所以选择Idle2插入。相对于一般的解码方法,EGI提供了更多可供选择的空闲时间段,更利于找到最优解。
2.3 种群初始化
初始种群质量的优劣对于算法而言至关重要,一个高质量的种群能够为算法的进化提供一个优越的起点,使算法减少从差解到优解的搜寻时间。本算法采用了ZHANG等[19]提出的GLS初始化方法,即全局选择(global selection,GS)、局部选择(local selection,LS)和随机选择(random selection,RS),除此以外,再加入一种全局最小化(global minimization,GM)方法,选择可选机器集中加工时间最短的那一台机器进行加工。在上述多种启发式规则启发下生成的初始种群能够为算法的进化提供一个较好的起点,加快算法的整体收敛速度。
2.4 族群划分
混合蛙跳算法区别于其他算法最大的特点就是对种群进行分组,而传统的随机划分方式由于不能平衡各个组内青蛙的优劣程度,会大大增加算法求解的随机性,使得算法的收敛速度变慢。本文算法采用LEI等[20]提出的二元锦标赛选择方式将种群划分成w个族群V(V1,V2,…,Vw),先从种群中选择最好的w个个体依次作为每个族群中的第一个个体,再从余下的个体中利用锦标赛选择法补充每个族群的剩余个体,即从剩下的种群中随机选择两个个体Q1和Q2,优秀的那一个个体进入V1,作为V1中的第二个个体,较差的那个返回种群;再从种群中随机选择两个个体,较好的那一个进入V2,作为V2中的第二个个体,以此类推,直至所有的族群被填满。
2.5 族群内进化策略
对于每一个族群内的个体来说,如果都采用相同的进化策略,则难以对不同质量的个体进行有针对性的进化,所以为了避免盲目进化,通常在各自族群内部会区分出优劣个体,然后对其采用不同的更新策略进行优化。对族群中优秀的个体采用邻域搜索,加强对更优解的挖掘。对族群中的劣势解,则采用全局加局部结合的协调优化策略,平衡整个族群中个体的优劣程度,加快算法的收敛速度。
2.6 更新策略
2.6.1 交叉操作
交叉的目的是为了获得新的个体,在尽量保证优良基因不被破坏的情况下,对解空间进行高效搜索,因而交叉操作应该满足可行性、继承性和非冗余性。针对FJSP的特性,ZHANG等[21]提出的POX交叉法,因其具有低约束性,并且可以避免冲突检测,所以被普遍用来完成对工序编码层的交叉操作。本文对POX交叉法进行局部改进,提出一种改进的交叉法(improved intersection method,IIM),具体步骤如下:
步骤1:选出两条染色体P1、P2作为父代,P1=[1 3 2 4 3 1 2 4 3],P2=[3 1 1 2 4 4 2 3 3];
步骤2:将工件集J={1,2,3,4}分为两个非空子集,J1={1,2},J2={3,4};
步骤3:复制P1中包含在J1中的基因按原顺序插入子代染色体C1中,复制P2中包含在J1中的基因按原顺序插入子代染色体C2中;
步骤4:复制P2中包含在J2中的基因按原顺序插入C1中,复制P1中包含在J2中的基因按原顺序插入C2中,得到C1=[1 3 2 4 4 1 2 3 3],C2=[3 1 1 2 4 3 2 4 3];
步骤5:对C1、C2进行倒序操作得到C3、C4,C3=[3 3 2 1 4 4 2 3 1],C4=[3 4 2 3 4 2 1 1 3],对C1、C2、C3、C4进行解码操作,选取最优的两个解代替C1、C2。
而对于机器编码层采用多点交叉方式,可避免产生非法解。具体步骤如下:
步骤1:随机选择两条机器染色体L1和L2,L1=[1 2 5 3 4 2 6 1 5],L2=[3 3 5 2 1 4 2 3 3];
步骤2:生成一个和机器染色体维度一样的0、1数组X,X=[0 0 1 1 0 0 1 0 0];
步骤3:找到矩阵中所有1所在的位置;
步骤4:将所有位置1上的L1和L2的基因对换得到L1′和L2′,L1′=[1 2 5 2 4 2 2 1 5],L2′=[3 3 4 3 4 2 6 3 3]。
2.6.2 局部搜索操作
为了提高算法的搜索能力和开发能力,在保持种群多样性的同时又能够提高算法的收敛能力,本文算法采用了分别针对于工序编码层和机器编码层的局部搜索策略。
(1)针对工序编码层OS,采用如下步骤进行局部搜索操作:
步骤1:选择一条工序染色体P,P=[1 3 2 4 1 1 2 2 3];
步骤2:随机选择两个工序数相等的工件J1和J2,J1={1},J2={2},找出它们所有工序在染色体中的位置;
步骤3:交换两个工件对应所有工序的位置,并保持原来的顺序,得到新的工染色体P′,P′=[2 3 1 4 2 2 1 1 3]。
(2)针对机器编码层,结合图2具体搜索步骤如下:
步骤1:选择一组染色体,其中工序染色体为P,P=[1 1 2 3 3 1 4 2 4];机器染色体为L,L=[2 1 3 2 3 1 3 2 1];对应加工时间矩阵为T,T=[1 2 1 3 1 4 1 2 2 ];
步骤2:计算出所有机器上的总负载Ptotal,Ptotal=[8 6 3];最大完成时间Cmax,Cmax=9;计算得到所有机器的负载率,其中每台机器的负载率P=Ptotal/Cmax,P=[0.89 0.67 0.33],并排序得到负载率最高和最低的机器;
步骤3:在满足约束条件的情况下,从负载率最高的机器上选择该机器加工的最后一道工序移动到负载率最低的那一台机器上,从图2可以看出,在未进行该局部搜索时,最大完成时间为9,经过该局部搜索,将M1上的O42移动到M3上,得到的最大完成时间为8。

图2 机器局部搜索
2.7 ISFLA算法整体框架
根据上述改进策略,结合FJSP,提出的ISFLA框架流程图如图3所示。
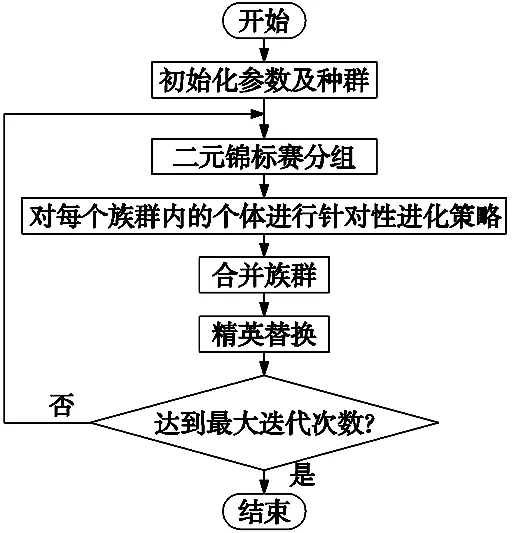
图3 ISFLA流程图
3 实验数据与分析
3.1 参数设置
ISFLA采用MATLAB编程实现,程序在Windows7系统,主频为2.9 GHz,内存为8 G的个人电脑上运行。由于参数的选择对算法的运算结果也十分重要,所以采用正交试验基于Brandinmrte[22]系列中的MK01算例来确定最终的参数,具体参数包括种群大小popsize,迭代次数maxgen,族群个数w以及每个族群内部搜索的次数gen。另外,考虑到算例规模大小对算法的运行效果有较大的影响,所以因子水平的选择均与算例的工件数与机器数有关。
对于一些规模较小的算例,如果参数选择过大可能会造成冗余计算,削弱算法的整体运行效率,而对于一些规模较大的算例,参数设置的过小则会造成搜索不完全,容易遗漏最优解。综合考虑之后选择了表2所示的指标水平。正交试验规模为 L9(34),即试验次数为9,参数个数为4,因子水平数为3。

表2 参数组合
算法在9种参数组合的基础上分别运行10次,得到的Cmax的平均值Cavg,Cavg越小则表示该种参数组合越适合ISFLA,正交试验结果如表3所示。

表3 正交试验结果
可以看出,参数组合8所得到的Cavg最小,表示这组参数最适合ISFLA,所以最终的参数设置为popsize=6×m×n,maxgen=m×n,w=m,gen=2×m×n。
3.2 策略有效性分析
为了进一步验证改进策略对算法的影响,本文对这些改进策略进行了有效性分析,3种改进策略分别为改进启发式规则初始化Ispt-Initial、改进贪婪解码方法EGI以及考虑机器负载平衡的局部搜索策略Local-Balance,然后对这3种改进策略进行排列组合得到7种不同的改进算法,然后在传统的SFLA基础上分别加上这7种改进算法,得到的进化曲线对比图如图4所示。
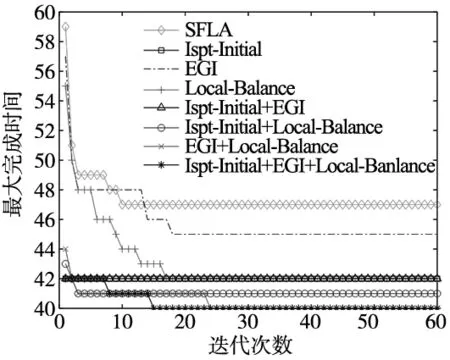
图4 改进策略进化曲线
可以看出,传统的SFLA在求解MK01算例时效果并不理想,而随着改进策略的加入,算法的性能逐渐提升,尤其Ispt-Initial这一改进策略得到的效果尤为突出,可见启发式规则对于算法的进化是十分重要的,它为整个算法提供了一个优秀的起点,加速了算法的收敛,避免了冗余计算。
而EGI和Local-Balance虽然改进效果不大,但相较于传统的SFLA,效果依旧可观。接下来3种改进策略的两两组合相较于其各自单独作用效果更加明显,其中Ispt-Initial和EGI这两个的改进策略的组合要明显优于另外两种,除了启发式初始化规则发挥的作用外,这种改进的贪婪解码方式为解码提供了更多可供选择的可插入空闲时间段,在满足约束 条件的前提下选择最优的空闲时间段插入,大大提高了解码的时效性。最后在这一基础上加入了Local-Balance这一局部搜索策略,最大化的考虑每台机器上的负载平衡,在减小Cmax的同时也能够减小能耗,改进效果也是最好的。
3.3 算例对比
为了更加直观地验证ISFLA在解决FJSP上的高效性能,本文与文献[23-25]提出的算法性能进行对比,采用Brandinmrte系列中MK01-MK10算例。对比算法具体标识如下:ICSO为文献[23]提出的猫群算法,VNS_MBOA为文献[24]提出的变邻域搜索候鸟优化算法,IGPSO为文献[25]提出的改进博弈粒子群算法。本文算法ISFLA与上述3种算法对比如表4所示,其中m×n表示工件数与机器数的乘积,即总工序数;C*表示已有文献得到的最优解;min表示本文算法得到的最优解;avg表示算法运行十次得到的平均值。

表4 ISFLA与WSA、VNS_MBOA、IGPSO最优解的比较
可以看出,ISFLA在MK01-MK10算例的求解上Cmax和Cavg都优于另外两种算法,并且MK01、MK02、MK03以及MK08算例都得到了与已有最优解相同的Cmax。另外可以看到,在处理小规模问题上例如MK01、MK03这类算例都取得了很好的效果,但随着问题规模的扩大,ISFLA性能有所降低,尤其是MK06和MK10这两个算例,机器数增多,工件可选择的机器数就增加,这无疑加大了不确定性,也同时加大了ISFLA求解的难度。另外从表4可以看到,本文算法在求解MK02实例得到最大完成时间不仅得到了与已有文献相同的最优解,并且另外三种算法没有得到,所以图5给出了MK02算例的调度甘特图,其中每个矩形中上面的数字代表工件号,下面的数字代表工序号。

图5 MK02算例调度甘特图
从图5可以看出,MK02实例的最大完成时间为26,与已有文献得到的最优解相同,并且各个工件之间基本没有间隙,说明贪婪插入的解码操作起到了很好的作用,提高了加工的效率,避免了不必要的加工损耗。
4 结论
本文针对最小化最大完工时间这一目标,结合传统蛙跳算法的优点和不足之处,提出了一种改进的混合蛙跳算法,从种群初始化、解码方式以及局部搜索策略这3个方面进行相应的改进。与随机初始化种群相比,利用启发式规则生成的种群质量更高,能够为接下来的进化过程提供一个优质的起点。而进化的贪婪解码方式则相较于传统的解码方式能够提供更多可供选择的插入空闲时间段,在满足所有约束条件前提下优化目标函数。试验结果表明,改进的混合蛙跳算法在寻优能力和收敛性上都优于传统的蛙跳算法,并且相较于另外3种智能算法,本算法表现出了更加突出的寻优性能。在实际生产应用中,多目标的生产调度问题无疑更加符合当下复杂的生产环境,所以由单目标生产调度向多目标生产调度的转变是很有必要的。另外为了响应当前“绿色制造”的号召,所以下一阶段将围绕多目标“绿色”调度展开。
猜你喜欢
中国石油石化(2022年12期)2022-07-16 08:28:28
科学之友(2021年12期)2021-12-23 04:19:09
语数外学习·高中版中旬(2021年4期)2021-11-24 07:17:51
小猕猴智力画刊(2021年2期)2021-02-22 07:22:26
中国外汇(2019年19期)2019-11-26 00:57:32
家庭影院技术(2018年11期)2019-01-21 02:20:50
家庭影院技术(2018年11期)2019-01-21 02:20:48
中国学术期刊文摘(2016年2期)2016-02-13 16:01:41
新乡学院学报(2015年6期)2015-11-06 08:04:55
电网与清洁能源(2015年2期)2015-02-28 16:03:15
